
基于邻域密度的K-means初始聚类中心优选方法
2021-11-06 12:02雒明雪苑迎春陈江薇王克俭
重庆理工大学学报(自然科学) 2021年10期
雒明雪,苑迎春,陈江薇,王克俭
(河北农业大学 a.信息科学与技术学院; b.教务处,河北 保定 071000)
大数据时代,对海量数据进行聚类分析是目前研究的重要方向,已被广泛应用于教育、电商、交通等领域[1-2]。聚类是根据物以类聚的思想,将数据对象分为不同簇,使簇内数据相似度高,而簇间数据相似度低。聚类算法通常有划分法、密度法、模型法、图论法等[3-9]。
K-means是划分法中的经典算法,因其效率高、便于理解而被广泛应用。但传统K-means算法的初始聚类中心采用随机选取方式,容易导致聚类结果陷入局部最优。同时,随机方式还会导致初始聚类中心选择具有不稳定性,使得聚类结果也不稳定。
针对K-means算法初始聚类中心选择问题,许多学者做了大量研究。例如,通过引入群智能算法,采用自适应布谷鸟、引力搜索算法等优化初始簇中心,但由于算法计算复杂没有得到应用[10-14]。一些学者从样本数据密度和距离角度出发优化初始聚类中心。例如,冯勇等[15]、王子龙等[16]同时考虑局部密度和距离进行算法优化。唐泽坤等[17]、唐东凯等[18]则是分步考虑密度和距离,首先根据局部密度构建聚类候选中心集,再利用基于距离的算法选取初始聚类中心。唐泽坤等[17]权衡密度和距离对聚类的影响,对数据进行局部加权处理,利用最大最小原则选取初始中心点,但计算数据权重增加了时间消耗。唐东凯等[18]从局部密度角度提出LOF算法计算样本点离群因子,并对离群因子进行排序,截取密度较高的样本点,再从距离角度出发利用最大最小距离算法选出聚类中心,确保高密度簇中心的选取,但忽略了低密度簇被作为离群点,造成聚类中心选取不准确。同样,由于对每个样本进行LOF计算增加时间消耗,邵伦等[19]引入网格思想,根据聚类种类数K,将样本数据映射到K维网格,然后将网格内样本数较多且距离满足定义距离的K个子网格作为初始聚类中心,以网格为最小单位进行计算,减少计算复杂度。但只考虑了单个网格密度,且候选网格集数目过多,算法后期基于距离进行选择时未考虑离散数据集对聚类中心选择的影响。
分析上述优化K-means聚类中心算法发现:① 基于密度和距离的优化算法,对初始聚类的选择具有很好的效果,但对每个样本进行密度计算,算法时间消耗较大;② 基于网格划分的算法能够大大减少计算时间消耗,但未对网格进行筛选,导致利用距离计算时聚类中心的选择出现偏差。综合上述问题,提出基于邻域密度的K-means初始聚类中心优选方法,即NDK-means算法(optimization method ofk-means initial clustering center based on neighborhood density),优化传统初始聚类中心选取。NDK-means算法基于网格思想划分数据集,并通过定义网格邻域描述网格与其邻域密度关系,实现较高密度网格的筛选;为进一步缩小候选集,扩大网格步长,合并候选集中的相邻中心点;最后基于距离选取K个初始聚类中心。在UCI数据集上进行的实验验证了算法的聚类效果和收敛速度。
1 问题分析
邵伦等[19]的算法通过多维网格划分,利用网格中数据点的数量代表网格密度,简化了样本点密度计算,但其在计算密度过程中仅计算网格密度,未考虑网格与其周围网格的关系,同时未对网格进行筛选,导致数据点稀疏的网格也在候选中心集。另外,基于距离选择聚类中心可能造成稀疏密度网格被选为初始聚类中心,如图1所示,数据集中1个簇中含有分布较为稀疏的样本点。邵伦等[19]的算法在选取时没有剔除稀疏样本点,致使稀疏区域被选中,影响聚类效果。图1为邵伦等[19]算法的聚类中心图。其中,三角形为真实聚类中心,十字形为初始聚类中心。
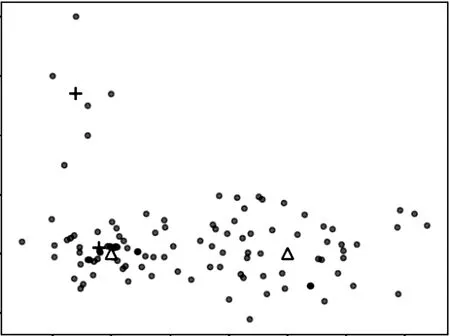
图1 文献[19]聚类中心图
2 NDK-means算法
NDK-means算法以K-means算法为基础,基于局部密度和距离因素对初始聚类中心选取进行改进。算法通过将数据集映射到不同网格实现样本数据的初步分类,以网格为最小单元进行聚类,避免每个样本参与复杂计算,减少资源消耗。在进行候选集的选择时,计算网格与其邻域网格的密度关系,筛选出多个局部高密度网格区域,避免稀疏簇被误判为离群点,真实的聚类中心应处于簇中密度较高的区域。在同一簇中可能存在多个高密度网格,因此本文算法利用迭代的思想,通过不断扩大网格步长将同一簇中的高密度网格中心合并,进一步缩小候选中心集。NDK-means算法聚类中心的选取思想与真实聚类相似,聚类中心应具有一定的距离。为避免选择同一簇的高密度网格作为初始聚类中心,利用最大最小距离算法和网格密度选取初始聚类中心。
2.1 相关定义
NDK-means算法基于网格思想对数据集进行划分,通过空间邻域进行候选网格的筛选,确定候选中心集,相关定义如下:
定义1(网格邻域)对任意一个网格Si,其相邻网格集合称为Si的网格邻域,记作Fe(Si)。图2所示是一个二维网格划分示意图,图中Si的网格邻域为Fe(Si)={Si1,Si2,Si3,Si4,Si5,Si6,Si7,Si8},共8个相邻网格单元。

图2 网格划分示意图
定义2(网格密度)网格Si中样本点的个数称为网格密度,记作DSi。
定义3(邻域密度)对任意一个网格Si,其网格邻域中所有网格密度的均值称为邻域密度,记作SKi。公式如下:
其中:DSij为网格Si的第j个邻域的网格密度;n为邻域的个数。
聚类中心出于簇的高密度区域, 但不一定出于最高密度区域,因此采用均值的方式筛选高密度网格,而不是选择网格密度大于邻域任一网格密度的方式。邻域密度反映了一个网格其相邻网格的样本聚集程度。通过对比该网格密度与其邻域密度,可判定该网格是否是高密度网格,并确定是否为初始聚类中心点候选网格。
定义4(高密度网格)对任意一个网格Si,若其网格密度大于其网格邻域密度,则网格Si称为高密度网格。
令SRKi记作Si的网格密度与其网格邻域密度的比值,则:
若SRKi>1,则网格Si属于高密度网格。
高密度网格固定阈值的设定很难同时满足密集簇、稀疏簇。对此,采取网格与其周围邻域密度关系确定高密度网格,减轻阈值设定的复杂度。
2.2 算法描述
NDK-means算法初始聚类中心选择主要分为3步:
步骤1依据数据集属性划分多维网格空间;
步骤2确定初始聚类中心点候选网格集;
步骤3基于最大最小距离算法确定初始聚类中心点。
2.2.1划分多维网格空间
数据集映射到多维网格的过程实际是解决网格划分的大小问题,确定网格大小是问题的关键所在。网格划分较大会使不同类别数据集划分到同一网格中,无法正常选取聚类中心;反之,网格划分较小则会导致网格过多,网格密度相似,无法根据密度剔除离群数据且计算量增大。基于王立英等[20]提出的网格划分函数,考虑数据集大小和属性个数,结合本文算法得到最终划分函数,如式(3)所示。
(3)
其中:N为数据集大小;F为属性个数;M为多维网格的各个维度网格数。
2.2.2确定初始聚类中心点候选网格集
完成多维网格划分后,通过计算得到候选网格集。此时,在候选网格集中,同一簇中可能存在多个候选网格。为了进一步缩小候选网格集数量,采取合并思想,通过改变网格划分、调整网格步长、扩大网格使同簇中相邻网格合并,直到满足数量公式。由此确定初始聚类中心点候选集的步骤如下:
步骤1根据式(3)划分多维网格,计算网格DSi。
步骤2根据式(1)(2)计算得到高密度网格和候选网格集。
步骤3计算候选集网格的中心,形成候选中心集DR。网格中心计算方法如下:
对任意网格Si包含样本x={xi1,xi2,…,xip},其中p为网格中样本点数量。网格内所有样本属性均值为网格中心,记作sci公式:

(4)
步骤4计算候选集合中元素数量,若不小于迭代因子则减少网格数量M=M-1,得到新的网格划分。按网格密度排序,计算网格中心形成新的候选中心集。迭代因子为:
α=2×k
其中k为聚类种类数。
步骤5重复步骤4直到满足迭代因子。得到最终候选中心集DR。
2.2.3确定初始聚类中心
由于距离较近的高密度网格可能来自于同一个簇,故选取相距较远的高密度网格作为初始聚类中心。本文中根据最大最小距离算法思想,利用网格密度值,首先选择密度最高网格的中心作为第1个初始聚类中心,锁定高密度簇中心;然后依据最大最小距离算法选取剩余聚类中心点,排除了初始聚类中心的随机性,具有稳定的准确性。算法描述如下:
Input:候选数据集DR,聚类个数k
Output:k个初始聚类中心
步骤1 选取DR中第1个元素作为初始聚类中心C1,加入聚类中心集合,则C={C1}。同时删除DR中的第1个元素。
步骤2 根据最大最小距离原则,计算第i个初始中心Ci,加入聚类中心C={C1,…,Ci},删除中心;
步骤3 当集合C长度小于聚类个数k时,返回步骤2;
步骤4 输出k个初始聚类中心。
2.2.4算法流程
综合上述3个过程,NDK-means算法整体流程如下:
Input:数据集D,聚类个数k
Output:k个簇
步骤1对数据集D中数据对象,根据网格划分公式划分多维网格,计算网格密度;
步骤2根据网格密度,计算网格邻域密度,确定初次候选初始聚类中心候选集,经过迭代,不断合并网格,得到最终候选集。
步骤3在候选数据集上,利用最大最小距离算法,选出k个初始聚类中心。
步骤4根据步骤3得到初始聚类中心,继续执行K-means算法,得出聚类结果。流程如图3所示。

图3 NDK-means算法流程框图
2.2.5算法复杂度分析
本文算法优化K-means初始聚类中心的选取分为3个步骤:① 划分多维网格空间,将每个数据点映射到空间网格中复杂度为O(n);② 首先计算每个网格的邻域密度,复杂度为O((3F-1)·M),然后判断每个网格是否为高密度网格,复杂度为O(M),该步骤的算法复杂度为O(3F·M);③ 基于距离选取初始聚类中心,该步骤的复杂度与网格候选集大小有关为常数。综合以上步骤,NDK-means算法复杂度为MAX(O(n),O(3F·M))。
3 实验结果与分析
为充分验证本文算法的效果,实验分为2个部分:第1部分采用计算机模拟数据,将传统K-means算法与本文NDK-means算法进行可视化对比;第2部分采用来自UCI实验室的3个真实数据集,对传统K-means算法、基于局部密度和距离的文献[18]算法、基于网格划分思想的文献[19]算法和本文算法进行对比。实验环境为PC机,具体配置:CPU为Intel Core i7-4510U,内存为8 G,硬盘为1T,Windows10操作系统。所有算法均使用Python3.2实现。
3.1 模拟数据集
使用python中make_blobs模块生成数据集。数据集具有4个类别,包含100个二维数据点。通过此数据集对K-means算法和本文算法进行聚类实验。各算法经过50次实验,在聚类结果中随机选取2组,如图4所示是传统K-means算法两组实验结果,图5所示是本文改进算法两组实验结果,其中三角形代表实际聚类中心,十字形表示初始聚类中心。对比实验结果可以发现:传统K-means算法采取随机方式选取初始聚类中心,迭代次数分别为7次、4次,迭代次数和聚类结果不稳定。改进算法迭代次数均为2次,这是由于改进算法选取的聚类中心与实际聚类中心接近,迭代次数较少且聚类结果稳定。

图4 K-means聚类结果

图5 NDK-means算法聚类结果
3.2 标准数据集
为了对NDK-means算法进行验证,选取专门用于测试聚类算法性能的UCI数据库。UCI数据库是加州大学提出的用于机器学习的数据库,是一个常用的标准测试数据集,每个数据集都有明确的分类,可以直接得到聚类效果。实验对Iris、Seeds、New_thy这3个数据集进行测试,与传统K-means 算法、文献[18]算法和文献[19]算法进行实验对比。在3个测试集上分别运行20次,记录每次结果。实验数据集具体信息如表1所示。

表1 测试数据集信息
3.2.1准确率
表2是4种算法在不同数据集上的准确率。首先可以得到,NDK-means算法在测试数据集上的平均准确率均高于对比算法。本文算法在Iris、Seeds、New_thy数据集上准确率比原始K-means算法分别提升了10.63%、10.71%、13.01%,这是由于新算法采用网格邻域密度筛选中心候选集,选出的聚类中心出于高密度区域,避免了数据集中离群点成为初始聚类中心的问题,使初始聚类中心更接近真实聚类中心。同时,采用最大最小距离算法在候选集中选取最终的聚类中心,避免了初始聚类中心相似的问题。还可以发现,因为传统K-means算法随机选取初始聚类中心,最好结果与最坏结果相差10%~27%,聚类结果不稳定。

表2 4种算法在不同数据集上准确率 %
本文算法在3个数据集上准确率比基于局部密度和距离的文献[18]算法平均高出3.6%,且聚类结果稳定。文献[18]算法虽然也采用局部密度的方式进行候选集选取,但其直接剔除局部密度较低的样本点,导致无法识别低密度簇中心。文献[18]算法在利用最大最小距离原则进行初始聚类中心选取时,采取随机的方式,导致聚类结果不稳定。同时可以看到,本文算法在3个数据集上准确率比文献[19]算法平均高出4.3%,其中在数据集New_thy上比文献[19]高出10%。这是因为New_thy数据集中存在个别离群点,与其他数据点距离较远。文献[19]算法虽然同样基于网格划分进行初始聚类的优化,但其在网格划分时,每一维网格数量由聚类数K决定,对离群数据敏感,导致影响最终聚类效果。而本文算法基于局部密度,避免了离群点的影响。
3.2.2迭代次数
本文算法、文献[18]和文献[19]算法均分为2个部分:第1部分为初始聚类中心的选取,第2部分基于初始聚类中心进行聚类。第2部分的3种算法的实现流程相同,本文针对后一部分进行迭代次数对比。图6是4种算法在不同数据集上平均迭代次数比对。迭代次数表明了算法收敛的速度,收敛速度越快表明算法初始聚类中心的选择越靠近真实聚类中心。从图6可以看出:本文算法在3个数据集上迭代次数均远远小于其他算法,在3个数据集上平均迭代速度是文献[18]算法的2倍,在New_thy数据集上迭代速度是文献[19]的3倍。这是由于本文算法在选取初始聚类中心时采用邻域密度思想,同时考虑到紧密簇和稀疏簇,进而减少了聚类部分的迭代次数,体现了本文算法对存在稀疏样本点数据集的优势,在提高准确率的同时,加速了聚类迭代过程。
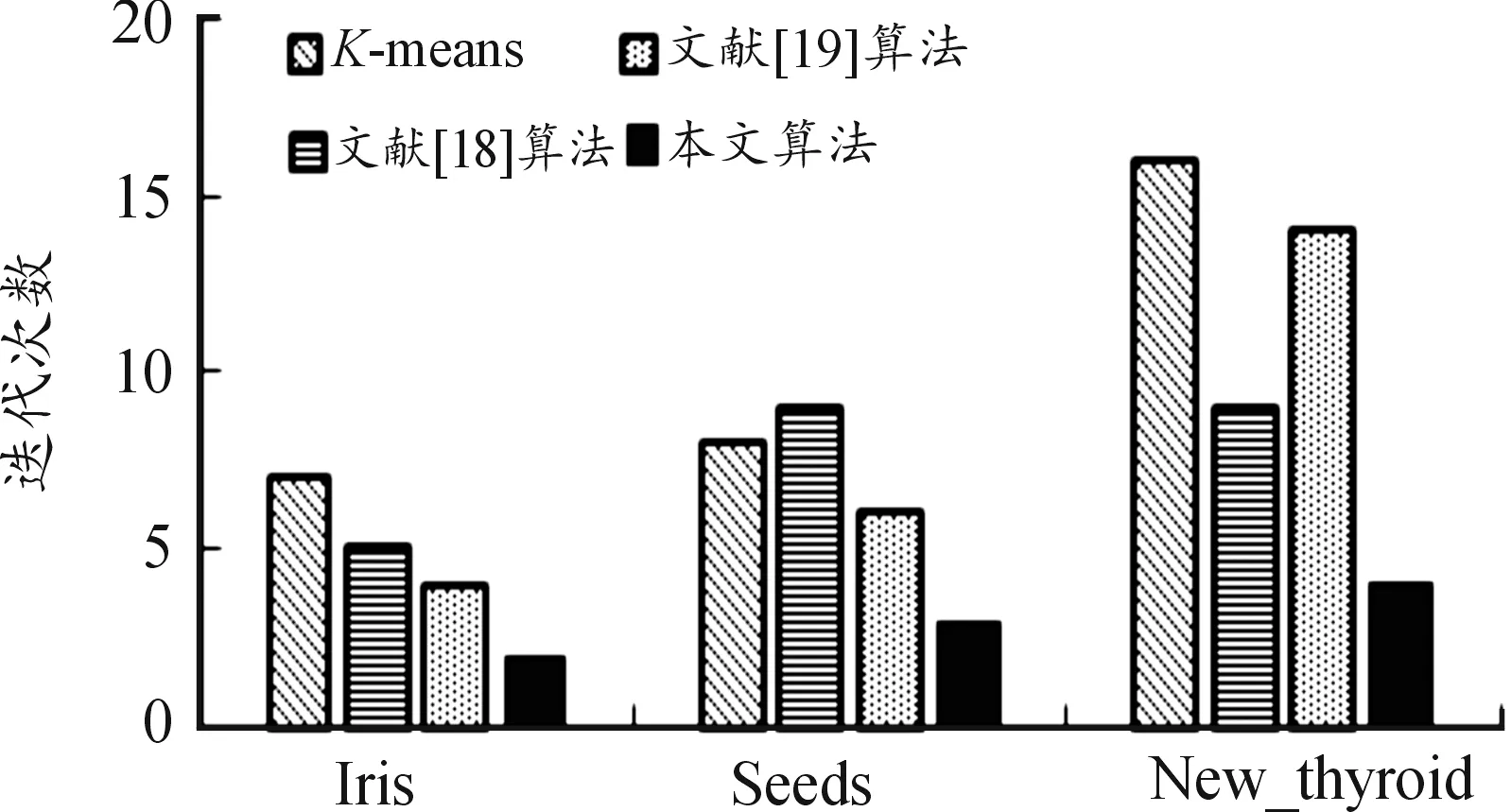
图6 4种算法在不同数据集上迭代次数直方图
4 结论
针对传统K-means算法初始聚类中心随机选取易导致陷入局部最优、聚类结果不稳定,且对离群点敏感的问题,提出基于邻域密度的改进K-means算法。借鉴文献[19]中网格思想划分样本空间,基于网格相对密度进行候选集筛选,排除离群点干扰,使候选集范围更加准确,同时利用合并思想,通过不断迭代缩小聚类中心范围,避免忽略稀疏簇中心;然后利用最大最小距离算法,选取聚类初始中心点,避免因相邻高密度区域重复而陷入局部最优。在UCI数据集上实验结果表明,本文算法较传统K-means算法减少了迭代次数,聚类结果具有较好的准确率和稳定性,并且对噪声数据不敏感。
猜你喜欢
陕西师范大学学报(自然科学版)(2022年3期)2022-06-07
资源信息与工程(2021年5期)2022-01-15
四川地质学报(2020年2期)2020-05-31
吉林大学学报(理学版)(2020年3期)2020-05-29
铁道通信信号(2019年6期)2019-10-08
自动化学报(2018年7期)2018-08-20
雷达学报(2017年6期)2017-03-26
周口师范学院学报(2016年5期)2016-10-17
互联网天地(2016年1期)2016-05-04
中国房地产业(2016年8期)2016-03-01
