
跨社交网络用户身份关联技术
2021-11-06 12:03王李冬胡克用
重庆理工大学学报(自然科学) 2021年10期
王李冬,张 引,胡克用,张 赟
(1.杭州师范大学 钱江学院,杭州 311121;2.浙江大学 计算机科学与技术学院,杭州 310012 3.浙江传媒学院,杭州 310018)
自媒体时代越来越多的用户开始习惯在社交网络(social media network,SMN)上实现日常的互动和信息的获取。现今,社交网络个数已达上百个,且种类繁多,典型的如校园类的人人网、开心网,学习类的知乎网等,综合类的如MySpace、Twi-tter和Facebook等。人们为了享受不同网站提供的服务往往需要注册为该网站的用户。普通用户拥有多个不同社交网站的帐号是较普遍的情况。用户可以在Foursquare上用手机与别人分享地理位置信息进行交流,也可以在MySpace上交友、分享个人信息并进行即时通讯。每个用户若在不同的社交网络注册,会留下其个人信息(如年龄、工作单位、毕业院校等),发表的文本内容,发布的视频、图像等多媒体信息,以及在自己感兴趣内容下的评论、转发等。对这些信息进行整合、分析,将构成用户完整的个人画像。
现有的社交网络与社交网络之间由于功能不同,因此往往是相互独立的,而且针对同一用户在不同网络上的注册信息缺乏有效的管理平台进行统一管理。为了分析某用户甚至群体用户在社交网络上的行为,获取用户的完整图像(profile),需要整合用户在不同社交网络上的数据,其突破口在于跨社交平台的用户身份匹配,即识别用户在多个社交网络上的帐号。跨社交平台的身份匹配对商业上的信息服务推送、好友推荐以及网络安全治理有重要意义。
同一用户在不同社交网络注册时往往会填报相同或相似的属性信息,如相同的用户名,相同的性别、生日等信息。这些信息为跨社交网络的身份匹配提供了一定的表面特征条件。但是,表面特征信息往往存在稀疏性、内容缺失以及部分属性与事实不符等特征,因此单纯依靠表征特征会提升匹配的错误率。本文主要研究跨社交网络的身份匹配问题,即给定部分已知种子用户(同时存在于2个社交网络)节点集MPprior的基础上,推断出所有潜在的匹配用户对集合MP。为了匹配跨社交网络用户,需要对2个网络中的所有用户一一比对。由于社交网络的日益庞大,针对两两用户节点进行计算会消耗大量的时间。因此,本文拟通过候选用户选择和基于匹配因子的识别方法实现配对用户对的判定,并提出融合用户表面特征(属性信息)和基于网络嵌入的朋友匹配度作为身份匹配的匹配因子,本文将该方法命名为JFA(joint friend-attribute)。现有方法往往单独采用基于表面特征的匹配技术或者基于网络嵌入学习的方法,而本文对这2种方法进行融合探讨,属于全新的一种尝试。
1 相关工作
跨社交网络用户身份匹配方法主要包括基于社交网络表面特征和基于表示学习2种方法。
1.1 社交网络表面特征
该类方法主要利用用户属性信息或者融合用户属性信息和拓扑结构的方法实现跨社交平台的身份匹配。针对前者,大部分方法计算某个特定属性值的字符串相似度或者组合多个属性值相似度,并通过不同的权重系数加权平均得到最终的结果,或将其作为输入以训练二类分类器。例如,Vosecky等[1]将姓名、出生年月等属性信息构成用户的特征向量,并计算用户与用户间的特征相似度,之后对每个相似度赋予权重计算综合相似度。孟波等[2-3]利用监督学习方法和提取的属性特征构建多个二类分类器实现身份识别,属性特征包括名字特征、用户信息特征以及拓扑特征。Kong等[4]利用用户的上网时间、地理位置、文本信息等提出MNA方法(multi-network anchoring),构建SVM分类器,在其基础上通过交叉匹配方法提升匹配效率。针对后者,Liang等[5]通过提取用户名、姓名等特征,并利用交叉匹配和剪枝原则实现用户匹配。Bartunov等[6]利用条件随机场(conditional random fields)提出联合属性和链接关系的JLA方法,通过构建能量函数并最小化能量函数的方式得到用户匹配,并利用监督分类器对结果实行剪枝操作,取得良好的匹配效果。该方法适用于由于隐私保护而导致个人信息缺乏的状况。Wang等[7]提出融合二元朋友、三元朋友关系以及属性特征的概率因子图模型PIFGM (pairwise identical factor graph model),在部分训练数据集的基础上预测配对用户对。大部分的研究表明,融入链接关系的身份匹配效果优越于单单依靠属性信息的匹配效果[8]。
除上述2种方法外,也有部分研究机构利用其他表面特征,如社交网络上的头像、朋友关系、用户发布的文本内容、用户行为等进行身份识别。例如,Goga等[9]提出了一种适用于海量用户的身份识别方法。该方法首先利用Jaro距离方法计算用户名字之间的相似度,利用感知哈希计算头像相似度,利用人脸识别技术得到脸部相似度,然后根据上述特征相似度,训练朴素贝叶斯分类器得到匹配结果。Zhou等[10]提出基于朋友关系的用户识别方法,为每个候选匹配用户对计算匹配度,并通过排序的手段得到最佳匹配用户对。Nie等[11]通过融合网络结构和用户发布的文本内容实现用户核心兴趣(core interest)建模,在其基础上实现身份识别。Zafarani等[12]提出利用用户行为建模的形式对不同网络的用户身份进行匹配。此外也有研究者开始针对MOOC网站的用户行为进行分析[13],将用户在不同MOOC网站上的学习资源进行整合。上述多数研究主要面向2个社交网络的跨身份识别,Zhang等[14]为了满足3个以上社交网络用户身份识别的局部一致性和全局一致性,提出一种全新的基于能量目标函数的方法。
1.2 表示学习
近几年,基于网络表示学习的方法开始引起学者们的关注[15-19]。该类方法的核心思想来自于网络嵌入(network embedding),即将网络嵌入到低维的特征空间,使得每个节点都由一个低维的特征向量表示,最后对不同网络的节点表示学习结果进行分析以预测是否为同一用户节点[20]。例如,Wang等[15]提出LHNE(linked heterogeneous network embedding model)模型将结构信息(朋友关系)和内容信息(主题)融合嵌入到统一的特征空间。Zhang等[16]假设若2个网络的用户在各自的ego network中具备更多的相似邻居,则他们为同一用户的概率就越大。基于此,提出基于图神经网络的MEgo2Vec模型,在构建匹配ego network的基础上,通过多角度节点嵌入方法获取用户名的字面和语义特征,并利用注意力机制对不同邻居用户间的影响力建模,最后结合结构嵌入对用户身份进行预测。Liu等[17-18]提出的IONE模型和PALE模型都利用结构信息进行用户节点的表示学习并获得嵌入向量,但没有利用用户的属性特征。Shang等[19]针对表征学习模型的鲁棒性提出基于对抗学习的方法,首先通过自编码器得到网络的低维嵌入空间,再引入节点的嵌入向量的先验分布,利用对抗正则化方法提升嵌入向量的鲁棒性。上述基于表示学习的方法虽然取得不错的效果,但是网络的表征学习和用户身份的对齐尚无法结合到一个模型中。
总之,面向跨社交网络的身份匹配已取得一定的研究成果,但多数方法缺乏普适性和高准确率。此外,大多数基于用户属性的匹配手段都缺乏对属性贡献度的深入分析,而且在研究方法上很少将表面特征匹配的结果与嵌入学习模型相结合。本文拟从融合属性特征和拓扑结构的角度出发,探讨单个特征和多个特征对用户匹配方法准确率的影响,将表面特征匹配与网络嵌入学习模型相结合提出准确有效的身份匹配准则。
2 JFA方法
Zhou等[10]对129个用户(同时在新浪网和人人网注册)进行调研,发现这些用户大约有67.5%的朋友关系同时存在于新浪网和人人网。可见,用户在不同的但具备相似功能的社交网络中往往具备相似的社交群。Goga等[9]发现很多用户同时具备Google+、MySpace、Twitter等帐号。由此,我们可以假设:① 若给定先验种子用户集,则可以根据朋友关系推断出候选配对用户对。② 若候选配对用户对中具有相似的属性信息和结构信息(朋友关系),则他们为同一个体的概率越大。基于此假设,我们提出融合属性特征(如用户名等)和拓扑结构(朋友匹配度)的JFA(joint friend-attribute)方法。
在讲述方法前,本文先作下述定义:
定义1(配对用户对) 给定2个社交网络,分别表示为SMNA={UA,EA},SMNB={UB,EB}。UA表示网络SMNA的用户实体集合,EA为网络SMNA的用户关系(相互关注或链接关系),UB表示网络SMNB的用户实体集合,UAi代表用户集合UA中的第i个用户,UBj代表用户集合UB中的第j个用户。若用户UAi和用户UBj在现实生活中属于同一个体,则(UAi,UBj)∈MP,MP为配对用户集合。
定义2(先验种子) 社交网络SMNA和社交网络SMNB的先验种子代表已知的匹配用户对,将先验种子集记为MPprior。
定义3(朋友关系) 在社交网络SMNA中,若用户UAi与用户UAj相互关注,则用户UAi和用户UAj为朋友关系,记为UAj∈friend(UAi)。
提出的JFA方法框架图如图1所示。
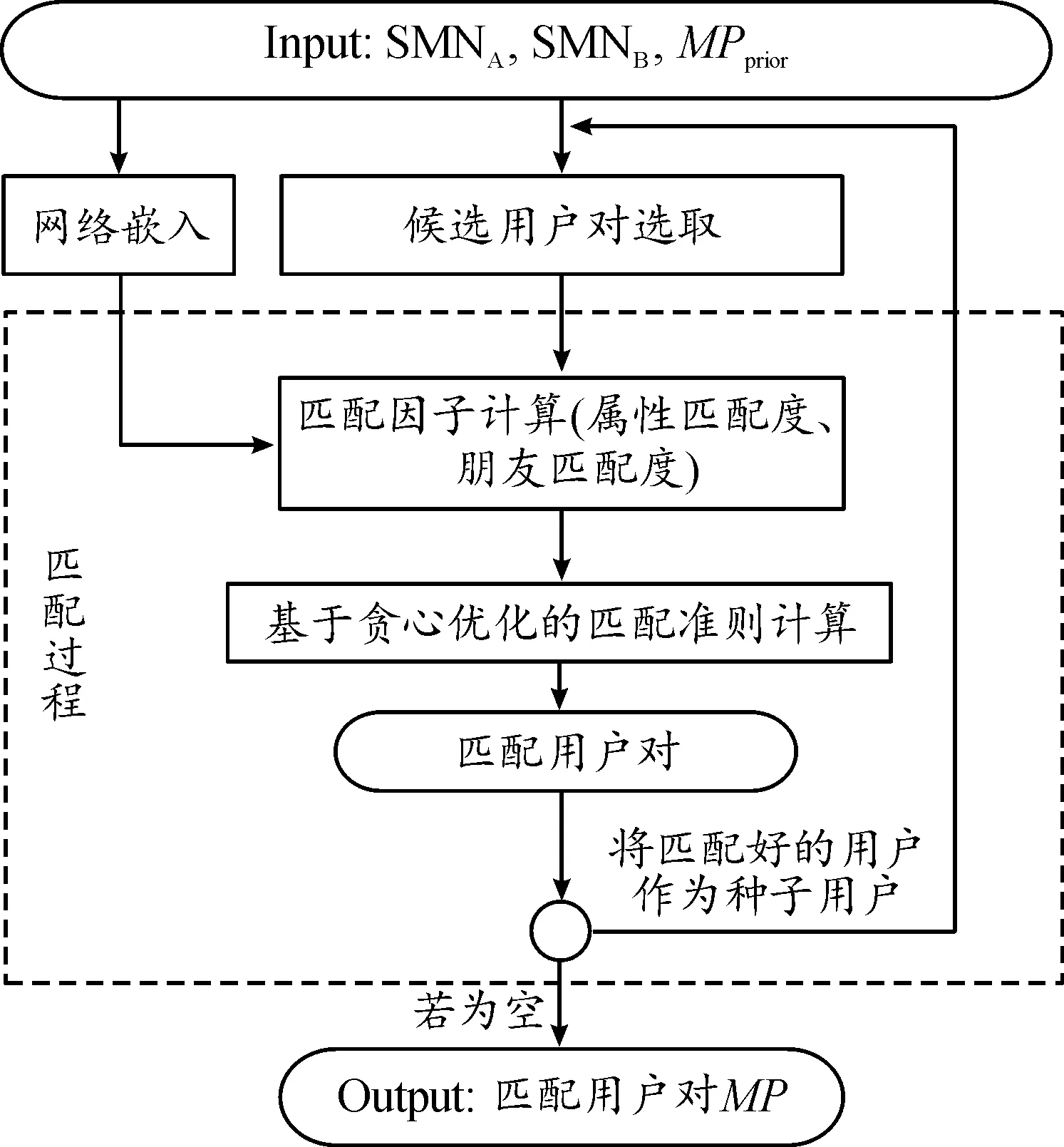
图1 JFA方法框架
该方法主要包含候选用户对选取和匹配过程两部分。前者主要根据网络的拓扑结构选出有较大可能成为匹配用户对的候选用户对。后者在候选用户对集合中进一步选择,利用字符串匹配等手段计算用户属性匹配度,并利用网络嵌入学习算法计算朋友匹配度,最后通过基于贪心优化的判定准则对匹配因子进行比较,以得到最终匹配用户对。上述2个过程相互迭代,直到种子用户集为空。
2.1 候选用户对选取
将候选用户选取规则定义如下:
定义4(候选用户对) 若UAi和UBj为2个社交网络中的先验种子用户(即代表同一用户),UAk∈friend(UAi),UBl∈friend(UBj),则(UAk,UBl)属于候选用户对CMP,定义为:
CMP={(UAk,UBl)
|UAk∈friend(UAi)∧UBl∈friend(UBj)∧
(UAi,UBj)∈MPprior}
(1)
其中,
friend(UAi)={UAj|(UAi,UAj)∈EA}
候选用户对选取示例见图2。图2描述2个社交网络SMNA和SMNB,2个网络中的虚线表示先验种子点,即存在于2个社交网络中的同一用户。根据候选用户选取规则,从种子点出发,得到(Lisa,Ben)×(Lisa,Ray,Cathy,Violet)为候选用户对,其中,×表示笛卡儿积。

图2 候选用户对选取示例
2.2 匹配过程
一旦获得候选用户对,需要通过一定的准则来判定这2个用户是否属于同一个体。目前没有方法适用于任意2个社交网络的配对用户判定,一般针对特定社交网络对已有方法进行适度的修改。Balduzzi等[21]提出利用email对用户进行判定。由于email的唯一性,利用email进行判定可以准确的对用户身份进行识别,但很多社交网络将email作为隐私数据。同个用户往往在不同的社交网络使用同一个昵称(nickname)[21]。若2个社交网络中用户的用户名一样,可认定为该对用户为同一对象。但是部分社交网络允许不同的用户以相同用户名进行注册,如人人网。单单通过用户名无法直接判断两用户是否属于同一人,因此可通过其他可获取的因素,如地理位置、生日、工作单位、性别等属性信息进行进一步确认。此外,部分网络会提供额外的信息,如twitter网络提供独特的URL地址用于用户识别,针对twitter网络的用户配对可直接利用该URL信息。除了上述信息外,已有研究表明融入网络链接关系的匹配方法效果优越于单单依靠属性信息的匹配效果[8]。
基于上述分析,本文融合属性匹配度和依赖链接结构的朋友关系匹配度作为准则判定的依据,提取用户名、姓名、URL信息(可选)、email(可选)等属性匹配度以及朋友匹配度等匹配因子。
2.2.1属性匹配度
用户名信息,表示为u,部分文献采用Levenshtein距离进行度量[22]。Levenshtein距离作为计算2个字符串间的差异程度的字符串度量,曾被多次应用于用户名的差异度量并取得较好的效果[23]。本文将2个用户名U1和U2之间的用户名相似度Simu(U1,U2)按照下式进行计算:
(2)
式中:lev(U1,U2)表示用户U1和U2之间的Levenshtein距离;l(ui)表示ui的字符数。
姓名信息(可选)表示为n,在多数的网络中都会出现,例如Facebook和Twitter。该信息可作为与用户名同等重要的属性字段进行身份匹配,但无法作为身份识别的唯一判定信息。由于国外社交网络的姓名中,“姓”和“名”的顺序并无统一规则,部分用户会将“姓”放前,部分用户则不会。Levenshtein距离对顺序较敏感,完全相同的名字,若“姓”和“名”的顺序倒置,将产生完全不一样的计算结果。利用VMN算法[6]对姓名进行度量。VMN是一种非常有效的名字匹配技术,可以对姓名等信息实现模糊匹配。在VMN算法中,名字“Tony Xie”和“Xie Tony”的相似度为1。
URL信息(可选),表示为l。若某社交网络提供URL信息助于身份识别,则根据URL信息与相应社交网络的链接地址进行比对,若相同,则返回1,否则为0。
2.2.2朋友匹配度
现今越来越多的社交网络中用户的属性信息存在缺失、不真实等问题,而社交网络的结构信息显得更加稳定可靠。朋友匹配度主要依赖于网络的链接结构。在社交网络中,若2个用户之间存在链接关系,往往代表2个用户之间相互关注,又或称之为朋友关系。若2个网络中的用户具备越多的共同朋友,则他们属于同一个体的概率越大[10]。假设F_Matchij代表朋友匹配度,文献[10]将其定义为:
F_matchij=|FAi∩FBj|
(3)
式中:FAi表示用户UAi已经被识别的朋友集;FBj表示用户UBj已经被识别的朋友集;F_Matchij表示用户UAi和用户UBj的共同朋友个数。F_Matchij值越高,代表两用户越匹配,为同一个体的概率越大。然而,上式计算模型在仅仅具备部分种子点的情况下,无法提前获得用户对的共同邻居个数。考虑到社交网络的朋友关系体现为网络的拓扑结构信息,因此,为了获得朋友匹配度,使用网络嵌入的方法学习得到每个节点的结构嵌入向量,训练多层感知机(MLP)模型作为网络间节点结构特征向量的映射函数,再根据欧氏距离计算结构特征向量之间的距离作为两节点的朋友匹配度。具体步骤如下:
步骤1针对社交网络SMNA,首先采用网络嵌入的方法将每个节点嵌入到低维向量空间。类似文献[24]的表示学习方法,本文定义2个节点间存在边的概率为:
(4)
式中:zAj和zAi分别代表节点UAj和节点UAi的嵌入向量;σ(x)代表 sigmoid函数。为了学习得到嵌入向量,通过最小化以下目标函数:
O′=-∑(UAi,UAj)∈EAlogp(UAj,UAi)
(5)
步骤2按照同样的方法对社交网络SMNB进行嵌入学习,再综合2个网络的目标函数得到网络嵌入的最终目标函数:
O1=-(∑(UAi,UAj)∈EAlogp(UAj,UAi)+
∑(UBi,UBj)∈EBlogp(UBj,UBi))
(6)
为了最小化目标函数,采用随机梯度下降法进行求解。同时,采用负采样方法(Negative Sampling)解决目标函数求解过程中的耗时较大问题。对于每条边(UAi,UAj),重新根据下式计算logp(UAj,UAi):
(7)
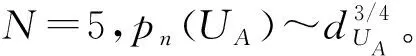
步骤3根据种子配对用户对的嵌入向量,学习SMNA和SMNB中节点的结构特征向量之间的映射函数φ。给定zAi∈ZA,映射函数φ(zAi,θ)将向量zAi映射到空间ZB。其中,θ代表映射函数的参数集合。利用多层感知器模型构建映射函数φ(zAi,θ),获得向量空间ZA到向量空间ZB的映射关系。设计的MLP模型包括输入层、隐藏层和输出层,隐藏层单元个数设定为2*d(d为输入层个数)。将种子配对用户的结构嵌入向量作为训练数据,对MLP模型进行训练。
步骤4通过下式计算得到用户UAi和用户UBj的用户匹配度:
f(F_Matchij)=||φ(zAi;θ)-zBj||2
(8)
2.2.3匹配准则
将SMNA和SMNB中UA→UB的配对结果记为矩阵Y。为了简化计算,假设SMNB中仅存在1个用户与UAi配对。若UAi和UBj配对,记为yij=1,否则yij=0。则2个社交网络的局部身份配对矩阵Y满足∑lyil≤1∀UAi∈UA,∑kykj≤1∀UBj∈UB。
基于此,定义以下目标函数融合用户的属性和基于嵌入学习的朋友匹配度:
αf(F_Matchij))
(9)
其中,
(10)
Matcha(UAi,UBj)表示为用户UAi和用户UBj在匹配因子a上的匹配度。1≤k≤|K|,k表示规则使用的匹配因子个数,K表示所有的属性匹配因子集合,|Κ|代表匹配因子总个数。式(9)中的参数α用于平衡属性匹配值和朋友匹配度。式(10)中的wa代表匹配因子a的权重。2个网络间用户的匹配问题就可以转化为式(9)的目标最大化问题:
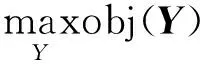
(11)
为了对式(9)的组合优化问题进行求解,利用贪心优化的原理,每次从候选用户集选取配对用户对(UAi,UBj)的过程中,使得在yij=1的条件下,obj(y)得到最大化。基于此,定义匹配分值Mat_score,针对每一个候选用户对中的用户UAi,从UB中选取匹配分值最大的用户为匹配用户。
Mat_score(UAi,UBj)=(1-α)Rk(UAi,UBj)+
αf(F_Matchij)
(12)
2.3 JFA算法描述
根据上述流程,首先根据种子配对用户对进行候选用户对选取,将该过程记为CandidateSelection(SMNA,SMNB,MPprior),其中,MPprior代表先验种子用户集。针对候选用户对集合中的每一对用户计算Mat_score(UAi,UBj)(见式(12)),以得到新的配对用户对,以此作为新的种子用户重新选取候选用户对。上述过程迭代计算,具体过程如下:
Input:SMNA,SMNB,种子用户集MPprior
Output:配对用户集MP
1MP←∅;
2Repeat
3 Randomly select a userUAm∈MPprior;
//遍历种子用户集中的每个种子点
4CMP←CandidateSelection(SMNA,SMNB,UAm);
//CMP代表候选配对用户对集合
5foreach(UAi,UBj)inCMPdo
6k←|K|; //初始化匹配因子个数
7 Calculate Mat_score(UAi,UBj) according to Eq.(14);
8endfor
9 (UAi,UBj)=arg max(UAk,UBl)∈CMPMat_score(UAk,UBl);
10MP←MP∪(UAi,UBj);
11 ifUAiis not included inMPpriorthen
12MPprior←MPprior∪UAi;
//将匹配好的用户作为种子用户
13 end if
14MPprior=MPprior-UAm;
15untilMPprior=∅
由上述方法可得,一旦获得配对用户对,则将该用户对视作新的种子点(见算法第12行),以重新计算得到候选配对用户对。该方法迭代运行,若种子集为空,则方法终止。
3 实验
3.1 数据集
使用3种数据集进行实验验证,分别为Facebook和Twitter数据集、SNS数据库以及随机网络数据集。
1) Facebook和Twitter数据集
该数据集共包含16个来自Facebook和Twitter的网络对。本数据集忽略网络中的单向关注关系,保留互相关注链接关系。数据集已经标注2个网络中的匹配用户对,并同时标注了种子用户,具体相关信息如表1所示。图3描述了数据集中的一个网络对,该网络对的种子用户为0号用户,且存在3对配对用户对(红色虚线表示)。

表1 数据集信息

图3 Facebook和Twitter网络对示例
2) SNS数据集
SNS数据集包括当下5种流行的社交网络:Twitter、Live-Journlal、Flickr、Last.fm和Myspace,每种数据集包括了用户的基本属性信息,同时包含了两两网络间用户对应的基准数据。具体数据集信息参考https://www.aminer.cn/cosnet。
3) 随机网络数据集
随机网络数据集利用Erdos-Renyi (ER)网络[25]、Watts-Strogatz(WS)网络[26]和Barabasi-Albert(BA)[27]网络3种网络类型。图4表示3种随机网络图(1 000个节点)的度分布。ER和WS网络都是通过边的随机化重连生成,而且度概率符合正态分布,BA网络的度概率符合幂律分布。
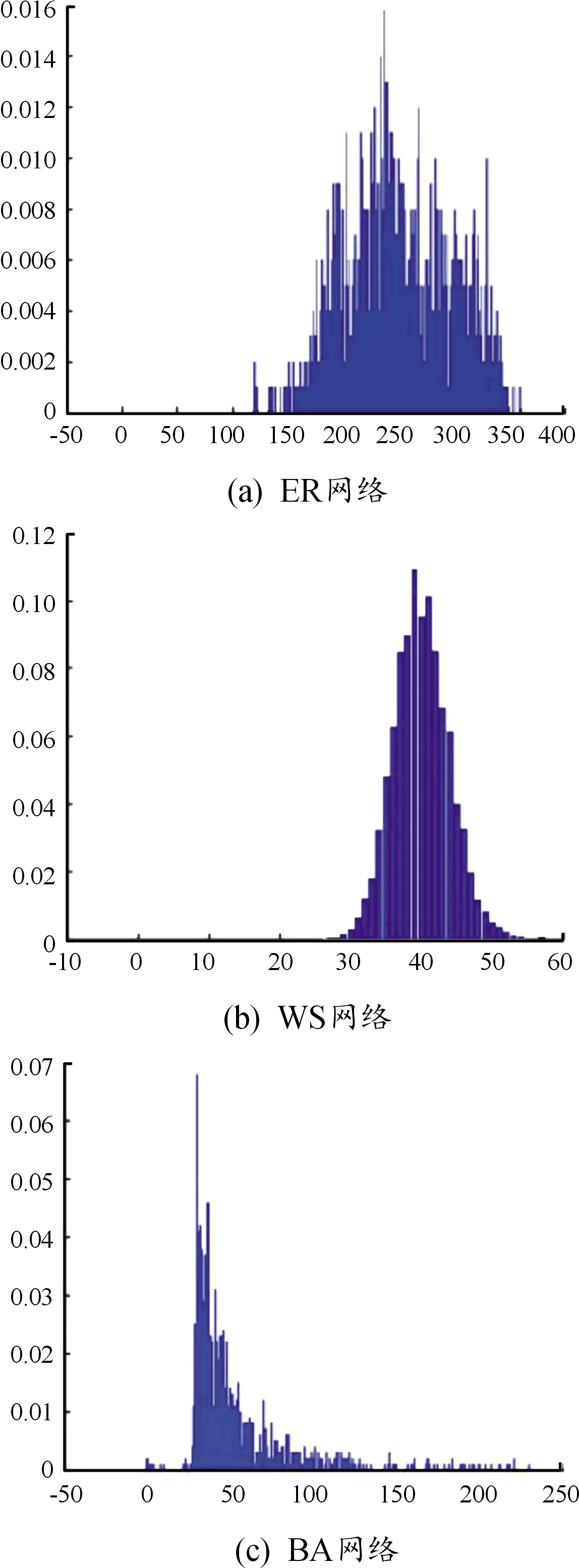
图4 随机网络的度分布曲线图
由于随机网络生成的节点无法体现用户属性等信息,因此,通过细粒化种子集在全部节点中的比例,分析JFA方法中的朋友匹配度因子在随机网络上的用户匹配效果。为了在随机网络对中获得配对用户,首先生成较大规模的随机网络,然后按照文献[28]的方法通过抽样进行子网络提取(抽样过程如图5所示),抽样好后的网络对(SMNA和SMNB)中序号相同的即为同一用户。同时引入Jaccard系数测量生成的网络对的节点/边的覆盖度。在实验部分,先生成1 000节点数的ER、WS网络(每种5个网络),再生成10 000节点的BA网络,然后分别针对ER、WS和BA网络生成5对网络对(共15对网络对),WS网络和ER网络中的边随机化重连概率p设定为0.05。在BA网络中,将每次引入新节点时新生成的边数m设定为20。

图5 随机网络抽样示例
3.2 实验结果
采用传统的准确率(precision)、召回率(recall)以及F1-measure进行效果度量,具体如下:
recall=tp/(tp+fn)
(13)
precision=tp/(tp+fp)
(14)

(15)
式中:tp代表真阳性,即被正确匹配的账号对;fp代表假阳性,即被错误匹配的账号对;fn代表假阴性,即无法被匹配出来的账号对。
3.2.1随机网络数据集
针对随机网络数据集,匹配准则中的匹配因子仅考虑朋友匹配度,并通过设定不同的种子个数,判定JFA方法的种子个数对用户身份匹配效果的影响。需要注意的是,仅计算朋友匹配度作为匹配因子使得JFA方法演变为单纯依赖拓扑结构的一种方法,因此本文将该方法和NS方法进行对比实验,并将结果记录于图6和图7中。由Narayanan等[29]提出的NS方法仅依赖于网络的拓扑结构。

图6 JFA和NS在3个随机网络上的召回率折线图
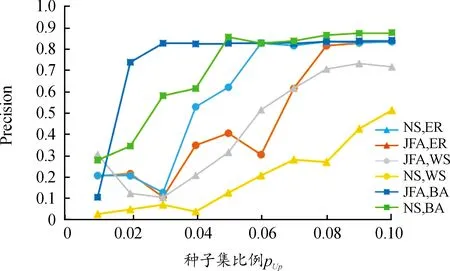
图7 JFA和NS在3个随机网络上的准确率折线图
图6表示JFA方法和NS方法在3个合成网络上的召回率结果。横坐标表示先验种子集占的比例,纵坐标代表召回率。由结果可得,当种子集的比例升高,召回率也会相应提升。在所有情况下,仅利用朋友匹配度的JFA方法比NS方法能够识别出更多的配对用户。图7给出2种方法在3个合成网络上的查准率结果。横坐标表示种子集占的比例,纵坐标代表召回率。在大部分情况下,随着种子集个数的增多,查准率也会相应得到提高。针对ER和WS网络,本文方法的识别准确率明显高于NS方法。针对BA网络,即便在种子集比例较小的情况下,本文方法依然能体现较强的优越性(在先验种子集比例为0.02的情况下,召回率达到0.735)。
3.2.2真实网络数据集
针对Facebook-Twitter数据集和SNS数据集,采用不同的基准算法与本文方法进行比较,分别为SVM、JLA(Joint Link-Attribute)[6]、NS[29]、SiGMa[30]、COSNET[14]和JFA。在SVM算法中,通过属性相似度得到用户UAi和用户UBj之间的相似度向量H(SAi,SBj),SAi和SBj为其各自的属性向量;然后将已知匹配的用户对的属性相似度向量作为训练向量,不同属性信息的相似度作为不同的向量维度值;基于此,用户身份是否匹配转化为一个二分类问题,即C(H(SAi,SBj))∈[0,1],C代表分类器,分类结果1代表UAi和UBj为同个用户,否则为不同用户。JLA方法为现今效果较好地实现局部身份匹配的常用方法,利用账号属性信息和网络结构,将2种信息融合到一个框架中。SiGMa方法是一种融合结构信息和实体的属性相似度测量的贪婪迭代算法。在具体实现上,将用户名完全匹配的用户作为种子点进行扩展,评分函数(score function)采用各个属性相似度的加权和。JFA方法中,式(13)的平衡因子α通过实验经验设定为0.5。COSNET方法是近几年效果较好的一种融合属性信息和结构信息的匹配方法,将其应用于SNS数据集的两两社交网络的匹配(去除全局匹配部分),局部属性特征按照原文中的方法进行提取。表2记录了不同匹配因子的测试结果。表3给出不同方法在Facebook-Twitter数据集的16对网络上的匹配效果的均值。表4记录了不同方法在SNS数据集上的实验结果。
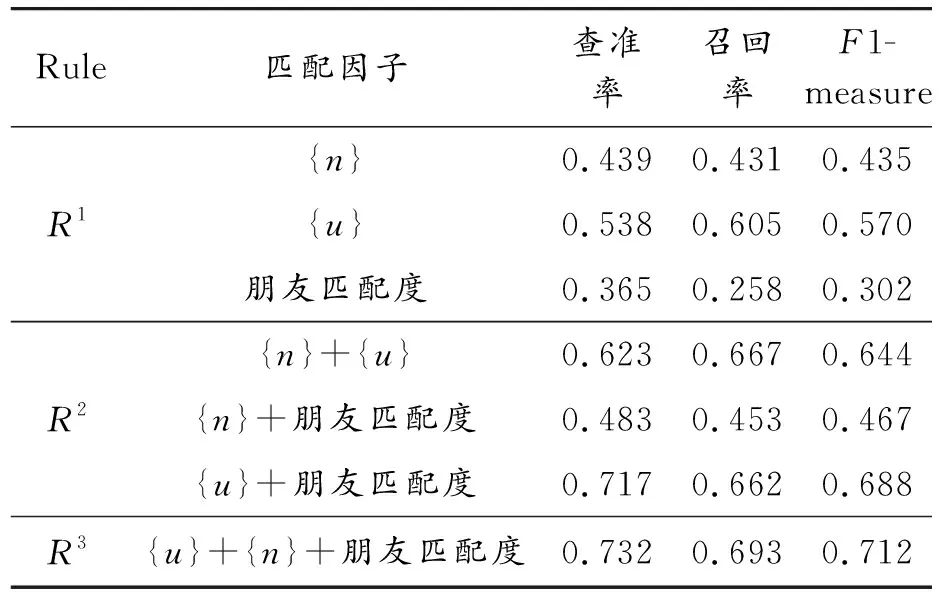
表2 面向Facebook-Twitter数据集不同匹配因子下的JFA方法效果
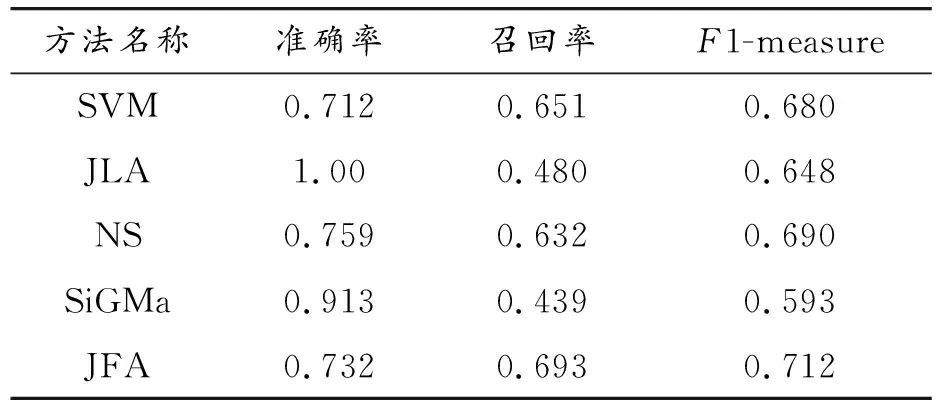
表3 Facebook-Twitter数据集的身份匹配效果

表4 SNS数据集的身份匹配效果
由表2数据可以看出,不同匹配因子取得不一样的效果。从单个匹配因子来看,姓名和用户名比朋友匹配度方法的准确率要高,而且能获得更高的召回率。朋友匹配度在该数据集上效果不佳,主要是由于该数据集中配对用户对的个数较少,且部分网络的结构信息差异较大。基于用户名的效果比基于姓名的效果好,主要源于部分用户在网络上填写的姓名存在一定的不真实性。总的来说,高级别判定准则的匹配效果比较低级别的匹配效果好,尤其是查全率得到一定的提升,F1值也得到提升。如大部分R2判定准则的匹配效果比R1判定准则效果好。由此可见,特定的匹配因子组合可有效提升跨社交平台用户身份匹配的效果。
表3记录了从Facebook到Twitter的匹配和Twitter到Facebook的匹配结果的均值。 其中,JLA方法使用监督分类器的剪枝手段,所有方法的结果都是无种子用户存在的情况下取16对网络对的均值。由表3结果可得,虽然JLA方法能得到最高的准确率,然而该方法的召回率并不十分理想。仅仅以网络拓扑为计算依据的NS方法效果比综合属性因素和链接关系的JFA方法要差。JFA方法的效果不仅比JLA优越,而且JFA方法中基于判定准则的匹配方法比JLA中基于条件随机场的最优用户映射实现更加简单,JLA方法需额外利用基于监督分类器的剪枝操作才可获得相对满意的效果,这样的步骤使得该方法无法直接适用于海量用户的跨社交平台应用。
表4记录SNS数据集中每对网络的匹配效果。针对每对网络,JFA算法的效果远比SVM、SiGma以及NS算法和JLA算法效果好,且在大部分的数据集上,效果优越于COSNET。与JLA方法类似,SiGMa针对2种数据库都可以获得高于90%的准确率,但是却获得较低的召回率。在与COSNET的比较中,COSNET对部分数据集的查全率并不理想(如Flickr-MySpace,Last.fm-MySpace等),但本文算法针对大部分数据集查全率有所提升。综合表3和表4数据可得,针对真实网络,本文方法优越于基于拓扑结构的NS方法和基于属性信息的SVM传统方法,同样比融合拓扑结构和属性信息的JLA和SiGMa方法效果优越。
4 结论
提出一种基于JFA方法的跨社交平台身份匹配,并将其应用于随机网络和真实社交网络的数据集上。首次通过表面特征与嵌入学习相结合的方式进行匹配,并选择不同的匹配因子进行实验,结果表明:该方法在综合多个匹配因子的条件下可取得较高的准确率,效果优于传统的JLA、NS、SiGMa、COSNET等方法,而且单单基于朋友匹配度匹配因子的匹配效果依然优于传统方法。今后的工作主要针对3个或3个以上的社交网络群,研究解决两两网络之间匹配结果不一致的情况。目前针对跨社交平台用户匹配的研究缺乏权威有效的基准数据集。
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
儿童时代·幸福宝宝(2019年9期)2019-10-28
文苑(2018年17期)2018-11-09
时代英语·高二(2017年4期)2017-08-11
莫愁·家教与成才(2017年7期)2017-07-11
红领巾·成长(2016年10期)2017-05-10
公民与法治(2016年22期)2016-05-17
今日教育(2014年1期)2014-04-16
