
Analysis of Coronary Angiography Video Interpolation Methods to Reduce X-ray Exposure Frequency Based on Deep Learning
2021-10-22 08:04XiaoleiYinDongxueLiangLuWangJingQiuZhiyunYangJianzengDongandZhaoyuanMa
Xiao-lei Yin,Dong-xue Liang,Lu Wang,Jing Qiu,Zhi-yun Yang,Jian-zeng Dong,3 and Zhao-yuan Ma
1 The Future Laboratory,Tsinghua University,Chengfu Road 160,Haidian,Beijing,China
2 Center for Cardiology,Beijing Anzhen Hospital,Capital Medical University,Anzhen Road,Beijing,China
3 The First Affiliated Hospital of Zhengzhou University,Jianshe East Road,Erqi District,Zhengzhou,China
Abstract Cardiac coronary angiography is a major technique that assists physicians during interventional heart surgery.Under X-ray irradiation,the physician injects a contrast agent through a catheter and determines the coronary arteries’state in real time.However,to obtain a more accurate state of the coronary arteries,physicians need to increase the frequency and intensity of X-ray exposure,which will inevitably increase the potential for harm to both the patient and the surgeon.In the work reported here,we use advanced deep learning algorithms to find a method of frame interpolation for coronary angiography videos that reduces the frequency of X-ray exposure by reducing the frame rate of the coronary angiography video,thereby reducing X-ray-induced damage to physicians.We established a new coronary angiography image group dataset containing 95,039 groups of images extracted from 31 videos.Each group includes three consecutive images,which are used to train the video interpolation network model.We apply six popular frame interpolation methods to this dataset to confirm that the video frame interpolation technology can reduce the video frame rate and reduce exposure of physicians to X-rays.
Keywords:coronary angiography;video interpolation;deep learning;X-ray exposure frequency
Introduction
Coronary artery disease threatens human health and has become one of the world’s most fatal diseases[1].Percutaneous coronary intervention(PCI)is a minimally invasive surgical procedure to treat coronary artery disease effectively.Coronary angiography plays a key auxiliary role in the PCI process.In coronary angiography,a radiopaque contrast agent is injected into the blood vessel and an X-ray source is used to irradiate the blood vessel to visualize the blood vessel to assist observation by physicians.To obtain a high frame rate and a clear angiography video during the operation,physicians need to increase the X-ray exposure frequency and intensity of X-rays,especially for heart-related PCI operations.Because of the influence of heartbeat and blood flow,the aquisition frame rate is higher than 30 frames per second or 15 frames per second for the head-related or abdomen-related PCI operations(in contrast to a frame rate of 4 frames per second for radiography of the head and abdomen),which will inevitably increase damage to patients and surgeons caused by X-rays.Since the X-ray light source of most imaging equipment used clinically is pulsed light,the pulse frequency represents the highest frequency of imaging.For the requirement oflow X-ray exposure and low pulse rate,at the same time,to obtain high frame rate contrast video,which can ensure that physicians can observe the coronary activity clearly,video interpolation technology has become a possible solution.High frame rate coronary angiography videos can be obtained without increasing the frequency and intensity of X-ray exposure.
Video frame insertion technology mainly refers to synthesizing one or more frames of images between two adjacent frames of the original video.This technology can be applied to generate slow-motion video and to increase the video frame rate and frame recovery in the video stream.Most classic video frame interpolation methods use optical flow algorithms[2–5]to estimate dense flow graphs and distort input frames[6–9].Therefore,the performance of these methods depends mainly on the optical flow algorithm.Similarly,methods based on optical flow have limitations in many cases,such as occlusion,large motion,and brightness changes.With the continuous emergence of deep learning methods in recent years,this technology has also been effectively applied and expanded in various video frame insertion fields[10–15].These methods usually use neural networks to extract optical flow features first.Then they combine other features such as depth features[10]and context features[15]or add adaptive convolution structure[13]or residual network structure[16]to obtain synthetic frames and obtain good performance.
In this article,we innovatively apply deep learning methods to coronary angiography videos.We use the typical deep learning frame interpolation algorithm to verify that the frame interpolation method is useful in coronary angiography videos to reduce exposure to X-ray radiation.The advantages and disadvantages of various methods are summarized and compared,which lays a good foundation for research into and implementation of future algorithms.The main contributions of this article are as follows:
•For the first time,we have used frame insertion technology in coronary angiography videos.
•For the first time,we use artificial intelligence to reduce the pulse frequency of X-rays.
•We established a dataset for video frame insertion and tested and verified the feasibility of frame insertion in different ways.
Materials and Methods
Materials
We used data from about 3000 pieces of coronary angiography interventional surgery data on the hospital platform.Every three coronary angiography images were used as a group,and 1000 groups of data were selected.D1000 represents this dataset.At the same time,we extracted four coronary angiography video clips,each of which contained 30–45 continuous frames.Each video clip includes the process ofinjection,diffusion,and disappearance of the contrast agent.We use VC1,VC2,VC3,and VC4 to represent these four video clips.For these four clips,we use odd frames to predict even frames and then use even frames to predict odd frames so that we can compare all the predicted frames with the original frames.We use the peak signal-to-noise ratio(PSNR)and structural similarity(SSIM)values as the evaluation criteria for the two-frame image error.
Methods
We experimented with six deep learning–based video interpolation algorithms on our own datasets:namely,SepConv[13],Super SloMo[12],DAIN[10],BMBC[17],AdaCoF[18],and RRIN[16].The video interpolation task has three main steps:motion estimation,image warping,and synthesis.To improve the interpolation task results,most new methods are focusing more on the details of every step.This section briefly introduces some improved methods and their comparisons.
SepConv(Separable Convolution)
To solve the problem that frame interpolation based on optical flow requires a large kernel to handle large motions,a large amount of memory is needed.This method uses a 1D kernel to perform locally separable convolution on the input frame.Compared with conventional 2D kernels,it can effectively reduce the number of parameters and save memory space.The method uses a deep,fully convolutional neural network and two input frames,and simultaneously estimates a pair of 1D kernels for all pixels.Simultaneously,this method can synthesize the entire video frame immediately when estimating the kernel to train the neural network in combination with the perceptual loss.This deep neural network is trained end-to-end using widely available video data without any manual annotations.
Super SloMo
Most of the existing video methods focus on singleframe interpolation between two frames of images.For the video interpolation task of multiframe video,Super SloMo proposes an end-to-end convolutional neural network.First,it uses the U-Net architecture to calculate bidirectional optical flow between input images.Then each time step’s flow is linearly combined to approximate the intermediate two-way optical flow,and another U-Net is used to refine this approximate flow.Finally,the two input images are warped and linearly merged to form an intermediate frame.
DAIN(Depth-Aware Interpolation)
Because of movement of large objects or occlusion,the quality of video-interpolated frames is usually reduced.The DAIN method explicitly detects occlusion through the analysis of image depth information.The depth-sensing flow projection layer is used to synthesize the intermediate optical flow,and the farther motion information is sampled first.The network of this method also learns neighboring pixels to collect contextual information.The method model distorts the input frame,depth map,and context feature on the basis of the optical flow and interpolation kernel output by the network,and finally synthesizes the output frame.
BMBC(Bilateral Motion with Bilateral Cost)
To increase the accuracy of motion estimation,this method uses a deep learning video interpolation algorithm based on bilateral motion estimation.With use of bilateral cost volume,a bilateral movement network is first established to estimate bilateral movement accurately.The approximate two-way motion is then used to predict different types of bilateral motion.After use of the estimated bilateral motion to warp the two input frames,a dynamic mixing filter is used to merge the warped frames to generate an intermediate frame.
AdaCoF(Adaptive Collaboration of Flows)
The limitations of the degree of freedom will make it difficult to handle complex motions in real videos.To solve this,this method proposes a new warping module,AdaCoF.The module estimates the kernel weight and offset vectors of each target pixel,and finally synthesizes the output frame image.Compared with other methods,AdaCofis one of the most versatile warping modules and can handle a very wide range of complex motions.The loss function is a dual-frame adversarial loss,which is better to further synthesize a more realistic output in the video frame interpolation tasks.
RRIN(Residue Refinement Interpolation)
There are still problems with common visual effects and artifacts in the final composite image in video frame insertion.This method proposes a new network structure that uses residual refinement and adaptive weights to synthesize frames.The technique uses residual refinement technology in optical flow and image generation,and adaptive weight mapping combines forward and backward warped frames to reduce artifacts to obtain higher synthesis accuracy.Because of the light U-Net’s high efficiency,the method’s modules all use a U-Net with a smaller depth.
Experiments and Results
Training Details
Training Dataset
To train a better network model conforming to the coronary angiography scene,we create a new training dataset.The dataset contains 95,039 triplets of consecutive frames with a resolution of 480 × 360.The triplets are extracted from 31 coronary angiography videos,which corresponds to about 25 hours.The videos are produced by recording screen images during the cardiac intervention.We processed these videos and selected suitable coronary angiography fragments as the dataset.The image frame rate of coronary angiography is 7–15 frames per second.The frame rate used for recording screen images is 25 frames per second,so we preprocessed the recorded videos to remove duplicate video frames.Coronary angiography images contain some patient information,so we occluded and removed this information to ensure that the patient’s privacy is maintained.
Training Strategy
Every triplet in the dataset contains three consecutive video frames:the previous frame,the middle frame,and the next frame.We trained the network to predict the middle frame,which serves as ground truth.We used a pretrained model as the initial model for training.The learning rate was initially 0.0001 and decayed by half every 20 epochs.The batch size was 4,and the network was trained for 100 epochs.We trained the network on an NVIDIA 2080Ti GPU card,which takes about 30 hours.
Evaluation Metrics
MSE represents the mean square error of the current 195 imagesXand the reference imagesY.HandWare the height and width of the image respectively.nis the number of bits per pixel,generally taken as 8,which means the number of pixel gray levels is 256.
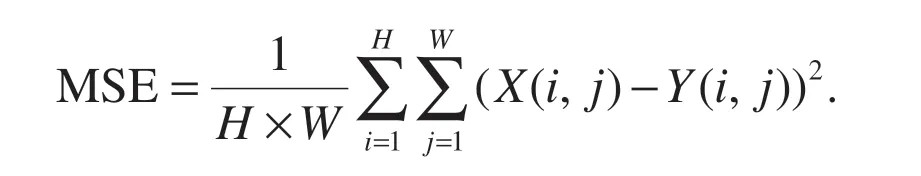
PSNR is the most common and widely used objective evaluation index for images.However,it is based on the error between corresponding pixels(i.e.,it is based on error-sensitive image quality evaluation).The larger the value,the smaller the distortion.
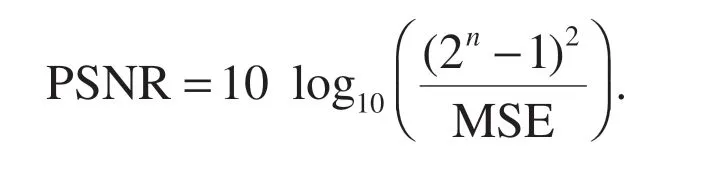
SSIM is also a full-reference image quality evaluation index,which measures image similarity from three aspects:brightness,contrast,and structure.The value range of SSIM is[0,1].The larger the value,the smaller the image distortion.
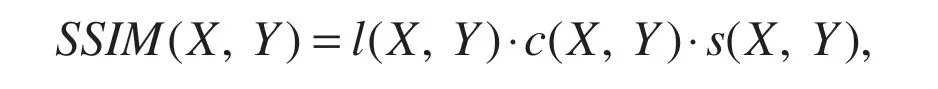
wherel(X,Y)represents brightness,c(X,Y)represents contrast,ands(X,Y)represents structure.
Results
To confirm our dataset’s validity,we first conducted some experiments with the DAIN method on some 215 test datasets.We compared the results of the pretrained DAIN model with those of the retrained model.Figure 1 shows the inputs of two original frames,and the ground truth is the actual middle frame.The interpolation middle frames of the pretrained model and the retrained model are namedandrespectively.As shown in Figure 2,the PSNR ofis 0.3 dB higher than that ofTable 1 records the averaget=0.5 values of the PSNR and SSIM of the DAIN method applied on D1000,VC1,and VC2.It shows the retrained model has higher PSNR and SSIM than the pretrained model.
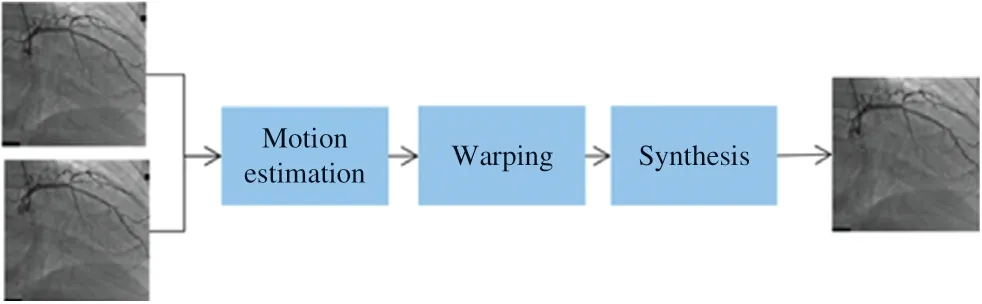
Figure 1 Flowchart for the Video Interpolation Task.
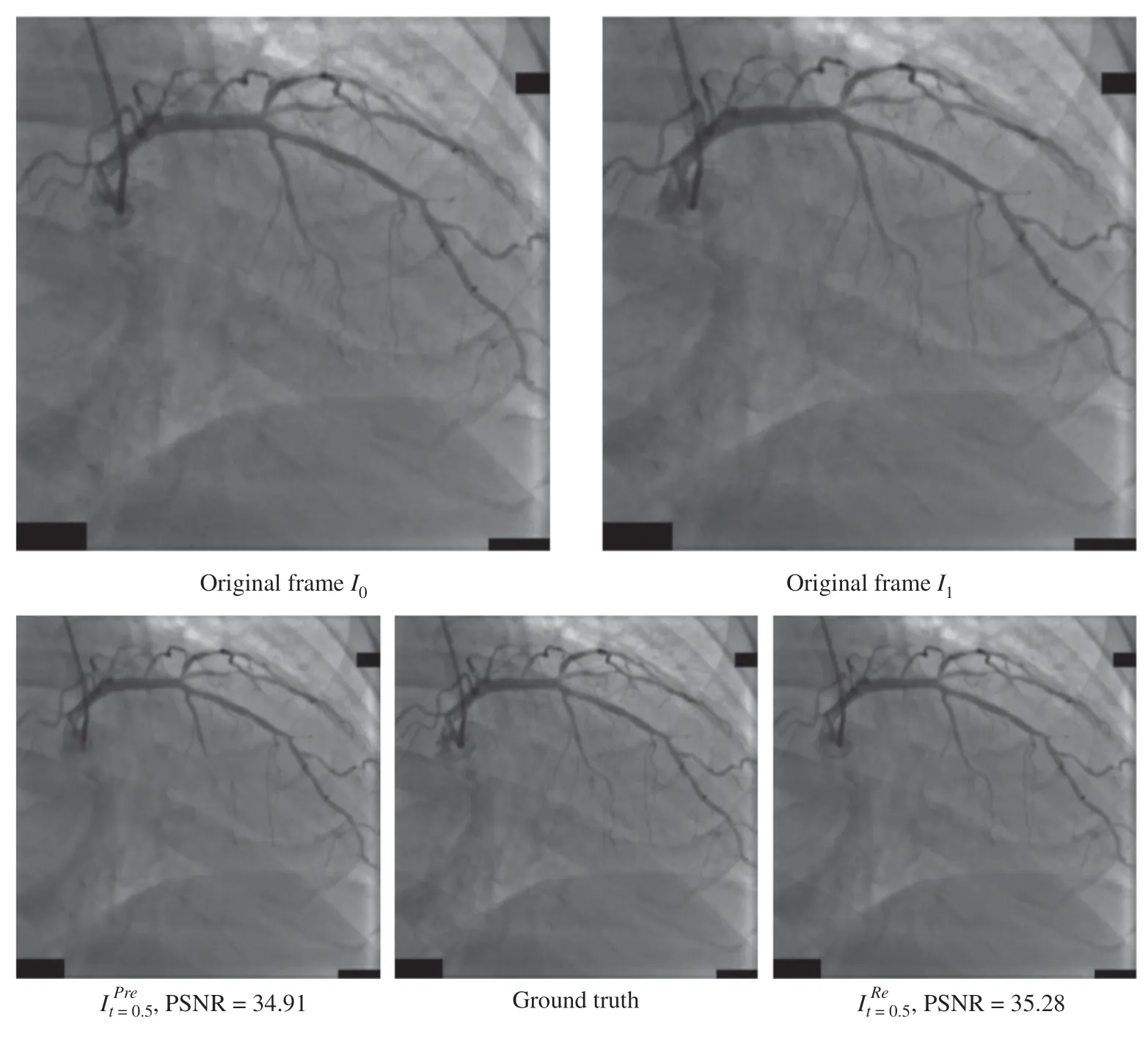
Figure 2 Comparison of the Output of the Retrained Model and the Pretrained Model.

Table 1 The DAIN Method’s Experimental Results for Different Datasets.
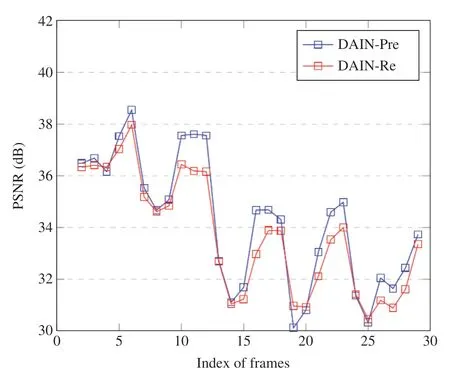
Figure 3 Peak Signal-to-Noise Ratio(PSNR)ofinterpolation Frame Changes with Frame Index of Dataset VC4.
Figure 3 shows the change of the PSNR as the number of frames in a video clip increases.The retrained model has a higher PSNR on every frame.From Figure 3 we can see that the PSNR has a similar periodic change,which is related to the cardiac cycle.We analyze the reasons for this phenomenon in the subsequent discussion.
Discussion
We compared our results with several recent frame interpolation algorithms,including two types of SepConv[13]with different loss functions SepConv-l1 and SepConv-lf,Super SloMo[12],DAIN[10],BMBC[17],AdaCoF[18]with two types of different size of kernel 5 and 11(AdaCoF-5,AdaCoF-11),and RRIN[16].To eliminate the influence of training data,we uniformly used our coronary angiography dataset and retrained these network models separately.Then we used these retrained models to validate the test dataset.
Table 2 shows a comparison of PSNRs and SSIM values of different interpolation methods applied on the coronary angiography test dataset.In Table 2,the bold numbers are the best scores of SSIM and PSNR for different test datasets.From the data,we can see that in the VC1–VC4 datasets,the results obtained with the RRIN method are significantly better than those obtained with the other methods,especially the average PSNR is higher than with the other methods.
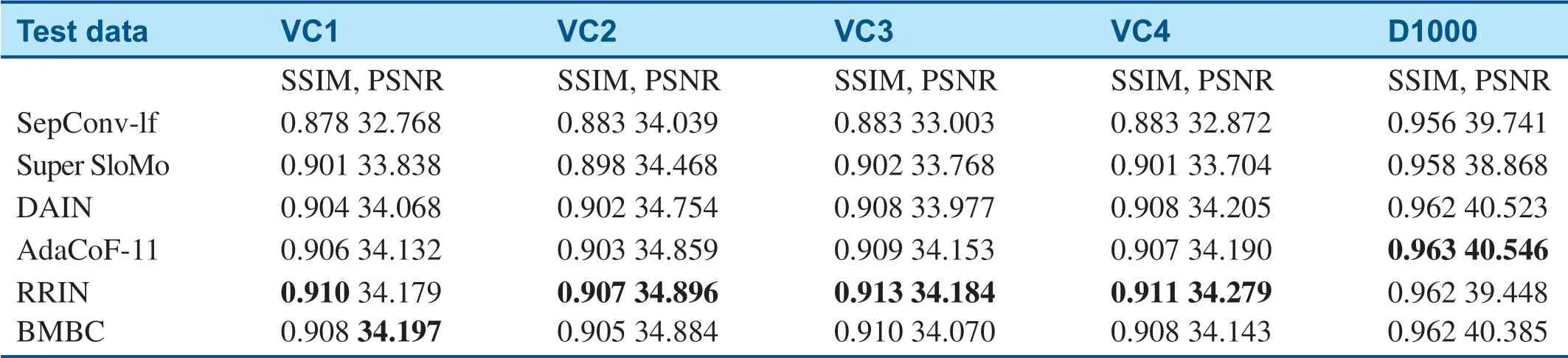
Table 2 The Average Peak Signal-to-Noise Ratio(PSNR)and Structural Similarity(SSIM)Value of Several Frame Interpolation Algorithms.
Figure 4 shows a comparison of the interpolation frame results for several video interpolation methods in the case of occlusion and large-object motion.As shown in Figure 4,the RRIN method performs well in the case of occlusion or motion of a large object.The image edges of the interpolated frame are clearer.
For Figure 5,we used the test results of two coronary angiography video clips to draw the PSNR curves of several frame interpolation algorithms.First,the overall PSNR curve for the RRIN method is higher than the curves for the other methods.Secondly,all PSNR curves have periodic changes.When the systolic and diastolic phases of the cardiac cycle switch,a lower PSNR occurs.We analyze this result because when the phase of the cardiac cycle is switched,the optical flow characteristics between two adjacent frames are not obvious enough.The motion vector of the coronary artery cannot be accurately predicted.At the same time,we can see that the PSNR decreases as the number of frames increases.The reason for this problem is that as the contrast agent spreads in the coronary arteries,the blood vessel motion area of the coronary angiography image continues to expand.As shown in Figure 5B,after the contrast agent has diffused to the end of the coronary artery,the PSNR no longer changes significantly between frame 35 and frame 45.To further improve the quality of coronary artery angiography video interpolation,we plan to use the trained coronary artery segmentation results[19]for comparison experiments in future work.
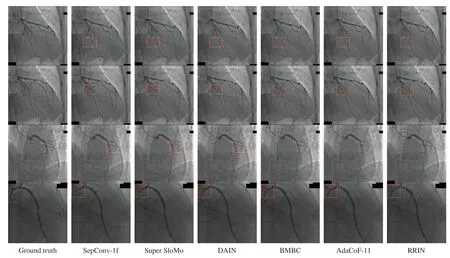
Figure 4 Comparison ofinterpolation Frame Results from Several Methods.
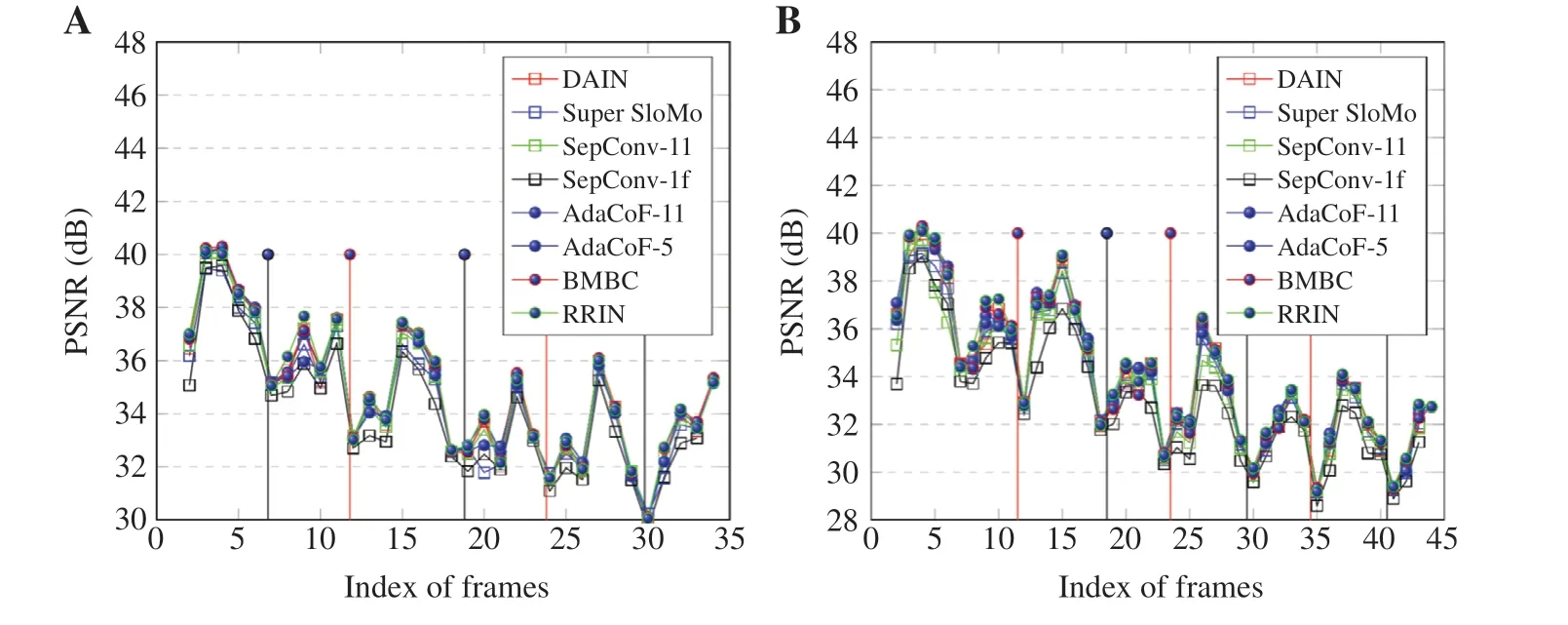
Figure 5 The Peak Signal-to-Noise Ratio(PSNR)Curves of Several Frame Interpolation Algorithms Applied on two Continuous Coronary Angiography Clips.
Conclusion
We innovatively applied a deep learning–based video frame interpolation algorithm to coronary angiography video.We established a new coronary angiography dataset to verify that the application of video interpolation technology in coronary angiography video is feasible.The new model has better performance in the application scenarios of coronary angiography through the retraining of different advanced frame interpolation algorithms.We found that the RRIN method has better performance than the other methods in the case of occlusion and movement of large objects.Many experimental results have proved the feasibility of using a video frame interpolation algorithm to synthesize continuous and clear high frame rate coronary angiography videos.With this technology,physicians can significantly reduce the frequency and intensity of X-ray exposure during coronary angiography.
 Cardiovascular Innovations and Applications2021年3期
Cardiovascular Innovations and Applications2021年3期
- Cardiovascular Innovations and Applications的其它文章
- Efficacy and Renal Tolerability of Ultrafiltration in Acute Decompensated Heart Failure:A Meta-analysis and Systematic Review of 19 Randomized Controlled Trials
- Similarities and Differences of CT Features between COVID-19 Pneumonia and Heart Failure
- Clinical Characteristics and Durations of Hospitalized Patients with COVID-19 in Beijing:A Retrospective Cohort Study
- A Patient with Atezolizumab-Induced Autoimmune Diabetes Mellitus Presenting with Diabetic Ketoacidosis
- Junctional Pacemaker May Replace the Sinoatrial Node
- In-Hospital Cardiac Arrest after Emotional Stress in a Patient Hospitalized with Gastrointestinal Symptoms and Chronic Anxiety Disorder