
英语字素音素的可视匹配与特征分析
2021-10-27 09:25:44龚文涛陈晓莹李华昱
郑州大学学报(理学版) 2021年4期
李 昕,李 珊,龚文涛,陈晓莹,李华昱
(1.中国石油大学(华东)计算机科学与技术学院 山东 青岛 266580;2.中国石油大学(华东)信息化建设处 山东 青岛 266580)
0 引言
音素(Phonemes)是决定发音差异的最小单位,例如/AA/、/B/,字素(Grapheme)是对应音素的单个字母或字母序列,例如〈a〉、〈th〉,字素和音素分别是单词和发音的基本单位。形音转换是指字素与音素逐步进行分解和匹配,在匹配对的基础上进行统计分析,形成发音规则,这个过程是语音识别和语音合成的基础。以英语为代表的印欧语系是语音型文字,从诞生之初就与发音形成紧密联系。掌握语音型文字的发音规则是学习相应语言的基础。Hanna[1]早在1965年就著书详细描述形音匹配,由于缺乏完整性和直观性,在当时并没有得到认可。Elovitz等[2]总结了329个字母到发音的规则,但准确性无法达到实际应用的需求。此外这些方法在词汇量很大时变得既耗时又繁杂。近年来,随着人工智能技术的发展,例如神经网络的应用,语音处理问题取得了极大的发展,在标准发音下的语音识别准确率达到了94%。尽管这些基于机器学习的方法提高了识别准确率,但是最终形成的语音规则数目繁多且冗长,不可解释性是其固有弊端,不利于学习者掌握。
建立发音规则非常复杂,主要是因为语言的历史演化和地域差别,出现了大量变种,外来词的引入、元音大迁移等事件的出现,加剧了发音异常变化。此外,由于地域的不同,即使在相同的上下文约束下,相同的字素序列也可能产生不同的发音,使得异常发音很难通过内部一致的方式提取通用规则集。因此,本文解决的问题归纳为以下四点。
1)通过动态分类的方式实现形音增量匹配。本文从分类视图到样例视图创建了多视图交互,提高分类准确性。在全局视图监督下,结合语言知识模型从粗略到精准动态地迭代匹配。
2)运用关联分析获取整体模式。为了呈现所有发音规则的整体分布,本文将形音匹配关系转换为多层树状视图,每一层从不同角度进行比较,根据大数定理探寻主要发音规律。
3)直观有效地定位异常变化。在匹配过程中会产生两种异常:匹配错误和特殊发音。对于匹配错误,本文通过相关分析构造条件规则进行纠正;对于特殊发音,本文把在字素视图和分布视图中使用率低于阈值的规则进行高亮显示。
4)为研究人员提供了灵活的工具,并且可以扩展到具有语音型文字的任何语言。
1 相关工作
1.1 形音匹配
Rentzepopoulos等[3]提出使用隐马尔可夫模型对自然语言的单词特征进行建模,并使用维特比算法对其进行形音匹配转换。Wang等[4]基于形音匹配,提出了结合实例学习和动态编程自动预测单词发音的方法。Ogbureke等[5]提出了基于HMM上下文相关的形音匹配转换方法,该方法在Unilex数据集中准确率达到了79.8%,但在CMUdict数据集中准确率仅为57.8%。Kheang等[6]使用基于加权有限状态感应器的方法实现两级结构的形音转换技术,并提出了将音素和字母信息组合作为形音转换输入序列的策略,更详细地区分单词中的元音和辅音。Hannemann等[7]提出了基于贝叶斯的形音转换联合序列模型,并使用CMUdict词库进行了实验,结果表明,存在5.92%的音素错误率和24.6%的词汇预测错误率。这些工作通过改进形音转换方法提高了语音预测的准确性,但是机器学习模型隐藏了推导的规则,缺乏可解释性。
1.2 可视化分类
字素音素匹配本质上是一个分类问题。针对该问题目前已提出多种方法和工具,其中交互式探索与数据分类的结合可以更有效地解决分类中存在的问题。交互式学习是一种通过集成人类专家的背景知识来扩展主动学习的方式,除了对引用数据进行手动标注之外,用户可以直接简化复杂分类器模型。模型可视化有助于检测和纠正由实例训练分类器模型与用户预期模型之间的矛盾。Alsallakh等[8]使用颜色直方图代表类别概率对分类数据进行分析。Kim等[9]通过分析单词对文档情感的影响,并使用相应的关系解释视觉特征,更好地区分文档情感。Jamróz等[10]提出结合Kohonen映射方法分类,并应用可视化技术识别各种类型煤炭中的显著差异,人类可使用最直观的可视化方法定性分析数据,并且有效地确定煤炭的类型。这些可视化技术通过可视化界面帮助用户在复杂数据中获得更准确的分类结果。
许多典型的分类方法都不适用于复杂的语音系统。针对形音匹配,本文对可视化分类进行调整,联合交互可视化和心理预期模型获得最佳结果。
1.3 可视化异常检测
在各种异常值检测技术中,可视化技术被众多研究者广泛关注。由于错误的模糊性,清理结果往往需要人类知识验证,因此异常值检测需要交互。Kandel等[11]证明了分析师可以通过集成数据验证、转换和可交互的可视化系统更有效地获取数据。Kandel等[12]还设计了以交互式检测和可视化呈现的方式查找数据异常值的Profiler。由于分析人员经常迭代清理数据,所以Krishnan等[13]设计了Active Clean渐进迭代解决统计建模问题。Liu等[14]开发了一个可视化分析框架,该框架通过迭代来提高数据质量。Wilkinson[15]提出了一种用于检测大数据领域异常值的统计方法,交互消除了用户指定数据转换的烦琐细节。Cao等[16]将基于张量的异常检测算法与丰富的上下文可视化相结合,为数据校正模块提供可信数据。李苑等[17]提出一种恶意代码的异常检测方法,结合上下文信息与可视化方法,通过比较颜色深浅,直接区分恶意代码区域,具有极高的检测率。Xiang等[18]在可视化分析工具中集成了分层可视化、数据可扩展的校正算法,通过交互提高数据质量。
上述异常值检测方法证明,应用数据分析和可视化技术能有效从复杂数据集中获取异常信息。
2 形式化定义
本文工作主要是将单词音标转换为形音匹配对和语音可视化分析。语料库中的单词和音标被转换为字素和音素序列:字素用尖括号表示,例如〈a〉、〈th〉;音素用斜线表示,例如/AA/、/B/。匹配之前,首先定义音素全集P和字素全集G。以CMUdict数据集为例,字素全集可定义为G={〈a〉,〈b〉,…,〈z〉,〈-〉},其中〈-〉代表空字素;音素全集P由ARPAbet数据集的39个音素和表示不发音的/-/组成,定义为P={/AA/,/AE/,…,/ZH/,/-/}。单词全集和音标全集分别定义为W={g+|g∈G}和T={p+|p∈P}。
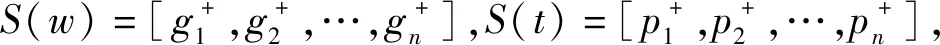

表1 apple一词及其音标匹配序列(〈apple〉→/AE1 P AH0 L/)Table 1 The word apple and its phonetic matching sequence(〈apple〉→/AE1 P AH0 L/)
本文形式化定义为六元组(G,P,W,T,R,M),其中R={c*[g+]c*→p+|c,g∈G,p∈P}是匹配规则,c*[·]c*表示所关注字素g+的上下文信息,约束匹配范围。
为提高匹配的准确性,匹配规则分级处理。条件规则应优先于无条件规则;不发音规则属于万能匹配,级别较低;对于同一级别规则,较长的规则具有更高的优先级。例如,规则〈ea〉高于规则〈e〉,规则〈g[ue] s$〉高于规则〈g[ue]$〉,其中$表示一个单词的结尾。精度系数θ的计算公式为
(1)
其中#(·)表示元素数。当规则m通过验证且正确时,sgn(m)=1,否则为0。在此过程中,某些匹配对可能会被错误的规则验证。例如,只有规则〈e〉→/IY/而尚未构建规则〈ea〉→/IY/时,〈easy〉→/IY1 Z IY0/会被分解为S(w→t)=[〈e〉→/IY1/,〈a〉→/-/,〈s〉→/Z/,〈y〉→/IY0/]。此时,〈e〉→/IY/会通过规则验证,但结果明显错误。当规则〈ea〉→/IY/建立后,easy分解结果为S(w→t)=[〈ea〉→/IY1/,〈s〉→/Z/,〈y〉→/IY0/],#S(m→t)从4变为3,精度提升。因此,本文方法是一个动态增量匹配过程。
3 数据准备与处理
3.1 数据准备
为了验证数据的实用性,本文以英语为例,使用布朗语料库、古腾堡语料库、网络和聊天记录、地址语料库和路透社语料库五种经典语料库与CMUdict的交集。由于人名、地名的发音规则与普通单词不同,因此将其从数据集中删除。如图1所示,最终采用35 182个常用英语单词及其音标作为语料库。
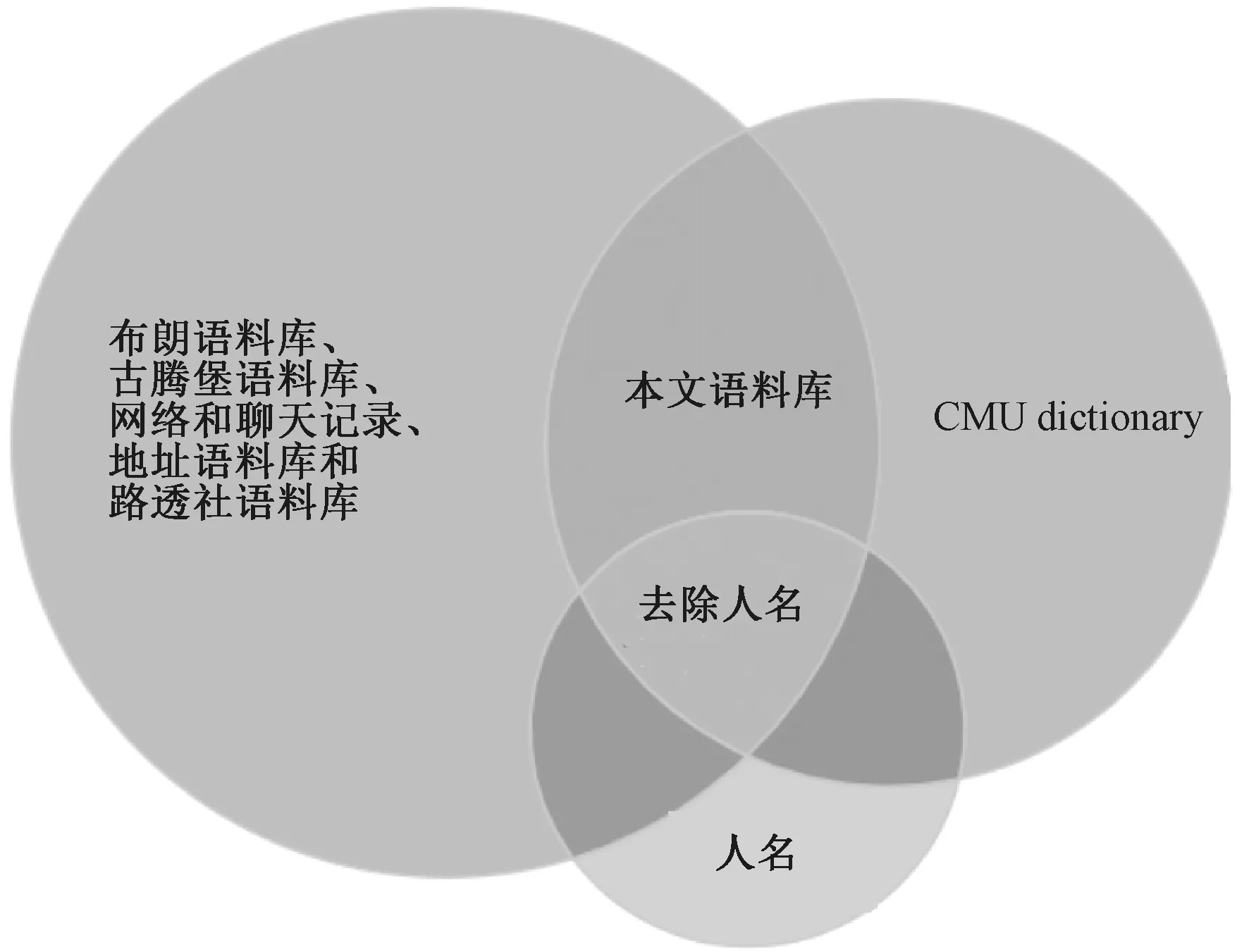
图1 数据源Figure 1 Data source
3.2 数据处理
本文提出的可视化系统主要具有两个功能:形音匹配和规则分析。作为规则分析的基础,形音匹配对的生成流程如图2所示。首先,参照单词集W和对应的音标集T,以一对一的对齐方式对每个单词进行匹配,构建初始形音匹配集合M。形音匹配对可分成两类:一类是将字素和音素对齐后形成的粗略匹配对;另一类则是通过了规则集中的某条规则验证的可信匹配对。开始处理前,所有的匹配对都是粗略的。随着处理的进行,将部分通过规则验证的粗略匹配对转化为可信匹配对,并记录到相应的单词中。然后将所有粗略匹配对和可信匹配对反馈至可视化系统。通过交互界面,用户将字素、音素、样例和上下文信息相关联,经过综合分析制定新规则。新规则的产生将触发系统进行下一轮匹配。重复上述过程,直到W和T中的所有元素分解为形音匹配对,即θ=1。因此,整个匹配过程是一个增量分类过程。用户可以参照匹配结果进行语音分析和异常值检测。
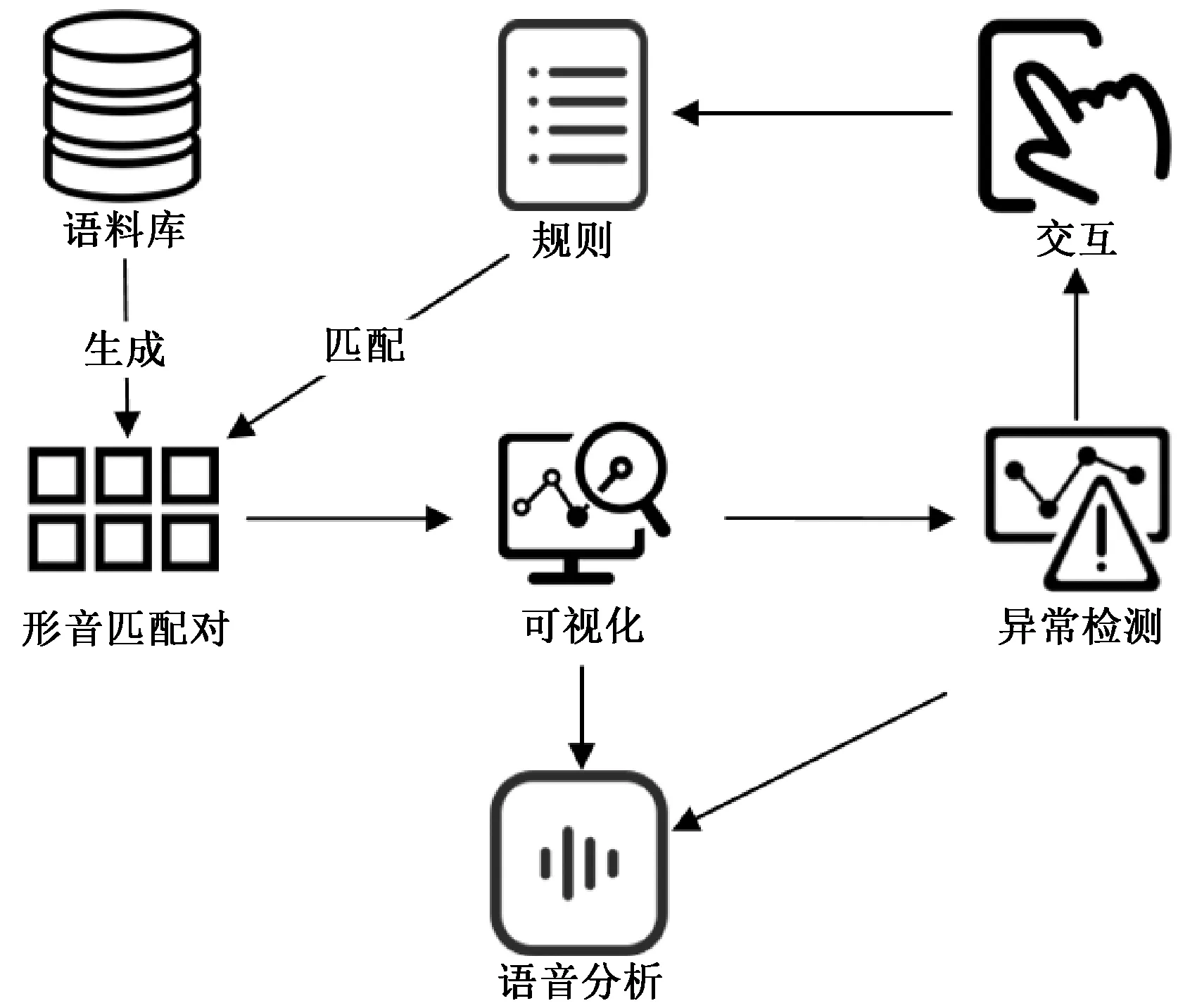
图2 形音匹配流程Figure 2 Shape-tone matching process
初始的形音匹配对集合M由字素与音素以对齐的方式生成。常用的两种字素音素对齐方法是ε散射法和手工播种法。ε散射法使用EM算法估计一对一字形匹配的概率,并使用动态时间规整引入ε,最大程度提高单词对齐可能性。手工播种法要求列出单词中每个字母可能对应的音素而不考虑上下文。手工播种法性能更优但需要标定初始种子。因为初始规则集合R为空集,所以本系统中使用ε散射法生成M。此过程同时构建部分生成形音匹配种子的规则,使用这些种子通过手工播种法进一步校正M。本文系统可以帮助用户根据整体信息做出决策,并交替执行粗略和精准匹配,直到取得最佳结果。
4 系统构建
根据任务和设计目标,本文提出并实现了基于自然语言形音匹配的可视化分析工具。系统的主界面分为全局视图、分类视图、细节视图和控制栏四个部分。全局视图包含进度视图和分布视图:进度视图显示了单词在形音匹配中的进度;分布视图展示了同级中比例关系的多层树图。分类视图将字素、相关规则和音素分为不同的组,分别呈现于字素视图、规则视图和音素视图。细节视图包含样例视图和上下文视图,可帮助用户做出决策。控制栏包含创建或删除规则的工具。粗略的形音对是从单词和音标的语料库中生成的,然后被划分为分类视图的子视图。借助样例视图,用户可以使用控制栏创建或删除新规则以更新匹配规则。系统迭代运行,由粗略到精细完成所有单词的形音匹配。用户可以在进度视图中观察所有单词的完成进度。分布视图使分析发音和检测异常值更加高效。
4.1 进度视图
如图3所示进度视图使用折线图显示词库中单词匹配的进度,其中X轴表示完成百分比,Y轴表示相应比例下的单词数量。创建新规则将更新进度视图。折线图的实时变化给予用户积极的心理影响,促进用户进一步完成工作。为了显示变化的意义,匹配成功的单词会从进度视图中删除,防止大量单词降低对比度。匹配的单词数量以数字形式显示在系统的左上角。

图3 使用进度视图筛选单词Figure 3 Using the progress view to filter words
进度视图的效果与进度指标类似,是人机交互中非常重要的环节。即使几秒钟的等待,也足以造成不愉快的用户体验。设计合适的指标,在应用过程中提供正反馈尤为重要。因此,进度视图虽然只是一个输出视图,但它对整个系统起着指导作用。进度视图的另一个功能是筛选单词,用户为关心的单词选定一个范围,发音往往与位置有关,如果一个相同位置发音数量非常多,应该为这些单词制定一些关键规则。例如,如果90%以上的范围内数量非常多,就意味着一些关键的后缀,如-ed、-s可能无法正确匹配。这个过滤可以帮助用户快速定位不匹配的情况,找到关键规则。
4.2 分布视图
分布视图是一个多层树图。第一层按字素分组,点击某字素进入第二层后显示所有相关序列,然后在第三层显示形音匹配规则。在分布视图中显示所有规则的比例关系,帮助用户从全局视角进行观察。为了显示规则的分布,使用不同颜色区分频率:浅蓝色代表正常的规则;深蓝色代表匹配率低于90%的规则;深红色代表使用频率低于一个阈值的异常发音变化。总结来说,分布视图是显示关于规则的匹配率、类别、比例和异常值的全局分布图。
4.3 字素视图
字素视图用气泡图显示上下文视图中的所有字素。气泡的大小与语料库中的出现次数成正比。可信匹配对和所有匹配对的比例映射成颜色的深度,黄色表示被选中。所有相关的匹配对都已完成的气泡显示白色边缘。大气泡和深色气泡会优先处理,以快速建立发音的整体性。例如元音和辅音〈t,n,p,s,l,d,c,r〉的比例相对较大,应优先处理。
4.4 规则视图
规则视图是一个单列的堆叠图,它展示所有与所选字素相关的规则,在字素视图中用黄色圆圈表示。所有粗略匹配对都被归入TODO方块中。规则视图中每个方块的高度代表其所占比例。当所有与当前选中字素相关的匹配对都被规则匹配后,TODO方块将消失。以字素〈u〉为例,相关规则不仅包括字素序列〈ua,ui,ur〉等,还包括条件序列〈g[ue]$〉等。在规则视图中,TODO方块以浅蓝色显示,并设置为默认选项,而规则方块则以深蓝色显示。当鼠标悬停在相应的方块上时,会提示详细信息。字素视图和规则视图实际上形成了匹配对字素序列的二级分类。
4.5 音素视图
M中的g+部分在字素视图和规则视图确定后,音素视图中显示M中对应的p+部分。音素视图也是一个气泡图,气泡大小表示不同发音数量的对比关系。黄色气泡表示正在处理的音素,当鼠标悬停时,会显示相应气泡的细节。而使用的音素小于阈值α则会以深蓝色显示,利于用户快速定位异常发音。
字素视图、规则视图和音素视图构成了本文系统中所有元素的分类,如字素、音素、规则和匹配对,因此合称为分类视图。字素视图中的元素是固定的,因为它们是由语言决定的,但规则视图和音素视图中的元素是在增量匹配过程中逐步形成的。
4.6 样例视图
样例视图显示了分类视图所选规则r对应的w∈W和t∈T。样例视图在样例单词和音标中高亮所选匹配对,为用户提供详细信息。在实际应用中,规则是匹配结果的最高准则。用户必须参考单词和音标,寻求最合适的规则,这就是样例视图的功能。采用随机抽样的方式将内容呈现在样例视图中,可以在样例视图中找到最具代表性的特征,该特征可以帮助用户制定新的规则,对匹配对的内容进行新的分类。符合新规则的内容将从当前的样例视图中移除,新的样例从剩余内容选取。本文系统在此基础上实现了规则的增量匹配。
4.7 上下文视图
上下文视图展示了当前匹配对前后内容对发音的影响。上下文视图由水平条形图组成,长度代表了字素或音素的数量。左右上下文和样例视图同步变化,对样例视图中的内容起到筛选作用,由用户确定上下文为字素或音素。考虑到上下文可为字素/音素序列,上下文视图进行了嵌套构造,单击图中条形栏可进入下一级,实现多级筛选。
4.8 交互式分析
形音匹配过程中,字素、音素、规则、样例和上下文相互影响,复杂的发音规律对交互性提出了更高的要求。本文采用多视图方式,通过交互快速确定关联关系。在字素视图中选择一个字素后,规则视图显示相关规则,形成对字素序列的二次分类,然后在音素视图中显示相关的音素选项。当用户在一个规则内选择了一个候选匹配对后,样例视图中会出现样例词及其音标,上下文视图借助上下文信息以降低匹配对的复杂性,促进正确规则的提取。新规则创建后,进度视图、分布视图也随之更新。所有视图构成一个有机整体,彼此相互依赖。用户处于主导地位,通过实时交互提高分析流畅性和结果准确性。
5 实验
本文中,交互的可视分析系统对字素、音素、样例和上下文进行关联分析。本节以三个具体案例详细说明匹配过程。这些案例的结果可以结合语言的发展历史和文化进行解释,对语音研究提供了帮助。
案例1
以字素〈u〉为例,首先在字素视图中选择字素〈u〉,规则视图中的TODO方块默认跟随变化。观察音素视图并结合英语发音的基本知识,得出元音字素〈u〉与辅音/JH/是一个错误匹配。观察样例视图,其中仅有〈gauge〉和两个变形词〈gauges〉、〈gauged〉,如图4所示。音素/EY/在/JH/的左侧,表示/EY/已被匹配。因此猜测〈a〉→/EY/的规则导致了这种错误匹配。结合语言学知识,应该是字素序列〈au〉对应音素/EY/。为了验证这个猜测,用户回到分类视图,观察〈au〉的信息,字素序列〈au〉没有/EY/的发音(图5左)。于是创建新规则〈au〉→/EY/,因为〈au〉比〈a〉长。根据规则匹配原则,〈au〉的规则会在〈a〉之前匹配。同时,错误的音素/JH/从〈u〉的TODO方块的字素视图中消除。新规则解决了错误匹配问题。

图4 〈u〉→/JH/匹配的样例视图Figure 4 〈u〉→/JH/matched sample view

图5 构造新规则〈au〉→/EY/Figure 5 Construct new rules 〈au〉→/EY/
据语言学家统计,英语中古典语词源只占33%,而拉丁语和希腊语占56%,其他词源占11%。大量外来词的存在成为英语的显著特点。
案例2
本系统对匹配具有较强的推理性。例如〈u〉→/EH/构成一个不常见的候选匹配,但发音知识告诉用户〈u〉不应该发音/EH/。显然,在这种情况下/EH/属于〈e〉。大多数的两个元音序列应该只有第一个元音发音,而这里第一个字素〈u〉不发音。
为了探究原因观察上下文视图,如图6所示。在这种情况下,只有一个前置字素〈g〉,推测〈g〉在〈u〉前导致了这种特殊发音。如图7所示,重新选择〈g〉→/G/,〈g〉→/JH/,〈g〉→/ZH/,观察上下文视图右侧。分析得出g后跟随〈a,o,u〉时产生硬发音/G/。如果后接〈i,e,y〉,大多数情况下会产生软发音/JH/。所以得出结论,为了避免〈g〉与〈e〉直接相连,中间插入不发音〈u〉,以明确g的发音,所以形成新规则〈g[u]〉→/-/。图中气泡大小表示规则频率。

图6 〈u〉→/EH/的上下文视图左右窗口Figure 6 〈u〉→/EH/context view of the left and right windows
纵观英语发展史,〈g〉的硬发音源于原始盎格鲁-撒克逊语或日耳曼语,而软发音大多源于拉丁语,尤其是法语。原始的软发音是法语的/ZH/,转入英语后改为/JH/,但仍有少量单词保持/ZH/,如图7右下角所示。所以在字素〈g〉后面有〈i,e,y〉的单词,是法语外来词产生的软发音,如generous、gesture、gin、gypsy。
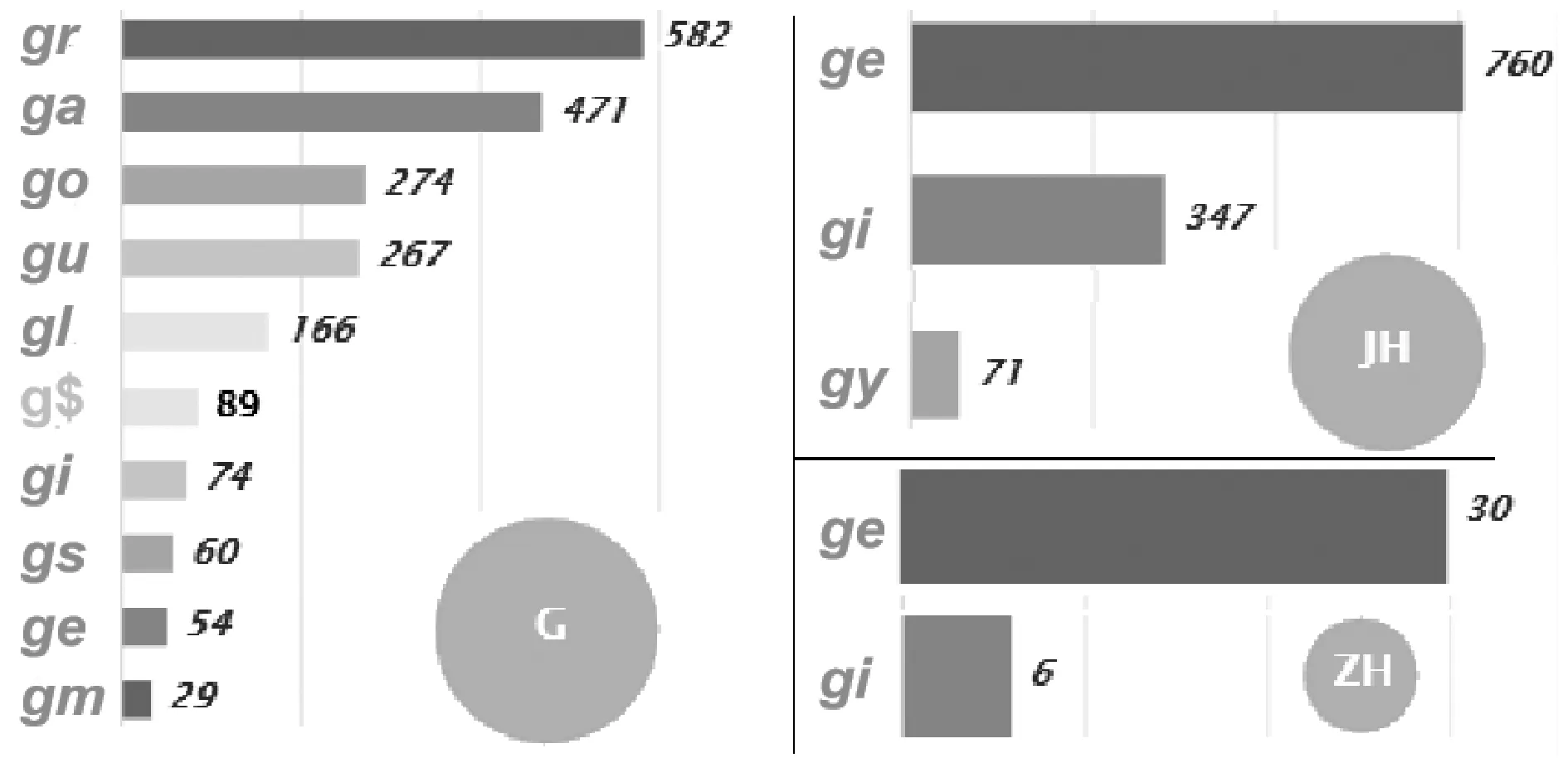
图7 〈g〉→/G/,/JH/,/ZH/的上下文视图右窗口Figure 7 〈g〉→/G/,/JH/,/ZH/context view right window
案例3
粗略匹配对〈b〉→/T/明显不合理。观察上下文视图,发现所有的样例都是在bt一起出现时发生的,所以设置条件规则〈[b]t〉→/-/,即b在t之前不发音。但是新规则会产生新的错误匹配,例如subtitle、obtain等,因为sub和ob是前缀,〈b〉的发音应该是/b/。所以需要两个新规则〈su[b]t〉→/B/和〈o[b]t〉→/B/。这个渐进的过程表明了本文系统的交互性和实时性。任何异常值的出现都被实时反馈给用户。
查阅相关资料,大量的拉丁文单词和特征被引入,并逐渐成为日常生活中的常用词。这给英语中的法语单词赋予拉丁面孔,比如在debt等单词中插入了字素b,但没有实际发音。规则〈[b]t〉→/-/就是来自这一历史事件。
6 评价
本系统将语料库中的35 182个单词与发音处理后得到235 272组匹配对,构建了386条发音规则。
6.1 全局语音分析
分布视图以树状图的形式显示所有规则,用不同大小的矩形区域代表规则的频率。元音规则比辅音多,相对较少的规则占据了大部分区域。将所有规则按照使用量进行逆向排序,然后将数值进行累加,得到图8左边的曲线。通过曲线可以看出,64条规则就占到90%的发音,它们是构成英语发音的最重要规则。
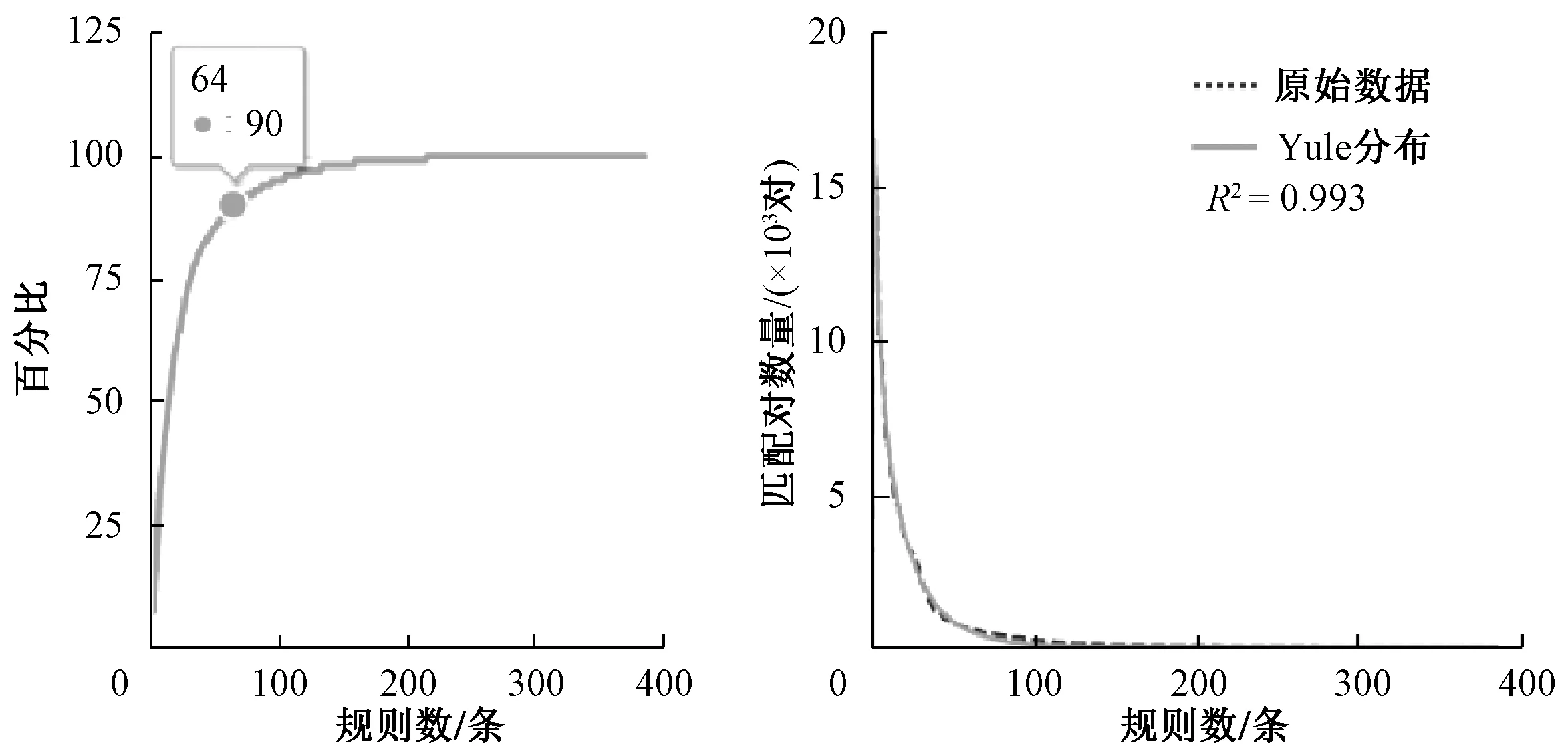
图8 累加曲线与频率拟合Figure 8 Accumulation curve fits with frequency
6.2 详细语音分析
如图8所示,本文采用Yule分布对规则频率进行拟合,得到R2=0.993。这个结果意味着规则的使用频率符合幂律分布。同时,这也反映了一个成熟的语言系统经过长期历史沉淀后自然选择、适者生存的生态特征。
此外,本系统还可以用来详细分析英语发音。在字素视图中选择e,在规则视图中选择〈[ed]$〉后,音素视图中显示三种发音,如图9所示。〈[ed]$〉在清辅音/S/、/K/、/CH/、/P/、/SH/后发/T/,如washed和skipped;在元音和浊辅音/L/、/N/、/Z/、/M/、/R/后发/D/,如played和prepared;在t、d后发/AH D/,如regarded、hoisted。

图9 〈[ed]$〉的发音分析Figure 9 〈[ed]$〉 pronunciation analysis
在古英语中,后缀ed用于构成动词过去式和过去分词的弱化语态,使用频率较低。但随着英语单词的增多,常规的ed形式逐渐演变为一种主要的应用形式。它的发音主要受清辅音和浊辅音的影响,清辅音和浊辅音的发音分别为/T/和/D/。但当产生上下文关联,前一声母发音为/T/、/D/时,发音就会重叠,于是形成了/AH D/的特殊发音。
6.3 异常值检测
自然语言的混乱导致很多发音的异常变化,异常发音的检测与分析也很重要。在本系统发现的386条规则中,有126条规则的使用率小于10。本系统建立了一个增量匹配的规则。常规发音规则创建后,异常发音就会突出,可在分布视图中观察到这些异常发音。图10显示了所有音素到字素〈u〉的匹配关系。小于阈值α的音素用深色突出显示,用户很容易找到这类特殊的发音,如women一词中的〈u〉→/IH/。字素〈o〉的分布视图第二层如图11所示。特殊读音的规则用暗深色突出显示,如〈ow〉→/AA/只出现在knowledge及其复合词中。
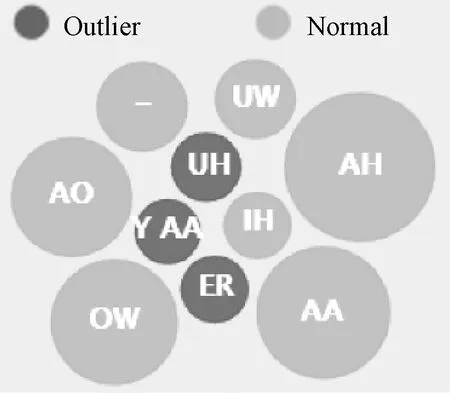
图10 字素〈u〉的音素Figure 10 The phoneme of 〈u〉

图11 字素〈o〉分布视图第二层Figure 11 〈o〉 overall view level 2
可视化反馈对异常值的检测十分有效。频率较低的规则可以帮助用户定位发音的异常值。一方面可以找到特殊发音,如观察规则〈oo〉→/UH/对应的样例视图,发现只有flood和blood两个词及其衍生词;另一方面可以发现错误。如在CMUdict中,bankruptcy被写成bankrupcty,laugher的发音为/L AA K ER/等,通过本文系统都被精确地发现,经过查找剑桥和牛津词典,确定为拼写错误。
7 结论
本文设计了一个交互可视化的语音分析工具,实现了对语料库中所有词及音标的粗略到精细的增量匹配。基于形音匹配对,本文将相关的字素、音素、样例和上下文一起关联分析语音特征。通过可视化,不仅支持整体的语音结构,还支持异常值检测下的发音异常变化的细节,打开了机器学习方法的黑匣子。通过可视化交互,语言学家可以结合历史和文化深入了解语音系统,进一步了解语言的本质特征。本文提出的可视化工具可以将字素和音素用便于人类理解的方式进行匹配,形成发音规则,对发音预测、语言学习和语音研究都起到积极促进作用。
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
苏州科技大学学报(社会科学版)(2023年4期)2023-03-03 05:37:43
心理学探新(2022年1期)2022-06-07 09:15:40
北京教育·普教版(2020年9期)2020-10-09 11:15:09
广东教学报·教育综合(2020年15期)2020-03-23 05:58:29
校园英语·中旬(2019年11期)2019-11-26 10:01:06
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
