
基于改进YOLO算法的激光清异场景目标检测方法
2021-11-15 09:21董晓虎方春华李承熹
湖北电力 2021年4期
吴 军,程 绳,董晓虎,范 杨,林 磊,方春华,李承熹,徐 鑫
(1.国网湖北省电力有限公司检修公司,湖北 武汉 430050;2.三峡大学电气与新能源学院,湖北 宜昌 443002)
0 引言
随着全社会对用电量需求的迅速增大,保证电力输送和用电安全也就成了非常重要的问题。但输电线路跨越森林,当树木生长高度接近架空导线时,易使导线对线路通道内超过安全距离的树木放电,造成的闪络、停电、火灾等事故,给线路的安全运行带来了巨大的灾难。除此之外,风筝、广告布、塑料布等漂浮性异物容易缠在导线和地线上,在雨雪的情况下容易引起单相接地、相间短路等故障,导致线路跳闸或线路损毁,影响供电安全,垂落地面的异物和烧断损毁的导线还有可能造成人畜伤亡。
目前,一般采用基于激光技术的异物清除装置[1-4],通过大功率激光的灼烧来达到清除异物的效果。由于激光树障清除装置功率较大,一旦照射到人或者其他公共物品,会带来极大的危害。因此电力激光作业属于高风险作业方式,需要做好严格的安全应对措施和解决办法,来防止电力激光清异过程中存在的危险[5-8]。
为了实现智能化、精确化的安全监察控制系统,采用人工智能技术是发展趋势。飞速发展的卷积神经网络(Convolutional Neural Network,CNN)技术和图形处理器(Graphics Processing Unit,GPU)快速发展,凭借图形处理器能够高效率地处理深度学习算法(Deep Learning,DL)训练和测试过程,使得深度学习这一需要大量计算的技术得以高速发展[9-15],所以深度学习在包括目标检测以及图像分类等图像识别任务上取得了非常大的突破。文献[16]采用改进的Faster R-CNN算法训练电力设备检测模型,然后对图像数据集进行数据扩充,并调整卷积核大小,从而实现了提高模型检测精度。文献[17]使用卷积神经网络提取图像目标特征,并将随机森林算法运用到网络中,将其作为分类器,实现对电力设施的识别,从而达到安全监控的效果;文献[18]对Faster R-CNN 进行改进,通过提出的改进策略能够有效实现输电设别的检测,并提出将图像先切分再检测的方法来提高小目标检测准确率。
上述文献针对人工智能算法优化及应用于电力设备等目标检测等问题进行了研究,实现了安全监控的效果,但并未考虑激光器户外使用时移动端性能受限等问题。本文考虑到YOLO算法对设备性能的要求较高,通过改进YOLO算法使之适用于移动端设备,同时搭建实验环境,扩充并建立激光清异安全控制图像数据集,进行了模型的训练,对比进行了移动端检测准确率及效率实验,验证了改进后YOLO算法的优势。
1 改进的YOLO算法
新一代YOLO 算法,虽然检测精度和效率大大提升,但同时模型本身的复杂性也大大提升,因此对算力的要求也越来越高,需要具有强大计算能力的服务器才能够进行有效的识别和检测,因此在最终的应用上,采用的还是前后端分离的检测方式。
对于电力激光作业安全监控中,激光器配备的摄像头本身就没有联网,没办法在激光器监控装置前端就实时获得后端的检测结果。而作业现场的监控摄像头虽然可能联网,但监控图像从前端传到服务器的过程中,可能因为网络等问题带来的不确定危险因素,从而降低了安全监控的有效性和实时性[19-23]。
所以,若是直接采用上述的目标检测算法对电力激光作业场景进行安全监控,会增加不必要的风险,无法达到实时安全监控的效果。因此,电力激光作业场景的安全监控应当选择轻量级目标检测神经网络模型在移动端进行实现,目标检测网络模型结构图见图1。
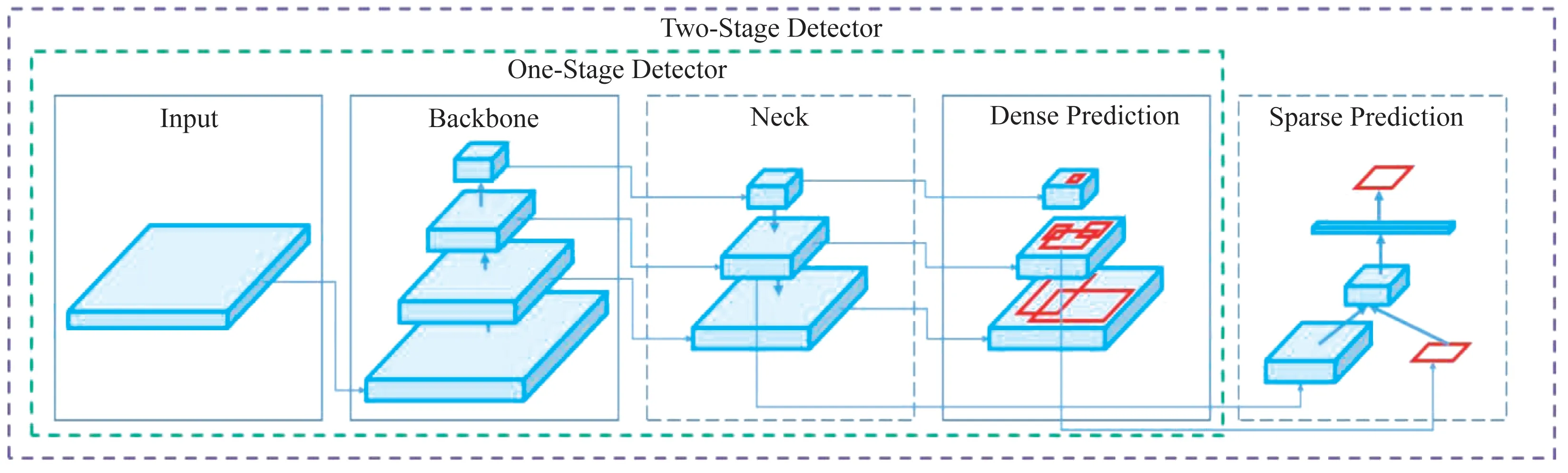
图1 目标检测网络模型结构Fig.1 Structure of target detection network model
目标检测模型往往分为四个部分,分别是:输入(Input)、骨干网络(Backbone)、特征融合网络(Neck)、检测器(Head)。针对电力激光作业安全监控装置的移动端性质,结合现有的目标检测研究现状,以YOLOv4 目标检测算法为基础,从骨干网络(Backbone)、特征融合网络(Neck)两个方面进行优化[24-26]。
1.1 改进的骨干网络(Backbone)
YOLOv4算法采用CSPDarknet-53作为骨干网络,整个网络约有6 000万个参数,极其复杂且需要较高的算力才能运行,所以并不适用于移动端。本文针对移动端的特性对主干网络进行调整,选择CSPDarknettiny 改进的特征提取网络,CSPDarknet-tiny 结构参数见图2。
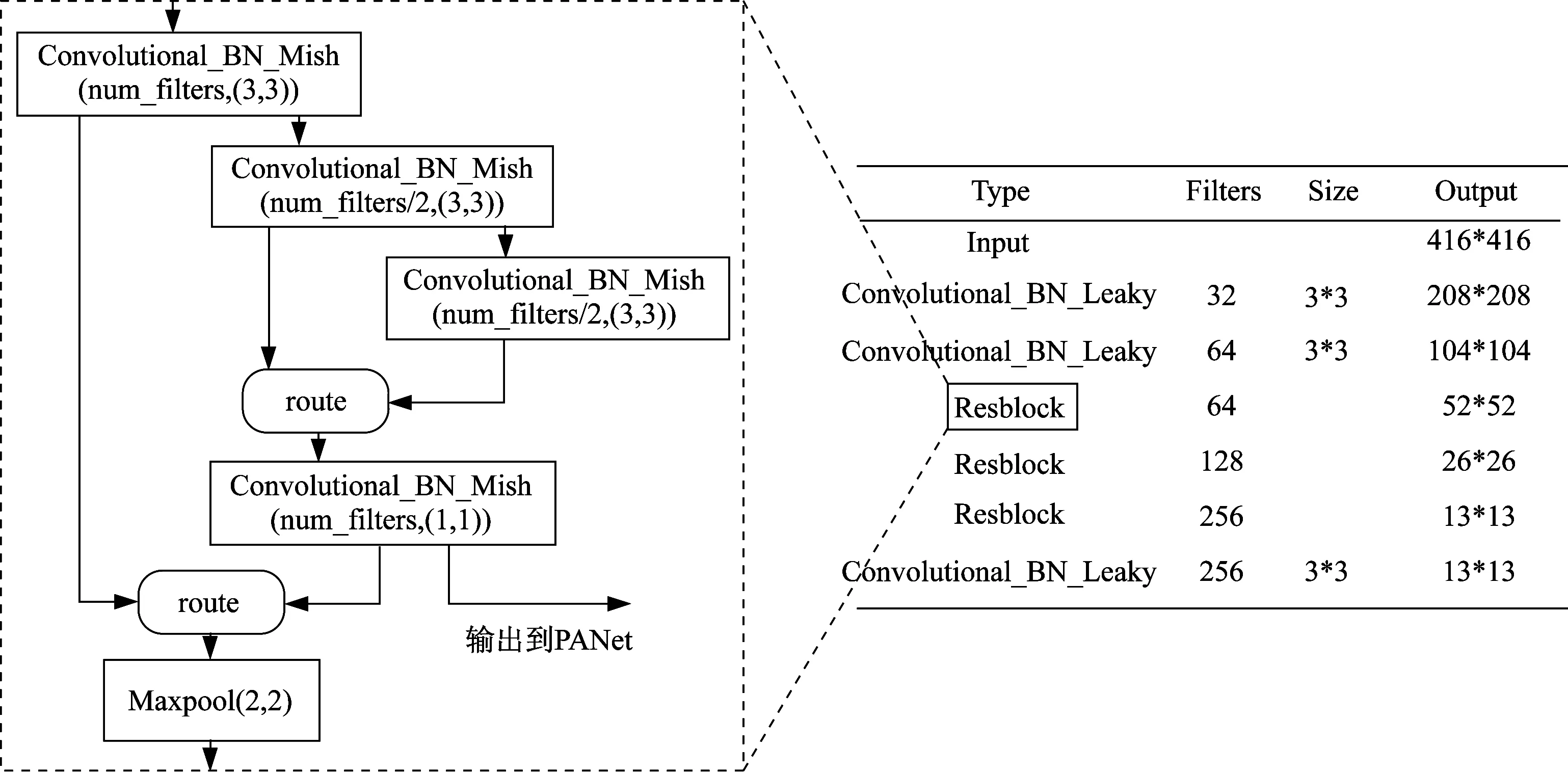
图2 CSPDarknet_tiny 特征提取网络Fig.2 CSPDarknet_tiny feature extraction network
CSPDarknet-tiny 同样也是在YOLOv4 中提出的一种精简版特征提取骨干网络,在保证了使用CSP 等改进措施的基础上,少了一些结构,将原来的Mish 激活函数换成了Leaky 激活函数,且在小幅度牺牲精度的前提下,且网络参数变为原来的十分之一,可以极大地消减特征提取网络中卷积部分的运算量和参数数量,极大地缩小了模型大小和推理时间,从而缩减整个模型使之可以运行在嵌入式设备中,且保证了在电力激光作业安全监控时具有较高的准确率和良好的实时性。
1.2 改进的特征融合网络(Neck)
对于原有的CSPDarknet-53特征提取网络使用了3 个特征层进行分类与回归预测,预测的尺度有3 个尺度,且采用多层卷积融合提取特征,但同样也会增加检测时间和加大性能需求,不能满足移动端的要求,所以本文从以下3 个方面对特征融合网络进行改进。
1)本文采用CSPDarknet-tiny作为主干网络,为了满足小目标的检测精确度的要求,并提高移动端实时性,本文的特征融合网络(neck)仅使用了两个特征层进行分类和回归,同时在特征融合网络中采用Laeky激活函数,能够在对模型的实时性和缩小模型的大小影响不大的前提下提高推理精度。
2)本文在CSPDarknet-tiny 主干网络后添加了SPP 网络,并减小了卷积次数,其产生固定大小的输出,得到同样长度的池化特征,从而显著地改善感受野的大小,加快网络收敛速度,降低了过拟合(overfitting),且速度几乎未降低。
3)本文结合YOLOv4 中的多尺度特征融合方法,针对移动端的特性,将原YOLOv4 的PANet 中的思想运用到CSPDarknet-tiny 之后的特征融合网络,对FPN进行了改进,得到简化版的PANet。由于CSPDarknettiny 属于浅层特征提取骨干网络,且仅使用了两个特征层进行分类和回归,所以在进行PANet特征融合时,并不需要多层卷积,可以将原来的5层卷积融合,改成1 层卷积融合,从而在融合所有层的信息基础上降低计算量,提高实时性。
改进的YOLOv4网络结构见图3。
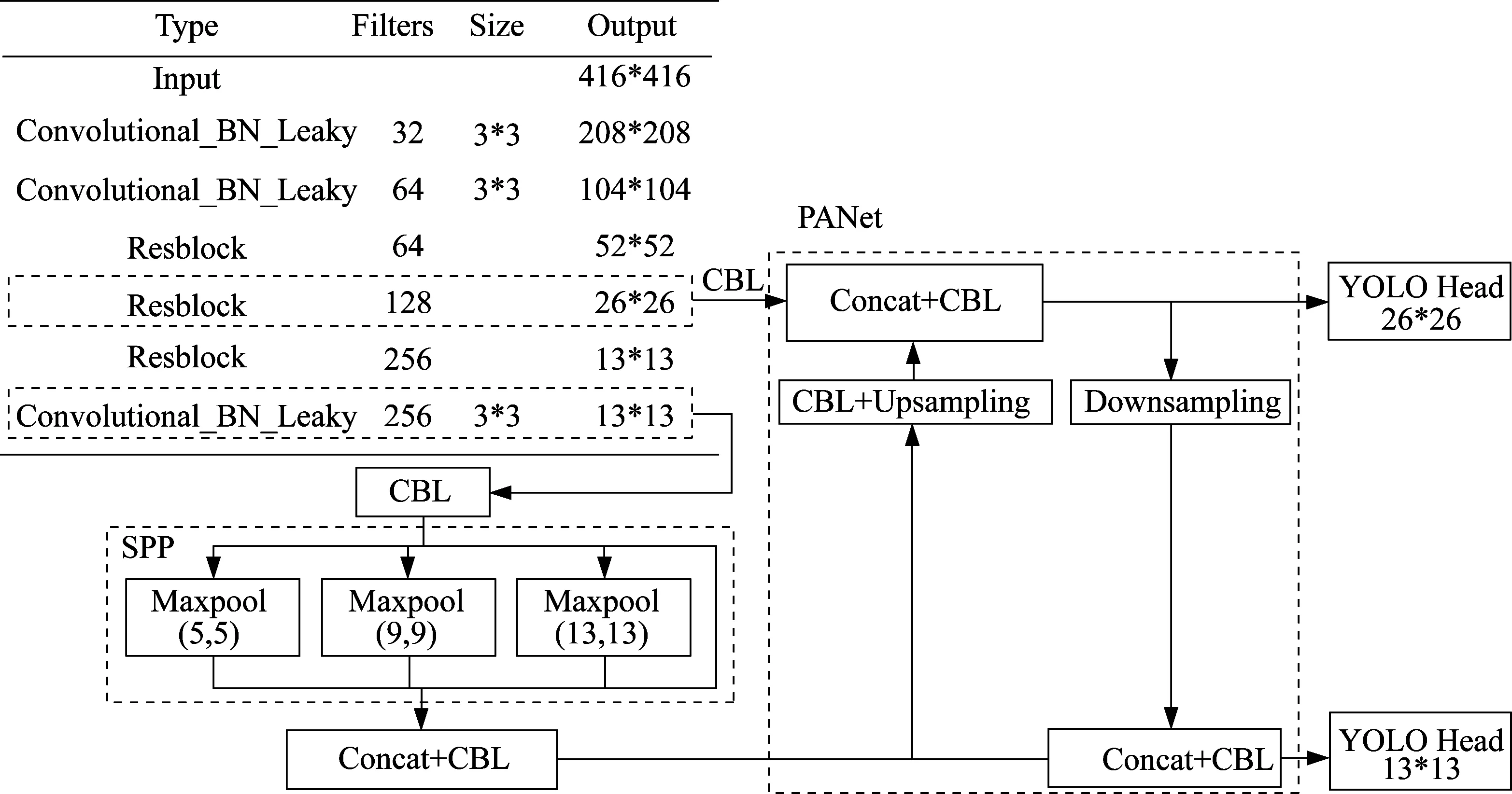
图3 基于CSPDarcknet-tiny的改进YOLOv4网络结构Fig.3 Improved YOLOv4 network structure based on CSPDarcknet-tiny
2 特征分析
激光器照射区域安全隐患可以归结为非法误入照射区域和照射损害其他电气设备两个方面。
在非法误入方面,如图4(a)、图4(b)所示,一些人员或者车辆可能未注意周围高压危险警示标志,突然闯入到激光器的照射区域中,导致激光器照射到人或者车辆上,发生意外。因此,需要快速识别闯入激光照射区域的危险物体[27-31]。
在照射损害其他电气设备方面,如图4(c)所示,可能由于作业人员的失误,导致激光器发射的激光偏移到非清异区域的其他电气设备上,如复合绝缘子,而输电线路除异的激光设备往往功率都很大,发射的激光能量很高,可能导致电气设备的损坏,所以需要标注好目标图像中存在的绝缘子位置,从而提醒作业人员。

图4 电力激光清异区域危险目标示意图Fig.4 Schematic diagram of dangerous targets in power laser cleaning area
对于激光器照射区域检测对象列于表1。

表1 输电线路激光照射区域检测目标和任务Table 1 Detection targets and tasks of laser irradiation area of transmission line
3 数据集和环境的构建
对于非法误入方面,主要的检测对象为人和汽车;对于照射损害其他电气设备方面,应提前检测到可能被激光照射产生危害的电气设备,如复合绝缘子,迅速识别照射区域周围的危险电气设备,一旦照射范围检测到安全隐患,就应当发出警报,打开激光器安全锁,不允许启动。
深度学习模型算法通过大量数据集训练发挥其优越的性能。在图像分类、目标检测与识别等方面,一些机构和公司无偿发布制作的数据集(含训练集和测试集),对比列于表2。

表2 公开实验数据集Table 2 Public experimental data set
对于以上公开的数据集,主要采用PASCAL VOC数据集(下面简称“VOC”)数据集,其包含为20 个类别:人类,交通工具(飞机、自行车、船、公共汽车、汽车、摩托车、火车),动物(鸟、猫、牛、狗、马、羊),其他目标(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。VOC数据集文件中主要包含3 个文件,JPEGImages 文件夹中包含了VOC所提供的所有图片信息。Annotations文件夹中存放的是xml 格式的标签文件,也就是图像中包含目标的位置信息,每一个xml 文件都对应于JPEGImages 文件夹中的一张图片。ImageSets 存放的是每一种类型任务对应的图像数据。
3.1 实拍实验数据集
本文需要建立电力场景下的目标检测数据集,数据集来源于收集到的大量电力场景中拍摄到的图像,且针对相应的检测目标在互联网上收集到了一些电力设备实拍图像数据。这些电气场景图像都是来源于实际的生产作业现场,所以具有很强的应用价值。
对于绝缘子检测的数据集,本文收集到了约600张图像,由于模型的训练需要大量的数据来实现目标定位和分类,所以以上数量图像远远不足以满足需求,为了解决激光清异作业场景的多样性问题和应对样本集和实际检测图像之间的差距,本文提出了采用数据扩充的方法。
首先将现有图像中的绝缘子剪裁下来后,添加不同的复杂场景且没有绝缘子的图像,然后将剪裁下来的绝缘子再随机组合粘贴在没有绝缘子图像的随机位置,通过现有的数据增强方法一共扩充到2 000张含绝缘子的图像。并通过LabelImg工具对未标注的图像数据进行标注,标注为“insulator”,以生成PASCAL VOC格式存储。电力场景实拍绝缘子数据集及图像增强扩充方法示意图见图5-图6。

图5 电力场景实拍绝缘子数据集Fig.5 Insulator data set of power scene

图6 图像增强扩充方法示意图Fig.6 Schematic diagram of image enhancement and expansion method
3.2 数据增强
在实际收集到的电力场景图像中,仅为在有限场景下的图像样本,为了应对多样化的实际监控拍摄情况,本文提出了采用数据增强的方法。数据增强又称为数据扩增,其作用是在不实质性增加样本的情况下,让有限的样本产生等价于更多样本训练的效果,从而提升检测模型泛化能力和鲁棒性。
3.2.1 训练数据增强
1)图像翻转、旋转、裁剪、位移、扭曲、遮挡
通过imgaug 库来对图像进行翻转、旋转、位移、裁剪、遮挡,将图像特征相对位置重新排列,并通过图像扭曲来改变目标图形的形状,这些经过处理后的图片放入神经网络进行训练时,可以有效防止模型训练出现过拟合现象并提高模型的鲁棒性,综合图像处理见图7。
2)图像色彩增强
在训练神经网络模型时,随机调整图像亮度、饱和度、对比度和色相属性,能够减小检测模型受到图像色彩因素的干扰。且图像色彩调整一定程度上模拟天气和光照等环境因素对图像色彩的影响,提高模型的鲁棒性,综合图像处理见图7。

图7 综合图像处理示意图Fig.7 Schematic diagram of integrated image processing
3)Mosaic数据增强
由于训练数据数量较少,训练出来的模型的多样性和鲁棒性无法保证,所以采用了YOLOv4 中的Mosaic 数据增强方法,将四张训练图片合并为一张训练图像。由于每个输入训练模型的训练图像是由4张图像组合而成,每个图像之间互相有遮挡,且增加了背景的多样性,从而提高训练样本的多样性和模型的鲁棒性,也可以在一定程度上减少对大Batch Size 的需求。
3.2.2 检测数据增强
1)图像锐化处理
针对电力激光清异作业监控图像显示模糊、目标太小、重叠分布等问题,本文采用二阶拉普拉斯算子来进行高电压区域监控图像的锐化处理,使图像色彩边界变得更鲜明突出,从而更好地提取目标特征。二元函数f(x,y)的拉普拉斯变换定义为公式(1)。
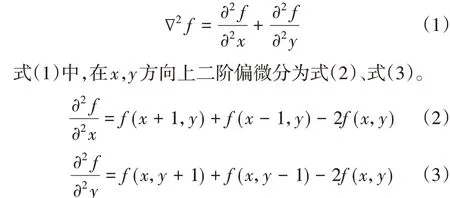
邻域矩阵的模板形式见图8(a)。
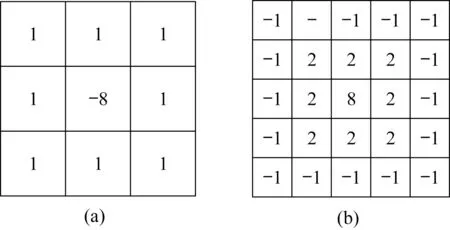
图8 锐化滤波器Fig.8 Sharpening filter
为进一步加强检测目标的特征,本文在拉普拉斯算子邻域矩阵模板的基础上,在中心位置加一,使锐化滤波后的图像与原始图像具有相同的亮度。
扩大后的拉普拉斯算子邻域矩阵模板见图8(b),对卷积操作后的图像各通道值除以8,最后得到锐化前后对比见图9。

图9 监控图像锐化前后对比Fig.9 Comparison of monitoring image before and after sharpening
2)图像色彩校正
电力激光清异作业场景下,监控设备采集的图像色彩因其所处户外环境复杂,光照、反射等受天气影响而容易产生变化。利用图像色彩校正来提高拍摄的稳定性,从而提高识别精度。
本文根据实际需要,采用了一种独特的颜色校正算法,提高图像颜色稳定性。首先根据图像色彩的偏移主要原因是亮度因素,计算出图像平均亮度,即利用均方差公式计算图像中所有R、G、B 通道分量的均方差,如式(4)、式(5)所示。

根据计算得到的图像平均亮度值,利用PIL.Image Enhance 函数对图像整体亮度、对比度和色度值进行调整。当亮度值偏低或偏高时,将亮度、色度和饱和度参数值相应提高或降低。当亮度值在合理范围内时,利用Gamma校正算法对图像做轻微校正,Gamma校正算法是基于人类感知光和颜色的非线性方式,使图像的颜色特征更加符合实际情况,减弱光照对图像颜色信息的干扰。通过本文所提出的颜色校正,对于色彩偏移的图像均有较好的校正作用。图像色彩校正前后对比图见图10。

图10 图像色彩校正前后对比Fig.10 Comparison before and after image color correction
3.3 LSCD数据集的构建和标注
为了保证检测模型的针对性和有效性,改善训练效果,本文建立多标记的“激光清异安全控制图像数据集(Laser Safety Control Dataset,LSCD 数据集)”,具体见表3。数据来源由几个部分组成,一部分数据集来源于公开实验数据集;一部分数据集来源于实验室采集到的图像数据集。

表3 LSCD数据集构建Table 3 LSCD dataset construction
通过采用LabelImg 工具对图像中的目标进行标注,在图像上圈住目标位置,然后标注类别信息,接着按照同样的步骤对图像中的所有目标进行标注,并以生成PASCAL VOC 格式的XML 标签文件保存到指定路径的文件夹中,LabelImg工具标注图像见图11。

图11 LabelImg工具标注图像Fig.11 Labelimg tool annotation image
由于收集到的有效图像数据较少,利用收集到的图像数据集进行数据增强和扩充,从而弥补数据不足的问题。
针对激光照射区域下的检测任务,主要的检测对象包括人员、汽车、绝缘子。由于实拍电力场景实验数据集中存在入侵人员车辆的图像较少,选择VOC数据集来补充人和车这两个类别的数据集图像。且针对可能被激光损害的电气设备,构建绝缘子图像数据集,经过数据增强和扩充后得到足量的数据满足训练模型的要求。
3.4 实验环境的搭建
1)实验的硬件环境为:采用的第七代CPU 处理器,16G 内存,NVIDIA 公司的GTX2080ti 系列GPU 卡,显存为12G。
2)实验的软件环境为:操作系统为Windows10,编程软件为PyCharm,编程环境为Python、opencv、LabelImg、CUDA9.2。运用Tensorflow 和Keras 深度学习框架。
4 目标检测
4.1 实验数据准备
通过准备好的激光清异安全控制图像数据集(LSCD),通过上文提到的数据增强的方法将这些数据进行数据增强和数据扩充,增加数据的多样性,具体训练图像数据见表4。

表4 图像数据集数量Table 4 Number of image data sets
按照9∶1的比例将其划分为训练集和测试集。在进行模型训练之前,需要确定预选框的个数及大小,采用合适的预选框参数可以有效地提高模型准确率和训练速度。本文采用k-means算法对标记好的激光清异安全控制图像数据集(LSCD)相应数据进行聚类分析,由于只有两个预测尺度,所以仅得到了6 组预选边界框参数,并使用这些参数进行下述模型训练,预选框参数表见表5。

表5 预选框参数Table 5 Pre selection box parameters
4.2 模型的训练
参考YOLOv4官方推荐权重参数及具体实验中进行适当调整后,采用模型训练参数如下:
初始学习速率设置为0.001,通过余弦退火衰减(Cosine annealing scheduler)来实现学习率的衰减,标签平滑取值为0.01,置信度阈值取0.5,NMS 阈值取0.5,batch-size 为16。为了防止训练发生过拟合,本文采用了Early Stopping 来防止网络发生过拟合,原理为将数据分为训练集和验证集,验证集的比例为0.1,记录每个epoch的验证集的loss,果然,随着epoch的增加在验证集上发现测试误差上升,则停止训练。
首先进行冻结训练,即“冻结”该层,指的是该层不参加网络训练,即该层的参数不会更新。冻结训练可以加快训练速度,也可以在训练初期防止权值被破坏。将特征提取主干网络冻结,即网络的前60 层,25 个epoch 的冻结训练,同时按照学习率为0.001 来执行学习率的余弦退火衰减对模型进行微调操作,再进行解冻后训练,对所有层解除冻结,使模型参数可以根据训练更新,再进行25个epoch的训练,同时按照学习率为0.000 1来执行学习率的余弦退火衰减。
使用上述训练流程,共训练50 个epoch,loss 和val_loss变化示意图如图12。随着网络训练的进行,网络的损失值随着训练的进行而继续缓慢下降,最终达到收敛状态。在解除冻结后的训练次数中,每个epoch输出一个模型,一共得到25个模型,如图13所示,通过比较这25个模型的平均精度均值(mAP),选出一个最优模型,可以看出在第47个epoch时,mAP达到最大值为73.65%,因此可以选出最优模型。激光照射范围目标检测模型训练的Loss 值和mAP 变化示意图见图12和图13。
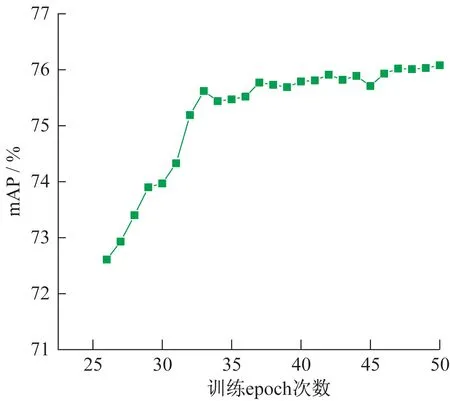
图13 激光照射范围目标检测模型训练的mAP变化示意图Fig.13 mAP change of target detection model training in laser irradiation range
4.3 实验检测结果与性能对比
4.3.1 特征提取过程可视化分析
对训练好的检测模型的卷积层提取特征效果进行可视化分析,得到特征提取网络的每个残差层输出的可视特征图以及经过特征金字塔SPP生成的可视化特征图,具体见图14。
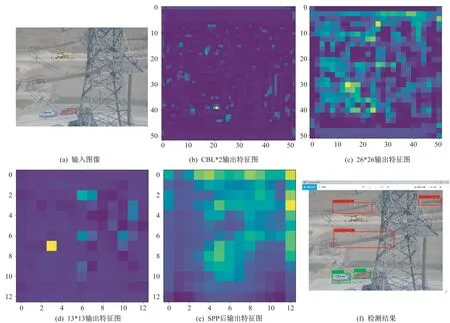
图14 特征提取网络以及特征金字塔生成的特征图层Fig.14 Feature layer generated by feature extraction network and feature pyramid
如图14所示,在前两个卷积层提取特征后所得到的特征图显示最为清晰,非常顺利地提取了图像特征,CSPDarcknet-tiny 网络从第3 个ResBlock 开始出现提取特征流失,开始对小目标特征提取不够精确,且一定量地丢失了图像信息。图14(e)表示经过特征金字塔SPP 融合了多范围的特征,可以看到加入特征金字塔后,融合提取将低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息,越到高层区分前景能力越强,SPP 在一定程度上挽回丢失的信息。
4.3.2 模型测试结果
为了验证模型的效果、准确情况、稳定性以及样本对其的影响,从测试集中每次随机抽取200 张图片进行测试,得到检测模型的AP图见图15。
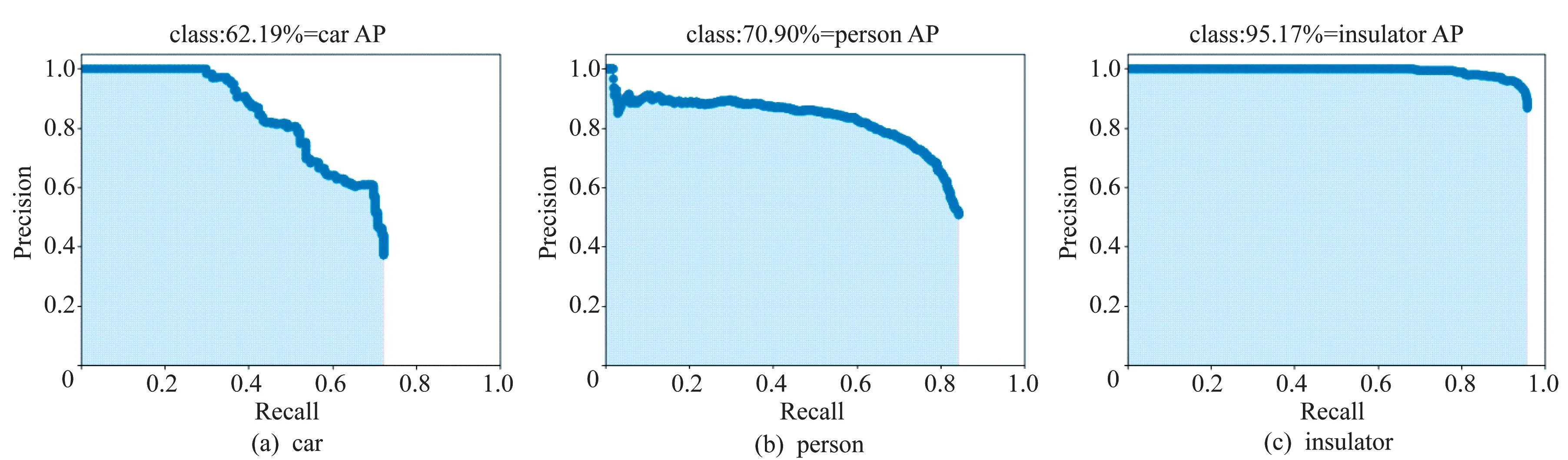
图15 特征提取网络以及特征金字塔生成的特征图Fig.15 Feature map generated by feature extraction network and feature pyramid
当NMS 阈值取值为0.5 时,测试结果见表6,可以看出,在检测输电线路激光清异照射区域中可能存在的危险物体上,该模型表现较好,准确率达到并稳定在73.65%左右,且该模型平均识别一张图片所用的时间为217 ms,且模型大小仅为29.5 MB,能顺利移植到移动设备中。
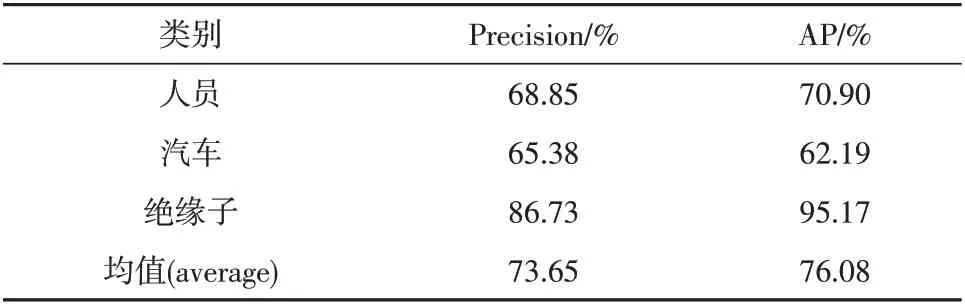
表6 模型测试结果Table 6 Model test results
4.3.3 性能对比
为测评该模型在移动端上的性能,关闭GPU,仅在CPU 上运行,本文对比了目前比较流行的目标检测模型:Faster R-CNN 和SSD,且将改进前的原YOLOv4 也作为比较组。运用相同的策略和数据集训练模型,并从测试集中随机抽取200张图片进行测试,mAP、每识别一张图片所用的平均时间和模型大小作为检测效果的评价指标,结果见表7。
由实验结果表7 可得在准确率方面,本文提出的适用于移动端的激光清异照射范围目标检测方法的mAP达到了76.08%,相比于SSD算法在准确率上有明显提升。虽然改进算法准确率低于原YOLOv4算法和Faster R-CNN算法,但是检测速度大大提升,且模型大小很小,更适用于嵌入式设备。前两者的算法无论是在检测速度还是模型大小上,都无法使用与嵌入设备。因此,改进的YOLO 模型可以顺利地应用到激光清异照射区域目标检测任务上,且可以较好地完成照射区域危险物体的检测任务,同时能够顺利地嵌入移动端,对启动警报器策略起到重要支撑作用。
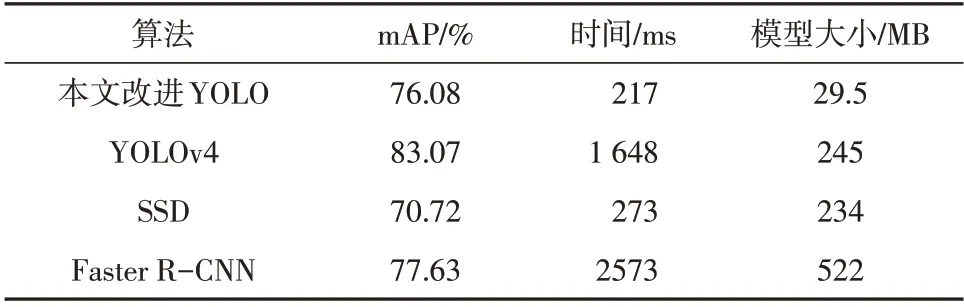
表7 同步算法性能对比Table 7 Performance comparison of synchronization algorithms
5 结语
1)对YOLO 算法进行改进,选择了CSPDarcknettiny 作为特征提取主干网络,并将SPP、PANet 等改进措施针对移动端的特性进行改进,使检测模型更适用于移动端检测环境。
2)在激光照射区域目标检测场景下,通过LSCD数据集训练,改进的YOLO算法检测准确度为73.65%,满足检测精度要求。
3)较Faster R-CNN 等算法相比,改进的YOLO 算法具有更快的检测速度,每张图片识别平均所需时间为217 ms,在保证精度的前提下,极大地缩小了模型大小,仅为29.5 MB,更适用于移动端安全监控系统。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
昆明医科大学学报(2021年6期)2021-07-31
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
科学(2020年5期)2020-11-26
作文小学中年级(2020年6期)2020-07-24
当代陕西(2019年10期)2019-06-03
儿童故事画报·发现号趣味百科(2016年3期)2016-06-24
意林(2011年10期)2011-05-14
