
基于GRU-MMD的电力数据挖掘方法
2021-11-12 00:27李毅靖吴元林
工业加热 2021年10期
黄 荷,陈 杰,李毅靖,郑 钟,吴元林
(1.国网福建省电力有限公司,福建 福州 350001;2.国网信通亿力科技有限责任公司,福建 福州 350001)
在电力数据挖掘中,对电力系统的安全评估和电网的规划及预测是最重要的研究方向[1]。精准的负荷预测,可以为电力企业制定合理的发电计划,降低电力损耗,提高电网的安全,对于电力用户来说,精准的负荷预测,能够使用户错峰填谷,提高电能利用率,降低用电费用[2-3]。
随着智能电网和大数据技术的飞速发展,近年来,电力数据挖掘方法引起了人们的广泛关注。文献[4]提出电力数据使智慧城市的重要成分,并分别从用电行为,负荷需求流向,区域成熟度等方面分析了数据挖掘对智慧城市的巨大作用。文献[5]针对电力数据挖掘对电网规划建设,安全评估,负荷预测,故障诊断等方向的作用,并对数据挖掘在智慧城市的发展上的推动作用进行了分析。文献[6]为了提高电力数据挖掘的准确性,采用蚁群聚类优化方法对粗糙数据特征进行分类,剔除干扰信息,从而获得准确的电力数据检测结果。文献[7]提出了一种基于低秩的电力数据异常检测方法,并应用拉格朗日方法优化目标方程,能够有效检测出智能电网种的异常信息和有害信息。文献[8]针对海洋电力数据挖掘问题,提出了一种基于节点动态性能值得处理方法,相比于传统的MapReduce算法,具有更快的处理速度和更高的稳定性。
针对电网大数据挖掘的方法越来越多,但是如何在具有不同特征的数据中挖掘出更高的知识,还未见有相关研究。本文针对数据特征不同的电力数据集,采用GRU-MMD方法建立准确的数据分析模型,获得期望输出结果。
1 基于GRU的电力负荷挖掘
1.1 GRU数学模型
GRU (Gated Recurrent Unit,简称 GRU)是在长短期循环神经网络的基础上发展起来的一种神经网络[9]。GRU的学习过程如图1所示。

图1 GRU单元结构
如图1所示,GRU的实现过程如式(1)~式(7)所示。
(1)
(2)
(3)
(4)
(5)
(6)
(7)

1.2 基于GRU的短期负荷预测
在采用GRU对电力用户进行短期负荷预测的时候,预测流程如图2所示[10]。

图2 基于GRU的短期负荷预测流程
将电力用户每天的用电情况作为一个样本P,每隔15 min采集一次电力负荷,每天96个数据。P的维度为96。P1是待负荷预测日7天前某天的用电情况。Dp,Wp,Tp指的是负荷预测当天的日期,气象和温度情况。Pp指的是负荷预测值。
2 基于GRU-MMD的电力数据挖掘模型
2.1 迁移学习
对于传统的机器学习来说,样本的训练数据和测试数据由同一个特征空间产生,当样本数据不是处于同一个特征空间的时候,就需要耗费大量资源去采集合适的样本数据。迁移学习为深度学习的深入发展提供了新思路,通过将先验知识转换到其他相关的任务上,以提高相关任务的处理效率和准确性[11-12]。迁移学习包括领域(Domain)和任务(Task)。
领域是学习的主体。领域包括特征空间χ和边缘分布概率P(X),且X=(x1,x2,…,xn)∈χ。若领域不同,则特征空间或边缘概率分布也不同。设领域D={χ,P(X)},任务T={y,P(Y|X)}。y 指的是标签空间,P{Y|X}为条件概率,通常情况下P{Y|X}没有具体形式。目标函数的预测函数通过样本数据对{xi,yi}得到。
迁移学习包括源领域Ds(Source domain)及目标领域DT(Target domain)[13]。源领域包含的信息对模型预测具有重要价值,是迁移的对象[14]。目标域指的是待解决问题。任务同样包含源领域任务TS和目标领域任务TT。 迁移学习就是通过推理学习源领域的规则,得到目标领域的输出结果,解决目标问题。表示过程为:源领域DS和TS,当DS≠DT,TS≠TT,推理得到目标域DS≠DT的预测输出f(·)。
图3为迁移学习的基本示例。当迁移学习应用在图像识别的时候,源领域包含了大量的图像,目标领域只含有少量数据,则通过训练源领域的数据,获取知识后,推理出目标域的预测输出[15]。在电力数据挖掘当中,将待挖掘的电力区域作为目标领域,将历史数据或ita电网作为源领域。

图3 迁移学习示例
2.2 最大均值差异算法
MMD(maximum mean discrepancy, 简称MMD)最初是用于判断两个样本的分布是否一样。在将MMD与迁移学习相结合的时候,MMD将源领域与目标领域通过推理联系在了一起。MMD在样本空间确定函数f,获取两类样本数据的平均值,计算两类数据的均值差异。当确定的f能够使均值差异最大化的时候,则将差异值作为这两类数据的MMD。MMD越小,则认为两类数据的分布相似度越高,相反,MMD越大,则表示两类数据分布的相似度越小。综上所述,MMD是用来衡量两类数据分布的相似程度。MMD的实现过程如下所述。
设F为样本空间连续函数,存在式(1):

设X,Y分别为p和q中采集的样本数据。X和Y的数据量分别为m,n。则MMD的经验估计表示为式(2):
(2)
从式(2)可以看出,只有当p,q分布相同时,MMD才等于0。当处理的数据量较大的时候,对F进行限定才能加快收敛。当F为再生核希尔伯特空间的单位球时,能够实现MMD快速收敛。可再生核希尔伯特空间的特征,采用点积来描述f→f(x)的映射,可以表示为式(3)。
f(x)=〈f,φ(x)〉H
(3)
用up和uq替换Ep[φ(x)]和Eq[φ(x)],可得式(4)。
‖up-uq‖H
(4)
对式(4)两边求平方,可得式(5)。
MMD2[F,p,q]=Ep〈φ(x),φ(x′)〉H+Ep〈φ(y),φ(y′)〉H-2Ep,q〈φ(x),φ(y)〉H
(5)
采用径向基核函数代替内积。
(6)
则MMD的求解公式可以转换为式(7)。

(7)
从式(7)中可以看出,MMD通过距离来判断样本相似程度。
2.3 基于GRU-MMD的电力数据挖掘
在采用深度学习对电网进行数据挖掘的时候,引入MMD方法后的实现过程如图4所示。
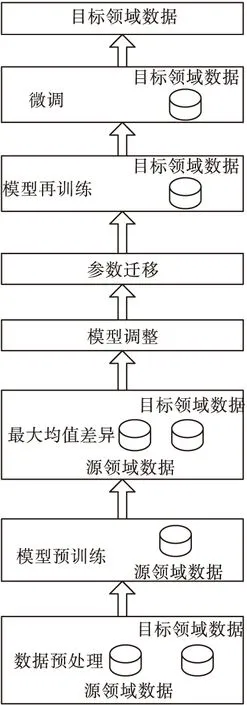
图4 基于深度学习和迁移学习的电力数据流程图
在对源领域和目标领域的数据进行数据预处理之后,取源领域的数据训练神经网络的结构。采用MMD方法求解源领域和目标领域之间的差异值,并根据差异情况调整网络的结构,获取新的结构。当MMD值小于设定阈值a时,表示源领域和目标领域分布类似,则网络的结构不用调整。当MMD的值处于设定阈值[a,b]之间的时候,则对网络的结构进行重新调整,以提高模型的知识学习能力。若MMD的值超过b,表示源领域与目标领域的差异较大,不适合迁移学习。
2.4 负荷预测迁移学习模型
基于GRU的短期负荷预测迁移学习模型如图5所示。如果源领域与目标领域的MMD小于a的时候,采用左侧网络结构获得输出。若源领域与目标领域的MMD处于[a,b]之间,则采用图5右侧的经过迁移学习后的网络结构求取输出。采用此种结构对线路跳闸故障进行预测,降低了学习率,提高了预测精度。

图5 短期负荷预测的迁移学习模型
3 实验仿真
3.1 仿真设置
为了验证本文所提的数据挖掘学习模型的准确性,进行了算例仿真。仿真用数据来自广东省东莞市电力局,采集时间为2016—2018年。仿真用计算机为联想,CPU cori i5 9400,内存8G。仿真的GRU参数设置如表1所示。

表1 GRU网络参数
本文将采用目标领域数据训练得到的模型作为模型1。采用源领域数据训练的模型,然后采用目标领域数据进行微调的模型作为模型2。采用源领域数据训练得到的模型,再根据目标领域数据对网络的所有参数进行调整的模型作为模型3。源领域和目标领域的样本分别为36 000和9 000。选用MAPE作为评价网络模型准确度的标准。
案例A:当目标域和源领域数据健全的情况下,建立三种预测模型的MAPE与MMD的预测关系曲线如图6所示。

图6 案例A的MMD与MAPE的关系曲线
案例B:当目标域数据不全的时候,建立三种预测模型的MAPE与MMD的预测关系曲线如图7所示。
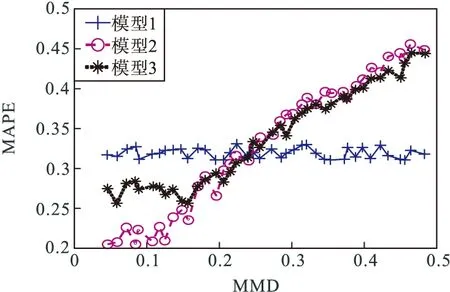
图7 案例B的MMD与MAPE的关系曲线
由于线路共有36条线路,选取前33个作为源数据,剩余的作为目标数据。含迁移学习以及不含迁移学习的MAPE结果如图8所示。与其他现有的负荷预测方法对比结果如表2所示,其中BP1,LSTM1,GRU为未引入迁移学习的算法,BP2,LSTM2及本文所提方法为引入迁移学习的算法。

图8 负荷预测MAPE结果对比

表2 各种算法MAPE对比结果 %
3.2 结果分析
从图6可以看出,源领域和目标领域的MMD影响着迁移学习的结果。当MMD很小的时候,模型1高于模型2的预测精度。当MMD较大的时候,模型2的预测精度高于模型1,此时模型2能够有效迁移模型1的知识,通过引入新的层提高网络的学习能力。
从图7可以看出,MMD较小的时候,模型1具有更好的预测能力。随着MMD的增大,会出现负迁移情况。当MMD较小的时候,在网络中引入新层会导致过拟合。当MMD≤0.24,采用模型1进行预测。当 MMD≥0.24,存在负迁移情况,需要更换源领域数据重新建立模型。
从图8可以看出,经过迁移学习之后,提升了负荷预测的准确定,降低了训练耗时。相比于其他现有的负荷预测方法,本文所提的方法具有最高的预测精度,说明本文所提的方法更适用于电力数据挖掘。
4 总 结
为了提高电力数据利用率和数据挖掘的效率,本文提出了GRU-MMD的电力数据挖掘方法。对采集的电力数据进行数据预处理,然后采用MMD方法分析源领域和目标领域的数据的差异,根据差异值决定是否调整GRU网络模型。经过仿真实验分析,验证了本文所提的方法能够提高数据挖掘的精度,有益于电力大数据的准确建模。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
电力与能源(2017年6期)2017-05-14
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
信息通信技术(2015年6期)2015-12-26
核科学与工程(2015年2期)2015-09-26
中共南宁市委党校学报(2015年4期)2015-02-28
电测与仪表(2014年14期)2014-04-04
