
基于深度可分离卷积的多目标追踪神经网络研究
2021-10-31 01:37:18温博阁
大连交通大学学报 2021年5期
温博阁
(大连交通大学 交通运输工程学院,辽宁 大连 116028)*
随着近年来人工智能神经网络的爆发式发展,在图像识别领域,结合人工智能方法的目标追踪属于刚刚兴起的研究方向,其应用场景十分广阔.智能追踪算法可以极大地提高各个领域的效率,目前很多的跟踪技术是基于卡尔曼滤波的算法.卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域,但通过卡尔曼滤波的预测值没法应对复杂环境下目标追踪所带来的挑战.因此为了更好地追踪效果,大部分使用卡尔曼滤波的方法都借助了更为先进的设备,如激光雷达,深度摄像头等.得益于雷达生成的3D点云,深度摄像头的像素深度信息,利用卡尔曼滤波将需要追踪的点云与目标区域相结合,进而得到稳定的追踪区域.但是缺点也十分明显,激光雷达成本不菲,其可靠性也难以达到工业产品7×24全天运行要求.
基于这种情况,引入深度学习的方法,让普通摄像头在追踪方面也达到激光雷达和深度摄像头的水平就成了研究的热点.其中最著名的就是相关滤波KCF[1]方法,自其提出以来,优秀的追踪算法就开始不断涌现,但相关滤波方法有很多不足的地方,如HOG特征不能很好地体现被追踪物体特征,导致追踪精度出现问题.随着深度神经网络的不断完善,深度神经网络替换滤波的追踪方法也涌现出来,如DCF[2],Siamese[3],SINT[4]等相关算法将传统KCF的滤波过程替换成基于深度神经网络的过程.
本文提出一种基于深度可分离卷积的神经网络来进行实时的多目标追踪,还可利用神经网络大规模训练样本的能力提取更加准确的特征,提高了整体追踪的准确度.除此之外,一般的追踪网络需要给定追踪目标的初始坐标,而本文提出的网络通过增加目标追踪的分支,满足了在各种环境和光照的变化下端到端的准确追踪.
1 多目标追踪神经网络总体架构
多目标追踪神经网络主要由四个部分组成,
分别为残差层(Resnet),瓶颈层(Bottleneck),检测层(Detections),深度可分离卷积层(Depthwise),如图1所示.

图1 多目标追踪神经网络总体架构
2 残差层结构
本文的残差层基于Resnet50[5]的网络结构进行修改,使其输出可以满足检测层和瓶颈层的输入要求.其结构如图2所示.

图2 残差层结构图
残差层的网络主要由卷积(Conv),批标准化(BN),激活函数(ReLU)以及残差块(Block)组成.其中残差块是由三个部分的卷积批处理激活函数ReLU组成.每组的卷积核大小、通道数、步长如表1所示.

表1 Resnet50网络具体参数
3 检测层结构
检测层网络修改了YOLOv2[7](Redmon, Joseph, Farhadi, Ali)网络在物体位置检测的分支.YOLOv2在物体检测方面使用了Darknet-19作为骨干网络提取特征.本文使用了修改后的残差层作为骨干网络提取特征,可以有效地降低网路的运算量,提升处理速度.改进了其检测分支,通过三层特征堆叠,可以有效检测大中小物体.通过向上采样与原特征相加来引入残差方法避免梯度爆炸发生.检测层的结构如图3所示.
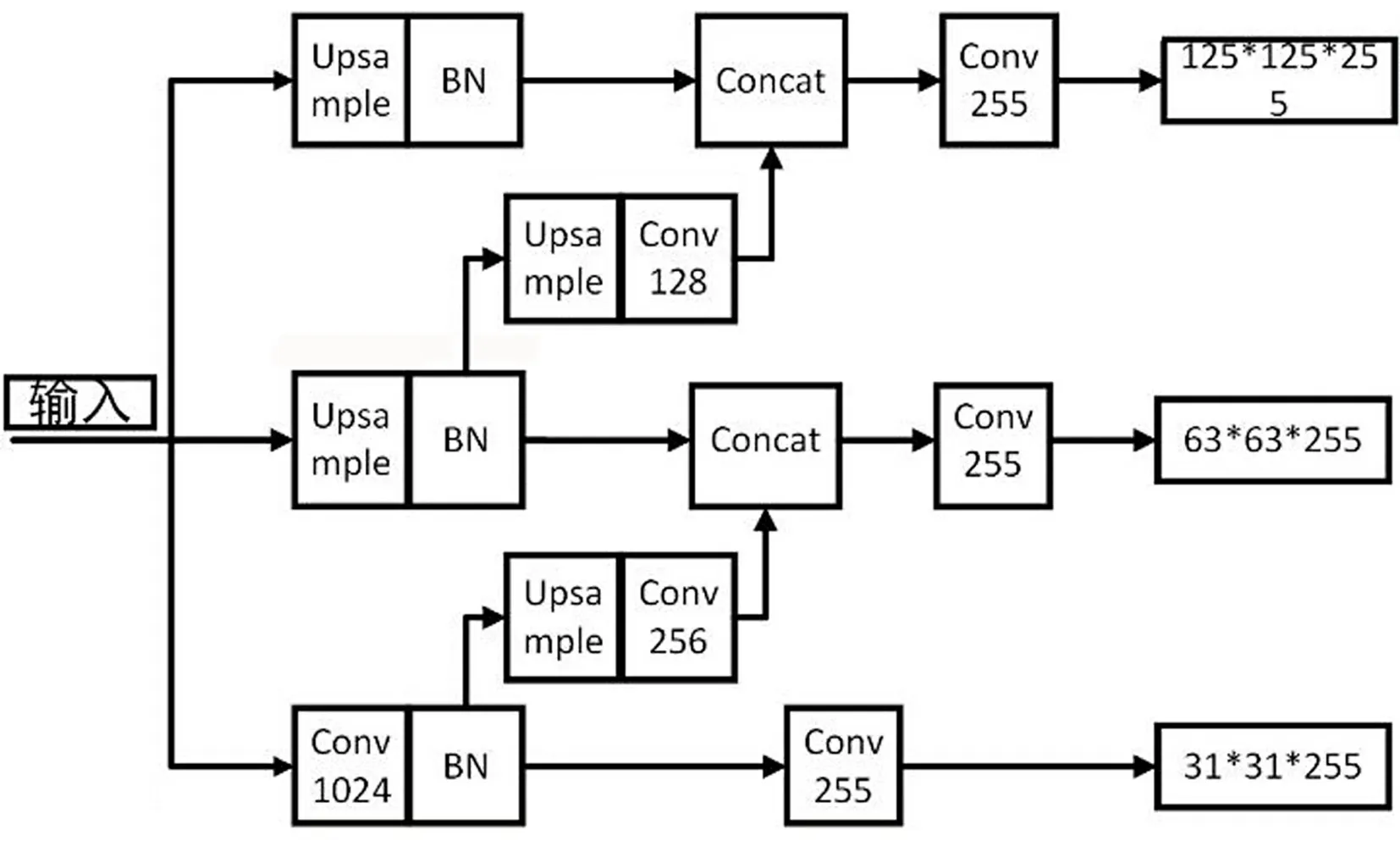
图3 检测层结构
4 瓶颈层结构
瓶颈层负责将残差网络输出进行调整.为了在全尺度上都可以精确地跟踪物体,残差网络输出一个金字塔特征矩阵,每一层矩阵代表不同尺度下图像的特征.瓶颈层的输入分别是残差层Block*4,Block*6,Block*3层的输出,每一层的特征图大小不一,通过卷积对特征图进行统一并融合[8],利用最后一个卷积对不同尺度的特征进行融合并降维,得到一个多尺度的特征矩阵,其结构如图4所示.

图4 瓶颈层结构
5 深度可分离卷积层结构
深度可分离卷积层主要目的是将需要追踪的目标进行特征提取并比对接下来每一帧中与其特征匹配度最高的位置,由此可以推断当前时刻,追踪目标的位置.其结构示意图如图5所示.

图5 深度可分离卷积层结构
Depthwise卷积可以将输入特征与原有特征进行互相关卷积,输出响应特征图代表了图片中与待追踪物体特征的相关性分布.通过Depthwise卷积后的特征图大小为25*25*检测物体数量,每个位置还有5种预先设置的先验框(Anchor number[9]),其宽长比为{1∶3,1∶2,1∶1,2∶1,3∶1}.因此每张特征图上共有25*25*5*检测物体数量个先验框,每个先验框与物体坐标位置的偏差用4个坐标表示,对于原始anchor,用A表示,真实坐标框用G表示,寻找一种变换F使其可以通过平移与缩放近似等于真实坐标:
其中:FC2为F函数,(x,y,w,h)分别表示中心点坐标和宽高,代表先验框的坐标.通过F映射为新坐标,使其更接近真实坐标G.
FC1为置信度函数,用来表示先验框中有目标物体的情况,共2组,分别对应存在物体和不存在物体的概率.
6 多目标追踪神经网络的训练
网络训练分为两个部分,一个部分是图片作为输入,残差层与检测层组成的检测分支,输出图片中不同物体的坐标与分类;另一部分将残差层的输出作为输入,瓶颈层和深度可分离卷积层作为追踪分支,输出每一个物体的追踪坐标.检测分支的偏差由三部分组成,分别是坐标偏差、置信度偏差和分类偏差.其中坐标偏差为:
其中,N为特征图尺寸,本文中有三种尺寸125、63、31.bool为每一个特征图中包含物体的可能,包含为1,不包含为0.Ax、Ay、Aw、Ah为网络输出的预测中心坐标和宽高.Gx、Gy、Gw、Gh为真实中心坐标和宽高.
置信度偏差为:
BCE是binary cross entropy,P、Q分别为真实物体存在和预测置信度的概率.
分类偏差为:
其中,C为物体类别,本文中使用了COCO数据集进行训练,因此C为80,p(c)、q(c)分别为各类的真实值和预测输出的概率.
追踪分支的偏差值为位置偏差:
|Ax-Gx|+|Ay-Gy|+|Aw-Gw|+|Ah-Gh|
其中,Ax,Ay,Aw,Ah为网络输出的预测中心坐标和宽高.Gx、Gy、Gw、Gh为真值的中心坐标和宽高.两个部分都选择了SGD作为优化器.
7 多目标追踪神经网络的评估
本文中使用了VOT-2016数据集进行训练和测试,使用VOT官方工具包中的测试方法对网络进行评估.
VOT的测试指标有EAO、Accuracy 、Robustness三个指标,其中Accuracy用作评价跟踪网络准确性,数值越大则准确度越高.Robustness用作评价跟踪网络跟踪目标的稳定性,数值越大,稳定性越差.EAO是VOT-2015提出的,其目的是描述一个追踪网络同时拥有好的recall和accuracy.测试结果如表2所示.本文的多目标追踪网络在EAO中,Accuracy和Robustness均取得了不错的结果,在追踪多目标的情况下仍比一部分单目标追踪网络实时性要好.

表2 VOT数据集测试结果与其他主流算法对比
8 结论
(1)本文针对在线视频中多目标的追踪方法进行了研究,提出一种在线的、实时的多目标追踪神经网络.通过一个骨干网络将检测与追踪两个分支融合为一个网络,在降低了运算量的同时,使得网络同时拥有目标检测与目标追踪的能力;
(2)根据骨干网络的特征,使用了改进的目标检测网络,使其满足于对多种目标地辨别.检测网络通过金字塔特征堆叠方式,增强了对大中小物体的检测.通过向上采样与原特征相加来引入残差方法避免梯度爆炸发生;
(3)骨干网络的特征和检测分支的结果同时作为追踪网络的输入,利用深度可分离卷积对不同特征相关性的判断,使其具备了对多目标追踪的能力.同时因为采用一个骨干网络和双分支的结构,保证了网络可以实时地运行于各种在线视频;
(4)本文中使用的方法在公开数据集的测试中,在EAO和Accuracy中都超过了主流的追踪算法,同时处理速度也得到了保证,证明了深度可分离卷积在没有增加太多计算量的情况下,有效地提高了特征提取的能力.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
学生天地(2020年6期)2020-08-25 09:10:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:36
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
自动化学报(2019年6期)2019-07-23 01:18:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
系统医学(2016年8期)2016-02-20 02:55:08
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
河南科技(2015年8期)2015-03-11 16:23:52
