
应对灾难风险的多虚拟机快速协同撤离机制研究
2021-10-31 06:20鲍宁海李国平岳渤涵
电子与信息学报 2021年10期
鲍宁海 李国平 冉 琴 岳渤涵
(重庆邮电大学通信与信息工程学院 重庆 400065)
1 引言
近年来,网络虚拟化技术的不断发展和应用打破了传统互联网的僵化结构,为各类新兴业务的迅速推广提供了极大的便利。通过对计算、存储和带宽资源的抽象、汇聚与分配,底层的物理网络资源可以在不同的互联网业务提供商之间灵活共享,从而使众多基于虚拟网的应用得以广泛部署[1]。
虚拟网(Virtual Network,VN)通常是一定数量的虚拟节点和虚拟链路的集合。其中,每个虚拟节点以虚拟机的形式映射于一个物理节点中,实现计算和存储资源的汇聚,而每条虚拟链路映射于两个虚拟节点间的物理通路上,提供虚拟机之间的连通[2]。由于虚拟网各组件间的密切关联性,任何虚拟节点或虚拟链路的损毁都可能造成大量的业务中断和数据丢失,因此,虚拟网的生存性将成为影响未来网络运行和业务发展的重要问题。
本文针对大规模灾难事件(如地震、海啸等)对多个物理网络节点及相关链路造成的严重威胁,重点研究同一虚拟网中多个风险虚拟机的快速协同撤离机制,以减少单个虚拟网的撤离完成时长和损毁风险。
虚拟网生存性策略可分为网络组件抗毁和在线业务抗毁两类。前者可以采用虚拟网备份映射或重构来实现[3,4],后者主要通过虚拟机在线迁移来完成[5]。而虚拟机的在线迁移技术又主要分为预复制迁移和后复制迁移两类,可广泛应用于在线系统维护、负载均衡、资源优化、能耗管理等领域[6]。
预复制迁移是先将原虚拟机的磁盘数据和主要内存页复制到目的虚拟机,再以迭代方式将原虚拟机产生的内存脏页(发生变化的内存信息)传递到目的虚拟机直到剩余脏页量或迭代次数满足要求,最后通过宕机切换将原虚拟机CPU状态和剩余脏页复制到目的虚拟机并启动目的虚拟机。后复制迁移则是首先通过宕机切换将原虚拟机CPU状态和少量必要内存页复制到目的虚拟机并启动目的虚拟机,然后再将剩余的内存页和磁盘数据主动复制并推送至目的虚拟机。
在虚拟机迁移技术的研究中,宕机时长和总迁移时长通常被用作衡量虚拟机在线迁移性能和效率的重要参考指标[7]。为减小虚拟机的预复制迁移时长,文献[8]通过预测迭代周期内的脏页数量,对迁移带宽进行动态预留和调整。文献[9]根据内存脏码率对迁移带宽和预复制迭代次数进行优化,提高网络带宽利用率,减小总迁移时长。文献[10]通过虚拟机迁移次序和迁移带宽的调度与优化,最小化预复制迁移时长。文献[11]采用速率感知的带宽共享传输满足预复制迁移的宕机时长和总迁移时长约束。文献[12]提出一种增强型距离自适应预复制迁移带宽分配算法,以降低迁移阻塞率。
为有效降低在线迁移过程中的传输负载,文献[13]针对后复制迁移,利用远程失效页面过滤技术提高迁移内容的有效性。文献[14]提出一种分散集中式后复制迁移策略,利用多个中间节点作为缓存代理,解决目标主机接收速率过慢的问题。文献[15]提出一种反向增量检查机制,保障后复制迁移中断后虚拟机的快速恢复,避免宕机时长和总迁移时长的恶化。
针对关联性多虚拟机迁移问题,文献[16]通过并行预复制迁移策略优化迁移带宽分配,获得低于串行预复制迁移的平均宕机时长、总迁移时长,以及迁移阻塞率。文献[17]根据关联虚拟机业务流量的相关性确定迁移次序,减小预复制迁移的平均宕机时长。文献[18]通过多虚拟机迁移带宽和预复制迭代次数的联合优化,对虚拟机宕机时长和总迁移时长进行平衡和折中。
显然,在现有研究工作中,预复制迁移技术受到了更多的关注[8–12,16–18]。在预复制迁移过程中,由于原虚拟机始终保有CPU状态,可在迁移中断时迅速恢复,能为在线迁移提供更高的可靠性。然而,原虚拟机产生的大量脏页将不可避免地增加迁移负载,因此,基于预复制迁移的研究工作大多集中在脏页迭代周期规划和网络带宽资源优化上,以便在宕机时长与总迁移时长上获得较好的折中[8–12]。而后复制迁移技术由于避免了大量脏页的产生和传递,迁移负载显著减小,从而获得更短的总迁移时长,因此,基于后复制迁移的研究工作主要集中在对内存页的压缩、标识,以及网络资源的有效利用上,以进一步提高在线迁移的效率或可靠性[13–15]。
从以上分析可以看出,相对于预复制迁移,后复制迁移更适合虚拟机的快速紧急迁移。然而,在大规模灾难风险下,虚拟网快速撤离的关键不是单个虚拟机的迁移完成时间,而是该虚拟网中所有风险虚拟机最终完成迁移的时间。现有关于多虚拟机迁移的研究大多采用预复制迁移技术,主要目标还是通过迭代调度和资源优化解决宕机时长和总迁移时长的平衡问题[16–18],并未就大规模灾难风险场景下的虚拟网生存性问题进行针对性研究。因此,本文基于后复制迁移技术,提出一种应对灾难风险的多虚拟机快速协同撤离机制。
2 问题描述及网络模型
2.1 问题描述
大规模灾难事件可能对通信网基础设施造成严重的破坏,并对映射于灾难风险区内的大量虚拟机及其相关业务构成极大的威胁。如何快速撤离这些风险虚拟机已成为虚拟网抗毁的一个重要问题。特别是,当虚拟网的多个甚至全部虚拟机均处于灾难风险区时,虚拟网的生存性将取决于所有风险虚拟机是否能够实现快速协同撤离,而目前对该问题的研究尚待深入。
针对以上情况,本文假设一次大规模灾难事件导致多个具有地理关联性的物理网络节点(及其邻接链路)陷入灾难风险区。当任何一个虚拟网有一个或多个虚拟机映射于风险物理节点上时,需要对该虚拟网进行快速撤离。虚拟网撤离问题主要包括虚拟网重构和虚拟机在线迁移两个子问题,二者均属于NP-hard问题[2,6]。由于大量虚拟网业务的运行依赖于各虚拟机的协同工作,虚拟网及其业务的生存性将取决于最后一个风险虚拟机的迁移结束时间。因此,本文以减少单个虚拟网的撤离完成时长,降低损毁风险为目标,重点研究同一虚拟网中多个风险虚拟机的快速协同撤离机制。
2.2 网络模型

3 方案描述
为应对大规模灾难风险对虚拟网及其业务造成的严重威胁,本文提出一种多虚拟机快速协同撤离(Multi-virtual-machine Rapid Cooperative Evacuation,MRCE)机制。该机制将虚拟网的撤离过程分为两个阶段,即首先在风险区外对虚拟网进行重构,实现虚拟网的组件抗毁,再通过多虚拟机协同迁移,实现虚拟网的业务抗毁。
3.1 虚拟网重构

在广域网中,节点资源相对于带宽资源更易于升级与扩容,因此,假设每个物理节点中的计算资源和存储资源都是足够的。为在重构虚拟链路长度与虚拟机迁移通路长度上取得平衡,实现网络带宽资源的优化利用,首先建立物理节点代价函数,如式(5)所示。其中,表 示虚拟节点nv到物理节点ns的 最短距离(跳数),表示虚拟网Gv中所有虚拟节点到中物理节点ns的最短距离和。
通过式(5),在风险区域外寻找代价最小的物理节点作为锚点,并将距离锚点H(≤2)跳内的区域划为的节点重构区域。然后,在重构区域内根据最大资源优先原则均衡分配节点资源,即优先将具有最大节点资源需求的虚拟节点映射到具有最大可用节点资源的物理节点上。最后,利用最短路算法在风险区域外重构中的虚拟链路。
3.2 多虚拟机协同迁移
在网络带宽资源有限的情况下,虚拟机的迁移数据量是影响迁移完成时间的重要因素,因此,本文采用后复制迁移技术,避免大量脏页的产生和迭代传输,并假设迁移数据均为总量确定的必要数据,不涉及数据清理、过滤及压缩等问题。
本文中多虚拟机协同迁移的主要目标是减小单个虚拟网的撤离完成时长。在为风险虚拟机建立迁移通路时,过小的迁移带宽将导致该虚拟机的迁移完成时长超长,从而影响整个虚拟网的撤离完成时长。为解决这一问题,首先引入虚拟机基础迁移带宽约束条件,如式(6)所示。其中,Tmax表示虚拟机的最大迁移完成时长门限,τmax表示虚拟机的最大宕机时长,Di表 示风险虚拟机mi的待迁移数据量,Bi表 示mi的迁移带宽。
由于虚拟网的撤离完成时长取决于最后一个风险虚拟机的迁移结束时间,当式(6)中的Bi取最小值时,该虚拟网中各风险虚拟机的迁移完成时长相同,且均为Tmax。然而,在动态变化的网络资源环境下,如果固定采用m in(Bi)作为迁移带宽,严格执行多虚拟机的同步迁移,可能会牺牲网络带宽的资源利用率。因此,通过选择合适的基础迁移带宽,并根据网络资源状态对其进行调整和升级,提高风险虚拟网的撤离效率。为解决可能出现的迁移带宽升级受限的问题,采用多通路策略提高带宽升级的灵活性。同时,为使同一虚拟网中各风险虚拟机的迁移完成时长尽可能一致,还需对各虚拟机的迁移带宽进行协同调整。


3.3 启发式算法
根据以上方案描述,本文设计了相应的MRCE启发式算法,用于实现大规模灾难风险下虚拟网的快速撤离。其中,子算法-1完成虚拟网重构,子算法-2完成多虚拟机协同迁移的初始配置。
(1)MRCE算法
步骤1 将所有风险虚拟网放入集合R,并按其所含风险虚拟机数量升序排列,初始化当前时间tc=0,每个虚拟机已迁移数据量=0,迁移完成时间=∞;
步骤2 如果集合R/=∅,调用子算法-1对R中的每个风险虚拟网进行重构,调用子算法-2为重构虚拟网中的每个风险虚拟机分配迁移通路和带宽,将迁移带宽分配成功的虚拟网移入集合E中,跳转到步骤3,否则,跳转到步骤8;
步骤3 如果集合E/=∅,对E中虚拟网的各风险虚拟机 mi执行后复制迁移,跳转到步骤4,否则,跳转到步骤2;
步骤5 如果该mi为所属虚拟网内第1个完成迁移的虚拟机,根据式(11)计算该虚拟网内其他mi的迁移完成时差并放入集合U,跳转到步骤7,否则,跳转到步骤6;
步骤6 如果该 mi为所属虚拟网内最后一个完成迁移的虚拟机,将该虚拟网从E中删除,跳转到步骤7,否则,跳转到步骤7;
步骤7 更新U中所有的并删除=0的记录,如果U/=∅,将降序排列,依次将相应的虚拟机迁移带宽升级至上限,跳转到步骤2,否则,跳转到步骤2;
步骤8 算法结束。
(2)子算法-1
步骤2 依次为中的虚拟节点按最大节点资源需求优先原则,在节点重构区域内选取具有最大可用资源的物理节点进行重映射;
步骤5 风险虚拟网Gv重构失败,释放已重构的虚拟节点及虚拟链路资源,跳转到步骤6;
步骤6 算法结束。
(3)子算法-2
步骤1 初始化k=1,分别为中的每个风险虚拟机 mi计算一条满足式(6)约束的最短迁移通路,如果成功,跳转到步骤2,否则,跳转到步骤6;
步骤3 如果集合M/=∅,令k=k+1,跳转到步骤4,否则,跳转到步骤6;
步骤4 依次为M中每个mi计算一条最短通路作为增量迁移通路,根据式(9)计算增量带宽如果,将该mi从M中删除,跳转到步骤5,否则,令,跳转到步骤5;
步骤5 如果k <K,跳转到步骤3,否则,跳转到步骤6;
步骤6 算法结束。
根据以上算法步骤分析,MRCE的时间复杂度为O(|Nv|2·|Ns|·log2|Ns|+|Nv|·K·|Ns|·log2|Ns|),其中,Ns与Nv分别表示物理网Gs和虚拟网Gv的最大节点数,K表示单个虚拟机的最大迁移通路数,|Ns|·log2|Ns|为最短路算法的时间复杂度。
4 仿真测试与分析
本文对提出的多虚拟机快速协同撤离算法(MRCE)进行仿真测试,并采用常规后复制迁移算法(Regular Post-Copy Migration,RPCM)和基于自适应带宽升级的后复制迁移算法(Adaptive bandwidth Upgraded Post-copy Migration,AUPM)进行风险虚拟网撤离的性能对比。3种算法均采用相同的虚拟网重构策略,其中,RPCM为每个虚拟机寻找最短迁移通路并分配最大可用迁移带宽,而AUPM在RPCM的基础上,根据网络带宽资源状态,对迁移带宽进行尽力而为的动态升级。
仿真采用的物理网络拓扑包含24个节点和43条链路,如图1所示。假设各物理节点均拥有充足的计算和存储资源,各物理链路的带宽资源均为240 Gbps。图中阴影部分代表3个独立的灾难风险模型,分别包含(3,4,5),(9,12,13)和(16,17,22)3组物理节点及其相邻物理链路。

图1 物理网络拓扑
随机产生90套初始业务模型,每套包含500个虚拟网络,且随机分布(映射)于上述物理网络中。其中,每个虚拟网络随机产生3~5个虚拟节点,任意两个虚拟节点间以0.5的概率建立虚拟链路,虚拟链路带宽在0.5~3 Gbps间随机产生。采用后复制迁移技术对风险虚拟机进行迁移,每个虚拟机的待迁移数据量在5~10 GB间随机产生,宕机时长在0.5~1.5 s间随机产生[9]。
在以上仿真环境中,分别对MRCE,RPCM和AUPM进行仿真测试,性能指标主要包括风险虚拟网的平均撤离完成时长、撤离完成时长标准差,以及撤离完成率。最终仿真结果对3个灾难风险模型和90套随机业务模型取平均。考虑到我国的地震监测系统已具备一定程度的预警能力(十几秒至几十秒的预警时间),但网络组件的损毁时间仍旧难以确定。因此,以10 s为基数设立6个考察周期,分别在算法执行后的10 s,20 s,30 s,40 s,50 s,60 s时间点对以上性能指标进行考察记录。
在MRCE中,虚拟机最大迁移完成时长门限Tmax的选取对网络带宽资源利用率有较大的影响。如果Tmax取值过大,则虚拟机的迁移效率降低,可能造成虚拟网的平均撤离完成时长过大;如果Tmax取值过小,则虚拟机的基础迁移带宽需求较大,可能造成过高的迁移带宽阻塞率。因此,首先考察MRCE在不同Tmax设置下的平均撤离完成时长和迁移带宽阻塞率,并用T10,T20,T30,T40,T50,T60分别代表Tmax取值为10 s,20 s,30 s,40 s,50 s,60 s时MRCE的相应指标。
如图2和图3所示,在10~60 s考察周期内,MRCE的平均撤离完成时长随着Tmax取值的增加不断变大,而其迁移带宽阻塞率却随着Tmax的增加而降低。显然,由式(6)可知,增大Tmax的取值等同于放松对基础迁移带宽的约束,使得虚拟机更容易找到可用的迁移通路。然而,当网络中的带宽资源较为紧张,且碎片化较为严重时,过小的基础迁移带宽会使以 min(Ti)为基准的增量带宽策略变得低效,从而导致虚拟网的撤离完成时长变大。图3数据显示,在此仿真环境下,当Tmax≥40 s时,迁移带宽阻塞率较低,且数值变化明显趋缓,因此在后续的仿真测试中,采用40 s作为MRCE的虚拟机最大迁移完成时长门限。
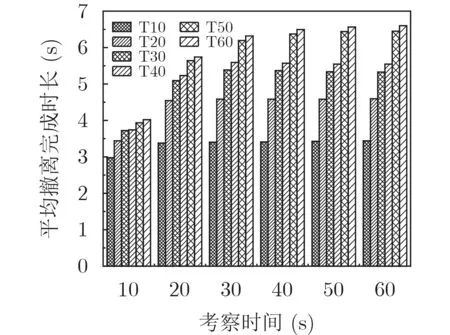
图2 T max对平均撤离完成时长的影响

图3 T max对迁移带宽阻塞率的影响
风险虚拟网平均撤离完成时长如图4所示。在10 s的考察时间点,MRCE和AUPM的平均撤离完成时长均高于RPCM,其原因包括两个方面:其一是在撤离开始的初期,包含风险虚拟机数量最少的虚拟网将被优先撤离,特别是仅包含单个风险虚拟机的虚拟网,能以最小代价尽快脱离风险区。而对此类风险虚拟网来说,MRCE的协同撤离策略和AUPM的自适应升级策略的优势不够突出。其二是在每一个考察时间点,虚拟网的平均撤离完成时长只统计当前已完成撤离的虚拟网,而RPCM在10 s周期内完成撤离的虚拟网数量远小于MRCE和AUPM,且完成撤离的主要是仅包含单一风险虚拟机的虚拟网。从图4中可以发现,在20 s及以后的考察时间点,MRCE的平均撤离完成时长有稍许增加但非常平稳,AUPM的平均撤离完成时长逐渐增长但较缓慢,而RPCM的平均撤离完成时长增长较为迅速。显然,相对于RPCM,AUPM的自适应升级策略能够更好地提高网络带宽资源利用率,缩短风险虚拟机的迁移完成时长,从而在一定程度上缩短风险虚拟网的撤离完成时长。而MRCE的协同撤离策略通过压缩同一虚拟网中风险虚拟机间的迁移完成时差,能够进一步减小各风险虚拟网的撤离完成时长。
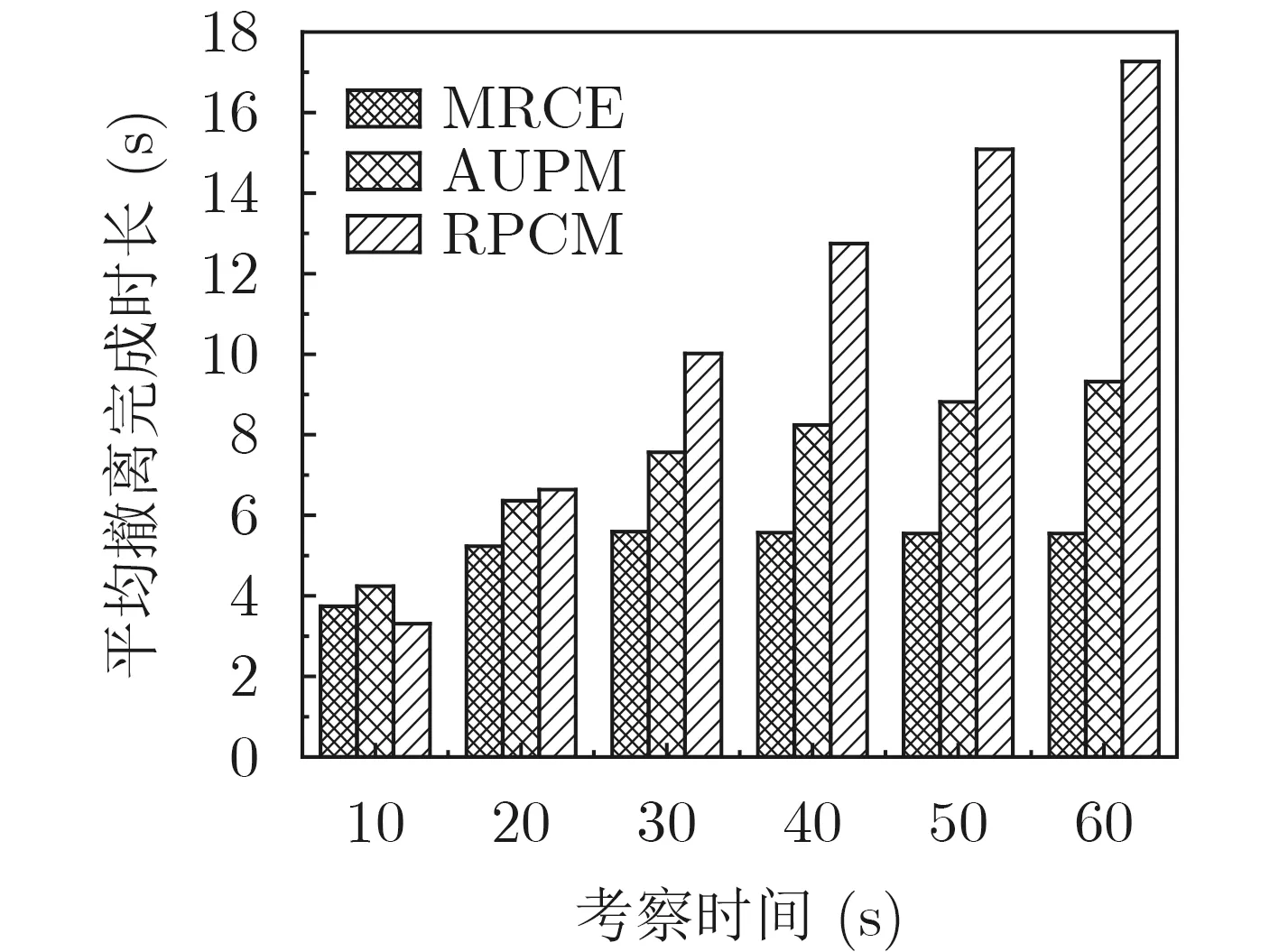
图4 不同考察时间下的平均撤离完成时长
风险虚拟网的撤离完成时长标准差如图5所示。在10 s考察时间点,RPCM的撤离完成时长标准差与MRCE的接近且稍低于AUPM。其原因除了前面提到的RPCM在该考察周期内完成撤离的虚拟网数量少且主要包含单一风险虚拟机以外,另一个原因是在撤离初期,风险区外的网络资源相对较充足,带宽资源碎片化情况不严重,因此,RPCM在此期间完成虚拟网撤离所耗费的时长较短且差距不大。然而,随着包含多风险虚拟机的虚拟网开始大量撤离,以及风险区外网络带宽资源的减少,RPCM的撤离完成时长标准差迅速上升。虽然AUPM可以通过自适应带宽升级提高带宽资源利用率,但对缩短同一虚拟网内不同风险虚拟机的迁移完成时差并无确定性的作用,即迁移带宽升级的结果可能使时差减小,也可能使时差增大。随着风险区外可用带宽资源的逐渐短缺和碎片化,AUPM的自适应带宽升级效率逐渐降低,这使得不同风险虚拟网撤离完成时长的差距逐渐变大。相对于RPCM和AUPM,MRCE通过基础迁移带宽的选取和增量迁移带宽的配置,以及基于虚拟机迁移完成时差的迁移带宽动态升级,能够在不同的网络带宽资源状态下获得较为稳定的撤离完成时长标准差。

图5 不同考察时间下的撤离完成时长标准差
风险虚拟网的撤离完成率可以直观反映灾难风险下虚拟网的抗毁能力。如图6所示,相对于AUPM和RPCM,MRCE在各个阶段都能取得更好的撤离完成率。该结果表明,在灾难损毁时间不确定的情况下,MRCE能够更快更多地完成虚拟网的撤离。值得注意的是,随着考察时间的不断推移,3种算法的撤离完成率也在不断增长,但增长率有逐渐变缓的趋势。这是因为随着风险区外的虚拟网(已重构且完成撤离)不断增多,该区域的带宽资源消耗也在不断增加,可用于虚拟机迁移的带宽资源大量减少,从而限制了并行撤离的虚拟网数量。因此,在大量风险虚拟网的撤离过程中,撤离完成率越高,其增长率下降越明显。
5 结束语
为应对大规模灾难事件对虚拟网生存性造成的严重威胁,本文研究并提出一种多虚拟机快速协同撤离机制。该机制采用风险虚拟网的重构实现网络组件的抗毁,采用风险虚拟机的后复制迁移实现在线业务的抗毁。特别针对同一虚拟网的多个或全部虚拟机均受到灾难威胁的情况,通过虚拟机最大迁移完成时限设定,约束虚拟网撤离完成时长,通过虚拟机迁移完成时长预估和基础迁移带宽分配,协调各虚拟机的迁移速度,通过虚拟机迁移完成时差评估和迁移带宽动态升级,进一步压缩虚拟网撤离完成时长。仿真测试证明,与常规后复制迁移算法和基于自适应带宽升级的后复制迁移算法相比,多虚拟机快速协同撤离算法能够在不同考察周期内获得较好的虚拟网撤离完成率和平均撤离完成时长。本文提出的虚拟网抗毁机制主要针对自然灾难风险,在应对未知或不可测风险(如军事打击、意外事件),以及更为严苛的时间约束等问题上,还有较大的研究空间。
猜你喜欢
环球时报(2022-08-08)2022-08-08
移动通信(2021年5期)2021-10-25
客联(2021年3期)2021-09-10
环球时报(2020-11-02)2020-11-02
新闻传播(2018年12期)2018-09-19
小学生学习指导(低年级)(2017年12期)2017-11-22
湖北函授大学学报(2017年6期)2017-06-16
科技视界(2017年2期)2017-04-18
数字通信世界(2017年1期)2017-02-13
中国交通信息化(2014年3期)2014-06-05
