
基于特征选择及机器学习的犯罪预测方法综述
2021-10-21 05:11:08张天祎冉义兵
科学技术与工程 2021年28期
魏 东, 张天祎*, 冉义兵
(1.北京建筑大学电气与信息工程学院, 北京 100044; 2.北京市科学技术委员会建筑大数据智能处理方法研究北京市重点实验室, 北京 100044)
随着经济改革的日趋深入,各类犯罪数量居高不下,犯罪手段与规模也在迅速发展。各类案事件犯罪(如网络犯罪、吸毒贩毒、抢劫盗窃、冲突纠纷、电信诈骗等)整体呈现出“高发低破”的态势[1]。例如,近几年犯罪量呈小幅下降趋势的毒品犯罪案引发的社会问题仍不可小觑。据中华人民共和国最高人民法院发布的2020年司法数据显示,2020年中国共破获毒品犯罪案件量高达6万余起,缴获毒品量超过55 t,捕获犯罪嫌疑人9万余名,相较于2019年分别下降了22.9%、14.8%和18.6%,但毒品犯罪势态仍较为泛滥。与此同时,犯罪类型结构随着时代革新也在逐渐发生变化。目前以互联网、电信等为媒介的非接触性犯罪正逐渐增多,传统犯罪加速向网络空间蔓延。据统计,2020年中国检察机关起诉涉嫌网络犯罪14.2万人,同比上升47.9%[2]。网络犯罪案件作案手段多样,犯罪形式隐蔽,特别是利用网络实施的诈骗和赌博犯罪持续高发,据司法数据显示,30%以上的网络犯罪案件涉及诈骗罪及非法买卖、盗窃、贩毒等多类案件,使犯罪防控工作面临着新的挑战[3]。
“日常活动理论”是古典犯罪学中的一种理论[4],该理论将引致犯罪的要素归为三项:具有犯罪动机的人、适合的目标及犯罪监管力的缺乏,当同时满足这三要素时,将造成犯罪发生在特定区域的概率增加。为解决犯罪和恐怖活动防控问题,中外多个研究机构正在开展犯罪行为预测方面的研究,从而构建犯罪预测模型。犯罪预测模型是在建立犯罪历史数据间关联性的基础上,充分汲取罪犯及受害人提供的信息[5],实时采集和分析视频监控[6]、通信、网络等各类数据,通过数据处理和机器学习等算法将犯罪从发生到发展的全过程进行还原复现,从而达到全面反应犯罪趋势的效果。因此,犯罪预测模型具有巨大的应用价值和研究价值。
为此,主要回顾了目前中外犯罪案事件建模和预测领域的研究成果,在全面综述案事件预测系统领域的最新研究成果的基础上,归纳整理了预测各类案件所选取的特征属性,分类分析了不同特征适用的建模方法,并对比了其预测性能的优劣势,通过系统论述现有研究成果中对犯罪信息的利用及处理方法方面存在的理论与技术挑战,对未来研究方向进行了展望。
1 犯罪预测方法综述
犯罪预测可根据警方的不同需求分为宏观预测和微观预测两类。宏观预测主要为公安机关制定各类政策以及统筹规划服务,而微观预测则通过案事件预测的手段,为特定时间和特定地点内的警力资源分配调控,以及为决策人员提供数据支持服务[7]。案事件预测方法主要分为两大类:一类是传统分析方法,指的是将犯罪数据按照嫌疑人特征、时间特征、犯罪地点特征等进行数量统计比较,并结合犯罪学理论相关方法进行分析和预测。传统分析方法多采用关联规则挖掘算法实现,通过支持度和置信度进行规则的筛选[8];另一类是经验模型法,指的是基于机器学习的方法,训练模型模仿人类决策策略进行预测,通过分析时间、位置、车辆、地址、物理特征和财产等因素,基于决策树[9]、神经网络[10]、支持向量机[11-12],以及针对犯罪预测研究的自适应调整[13]等算法进行建模,并实现线下犯罪预测;此外,对于线上犯罪,犯罪关联[14]、聚类[15]和用于研究网络平台犯罪文本信息的非结构化数据情绪分析[16]等算法能够进行网络犯罪行为预测,并揭示利用互联网传播非法信息或恶意代码的网络罪犯身份。
1.1 传统分析法
传统分析法在判断犯罪案情时,通常需要借助数据统计、统计比较、关联规则分析等方法。传统分析法在犯罪决策时所涉及的犯罪学和统计学方法如图1所示。

图1 传统分析法犯罪决策所涉及内容Fig.1 The contents involved in crime decision by traditional analysis method
但在实践过程中发现,犯罪案件的形成往往受到各方面因素的共同作用,而传统分析方法无法做到实时统筹分析各类影响因素对犯罪的影响及其相互间的作用,从而影响预测效果。如海量实时更新的数据无法做到即时采集及归纳整合、预测对象不可控、无法准确预测犯罪等[17]。因此,在大数据时代传统分析法不适合广泛使用,需要借助经验分析法进行改进更新[18]。
1.2 经验分析法
经验分析法,是以侦查人员的经验知识为基础,以机器学习算法为手段,建立犯罪预测系统[19],其核心是在建立犯罪数据间关联性的基础上进行数据信息的预测[20]。经验分析法能够评估复杂的异质数据,通过逐步将一线执法人员的经验和犯罪学理论转化为机器可处理的特征,能够更有效地利用专家经验,从而提高预测准确性[21]。
如图2所示,经验分析法的研究方向主要分为两类,即经验模型和时空模型,前者侧重于对犯罪特征及相关属性进行研究,后者则重点分析连锁犯罪案发地点及整个时间轴之间的联系。
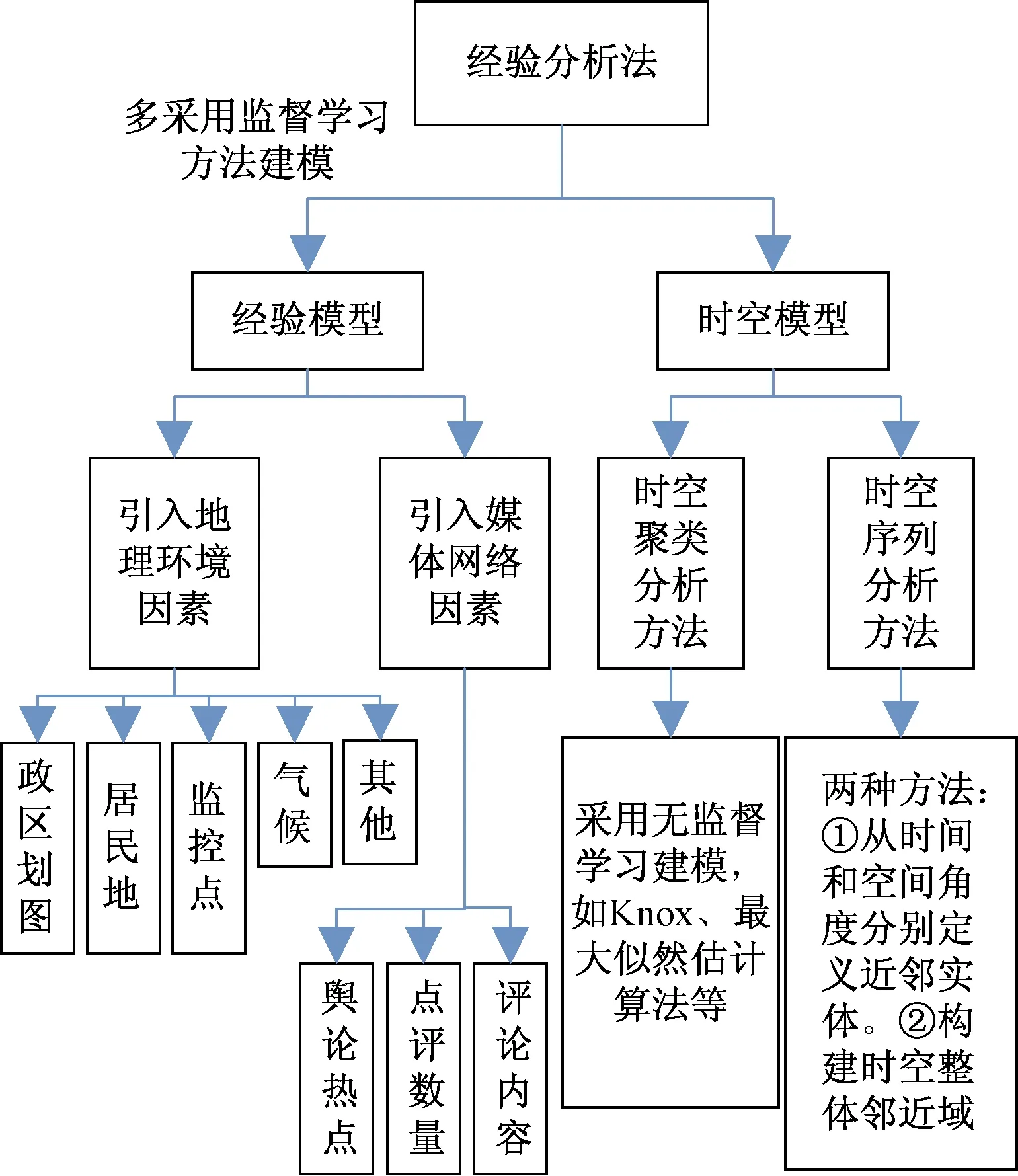
图2 经验分析法分类Fig.2 Empirical analysis classification
2 模型特征选择
犯罪预测系统可对所收集到的数据进行研判,如表1[22-29]所示,并预测出犯罪热点地区,从而能够指导公安机关分配更多的警力资源来应对该地区潜在犯罪高发的风险。
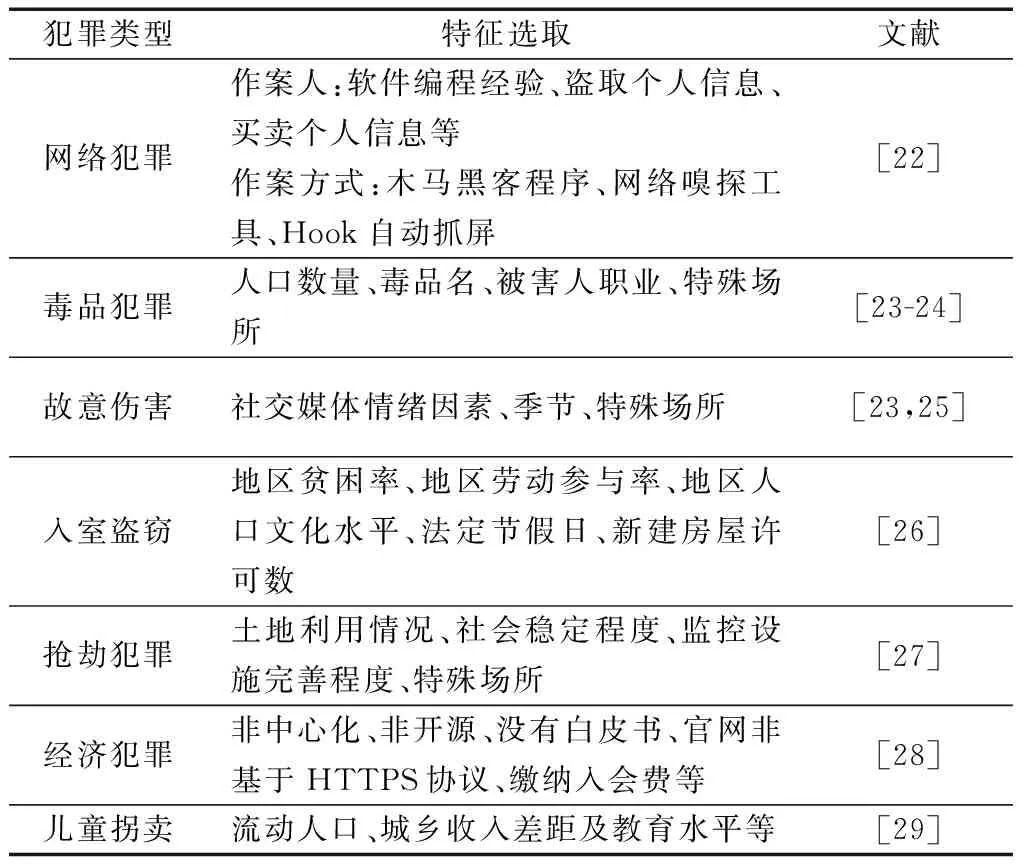
表1 常用犯罪特征选取[22-29]Table1 Selection of common criminal characteristics[22-29]
随着预测系统在公安日常工作中的快速普及,犯罪预测建模已然是近几年的研究热点。指挥官利用时间、地形、气候及周围环境因素对犯罪发生的可能性进行预测,并将警务预测分析与实践进行有机结合至关重要。Anneleen等[30]证明了两周一次与每月一次的昼夜预测差异对最终的预测性能有决定性的影响。因此,模型需要根据应用背景的具体情况来调整特定的方法。
3 经验模型研究分析
对于经验模型而言,在利用基本犯罪特征(如作案人特征、人口属性及社会条件等)的前提下,将其按照引入新特征的不同分为融合基本地理特征模型[31]和媒体网络信息模型[32]两大类。研究人员多采用有监督学习方法建立此类模型,有监督学习在训练集中识别事物并寻找规律后,为测试样本中的数据加标签并使用所得规律进行识别[33]。经验模型即利用现有的经验知识来识别犯罪事件,无需利用模型寻找数据集中的规律性,因此使用有监督学习便可达到预测目的[34]。
3.1 融合地理特征的预测模型
犯罪场所论与边界带理论认为,作案人思维中由住所位置、工作(或学校)地点和商业购物消费圈构成的三角区域的犯罪地图,是其选择作案场所的重要依据[35]。基于地理特征的方法专注于作案地点周围环境以及气候等环境因素,对案件发生的概率进行预测[36]。现有基于地理特征分析预测犯罪的模型,主要以警用地理信息系统(police geographic information system,PGIS)、犯罪地理目标模型(criminal geographic targeting,CGT)及其衍生模型为代表。
PGIS将空间关系纳入犯罪预测时,现有成果往往利用PGIS,在建模时适用空间自相关方法进行犯罪数据的聚类和回归分析,最终得出犯罪案件或犯罪主体及客体的分布聚集性热点地带[37]。然而,城市犯罪数据的非高斯分布和多重共线性特征,导致传统PGIS处理后的犯罪信息覆盖率及数据精度较低,为解决该问题Wang等[38]利用最小绝对收缩和选择算子(least absolute shrinkage and selection operator,LASSO)模型量化特征参数对犯罪的影响。此外,为了服务于不同的警种任务,研究人员仍需在PGIS系统基础上进行多功能开发。如连环犯罪事件,作案人会在重复性犯罪行为中显露其思维定势,产生犯罪行为的类似性[39],而传统PGIS系统缺乏考虑其关联性。
CGT是一种基于地理信息系统的时空分析方法,根据犯罪地点或其相关地点在时空分布上存在的规律,分析推断出最有可能发生下次犯罪的位置。方嘉良等[14]利用此模型预测连环案件嫌疑人落脚点,并在此基础上采用分段距离递减函数模拟罪犯行为路径,在此基础上采用灰色关联分析方法[40]对犯罪系统发展事态进行定量描述。李新光[10]以CGT为基础,结合模糊反向传播(back pro-pagation,BP)神经网络和元启发式算法,将作案环境分为3个模糊集,将搜索区域面积增加到优化前的3倍的同时命中率提高了至少6%以上。
而天气因素作为基本地理因素常被研究人员所忽略。研究发现暴力犯罪的发生概率与气温呈正线性关系,从而证明了天气因素,尤其是温度特征,是导致罪犯产生犯罪行为的重要影响因素之一[41]。从历史犯罪数据分布来看,某些时间节点会导致犯罪数量趋势出现或大或小的波动。Sherry等[42]采用自助抽样法调用线性回归,并利用Box-Cox变换对异方差进行校正,分析日常犯罪数据发生率,研究结果证实,引入天气属性可以提高模型短期预测能力,并指出各类犯罪率均依赖于一年之中的特殊时间点,如节假日和工作日。
3.2 融合社交网络信息的控制模型
随着社交网络用户数量的快速增长,数据平台中积累了广泛的信息资源,这些数据隐藏的信息可能会促使犯罪的生成,或暴露犯罪意图及动机[43-44]。对于犯罪预测而言,研究人员能够通过不同的社交平台获取特定公共群体的数据来提高模型的预测能力。用于犯罪预测的社交媒体数据主要从Twitter平台数据集中获取,公开的人群数据可以指导预测犯罪率的变化趋势。利用Twitter推文预测犯罪事件的流程如图3[16]所示。

图3 利用Twitter预测犯罪事件的流程[16]Fig.3 The process of using Twitter to predict criminal events[16]
Twitter数据中的文本内容可以显露出发言人积极与消极程度,从而探索犯罪趋势。因此,Johan等[45]基于Twitter上每日订阅的文本内容,采用OpinionFinder测量积极和消极情绪的程度,然后利用格兰杰因果关系分析情绪状态对犯罪行为的影响,并采用自组织模糊神经网络方法建立模型,使得犯罪系统预测准确率高达86.7%,证实了情绪可以深刻地影响一个人的行为和决策。同样,Chen等[46]利用文本分析方法研究犯罪预测,选择结合历史犯罪记录进行核密度估计(kernel density estimation, KDE),并通过逻辑回归模型得出较热天气环境下,消极的评论文字容易引发暴躁情绪,导致暴力犯罪发生较为频繁。Wang等[16]考虑到围绕网络社交媒体环境中的兴趣点,使用语义角色标注(semantic role labeling, SRL)的自然语言处理技术(natural language processing, NLP),对Twitter中的推文内容进行自动分析理解,结合隐狄利克雷分配模型(latent dirichlet allocation, LDA)识别、提取事件中的突出主题,并在该主题上建立线性回归模型,研究人员通过搜索与正面意见和负面意见高度相关的话题,能够检测出与情绪极性相关的犯罪活动。网络信息数据中描述了犯罪事件的细节,Das等[47]开发了一种增量式监督学习技术,动态地进行在线分类和统计分析,帮助执法机构在实际工作中针对不同案件类型制定犯罪预防战略。
4 时空模型研究分析
4.1 时空模型概述
犯罪模式理论认为,犯罪者通常选择他们自己最熟悉的地域,作为自己犯罪活动空间的一部分,而不是冒险进入未知的领域,并且,往往犯罪发生的时间和空间存在紧密联系[48],这就是犯罪所具有的近似重复特性。为了获得有效的犯罪预测模型,并对每一种数据特征进行分析,研究人员引入深度学习方法利用多个计算模型对这些种类繁多的数据进行处理,对于彼此之间存在关系的数据,生成更高层次的知识表示模型[49]。以犯罪学为基础的时空特征如表2[50]所示。

表2 以犯罪学为基础的时空特征[50]Table 2 A spatio-temporal feature based on criminology[50]
此外,在犯罪学研究中明确提到[51],犯罪不应该被认作随机事件,其发生会受到一些周期性因素的影响,从而使犯罪具有周期性。犯罪时空模型在学习分析离散案件点的各类因子间隔长度的基础上,深入探究案件点间内部时空自相关性,进而优化基础模型缺乏分析犯罪近似重复属性的不足。时空模型专注于对连环犯罪的整个案件链进行研究分析,以精准抓取链首案件,实现下一个犯罪案发生的时间地点预测,从而可帮助公安机关对应分配警力资源,达到高效防控的目的。
总体来说,从时空角度将犯罪预测模型进行分类,可分为四类:①单从时间或空间角度进行分析预测;②分别从时间和空间进行预测,并组合结果;③将事件和空间作为独立变量共同作为输入参数建立模型;④利用时空序列方法挖掘数据建立模型。第一种分类往往结合其他属性进行建模(见第3节),②、③类通常采用聚类方法建立模型,而相较于前3种,④类则利用时空序列模型更好地顾及了时空自相关性和时空异质性(见4.2节)。
4.2 时空聚类分析方法
4.2.1 时空聚类分析方法原理
时空聚类分析对于揭示犯罪的变化规律、发展趋势及本质特征具有至关重要的意义[52],其旨是一个无监督分类的过程,其根据相似性准则将时空犯罪案事件划分成一系列较为均匀的时空簇,如图4[53]所示,同一簇内犯罪案事件的相似度要尽可能大于不同簇间的相似度,从而分析时空纬度中案件与案件间的相互作用,能够准确识别犯罪时空近似重复模式[54],并确定出控制和预防犯罪发生的最佳点,能够为公安机关警力部署工作提供有力依据。在研究自相关性显著的连环犯罪案件类型时,该类模型性能表现突出。
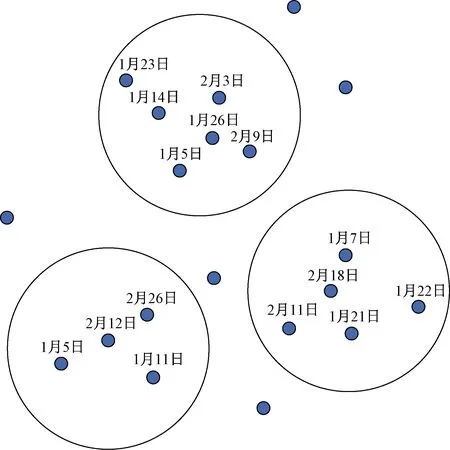
图4 2016年犯罪时空簇示例[53]Fig.4 Examples of crime clusters in 2016[53]
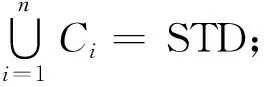
4.2.2 时空聚类分析方法的应用
对在数据预处理阶段构建时空交互多维框架,是犯罪时空聚类分析的常用方法[55],将空间密度聚类在时空域上进行扩展,其采用密度作为犯罪案件间相似性的度量标准,将时空簇定义为一系列被低密度噪声分割的高密度连通区域。随着城市中两个区域地理距离的增加,区域间在一定时间段内的犯罪差异有增大的趋势,采用时空邻近域估计时空犯罪案事件的密度。同时,框架中可以根据需求选择不同的时间颗粒,如小时、日、周、月等。时空聚类框架工作流程如图5[56]所示。
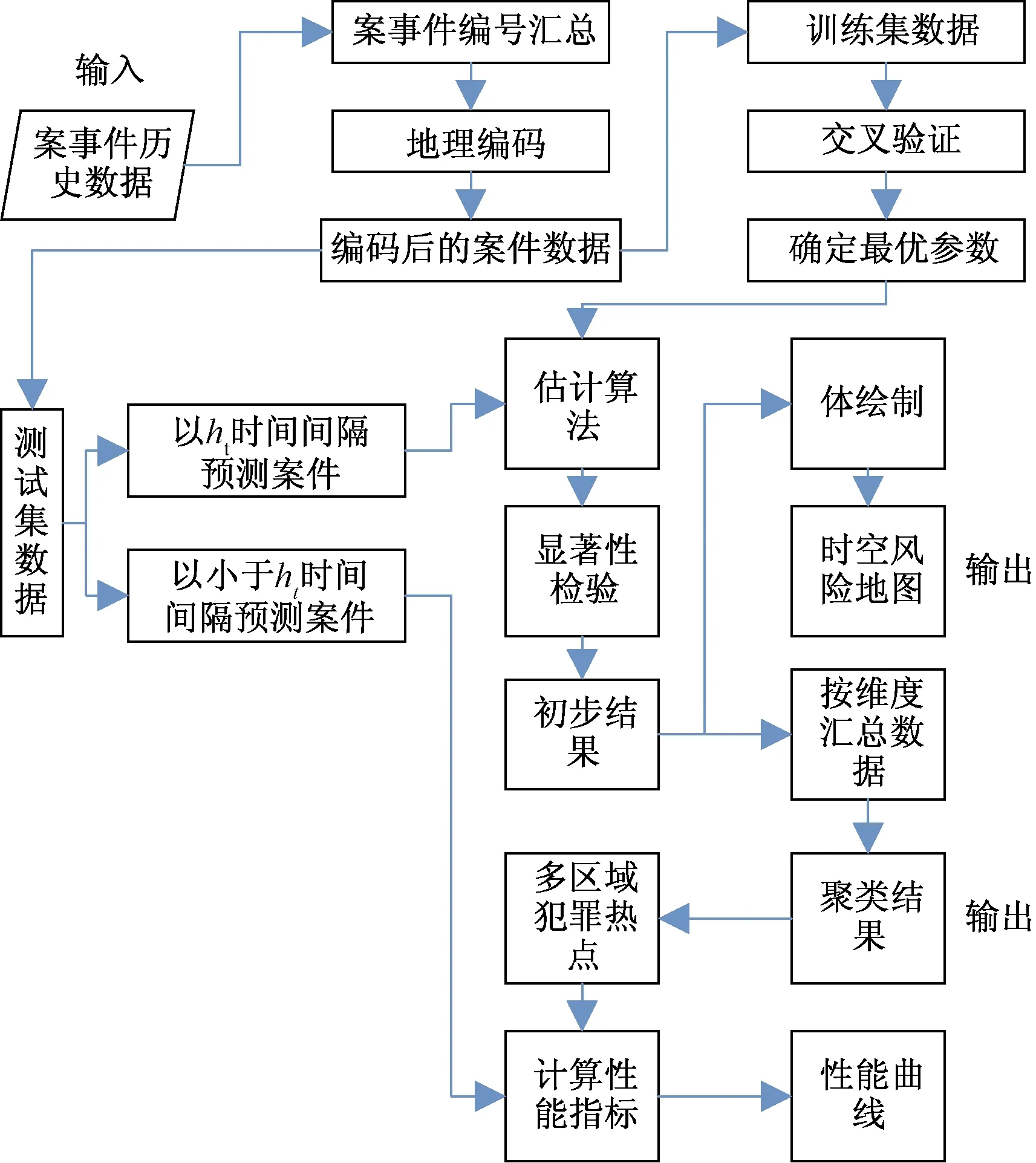
ht为基于不同时间颗粒单位下设定的时间间隔长度图5 时空聚类框架的工作流程[56]Fig.5 The workflow of the spatio-temporal clustering framework[56]
针对不同警务应用,研究人员将预处理所得时空数据输入到对应算法模型中。为研究犯罪地图中各个位置上的热点属性,Pukhtoon等[39]按犯罪持续时间长短细分为长期热点和动态热点,结合长短期的核密度估计,发现了长期热点是热点地图的主要组成部分。针对研究盗窃案时空热点分布规律和形成问题,李欣竹等[8]将模拟退火的遗传算法引入到犯罪时空框架中,并通过交叉变异的方法筛选出案发时空分布密集性较高的区域,最后采用时空热点矩阵法对分布成因进行了关联规则的结果分析。Chandra等[57]利用动态时间规整(dynamic time warping, DTW)和Minkowski参数模型的方法,在不同犯罪地点的不同犯罪序列中寻找相似的犯罪趋势,并将这些信息用于预测未来犯罪趋势。在此基础上,Li等[58]证明了DTW用于度量连环案件特征相似性的优势,并结合信息熵方法精确识别相似的犯罪行动及犯罪对象特征,从而获取全面的作案过程相似性特征。
4.3 时空序列分析方法
4.3.1 时空序列分析方法原理
西方环境犯罪学中“二八定律(80/20 Rule)”指出,将近80%的犯罪通常发生在很小的一块地区或时间段内,且仅与20%的作案者或案件相关[59],这说明犯罪热点分布及形成存在规律性和关联性,该研究基于犯罪热点形成特点及时空序列规律,得到完整的犯罪链预测模型。公安机关根据时空序列规律,在犯罪将要发生的区域,加强巡逻工作,重点部署警力资源,达到精准防控犯罪的目的。
当定量的时间序列在空间上存在相互影响时[60-61],表明这些时间序列具有时空依赖性,便可称为时空序列[30],时空序列混合预测建模过程如图6所示。
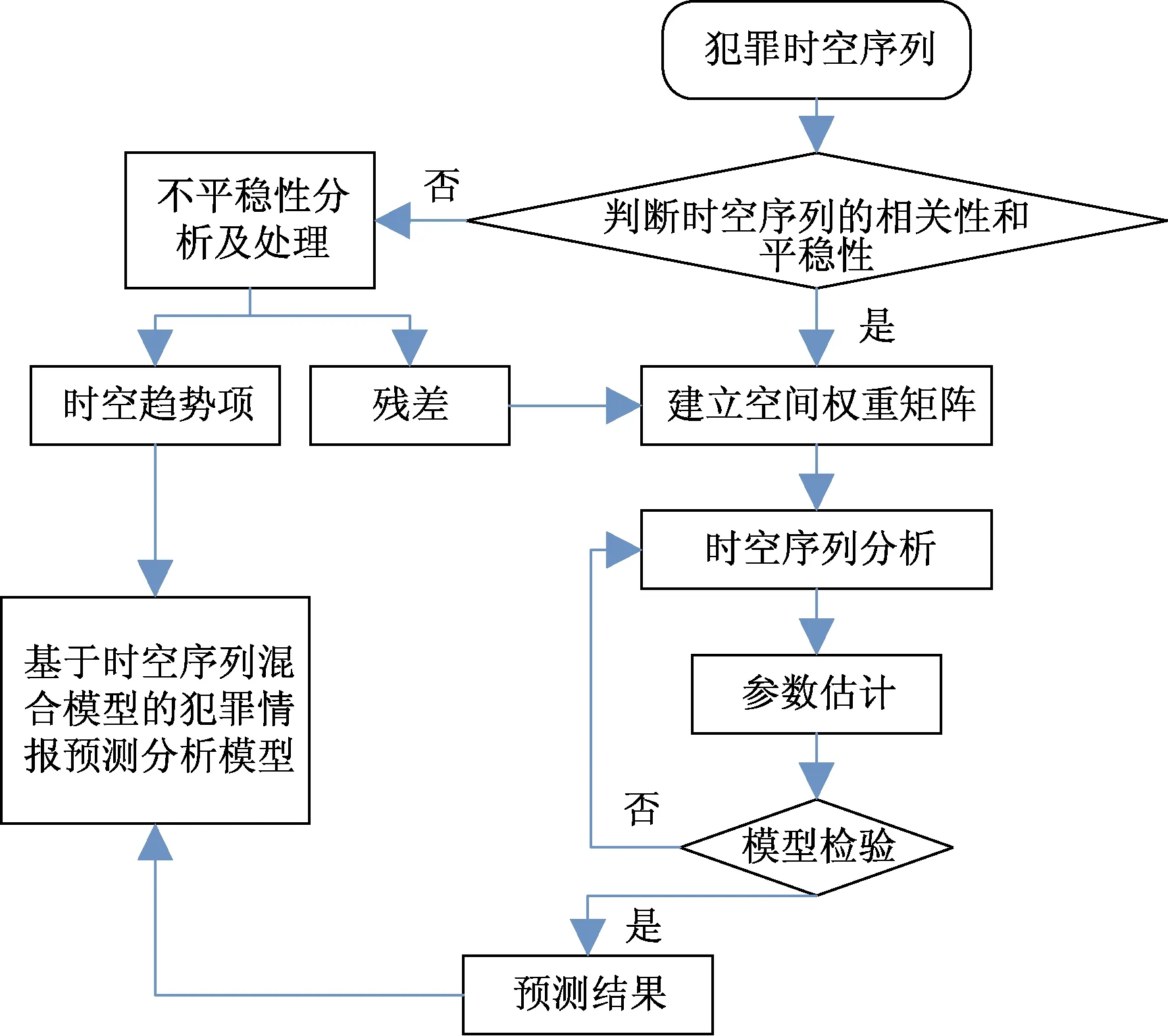
图6 时空序列混合模型的建模流程图Fig.6 Modeling flow chart of spatio-temporal sequence hybrid model
通常犯罪历史数据中都有犯罪时间点及地点的记录,所以可以用时空序列的方法进行分析,避免单独分析时间特征和空间特征后再进行结果的组合而带来的在时空域中结果不适用的可能性[62]。犯罪案事件除了自相关性外,还具有时空异质性和时空尺度依赖特性。其中,时空异质性表示犯罪时空变量的统计特征随时间和空间的演变而变化的;而时空尺度特性表示犯罪时空数据在不同的时空粒度上所遵循的规律及表征不尽相同,利用上述特性探寻犯罪规律。在时空序列方法建模过程中,时空数据在大尺度上表现出犯罪区域性的总变化,受系统性的大范围因素影响;而在小尺度上,受局部变异的随机因素影响,可以捕捉到犯罪细节信息;同时兼顾犯罪时空数据在这两种尺度上的变化特征,全面地综合时空维度中数据局部和整体两个层次的特征渐变规律[63]。
犯罪时空序列在两类空间尺度下可表示为

(1)
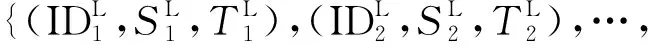
(2)
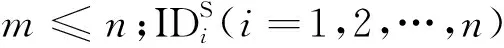
4.3.2 时空序列分析方法的应用
现有的犯罪时空序列预测建模方法大多是在传统时间建模的基础上,结合犯罪数据的时空典型的时空序列分析方法有时空自相关移动平均模型、长短期记忆网络(long short-term memory, LSTM)及其衍生方法。
时间循环神经网络LSTM模型常用于城市网格化管理预测案件数量,对此陈栾杰等[22]分别采用Box-Jenkins、Auto-ARIMA和LSTM 3种模型进行实验对比,发现LSTM模型预测精度较为平稳,可调节参数多利于优化。LSTM模型能够较好地预测日盗窃犯罪数量的变化趋势,但其对数量波动较大时段的预测效果不佳[64]。因此,黄娜等[65]提出了一种基于改进LSTM的犯罪态势预测模型,在预测过程中利用实际数据自动修正网络,与依赖先前时间步长的预测值进行滚动预测方法相比,预测结果的均方根误差平均值降低了57.33。
时空自相关移动平均模型是一个线性模型,刘美霖等[66]针对其只能对平稳的时空序列进行建模的不足,从算法结构入手,结合神经网络预测犯罪变化趋势,该混合模型处理了传统STARMA模型数据的不平稳性[67],添加了非线性功能,从而提高了模型拟合的精准性,并且预测时间单位可根据实际需求及时进行调整[68-69]。从优化线性函数角度入手,王尚北等[70]基于样本数据驱动的空间权重矩阵建立方法,将建立空间权重矩阵转换为求解位置系数方程,以非线性函数代替线性组合,从而弥补了时空自相关移动平均模型的不足之处。刘宵婧等[71]将地理加权回归(geographically weighted regression, GWR)和时空自相关移动平均模型结合,综合考虑访问时空分异特征对地区检测点相应时间的影响,并描述其时空趋势。
5 展望
现阶段,研究人员致力于通过机器学习算法建立预测模型,如表3所示,分析大量与案件有关的数据,预测下一次犯罪或犯罪活动将在何处发生,这些研究主要集中在两个方面:利用历史数据判断案件的因果关系并结合决策人员经验建模(即经验模型),以及基于时间空间的发展变化规律建模(即时空模型)。警务预测模型在实际应用时,可以根据不同的侧重方向从多个视角对犯罪行为进行多维度的预测,使犯罪预测系统达到灵活应用的目的,从而有针对性地指导警务工作。

表3 建模方法对比及未来优化方向Table 3 Modeling method comparison and future optimization direction
在大数据背景下,数据的范围不仅在横向上聚拢,也在纵向上逐渐深化,执法机构利用数据分析和建模技术来预防及应对犯罪比以往任何时候都重要。由于网络电信犯罪拥有隐蔽性和智能性的优势变得日益猖獗,对该类犯罪行为进行预测将是未来的重要研究方向。同时,目前国际形势复杂,有组织的暴力和恐怖主义有抬头的趋势,研究人员应利用移动设备和定位技术收集现代城市数据,精准预测犯罪轨迹,为犯罪分析研究提供新视角。
6 结论
当前的中外研究还存在一些共性问题,主要体现在以下几点。
(1)对于低人口密度地区的犯罪预测模型,研究人员普遍采用超集成算法进行建模,决策规则依赖于数据驱动,而缺乏理论解释性,因此不适用于测试个体特征对预测性能的影响。在未来研究无监督学习的领域中,可以进一步探索高度不平衡分类的其他方法,如奇异值探测和离群点检测,此类方法不受离群值的影响,在观测中检测异常是研究的重点。
(2)对于研究样本数量级较小的犯罪类型,由于数据限制无法以年为单位进行时空分析,随着时间的推移,犯罪趋势变化小。例如仇恨犯罪,在未来的研究中可以额外考虑添加种族、经济和社会变量来扩充样本容量,使用离散全球网格系统(discrete global grid system, DGGS)将仇恨犯罪的点级数据引入数据框架中相关联后采用空间回归分析方法[74]。
(3)研究人员对网络平台数据的利用普遍拘泥于标记词性和情绪主题建模方面,而缺少对网络平台数据文本内容的分析,在未来研究中,研究人员可以尝试深度挖掘文本的语义进而提高预测模型的性能,例如,可通过分析推文的述词论元结构来提取案件信息和案件参与者。未来可以将成熟的新闻分析程序应用于Twitter文本,研究Twitter内部的各种网络结构(如follower-followee和@-mentions)[43]等。同时,该方法也可以应用于其他微博类网络平台,如新浪、腾讯、网易等。
(4)在犯罪相关性分析中,为保证分析的全面性,研究人员可能会选择较多特征作为模型输入,这会导致分析过程的难度和复杂性增加。由于犯罪概率与其影响因子间具有一定的相关系数,因此在未来的研究中,可以尝试利用主成分分析法[75]在保证尽可能多的保留原始变量所反映的信息的前提下,用较少的新变量代替原变量。
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
学生导报·东方少年(2019年8期)2019-06-11 11:53:54
作文大王·低年级(2018年10期)2018-12-06 06:22:44
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
法哲学与法社会学论丛(2016年0期)2016-04-19 02:07:30
湖南警察学院学报(2015年2期)2015-08-24 01:44:12
