
面向能源互联网终端用户的异常数据检测方法
2021-10-20 02:11户艳琴李海明刘念傅皆恺黄天翔李承霖李珂舟胡志强范志夫邬小可
电力建设 2021年10期
户艳琴,李海明,刘念,傅皆恺,黄天翔,李承霖,李珂舟,胡志强,范志夫,邬小可
(1.国网江西综合能源服务有限公司,南昌市330096;2.新能源电力系统国家重点实验室(华北电力大学),北京市 102206;3.国网江西省电力有限公司,南昌市330077;4.国网江西省电力有限公司鹰潭供电分公司,江西省鹰潭市335000)
0 引 言
随着互联网理念的不断深化,一种新型能源体系架构——“能源互联网”应运而生[1]。能源互联网结合互联网信息技术与能源利用技术,为终端用户提供灵活多样的能源共享服务[2-3]。此外,能源互联网的发展,增加了能源系统中的数据采集量,提高了其信息共享程度,为基于大数据分析技术解决能源系统中的问题提供了数据基础。若能源互联网终端发生用电异常情况,将会增大系统的电能损耗,降低能源利用效率,因此需要对终端用户进行异常用电模式检测,从而便于电网公司及时发现用电异常的情况,减少电网的经济损失,降低窃电行为的发生率[4]。
传统的终端用户异常用电模式检测方法是现场人员定期巡检线路、定期校验电表、用户举报等,但这些手段对人的依赖性较大,需要投入大量的人力成本,同时,用电模式的检测耗时较长、效率较低[5]。此外,用户的窃电手段多种多样,传统的异常用电模式检测方法难以准确地判断用户用电是否正常,亟需检测精度较高、耗时较少的轻量化的异常用电模式检测方法。
目前,对于异常用电模式检测的研究主要分为基于系统状态和基于人工智能2类方法。基于系统状态的分析方法是通过实时比较配电网的功率、电压、电流等大量数据的变化来检测异常用电模式[6]。文献[7]通过对用户日用电量和日线损电量数据进行批量处理及相关度分析识别台区用户窃电行为,从而实现用户异常用电模式的检测。文献[8]中综合对比分析同期线损、用电负荷、日用电量、电流及有功功率等电量信息,实现用户异常用电模式的精准检测。然而用户侧具有海量且多元的用电数据,异常用电模式也多种多样,基于系统状态的检测方法需要较长的检测时间。为了缩短检测时间并提高检测精度,逐渐出现了基于人工智能的异常用电模式检测模型,该模型首先通过数据分析提取可以反映异常用电模式的指标,再借助人工智能的方法训练指标与用电模式检测结果之间的映射关系,完成异常用电模式检测模型的构建。例如,借助主成分分析实现大量负荷数据的可视化,构建了无监督学习的异常用电模式检测模型[9];以正常用户用电数据为训练样本,采用自编码网络学习数据特征,重构输入数据以计算检测阈值,基于此建立了对比误差与检测阈值的异常用电行为辨识模型[10];利用时间窗函数与Bootstrap重采样建立用户侧行为模式信息簇的随机森林模型[11]。文献[12-13]采用极端梯度提升(extreme gradient boosting,XGBoost)算法对异常用户进行识别,从用电用户基本属性特征、不同时间尺度用电特征和不同时间尺度上用电相似性3个方面进行特征提取,但未采取特征重新构造的方法对数据进行加工处理,因此这种粗颗粒度的原始数据会限制模型检测精度的提升。为了进一步提高检测精度,2种或2种以上算法形成的组合算法被提出[14]。此外,基于图论的方法[15]、加权算法[16]、神经网络算法[17]、支持向量机[18]等也应用于用电模式检测问题中。上述方法均在特定情况下取得了不错的检测结果,但是在评价指标的选择、检测时间和效率的优化方面仍存在较大的提升空间。
为此,本文首先综合考虑终端用户用能负荷、用能损耗及告警信息等数据对用户异常用电模式的影响,构建由负荷曲线斜率指标、线损指标和告警类指标组成的异常用电模式检测评估指标体系,提出基于XGBoost的能源互联网终端用户模式检测模型。此外,为了消除无关数据及缺失数据对模型精确度的影响,在模型训练前进行数据预处理。最后通过与决策树、随机森林及Adaboost算法进行对比分析验证方法的有效性。
1 异常用电模式评价指标体系
能源互联网终端用户发生异常用电时,配电网的电气参数会发生变化,如电压、电流、线损等,根据变化的电气参数可以构建异常用电模式评价指标体系,从而便于检测异常用电的终端用户。基于采集系统中的数据,选择用户用电量、线损、终端告警情况建立如图1所示的评价指标体系。
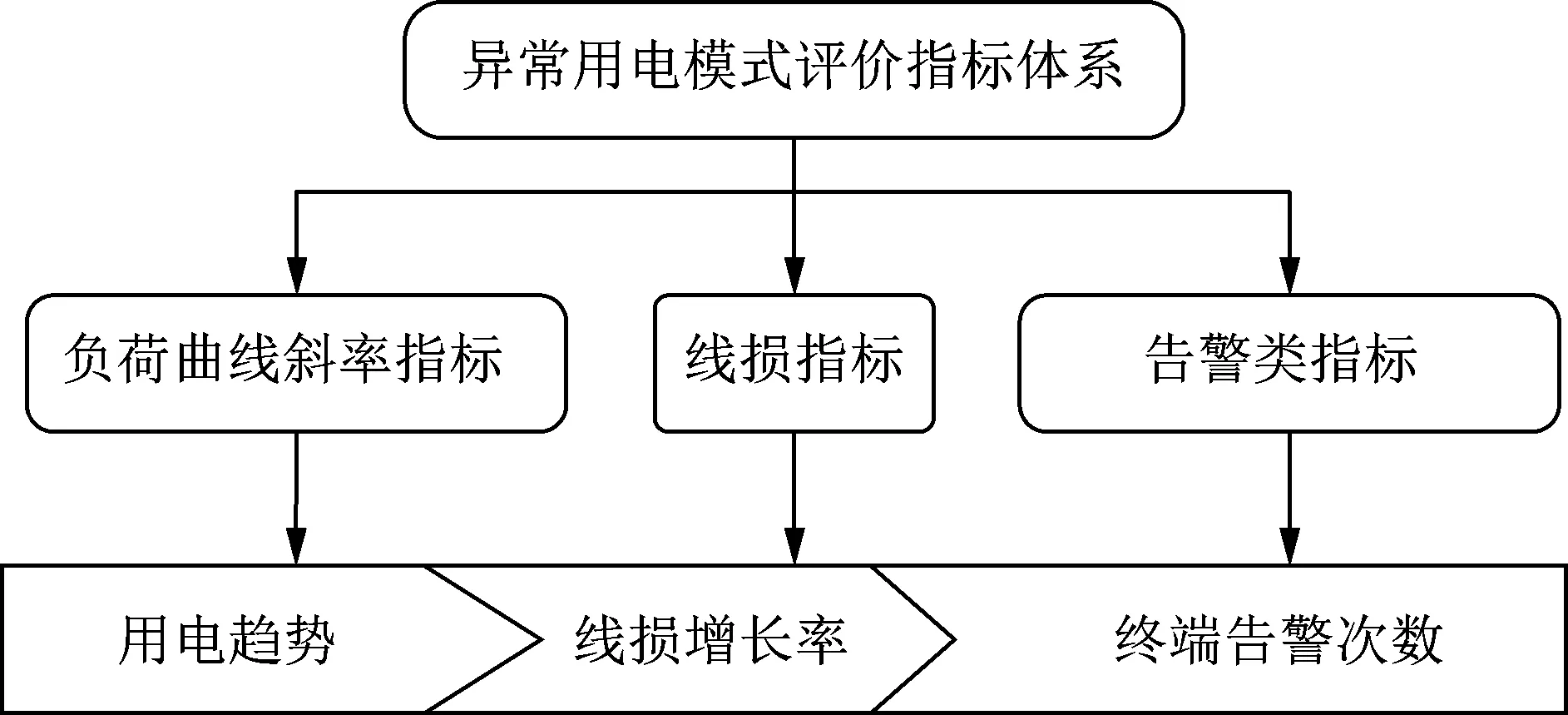
图1 异常用电模式评价指标体系Fig.1 Evaluation index system of abnormal electricity consumption pattern
1.1 负荷曲线斜率指标
由于用户的用电行为存在惯性,每天的用电负荷基本一致,一般情况下正常用户的用电量斜率接近于0,然而处于异常用电模式的用户的用电量曲线较为特殊,在异常初期其用电量持续下降,斜率随时间而减小,下降到某一较低值后,长期处于这一稳定状态。因此将用户在某一个时间段内用电量是否持续下降作为识别其是否发生异常用电行为的特征之一。计算公式如式(1)—(3)所示[5]。
(1)
(2)
(3)
式中:Kα为第α天的负荷曲线斜率;Lt为第t天的负荷,以m天为统计周期,计算包括该天在内的共(2m+1)天的负荷曲线斜率。
如果负荷曲线的斜率持续减小,则该用户具有异常用电嫌疑。对于该类用户,统计(2m+1)天中当天负荷曲线斜率比前一天小的天数,并且定义(2m+1)天的负荷曲线斜率指标为:
(4)
(5)
式中:IS为负荷曲线斜率指标;D(t)为负荷曲线斜率变化的标志,若负荷曲线斜率变小,则D(t)=1,否则D(t)=0。
1.2 线损指标
较多的可靠特征会提高基于数据的学习类算法的准确性,降低误判率,增强实际应用过程中对数据集的适应性,因此增加线损指标作为检测异常用电模式的一个关键特征。线损为电网供电量与售电量的差值,当用户侧出现异常用电时,电网供电量不变,售电量降低,导致电网的线损会出现明显增大。考虑到用电量数值差异,定义线损率为线损指标,其计算公式如式(6)所示[19]。
(6)
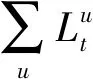
当用户侧出现异常用电模式时,线路的线损率增大。然而用户每天的用电量存在一定的波动,仅以当天线损率的增大作为异常用电特征会导致较大的误差,因此将m天的线损率平均值作为评估指标,并分别计算当天的前m天和后m天的平均线损率。定义线损指标如式(7)所示。
(7)
(8)
(9)
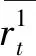
1.3 告警类指标
与异常用电模式有关的终端告警信息主要包括电压断相、电流不平衡及电能表异常等[20]。将与异常用电模式有关的终端告警次数的总和作为告警信息指标,可以有效地减少单一告警信息带来的误差。告警类指标的计算公式如式(10)所示。
(10)
(11)
式中:wt为报警的总次数;Q为终端告警信号类别总数;sq是警告信号的状态,如果有报警信息,则sq=1,否则sq=0;Iw是告警类指标;b是警告次数参考值。
2 异常用电模式检测模型
2.1 数据预处理
从用电采集系统和能量管理系统获取的数据存在部分数据缺失的问题,无法直接进行特征挖掘。为了提高数据质量,并使数据更好地适应挖掘方法,对原始数据进行数据预处理,包括数据清洗、缺失值处理及数据变换等。
1)数据清洗。
数据清洗是基于建模需要,筛选出所需要的数据。原始数据中的冗余、无关数据会影响特征挖掘过程,因此需要删除此类数据,平滑数据噪声。
公用事业等非居民用电一般不会存在异常用电模式,因此删除非居民用电类别的用电数据。对于居民用户而言,节假日与工作日的用电存在较大差异,为减小用电量差异对检测模型的影响,删除节假日的用电数据,即令m=5。
2)缺失值处理。
用电采集系统记录的数据会由于采集设备故障、传输丢包等原因存在部分缺失,若直接忽略缺失样本,会导致日线损率数据误差较大,从而降低异常用电模式检测模型的精确度。为了避免这种影响,采用拉格朗日插值法[21]对缺失值进行处理。具体方法如下:首先从原始数据集中确定因变量和自变量,取出缺失值前后的5个数据(若遇到数据不存在或者为空,直接将数据舍去,将仅有的数据组成一组),将取出来的10个数据组成一组。然后采用拉格朗日多项式插值公式进行处理,如式(12)—(13)所示。对全部缺失数据依次进行插补,直到不存在缺失值为止。
(12)
(13)
式中:v为缺失值对应的节点序号;Ф(v)为缺失值的插值结果;φh(v)为插值基函数;vβ、vh为非缺失值Vh对应的不同节点序号;N是缺失值前后取出数据样本的总数。
3)数据变换。
数据变换是指对数据进行规范化处理,即转换数据格式使之适用于特征挖掘算法。根据数据特点,可以从规范化处理和属性构造2个方面进行数据变换。规范化处理是将具有不同量纲的数据转换到同一量纲,将数据规定到一个较小的特定范围。数据规范化的方法有3种:最小-最大规范化、z-score规范化和小数定标规范化[22],这里采用操作简单的最小-最大规范化处理方法。
2.2 XGBboost算法
XGBoost能够进行多线程并行计算,在计算速度和学习能力方面都大幅提升[23]。并且XGBoost算法的损失函数根据二阶泰勒展开,具有高准确度、不易过拟合、可扩展性等特点。XGBoost还可以分布式处理高维度稀疏特征,因此,XGBoost算法优于同类算法。
1)模型输入。
将给定的包含c个属性,n个样本的数据集作为XGBoost算法的输入数据,记为:
D={(xi,yi):xi∈Rc,|D|=n}
(14)
式中:xi表示样本的特征向量,i=1,2,…,n,n为样本总数;yi表示样本的类别标签;Rc为c维特征实数空间。
2)构建提升树。
提升树是一种集成方法,XGBoost算法基于数据集D进行树的累加,每次迭代训练一棵树,并且采用CART回归树作为该模型的子树模型,一棵回归树的集合记为:
F={fϑ(x)=ωq(x),q:Rc→T,ω∈RT}
(15)
式中:q代表样本映射到相应的叶子节点的规则;T代表一棵树的叶子节点数量;ω表示叶子节点的权重;fϑ(·)代表CART树。
当完成θ棵树的训练时,基于XGBoost模型的预测值表示为:
(16)
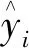
对树的训练迭代过程是相互独立的,即原来的模型保持不变,将一个新的函数添加到模型中。一个函数对应一棵树,新生成的树拟合上次预测的残差,迭代过程如公式(17)所示。
(17)
3)正则化目标函数。
XGBoost的目标函数如式(18)、(19)所示:
(18)
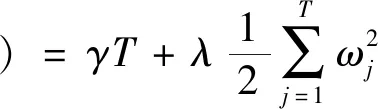
(19)
式中:l(·)是误差函数,用来衡量预测值与真实值之间的偏差;Ω(fϑ)是正则化项,用来衡量模型的复杂度,防止模型训练过拟合;γ、λ为参数,分别用来控制叶子结点的个数和控制叶子节点的权重大小。对式(18)第一项进行泰勒展开,并联立式(19),最终的目标函数只依赖于每个数据点在误差函数上的一阶导数和二阶导数,如式(20)所示。
(20)
(21)
(22)
(23)
(24)
式中:Lobj(t)为第t次迭代的目标函数;Ij={i|q(xi)=j}为节点j上的样本集合;gi、hi分别为训练误差的一阶和二阶梯度统计量。
4)节点切分算法。
XGBoost算法采用贪心算法从根节点开始,每次分裂一个节点,计算分裂后的增益并选择最大增益对应的节点。IL和IR分别是分割点左边和右边的样本集,根据XGBoost损失函数计算其信息增益:
(25)
式中:I=IL∪IR;加和的3项分别为左子树、右子树和不分割时的增益分数,当增益Gain<0时,放弃分割。
训练过程中,模型不断计算节点损失以选择增益损失最大的叶子节点。模型损失计算过程见表1。

表1 XGBoost节点切分算法Table 1 Node segmentation algorithm for XGBoost
2.3 基于XGBoost的终端用户异常用电模式检测模型
1)终端用户异常用电模式检测流程。
根据基学习器为树的XGBoost算法建立终端用户异常用电模式检测模型,其流程如图2所示,具体步骤如下所示:
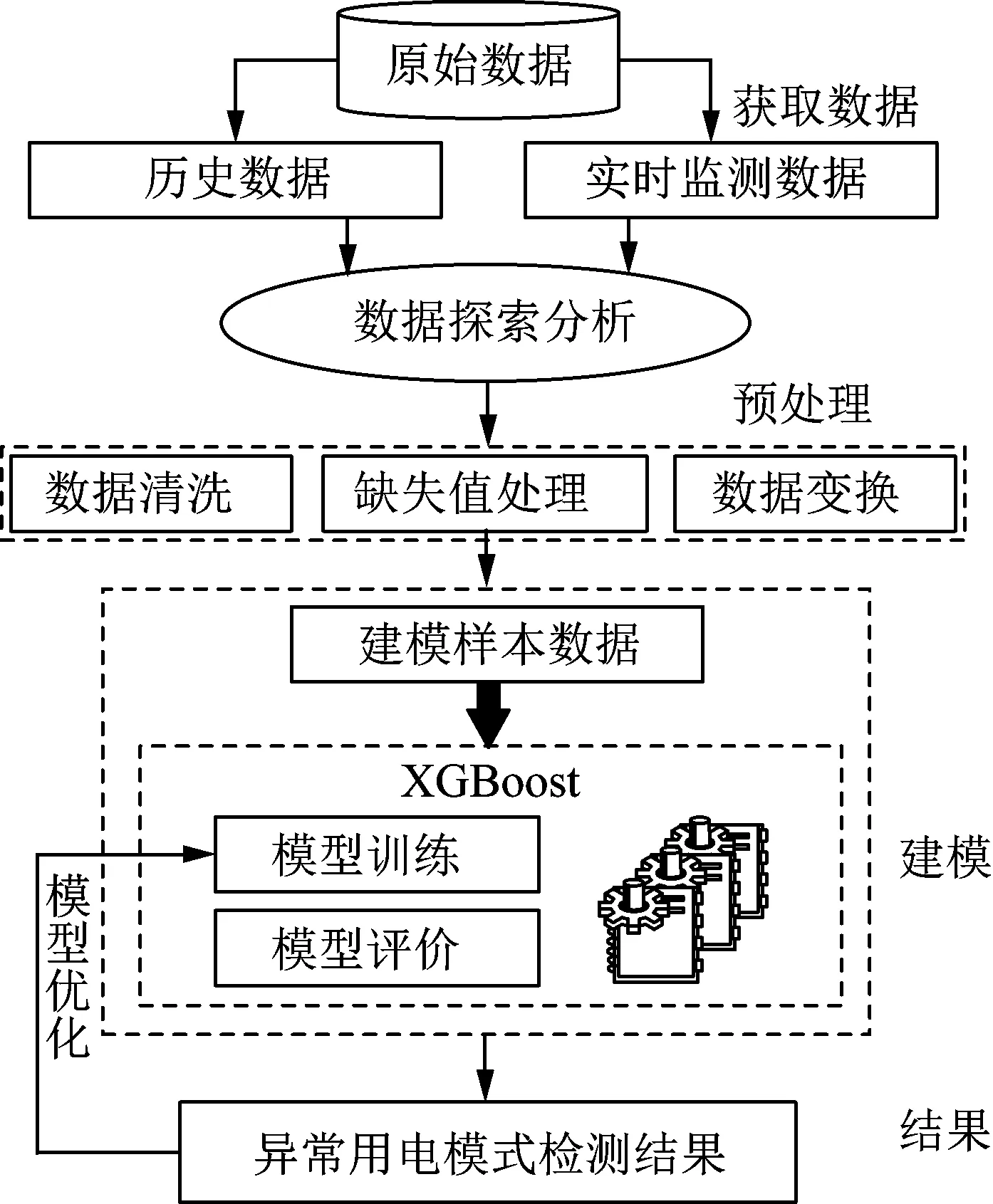
图2 基于XGBoost的异常用电模式检测流程Fig.2 Flow chart of detection of abnormal electricity consumption pattern based on XGBoost
步骤1:导入预处理后的用户数据,并将其分为训练集和测试集,训练集用来训练XGBoost异常用电模式检测模型,测试集用来评价模型的泛化性能。
步骤2:通过绘制弱学习器个数-准确率曲线,确定弱学习器个数M(迭代次数)及学习率参数。在弱学习器个数和学习率确定的条件下,通过网格搜索法来确定XGBoost子树的最大深度、样本的采样比和样本属性采样比等其他模型参数。最终得到最优的基于XGBoost的异常用电模式检测模型。
步骤3:将步骤1中的测试集输入到步骤2得到的检测模型中,输出终端用户异常用电模式检测结果,并通过绘制受试者工作特征(receiver operating characteristic,ROC)曲线来评价模型的性能。
2)准确率检验。
终端用户异常用电模式检测的本质是基于用电数据进行用户正常和异常用电行为的检测。
对于二分类检测问题,可将样例根据其真假类别与学习器预测类别的组合划分为:真正例 (true positive,TP)、假正例 (false positive,FP)、真反例 (true negative,TN)、假反例 (false negative,FN),分别用TP、FP、TN、FN表示上述4种情形。分类结果的“混淆矩阵”如表2所示。

表2 混淆矩阵Table 2 Confusion matrix
定义准确率为正确分类的测试样本的个数占测试样本总数的比例Accurary:
(26)
式中:nTP、nFP、nFN、nTN分别为TP、FP、FN、TN的数量。
由于准确率指标无法体现正例和负例的覆盖率,在一些有特殊要求的场景下,单一的准确率指标并不能够全面地表现模型的分类效果。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。而ROC曲线则不受这种变化的影响,更能反映模型的检测效果。ROC曲线的横坐标为FPR,纵坐标为TPR。其中,TPR表示正常用电的样本被正确地判断为正常的比率,如式(27)所示;FPR 表示异常用电的样本被错误地判断为正常用电的比率,如式(28)所示。
(27)
(28)
ROC曲线覆盖下的面积 (area under curve,AUC)介于0.1和1.0之间,AUC的值越大则模型的准确率越高。
3 算例分析
3.1 基础数据
本算例基于如图3所示的配电系统结构,208个用户在5年内的相关数据[24]验证所提模型的有效性。该系统包括用户层及能量管理层,首先借助用户层终端智能电表获取用户的负荷数据、线损数据及终端报警次数等信息,再将采集信息传输到能量管理层的数据接收单元,在用电异常模式检测单元训练检测模型并分析用户的用能特征,若用户用电异常,则借助用户侧开关控制单元断开该用户的接入开关,减少电网损失。
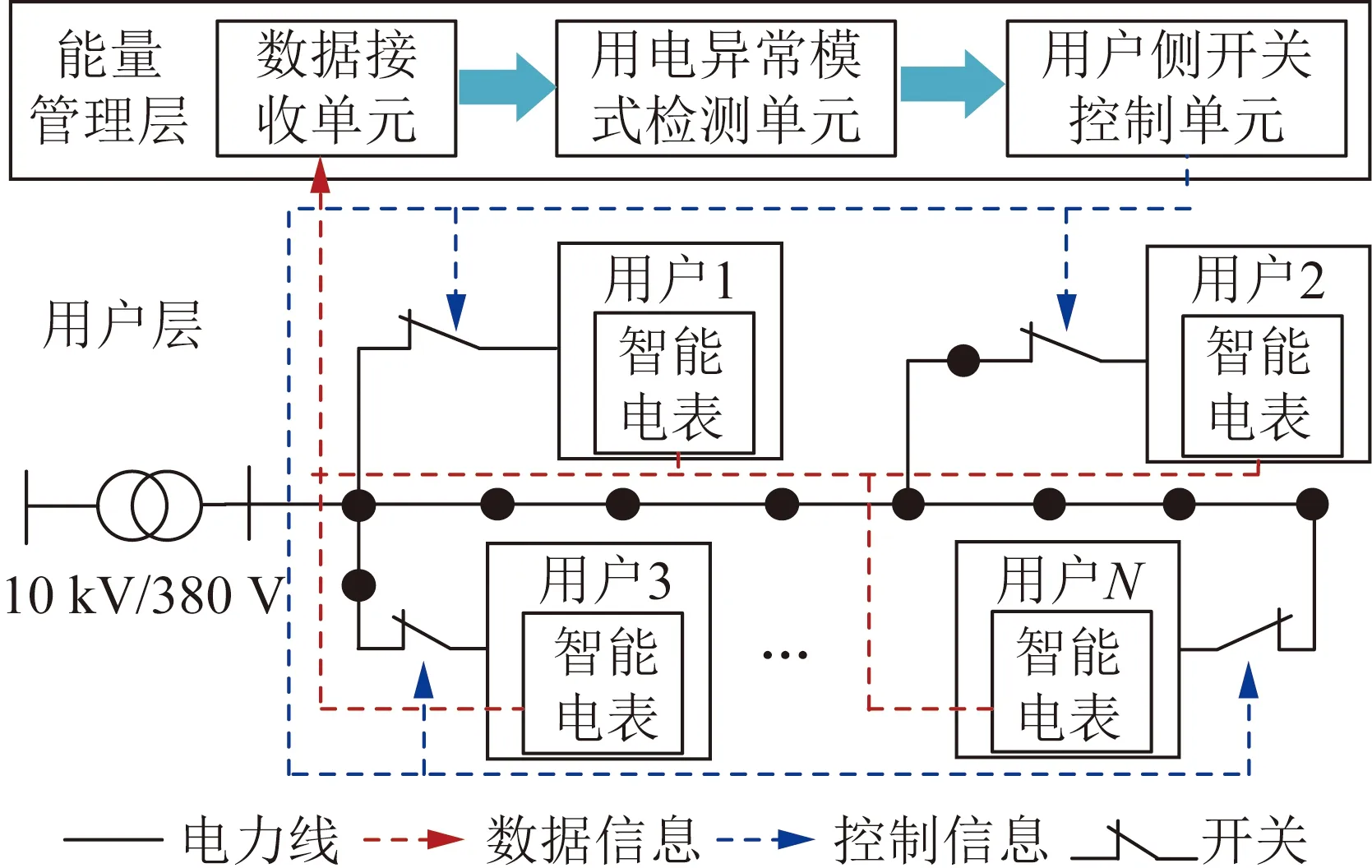
图3 配电系统结构Fig.3 The structure of distribution network
3.2 终端用户异常用电模式检测模型参数的确定
在数据预处理后的数据样本中随机抽取70%作为训练集,30%作为测试集,并且训练集与测试集中正负样本的比例均为1∶1。基于XGBoost算法的异常用电模式检测模型包含多种参数,如学习率、树的最大深度、迭代次数、样本采样比、样本属性采样比及正则化项权重比等,其中迭代次数、树的最大深度和学习率3个参数直接影响模型的准确率,因此需要调节参数以达到模型的最优效果。
为了确定检测模型的最佳学习率及迭代次数,分别令学习率为0.1、0.3、0.5、0.8和1.0,并基于训练集得到各自的准确率曲线,如图4所示。
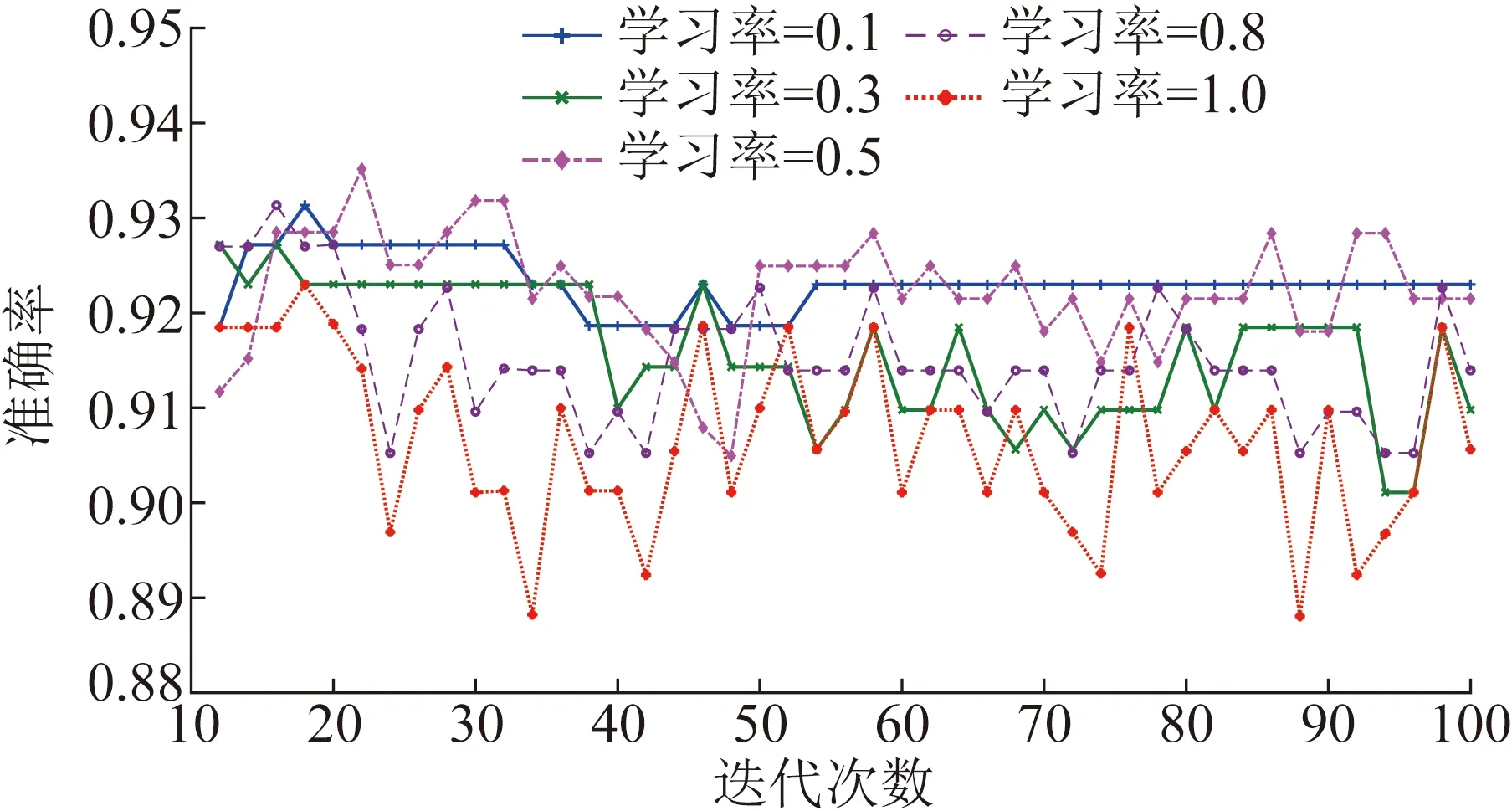
图4 迭代次数-准确率曲线Fig.4 Iteration times -accuracy curve
由图4可知,学习率为0.5时,模型的准确率最高,因此确定学习率取值范围为0.1~0.5。根据学习率为0.1、0.3和0.5的曲线可以得到,迭代次数为48时的准确率效果较好,且曲线相对稳定,考虑到训练时间与迭代次数的近似正比关系,将模型的迭代次数设定为48。
XGBoost算法在迭代每一棵树的过程中,树的最大深度是防止模型过拟合的重要参数,树的最大深度较大时会使模型更为复杂,并容易导致过拟合,延长训练时间。为了减轻调参的工作量,采用网格搜索法确定树的最大深度和其他参数的最佳值。依据训练结果得知,树的最大深度为5、样本的采样比为0.9、样本属性的采样比为1.0、正则化项权重比为5,其余参数值选择默认时,模型表现出更优的综合性能。
为了排除训练得到的模型产生过拟合现象,分别基于训练集与测试集得到异常用电模式检测模型的准确率曲线,如图5所示,训练集与测试集的准确率比较接近,从而说明异常用电模式检测模型没有被过拟合。
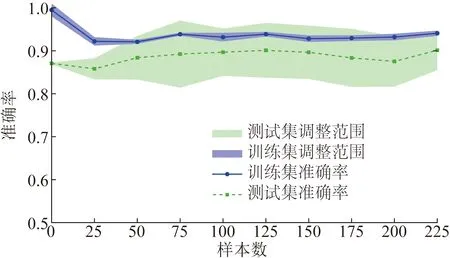
图5 XGBoost的准确度曲线Fig.5 Accuracy curve of XGBoost algorithm
3.3 终端用户异常用电模式检测模型的训练结果
通过调参过程,确定终端用户异常用电模式检测模型的最优训练参数,然后基于测试集得到检测模型检测结果及准确率。如图6所示,该模型的训练时间为8.971 ms,在测试集上的准确率达到94.915%,说明该模型具有较好的检测效果。从模型的评估报告中可以看出,模型的精确度、召回率和F1都有较高的得分。
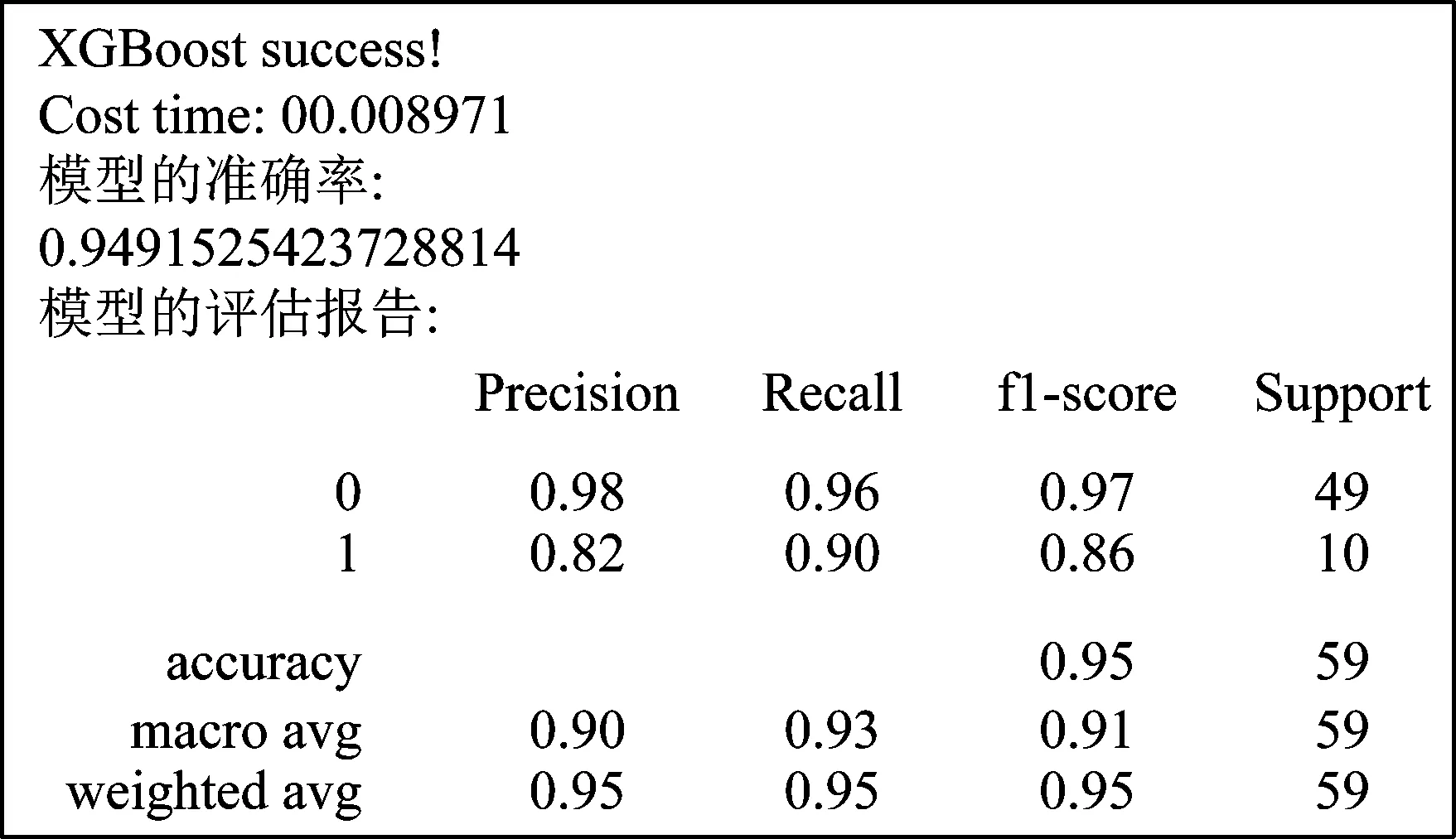
图6 训练效果Fig.6 Training effect
XGBoost算法根据结构分数的增益计算得到作为分割点的特征,并且某个特征的重要性就是它在所有树中出现的次数之和,即出现次数越多,重要性就越高。负荷曲线斜率指标、线损指标和告警类指标三类指标对异常用电模式检测的重要性如图7所示,从图7可以得出,负荷曲线斜率指标的重要性最高,其次为线损指标,告警类指标的重要程度相对较低。
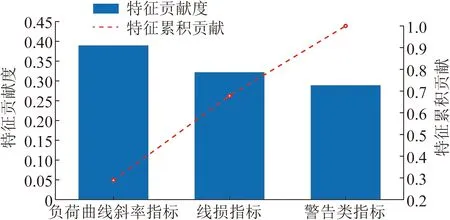
图7 特征贡献度Fig.7 The contribution of features
3.4 数据清洗前后对比
数据质量的好坏会给模型的训练效果带来一定程度的影响,而获取的原始数据存在缺失、冗余和无关数据,因此需要对其进行一定的数据清洗工作。对于大数据分析而言,数据清洗是数据挖掘的关键环节。本文通过缺失值处理、属性构造等技术对原始数据进行必要的数据预处理,并且通过比较数据清洗前后XGBoost检测模型的训练效果,来验证数据清洗工作对模型训练产生的影响。
如表3所示,经过清洗后的数据在XGBoost模型上有更好的训练效果,其检测准确度明显高于原始数据。由于清洗前后的数据样本量会发生略微改变,所以在训练时间上,经过数据清洗的模型训练时间也会低于直接使用原始数据训练的时间。
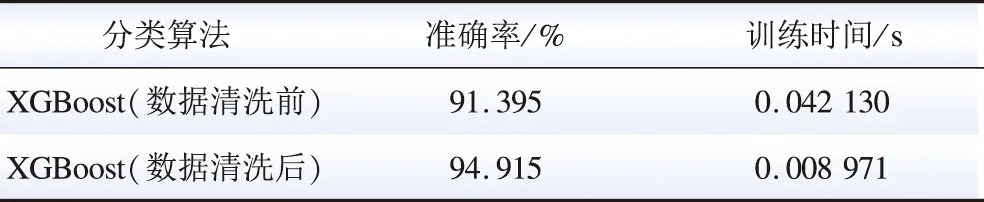
表3 数据清洗前后的测试结果Table 3 Test results before and after data cleaning
3.5 与其他算法的对比
为了验证模型的有效性,选择决策树、随机森林、Adaboost、文献[12]中的检测模型与本文XGBoost模型进行对比分析。文献[12]也采用XGBoost算法进行用户异常用电检测,但是本文对原始数据做了新的特征构造,使得离线数据在XGBoost模型上有更出色的检测效果。各算法检测结果的准确率和训练时间如表4所示,本文所提方法在测试集上的准确率为94.915%,明显高于其他4种算法;其训练时间也短于随机森林算法和Adaboost算法。虽然决策树算法的训练时间比本文所提算法短,但是其分类准确率较低。此外,本文对训练数据进行了新的特征构造,通过与文献[12]对比可以看出,本文经过新特征构造的数据在XGBoost模型上有更好的检测精度。由于文献[12]的数据样本容量较大,两者数据集存在一定差异,因此,在训练时间方面不具有比较性。通过以上对比,可以看出本文通过数据清洗和新特征构建的XGBoost异常用电模模型具有更优的检测性能。
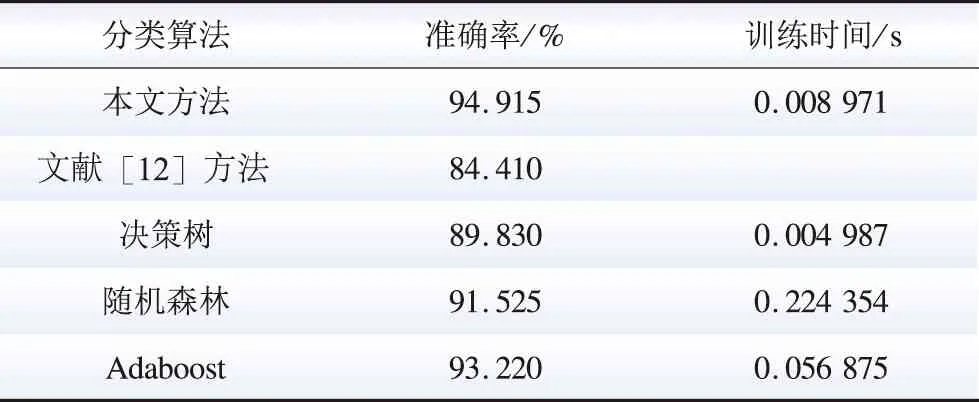
表4 5种算法的测试结果Table 4 Test results of the five algorithms
为了全面评价上述算法的检测效果,分别绘制其ROC曲线并计算AUC面积,如图8所示。由图8可知,基于XGBoost算法的异常用电模式检测模型的ROC曲线明显包住了Adaboost算法和决策树的曲线,而随机森林算法的ROC曲线和XGBoost、Adaboost算法都存在部分交叉;计算各自ROC曲线下的面积AUC值,可以得出XGBoost(0.97)>随机森林算法(0.96)>Adaboost算法(0.94)>决策树(0.87)。以上比较可以说明基于XGBoost的异常用电模式检测模型的准确性明显优于决策树、随机森林和Adaboost算法。
4 结 论
首先基于能源互联网系统采集到的大量且多元的终端数据,筛选出用电量、线损及告警次数3个特征,并建立了包含负荷曲线斜率指标、线损指标与告警类指标的终端用户异常用电模式评价指标体系,提出了基于XGBoost的异常用电模式检测模型。针对原始数据中存在坏数据、数据缺失及量纲影响等问题,提出数据清洗方法、基于拉格朗日插值法的缺失值处理方法和数据变换方法,提高了数据质量并使之适用于异常用电模式检测模型。最后,通过案例分析,验证了异常用电模式检测模型的有效性,基于与决策树、随机森林及Adaboost算法的对比,所提检测模型具有更好的检测性能、较强的泛化能力。未来将进一步挖掘影响异常用电模式检测的因素,借助多核服务器、云边结合的计算平台提高检测模型对大数据的训练速度,实现所采集数据的最大化利用。
猜你喜欢
出版人(2022年8期)2022-08-23
中国化肥信息(2021年12期)2021-04-19
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·中考版(2020年12期)2021-01-18
英语文摘(2020年6期)2020-09-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
