
DSCE-GEP算法在PM2.5浓度预测中的应用
2021-11-01 13:15王超学贾晓莉孙嘉诚
计算机测量与控制 2021年10期
王超学, 贾晓莉,孙嘉诚
(西安建筑科技大学 信息与控制工程学院, 西安 710055)
0 引言
近年来,雾霾已成为一种频繁出现的天气,对人们生产生活产生了很大影响。医学期刊公布的研究表明,2015年的大气污染事件已经在全世界范围内造成了约640万名患者死亡,其中约420万名患者由于户外大气污染罹难,2017年刚开始,雾霾就已经席卷了中国的大部分地区[1]。人们对于空气悬浮物PM10和PM2.5的污染表现出空前未有的忧虑和关注,已有的研究结论表示,PM10和PM2.5是当前对公众健康造成危害的主要污染物。尤其颗粒物(PM2.5)由于体积小,可黏附于深呼吸道,通过穿透肺细胞影响血液循环,从而影响人类健康[2-3]。研究表明,PM2.5浓度的上升将使人们增加患各种呼吸道疾病的风险[4]。因此,对PM2.5浓度的准确预测,不仅对于降低患病风险和保护日常健康都具有重要意义,而且可以为PM2.5浓度的防治提供依据。
基因表达式编程算法[5](GEP,gene expression programming)是Ferreira受基因学中开放阅读框的启发提出的一种新型的智能进化算法,是对遗传算法和遗传编程的融合与升华。它吸取了遗传算法(GA)的编码特点和遗传编程(GP)的树形特征,同时又将个体的基因型和表现型相分离。它的优点在于在不了解事物内部机理、只有实验数据的情况下,依靠它的搜索和进化能力,找出最符合建模数据的表达式。目前已经成功应用于软件可靠性[6]、气象露点[7]、函数发现[8]、能源损耗[9]、建筑[10]等领域的预测建模中。该算法不仅具有强大的模型学习能力,而且还可以得到显式的函数关系式。本文基于GEP算法对西安地区的PM2.5浓度进行预测,实验表明不仅预测精度高,而且可以得到PM2.5浓度与各影响因素间的函数关系。
1 相关工作
随着人工智能技术的快速发展,许多学者采用基于神经网络的相关算法进行PM2.5浓度相关的预测。谢劭峰等[11]利用鲸鱼优化算法(WOA)以及狼群算法(WPA)混合优化BP神经网络的权值和阈值,构建WPA-WOA-BP神经网络模型,实验结果表明预测稳定性高且优于BP网络。王勇等[12]利用LSTM构建融合大气污染物、GNSS水汽和风速的PM2.5浓度预测模型,结果表明该模型预测精度较好。段大高等[13]提出LSTM预测模型,能较准确地预测未来5小时的PM2.5浓度。Y.B.Sun等[14]提出了一种深度神经网络模型(DNN),可以提高PM2.5浓度的预测精度。赵文芳等[15]提出卷积神经网络和长短时记忆相结合的预测方法,能有效提高PM2.5浓度未来24 h预测精度,并具有较高的泛化能力。陈成等[15]采用多示例遗传神经网络预测室内PM2.5浓度,其结果优于线性回归、支持向量回归、随机森林等方法。郑国威等[16]针对 PM2.5 浓度变化的非线性、时变性等特点,建立的基于支持向量机-小波神经网络的组合预测模型,其预测结果优于支持向量机单一模型。Z.G.Shang等[17]针对每小时PM2.5浓度的多种变化模式采用分类回归树和极限学习机的集成模型(CART-EELM)预测未来一小时的PM2.5浓度,提高了处理多种PM2.5变化模式的能力。T.Y.Li 等[18]提出卷积神经网络和长短期记忆神经网络组合模型(CNN-LSTM),通过单变量CNN-LSTM模型和多变量CNN-LSTM模型对比,证明了多变量CNN- LSTM模型预测效果更好。
综上所述,神经网络算法已经是PM2.5浓度预测的热点方法,但是它并不能得到显式的函数表达式。基因表达式编程是受基因学中DNA蛋白质系统提出的一种新型的智能优化算法。GEP不但有和神经网络算法一样强大的泛函学习能力,而且可以得到显式的数学模型。
刘小生等[19]采用GEP算法对北京地区的PM2.5浓度进行逐日预测,结果发现其预测精度高于灰色理论、BP神经网络。S.Samadianfard等[20]采用GEP算法对o3浓度进行预测,结果发现GEP在预测o3浓度上是一个有前景的算法。但是传统GEP算法存在着收敛速度慢,容易早熟等问题,本文采用模拟人类进化的基因表达式编程算法(DSCE-GEP, double system co-evolutionary gene expression programming),通过人工干预与自然进化协同来提高收敛速度和全局寻优能力。目前DSCE-GEP已经成功应用于函数发现问题、小麦蚜虫预测问题中[21]。
本文探索双系统协同进化基因表达式编程算法在PM2.5浓度预测中的研究。以西安市PM2.5浓度预测为案例进行逐日预测模拟,以拟合度(R2)、平均绝对误差(MAE)和均方根误差(RMSE)作为模型预测评价指标。实验中通过与传统GEP算法、文献中分类回归树与极限学习机组合模型(CART-EELM)和卷积神经网络与长短期记忆神经网络组合模型(CNN-LSTM)对比证明DSCE-GEP预测模型的有效性和先进性。
2 基于DSCE-GEP的PM2.5浓度预测算法
文章采用双系统协同进化DSCE-GEP算法,该算法模拟人类进化思想引入人工干预操作与自然进化协同进化进行。人工干预由两部分组成,个体干预和种群干预。
2.1 自然进化系统
自然进化系统和传统基因表达式编程算法进化操作相同,包括变异、转座、重组操作。
变异:由于GEP算法的编码特性,根据设定的变异概率在种群中随机选择位置改变其原来的符号,按照GEP的变异法则进行变异运算。
转座:转座又称插串,是GEP算法中特有的遗传算子,其中转座元素为染色体的基因片段。在GEP算法中,根据插入位置的不同分为IS转座、RIS转座和基因转座。
IS转座:起始位置上是函数或终结点的短片段(IS元素)转座到基因的头部中除根部以外的任何位置,IS元素为种群中随机选取的基因片段。
RIS转座:和IS转座的操作类似,转座片段的选取以及转座目标位置不同。转座的片段的起始位应是基因头部中的一个元素,转座的目标位置应在基因的首位。
基因转座:把个体中的某个基因转座至个体的首位作为第一个基因。
重组:又名交叉。根据基因片段不同的截取点和截取方式分为单点、两点和基因重组。
单点重组:在当代种群随机选择两个个体,然后选择同一位置将个体截断,两个个体交换截断点之后的基因片段形成两个新的个体。
两点重组:在当代种群中随机选取两个个体,接着任意选取两个基因位置,将个体切断。两个个体相互交换切断点之间的基因片段,形成两个新的个体。
基因重组:父代种群中随机选取两个染色体中,然后随机选择某一个基因进行整个基因相互交换,形成两个新的子代染色体,形成的两个子代染色体含有来自两个父体的基因。
2.2 人工干预系统
2.2.1 个体干预
个体干预通过去掉种群中的劣质基因,增加种群中的优质基因来提高算法的进化速度以及解的质量。个体干预由“去劣”和“增优”两部分组成。“去劣”删掉PM2.5浓度与影响因素错误的函数表达;“增优”增加与PM2.5浓度相关度高的函数和影响因素在染色体中的表达。具体操作如下:
去劣:对种群中非法表达包含的劣质基因位,如使得除数为0、对数函数真数为0、二次根号下小于0等使得表达式无意义的基因位,通过随机选择改变相应位置的基因使其成为可行解。
增优:保存每-代种群中较优的m个个体作为优质基因库。在“去劣”操作完成后,根据增优概率,对当前种群的第j个个体的s位置到t位置采用优质基因库中的个体通过随机选择选中的第i个个体中从s位置到t位置的基因片段[s:t]移植替换,形成新个体k。并评价k的适应度,如果适应度大于原个体j的适应度,则用新个体k替换原个体j,否则保持原个体j不变。
2.2.2 种群干预
种群干预的目的是增加种群遗传信息多样性,在算法进化过程中,通过自然选择、优胜劣汰使得种群多样性减少,即基因种类减少,使得算法表达过早收敛,陷入局部最优。因此算法通过种群干预来增加种群遗传信息的多样性,以提高最优解的质量。种群干预使得DSCE-GEP算法能在较大范围的函数集中更准确地表达PM2.5浓度和各影响因素之间的关系。
本文选取信息熵作为种群遗传信息是否丰富的评判准则,依据设定信息熵值评判当前种群遗传信息是否丰富。如果当前种群信息熵值大于或等于设定值则当前种群不变;小于设定值则对进行干预操作。具体操作如下:
把种群根据适应度从大到小排序,对于倒数a个个体,即适应度较低的a个个体,采用镜像个体替换;对于倒数第a个到倒数第a+b个个体,即适应度更低的b个个体,采用随机个体替换形成新种群。
1)镜像个体:函数符集F={+、-、*、/、sqrt、x2、exp、cos、sin、ln、lg、~(以10为底的指数)abs、C(常数)},镜像函数符集mr_F={-、+、/、*、x2、sqrt、ln、sin、cos、exp,~,log、C、abs},对需要镜像替换的个体遍历,如果第i位基因为F中第j个元素,则替换后个体第i位基因为mr_F中第j个元素。依据上述规则操作遍历完个体所有基因位后形成新个体。
2)随机个体:和初始化生成个体规则相同。
2.3 DSCE-GEP算法具体步骤
算法流程如图1所示。
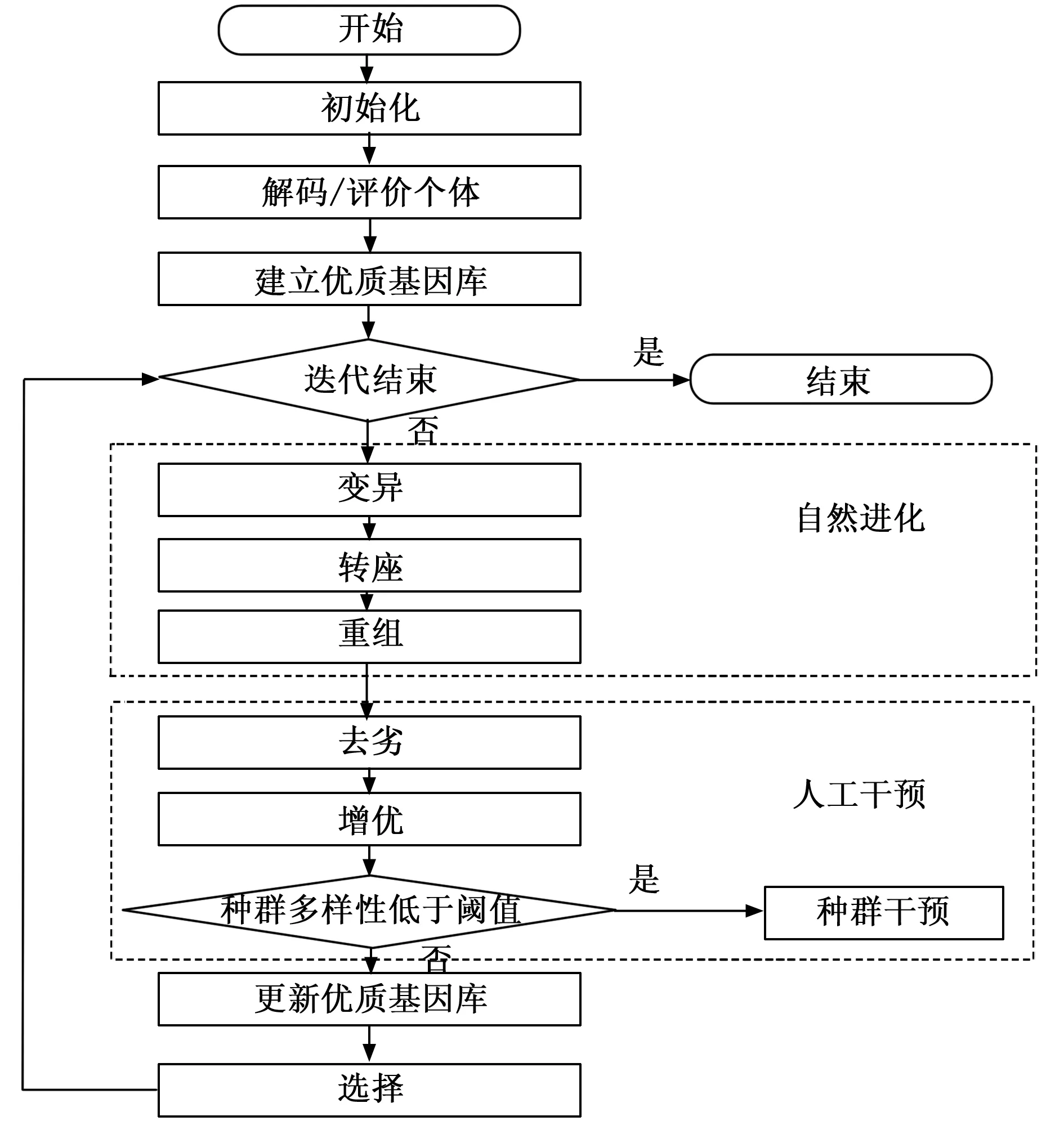
图1 DSCE-GEP流程图
步骤1:始化参数:确定种群规模、头部长度、尾部长度、基因个数、函数集、终点集、遗传概率等参数。
步骤2:码/评价个体:针对每个染色体,根据适应度求解公式计算其适应度。
步骤3:建立优质基因库:选出种群中适应度较大的m个个体作为优质基因库成员。
步骤4:判断是否满足终止条件:判断是否存在个体适应度达到最大值或进化代数达到最大值,如果是,则结束;否则,进入下一步。
步骤5:遗传操作:
1)变异:根据变异概率随机选择变异个体进行变异操作。
2)转座(IS RIS 基因):根据不同的转座位置分为IS、RIS、基因转座,依据转座概率随机选择个体进行相应的转座操作。
3)重组(单点两点基因):根据不同基因片段的组合分为单点、两点、基因重组,依据重组概率随机选择个体进行相应的重组操作。
步骤6:人工干预操作
1)个体干预:(1)去劣,对种群个体遍历,对于造成不可行解的基因通过随机选择替换使其成为可行解;(2)增优,对于适应度较低的个体,通过优质基因库中的优质基因片段替换适应度较低个体相应位置的基因片段。
2)种群干预:根据当前种群的信息熵值判断是否需要种群干预。如果当前种群信息熵值小于理想种群信息熵值就进行种群干预,否则不干预。
步骤7:更新优质基因库:合并当前优质基因库和当前种群的所有个体,从中选出适应度较高的前m个个体作为新的优质基因库成员。
步骤8:选择:采用轮盘赌选择策略进行选择操作形成新种群并进入下一次迭代。
3 实验
本文设计了3个对比实验来验证DSCE-GEP算法在PM2.5浓度预测中的有效性和先进性。实验程序用python实现,实验环境为Intel i5处理器、16 GB内存、Windows10操作系统。
3.1 数据集
本文采用的空气质量数据(PM2.5,PM10,SO2,NO2,CO,O3)与气象数据(温度,湿度,风向,风速,气压,露点),通过中国环境监测网站获取的2017.1.1~2018.12.31的西安地区每天监测数据,所采集的数据为每日平均值。70%数据作为训练集,30%数据作为测试集。
3.2 适应度函数
文中采用拟合度R2=1-SSE/SST作为适应度函数,即统计学中的复相关系数。其中,SSE计算如公式(1)所示,SST计算如公式(2)所示:
(1)
(2)

3.3 预测精度评价指标
本文采用拟合度(R2)、均方根误差(RMSE)、平均绝对误差(MAE)3个指标来对预测结果进行评价。均方根误差(RMSE)计算如公式(3)所示,平均绝对误差(MAE)计算如公式(4)所示:
(3)
(4)

3.4 初始化参数设定
DSCE-GEP算法参数如表1所示。

表1 初始化参数设置
3.5 对比实验与结论
3.5.1 GEP、DSCE-GEP预测精度对比
1)预测精度对比:GEP算法、DSCE-GEP算法算法预测曲线分别如图2、图3所示。拟合度、均方根误差、平均绝对误差比较如表2所示。

图2 GEP预测曲线
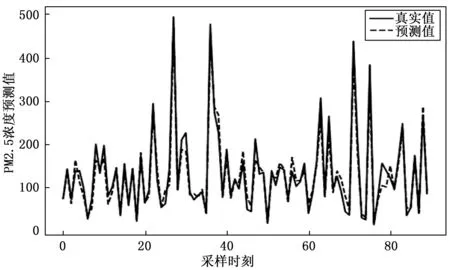
图3 DSCE-GEP预测曲线
从图2、图3可看出GEP算法、DSCE-GEP算法预测效果都比较好,由表2得出DSCE-GEP较GEP拟合度提高0.03,均方根误差降低4.29,平均绝对误差降低5.47,较传统GEP提高了预测精度,证明了KDSCE-GEP的有效性。

表2 DSCE-GEP和GEP性能比较
2)GEP、DSCE-GEP进化速度对比:GEP算法、DSCE-GEP算法进化曲线分别如图4、图5所示。
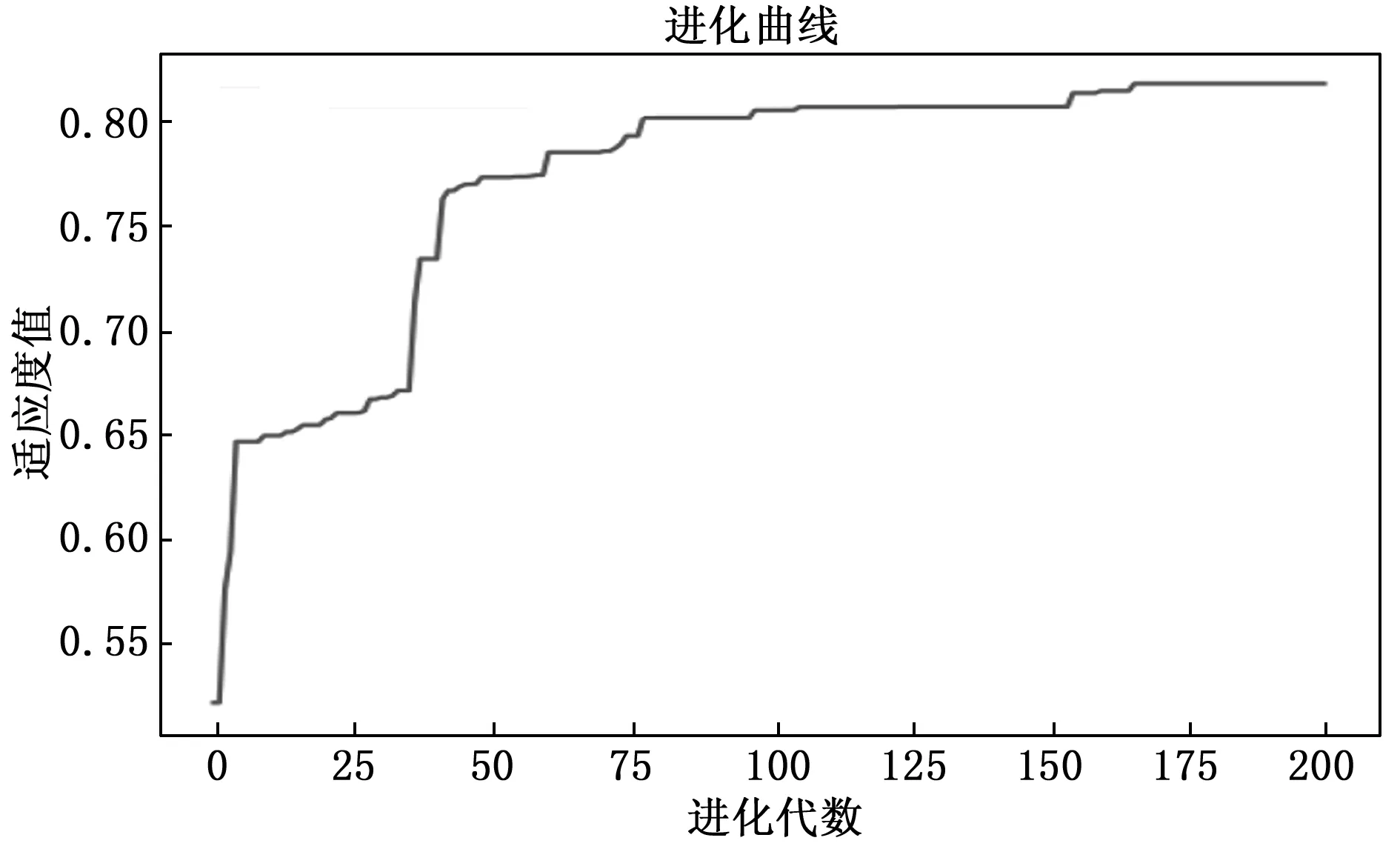
图4 GEP最优进化曲线

图5 DSCE-GEP最优进化曲线
通过图4、图5进化曲线对比发现,GEP在175代找到最优解,DSCE-GEP在100代左右找到最优解DSCE-GEP较GEP提高了进化速度,DSCE-GEP通过个体干预及种群干预,缩小了解的搜索空间,提高了进化速度。通过实验对比DSCE-GEP算法能有效提高收敛速度和预测精度。
3.5.2 DSCE-GEP、CART-EEL和CNN-LSTM对比实验
1)DSCE-GEP算法的显式表达式:
y= cos10cos((sinx11 *x11)-x1+cos10x7+2x6-
(5)
通过实验得到DSCE-GEP算法的预测模型为公式(5)。其中y为当前一天PM2.5浓度,x1,x5,x6,x7,x8,x10,x11分别为前一天SO2,O3,温度,湿度,风向,露点,PM2.5。通过实验模型可以看出,西安地区当天PM2.5浓度主要与前一天SO2,O3,温度,湿度,风向,露点,PM2.5相关,具体关系体现在公式(5)中。
2)DSCE-GEP算法、CART-EELM模型、CNN-LSTM模型预测精度对比
DSCE-GEP算法与比较分类回归树和极限学习机的组合模型和CNN-LSTM模型,证明其先进性,结果表3所示。
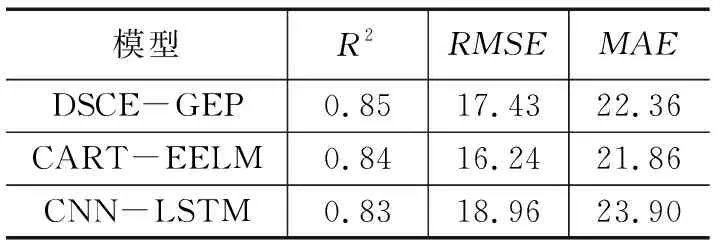
表3 DSCE-GEP和CART-EELM、 CNN- LSTM预测结果对比
通过表3发现,DSCE-GEP算法较CART-EELM拟合度高了0.01,均方根误差和平均绝对误差稍高于CART-EELM;较CNN-LSTM拟合度高了0.01,均方根误差低了1.53,平均绝对误差低了1.54。拟合度均优于其他两种模型,证明了DSCE-GEP算法在PM2.5浓度预测中的竞争力与先进性。CART-EELM和CNN-LSTM分别都是基于神经网络的模型,最终得出的模型为参数矩阵,无法看到PM2.5浓度与各影响因素之间的关系,而DSCE-GEP算法最终可以得到PM2.5浓度与其影响因素之间的显式函数关系,可以明确表达PM2.5浓度与各影响因素之间的关系。
3.5.3 实验结论
经过上述实验分析发现,DSCE-GEP算法不仅较传统GEP算法、分类回归树和极限学习机组合算法(CART-EELM)以及卷积神经网络和长短期记忆神经网络算法(CNN-LSTM)在西安地区逐日的 PM2.5浓度中性能较优,拟合度均高于其他3种模型,而且得到了PM2.5浓度预测的显式函数关系。证明DSCE-GEP算法在PM2.5浓度预测中的有效性与竞争力,对于准确的控制PM2.5浓度具有重要意义。
4 结束语
通过对西安地区空气质量数据进行分析,根据过去一天的空气质量数据及气象数据预测当天的PM2.5浓度,利用基于双系统协同进化算法得到预测模型,不仅可以有较高的预测精度,而且可以明确地看出各影响因素与PM2.5浓度之间的关系。未来还可以把DSCE-GEP算法应用于其他智能预测领域中。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2022年15期)2022-09-20
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
中学生物学(2018年8期)2018-03-01
软件(2017年6期)2017-09-23
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
中学生物学(2008年6期)2008-08-29
