
基于已实现极差的上证综指波动长记忆性识别与风险度量研究
2021-11-11 11:35:00周文浩张红梅
西南大学学报(自然科学版) 2021年11期
周文浩,王 沁,张红梅,汪 玲
西南交通大学 数学学院统计系,成都 611756
在全球经济一体化的推进下,中国金融市场的波动日益加剧,金融风险也随之不断增加,因此,对金融市场风险进行度量与控制是非常有必要的.VaR作为金融风险度量的关键指标,将不同资产的组合风险综合成一个数值进行度量,在国际金融市场得到了广泛认可与应用.
资产收益波动的估计是度量VaR的关键,为此国内外学者通常选用GARCH簇模型来对资产波动进行度量,进而实现对VaR更有效地控制与预测.文献[1]结合EVT与GARCH模型对市场的VaR进行预测,实现了极端风险的精确度量; 文献[2]基于GARCH模型,针对基金收益率序列,计算各种基金收益率序列的VaR,发现各基金具有相似的风险偏好; 文献[3]利用对冲基金日交易数据,建立了GARCH模型,预测对冲基金的波动率并计算其VaR,减少对冲基金激进的投资策略对市场的冲击; 文献[4]用ARFIMA-ARCH模型来对中国股票市场长记忆性进行分析并对VaR进行测算与检验; 文献[5]基于ARFIMA-GARCH-F模型对重庆市空气质量指数(AQI)的VaR进行了度量与检验; 文献[6]基于不同分布下的FIGARCH计算了期货的VaR,结果表明FIGARCH相较于GARCH模型更精确; 文献[7]结合有偏t分布与FIGARCH对股票市场的VaR进行测算与检验,证明了FIGARCH在实践中风险控制的优越性; 文献[8]应用ARFIMA-FIGARCH模型对同业拆借利率进行度量并结合VaR对模型优劣进行检验,结果表明ARFIMA-FIGARCH能更好地刻画同业拆借利率的波动特征.尽管双长记忆的ARFIMA-FIGARCH模型能有效地刻画资产收益的双长记忆性和异方差性,但考虑杠杆效应的存在以及高阶矩对收益的影响,需要对ARFIMA-FIGARCH模型进行修正与拓展,从而有效地度量股票市场的VaR以及预测和检验.
考虑到高频数据日内“U”型特点,文献[9]结合高频信息首次提出“已实现”波动率(realized volatility,RV),作为波动率的全新非参数度量方法; 文献[10]建立ARFIMA-RV模型并实证表明RV的引入能很好地刻画资产的波动特征并大幅度提升模型的拟合与预测能力; 文献[11]基于已实现波动率建立了ARFIMAX-FIGARCH模型,对农产品期货市场波动率进行预测,结果表明引入RV能使ARFIMA-FIGARCH模型预测精度更高.但真实市场往往可能存在跳跃点,这导致RV的稳健性与有效性可能难以成立.因此文献[12]结合高频极差信息提出了已实现极差(realized range variance,RRV),并证明RRV的有效性约为RV的5倍,实现了对RV与市场真实波动率拟合的优化.文献[13]在理论上证明了已实现极差波动率是比已实现波动率更有效的波动估计量; 文献[14]基于已实现极差建立了LHAR-RRV-CJ模型,分析了中国股市的异质性、 跳跃性以及杠杆效应; 文献[15]基于已实现极差建立了CARR-EVT模型,实现对日VaR和CVaR的动态估计.
一方面,由于对数化已实现极差具有双长记忆性和异方差性; 另一方面,考虑到杠杆效应的存在以及高阶矩对收益的影响.借鉴前述研究,本文基于对数化已实现极差,建立偏t分布下的ARFIMA-M-FIGARCH簇模型,分析资产收益的双长记忆性以及异方差性,分析杠杆效应下的极端风险,以实现对上证综指VaR的度量与控制.
1 基于已实现极差的ARFIMA-M-FIGARCH簇模型
1.1 已实现极差
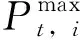
(1)
则RRVt定义为极差下的日内高频收益率的平方和:
(2)
1.2 双长记忆模型
文献[16]考虑到长记忆性,提出了FIGARCH(BBM)模型,并在FIGARCH(BBM)模型上对结构进行修正,结合ARFIMA提出了ARFIMA-FIGARCH(CHUNG)模型,其结构如下:
(3)

(4)
考虑到杠杆效应,文献[16]引入杠杆项θ1,θ2来对杠杆效应进行刻画,进而构建了FIEGARCH模型,其条件方差方程可以表示为:
(5)
事实上收益序列的高阶矩未必存在,这使得FIEGARCH的基本假设难以成立.文献[17]引入lnα创建了HYGARCH模型,考虑了高阶矩对波动和长记忆性的影响,其对应的条件方差可以表示为:
(6)
基于对数化已实现极差,考虑到双长记忆性、 异方差性、 杠杆效应以及高阶矩对收益的影响,本文构建了ARFIMA-M-HYGARCH模型:
(7)

2 VaR的计算与检验
VaR定义为在一定置信水平下,资产组合在一段时间内可能受到的最大损失.由此可以得出VaR的定义式:
P(ΔP≤VaR)=α
(8)
针对对数化已实现极差的尖峰后尾特征,选取偏t分布下ARFIMA-M-HYGARCH模型来建模,可以得到ARFIMA-M-FIGARCH簇的VaR为:
(9)
其中:ut为lnRRV率的均值;skstα是标准偏t分布为skst(0,1,ξ,v),且下置信水平为α的单侧分位数,ξ为偏度参数,v为自由度.
基于已实现极差的ARFIMA-M-HYGARCH模型计算与检验VaR的具体思路如下:
步骤一: 计算RRV,结合R/S,单位根检验以及自相关图识别其长记忆性,利用QQ图判断其分布是否符合偏t分布.
步骤二: 基于分数阶差分后序列计算残差序列,对残差序列进行异方差检验以及长记忆检验.
步骤三: 对基于已实现极差下的ARFIMA-M-FIGARCH簇模型进行参数估计以及拟合优度检验.
步骤五: 利用失败率检验法和动态分位数检验法对VaR进行检验.失败率检验法并未对分位数起到评估的作用且受样本量的影响较大,而动态分位数检验法弥补了这一缺陷.
3 实证分析
3.1 数据收集
中国股票市场主要分为沪市和深市,因此上证综指与深成指数自然最能反映中国股市的整体波动情况,但由于沪市与深市存在较高的相关性,而沪市开市较早,对外部冲击较为敏感,同时对深市而言具有“溢出效应”,所以本文选择上证综指作为研究对象.借鉴文献[18]的结论,在避免市场微观结构带来严重噪声的基础上,选择尽可能高频率的数据,因此本文选择上证综指5分钟高频数据,取样区间为2016年1月4日-2018年12月28日,共有35 088个数据,数据来源于Wind资讯金融数据库.
3.2 统计特征与分布检验
对上证综指的RRV进行基本统计特征分析与检验,相关结果如下表所示:

表1 上证综指RRV的描述性统计与检验
从表中可以得知,上证综指RRV与lnRRV序列偏度大于0,呈现出右偏的趋势; 同时峰度大于0,表现为尖峰特征.总体而言,呈现出有偏、 尖峰厚尾的特征,结合Jarque-Bera结果可知,整体并不服从正态分布.尝试利用QQ图对lnRRV整体是否服从有偏t分布进行判断,结果见图1.

图1 上证综指ln RRV基于有偏t分布的QQ图
从有偏t分布下的QQ图可以得知,lnRRV的对应点基本构成一条直线,因此本文选取有偏t分布作为假设分布.
3.3 双长记忆性与异方差性检验
对上证综指lnRRV序列进行单位根检验,结果如下表所示:

表2 上证综指ln RRV单位根检验
从表2可以看出,ADF检验结果表明序列平稳,而KPSS检验显示序列并不平稳,根据文献[19]对ADF结合KPSS检验的研究,可以得知上证综指lnRRV序列平稳,同时具有一定的长记忆性.
对lnRRV序列自相关性进行分析,结果如图2所示.从图2中可以看出序列的自相关函数以非常缓慢的速度衰减,根据文献[19]对长记忆性与自相关系数的研究,可以认为序列具有较强的长记忆性.
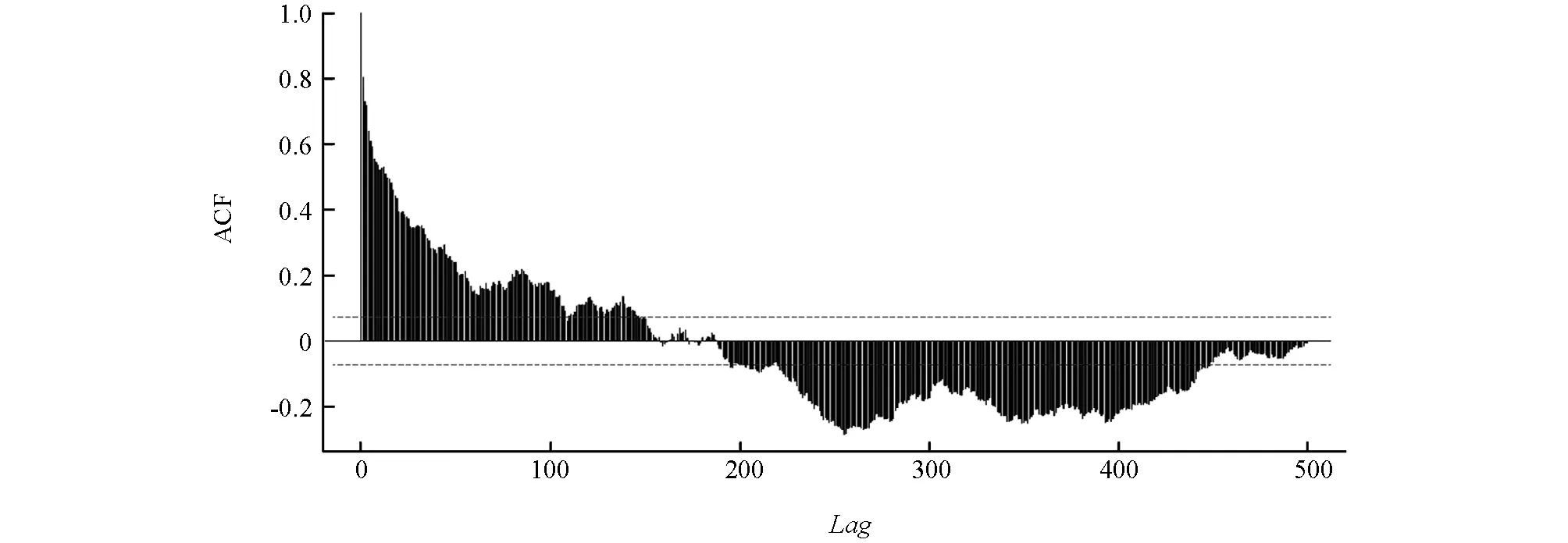
图2 上证综指ln RRV序列自相关图
对上证综指lnRRV进行R/S检验得到Hurst指数,进而判断序列长记忆性的强弱,检验结果如图3,4所示.

图3 上证综指ln RRV的R/S检验图

图4 拟合残差的R/S检验图
R/S检验结果表明Hurst指数H=0.928 2,R-Squared=0.976 5,同时结合图3,可知拟合效果良好,并且Hurst指数远大于0.5且接近于1,因此可以判断上证综指的lnRRV序列具有很强的长记忆性,这与前面的分析结果完全一致.
由于Hurst指数与d近似存在d=H-0.5的关系,则d≈0.428 2.对ARFIMA-M-RRV模型进行拟合,并对拟合残差进行异方差性检验与长记忆性检验,来判断是否适用于FIGARCH族模型,检验结果见表3.

表3 异方差性检验(ARCH检验)
结合表3可以得知,在滞后阶数分别为1,3,4阶,显著性水平为10%时均拒绝原假设,即认为lnRRV的波动率并非常数,存在较强异方差性.
针对拟合残差的R/S检验结果表明Hurst指数H=0.732,R-Squared=0.650,同时结合图4可以得知拟合效果较好,并且Hurst指数大于0.5,因此可以判断波动率同样具有长记忆性.
结合上述分析可知上证综指的lnRRV具有异方差性和双长记忆性的特征,因此结合FIGARCH族对ARFIMA-M-RRV建立双长记忆模型.
3.4 模型的建立与参数估计
对lnRRV序列进行0.428 2阶差分,并对分数阶差分后的lnRRV序列测算其自相关以及偏相关系数,对自回归与移动平均项进行定阶,测算结果如下表所示:

表4 分数阶差分后ln RRV序列的ACF与PACF
对于自相关系数,存在
(9)
对于偏相关系数,存在
(10)
根据Box-Jeins定阶理论,可以确定模型的自回归阶数为1,移动平均阶数为0,即模型为ARFIMA-M-RRV(1,0)模型.同时,确定ARCH与GARCH阶数均为1阶.
分别针对FIGARCH(CHUNG),FIEGARCH以及HYGARCH建立基于ARFIMA-M-RRV的双长记忆模型,并利用基于BHHH算法的极大似然估计对参数进行估计,参数估计结果见表5.

表5 偏t分布下各模型估计结果
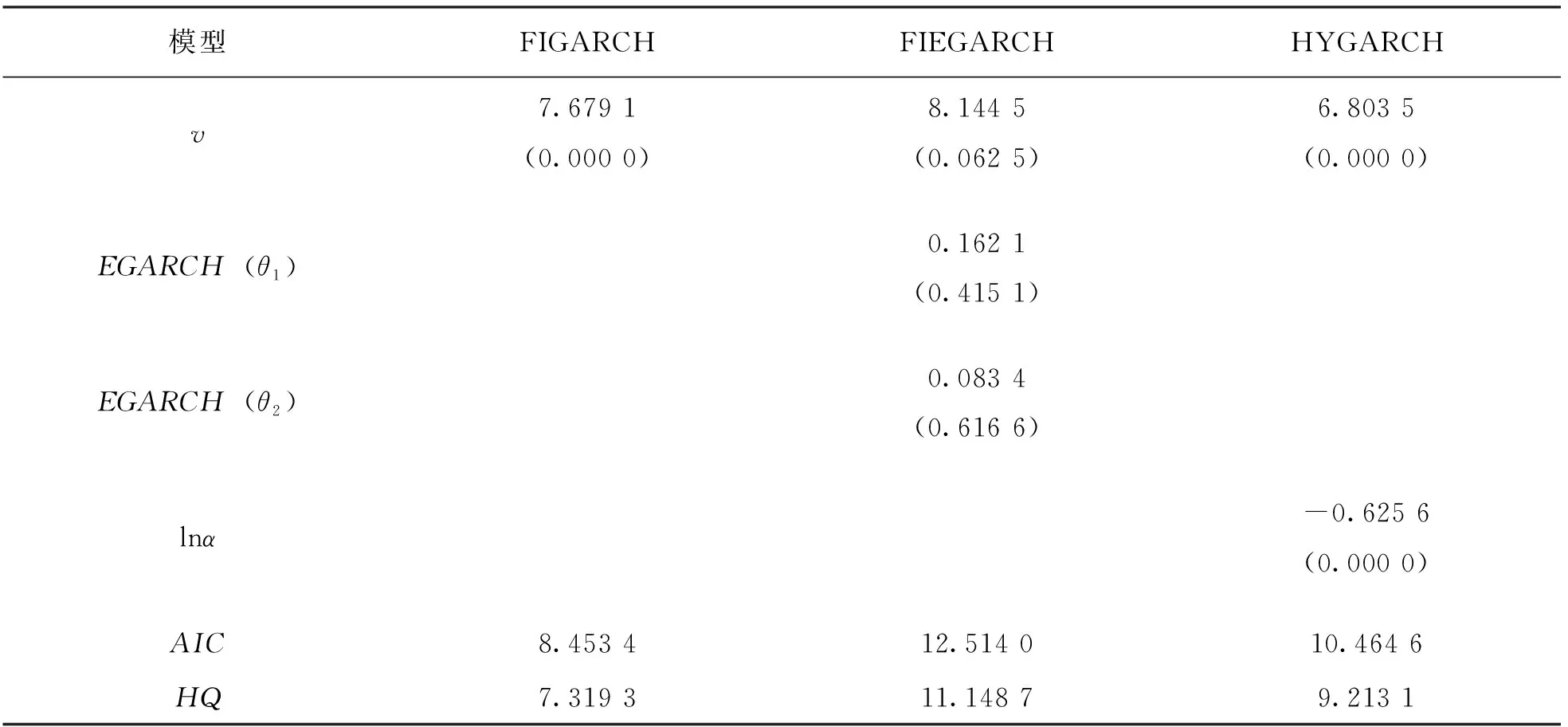
续表5
结合表5中的模型参数估计结果,可以发现:
1) FIEGARCH中的杠杆项参数均不显著,这恰巧说明了均值方程引入的杠杆项比较完美地刻画了lnRRV的杠杆效应,进而导致方差方程杠杆项并不显著.同时d1以及AR(1)的估计结果同样不显著,d1>0.5,表明FIEGARCH的参数估计效果较差.
2) HYGARCH与FIGARCH关于d1的估计值均接近于0.5,体现了lnRRV很强的长记忆性,同时d2>0且不太接近0.5,体现了波动率较强的长记忆性,这与前文研究结果完全一致.
3) FIEGARCH的AIC与HQ值均大于其他2种模型,而HYGARCH与FIGARCH的AIC与HQ值相对较小,另外FIGARCH的ARCH项并不显著,因此FIGARCH与HYGARCH能更好地对波动率的异方差性进行描述,但HYGARCH略优于FIGARCH.
3.4 VaR计算与检验


表6 失败率检验结果

表7 动态分位数检验结果

图5 HYGARCH模型VaR(0.950; 0.975)图
结合VaR的计算与检验结果可以发现:
1) 失败率检验中,HYGARCH在0.950 0,0.975 0以及0.997 5分位数下的成功率相对于FIGARCH而言更接近对应的分位数,p值同样更优于FIGARCH,尤其在0.997 5分位数下FIGARCH对应的p值仅为0.053 0,检验结果非常不理想,反观HYGARCH在0.997 5分位数下p值为0.431 2,能更好地对极端风险进行控制.
2) 动态分位数检验中,FIGARCH在0.950 0,0.975 0以及0.997 5分位数下的p值均小于HYGARCH,尤其是在0.950 0分位数下的p值仅有0.047 4,效果非常不理想,远低于HYGARCH对应的0.439 8,这表明在动态分位数检验下HYGARCH同样能更好地对极端风险进行控制.
综上所述,HYGARCH对于ARFIMA-RRV模型VaR的估计效果更好,能够更好地适应和控制股票市场的极端风险.
4 结 论
本文在高频信息的基础上,引入RRV,结合杠杆效应,对双长记忆性进行识别并建立相应的模型,对模型的VaR进行计算与检验,得到了以下结论:
1) 上证综指lnRRV序列具有尖峰厚尾的特征,结合Jarque-Bera检验以及QQ图,可以得知整体服从有偏t分布.
2) 结合单位根检验,自相关图检验,异方差检验以及R/S检验可知上证综指lnRRV序列具有双长记忆性的特征.
3) 对FIGARCH,FIEGARCH以及HYGARCH下的ARFIMA-M-RRV模型进行拟合,结果表明FIGARCH与HYGARCH拟合结果较好,其中HYGARCH略优于FIGARCH.
4) 对FIGARCH与HYGARCH下的ARFIMA-M-RRV模型进行VaR的失败率检验与动态分位数检验,结果表明HYGARCH能更好地刻画上证综指lnRRV序列在极端风险下的VaR.
由实证结果可知,针对上证综指可以建立有偏t分布下的ARFIMA-M-RRV-HYGARCH模型来对极端风险下的VaR进行度量与控制,从而实现更有效的金融风险管理.
猜你喜欢
微创医学(2020年6期)2020-03-09 02:53:12
中学数学研究(江西)(2019年5期)2019-06-11 12:47:28
中国畜禽种业(2018年5期)2018-01-18 12:24:58
中国免疫学杂志(2017年1期)2017-01-17 04:53:25
股市动态分析(2016年11期)2016-10-11 14:10:16
股市动态分析(2016年10期)2016-09-30 14:12:12
股市动态分析(2016年25期)2016-07-23 07:31:08
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
股市动态分析(2015年35期)2015-09-10 07:22:44
电源技术(2015年1期)2015-08-22 11:16:08
