
一种自适应的低负载故障检测方法
2021-11-08 00:41叶进邓志宇胡亮青陈贵豪李琳
广西大学学报(自然科学版) 2021年4期
叶进,邓志宇,胡亮青,陈贵豪,李琳
(广西大学 计算机与电子消息学院, 广西 南宁 530004)
0 引言
故障检测是分布式系统容错技术的重要组成部分, CHANDRA等[1]首次对故障检测做出了定义之后,规模不断扩大,检测机制对自适应和可扩展性要求越来越高。
故障检测大部分是通过心跳包实现的,根据超时时间内是否收到被检测节点的心跳消息来判断该节点是处于故障状态还是活跃状态。自适应故障检测是以历史最大的心跳消息间隔时间、消息延迟均值等作为下一次超时时间值进行预测,相比固定超时设定有较好的预测效果。FALAI等[2]通过实验对几种计算延迟的方法进行了对比和系统性的总结,让各种方法搭配不同的安全量,获取相应的检测性能,以上的方法对检测时间和准确性的确有所改善,但对服务质量(quality of service, QoS)的反馈并不完全准确。CHEN等[3]首次在论文里提出故障检测QoS的评价标准并提出可控服务质量的自适应故障检测器,可以用最小的代价获得QoS,同时满足不同服务需求[4]。
随着的分布式系统越来越庞大,节点需要处理大量的检测消息,例如一个分布式系统有n个节点,其检测机制采用传统的心跳检测,通信方式为一对多或者多对多,那么其产生的通信量就是O(n2)数量级。GUPATA等[5]对此类检测和基于再检测的网络负载进行了讨论,传统多对多心跳检测的次优因子随系统规模变化,而基于再检测的网络负载的次优因子是常数级别,从而拥有较低负载的故障检测越来越受重视。其研究主要分为以下两类:
① 层次式检测。系统中的节点被分成多个层次,在各层中都会有一个主节点,若主节点失效,将直接影响系统运行性能。为此GOSSIP协议[6]由RENESSE等[7]引入到故障检测之中的,逐渐成为故障检测消息更新的关键模块,将故障结果随机的分享给其他节点或者进程[8-9],可以有效避免层次式检测主节点失效的问题。
② 感染式检测[10]。这种检测方式随机选择临近节点传输信息,类似于流行病的传播,具有可扩展性、健壮性和容错性[11]。如SWIM协议[12],采用类似于谣言传播或病毒传染的方式进行故障检测,该协议提高了检测准确度且使得检测时间有了界限,但系统中节点处理消息缓慢而造成的误判依旧较高。HORITA等[13]采用静态配置的方式,选取额外的节点辅助检测,优化了检测的准确性,也缩短了检测时间,但辅助检测都是静态配置的。由于具有快速收敛和较低网络负载的特性,SWIM协议在HPC[14-16]中得到了广泛应用。DADGAR等[17-18]提出的Lifeguard协议,增加了评分机制,用以调整检测的超时和间隔,进而改变检测的怀疑超时,进一步降低了故障检测的误判率,但评分方式计算粒度较粗,对检测超时等因素的调整不够细化。
上述方法极大提高了故障检测的性能,但分布式系统的网络仍然复杂多变,依据网络多变的状态优化故障检测策略依旧是亟待解决的问题之一。
1 研究动机
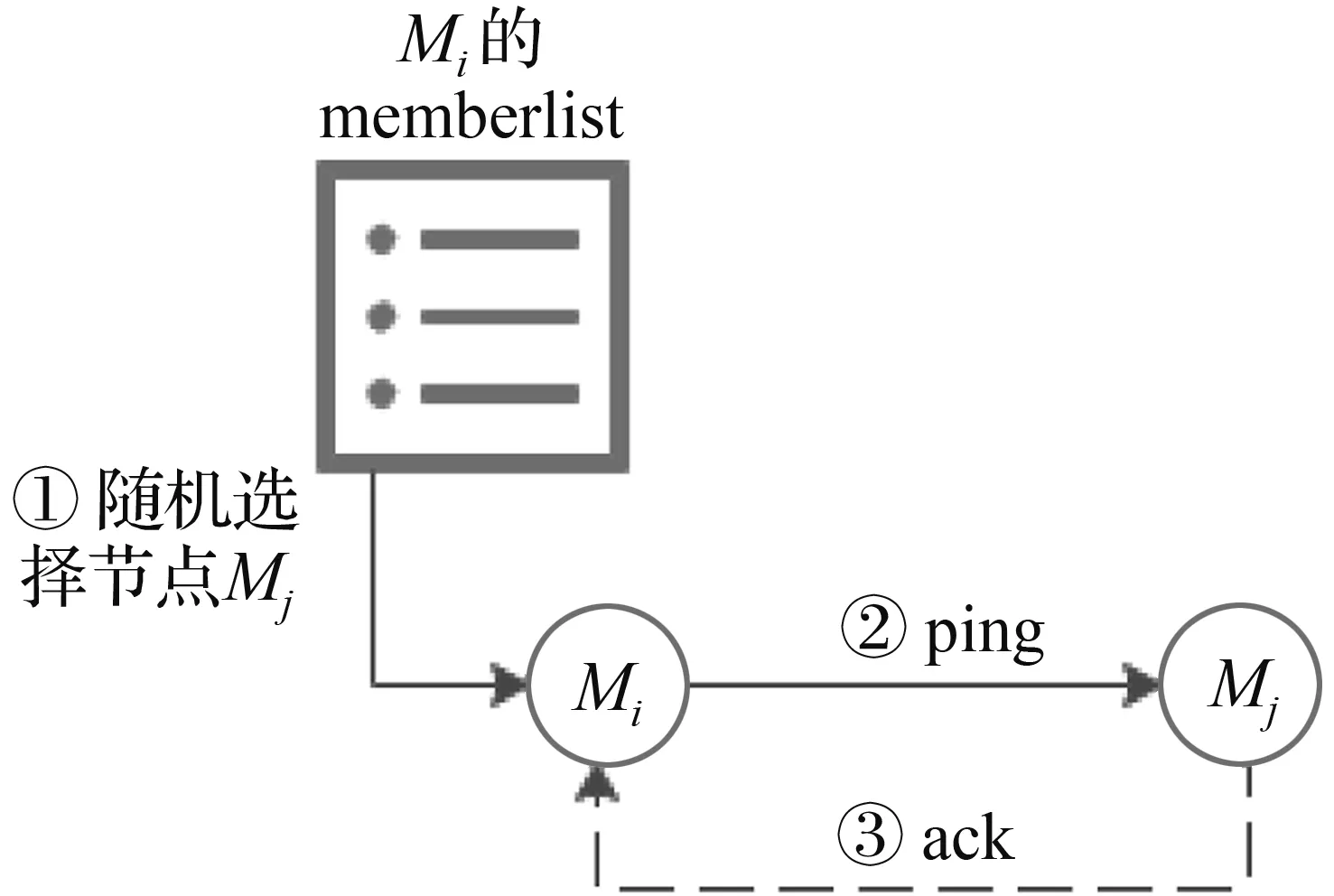
网络带宽弥足珍贵,分布式系统有许多的任务需要处理,如果故障检测网络负载过高,则会适得其反,作为低负载的故障检测方法,SWIM协议使用随机检测的方式进行故障检测,缓解了传统心跳机制的可扩展性问题。SWIM协议是由故障检测和信息传输两个部分组成,故障检测部分包括循环检测、再检测、怀疑等待和故障确认。SWIM故障检测过程如图1所示。
其中Mi是检测节点,Mj是被检测节点,记录在Mi的成员列表(memberlist)中。故障检测过程中,Mi对Mj进行故障检测,若在规定时间内收到Mj的ack响应,则标记Mj为活跃节点,如图1(a)展示。若Mi未收到响应,则开启图1(b)所示的再检测环节,此时Mi将在memberlist中选择其他的k个节点,发送检测消息(ping-req),若在规定时间内收到任意一个回应,则认定Mj为活跃节点。若规定时间内仍未收任何回应,则进入怀疑等待阶段,如图1(c)所示,如果其他节点检测Mj节点为活跃节点,则记录Mj节点状态为活跃并发送此消息。若Mj节点收到怀疑其为故障节点的消息,则发送其自身为活跃的消息。最后,如果Mi没有收到反驳消息,则标记Mj为故障节点,并随机发送故障消息,如图1(d)所示。Dissemination Component组件利用Gossip协议进行消息传播,该协议将消息传播给所有节点所耗费的时间为O(log2N)数量级。
(a) 初次检测
SWIM协议与传统的故障检测方法相比,增加了怀疑阶段,有效降低了误判率。但分布式系统中的节点性能并不是时刻一致的,因性能低下造成的误判依然居高不下,鉴于此,Lifeguard协议增加“自我意识”的方式来调整检测超时值、检测的间隔,进而动态改变怀疑超时,最终大幅度降低了系统中的故障误判。
Lifeguard协议通过3个组件的相互租用来降低系统故障误判的概率,这3个组件分别是Self-Awareness、Dogpile和Buddy System。Self-Awareness和Dogpile都是通过评分分数的变化而改变的,以此为基础,Buddy System则是控制相关变量(传输消息数量、新Gossip消息优先级、重发限制等)情况对Self-Awareness、Dogpile运行细节做调整。通过Self-Awareness、Dogpile和Buddy System的联合作用,Lifeguard协议更进一步地降低了误判率,但是故障检测、传输的延迟以及网络负载都较之前有所增加,并且评分机制的最终结果是预设数值的某一个。没有权衡好检测时间、传输延迟和检测准确度之间的关系。此外,Lifeguard协议还有存在其他的问题:①利用Gossip协议传输的所有消息都是随机的,检测过程中,检测节点对被检测节点没有回应而产生怀疑时,系统中的其他节点成功地检测到了被检测节点,而随机发送被检测节点是活跃节点的消息时不发送给检测节点,超时时间结束之后,被检测节点被标记为故障,此时,经过评分机制之后,评分结果加1,超时的设定就会大于正常情况。②再检测过程中,nack(negative-acknowledgment)的发送是在检测超时时间剩余20%时启动,如果此后收到了响应ack,再回馈给检测节点,检测节点由于时间关系收不到此信息,也会判断被检测节点故障,由于发送了nack且被判定为故障节点,那么评分分数就会加2,如此类情况频繁发生,超时值始终会处于最大值的状态,势必会增加故障检测的时间。
基于以上的分析,笔者通过算法对最近一段时间内的往返时间做计算,利用所得结果预测检测超时,并依次预测设定超时值、检测间隔和怀疑超时,为使时间粒度更加细致。本文用离当前时间最近的多个往返时间计算超时预测结果,提出了动态自适应的故障检测模型(dynamic self-adaptative SWIM, DSS),希望可以改善系统性能,降低负载和检测时间。
2 自适应DSS故障检测模型
本文考虑的系统模型是由m(m≥1)个节点组成,节点之间通过网络互通消息,相互交换数据。本文中的节点可以是计算机中的进程,也可以是真实的计算机节点。利用往返时延来计算各节点之间超时预设结果。本文利用窗口池来放置最近一段时间内的往返时间,通过指数加权移动平均(exponentially weighted moving-average, EWMA)[19-20]计算预测值,之后根据预测值动态的设定故障检测的超时。最终的超时预测值随近期的往返时延波动,更加能反应当前系统网络中不断变化的实际情况。
本文设计的DSS故障检测系统由故障检测部分、怀疑部分和传输部分组成,其检测流程如图2所示。节点在memberlist中选择被检测节点进行检测,如果该被检测节点返回响应ack,那么记录两个节点之间的往返时间,与此同时标记被检测节点为活跃节点。若被检测节点无反馈信息,进入再检测过程;若检测节点最终收到反馈信息,执行同样的操作(记录时间、标价状态);若检测节点未收到反馈则开启怀疑等待;若在此时间内检测节点收到关于被检测节点的反驳消息,标记被检测节点为活跃节点,否则认定被检测节点发生故障,并发送此消息。整个过程中的怀疑消息、反驳消息和故障消息传输都是通过Gossip协议进行的。
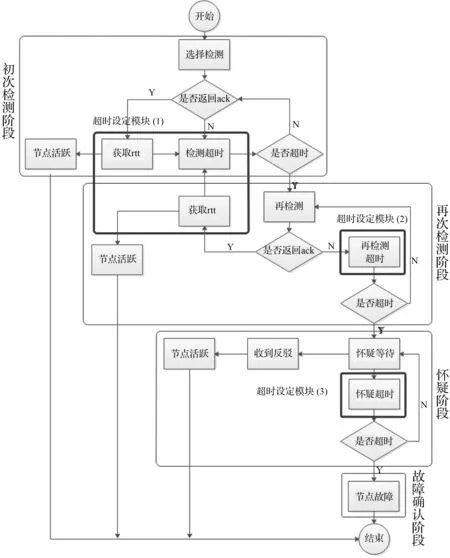
图2 DSS故障检测流程
定义当前最近的一个往返时间是Rt,承载往返时间的滑动窗口的大小为w,用序列 (Rt-m-1,Rt-m-2,…,Rt-1,Rt) 表示往返时间序列。 变量Et表示下一个初次检测超时的预测值,那么式(1)是初次检测超时Ft计算公式:
Ft=βFt-1+(1-β)Rt,
(1)
式中,β是可以调节的参数,β∈(0,1),将公式(1)继续分解可得:
(2)
根据文献[15]的实验默认初始时的初次检测超时为50 ms,F0表示初始超时值。
再检测至少需要经过两次请求的反馈,因此再检测超时Zt计算公式如式(3)所示:
Zt=λFt,
(3)
式中,若λ≥2,则故障检测的超时时间Et如公式(4)所示:
Et=Ft+Zt。
(4)
在实际网络中,怀疑超时设置的影响因素也包括探测间隔,可以通过系统中帧的反馈来判断,由此探测间隔Pt如公式(5)所示:
Pt=αEt,
(5)
式中,α表示数量关系。
同样,探测间隔、怀疑消息数量也是超时设定的要素。在系统中,若对某个节点的怀疑消息过多,那么该节点大概率已经发生故障,应减少检测的时间,节点的怀疑消息较少时,相应增加怀疑超时时长,节点可以有更多时间做故障检测。怀疑超时St如公式(6)所示:
(6)
式中,γ表示数量关系;N表示组成员数量;C表示怀疑消息的数量。
3 实验分析
开源项目Consul已经实现了Lifeguard协议和SWIM协议,本文在相关部分做对应修改,并采用Docker部署Consul节点,Docker技术比传统的虚拟机技术更加方便快捷,可以在一台物理机上部署多个虚拟计算机节点,组成分布式系统。本实验利用Docker Compose工具对多个容器进行操作,Compose也是Docker的开源项目,负责对Docker容器集群的编排。本实验需要奇数个服务器端节点,因此利用Compose文件生成7个服务器端节点和25个客户端节点,系统网络是172.20.0.0/16。实验物理环境为32 GB内存的工作站,64位的Ubuntu18.04系统。本实验根据误判、检测延迟和网络负载三个方面的变化来说明本文提出的检测模型的优势。
3.1 参数设置
①β的选取
在当前环境中,窗口大小w和公式(1)中的β关联起来做数学处理:
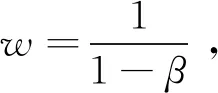
修改滑动窗口值的大小,预测准确率也随之变化,预测效果变化如图3所示。由图3可知滑动窗口w取值20时,预测效果最好,因为近期往返时间的权值降低,若持续增大滑动窗口w的值,预测的准确性也逐渐降低。因此本文的实验取β=0.95。
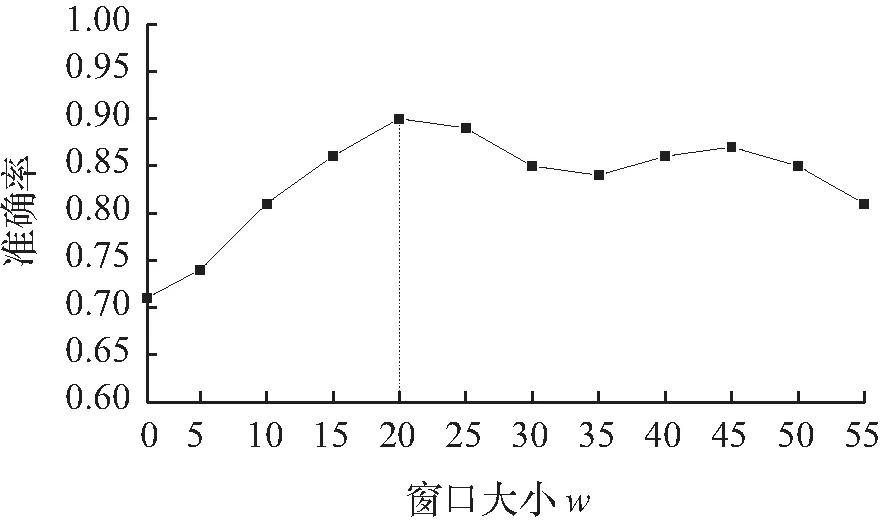
图3 预测效果变化
②α和γ选取
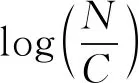

表1 误判率变化
3.2 测试实验
根据组件的多寡,将SWIM分为原始SWIM、Gossip式SWIM和G-S(感染风格传输并且拥有怀疑超时)式SWIM。本实验选取G-S式SWIM。
本实验Lifeguard协议包含了Self-Awareness和Dogpile,为了实验更具一般性,每一类别实验进行10次,并取这10次数值的均值。
① 误判实验
在实验中统计系统内发生的误判事件数量,每5 s统计1次,记录误判事件数量。图4是3种模型误判率对比, Lifeguard和DSS的误判率都处于较低的水平,相比固定的怀疑超时,动态改变的怀疑超时可以降低系统中的误判事件的发生。总之,相比Lifeguard,DSS平均降低了26%的误判率。
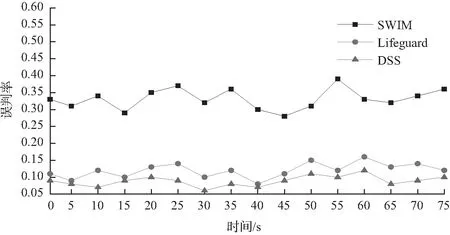
图4 3种模型误判率对比
② 检测延迟实验
观察多次实验结果后发现,在系统故障节点到达一定数量后,系统性能都下降到一个较低水平,不具备参考价值,所以实验设置的最多故障节点数量为16个,每增加1次故障节点,则统计1次实验结果。图5是3种模型的检测时延对比。从图5可见,对于节点故障的检测,Lifeguard拥有最高的延迟,采用平均化方式计算的SWIM协议次之,虽然检测延迟比Lifeguard小,但是不能反映真实环境的真实情况,本文提出的DSS综合考虑了各种因素,根据具体的往返时间动态调整超时,更加真实,检测时间平均降低了39%。
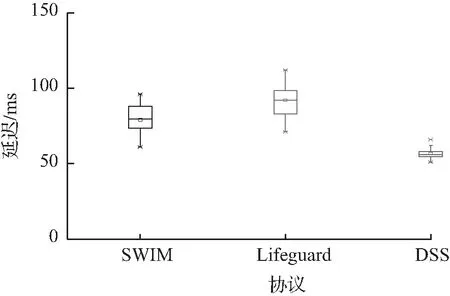
图5 3种模型的检测时延对比
指数加权移动平均算法充分考虑了波动环境中往返时间变化,计算最近往返时间的同时也考虑了较长时间内的往返时间,比Lifeguard协议采用粗粒度的评分机制来设定超时值更加合理。
③ 网络负载实验
3种模型网络负载对比如图6所示。从图6可以看出随着故障的增多,系统中的数据量是逐渐减小的,并且SWIM协议的网络负载在每种故障情况下都是最小的,由于DSS减少了nack帧的发送,DSS平均比SWIM增加了9%的网络负载。
综上所述,相比Lifeguard,采用指数加权移动平均做超时预测的DSS模型平均降低了39%的故障检测时间,同时平均降低了26%的检测误判率。
4 结语
本文提出的故障检测模型采用指数加权移动平均对三个阶段的超时进行预测,以及相应的自适应超时调整,更能反应当前时间段内网络变化,实验表明所设计的DSS故障检测机制有效降低了检测时间和误判率。接下来作者将致力于改善以Gossip协议为基础的检测结果共享机制,着力优化DSS故障检测的性能,使DSS模型能更好的适应由于节点处理消息缓慢而造成误判的分布式系统,增强协议在具有crash-stop故障类型的分布式系统中的适用性。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
中外女性健康研究(2020年10期)2020-08-02
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
通信产业报(2020年43期)2020-01-15
中国医学创新(2019年9期)2019-08-19
医学信息(2017年16期)2017-09-05
建筑建材装饰(2016年13期)2017-01-04
中国卫生(2015年12期)2015-11-10
中国卫生(2014年12期)2014-11-12
