
数据挖掘在教学诊断与改进中的智能算法的应用研究
2021-11-01 01:22范宏宇杨海卉
安徽职业技术学院学报 2021年3期
何 晶,范宏宇,杨海卉
(安徽机电职业技术学院 教务处,安徽 芜湖 241002)
学校内部质量保证体系诊断与改进工作是学校全局性、系统性、长期性的一项工作。近几年,教育部就高职院校的教学诊断和改进提出了新策略,旨在保证高职院校教学质量的提升,因此,依托“高等职业院校人才培养工作状态数据管理系统”平台,实现学校专业群与行业、产业及企业岗位进行对接,专业人才培养与企业岗位技能要求相融合,课程体系设置对接国家教学标准,并进一步丰富信息化教学资源,在师资队伍建设中加强校企合作,引入企业工程师,实现全员质量保证体系建设,努力提高人才培养质量,已成必然趋势。随着数据挖掘及大数据技术的发展,也为高职院校教学诊改工作提供了更多的可能性,数据挖掘是实现高职院校教学诊断与改进人才培养要素全覆盖、提高诊改结果的实时性与真实性、进一步健全内部质量保证体系的重要手段。充分利用状态数据做好人才培养工作的趋势预测、预警、风险防范等方面工作,对日常管理和教学质量过程进行监控,进而形成常态化的信息诊断分析与改进反馈机制。
1 数据挖掘在教学诊断与改进中的智能推荐中的应用
数据挖掘是一个目标和数据不断优化的过程,数据挖掘是能够从海量数据中挖掘出有价值的潜在信息,数据挖掘过程如图1所示。

图1 数据挖掘过程
数据抽取阶段就是根据源数据结构的特点进行相关数据的抽取工作。在数据预处理阶段,就是将数据进行再加工的一个过程。数据经过再加工,能够使其得到一种标准格式,以便后续进行的抽取工作。数据预处理的主要方式包括数据清洗和数据选择。
所谓数据清洗就是将一些不完整、不一致、不精确以及重复的数据进行筛选清洗工作,以备后续能够选择出满足要求的数据形式。在数据挖掘和知识库阶段,就是将规格化的数据进行抽象分层,将这些数据存储在知识库当中,以便能够更加有效的实现数据的分析。
2 基于决策树的数据挖掘
2.1 决策树ID 3算法实现系统
在解决分类问题时,使用效果较好、范围较广的算法主要是决策树算法(简称“ID3算法”)。ID3算法是由Quinlan提出的,它是信息增益自上而下的归纳算法,它主要是用来解决离散化数据值的问题,并对错误数据有很好的健壮性。其主要的特点是,通过“分而治之”的策略,生成决策树。将整个训练样本数据集被分割成一个个互斥的子集,在决策树的每一个节点上,使用最大化的数据集的信息增益量,作为启发式来决定选择一种属性进行决策树展开运算。
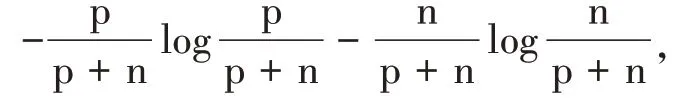
应用ID3算法,选择Gain(A)的最大属性值A作为根节点。对A中的不同取值对应E中的Y个子集E递归,调用上述过程,生成A的子节点为B,B...B。
在挖掘数据平台中,各个记载数据量庞大,相对应的属性数值比较多。ID3算法对于离散型属性效果较好,对于连续型属性难以处理,一般需要通过预处理将连续型属性离散化,才可以对其进行处理。并且ID3算法对于错误类别的样本所产生的噪声数据比较敏感,容易产生过度拟合的现象。ID3算法针对所有属性值都确定的情况下适用,但是在现实情况中经常会出现一些数值空白或者丢失的情况,此时应用ID3算法,算法就会自动跳过空白数据,在进行数据挖掘时就不能够很好地建立完整的模型,不能正确分析或者预测,而且ID3算法往往会选取数值较多的属性作为测试属性,这样也会影响决策树的生成效率。
2.2 决策树ID 3的算法改进
决策树ID3算法在挖掘数据平台的应用中仍然存在一些问题,下面就这些问题提出相应优化方法。
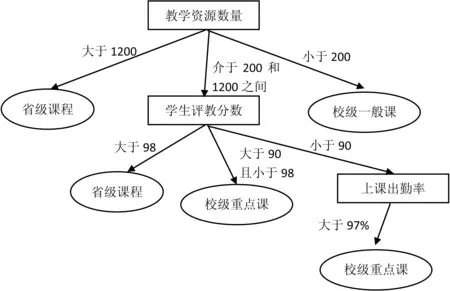
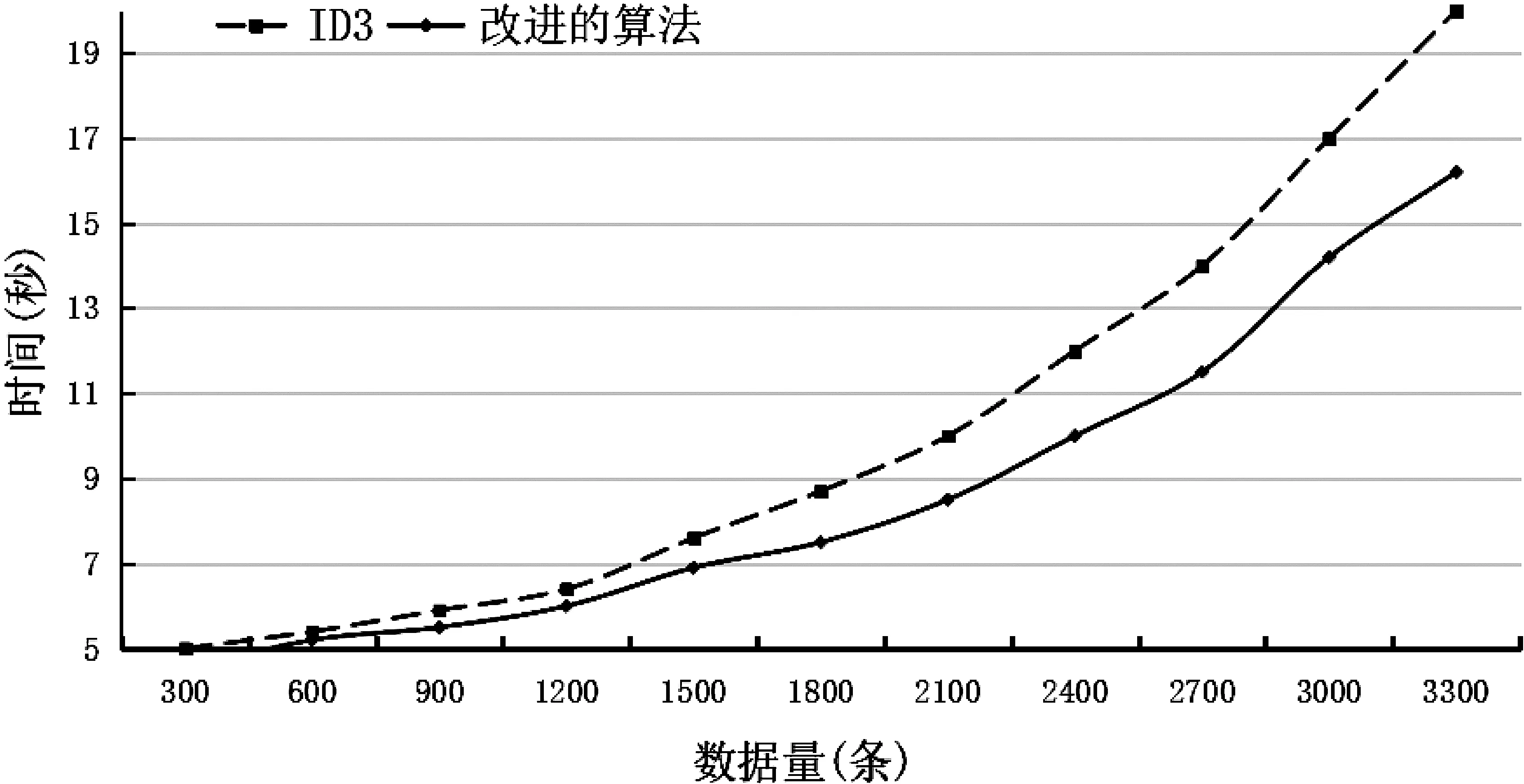
问题1:对于属性值缺失或者空白情况处理,对训练集中其他完整的实例进行选择,在构建决策树之前,可以选择较优的数据进行填充。填充过程如下:训练集中N个属性集合中的其中一个属性A,其中一个实例S在属性A上出现数据缺失,令M=N-1,在训练集中找出其余M个属性值和实例S对应一致的实例,组成实例集合S’,如果集合不为空,则计算S’中A的不同取值比例,取最大值进行填充,如果集合为空,则令M=M-1,如果M 问题2:ID3算法要经过多次对数运算,影响决策树生成效率。这样可以应用简化熵的计算方法,对信息增益公式的对数运算进行转换,找到一种新方法进行属性选择,缩短决策树的生成时间。计算方式如下: 问题3:ID3算法在进行决策树生成时选取的属性往往是取值较多的属性,整个数据不确定程度很高,为了提高数据确定程度,选择在选取属性时为信息熵添加权值,这样就可以对每一个属性的不确定程度进行平衡,数据的分布也会更加合理。为保障决策树的生成效率,在每个属性的简化熵中,我们也可以添加权值,这里的权值指的就是每个属性在数据集中的取值个数,然后做权值乘以简化熵的运算,就能够得到信息熵的取值结果,而这个结果是由权值所决定的,也可以叫做加权简化熵。进一步地,我们对加权简化熵做大小的比较,就能够选择出最优的属性,它可以作为决策树的分裂节点。 本系统采集了安徽机电职业技术学院三年的课程建设情况,包括课程标准、课程建设年度计划、课程建设实施方案、课程教学目标支撑专业培养目标、课程培养目标对接职业岗位、教学内容是否符合课程教学目标、教学内容是否任务驱动、是否对接技能证书、混合式教学学时占总课时比例等属性。预测目标为:该课程已经达到的“等级”。对于课程的等级分为:国家级课程、省级课程、校级重点课程和校级一般课程四类,数据来源为安徽机电职业技术学院“校情大数据”软件系统中2018年-2020年采集的数据,共计3351条记录。 采集的数据存在连续属性、数据缺失、非法数据、不一致等情况,需要对数据进行预处理。数据预处理的主要方法有:针对连续的属性进行离散化处理,例如属性“教学资源数量”值为连续型数据,根据需要将数据进行了离散化处理,将区间[0,50)设置为1,[50,100)设置为2,以此类推。数据缺失的属性,通过数据类型的使用均值来填充,离散类型以个数最多的值进行填充。例如:部分课程“是否有课程建设实施方案”值是否缺失,经过统计,此属性最多值为“有”,则将缺失的值设置为“有”。对于不一致的数据取值,一般通过字符串的规范化进行处理,将属性取值进行统一。 本系统根据课程采集平台收集的数据,选用了其中45个属性,按照机器学习中测试集与训练集比率常用的2-8原则,将数据集的80%作为训练集,20%作为测试集。随机抽取原始数据中的2680条记录作为训练数据集,其余的671条记录作为测试数据集。 为验证改进算法的有效性,对测试数据进行分析。如表1所示,相对于ID3算法,改进的算法在准确率和检出率都有所上升,在误检率上有所下降。所以本文提出的改进算法是有效的。 表1 两种算法结果对比 图2为改进的算法针对数据集挖掘的决策树的前三层结果,由图2可见,在数据集的所有属性中信息增益高的属性为教学资源数量、学生评教和上课出勤率。授课教师通过针对性的提升课程的这些属性,以提高教学质量。 图2 基于改进算法的决策树 图3给出了在数据集上不同数量数据的运行时间比较。由图3可知,改进后的算法运行时间一直低于ID3算法,并且随着数据量的增加,改进后算法所节约的时间也越多。 图3 数据集上不同数量数据算法运算时间 由以上试验结果可得,改进的算法总体优于原算法,检测的准确率和检测率都有所提高,误检率有所下降。改进后的算法使用了简化的信息熵的运算,将复杂的对数运算改进后四则算术运算,所以算法运行的更快,运行速度提高了20%,更适合大量数据的挖掘工作。 本文通过对基于ID3算法的数据挖掘平台进行研究分析,针对ID3算法在智能推荐系统中的应用的不足之处提出改进方案,改进后的算法很好的提高了算法的准确率以及减少了算法所用时间,最大化的提升了自我诊断改进的准确性和及时性。


3 实验结果
3.1 数据准备
3.2 挖掘结果

4 结语
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
科学与信息化(2019年28期)2019-10-21
学苑创造·B版(2019年4期)2019-05-09
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
科学与财富(2016年32期)2017-03-04
电子技术与软件工程(2016年24期)2017-02-23
决策与信息·下旬刊(2013年1期)2013-03-11
