
基于异构信息网络元路径作张量分解的深度学习推荐系统
2021-11-10 07:19许荣海王昌栋
信息安全学报 2021年5期
许荣海, 王昌栋
中山大学 计算机学院, 广州 中国510000
1 引言
1.1 选题背景及意义
互联网爆炸式增长的今天, 在电商邻域[1], 淘宝、京东等电商平台拥有数以亿计的商品数目, 每日上千万的用户级流量。在社交网络领域, 新浪微博坐拥千万级日活量, 知乎作为新兴的知识型社区总回答数也过亿。这些新型的平台极大地改变了传统的信息传递方式[2], 使得信息能够即时共享, 用户与他人与世界能够更加高效地交互、作用、影响。
然而, 面对海量的信息, 一方面用户逐渐提高了对信息准确性和有效性的要求, 一方面却日益难以获取到自己真正需要的信息。在信息爆炸的时代,如何从庞大的数据中获取不同用户所需的有效信息成了一个重要的问题。而个性化推荐算法可以有效地缓解此类问题[3]。推荐算法本质在做的是挖掘不同用户的不同喜好, 基于用户的偏好来推荐信息。这个信息可以是某一商品信息, 也可以是某一条微博包含的文本信息, 也可以是好友推荐的用户信息。推荐算法过滤掉大部分无效信息, 留下少量用户可能感兴趣的内容, 在这一意义上, 推荐算法在应用层面改变了信息的传递方式。
然而, 基于过去的方法, 我们仍然面临着许多挑战[4]。如常见的由数据稀疏带来的冷启动问题[5]。商品的信息是庞大的, 但新用户却缺乏历史购物数据, 使得推荐的误差极大。为了应对这一问题, 许多方法加入了辅助信息进行缓解。新用户虽然缺乏购物信息, 通过考虑用户年龄段、性别、职业、兴趣、好友等辅助信息能较好地应对冷启动问题。对这类辅助信息, 异构信息网络[6]相比同构网络能够存储更加丰富的语义特征。
此外, 深度学习在推荐系统取得了不错的成果[7]。基于神经网络的深度学习模型一般是深层非线性结构的。能够自动地学习不同的多维的异构数据,深度地挖掘其中的特征。从而缓解了数据稀疏的问题。基于此, 本文将结合异构信息网络和深度学习的方法, 提出新的推荐模型, 以此缓解数据稀疏问题。
1.2 国内外研究现状和相关工作
协同过滤算法[8], 有分为基于用户[9]的协同过滤和基于物品[10]的协同过滤方法。其主要思想是基于邻域考虑用户对商品偏好的关联性。基于物品的方法(item-based)考虑相似度高的物品做推荐, 基于用户的方法(user-based)考虑相似度高的用户的物品做推荐。这一类方法由于只考虑了领域间的信息传递,导致泛化能力较差。
另一种基于矩阵分解(matrix factorization, MF)[11]的方法很好地解决了这一问题, 矩阵分解方法将用户和物品映射到同一维度的向量空间中。但矩阵分解只考虑了二维的用户评分信息, 在用户评分较少时, 无法很好地应对数据稀疏的问题。
近年来, 深度神经网络在各个领域都有了很成功的应用[12]。在推荐系统领域中, He 等[13]提出了NCF 模型, 用MLP 代替了MF 中的点积操作, 同时融合了改进的矩阵分解方法, 增强了泛化能力。Deng等提出的DeepCF[14],将协同过滤算法分为表征学习过程和融合学习过程, 结合MLP 提出的CFnet, 提高了推荐的准确率。
在辅助信息方面, 异构信息网络(heterogeneous information network , HIN)[15]是包含多种类型的节点和边的图。基于此产生了许多基于异构信息网络的推荐模型。这类模型的一个基本思想是基于元路径(meta-path)产生路径实例。通过路径本身包含的语义信息, 可以计算出用户, 物品间相似性, 以此作推荐。Sun 等[15], 提出新的基于路径的相似度计算方式(path-sim), 做top-k 推荐。Yu 等[16], 通过不同元路径,建立用户和物品的不同关联性矩阵, 在结合传统的矩阵分解做推荐。Shi 等[17], 通过不同路径提取出用户序列和物品序列, 通过序列训练生成用户和物品的表征, 在通过融合方程做预测。以上方法多致力于结合异构信息网络的辅助信息到推荐中。但依然存在挑战, 路径的语义如何与推荐关联, 在提高准确性的同时导致的可解释性丢失的问题, 以及如何利用异构信息网络充分地挖掘用户的偏好特征等等问题。
在矩阵分解的基础上, 为了考虑更高维度的特征, 在推荐系统中也有结合张量分解的模型[18]。例如加入标签信息[19], 文本信息等等。但这类方法都是直接加入显性的辅助信息, 进行张量分解, 相比传统矩阵分解的提升有限。本文考虑结合异构信息网络具有丰富语义的优势, 通过元路径做信息的提取。相比常见的基于标签的张量分解方法更好地利用了辅助信息。
1.3 主要贡献
1) 提出基于张量分解方法(Tensor Decomposition)和异构信息网络(heterogeneous information network)的深度学习推荐算法。主要分为三个阶段: 首先根据数据集建立对应的异构信息网络, 并提取出元路径信息; 随后通过张量分解算法将用户、物品、元路径映射到同维度的隐语义向量空间中; 最终结合深度协同过滤算法, 将前一步得到的隐语义向量作为输入, 增强了模型的精确度。
2) 将张量分解得到的隐语义向量作为深度神经网络的输入层的初始化, 参考DeepCF[14]的双塔模式,一部分做表征学习、一部分做匹配学习, 通过多层感知机(MLP)增强泛化能力。考虑到不同用户对不同元路径的关联性偏好不同, 融入注意力机制(attention mechanism), 学习不同用户、物品, 与不同元路径的偏好权重。
3) 使用movielens, douban movie 和Amazon 数据集进行训练和测试, 与其他推荐算法做多组不同指标的对比试验, 本文提出的hin-dcf 模型有了张量分解的嵌入向量初始化后, 模型的精确度和收敛速度皆有效提升, 并且在数据稀疏情况下更好地应对了数据稀疏的问题。
2 预备知识
2.1 异构信息网络

例一: 图1 列举了异构信息网络(Hin)的例子。该Hin 为电影场景下的网络图, 包含五类节点类型,分别是用户user(u)、电影movie(m)、导演director(d)、小组group(g)、电影类型type(t)。每个节点表示某一结点类型的实例, 如图中u1特指某一用户、t1特指某一电影类型(如恐怖电影类型)。Hin 中的边的意义是直观的, 如边类型u-g, 表示用户加入了该小组; 边类型u-m, 表示用户看过该电影并给出评分。
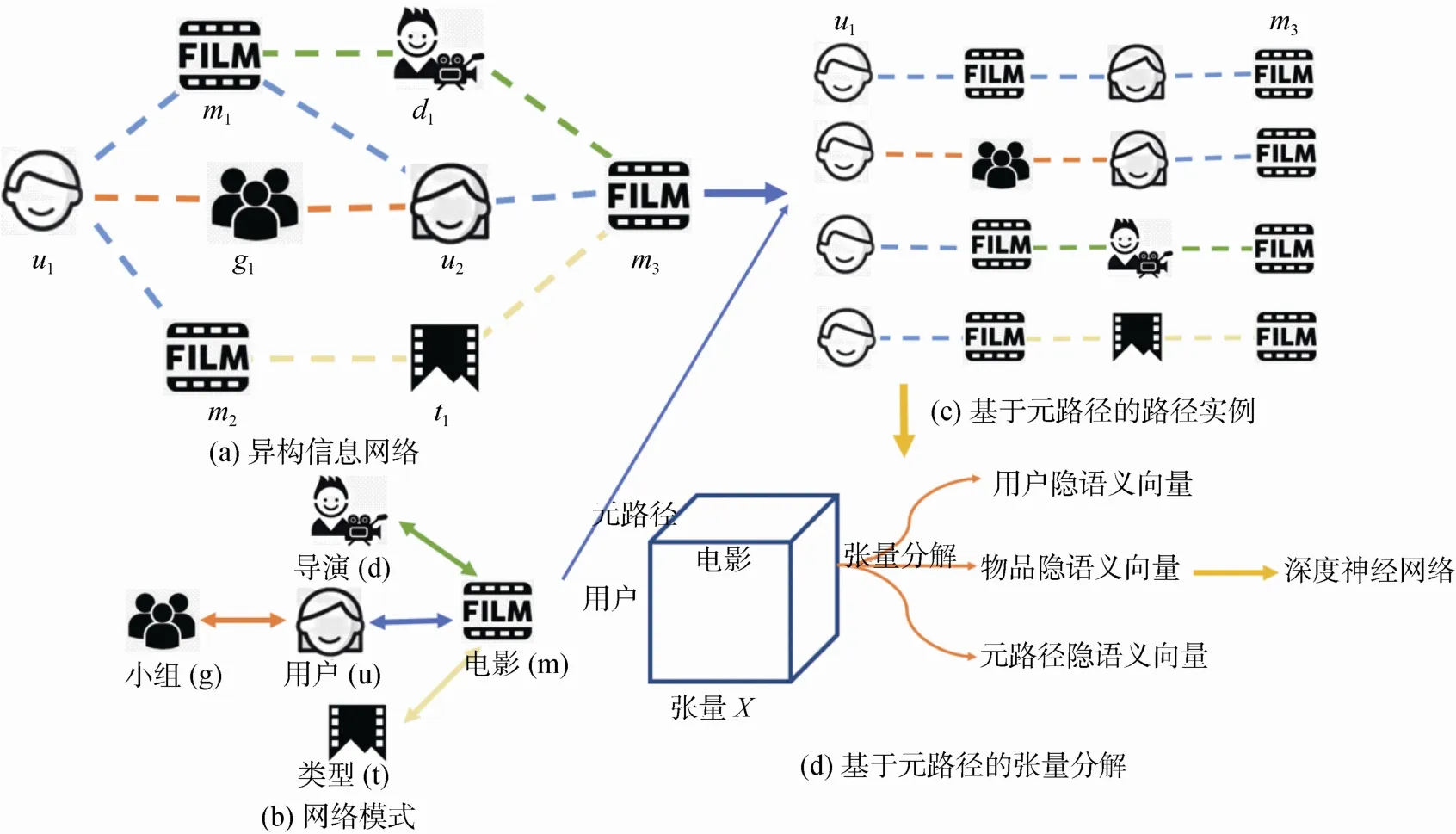
图1 HIN 异构信息网络的实例以及基于元路径建立张量的思路Figure 1 Example of heterogeneous information network and the idea of building a tensor based on meta-paths

例二: 图1为(a)的网络模式, 网络模式可以简单理解为包含所有节点类型和边类型的最小图结构。相反, 根据网络模式我们也可以生成一个新的异构信息网络。

例三: 基于图1(b)的网络模式, 我们能生成很多不同的元路径(meta-path)。对于推荐问题, 将元路径的长度限制在4, 且头节点为用户类型, 尾节点为电影类型。如UMUM, UMDM, UMTM, UGUM。这些元路径包含了各自特定的语义, 例如UMUM表示联系建立在看过共同电影的用户上。基于这些语义能够在推荐的可解释上发挥一定的作用。以图1(c)为例子,基于元路径(meta-path)在用户u1和电影m3间能建立多条路径关系。例如图中的u1-m1-u2-m3属于UMUM, 还有u1-g1-u2-m3、u1-m2-d1-m3、u1-m2-t1-m3, 分别属于不同的元路径。

例四:在图1(a)中, 用户u1和电影m1以及电影m2之间有U-M的边类型, 即这两部电影被评分了。而用户u1未曾给过电影m3评分。推荐系统的目标为,判断用户u1和电影m3建立连边的可能性。
2.2 CP 张量分解
张量分解的一种主流方法是CP 分解[20](Canonical Polyadic Decomposition)。CP 分解已在信号处理、图像处理、降噪等方面有了广泛的应用。本文考虑采用三维的CP张量分解提取前文提到的基于元路径的张量矩阵中的用户隐藏的辅助信息和物品的隐藏的辅助信息。CP 分解的分解形似如下:

X ∊RN×M×P,ai∊RN×1×1,bi∊R1×M×1,ci∊R1×1×P
即对X分解得到长度为r的隐语义向量(latent factors),其中ai、bi、ci分别表示CP 分解得到的对应维度的向量。
2.3 基于张量分解提取隐语义
建立张量X ∊RN×M×P, 其中 Xi,j,k表示用户ui与物品mj之间在建立的异构信息网络中元路径 pk的数量。用户的数量为N, 物品的数量为M, 元路径的数量为P。
经过R阶CP 分解后, 对每个用户i, 物品j和元路径k 都得到一个长度为r 的隐语义向量, 分别为ui,mj,pk。如图1(d)所示。且有:

其中ui,r表示向量ui的第r个位置的数值。mj,r与pk,r同理。
2.4 张量分解损失函数
R阶张量分解的损失函数为实际张量的值与近似张量值得平方误差。为了防止过拟合现象, 加入正则化项。损失函数如下:
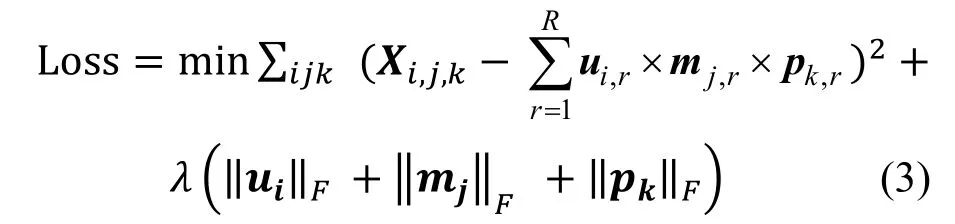
其中, λ表示正则化项的系数, ‖…‖F表示F范数。
本文将会把这三种基于线性关系的隐语义向量作为深度学习网络的输入, 以此捕获更多的信息。

表1 主要的符号及其意义Table 1 The main symbols and their meanings
3 提出的模型
在这一部分, 我们将提出基于异构信息网络中元路径作张量分解的深度神经网络推荐算法hin-dcf。主要分为两部分: 首先基于hin 元路径信息做张量分解, 生成用户、物品、元路径的隐语义向量作为embedding。其次, 将该embedding 作为输入, 结合当前的流行的深度神经网络推荐模型, 采用双塔结构,兼顾表征学习和匹配学习[19]。同时, 结合MLP 与基于元路径的注意力机制, 提高了模型的预测准确率。
3.1 基于元路径建立张量
3.1.1 基于元路径建立用户-物品的关联性矩阵
上文中已经提到元路径以及路径的定义和相关例子, 接下来, 将基于此建立能够表达用户和物品间关联度的矩阵Y。参考图1, 对特定的元路径, 如UMUM, 寻找用户u1到物品m3间所有的属于该元路径的路径。例如u1-m1-u2-m3, 显然这样的路径,表达了用户u1和物品m3的一种正向关联性, 因为购买相同物品的人更可能有相同的偏好, 并且这种关联是显示语义的, 具有直接的可解释性。直观地, 这样的路径数目越多, 物品m3就具有更高的可能性满足用户u1的喜好, 同时该物品也更可能与用户u1购买过的历史物品具有更高的相似性。此外, 路径反应用户和物品的关系程度也与元路径本身直接相关。因此, 对于元路径pk, 可以建立用户与物品的关联性矩阵Ypk。
特别地, 对于长度为1 的元路径, 如UG, 当ui-gj∊E时Y=1, 否则为0。其中Y表示矩阵Ypk第i行、第j列的取值。
3.1.2 关联性矩阵的递归生成
如上文, 对长度为1 的元路径, 生产关联矩阵的方法是简单的。参考图2, 对于长度大于1 的情况,可以基于更短的元路径的关联性矩阵递归的生成。例如对元路径UGUM, 可以通过如下矩阵乘法递归生成:
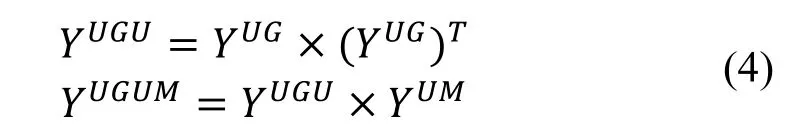

图2 基于元路径建立关联性矩阵及张量Figure 2 Establishing correlation matrix and tensor based on meta-path
3.1.3 建立张量
参考图2, 本文只考虑用户和物品间的关系, 因此只选取的头节点为用户尾节点为物品的元路径,即U…M。选取P条元路径, 分别为p1,p2,…,pP。基于此可以建立P个不同的关联性矩阵, 考虑到不同元路径生成的关联性矩阵数值范围差别很大, 可能导致接下来的张量分解中有效信息的损失, 因此在建立张量前, 对每个关联性矩阵进行标准化处理。参考图2,最后将这P个关联性矩阵进行合并得到张量X:

3.2 嵌入层(embedding)的初始化
将张量分解得到用户、物品和元路径的隐语义向量作为hin-dcf 模型的embedding 层。基于CP 分解后, 这些表征向量在同一向量空间中, 并且是线性关系的, 可以直接通过点积反映其关联程度。同时,更为重要的是, 由于张量是基于元路径建立的, 分解得到的表征向量本质上反映的是用户和物品间的路径的关系, 并不能直接用于推荐问题里的评分预测。另一方面它又包含了许多hin 的重要信息以及用户的评分偏好信息。基于此, 本文直接将其作为hin-dcf 模型的embedding 的初始化, 通过后续的表征学习过程和匹配学习过程, 使其更加适应于推荐问题。
3.3 基于元路径的注意力机制(attention mechanism)
不同用户有不同的喜好模式, 例如某一用户可能会更关注相同兴趣小组成员看过的电影, 而其他用户可能更偏向于看同一导演的系列作品, 或者偏爱于喜剧类型电影。而这样的喜好模式恰好是元路径所表达的, 基于不同的用户有不同的喜好模式的假设, 本文提出新的基于元路径的注意力机制, 以此挖掘出不同的偏好模式信息。
用户、物品、元路径张量X经过CP 分解后分别得到用户、物品、元路径的隐语义向量ui,mj,pk。参考图3 的注意力机制部分, 考虑不同的用户、物品对,存在更倾向于某一喜好模式(元路径)的情况。本文通过不同的(用户, 物品, 元路径)三元组, 学习不同元路径的权重。采用两层的网络结构做注意力机制:

图3 基于异构信息网络元路径注意力机制的深度学习推荐系统 hin-dcfFigure 3 Deep learning recommendation system based on meta-path attention mechanism of heterogeneous information network hin-dcf

最终,将得到的注意力权重系数通过softmax 函数进行归一化。得到的权重可以理解为, 不同元路径与同一用户、物品对的关联程度。表示合并向量。
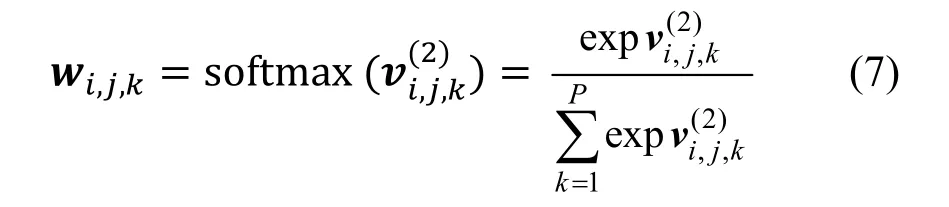
其中, wi,j,k表示元路径k对于用户i、物品j的权重系数。
通过注意力权重系数, 可以聚合得到总的元路径embedding 向量p。通过简单地加权求和得到:
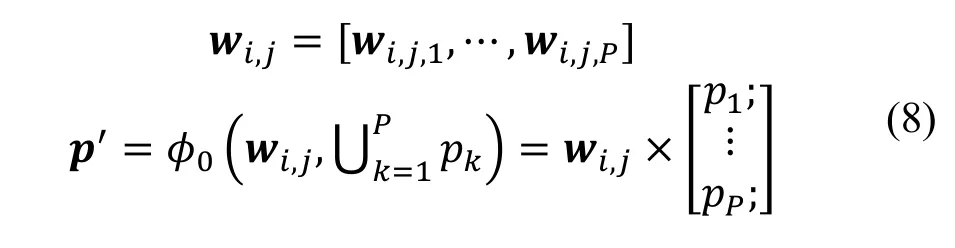
3.4 基于表征学习方法
参考图3, 本文提出了结合元路径的表征学习过程(presentation learning)。对用户和物品, 采用one-hot 向量输入进预先初始化的embedding 层, 得到对应的表征向量。对于元路径, 通过基于元路径的注意力机制, 我们学得元路径的融合向量。在本文,我们采用多层感知机[21](MLP)作为表征学习函数,学习用户、物品、元路径的非线性信息。因此, 表征学习过程的定义如下:
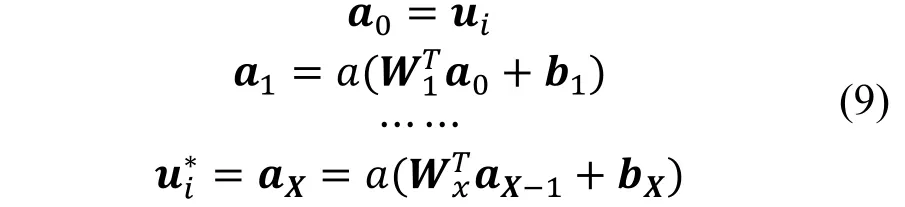

用同样的表征学习方法, 可以得到mj和pk的表征向量mj*, pk*:


3.5 基于匹配学习方法
参考图2, 本文提出了结合元路径的匹配学习过程(interaction learning)。基于匹配学习的方法更侧重学习用户、物品、元路径的匹配融合过程。本文先合并用户i、物品j的张量分解得到的嵌入表征向量,以及基于注意力机制得到的元路径的融合向量。通过多层感知机(MLP)学习三者间的匹配过程。具体过程如下:

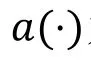
3.6 结合表征学习与匹配学习
表征学习更好地学习用户的表征向量, 而匹配学习更深刻地挖掘了用户、物品、元路径三元组间的融合方式, 将结合这两种方法, 使得模型同时拥有这两个学习过程的优势。

其中Wout为权重矩阵,为表征学习方法中用户、物品、元路径三者间元素积得到的向量,为匹配学习方法中倒数第二层得到的向量, 即aY。通过全连接层和激活函数最终学习用户i对物品j的预测评分。
3.7 目标函数
在点对点(point-wise)的推荐模型中, 以及显示反馈信息的情况下, 假设评分服从正态分布, 可以采用经典的均方误差(MSE)作为损失函数:

在隐式反馈的情况下, 由于没有显示的评分信息, 只有隐式的反馈, 例如是否有点击等。这样的反馈服从0-1 的二项分布。更适合采用交叉熵作为损失函数:

4 实验部分
4.1 实验设置
4.1.1 实验数据集
本文采用了几个常用的测试数据集①https://github.com/librahu/HIN-Datasets-for-Recommendation-and-Network-Embedding。其中Movielens 为电影数据集, 包含了用户对电影的评分、用户年龄、职业等相关信息。还有关于豆瓣的数据集, 豆瓣是国内最大的评分网站之一, 因此具有较高的实际意义,相比Movielens数据集, 该数据集包含了更有意义的群组信息, 加入相同小组的用户具有相同的兴趣。亚马逊(Amazon)数据集, 包含商品的品牌、类型等信息。关于实验数据集具体的细节可以看表2 。
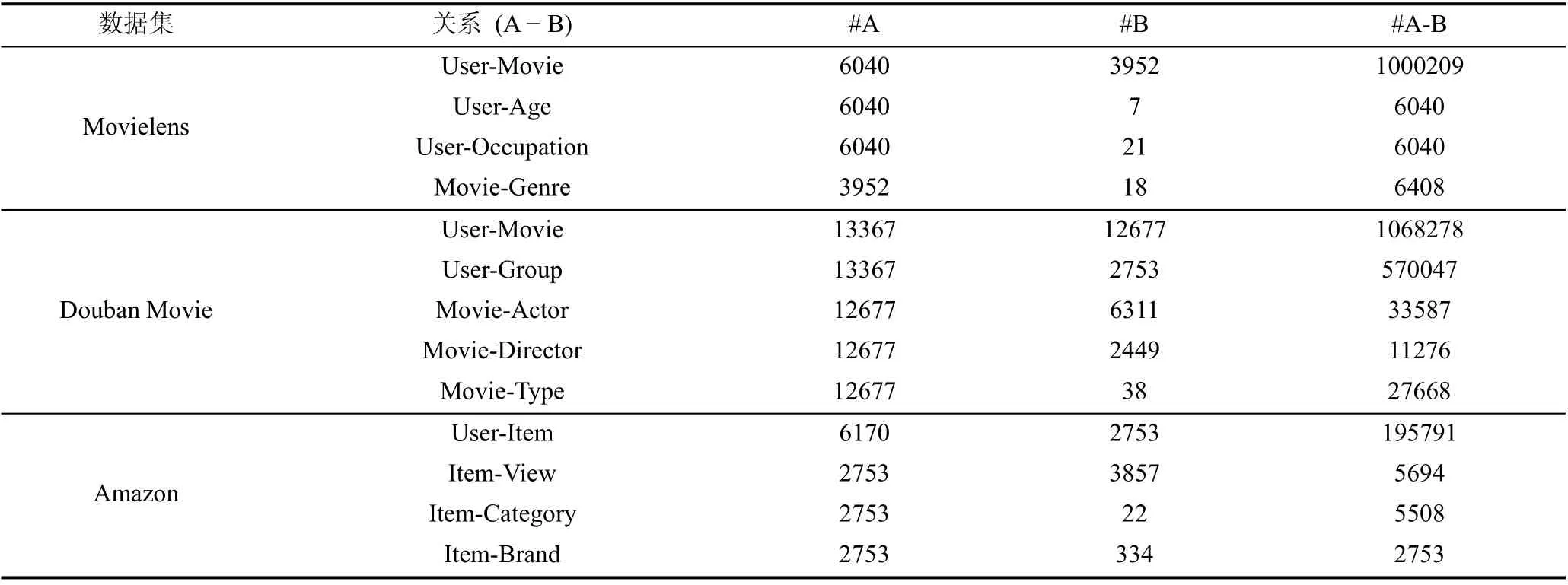
表2 实验数据集Table 2 Datasets
“#A”和“#B”一列表示分别表示A 类型和B类型节点的数量。“#A-B”表示AB 间交互的数量。例如, 对于每个数据集的第一行, 分别表示了用户数量、物品数量和用户物品间交互数量。由表3, 展示了在不同数据集中选取的元路径。考虑到计算的复杂度, 本文只选取了长度为三的元路径。因为元路径越长, 所表达的用户和物品间的关联性越弱, 也就包含了更多的无用的噪音语义信息。为了避免这一问题, 采用限制元路径的长度的方法。

表3 元路径Table 3 Meta-path
以Movielens 数据集为例, A表示不同年龄段,UAUM表示反映了相同年龄段电影喜好的元路径。O表示职业类型, UOUM表示反映了相同职业类型电影喜好的元路径。
4.1.2 评估方法
在本文的实验部分中, 由于数据集为有评分数据, 所以属于显式反馈记录。本文采用常见的均方根误差(RMSE)和平均绝对误差(MAE)来评价模型误差。其数值越小, 表示模型越精确, 预测效果越好。具体公式如下:
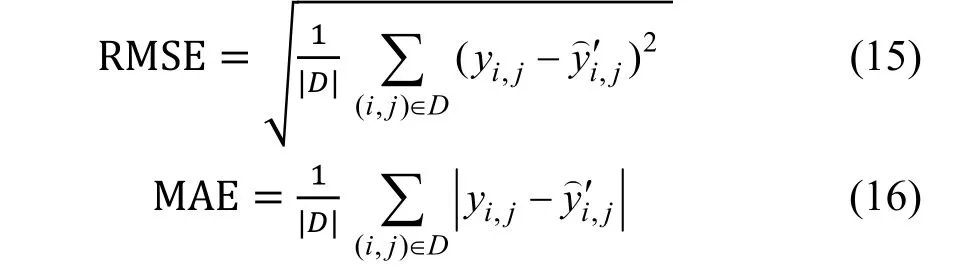
其中, D表示测试集数据。
4.1.3 对比方法
NeuCF:ncf[13]是第一个将神经网络应用到协同过滤上的方法。模型分为广义的矩阵分解方法和基于MLP 的模块。
DCF:dcf[14]是在2019 年, 提出的基于协同过滤分为表征学习过程和匹配学习过程的方法。也是本文所学习的思路。
DMF:dmf[22]将传统的矩阵分解方法融合神经网络, 大大提升了模型的泛化能力。
Hin-dcf:hin-dcf 是本文提出的模型。
4.1.4 实现细节
CP 张量分解部分采用python 的tensorly 库[23]来实现。hin-dcf 模型基于python 的torch[24]深度学习库实现的。具体地, 模型参数的初始化采用正态分布,优化部分采用Adam[25](Adaptive Moment Estimation)方法。而训练的batch 大小设置为256。学习率设置为0.001。
为了保证训练的公平性, 生成元路径的数据只考虑了训练集, 元路径的数量和类型见表3。其中大写字母对应表2 中关系一列的首字母。
4.1.5 实验结果
实验的对比结果参考表4。主要的结论如下:

表4 实验结果Table 4 Experimental result
在三个数据集中, 实验结果大部分都是hin-dcf最佳, 除了movielens 80%略差于dmf 模型。这一结果证明了在加入异构信息网络中元路径的hin-dcf 模型在推荐问题上准确度有了提升。
本次实验将对比了不同训练比例(training rate即训练集占总评分数据集的比例)下, 模型的准确率。显然的, 在降低训练集的同时, 模型的准确率会下降。参考图5,在movielens 和Amazon 这两个数据集上, 随着训练比例的下降, hin-dcf 的准确率下降是最平缓的, 说明在数据集越稀疏的情况下(较低的训练比例下), 模型发挥的作用是相对稳定且有效的。

图5 不同训练比例下MAE 的变化Figure 5 MAE in different training ratios
关于可解释的实例分析: 为了直观地演示hin-dcf 基于元路径注意力机制的可解释方法。参考图4, 本文随机从douban-movies 测试集中选取用户电影做分析,训练比例为80%。图4 中的条形统计图展现了用户10572 与电影437 和电影4913 分别的注意力权重。对电影437, 注意力权重最高的是UMUM元路径。表明这次推荐主要是基于看过相同电影的用户来作推荐。对电影4913, 注意力权重最高的是UGUM,表示这次推荐主要基于共同兴趣小组作推荐。我们可以看出, hin-dcf 模型可以对推荐的结果基于元路径做一定的可解释。

图4 基于元路径注意力机制做可解释的例子Figure 4 An interpretable example based on the meta-path attention mechanism
参考图6, 在不改变模型结构的条件下, 有无隐语义向量作为初始化的模型在预测误差(MAE)上的表现差异是明显的。原模型hin-dcf 随着训练比例地增大, 准确率同时稳定地增大。而采用随机初始化表征向量的对比模型, 准确率下降很大, 并且在四个不同训练比例下的表现也波动较大。其中在训练比例为40%时, 随机模型的MAE 为1.273 相比比hin-dcf 的MAE 为0.554 高了129.8%。在没有张量分解得到的隐语义向量作为初始化的模型表现是糟糕的, 说明了嵌入层的初始化过程在hin-dcf 中的有效性。

图6 有无隐语义向量初始化模型的MAE 误差的对比图Figure 6 MAE comparison of models with or without latent factor initialization in different training ratios
为了验证结合表征学习方法和匹配学习方法能够提升模型性能, 参考图7, 本文将hin-dcf 与单独的表征学习模型和匹配学习模型在不同数据集上的表现进行对比。hin-dcf 在所有数据集中都表现最佳。其中在movielens 数据集中, 匹配学习模型的MAE比hin-dcf 比提升了2.3%。
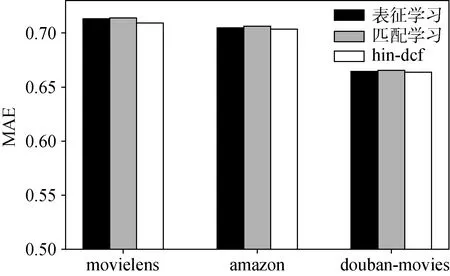
图7 表征学习模型和匹配学习模型和hin-dcf 在不同数据集上的MAE 对比图Figure 7 MAE comparison of representation learning model and interaction learning model and hin-dcf in different datasets
参考图8, 本文考虑了是否加入注意力机制对模型影响的对比实验。其中, 为了控制变量, 无注意力机制模型对不同的元路径的隐语义向量采用相同权重的加权聚合。而加入注意力机制的模型则通过注意力机制学习不同元路径的权重。在不同数据集中, 加入注意力机制后模型的准确率皆有了提升。

图8 有无注意力机制模型在不同数据集上的MAE 对比图Figure 8 Comparison of models with or without attention mechanism on different datasets
4.2 结论
本文研究了一种结合张量分解方法和异构信息网络中路径信息的深度学习推荐模型。将用户、物品、元路径映射到相同维度的隐语义向量空间中的。且将分解得到的隐语义向量作为深度神经网络的输入的初始化, 采用双塔的学习模式, 一部分做表征学习、一部分做匹配学习。考虑到不同用户有不同的喜好模式, 即对不同元路径的偏好不同, 本文融入基于元路径的注意力机制, 学习不同元路径的偏好权重。同时基于元路径的注意力权重可以在推荐过程中做一定的可解释。在实验部分, 与其他流行的推荐算法做多组不同指标的对比试验, hin-dcf 模型的精确度和收敛速度皆有效提升, 并且能够更好地应对数据集稀疏的问题。
本文讨论的方法结合了异构信息网络, 是在网络信息不缺失的情况下的研究。然而现实中信息的很难完整地获取, 需要进一步研究在异构信息网络缺失部分信息的情况下, 如何更好地应对数据集稀疏的问题。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
小学教学研究(2022年5期)2022-04-28
数学物理学报(2021年1期)2021-03-29
疯狂英语·初中天地(2021年11期)2021-02-16
五邑大学学报(自然科学版)(2020年4期)2020-12-09
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
少年漫画(艺术创想)(2019年2期)2019-06-06
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
