
基于递归特征消除和Stacking集成学习的股票预测实证研究
2021-11-05 06:15黄秋丽黄柱兴
南宁师范大学学报(自然科学版) 2021年3期
黄秋丽,黄柱兴,杨 燕
(南宁师范大学 数学与统计学院,广西 南宁 530100)
0 引言
在预测股票走势的众多方法中,机器学习算法得到越来越多的应用.该算法选择合适的选股指标体系[1],使用数量化的统计分析工具来预测股票的优劣,其本质是数据挖掘领域[2]的二分类预测问题.李斌[3]等用技术指标作为输入变量,并比较不同算法模型的预测情况,得出SVM模型的策略最优,收益能力最高,夏普比率达到1.38以上,最大回测低于20%.王淑燕[4]等采用相关性分析方法分析指标的相关性,得出八因子的选股模型,随后利用随机森林算法模型验证该选股模型在中国的股票市场上是有效的.Yu[5]等在选择属性中应用遗传算法,并在预测股票市场涨跌趋势时,使用支持向量机模型,这种方法不但可以降低支持向量机模型的复杂性,还能提高该模型的效率,其结果与传统的时间序列及神经网络模型相比更优.
综合上述情况,我们认为,采用单模型预测算法对股票市场进行预测的效果有优有劣,不够稳定,采用集成学习方法则可吸取和融合各模型的长处,增加稳定性和提升准确率[6].集成学习思想由Dasarathy和Sheela在1979 年提出[7].一种基于神经网络的集成学习模型则是Hansen 和Salamon于1990 年首次展示[8],该模型的泛化能力较强,但方差较低;同年,Schapire[9]通过Boosting方法将弱分类器组合成一个强分类器.这说明在机器学习研究领域中集成学习已成为一种重要的方法.集成学习方法中常用的是堆叠法(Stacking),此方法的预测效果比单模型更好[10,11],但目前研究较少,多为单一算法.
因此,以股票预测研究为背景,讨论集成学习模型在股票预测研究中的学习能力,并与其他分类模型进行实证比对,寻找优化的股票预测模型,是本文的研究内容.我们以沪深300为投资标的池,选取波动指标、收益指标、经典技术指标和交易指标等4大类指标共24个二级指标作为评价因子,利用递归特征消除法结合Stacking 集成学习以及传统的随机森林、支持向量机和逻辑回归等4个机器学习算法分别构建分类模型,预测投资标的池中周频收益率排名前20%的股票标的,为投资者提供量化投资策略.
1 相关原理
1.1 递归特征消除法(RFE)
递归特征消除法可以说是一种“贪心”的算法,目的在于搜寻最优特征子集.先是反复构建模型,最后选出分类中的最佳特征子集,是递归特征消除法的主要思想内容[12].现将递归特征消除法的步骤总结如下[13,14]:
步骤1:建立训练分类器.
步骤2:计算特征的重要性测度.
步骤3:消除重要性测度低的不相关特征.
步骤4:将剩余的特征重复步骤1到步骤3,直到选出最佳特征子集.
1.2 逻辑回归
逻辑回归是机器学习中常用的算法之一,是一种简单高效、应用广泛的分类算法,主要用于二分类问题.它建立在线性回归的基础上,其公式如下:
z=wTx.
引入“Sigmoid函数”将结果转换为0或1的二分类形式,其函数的具体形式为
其中w已知.用hw(x)来计算特征变量x,若得到的结果大于 0.5,则预测其为分类 1,否则为分类 0.
1.3 支持向量机
支持向量机(SVM)是一种广义的线性分类器,它的基本思想是基于样本数据找到一个最优分界面,以将不同类别的样本进行区分.如果样本数据是线性可分的,就可以直接寻找最优分界面;若样本数据不是线性可分的,那么就需要使用核函数将低维样本空间映射到高维样本空间,然后再在高维样本空间中寻找最优的分界面.最优分类函数为
1.4 随机森林
在机器学习中,随机森林(RF)是一个包含多棵决策树的分类器,其中每棵决策树都是一个分类器.它首先在原始的样本里用bootstrap方法抽出多个样本;然后对每个样本分别进行建模训练,得到多棵决策树,组成随机森林;最后统计所有决策树的结果,用投票方式选出票数最多的分类结果,以之作为算法的最终结果.
1.5 Stacking 集成学习
Stacking 集成学习是一种训练一个可用于组合所有个体分类器的模型.Stacking 又称为Stacked Generalization,其具体做法是先训练多个不同的个体分类器,之后把这些个体分类器的输出数据作为输入数据来训练模型,最终可以得到预测结果.Sigletos[15]等对投票法和Stacking 法进行对比,结果证明Stacking 的效果优于投票法,在很多领域中皆如此.在分析 Stacking 算法时,因为基础学习器、元学习器和参数的选择对学习效果有直接决定作用,所以,Ledezma[16]等通过遗传算法来选择该算法中最好的配置.在我们构建的Stacking 集成学习模型中,第一层模型是采用支持向量机和随机森林的初级学习器,第二层模型是采用逻辑回归的次级学习器,如图 1 所示.
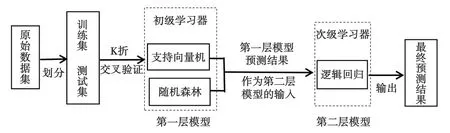
图1 Stacking集成学习模型架构
2 数据处理
2.1 构建初级特征集合
在分析国内外选股指标体系的基础上,为了能充分验证递归特征消除法和Stacking集成学习对我国股市预测的有效性,本文选取了4大类共24项数据指标[17],以之作为模型因子,其经典技术指标通过talib函数库计算得到,数据来源于baostock,数据按周频获取.有关因子的说明见表1.

表1 初级特征因子介绍
2.2 基于随机森林为迭代分类器的递归特征消除法选择特征子集
为选取与股票收益率关系密切的关键指标作为模型的输入,我们以随机森林为迭代分类器,利用RFE对特征进行选择.具体流程如图2所示.

图2 RFE-RF 特征选择流程
利用随机森林为迭代分类器的递归特征消除法(RFE),从初始的24 个特征中,对最不重要的特征进行修剪,在集合上递归进行修剪时重复这个过程,将此过程进行至最终达到所需特征的数量才停止,由交叉验证实验结果中所获取的最佳特征数量为19,交叉验证选择特征数量如图3所示.

图3 RFE最佳特征数量
最终选取最佳特征子集,具体如表2所示.

表2 特征子集

续表
2.3 构建响应变量
为了分类预测高收益的率股票标的,我们从2017年4月23日到2021年2月21日按周频获取193周沪深300的相关因子数据,将下周的因子收益率最高的前20%股票归为1类,将收益率最低的前20%股票归为0类,删除其他样本——也就是将样本数据转换为一个二分类的数据集.
3 模型构建与结果分析
3.1 模型构建
基于上述原理,我们通过baostock接口获取数据,并对获取的股票数据进行数据预处理、特征筛选和标签提取、训练模型等.其中训练集是用随机抽取75%的股票数据组成,测试集则是用随机抽取25%的数据组成.构建模型来预测股票收益率的总体流程图如图4所示.

图4 建模过程流程图
3.2 结果分析
本文研究的问题属于二分类问题,周频收益率排名前20%的股票标签为1,收益率排名后20%的股票标签为0.因此,我们采用分类模型常用性能评价指标来评价模型的分类性能,包括准确率、精确率、召回率、F1值以及AUC值.针对沪深300的股票预测问题,我们构造了利用递归特征消除法结合Stacking 集成学习以及传统的随机森林、支持向量机和逻辑回归等4个分类学习模型.模型的参数均采用GridsearchCV-3来进行寻参,其性能指标结果分别如表3和表4所示.

表3 基于训练集的模型性能结果比对

表4 基于测试集的模型性能结果比对
由表中数据可见,逻辑回归、支持向量机和随机森林这三个传统单模型的效果都不如RFE_Stacking集成学习模型.在测试集中,RFE_Stacking集成学习模型的性能比逻辑回归、支持向量机、随机森林模型都高,具有更好的预测性能,其准确率达到 60.21%,精确率为59.87%,召回率为62.65%,F1值为61.23%,AUC值为0.644 7.在训练集中,随机森林的模型性能最好,其次是RFE_Stacking集成学习模型,但结合测试集结果可知,随机森林容易过拟合,稳定性较低.总的来说,RFE_Stacking集成学习模型具有更好的预测性能和稳定性.
4 总结
本文基于递归特征消除法和Stacking集成学习模型去预测沪深300成分股的收益率,同时与传统的逻辑回归、支持向量机、随机森林模型进行对比分析,得出以下结论:
(1)RFE_Stacking集成学习模型的准确率达到60.21%,精确率为59.87%,召回率为62.65%,F1值为61.23%,AUC值为0.644 7均高于50%,这表明该模型的预测结果优于随机测试,并不遵循随机漫步理论.
(2)RFE_Stacking集成学习模型与传统的逻辑回归、支持向量机、随机森林模型进行比较.在训练集中,随机森林模型性能最好,其次为RFE_Stacking集成学习模型;在测试集中,RFE_Stacking集成学习模型性能最好,其次是支持向量机模型.由训练集和测试集的结果可知,RFE_Stacking集成学习模型性能好,稳定性高;随机森林和支持向量机模型容易过拟合,稳定性差;逻辑回归模型性能较差.
以上两点说明基于递归特征消除法和Stacking集成学习的模型能有效地预测股票的收益率,为广大投资者提供可行的投资策略.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
