
京津冀协同发展报纸新闻主题发现及其关联分析
2021-10-21 05:13李海峰
科学技术与工程 2021年28期
李海峰
(河北大学计算机教学部, 保定 071002)
京津冀协同发展上升为国家战略,新闻媒体持续高度关注,积累了大量新闻报道网络信息资源。随着信息和媒体技术的快速发展,大规模新闻报道信息以文本方式存储。大规模文本信息使得人们在信息处理和检索上面临前所未有的挑战。为了深入理解京津冀协同发展新闻报道的整体概貌和主题分布,传统的阅读方法已经不能满足获取信息的需求。采用基于数据挖掘技术的自动化处理和组织方式,从大规模新闻集中开展主题发现和主题演化分析,为用户提供新闻信息整合服务,对京津冀协同发展国家战略的研究具有较高的理论价值和实践意义。
1 相关研究
1.1 新闻话题检测与跟踪
话题检测与跟踪(topic detection and tracking,TDT)是一项针对新闻报道进行信息识别、挖掘和组织的研究,主要包括报道切分、话题关联识别、新事件发现、话题追踪、话题发现等[1]。隐含狄利克雷分布(latent Dirichlet allocation,LDA)为经典的主题模型方法,利用词项在文档层共现提取文本中的语义信息,即主题,同时将词项矩阵转化为主题矩阵[2]。时序信息是新闻文本的重要特征,将时态信息引入主题模型,从时间维度分析主题的新生、继承、合并、分裂和消亡的演化过程,成为新闻文本挖掘的重要研究内容。Griffiths等[3]将时间信息引入主题模型,提出了话题演化模型理论。Wang等[4]提出了TOT(topic over time)模型,采用Beta分布对给定时间范围内的文本主题强度变化进行建模,将文本、词、时间三者相结合分析主题演化情况。Blei等[5]提出了动态主题模型(dynamic topic models, DTM),按照时间顺序将新闻文本集划分为若干个片段,每个片段按静态模型的思路建模,最终形成主题随时间的演化。王曰芬等[6]通过话题识别和主题关联分析开展了新闻报道舆情评论在主题内容和时间阶段上的异同。目前普遍认为LDA的最大问题是难于确定最优主题数目。
1.2 京津冀协同发展话题研究
京津冀协同发展成为广大研究机构和学者的重点研究对象,主要围绕京津冀区域协同发展的体制机制改革、城市空间布局、产业转移、交通一体化、生态环境协同治理等多个角度开展专题研究。为了全面了解京津冀协同发展的研究进展,孙威等[7]、李海峰等[8]、赵杰等[9]以中国知网期刊文献为数据源,采用文献计量学、共词分析、概率主题模型等方法,对中国学者研究京津冀协同发展主题的内容、强度和趋势等进行深入分析。丁曼旎等[10]以Web of Science为数据源,从英文期刊论文角度对京津冀地区的研究热点演化知识图谱进行了分析。吴芸等[11]、魏巍[12]、李雪伟等[13]以京津冀协同发展政策文本为研究对象,采用政策工具和政策文本分析等方法,分析了京津冀协同发展治理模式的特征和形成过程。然而,面对新闻媒体对京津冀协同发展宣传报道,鲜有学者围绕新闻报道信息进行深入研究和分析。
基于此,采用数据挖掘方法开展京津冀协同发展新闻报道的研究是非常有必要的。以“京津冀协同发展”媒体报道的大规模新闻集为研究对象,采用改进的时序主题模型方法进行基于主题和子主题的主题发现、主题关联和主题演化等方面的研究,挖掘出传统阅读方法难以获取隐藏在大规模新闻集中的系统性知识和隐含知识。
2 研究设计
2.1 方法流程
基于时序主题关联演化的新闻文本分析方法包括新闻文本获取、数据预处理、主题提取、主题强度计算、主题关联关系、主题演化分析等多个步骤。与传统主题模型方法[9]相比,本文方法提出了全局主题与子主题、时序主题与子主题和时序主题之间关联计算的主题关联演化分析模式,其研究框架如图1所示。
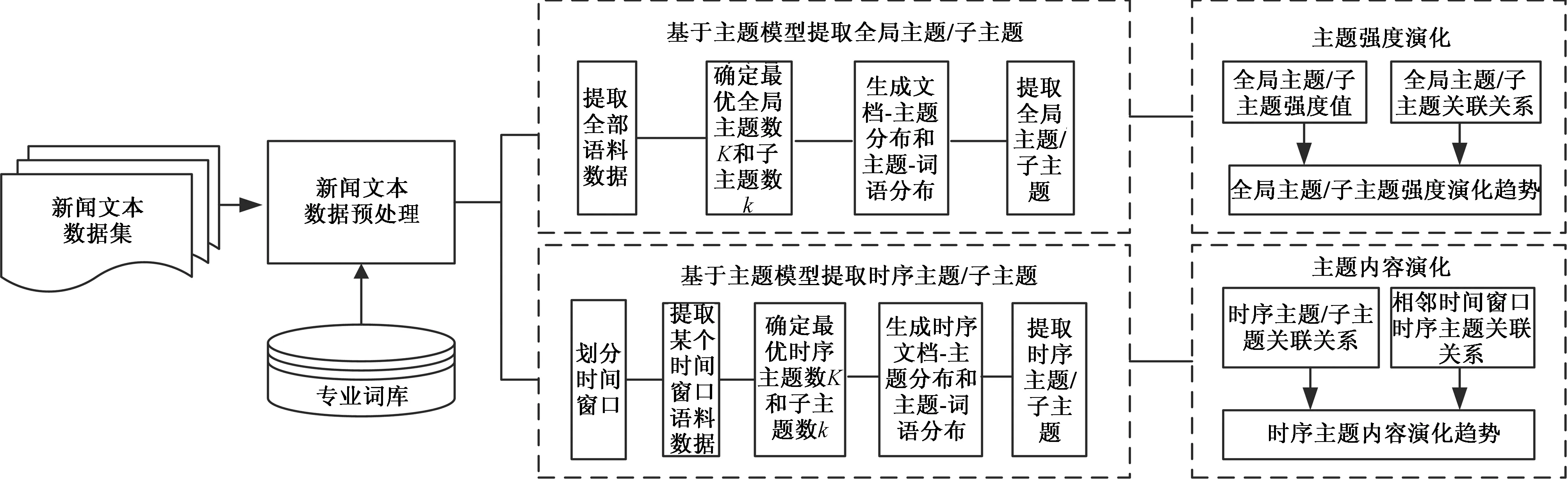
图1 研究框架Fig.1 Researchframework
2.2 LDA主题模型
LDA是Blei等[14]在2003年提出的一种文档概率主题模型。LDA主题模型是一种非监督机器学习方法,可以用来识别大规模文档集或语料库中潜在的主题信息。具体而言,LDA是三层贝叶斯概率模型,从低到高包含词、主题和文档三层次结构,其中,每个文档表示潜在主题的混合分布,每个主题表示为固定单词集上的概率分布。LDA主题模型描述如图2所示,LDA模型中使用的符号如表1所示。

表1 LDA模型中使用的符号
图2中,文档是由单词集w=(w1,w2,…,wn)构成的序列。语料库是由一系列文档D=(d1,d2,…,dm)组成。LDA的联合概率分布表示为

(1)

表示文档m中的第n个词,是可观测变量,为已知信息; 表示潜在变量,为未知信息;方框表示重复抽样(用于参数估计); 箭头表示变量间的条件依赖关系图2 LDA模型Fig.2 LDA model
式(1)中:w为可观测变量;θ和z为隐含变量;zn和wn分别为指定的主题和特征词;α和β由最大期望算法(expectation-maximization algorithm, EM)得到[15]。
2.3 确定最优主题数
LDA主题模型采用困惑度(perplexity)作为评价模型好坏的标准,选取困惑度最小的模型确定最优主题数[14]。困惑度的计算公式为
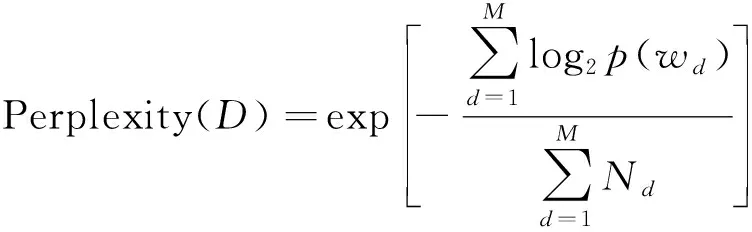
(2)
式(2)中:测试集语料库D中有M篇文档;Nd为文档d中的单词个数;p(wd)为文档d中词wd产生的概率。
困惑度值一般随着潜在主题数量的增加呈现递减的规律,较小的困惑度值表示模型对新文本具有较好的预测能力,从而造成选取的主题数目往往较大,导致主题的辨识度不高。为了权衡模型的泛化能力和主题的抽取效果,采用基于困惑度和主题相似度相结合的评价指标(Perplexity-Var)来确定主题的最优数目[16]。
Perplexity-Var指标引入主题方差到潜在主题空间,用于衡量主题空间整体的差异性和稳定性,主题方差的计算公式为
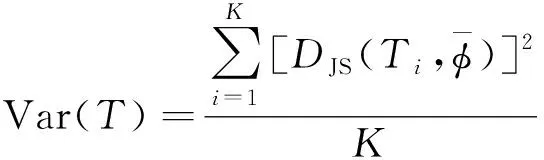
(3)

当主题方差越大时,主题之间的差异性越大,主题之间的区分性越好,故将困惑度值和主题方差两者结合起来,可以解决主题辨识度不高的问题。Perplexity-Var指标计算公式为

(4)
式(4)中: Perplexity(D)为数据集的困惑度,其值越小LDA的泛化能力好;Var(T)为数据集的主题方差,其值越大LDA主题抽取的效果越佳;Perplexity-Var指标越小是,对应的LDA主题模型最优。
2.4 基于主题与子主题的关联演化
主题演化过程需要考虑时间和内容两大因素,既要实现时间上的延续和关联,又要实现在内容上按主题进行分类识别。要实现上述功能,基于主题与子主题的关联分析流程如图3所示。
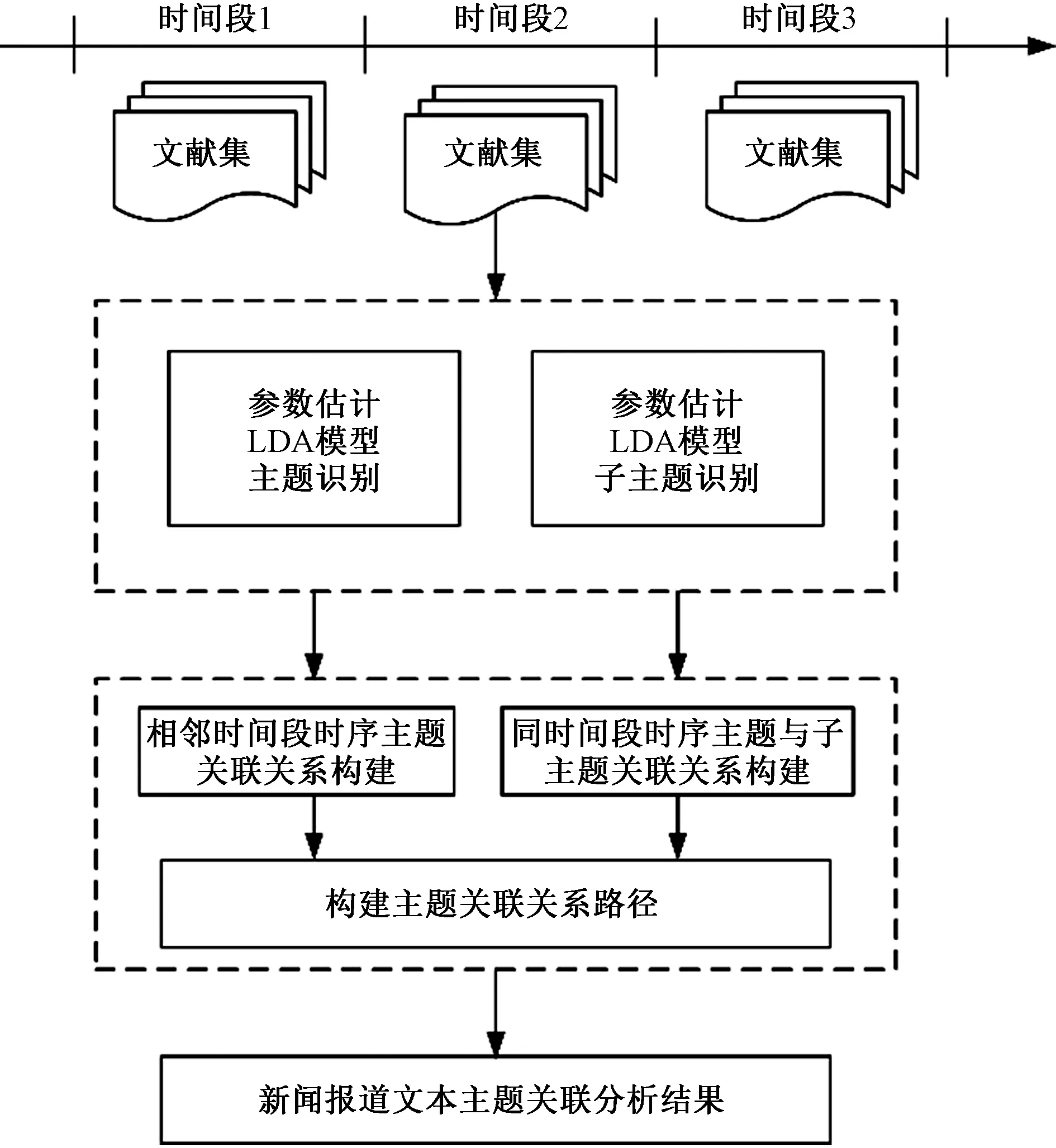
图3 主题关联分析流程Fig.3 Topic correlation analysis process
2.4.1 获取主题和子主题
通过对整个语料库计算Perplexity-Var指标值,获取全局主题数K和子主题数k。采用LDA模型获取整个语料库的全局主题-主题词概率分布Z和子主题-主题词概率分布z,可分别表示为
Z={Z1,Z2,…,ZK}
(5)
Zi={(Wzi1,Pzi1),(Wzi2,Pzi2),…,(Wzin,Pzin)}
(6)
z={z1,z2,…,zk}
(7)
zi={(wzi1,pzi1),(wzi2,pzi2),…(wzin,pzin)}
(8)
式中:Zi为全局主题-主题词概率分布;(Wzin,Pzin)为全局主题词及其概率值;zi为子主题-主题词的概率分布;(wzin,pzin)为子主题词及其概率值,用于分析整个语料库中主题分布情况。
按新闻报道时间划分l个时间窗口,语料库划分为l个子集,通过对时间片内的语料库子集计算Perplexity-Var指标值,获取时间窗口内的时序主题数K和子主题数k。采用LDA模型分别获取各个时间片内的时序主题Z′和子主题z′,可分别表示为
Z′l={Z′l1,Z′l2,…,Z′lK}
(9)
Z′li={(W′zi1,P′zi1),(Wzi2,Pzi2),…(W′zin,P′zin)}
(10)
z′l={z′l1,z′l2,…,z′lk}
(11)
z′li={(w′zi1,p′zi1),(w′zi2,p′zi2),…(w′zin,p′zin)}
(12)
式中:Z′l为l时间片时序主题-主题词概率分布;z′l为l时间片子主题-主题词的概率分布,用于分析l时间片语料的主题分布和时序主题间的关联演化。
2.4.2 主题关联关系计算
主题相关性判断是进行主题演化分析的先决条件。通过计算某个时间片上时序主题与子主题的相似度,判断主题内容的语义信息和子主题划分;通过计算相邻两个时间片主题间的相似度,判断相邻时间片主题的演化路径。采用JS散度计算主题间的相似度[17],其计算公式为
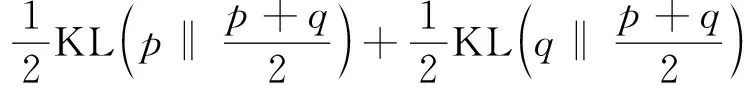
(13)
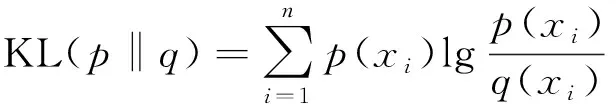
(14)
式中:KL(p‖q)为两个概率分布p和q间的KL距离;xi为概率分布p和q中的第i个词汇,两个概率分布p和q中词汇总数均是n;JS散度大小为0~1,其值越小,表明两个主题越相似,主题关联关系越紧密,将JS散度值小于0.5的值分为弱(0.5,0.35]、中(0.35,0.25]和强(0.25,0]这3个等级,判断主题间的相关性[9]。
3 实证分析
3.1 数据采集与预处理
主要以国家图书馆慧科报刊数据库中有关“京津冀协同发展”的新闻报道为数据源,从大众媒体视角观测京津冀协同发展新闻报道的主题分布及主题演化趋势。以主题包含“京津冀协同发展”为检索词,设定时间2014年1月1日—2020年12月31日为检索区间,进行精确检索,获取147 299篇新闻报道,信息包括新闻标题、报道时间、报纸名称、新闻版面、全文内容等。
利用Python中的Jieba中文分词工具对于 147 299 篇报道的新闻正文进行分词处理。分词工具中加入了京津冀协同发展领域的专业词汇,确保分词结果的合理性。利用中文分词停用词表,将分词后的文本去除停用词,最终形成用于统计分析和主题建模的语料库。
3.2 报道概况分析
3.2.1 时间趋势分布
采用数理统计方法,中国主流报纸媒体关于京津冀协同发展报道数量的时间分布趋势如图4所示。

图4 新闻报道年度分布Fig.4 Annual distribution of news coverage
京津冀协同发展于2014年2月上升为国家战略,新闻报道数量发生了较为明显的变化趋势,始终保持主流报纸媒体高度关注度。2014年是京津冀协同发展上升为国家战略元年,除了3月、4月和12月新闻报道量较多外,其他月份相应报道量较低;受北京行政副中心和设立河北雄安新区等重大政策深入推进落实的影响,2015年、2017年年度新闻报道量均接近30 000,达到高潮;随着京津冀协同发展政策的稳步推进,2018年、2019年的新闻报道量趋于平稳;到2020年,随着京津冀协同发展的深入落实,其新闻热度逐渐降低,报纸新闻媒体对京津冀协同发展报道量出现明显下降趋势。通过新闻报道月度分布观测,报道量最大的前3个月度分别是2017年4月、2015年7月和2014年12月。从新闻报道时间趋势分布来看,主流报纸媒体对京津冀协同发展话题持续关注,经历了快速提升(2014年)、持续高潮(2015—2017年)平稳发展(2018—2019年)和逐渐衰退(2020年)的演化过程。
3.2.2 报道来源分布
从媒体来源来看,147 299篇新闻报道来自中国638种报纸。依据文献计量领域的布拉德福定律(law of Bradford)[18],对来源报纸进行统计分析,可以发现报道京津冀协同发展话题的核心报纸群,如表2所示。从报道来源的核心报纸看,报道京津冀协同发展的主流媒体是人民日报、中国新闻社等国家级媒体和京津冀三地的省级日报以及环北京周边的河北省地级市日报,可以看出,京津冀地区的报纸是报道京津冀协同发展的主流报纸媒体。

表2 核心报纸和报道数量
3.3 全局主题分析
3.3.1 全局主题分布和主题强度
根据LDA主题模型分析的一般步骤,分别设定了6~200个主题数,对整个语料库的数据进行计算Perplexity-Var值,分别生成不同的主题分类组合,确定最优全局主题数17和子主题数90,能够较好地反映出2014—2020年中国主流报纸媒体报道京津冀协同发展的主题分布总体情况。对全局主题相近的进行合并,取前15个高概率主题词,其主题词分布情况如表3所示。
通过LDA模型获取文档-主题概率分布θij,根据计算主题强度计算方法[8],利用所有文档在某个主题上的概率分布值的平均值描述全局主题强度,如图5所示。
通过主题分布和主题强度观测,主流报纸媒体报道京津冀协同发展的主题大体分为以下四类。
(1)围绕学习贯彻落实党中央推进京津冀协同发展精神的重要报道,如主题类1所示。各级政府、部门和组织通过会议、讲话、报告、学习教育等多种方式落实京津冀协同发展国家战略;其主题类强度最高,体现了报纸媒体对国家大政方针和社会重点问题的宣传报道和积极引导作用。
(2)围绕京津冀区域交通、产业、生态重点领域率先突破的重要报道,如主题类2、主题类4、主题类6、主题类10所示。国家和京津冀“三地四方”着力推动网络化布局、智能化管理、一体化服务,构建安全可靠、便捷高效、经济实用、绿色环保的综合交通运输体系;着力推进绿色循环低碳发展,加强生态环境保护,发挥重点治理工程带动作用,节约集约利用资源,形成区域良好生态格局;着力实施创新驱动发展战略,建设北京行政副中心和河北雄安新区,促进产业有序转移承接,推动产业结构调整优化升级。尤其是天津自贸区建设,构建京津冀国际贸易大通道,服务京津冀企业国际化经营,服务京津冀高质量发展,成为报纸媒体重点关注的领域。
(3)围绕京津冀区域市场要素的重要报道,如主题类3、主题类5、主题类8、主题类9所示。市场一体化是京津冀协同发展的核心内容,市场资源的统一配置是激发区域经济发展活力的根本保障,资金、科技、信息、土地、人才、教育等市场要素自由流动成为制约京津冀协同发展推进的重要因素。通过报纸媒体报道的宣传和引导,京津冀政府间应建立统一的市场法规和市场监管制度,企业间应加强市场联合联盟和市场供需合作,保证市场要素合理流动,共同推动区域统一市场的形成。
(4)围绕京津冀文化旅游协同发展的重要报道,如主题类7所示。文化旅游产业是带动京津冀区域经济社会健康发展的有效路径。京津冀地缘相接,历史相通,区域文化资源一脉相承,呈现出集群化的特征。通过主题类7主题词来看,依托冬奥会的冰雪游和体育游、依托旅游小镇的休闲游和农村游、依托区域特色文化游等特色文化旅游整合,进一步提升文化与旅游的深度融合,推进京津冀文化旅游协同发展。
3.4 主题与子主题关联及演化
基于LDA主题建模,从全局和按时间片两个层面对新闻报道进行主题提取,计算全局主题与子主题、时序主题与子主题、时序主题和时序主题之间的相似度,进而确定主题的演化趋势。以全局主题Topic13“京津冀文旅产业协同发展”主题为例,开展主题关联演化分析。
3.4.1 主题与子主题关联关系
(1)全局主题与子主题。根据全局主题-主题词概率分布Z和子主题-主题词概率分布z,采用JS散度计算主题间的相似度,获得主题相似度矩阵Smn,如表4所示。根据2.4节主题关联强度计算方法,设定主题相似度阈值,获取全局主题的关联子主题。以全局主题“京津冀文旅产业协同发展”为例,其子主题及前15个高概率主题词分布如表5所示。
结合新闻报道时间信息,按年度划分为2014—2020年7个时间片。对每个时间片内的新闻文本进行主题建模,获的时序主题和子主题。采用JS散度计算相邻时间片时序主题间的相似度和时间片内时序主题与子主题相似度,分别获得时序主题间的相似度矩阵和时序主题与子主题的相似度矩阵。以全局主题“京津冀文旅产业协同发展”为例,其在不同时间片上的时序主题和时间片上子主题的前15个高概率主题词分布如表6所示。
3.4.2 主题关联与演化分析
文化旅游产业建设是京津冀协同发展的重要抓手,也是新闻媒体宣传报道京津冀协同发展的重点领域。以“京津冀文旅产业协同发展”主题为例,开展主题关联和演化分析。
(1)整体分析。通过全局主题与子主题关联关系和前15个高概率主题词(表5)观测,从整体来看京津冀三地合理规划区域文化旅游空间布局,打造文化旅游特色产业,发展集乡村休闲旅游、景区生态旅游、冰雪体育旅游、休闲购物旅游、滨海休闲旅游和历史文化古迹旅游等为一体的大旅游产业,全面提升京津冀区域旅游基础设施和公共服务水平,培育区域旅游品牌,实现合作项目共建共享。
(2)局部分析。通过时序主题关联关系和前15个高概率主题词(表6)观测,2014—2017年京津冀文化旅游产业与生态环境、城市规划等联系较为紧密,而到2018—2020年则演变成与区域交通一体化、北京冬奥会等主题关联更加密切。通过时间片内子主题主题词分布观测,进行如下分析。

表6 时序主题与子主题的关联关系(2014—2020)
一是京津冀生态环境的改善提升文化旅游产业品质。文化、旅游、生态有着密不可分的联系,生态环境与文化旅游产业互相依存、互动发展。京津冀协同发展上升为国家战略初期,京津冀区域生态环境破坏较为严重,尤其是大气污染、水资源恶化更为突出。从2014—2017年4个时间片主题分布看,京津冀三地重点优先开展生态环境综合治理,促进了区域文化旅游产业的快速发展,实现了生态环境与文化旅游的深度融合。
二是京津冀交通一体化带动文化旅游产业快速发展。从2018—2020年3个时间片主题分布看,文化旅游产业与交通一体化关联更加紧密。发展交通是旅游业壮大的先决条件,“十三五”期间大兴国际机场的建成,加速了京津冀区域和全世界的连接;京张高铁、京雄高铁等骨干城际铁路的启用,环首都一小时交通圈逐步扩大;多条高速贯通,促进京津冀三地人流、物流、信息流的流动;京津冀区域公交省际化、省际公交化实现了城乡、景区、场馆之间的互联互通。可见,交通先行战略为区域文化旅游一体化由蓝图变为现实提供了最强有力的支撑。
三是聚焦重大战略任务协同推进文化旅游实现新突破。从2014—2020年各个时间片子主题分布看,冬奥会、大运河、长城等成为文化旅游产业发展的热门词汇。以2022年冬奥会为契机,充分发挥京北水源涵养功能区、生态环境支撑区的作用,建设以冰雪运动基地、滑雪度假小镇为支撑的冰雪主题旅游度假区,推动区域文化旅游产业迈出新步伐。区域协同推动长城、大运河国家文化公园建设,深入挖掘长城、大运河历史文化资源,整合旅游观光线路,提升区域文化旅游产业品质。
通过与2020—2021年发布的“京津冀文化和旅游协同发展工作要点”进行比较,采用的基于时序主题关联演化的报纸新闻文本分析结果与政府制定的相关政策的主要内容相吻合,进一步验证了方法的有效性。
4 结论
以2014—2020年中国主流报纸媒体有关京津冀协同发展的147 299篇新闻文本为研究对象,采用数理统计、文献计量和基于时序主题关联关系演化等研究方法进行数据分析,得到如下结论。
(1)京津冀协同发展上升为国家战略以来,中国主流报纸媒体围绕京津冀协同发展的报道,按时间趋势划分为快速提升(2014)、持续高潮期(2015—2017)、平稳发展(2018—2019)和逐步衰退(2020年)4个阶段,并依据文献计量领域的布拉德福定律确定了报道京津冀协同发展领域的核心报纸群。
(2)基于LDA主题建模,采用基于困惑度和主题相似度相结合的指标确定主题的最优数目,挖掘京津冀协同发展主流报纸媒体报道的十大主题类分布,计算出各主题类的主题强度,通过主题词分布对主题类进行了分类分析。
(3)采用基于时序主题关联演化分析方法,按年度划分时间片,获取时序主题和子主题的关联关系。以“京津冀文旅产业协同发展”主题为例,通过全局主题、时序主题与子主题的关联关系,对文化旅游产业的主题演化关系进行了分析,进而验证了所采用信息分析方法的有效性。
综上所述,研究结果对深化国家战略政策新闻文本内容分析、把握政策事件发展的特点与规律,对于政府决策和管理,提供理论参考和依据。重点围绕“京津冀文旅产业协同发展”主题开展了主题内容和演化分析,在后续的工作中还需要开展其他主题的深入研究。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
海峡姐妹(2020年4期)2020-05-30
活力(2019年15期)2019-09-25
汽车文摘(2019年3期)2019-03-04
商周刊(2018年19期)2018-10-26
档案管理(2014年6期)2014-10-30
声屏世界(2014年9期)2014-02-28
