
非物质文化遗产的知识图谱构建*
2021-10-19 10:25:14范青史中超谈国新
图书馆论坛 2021年10期
范青,史中超,谈国新
人工智能及大数据的快速发展为非物质文化遗产(以下简称“非遗”)的传承与保护提供了平台,而如何在繁杂的数据中进行搜索,以可视化方式呈现非遗之间关联关系是研究的热点。知识图谱是非遗可视化的主要应用工具,相关技术为互联网时代的知识组织和知识关系显示提供支撑[1]。传统的知识图谱在非遗领域的应用存在不足,主要表现为信息碎片化严重、知识耦合度不高、知识关联性不强,限制了可视化的呈现效果。本文以RDF三元组为描述框架,阐释区域非遗知识结构及数据关联,为碎片化的区域非遗数据资源统一建模和存储,实现可视化表达;并以区域非遗项目为例,对非遗知识进行识别、抽取、表示等,构建可视化知识平台。
1 文献综述
知识图谱是以图形方式呈现知识之间关联关系的技术[2]。2012年,谷歌首次提出知识图谱技术,通过搜索词条向用户展示相关词条或关键字的相互关系,以便于快速发现信息和知识[3]。目前成熟的知识图谱应用有Freebase[4]、Wikidata[5]等。知识图谱在非遗领域的应用较广泛,以围绕本体和语义关系构建的应用为主。美国国家网络化文化遗产倡导组织专门从事非物质文化的数字建构,如语义信息架构、语义关系、关键字索引呈现、文化内容数字化重构[6]。欧洲数字博物馆较早采用语义网技术,通过分散、异构数字文化资源间的语义关联,将不同机构、不同元数据标准的信息资源进行统一,从知识表示、资源描述、本体构建和数据关系等方面实现非遗资源多维度可视化呈现,成为欧洲重要的文化资源平台[7]。Vincenzo等设计戏剧文化本体模型,包含戏剧实体、数据结构、描述框架等,并利用该模型构建具有人物情感及意图的可视化图谱[8]。Carriero等提出利用知识图谱RDF技术将意大利非遗资源进行编码分类,最终以SPARQL语言查询和检索各项非遗之间的关联关系[9]。这一系列应用开启了非遗资源数字化传播的新时代。
针对不同非遗文化分类及呈现形式,国内一般聚焦非遗数字化和语义关系研究。孙传明运用知识表示、知识工程等技术,构建民俗舞蹈知识框架模型,为民俗舞蹈数字化保护提供借鉴[10]。上海图书馆推出的家谱知识库、古籍循证平台、名人手稿知识库等数字非遗项目,以关联数据技术和本体建构作为核心技术,实现知识可视化[11]。
梳理知识图谱应用现状,发现基于关联数据的资源整合集中应用在网络信息资源、数字图书馆等领域,呈现出从理论研究转向应用研究的趋势,出现了大量实践项目[12]。非遗知识库的建立是为了通过语义检索,可视化呈现非遗资源之间关联关系[13]。目前非遗数字化的建构应用丰富,主要表现在本体、语义关系、数据关联、资源聚合等方面。
综合国内外研究,利用语义关系建立关联数据,使其成为本体构建的一部分,是知识图谱研究的热点。国内基于知识图谱的研究集中在数字人文语义网、数据关联构建等方面,有关非遗知识图谱构建、搜索及可视化表达的研究不多,缺乏对非遗领域知识服务的深层理解和应用。知识图谱构建是非遗数字资源可视化呈现的重要组成部分,不仅涉及语义知识分析、表述框架设计、知识表示方法,还包括人物关系呈现、知识推理等复杂环节。本文针对以上局限,以非遗知识图谱构建为创新点,探索区域非遗数字资源可视化应用研究。
2 非遗知识图谱模型构建
目前我国非遗数字化资源保护取得一系列进展,也面临以下问题:一方面资源入库信息零散,关联少;另一方面非遗资源库缺少统一建设,未实现跨平台、跨系统应用,难以实现多源异构数据的高效检索和可视化呈现。知识图谱技术为解决此问题提供契机,基于知识图谱的知识构建与检索可以实现异构非遗数据的共享、语义检索、自动问答与可视化呈现等智能应用。本文从非遗信息内容、类型、呈现形式等方面着手,遵循从知识建构、知识存储、知识管理到知识应用(语义搜索)的逻辑,构建以区域分布为特征的非遗知识库,以解决非遗数字化资源耦合度不高、关联性不强、低响应高延时等问题,构建框架见图1。在语义搜索方面,以RDF为描述框架,对非遗资源实体、属性进行描述,揭示非遗语义关系,形成非遗数据关联,便于网络检索和数字化传播。
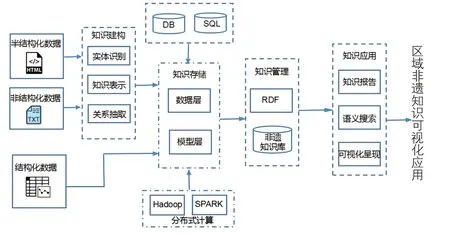
图1 非遗知识图谱模型构建流程
2.1 知识建构
知识建构研究可以追溯到人工智能早期由Quillian[14]和Collins等[15]提出关于网络知识建构的方法。知识建构实际是知识图谱表示,是指选择一种合适的语言对图谱进行建模,描述实体间的语义关系,以便于网络计算机识别及计算。从知识提取的角度来讲,知识建构包括实体识别、知识表示和知识抽取。
2.1.1 实体识别
实体识别是从非遗文本数据源获取知识的重要组成部分,命名实体是一个词或一个短语,可以在具有相同或相似的属性中标识一个事物[16]。命名实体识别(NER)是相同或相似事物集合的过程,有深度学习和机器学习两种方法。在非遗知识图谱建构中,本文采取基于深度学习的NER方法,即将非遗的相关文本转换为自然语言处理的文本序列标注内容,以方便从中提取语义信息。深度学习中常用的架构是LSTM-CRF模型,其主体结构是长短时记忆网络与条件随机场(CRF),架构见图2,由嵌入层、双向LSTM层和CRF层组成。在嵌入层中,对网络信息进行数据预处理(即one-hot编码),将其转化为向量输入嵌入层,再经过嵌入层处理得到相应信息的嵌入向量。在双向LSTM层,有正负向量层(对应li和ri层)和信息加工ci层,li和ri层分别计算输入对应的向量信息,ci层整合li和ri的信息并进行解码输出。在CRF层对输入信息进行序列标注。
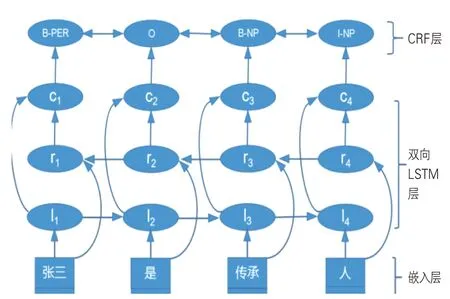
图2 LSTM-CRF结构图
2.1.2 知识表示
知识表示是对现实世界的一种抽象表达。一个知识表示载体应具有较强的表达能力,使计算机执行求解过程精确且高效。在计算机中,知识表示通常由符号和数值组成,以关联图表示实体间关系,而标量、概率等数值有助于刻画知识更深层次的细节。在知识图谱中,语义网络、RDF三元组、实体关系图均是知识表现的形式。图模型是知识图谱的逻辑表达方式,是人们最容易理解的一种知识表示,其基本思路是用图中的点与边代表数值化向量。在知识图谱中,每一个事实都用一个三元组来表达,即头实体(head entity),关系(relation),尾实体(tail entity),可将其定义为一个三元组(h,r,t),其中h和r分别表示头实体和关系的向量,根据TransE模型假设,当h+r≈t,事实(h,r,t)成立,反之则不成立。基于这一思路可以推导出TransE模型损失函数,该函数用实体和关系的分布式向量表示。在函数中,对于每一个事实,三元组(h,r,t)表示头实体、关系及尾实体对应的分布式向量,它们之间关系成立的程度可以通过平移关系来表达,其函数表达式如下:
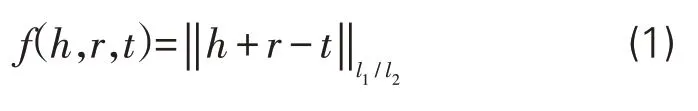
其中,l1/l2表示l1正则或l2正则。在知识图谱中,对应的是实体与实体间存在的关系。例如,“撒叶儿嗬传承人是黄在秀”和“皮影戏传承人是林世敏”,三元组分别为(撒叶儿嗬,传承人是,黄在秀)(皮影戏,传承人是,林世敏)。头实体“撒叶儿嗬”和“皮影戏”的向量加上关系“传承人是”,可能接近尾实体“黄在秀”和“林世敏”,其知识表示的模型见图3。
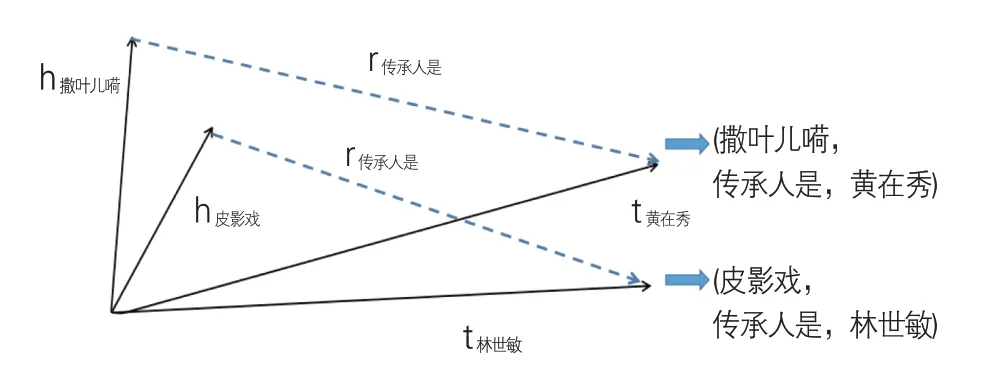
图3 非遗的TransE模型表示
在实际中,函数值越小,对正例三元组集合越有利,而对负例三元组,函数值则需尽可能大。因此,为使非遗知识的区分度更加明显,将Hing Loss目标函数引入TransE模型,其中r是间隔参数,s是正例集合(知识库已存在三元组),s'是负例集合(知识库不存在三元组),使得其正负值尽可能分开:
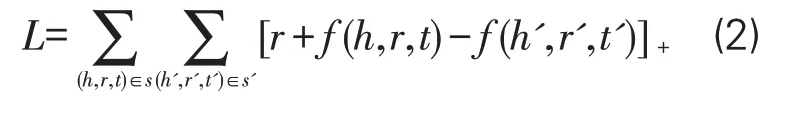
在非遗知识图谱知识表示的过程之中,TransE模型通过向量的运算,能实现语义特征的高效获取以及运算,从而最终实现知识挖掘。笔者采用TransE模型以提高计算效率,将知识内容快速映射到向量图中,其相应的算法如下:
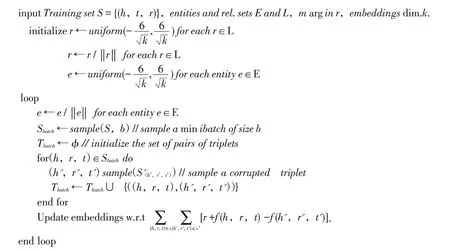
2.1.3 知识抽取
非遗数据主要有非结构化、结构化、半结构化等类型(见图4)。结构化数据本身就已存在数据库中,其知识组织计算机能够识别,抽取简单,只需将关系数据中的知识直接映射或转换映射为RDF数据。半结构化数据是从Web信息中抽取的网页内容,这类数据不符合关系数据库的存储规则,但有标签及语义元素标记。非遗互联网数据丰富,半结构化信息抽取也是非遗知识获取的重要来源。非结构化抽取是从自由文本中提取知识,包括实体、关系及事件3个模块,抽取过程主要基于已有的标注规则和知识库,在3种数据来源中难度最大:在数据收集、文本处理、实体抽取、关系抽取等环节都可能存在噪声和误差,严重影响知识获取的精度;由于来源多种多样且结构复杂,数据处理变得尤为困难。在处理非结构化数据时采用API接口技术,允许用户根据规则抽取文本信息实体与关系,以确保非遗知识图谱构建的准确性。实体抽取目的是从非遗文本中抽取实体信息,如项目名称、传承人、区域、时间、遗产类别。
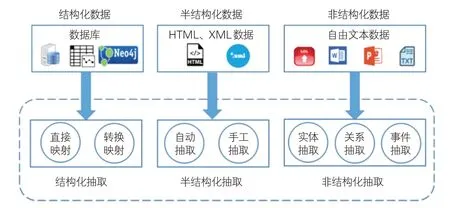
图4 知识抽取示意图
实体抽取,一般先从文本中识别和定位实体开始,然后再将实体划归到预定义的类别中。例如,对于自由文本“湖北省政府于2020年公布第六批荆楚非物质文化遗产目录”,根据规则抽取的实体分别为“湖北省政府”“2020年”“荆楚非物质文化遗产”。
关系抽取,这是指抽取两个实体间的语义关系。在非结构化数据中,关系抽取与实体抽取密切联系。在关系抽取中,先行找到三元组实体主体或客体,然后用句子信息填充三元组的其他部分,填充内容即是实体间关系。关系抽取是非结构化数据知识抽取的关键,目前基于关系抽取的方法有模板关系抽取、监督学习关系抽取等。针对非遗数据,监督学习抽取方法更为合适。基于监督学习的关系抽取是从知识库中找出具有实体与属性的句子,构成训练集,通过训练集形成分类器,面向大量分类标注数据样本,对输入信息进行加工,以建立关系分类。基于监督学习的关系抽取重点是训练语料,包括语料获取和分类器语料优化两个步骤。早期的知识抽取方法包括基于规则的关系抽取、词典驱动的关系抽取、本体的关系抽取[17],这些方法描述语句不强,正确率低。为提高其准确率,在关系抽取中设定关系关键词。例如,在非遗领域中,“遗产地区”关系可以为“位于”“坐落”等;“遗产发源时间”的关键词可能是“起源”“建立”“设立”等。因此,在知识库中关系名称是单一的,但在网络资源中对应的关系语言表达是多样的。如果在关系抽取中直接匹配,会降低关系抽取的精度,而引入关系关键词可以很好解决这一问题。分类器语料优化与人工标注不同,人工标注往往会导致遗漏或错误,且只能用于简单的知识图谱关系抽取,分类器语料优化是将非遗文本已标注语料设为正例,将未标注语料设置负例,按此算法反复迭代,最终完成文本分类。在分类器模型中,条件概率是关系抽取的关键,其公式见下:

在式中,x是上下文,y是关键词标签,Z(x)是归一化因子,λi是方程权重,fi(x,y)是特征方程。在关系抽取中,当x与y满足条件时为1,不满足时为0。
事件抽取,主要是指从自然文本中抽取用户所关注的事件信息,并以结构化的形式呈现出来。事件抽取包括元事件抽取和主题事件抽取。元事件是指一个动作的发生或状态的变化,涉及时间、地点、参与者等。主题事件是指某类核心事件以及与其相关的活动。例如,针对某个非遗项目,可以从非遗文本库中得到其非遗名称、传承人、区域、遗产类别等信息。事件抽取能够从非结构化文本数据中汇集相关信息,实现对实体的完整描述。表1为事件抽取实例。

表1 事件抽取实例
2.2 知识存储
非遗资源包含大量数据,其具有关联性和灵活性,如何将这些数据有效表示和存储是知识图谱应用的关键。以传统文件或关系数据库存储的知识图谱越来越难以应用在非遗的知识管理中。基于新型知识图谱的图数据库框架、数据模型及管理模型的设计和选型是大规模数据存储的关键。
2.2.1 存储架构
在图数据库存储中,非遗数据庞大,必须构建一个能对数据进行高效访问的图数据库框架,以提高知识图谱存储效率。图数据库存储与传统的数据库存储存在很大区别。传统数据库存储时需考虑数据的动态读写操作等;而知识图谱的存储方式以三元组为单元,三元组信息以主、谓、宾的形式存在,其数据组织具有碎片化和灵活性。因此,知识图谱的数据存储必然具有高度灵活性和碎片化。知识图谱存储涉及到图的节点、关系和属性等数据,要想对存储的数据进行高效访问,需考虑建立一个存储代价小、访问数据快的存储框架。当数据规模庞大时,可采用分布式存储以提高存储系统的可扩展性。在分布式存储中,各RDF数据节点分散存储,相对独立。因而,非遗知识图谱有两种存储方式:属性存储和图数据存储。在分布式环境中,基于知识图谱的数据结构,用属性存储方式管理数据之间的关系,减少自连接操作次数,执行效率高。而在图数据存储中,将RDF数据存储到一个3列结构表中,对应三元组的主体、谓词和客体3种数据。当用户提出查询请求时,系统会在三元组表中进行多次自连接以得到用户搜索结果。高效的知识图谱存储架构包含数据层和模型层,如图5所示。
数据层定义存储的物理结构,是图数据库的最底层,决定图数据库存储管理的方式,包括存储管理及数据操作。存储管理涉及原生态的数据及关系数据。在数据操作中,数据预处理环节剔除无效数据,以确保图数据的精确性;此外,还包括数据导入、导出和数据修改。常用的数据层有两种模型,分别为RDF(图)模型和属性图模型。模型层主要功能是逻辑建模,提供图数据库的连接、编码及接口扩展等服务,同时对外部的存储访问提供并行数据操作。
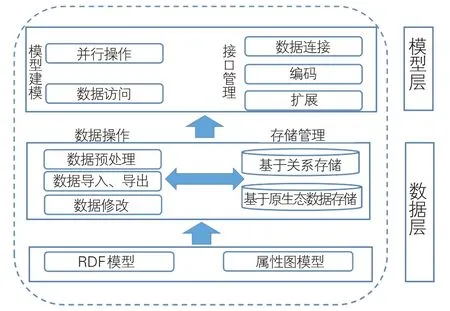
图5 图数据存储框架
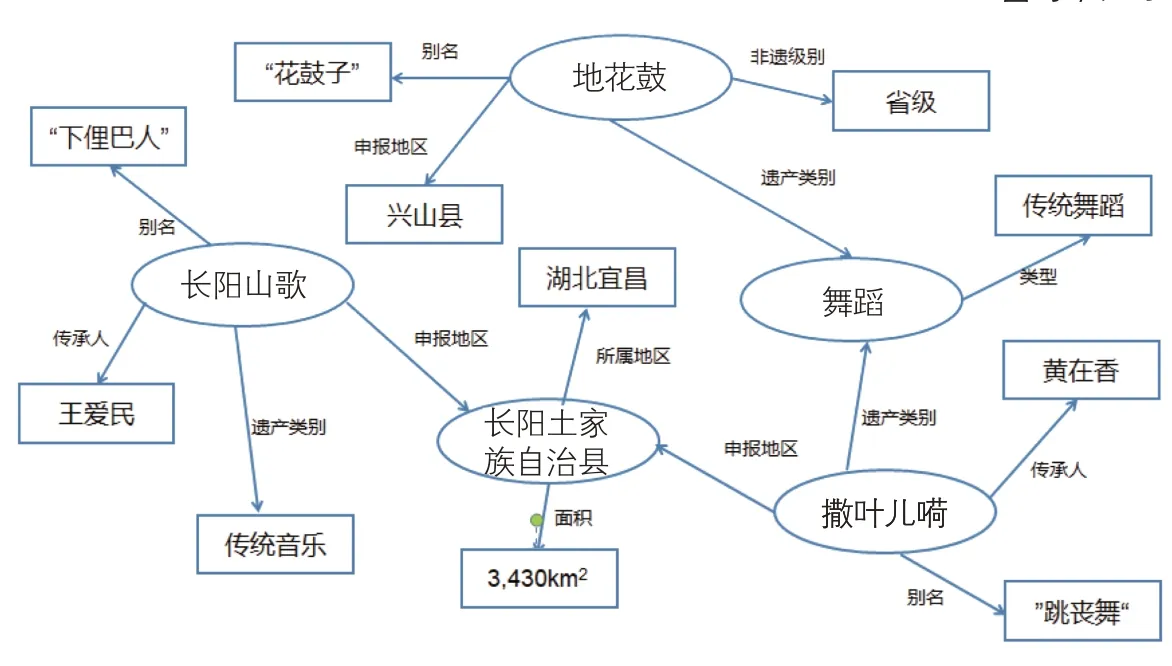
图6 宜昌地区非遗知识图谱RDF图模型
2.2.2 数据存储模型
数据模型定义图数据库的上层逻辑结构,其结构操作决定图数据库存储、查询的方法和效率。知识图谱数据本质是图数据,传统图数据以二元组表示,其图结构为G=(V,E),V表示节点集,E为边集[18]。基于知识图谱的数据模型源于图结构表示方法,用顶点表示实体,边表示实体间关系[19]。在知识图谱中,以分块方式来存储不同实体类型,运用特征聚类方法处理未定义实体,将其归入相近的语义类型。图数据库存储过程遵循统一语义关系以及集中存储原则,即底层使用相同存储结构处理不同类型数据,在语义搜索上兼容不同的数据库查询语言。知识图谱的图数据模型主要有RDF图模型和属性图模型。
(1)RDF图模型。RDF是W3C制定的在语义万维网上计算机可以理解的标准数据模型[20]。在三元组中,节点和边都带有标签,展现知识图谱的语义关联。RDF图模型定义为:设U、B、L分别为有限集合的统一资源标识符(URI)、空结点及字面量,每个RDF三元组(S,P,O)∈(U∩B)×U×(U∪B∪L)是一个陈述句,其中S是主语,P是谓语,O是宾语,则(S,P,O)表示资源S的属性P取值为O。图6展示湖北宜昌非遗知识图谱三元组数据的图形式,包括长阳山歌、地花鼓、撒叶儿嗬等非遗资源。在该RDF图模型中,椭圆表示实体,矩形表示属性值,有向边表示一个三元组的谓词,如三元组(长阳山歌,遗产类别,传统音乐)表示长阳山歌的遗产类别是传统音乐。长阳山歌申报地区是长阳土家族自治县,但不知道具体申报地区的信息。实际上,RDF图模型表示的边属性并不清晰,因此需要利用RDF中“具体化”技术[21],即引入额外点来表示整个三元组,将原边属性以新的三元组表示。如图7所示,本文引入Dec_area代表(长阳山歌,申报地区,长阳土家族自治县),使用三元组的3个 元 素rdf:subject、rdf:predicate和rdf:object对应代表主语、谓语和宾语。这样就形成了一个新的三元组,其集合形式为:
G=((Dec_area,rdf:subject,长阳山歌),
(Dec_area,rdf:predicate,申报地区),
(Dec_area,rdf:object,长阳土家族自治县)).
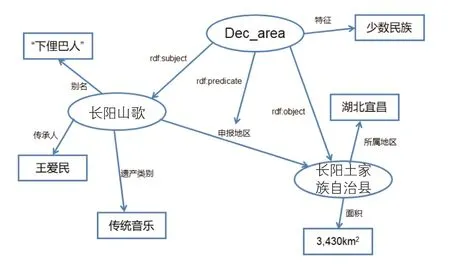
图7 RDF图边属性表示
部分RDF/XML代码如下:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdfsyntax-ns#">
<xmlns:inc="http://hbinc.com/foaf/inc/11#">
<xmlns:inc="http://hbinc.com/foaf/inc/21#">
<rdf:Description
rdf:about="http://hbinc.com/foaf/inc/11/ChangyangFolkSong">
<inc:people>Wang Aimin</inc:people>
<inc:alias>Xialibaren</inc:alias>
<inc:sort>Traditional Music</inc:sort>
<inc:region>Changyang</inc:region>
</rdf:Description>
<rdf:Description
rdf:about="http://hbinc.com/foaf/inc/21/Changyang">
<inc:city>Yichang</inc:city>
<inc:area>"3,430"</inc:area>
</rdf:Description>
</rdf:RDF>
RDF图模型是特殊的有向标签图,本文利用这些标签图将所有资源连接起来,形成一个大规模的非遗知识图谱。在标签图中,一个三元组的谓语也可以是另一个三元组的主语或宾语,映射在这个数据标签图中。边的属性也可以做顶点,这是RDF图表现灵活之处。
(2)属性图模型。属性图是知识图谱另一种常用数据模型,定义为:G=(V,E,ρ,λ,σ)。其中,V表示顶点,E表示边,且V∩E=φ;函数ρ:E→(V×V)是将边映射到对应顶点,如ρ(E)=(V1,V2)表示顶点V1到V2存在边E;Lab为标签,函数λ=(V∪E)→Lab表示顶点或边对标签的映射,如e∈E(或v∈V)且λ(e)=l(或λ(v)=l),则边e(或顶点v)的标签是l;设属性为pro,值为Val,函数σ=(E∪V)×pro→Val表示边或顶点具有关系属性,如e∈E(或v∈V)、ρ∈pro且σ(e,ρ)=Val(或σ(v,ρ)=Val),则边e(或顶点v)的属性pro是Val。与RDF相比,属性图对于节点属性和边属性具有内在的支持。由工业界和图数据管理领域学术界成员共同组成的关联数据基准委员会(Linked Data Benchmark Council,LDBC)正以属性图为基础对图数据模型开展标准化工作[22],因此属性图在图数据库领域应用广泛。
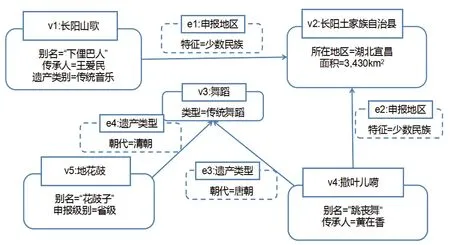
图8 非遗属性图
图8是宜昌地区部分非遗资源对应的属性图,从图中可清晰看出每个顶点和边都有一个ID(顶点:v1-v5,边:e1-e4),且这些边和顶点都有对应的类型标签。在该属性图中,每个顶点和边均有属性,每一项属性有赋值(如顶点v1:长阳山歌有3个属性,赋值分别是:别名=“下俚巴人”,传承人=王爱民,遗产类别=传统音乐;边e1:申报地区有一个属性,为“特征=少数民族”)。因此,在没有改变图的整体结构下,属性图能更加清晰地表达非遗信息。
非遗属性图的集合形式如下:
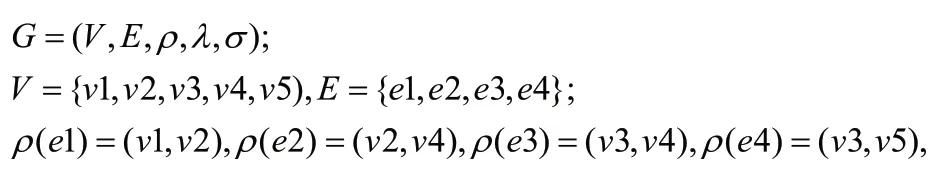
函数ρ表示边与顶点的关联,函数λ是顶点或边的标签,

函数σ是基点或边的关联属性,

2.2.3 非遗知识图谱存储管理
非遗知识图谱数据相对传统关系数据更具关联性和鲜活性。在线查询、离线分析、智能推荐、智能问答及高响应低延时是大规模知识图谱存储管理应用的新要求。因此,高效的知识图谱存储管理应做到以下两点:其一是能高效处理随机访问数据,图存储管理性能的好坏取决于随机访问数据的快慢,包括在线查询任务和离线分析任务;其二是避免图结构索引,索引通常会消耗大量时间和空间,对超线性、复杂度高、规模大的图数据来说,获取图结构化信息是不可行的,但基于高效存储及零索引(Index-free)的图处理不仅可行而且高效[23]。在非遗数据存储管理中,原生态管理系统Neo4j的最大特性是无索引邻接,即图数据的每个顶点、边、标签和属性都被分别存储在不同文件中,每个顶点都指向邻接顶点,这种高效的图遍历能节省大量查找时间。Neo4j图数据管理系统分为3层,分别为数据层、图模型层和图应用层。其中,数据层使用物理存储模型,由底向上管理数据访问接口,负责图数据的物理访问和存储;图模型层提供图的节点、边及标签等操作接口,用于直观操作图数据;图应用层提供用户查询、关键词搜索等功能。
2.3 语义搜索
智能搜索已成为互联网时代重要的信息服务。语义搜索需处理颗粒度更精细的文本数据。原有的搜索对非结构化数据不再适用,现有的搜索算法也不能直接面向实体与关系的知识图谱。在非遗数字化领域,语义搜索同样具有重要的价值。如何从多源异构的数据中,根据用户个性化信息需求,建立基于语义关系的非遗知识搜索,实现知识图谱的个性化查询是研究重点。在语义搜索与优化方面,也需重点研究查询系统的设计、结果优化及展示等。语义搜索的核心思想在于呈现用户信息多样化需求,搜索设计应支持复杂信息需求,以精确的方式匹配用户查询,并对搜索结果进行排序。一般语义搜索方法有3种,分别是关键词语义搜索、基于分面的语义搜索和基于表示学习的语义搜索。在非遗知识图谱构建中,采用关键词语义搜索,利用RDF图模型,将关键词转换为结构化搜索。其步骤如下:首先,根据用户输入的关键词对知识库的三元组进行预处理,根据预处理映射关键词索引,并在知识库中建立与关键词相关联的边和顶点;然后,在RDF三元组的知识库中生成与关键词搜索匹配的查询子图,并将子图中的实体、关系替换成常量、变量和谓词,生成结构化查询;最后,通过查询语言对RDF三元组知识库查询结果进行排序。在关键词语义搜索中,图的顶点距离用来衡量点的相关度,关键词匹配得分是语义搜索过程中所返回的结果与关键词的相符程度。非遗知识图谱包含大量实体与关系,结构复杂,表达式多样,而关键词语义搜索使用户无须指定精确的关键词就能查到相关知识,其优点是不需要建立大规模索引,所占存储空间小。
3 区域非遗知识图谱的应用
3.1 非遗知识库展示平台
非遗知识图谱需要多源渠道形成非遗数据知识库,以知识抽取和融合技术进行构建[24]。其中,RDF技术将非遗数据转换到图数据库中,提供链接、共享及查询等操作。
(1)数据获取。对非遗信息的组织,文本和图片资源收集是数据获取的第一步。非遗种类繁多,有传统舞蹈、传统音乐、曲艺、民间文学、手工美术等。本文以地区非物质文化遗产及中国非物质文化遗产数字博物馆资源为基础,收集地区非遗基本信息,构建区域非遗知识图谱知识库。信息获取来源:一是湖北非遗申报数据,二是通过python技术提取网络数据,然后对数据进行预处理,剔除无效数据。
(2)知识抽取。获取非遗数据后,需对现有数据的知识和关系进行抽取,以构建非遗知识库。知识抽取方法很多,有结构化、半结构化和非结构文本抽取。本研究对非遗领域的文本数据采用非结构化抽取,对网页和数据库数据采用结构化和半结构化抽取。
(3)知识存储。对获取的非遗知识进行加工后,本文按知识图谱的存储规则将其转换成RDF三元组存入知识库。在存储过程中,采用分布式存储技术和分块管理来保证非遗知识图谱的使用效率。
3.2 用户语义搜索
与互联网中的检索不同,非遗知识图谱是处理粒度更细的语义数据,原有算法很难应用到非结构化的实体和关联数据中。知识图谱查询与检索是通过语义模型建构来实现的,包括语言学模型和概念建模。其中,语言学模型主要涉及词语关系建模、分类及同义词库,而概念模型主要是对语法元素(如主、谓、宾等)进行映射。同时,语义建模的解析过程必须是可以计算。在庞大的非遗知识库中,语义搜索采用形式化结构,如在知识图谱的关系库中,采用RDF和OWL模型,RDF数据与非遗文档形成了关联。
知识图谱数据模型为RDF,它是W3C推荐的用来描述网络资源、表示语义知识的重要标准。而SPARQL则是面向RDF图模型的结构化查询语言,目前已被W3C列为访问RDF的标准查询语言和协议。SPARQL查询的核心类似三元组模式,不同的是,SPARQL语句中主、谓、宾语均是变量。为更好显示区域非遗知识图谱的应用,下面以查询宜昌地区传统舞蹈非遗项目的SPARQL语句为例,系统探究其查询效果。有关代码如下(结果见图9):
PREFIX inc:<http://hbinc.com/foaf/inc/1/>
SELECT?item?content
FROM <inc.rdf>
WHERE{
?area inc:city?city.
?item inc:area?area.
?item inc:type?ty.
Filter regex(?city,"^YiChang")
Filter regex(?ty,"^dance")
}
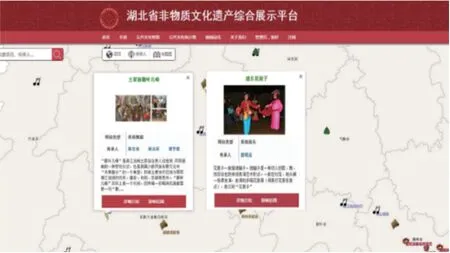
图9 查询结果
3.3 应用效果呈现
节点是知识图谱关联关系呈现的关键,在区域非遗知识图谱中节点数据有几十万条,这些数据以RDF形式存储。下面同样以宜昌为例,叙述非遗知识图谱的可视化呈现效果。如图10所示,湖北宜昌地区的非遗项目非常丰富,但需要注意的是,在非遗知识图谱中关系均为有向图,每一个节点都有各自的属性。
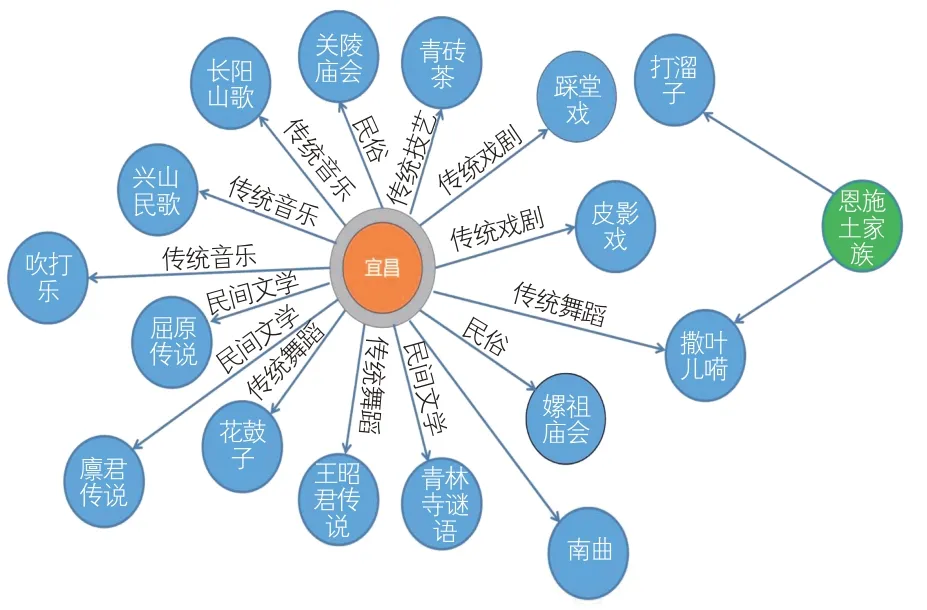
图10 宜昌地区非遗知识图谱
本文所构建的非遗知识图谱以区域形式进行可视化表达,通过城市或地名检索呈现非遗之间的关系。在相关专家和非遗保护组织的支持下,非遗知识图谱知识库将更加丰富和庞大。通过知识库构建的标准化及共享,非遗领域的可视化应用更加广泛,实用性及可操作性更强。基于非遗知识图谱的研究,可为数字人文的应用提供了新思路,对我国非遗的可视化具有可供借鉴的价值。
4 结语
在大数据时代,知识图谱的发展为非遗资源可视化研究提供新的方向。本文对知识图谱的理论构建、知识建构、知识存储等进行深入分析,指出知识建构包括实体识别,知识抽取及知识表示等3种过程。在知识的存储管理中详细分析数据存储的架构、主要模型及管理方式。此外,本文以非遗知识数字化保护为契机,通过构建区域非遗知识库平台,运用知识图谱相关技术展示区域内不同类型的非遗。虽然本文对知识的理论和应用研究还比较粗浅,但将知识图谱的相关理论应用于区域非遗资源的数字化呈现是本研究的重点,以期为今后非遗数字化保护提出参考。未来的研究将进一步增加非遗的数量,以丰富非遗三元组知识库;同时,在知识抽取的模型设计中,将深入分析比较不同抽取算法的执行效率,以提高图计算能力。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
制造技术与机床(2019年6期)2019-06-25 10:17:46
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
计算机工程(2015年8期)2015-07-03 12:20:35
现代防御技术(2014年6期)2014-02-28 18:26:29
