
基于混合神经网络的实体关系抽取方法研究
2021-11-16 08:14杜坤钰杜军威
中文信息学报 2021年10期
葛 艳,杜坤钰,杜军威,陈 卓
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
0 引言
目前,实体关系抽取技术的研究在信息抽取领域受到了极高的重视,实体关系抽取作为信息抽取、自然语言理解、信息检索等领域的核心任务和重要环节,能够从非结构化或半结构化文本中识别出实体信息以及实体之间的语义关系类别的信息[1]。
传统的实体关系抽取方法最先采用基于特征的方法并取得了较好的效果,但是后续研究发现该方法无法很好地利用实体对的上下文结构信息,于是研究者们又提出了一种基于核函数的方法,但是由于中文与英文的句子结构有很大的不同,中文句子结构比较松散并且词语之间没有位置的指示信息,所以最终基于核函数的传统实体关系抽取方法也没有取得理想的效果[2]。
在深度学习不断发展的过程中,自然语言处理(NLP)任务用到了越来越多的神经网络模型[3]。基于深度学习的实体关系抽取方法主要是通过将低维词向量表示为不同粒度的语言单元,然后使用卷积和循环等神经网络模型来达到自动学习并提取相关特征的目的[4]。Socher等[5]提出的关系抽取方法使用到了递归神经网络(RNN),该方法利用了句子的句法结构信息,但是忽略了实体对的位置信息和语义信息。Zeng等[6]提出的关系抽取的方法,使用到了卷积神经网络(CNN),该方法采用单个最大池化操作来确定语句中的最重要的特征,后来 Collober[7]和Kim[8]等通过实验证明了Zeng等提出的方法在提取文本特征任务中具有很好的效果。但是人们发现只进行单个最大池化操作捕获不到两个实体之间的结构信息,这是因为单个最大池化会快速地减少隐藏层的参数。然而在关系抽取任务中实体之间结构特征是至关重要的,因此Zeng等[9]将原方法进行了改进,标记实体所在的位置,并根据实体位置将需要池化的向量先分成三段再进行池化操作,最终取得了较好的效果。
在实体关系抽取任务中,为了更好地利用实体的上下文信息,双向神经网络被广泛运用到了实体关系抽取模型中。Zhang等[10]提出的关系抽取的方法使用了双向RNN,该方法能够利用词语序列的上下文语义信息,可以从最原始的数据中学习到关系模式,缺点是在具体的迭代过程中不能避免梯度消失的问题,能利用的信息有很大的局限性。Zhang等[11]提出的关系抽取方法,使用的是双向长短时记忆网络(BiLSTM),替代了容易出现梯度消失问题的双向RNN模型,该方法可以获取到实体之间的长距离关系,更好地利用实体的上下文信息,最终取得了满意的关系抽取效果。由于LSTM的结构比较复杂,Dey和Salemt[12]提出了门控循环单元GRU,做为LSTM的一个变体,GRU模型的结构更加简单,参数也更少,运用到关系抽取任务中其在收敛时间和需要的迭代次数上更具优越性。
后来Attention机制也被逐步运用到关系抽取任务中,并取得了很好的效果。Attention机制在关系抽取任务中的作用是重新分配权重,首先让模型能够自动地识别出句子中对分类结果影响较大的成分,然后根据该成分对关系分类结果的影响程度来分配相应大的权重,从而可以增强该模型对重要成分的关注度。Zhou等[13]提出的关系抽取的方法就是基于Attention机制的,该方法能关注到词对于句子的重要程度,最终提高关系分类的效果。
为了能够在实体关系抽取中考虑到实体之间的长距离关系,更好地获取文本序列的上下文语义信息,同时提取到更多更有效的特征,本文提出了一种新型的关系抽取模型BiGRU-Att-PCNN。该模型是基于BiGRU和PCNN的混合神经网络模型,利用BiGRU模块在文本序列中获取更多、更有效的实体的上下文语义信息;然后利用Attention机制的权值分配,根据特征元素对关系分类的影响程度来自动分配给该特征元素相应大小的权重;再将调整完权重后的序列传递给PCNN模块,该模块在执行完卷积操作之后,池化层会根据两个实体所在的位置将卷积结果分为三段,再分别对每一段进行最大池化操作,最终更好地获取到两个实体之间的结构信息和其他相关环境特征。实验结果表明,本文方法在公开的英文数据集SemEval 2010 Task 8上表现出了较好的性能[14]。
1 相关工作
关系抽取的方法主要包括基于特征的方法、基于核函数的方法和基于深度学习的方法。
1.1 基于特征的方法
基于特征的关系抽取方法主要是通过提取文本中的重要特征来描述实体之间的关系,然后将其组织成向量的形式,再利用机器学习算法来对该关系特征进行分类[15]。车万翔等[16]通过使用Winnow和SVM两种方法验证了能够在文本中提取到质量好的特征对于关系抽取的研究是至关重要的。董静等[17]提出的关系抽取方法使用到了条件随机场(CRF)模型,在已有的句法特征的基础上进行分类。甘丽新等[18]提出的关系抽取方法在句法语义特征的基础上进行中文实体关系抽取。以上基于特征的关系抽取方法都取得了较好的效果,但是这些方法依赖于特征的设计,还有NLP工具的准确率,整个方法设计既耗时又容易导致错误累积,最终影响分类的性能。
1.2 基于核函数的方法
基于核函数的方法首先是设计核函数,计算对象在高维空间中的相似度,从而获取对象的结构化特征,再根据该结构化特征来构建分类模型[19]。Zelenko等[20]最早使用核函数的方法进行实体关系抽取。郭剑毅等[21]提出的基于多核融合的实体关系抽取方法,通过改进径向基核函数保留了实例的原状结构,该方法是通过在高维度的特征中选取特定的核函数对来计算两个实体关系的相似度,但是该方法依赖于核函数的设计,通用性不强[14]。
1.3 基于深度学习的方法
基于深度学习的方法可以自动学习文本特征,对NLP工具的依赖性很小,并且能够更加充分地利用文本中的结构信息。Liu等[22]较早地提出了将CNN运用到实体关系抽取任务中。Zeng等[6]在Liu等提出的方法中增加了位置向量以达到能够在句子中表征出实体所在的位置信息的目的,从而可以提取到句子中关系实例的局部特征,但是卷积神经网络学习不到实体之间的长距离的语义信息。Zhang等[10]提出的关系抽取方法使用递归神经网络代替卷积神经网络来进行关系实例建模,该方法用简单的位置标签来代替位置向量,解决了长距离词之间的依赖问题。Li等[23]提出的关系抽取方法运用递归神经网络对不同的句法结构进行建模。但是运用RNN的单网络实体关系抽取模型存在梯度消失的问题,无法利用很广泛的信息范围,也整合不了过长序列的相关依赖。因此,Hochreiter等[24]提出的关系抽取方法运用LSTM记录距离较远的历史信息,有效解决了运用RNN时的梯度弥散问题,并且能够很好地捕获序列的整体信息,但是该方法只能学习一个方向的信息。Zhang等[11]提出的关系抽取方法运用BiLSTM来进行关系抽取,可以学习双向的信息,更好地获取双向的语义依赖,在实体关系抽取任务上取得了不错的效果。王红等[25]提出的关系抽取方法结合了BiLSTM与Attention机制,该方法不但可以很好地学习到词与词之间的相互关系信息,而且还利用Attention机制考虑到了关系抽取模型的输入和输出之间的相关性,最终获得了更加有效的文本特征,取得了理想的关系分类效果[14]。
2 基于BiGRU和PCNN的关系抽取模型
2.1 框架概述
为了更好地表征出非结构化文本中的上下文环境信息,更准确地识别出实体信息及实体之间的语义关系类别,本文提出了BiGRU-Att-PCNN关系抽取模型,该模型主要由Embedding层、BiGRU层、Attention层、PCNN层和Softmax层组成,整体结构如图1所示。

图1 BiGRU-Att-PCNN模型结构
2.1.1 Embedding层
Embedding层的词嵌入训练是利用Word2Vec[26]算法来进行的,首先,生成每个单词的w维词向量。另外,为了记录句子中每个单词到两个实体的相对距离以充分地获取到句子中词语的句法和语义信息,本文在模型中加入了相对位置特征,例如,“Sam was born in Boston”中,能够体现关系的单词“born”到头实体“Sam”和尾实体“Boston”的相对距离分别为2和-2。将这两个相对距离分别映射成随机初始化的两个p维的位置向量。句子向量S={q1,q2,…,qn},由n个单词的实值向量qn表示而成,其中qn是第n个单词xn的词向量和实体相对位置向量的组合[14]。S∈Rn*d,其中,d=w+p*2。
2.1.2 BiGRU层
BiGRU层是一系列GRU单元,控制信息的增加和删除。GRU是LSTM的一种效果很好的变体,模型中只有两个门,分别是更新门和重置门[27]。GRU的具体结构如图2所示。

图2 GRU单元的体系结构
GRU单元在信息传递过程中,更新门的值zn和重置门的值rn共同控制了从之前的隐藏状态hn-1上计算获得新的隐藏状态hn[14],如式(1)~式(4)所示。
其中,qn和hn分别是GRU单元的输入和输出,n是单词序列中的位置,Wz、Wr、Wh、Uz、Ur、Uh都是权重矩阵,σ()是Sigmoid函数。

其中,⊕是向量求和符号,最终BiGRU层输出结果向量为H={H1,H2,…,Hn},Hi∈Rd。
2.1.3 Attention层
Attention层的作用是对BiGRU层获取到的语义特征进行加权处理,输出的结果向量为T={T1,T2,T3,…,Tn},其中,Ti∈Rd。
Attention层的计算分为相似性计算、归一化处理和计算BiGRU输出的Attention值三个步骤。相似性计算是使用余弦相似度来计算Ti和Hj的相似度得分Scoreij,如式(8)所示。
(8)
其中,在第一轮训练时,T的初始值为H。
归一化处理是对Ti和H的相似度得分Scoreij进行归一化处理,如式(9)所示。
(9)
最终得到Ti和H所对应的权值向量ai={ai1,ai2,…,ain}。
最后计算出BiGRU输出的Attention的值T,如式(10)所示。
(10)
经过Attention层的加权处理,在语句中对分类结果影响较大的词会被赋予较大权重,对分类结果影响程度较小的词被赋予较小的权重。
2.1.4 PCNN层
PCNN层由卷积层和分段最大池化层组成。为了进一步识别出实体之间的语义关系,本文模型中的卷积层将Attention层的输出向量序列T={T1,T2,T3,…,Tn}结合权重向量w进行了分段卷积操作。其中,权重矩阵w被认为是卷积的滤波器。假设滤波器长度为l,则w∈Rl*d。
为了更好地捕获到更多不同的特征,本文模型在卷积操作中使用了m个滤波器(W={w1,w2,…,wm})。卷积操作涉及到取w和在序列T中每个l-gram的点积,以获得另一个序列c∈Rn+l-1,卷积操作计算如式(11)所示[14]。
cki=wkTi-l+1:i1≤k≤m
(11)
式(11)中的Ti-l+1:i是Ti-l+1和Ti的连接,索引i的取值范围是1到n+l-1之间,当i<1或者i>n时,Ti的值为0。卷积运算结果为矩阵C={c1,c2,…,cm}∈Rm*(n+l-1)。
最开始卷积输出矩阵C的大小是取决于输入到模型中的句子的长度,而本文是将卷积层提取的特征组合起来应用于后续层,因此最终的输出结果不再取决于输入到模型中的句子长度。本文提出的关系抽取方法运用的是分段最大池算法,首先识别出输入的句子中的两个实体,再根据两个实体所在的位置将句子向量分成三段,最终返回的结果是每个段中的最大值[9]。如图1所示,每个卷积滤波器的输出结果ci根据两个实体的位置被分成了{ci1,ci2,ci3}三段,如式(12)所示。
pij=max(cij) 1≤i≤m,1≤j≤3
(12)
对于每个卷积滤波器的输出,可以得到一个三维向量pi={pi1,pi2,pi3}。然后连接所有的向量p1:m,并将其应用于双曲正切非线性函数[14],如式(13)所示。
g=tanh(p1:m)
(13)
其中,g为分段最大池的输出向量,其大小是固定的,跟句子的长度再无关系,g∈R3*m。
2.1.5 Softmax层
Softmax层的作用是计算出在实体关系抽取任务中定义的每个关系标签的概率,将Softmax函数应用于每个PCNN模块的当前输出向量g,生成一个L维向量,即标签类型的数量为L,再给定加权向量z,那么第j个标签的预测概率计算如式(14)所示。
(14)
2.2 模型训练与优化

(15)
其中,l为指示函数,j∈{1,2,…,K},K为标签类型的数量,当yi=j为真时l=1,否则为0。
另外,本文模型在BiGRU层之后添加了Dropout[30]策略来进行正则化约束,目的是按照一定的概率屏蔽掉神经网络单元,从而达到防止过拟合的目的,并提高模型的训练速度。
2.3 模型训练过程
本模型针对的是英文语料的关系抽取,当句子序列输入神经网络之后,嵌入层首先将输入到该神经网络模型中的句子序列进行词嵌入训练,生成易于数值运算的嵌入向量。再将该向量输入到BiGRU层中,该层会提取到每个元素以及每个元素所在位置的关系等序列特征。但是由于BiGRU有一定的距离衰减性,所以当BiGRU运算完毕过后,本文模型增加了Attention层来将该BiGRU层得到的结果进行权值再分配,即根据其对关系分类结果的影响程度来分配相应大的权重后再送入到 PCNN 层中,例如,例1中的两个实体“report”和“role”的权值就会被Attention调高。在PCNN中进行的是分段卷积池化操作,具体步骤是先以两个实体所在的位置将整个句子分成3段,然后在这三段中分别提取细节特征和彼此之间的影响信息。最后由Softmax层将特征信息映射到对应的Message-Topic类型上,至此模型最终就形成了类型特征到类型上的一个完整映射[14]。
例1This describes the of neuroprotection in acute disorders such as stroke and injuries of the nervous system.
关系:Message-Topic(e1,e2)
3 实验与分析
3.1 数据集
为了验证本文提出的实体关系抽取模型的有效性,实验选用了公开的英文数据集SemEval 2010 Task 8。该数据集一共有10 717条语料,包括 8 000 条训练语料和2 717条测试语料。其中实体以及实体之间的关系都已标注,包含9种有方向的关系和1种无方向的Other类型的关系,因此有19种关系类型,详情如表1所示。

表1 SemEval 2010 Task 8数据集
3.2 实验设置及评价指标
本文实验使用的由Word2Vec算法进行词嵌入训练的词向量,维度为300。根据先验知识将K参数设置为20,alpha参数设置为4e-2,其他参数的最优值通过在数据集上运用网格搜索算法来确定,最终在第55~60个迭代轮中取得了最优结果。模型的最优参数设置如表2所示。
马来西亚森林分为三种类型,一是旱地林,占整个森林面积的93%;二是沼泽林,占整个森林面积的5%,他们分布在马来西亚半岛和沙捞越的海岸线上,担负着独特的生态系统功能;三是红树林,占整个森林总量的2%。

表2 最优参数设置
本文运用混淆矩阵求得在每个类别下的精确率、召回率和F1值[29],然后根据数据集官方文档中的评价指标macro-averageF1值作为衡量模型性能的评价指标。
3.3 实验结果与分析
为了确保实验的准确性,本实验在同类的关系抽取模型中进行了相同的输入,然后对各个模型获得的F1值进行比较。在各个模型中获得的F1值如表3中所示。
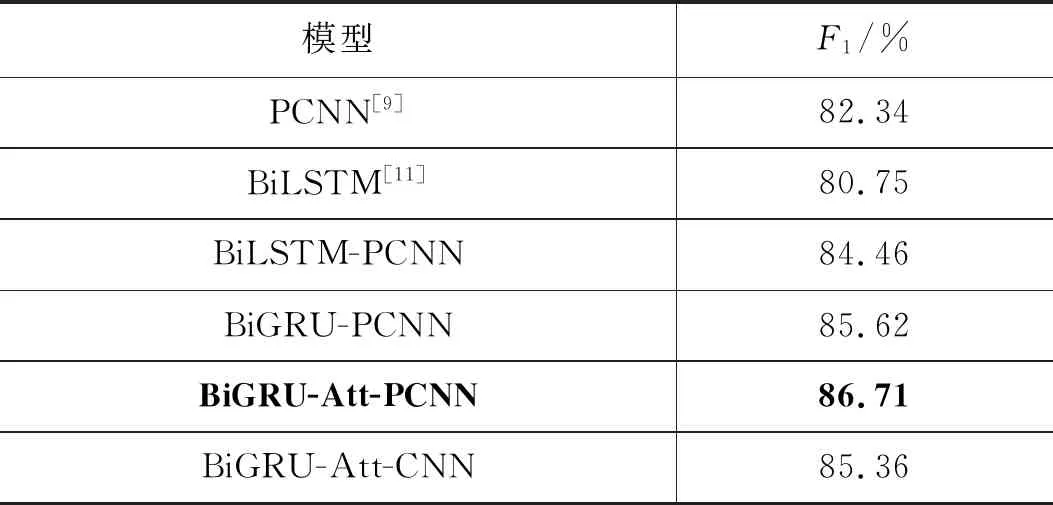
表3 各个模型中获得的F1值
对比表3中的在各个模型中获得的F1值的大小可以看出,基于混合神经网络的模型的性能是优于单个网络模型的,混合神经网络模型得益于各个模型在关系抽取中的作用互补,可以从多个角度来进行特征提取训练,从而更精确地提取关系特征。例如,单个PCNN模型只能关注到序列中的局部特征,而基于BiLSTM和PCNN两个神经网络模型的BiLSTM-PCNN混合模型可以先由BiLSTM模块解决掉长句子中的单词依赖问题,然后再利用PCNN模块来更好地获取特征之间的联系,最终提取到关系实例的整体特征,从而得到更好的关系抽取结果。另外在表3的实验结果中可以很明显地看出,BiGRU-PCNN模型比BiLSTM-PCNN模型取得了更高的关系分类效果,这是由于BiGRU相比BiLSTM的结构更加简单,且参数更少,既能够保留序列特征提取能力,又不易产生过拟合现象,因此BiGRU-PCNN模型的关系抽取效果更好。
本文模型是在BiGRU-PCNN模型的基础上,引入了Attention机制来进行优化,从表3可以看出本文方法取得了最高的F1值。本文模型比 BiGRU-PCNN模型的分类效果更好,是因为本文引入的Attention机制能够自动对齐BiGRU模型的输出和PCNN的输入,并自动关注到在序列中对关系抽取结果影响更大的序列元素,对其进行权值再分配,该操作使得PCNN层更好地利用到了BiGRU层的输出数据,最终提取到了更准确的关系信息。
图3为BiGRU-PCNN模型和BiGRU-Att-PCNN模型在相同测试集上的实验结果F1值的变化曲线,很明显可以看出BiGRU-PCNN模型在加入Attention之前其F1值的变化趋势波动较为剧烈,直到模型的最后收敛阶段,F1值的变化趋势仍然有较大的波动。与加入Attention后的模型F1值变化曲线相比较,在相同迭代次数下,很明显BiGRU-Att-PCNN模型的F1值波动幅度更小,收敛速度更快,最终取得的F1值也比BiGRU-PCNN模型高。经过以上分析可以得出结论:①在模型中加入Attention机制之后,将从BiGRU模块输出的结果进行权值再分配,使PCNN模块可以更直接有效地获取到有用的信息,从而有助于加快迭代的过程;②Attention机制的权值再分配功能会给对分类结果影响程度较小的信息赋予较小的权重,从而使得这部分信息在传递给PCNN层时被削减,这就减少了在模型训练过程中的噪声传递,最终该模型的F1值也就不会有那么剧烈的波动了。另外,通过分析图3可发现,模型的F1值随着迭代次数的增加也在逐渐增大,即使有一定的波动,但是波动的幅度范围很小,总体趋势是收敛于稳定的,证明了本文模型的稳定性[14]。

图3 F1值随迭代次数变化曲线
从表3中的数据可以看出,BiGRU-Att-PCNN模型比BiGRU-Att-CNN模型的F1值更大,也就是分类效果更好,这是因为PCNN模块在进行池化操作前根据两个实体所在的位置将句子的特征向量分成了3段,然后对每一段分别进行最大池化操作,这样分段卷积不仅更好地提取到了两个实体之间的结构信息和其他相关环境特征,而且有助于提取到更为丰富的特征。另外,通过实验可以发现,当增加CNN隐藏层的尺寸时,CNN也还是不能达到PCNN的分类效果,这是因为所有模型的参数都是通过网格搜索算法来确定的,不能通过简单地增加卷积神经网络的参数来获取到更有用的信息。
3.4 不同关系类型结果分析
为了探究本文方法在不同关系类型上的分类效果,本实验还统计了除Other之外的9种关系类型的F1值,如图4所示。
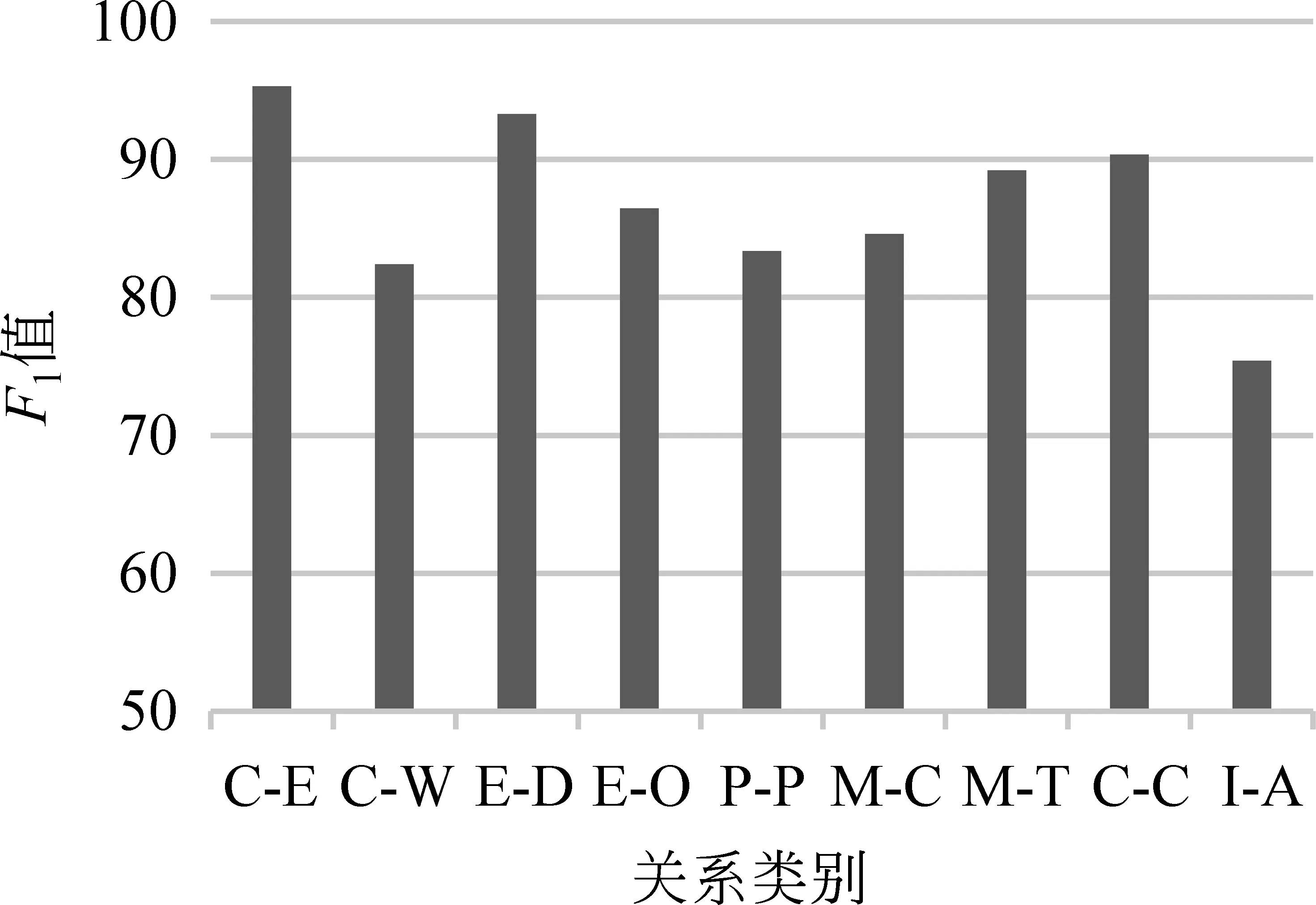
图4 不同关系类型的分类效果图
从图4中可以发现,关系类型C-E和E-D的F1值明显高于其他类型,I-A的F1值最低。通过对测试数据集进行分析,发现在F1值最高的C-E关系类型的句子中经常会出现“cause”和“result”等词汇及其变体,并且通常会伴随着介词“by”和“in”等一起出现,具有较明显的结构特征,关系类型E-D同样如此,因此这两个类型都有较好的抽取效果。对于F1值最低的I-A类型来说,虽然在句子中也有“use”等高频词汇及其变体出现,但在表示工具的使用时通常仅使用“by”和“with”等介词。这些介词在大部分的句子中是不伴随着高频词汇出现的,因此该类型的句子结构特征不明显,从而影响了关系分类的效果。
4 总结与展望
为了更精确地从非结构化文本中识别实体信息及实体之间的语义关系类别,本文提出了一种新型的混合神经网络BiGRU-Att-PCNN来进行实体关系抽取。该模型是基于BiGRU和PCNN两种神经网络模型的,与其他神经网络的模型相比,它能够更好地挖掘事件句的上下文语义信息,较好地学习相关环境特征,避免了使用复杂的特征工程,最终通过在公共的英文数据集SemEval 2010 Task 8上进行实验,取得了不错的效果。但是本文模型在处理结构特征不明显的句子时还存在不足,原因是在进行关系抽取时未充分利用文本中的语法特征,因此下一步的工作计划是在实体关系抽取模型中加入语义角色、词性、语法结构等特征,以争取获得更好的实体关系抽取性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
