
语料库语言学视域下数据驱动的数字人文研究*
——以《数字人文季刊》为例
2021-10-19 10:25:14徐彤阳王霞
图书馆论坛 2021年10期
徐彤阳,王霞
0 引言
随着信息技术发展,数字人文领域不断汲取其他学科的技术和方法。数字人文起源于人文计算,而人文计算发端于文学和语言学领域[1],数字人文在语言学方面的研究趋势是基于大型语料库的语料库语言学[2]。数字人文是数字技术与人文学科的跨界融合产物[3],语料库语言学是语言学在计算机技术发展过程中产生的新兴学科,与数字人文学科的诞生有异曲同工之妙,二者在诸多方面有交融之处。Oberhelman[4]认为数字人文和语料库语言学均实现从元学科领域的“近读”到“远读”模式;Brooke等[5]认为在文学计算分析的语境中,数字人文学者和计算语言学家是天然的共生关系,两个领域重叠度的升高为彼此发展产生强大的驱动力;Pastuch等[6]认为数字人文学科的发展对语言历史学家的需求,以及在与数字人文学科不直接相关的语言学家中传播数字人文学科发展成果的前景,使更广泛的受众能够充分有效地利用数字人文成果。综上,语料库语言学无论被认为是一门学科还是一种研究方法,作为极具包容性的数字人文学科来讲,运用其方法或研究范式进行数字人文研究无论是对于数字人文方法体系的进一步完善还是学科的方向探索都是大有裨益的。
1 相关概念的厘清
对语料库语言学这一跨界与融合的产物,学界对于其学科论和方法论的归属存在争议。本文既将它视作一门学科也视为一种方法,一种通过构建语料库以揭示语言现象的学科和方法。从方法论讲,语料库语言学方法主要是采用专门的计算机软件来分析被称为语料库的计算文本中产生的语言[7],是一种基于频率分析和索引分析的量化的实证性研究方法[8]。从学科讲,其主要应用于教学、翻译、词汇、词义、词典和语法等领域[9],除有专属的研究范式和研究步骤外,主要关注宏观(整个语料库语言特征与文体类型)和微观(具体的词汇和语法等语言现象)两个方面,对应两种研究范式分别为基于语料库方法和语料库驱动[10]。基于数据驱动的研究范式与这二者之间的区别在于事先不对研究做任何假设,也不试图推翻既定的理论和定理,让数据指引研究者从语言中挖掘新的现象并作为下一阶段研究依据。在将语料库语言学引入数字人文的研究之前,需要厘清两个领域的相关交叉概念:计算机语言学、文本挖掘、自然语言处理,通过剖析相关概念来为文章提供深层次的理论依据。
1.1 计算机语言学
语料库语言学和计算机语言学两者存在交叉关系。计算机语言学则是语言学的研究方法之一。Morante等[11]将计算机语言学定义为:使用计算机系统来理解和生成自然语言的方法,主要关注将计算机作为工具来对感兴趣的语言论及其分支进行建模,应用领域为机器翻译、信息检索和人机交互。语料库语言学是采用计算机处理和发现语言学的特定研究现象。计算机语言学的研究和应用范围较语料库语言学广泛。
1.2 文本挖掘
文本挖掘(Text Mining,TM)指使用计算工具和技术从机器可读文本或数据的聚合体中自动发现新信息和意外信息。文本挖掘需要准备源于研究问题的数据,包括数据或文本语料库的整理、数据熟悉和清理、数据格式化以及分析方法的选择。文本挖掘是一个通用术语,用于对大量文本进行计算分析,涉及不同研究领域和程度的分析技术,可以说语料库语言学是语言学领域基于语料库的文本挖掘,重点关注语言学的某种特定现象。
1.3 自然语言处理
自然语言处理(Natural Language Processing,NLP)是通过开发计算机系统来模仿人类语言行为,主要分为开发计算机程序来进行现实生活的仿真模拟交流和在更严格的层面(词法、句法和语义)进行较大范围的语篇分析两个阶段[12]。其中第二阶段和语料库语言学研究内容存在交叉关系,且自然语言处理技术如SGLM和XML标记系统为语料库处理中的注释阶段提供了技术支撑。语料库语言学可看作是自然语言处理的一个应用领域,同时也是数字人文学科在处理计算机可读文本时的处理技术和手段。
2 数字人文和语料库语言学结合的可行性
在厘清两个领域交叉概念基础上,对数字人文和语料库语言学之间关系的剖析、二者跨领域结合的可行性探讨很有必要。Brooke等[5]认为数字人文和语料库语言学的关系是互惠互利、互动共生的,从数据和方法两个维度来对数字人文和语料库语言学进行对比[13]。首先,二者都是依赖数字技术解决领域传统研究技术落后的新兴学科,均实现了“定性-定量”二者结合的方法转变。其次,语料库语言学的研究对象——语料库既可为语言学领域的研究提供数据基础,又可利用语料库提供的数字图像和文本之间的关联来支持自动语言处理和增强数字人文学科的资源[14];反之,数字人文研究成果可以为语料库语言学提供研究数据的支撑。总体讲,无论是数字人文还是语料库语言学的发展不仅对传统人文学科进入数字时代的发展困境,而且还为人类特有语言文本和其他形式的精神成果的数字化存储、转译、处理、分析和检索提供了新的思路。因此,恰当处理大数据时代数据和人文的平衡关系是数字人文学者需要重点关注的问题[15]。数字人文和语料库语言学对比,详见表1。
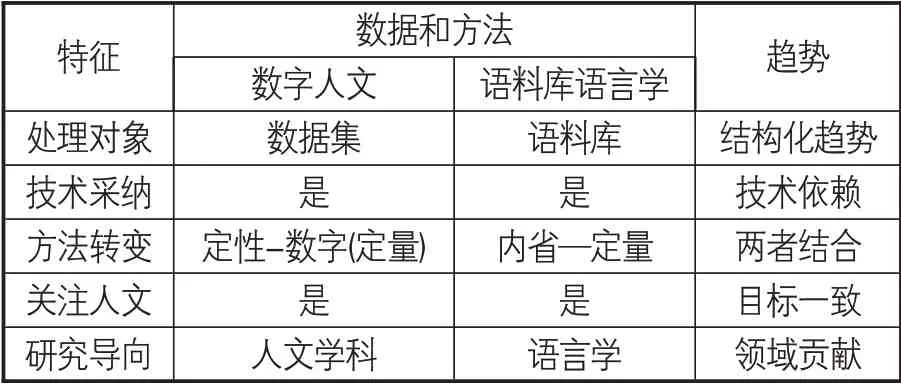
表1 数字人文和语料库语言学对比
3 语料库构建与工具选取
文章以《数字人文季刊》(Digital Humanities Quarterly,DHQ)作为语料库构建的数据来源。从DHQ官方网站下载2007年和2019年数据,以基于数据—驱动的研究范式进行数字人文语料库研究,采用同类型语料库对比的研究方法[16]。需要说明的是,对比语料库需要满足代表性、同质性和可比较性3个原则[17]。
3.1 数据选取原则
(1)代表性。代表性作为一种重要的属性和指标,衡量样本语料库是否能作为该领域语言整体来与一般语料库进行比较[17]。代表性可以应用到专业领域的语料库构建中,以揭示在特定领域中真实语料库所反映的语言现象。文章采用DHQ作为数字人文领域的数据来源,因为该刊自2007年建刊以来在同行期刊中具有权威性,且以数字人文为专题建刊,对数字人文领域的文章收录范围广、形式多样,具有数字人文领域的代表性特征[18]。
(2)同质性。同质性主要针对两个语料库(非常规语料库)间的对比,同质性重要之处在于能够反映一个语料库在某些特征与另一个语料库的差异[19]。文章语料库对比均来自DHQ,同属数字人文领域的语料库,因此具备同质性要求。
(3)可比较性。可比较性体现在两个语料库进行比较时,对于语料库的选择采用同样的抽取方法[20]。文章采用DHQ语料库中不同年份的子语料库间的对比,通过分析语料库的语言特征来揭示数字人文发展路径和未来趋势。
3.2 数据处理
(1)处理工具。采用英国兰卡斯特(Lancaster)大学语料库研究中心Paul Rayson等开发的基于网络的语料分析工具Wmatrix,第四版本[21]。该工具在实现关键词表、索引行、搭配功能基础上,由关键词分析向词性、语义分析扩展[22]。词性分析时采用CLAWS进行标记和注释,在关键词列表的生成过程中综合考虑词在句中语法重要性、词的范围和分布对关键词表的影响。由内嵌的工具USAS对文本进行语义赋码,将没有成为关键词但具有重要语法功能的低频词结合起来,实现语料库整体的词汇定量分析。
(2)2019年语料库和2007年语料库对比。2019年语料库共32篇文章,纯文本格式占1.2MB;2007年语料库共12篇文章,纯文本格式占520kb。参照语料库选自BNC Sampler Written(968,267词)[23]。
3.3 语料库分析
3.3.1 关键词分析
对两个语料库的比较先从词的维度进行。由于不同语料库中词频排序不同,所以不能直接比较词的频数,且语料库大小不同,因此需要根据语料库大小将频数转换为频数占比进行标准化处理。另外,采用的LL值是对数似然比,Rayson[24]通过对不同显著性差异指标对比,认为LL值更适合语料库对比研究的统计分析。当自由度为1,(LL值计算采用2*2列联表)在99%水平上,临界值为6.63(p<0.0.1)时,两个语料库有1,145个过度使用或为充分使用的具有显著差异的词,但将临界值调整为99.99%(p<0.0001)水平上临界值为15.13时,具有显著差异的词仅有446个。去除“our”“we”“and”“if”等不做重点研究的词外,排名前20的关键词见表2。
居于第一位的词是“projects”。“项目”一词在2019年语料库中出现462次而在2007年语料库中出现13次,LL值为247.57>15.13。通过进一步查看该词在索引行中的位置,如图1所示,发现搭配的词为“数字人文”“很多”“一些”等,用来修饰“项目”这个名词。可以推断,数字人文领域目前以项目制为主要研究形式。出现在第二位的“humanities”和第19位的“digital”在2019年语料库中出现频率分别为0.37%和0.63%远大于2007年语料库的0.08%和0.39%。除掉“人文”与“数字”共现外,人文都是独立存在的,说明数字人文领域相关学者和研究人员对人文性的关注愈发凸显。需要注意的是,“digital”一词虽然在两个语料库中出现频次都较多,但出现在表2的倒数位置,归结为两个原因:一是表2为2019年与2007年语料库对比情况,旨在分析二者语言现象的差异,反过来会出现不同的结果;二是Wmatrix中关于词维度的分析兼顾词频和词在句子中的语法重要性程度,“数字”的出现频率和在句子中的语法成分导致这种情况的出现。
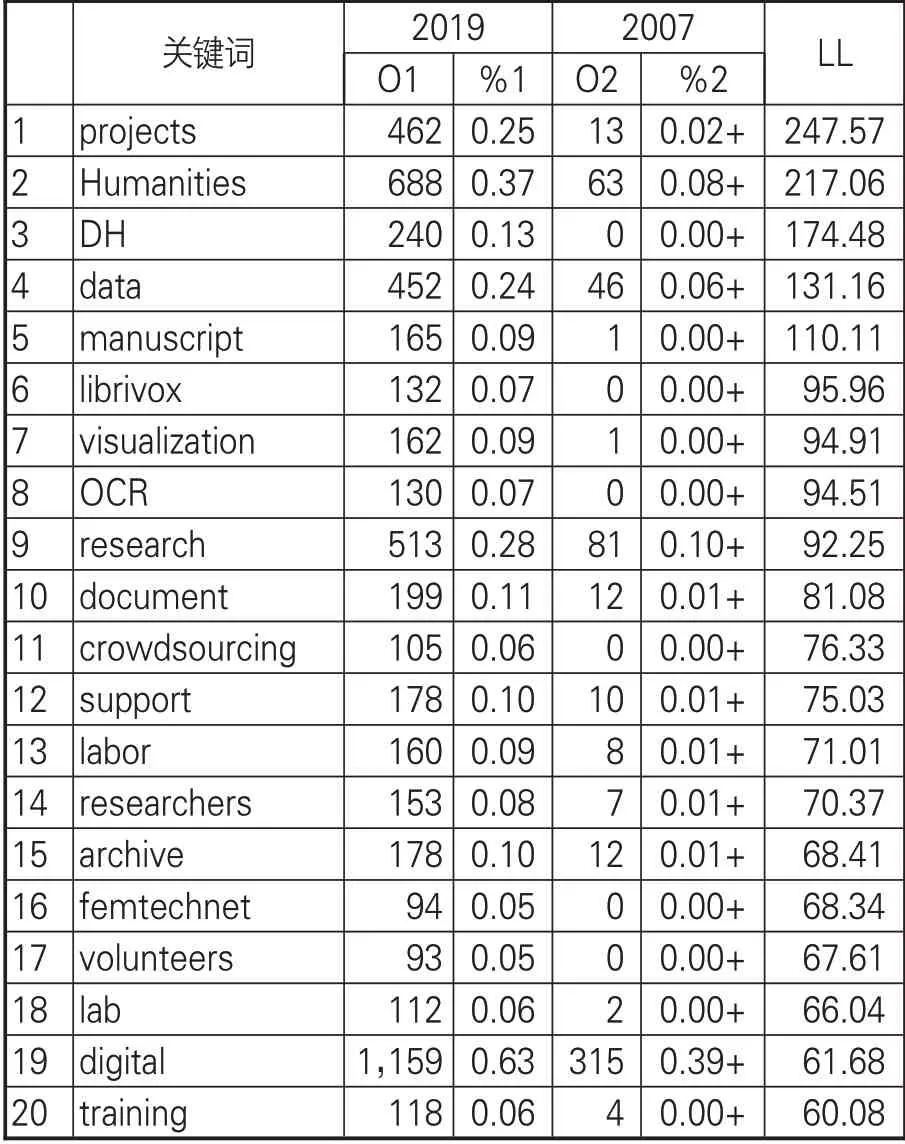
表2 2019年和2007年语料库前20关键词对比

图1 “projects”一词出现在对应句子中呈现的索引行列表
由于语料库选择的领域为数字人文,故“DH”出现频率高不足为奇。“data”“manuscript”“document”“archive”4个词都是对数字人文处理对象的描述。从档案-文件-手写稿-数据这样一个数据形式过渡链,可以看出,数字人文研究对数据集的要求从结构化向非结构化过渡:从数字人文发展伊始以图博档机构的结构化程度较高的资源为研究基础,至今以数据来统称一切可作为数字人文的研究对象。这种转变对大数据技术的发展应用提出了挑战,也表明数字人文发展中研究范式逐渐倾向基于数据驱动的研究范式。
“visualization”“OCR”是两种不同数据处理阶段的技术。可视化技术一般出现在对数据的分析和处理阶段,以直观方式展示数据中包含的信息及发现新知识的过程。OCR(光学字符识别)技术是采用光学的方式将纸质的字符和图片中的文字转化为文本格式,供文字处理技术进一步编辑和加工处理。数字人文在发展进程中,不断吸收前沿技术带来的新鲜养分,帮助研究人员提高处理数据的效率,加深对数字人文研究的洞见。
“research”“researchers”两个条目虽然词根相同,但考虑其词性在句中承担的成分不同,故分别进行关键值计算,二词均表达学科领域从事研究工作的参与者。很多语料库工具在词频统计时,将这类词作为一个词来统计,忽略了部分词的词性不同其含义也不同的可能。“spring”一词作为名词译为“春天”,作动词时当“活跃、涌现”讲,可见词的隐喻性分析对于语言表达中隐喻含义的表征意义重大。
值得关注的是“librivox”“crowdsourcing”“volunteers”3个词在2007年语料库中没有出现,说明与2007年相比,“有声读物数字图书馆”“众包”“志愿者”已经成为2007年之后数字人文新的发展模式和趋势。“众包”已然成为数字人文项目发展模式,“志愿者”出现说明了传统数字人文项目队伍建设向众包项目制数字人文研究队伍建设的重整,“有声读物数字图书馆”网站提供了一个全球性的志愿者社区,致力于记录所有作为免费有声读物的公共领域文本,是典型的众包模式实践。
“support”“labor”为2019年语料库中具有显著性意义的词,可见数字人文研究和项目运行中需要跨学科、多领域展开广泛的合作,不仅需要政策和资金的支持来保障数字人文研究项目顺利进行,还要求大量科研机构和人员参与。查看“training”这一关键词的索引行,发现“训练”大多与数据和数据集搭配出现,表明数字人文研究对数据的处理基于训练数据集,进而构建模型来实现大量数据的处理。利用机器学习等计算方法来对语料库分析屡见不鲜,如Schlör等[25]研究采用支持向量机和深度学习的方法对,对句子进行自动判断与识别。尽管如此,句子、语言、古籍等人为产物是人的意识和思维的外显,是有温度的,如何平衡技术冰冷和人文性温暖是未来在给人文研究插上数字翅膀时需要思考的问题。
3.3.2 词性分析
Wmatrix的优势之一在将关键词分析扩展到词性分析。多角度提供对语料库数据语言现象和整体文本信息的挖掘。当自由度为1,p<0.01临界值为6.63时在2019年和2007年语料库中出现97个过度使用或未充分使用的具有显著意义的词性标记,在99.99%水平(p<0.0001)有31个显著的词性标记。前20标记对比见表3。最显著的词性标记PPIS2代表第一人称复数主观人称代词(we)。2019年语料库对“we”的使用频率相当于2007年的3倍。对于“we”的使用受到英语语言使用习惯的影响,在此不做深入分析。需要特别注意的是,ND1代表方向名词的单数形式,检索索引行发现,2007年“西方”这一方位词的使用最多,2019年则以“南部”最为显著,进一步分析索引行内容,发现DH2018年会首次在南半球举行。FO代表公式、符号,索引行均为数字或者简单数学公式、百分比等,可看出数字人文研究越来越多地融入数学、统计学学科理论,为数字技术环境下人文现象的发现和解释提供客观依据,其余词性标记如名词、动词、形容词等反映的语词性质,需要依附在一定的关键词才具有更丰富的研究价值。
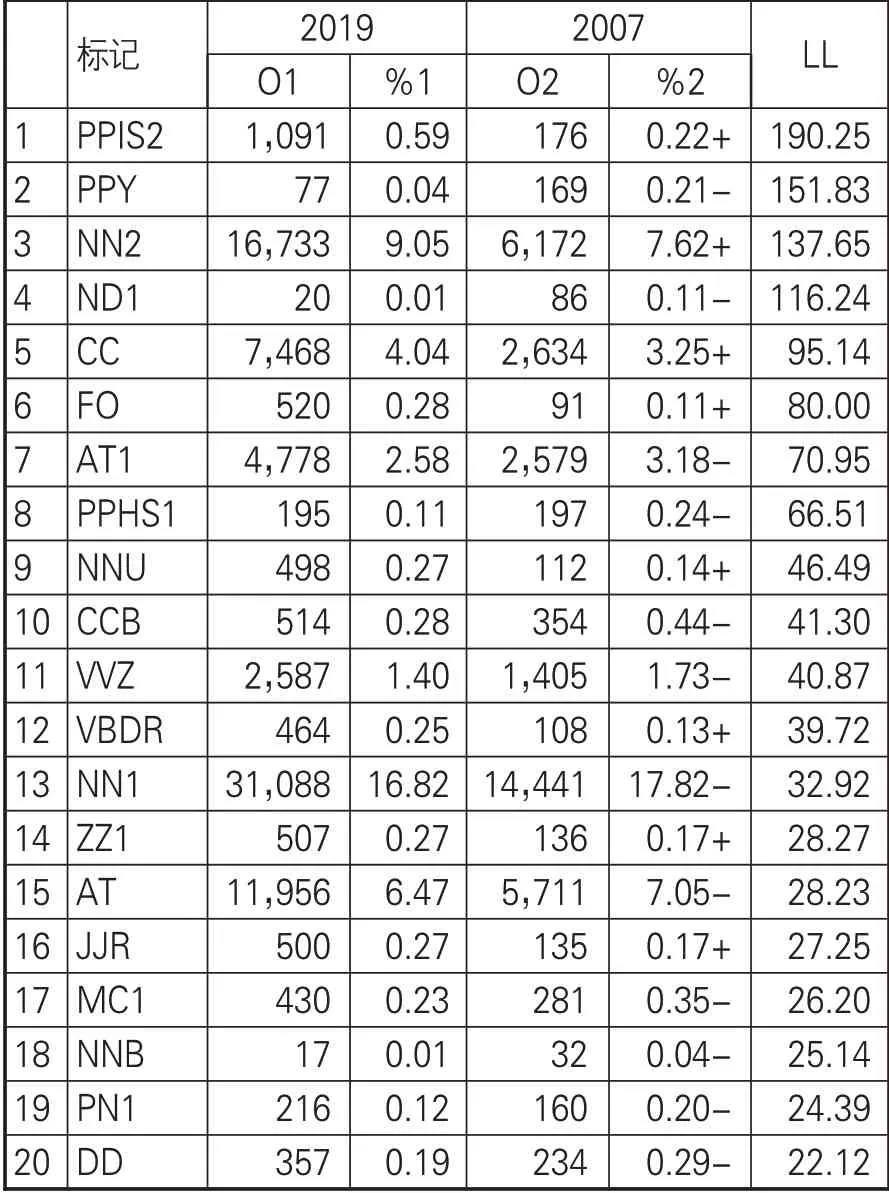
表3 2019年和2007年语料库前20词性标记对比
3.3.3 语义域分析
使用USAS标记为2019年和2007年语料库分配语义域标签。在自由度为1(P<0.1)临界值为6.63时有140个有显著差异的过度使用和未充分使用语义域标签。在(P<0.0001)临界值为15.13时有88个显著差异的语义域标签,表4列出前20语义域标签。
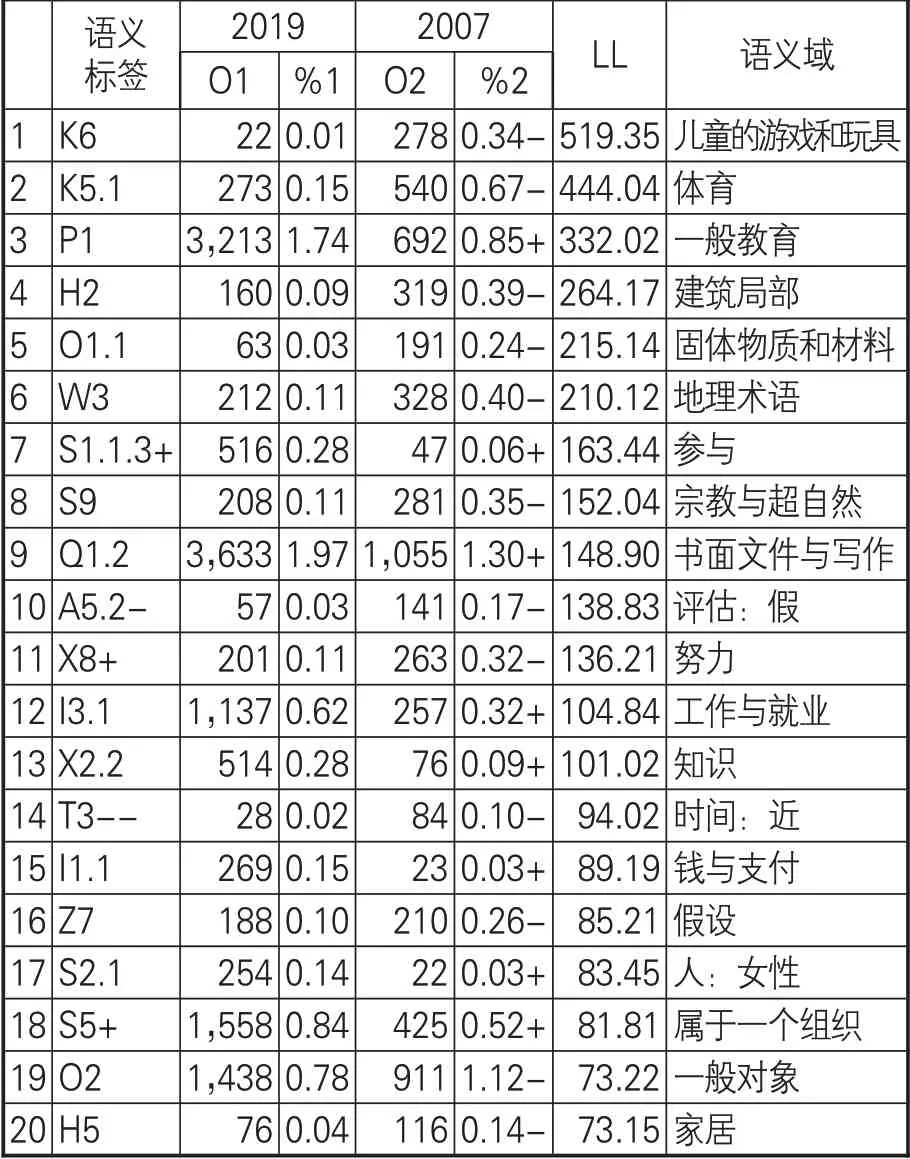
表4 2019年和2007年语料库前20语义域标记对比
K6最具显著性差异的LL值为519.35,但要关注排名第二的K5.1语义域中包含“game”“goal”。虽然在对照语料库中两个词用来描述体育领域,但结合关键词所在语境分析,“game”指游戏,“goal”指目标。将“game”与第一语义域中“player”等描述游戏词汇汇总,得到语义域频率:2019年频率为137,2007年频率为709,“-”代表“游戏”语义域在2007年语料库中使用较多。P1代表“一般教育”,“+”说明教育在2019年语料库中使用较多。H2语义域中以2007年语料库中使用显著,相关索引行显示的“room”“departments”“threshold”“walls”“doors”等词,并非使用词本义,在语境中分析采用词的引申含义,代表空间、阻挡和壁垒等含义。O1.1语义域中除去“Woods”作为人名的频率,其余“stone”“cave”“steel”“mud”等词在语境中以本意出现。W3语义域在2007年语料库中使用较多,相关词语为“hill”“valley”。S1.1.3+语义域代表“参与”的相关语义域词汇,如图2所示。
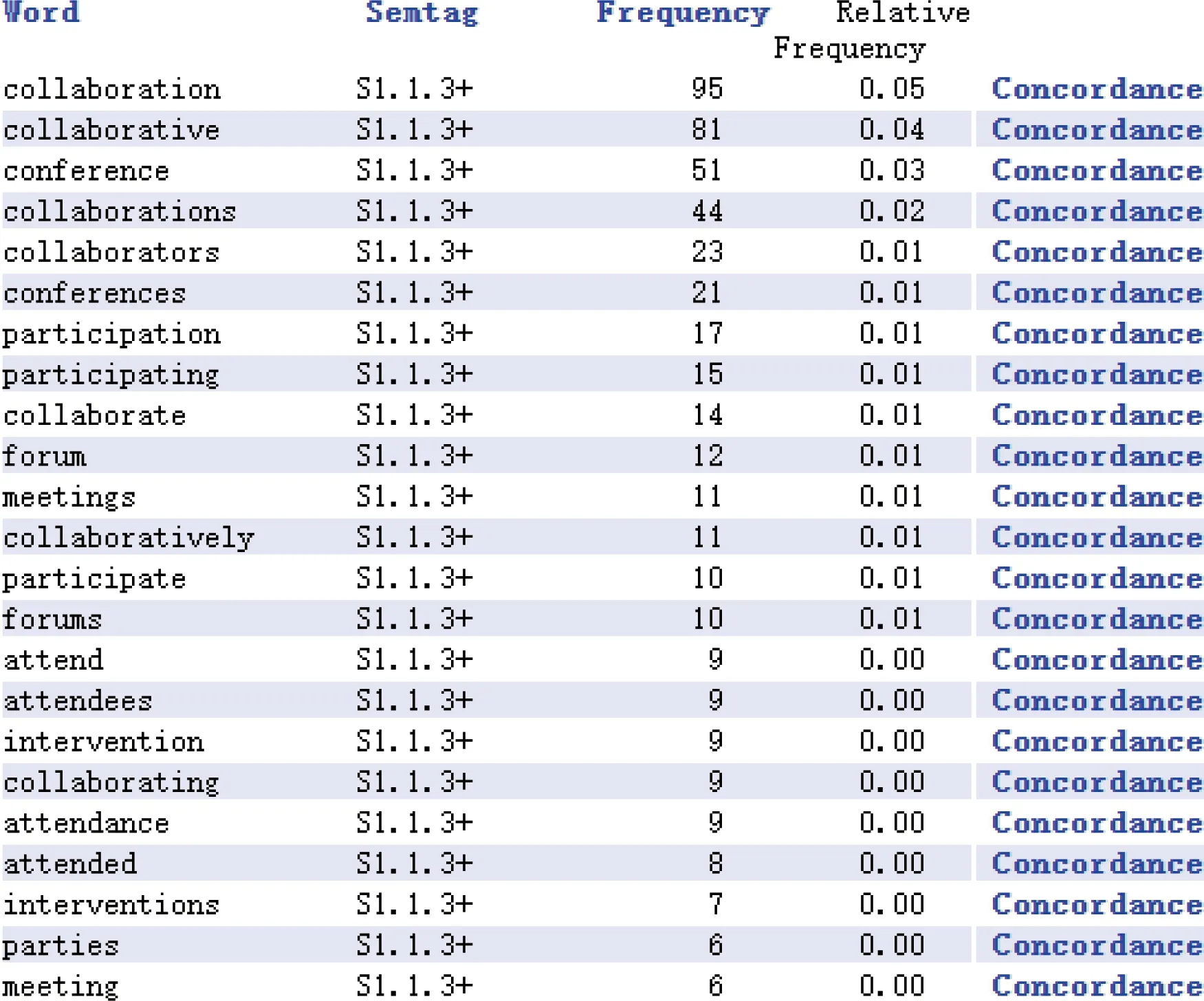
图2 “参与”语义域的相关词汇列表
S9代表“宗教与超自然”语义域,该领域在2007年语料库中出现的背后原因在于宗教学科也是数字人文应用领域。Q1.2语义域以文本、列表、记录和档案等词汇构成。A5.2-语义域以“虚假”“误导”等词为主,在2007年语料库中使用较多,其中需要提出“fiction”一词,该词在相关语境中译作“小说”,说明在2007年数字人文研究关注小说这一文学形式。X8+语义域的关键词为“努力”“尽力”“斗争”“试图”等。I3.1语义域在2019年使用多于2007年,“团队协作”“志愿者”“招聘”等词反映了数字人文团队构建和招聘等相关工作。X2.2、I1.1、S2.1、S5+等4个语义域在2019年语料库中的频率分别为0.28、0.15、0.14、0.84,其中X2.2代表知识,反映了数字人文研究以数据为基础进行的知识挖掘;I1.1语义域突出了数字人文研究项目的资金支持与来源;S2.1语义域代表女性话题,映射出无论是女性数字人文研究者还是女权主义的发展研究者逐渐成为数字人文领域研究群体;S5+语义域以“组织”“机构”“团队”等为主要关键词,表明数字人文研究的队伍建设情况。
T3--语义域在2007年语料库中使用最多的词汇是“avant-garde”,译为前卫派思想或先锋。Z7语义域——“假设”以“if(假如)”为关键词。O2语义域虽然在2019年语料库中频率较高,但是频率占比低于2007年,以“object(对象)”“model(模型)”为主要关键词。H5语义域中包含歧义词“table”,根据语境译为“表格”,这里不做进一步研究。
综上,去除有歧义词语义域归属不恰当的标记后可知,“游戏”“阻碍”“地理术语”“宗教”“努力”“前卫思想”“假如”“对象”等关键词为2019年与2007年语料库对比中具有显著性差异的语义域典型关键词。其中,“游戏”和“宗教”作为数字人文的主要应用领域;“努力”和“假如”从语言学角度体现了学者对数字人文未来发展的憧憬和信心。2019年语料库中使用较多的语义域中关键词有“教育”,从侧面揭示了数字人文在发展十余年来对教育开始重视并开展数字人文素质教育;“参与”“团队”“组织”体现了数字人文团队组织的要件,与第一部分词分析结果中的众包对组织构建的内涵属同一范畴;“数据”一词强调数据是数字人文研究的基础;“机构”“资助”表明数字人文项目的开展需要政府机构和相关组织予以大力支持;“女性”表明了女性问题在数字人文研究中的关注度越来越高,无论是作为研究成员还是历史上关于女性问题的研究。
3.3.4 进行可视化分析并对比Wmatrix分析结果
为了更直观地观察构建的DHQ语料库文本中出现频率较高的关键词,选用可视化工具Voyant来对Wmatrix工具处理数据结果进行简单验证。
运用Stéfan Sinclair等开发的Voyant文本挖掘工具[26],对两个语料库进行可视化分析,作为Wmatrix工具分析结果的对比,见图3-4。可以看到,两个语料库中关键词的可视化分析与Wmatrix的分析结果基本吻合,关于频数差异在于工具对多词组合和词的单复数形式统计标准不同导致。在2019年语料库中出现的“work”在Wmatrix中没有显示,原因在于Wmatrix并不是单纯基于统计和计量学角度进行词频统计,还结合语言学领域中词在句中成分的重要性,让更多频率不高但处于语言学关键位置的词析出,为关键词分析提供不同的统计标准,有利于实现文本中不同词汇现象和信息的深度挖掘。通过分析发现,不同的处理工具对于词频的统计方式、核心算法和研究侧重点存在差异,导致全面把握领域研究内容有一定的误差,但对于整体语料的解释性方面是一致的。因此,构建领域语料库、优化准确率较高的算法、改进语料库处理准确性是未来重要的突破口。

图3 Voyant工具中2007年语料库关键词

图4 Voyant工具中2019年语料库关键词
4 结果与讨论
传统的数字人文热点与发展趋势研究基于关键词、共词、上下文、项目信息、作者合著等,这样的模式可看作“远读”模式[27]。远读虽然可以从宏观角度来俯视整个学科的发展脉络,但是一些细微、具体的语言现象不被重视和发觉,语料库语言学分析弥补了这样的不足,兼顾“远读”和“近读”模式,将具有重要语法意义的词汇析出,弥补作为数字人文发展热点分析的微观体现,只有远读和近读结合才能全面考量学科领域的整体发展状况。本文对DHQ语料库关键词、词性、语义域进行文本及可视化分析,下文进行结果讨论。
4.1 研究对象:数据作为数字人文研究结构化形式的数据基础设施
夏翠娟提出数字人文“数据基础设施”为数字人文研究基础设施的一部分[28],这一概念彰显数据在数字人文研究中的重要地位,尤其是基于数据驱动的数字人文研究。这里是以数据本意来谈基础设施的,而笔者现在要研究的是数据的结构化形式。从文中的关键词分析不难看出,数字人文实现了从最初的图档博馆藏结构化资源到手写稿再到数据的非结构化过渡,研究数据的细粒度化和包容性不断提高,同时也揭示了数字人文的实践和服务半径在不断扩展和延伸。
4.2 研究模式:众包模式是项目制数字人文研究探索的新成果
本文的语料库关键词分析表明,出版公司和志愿者等词汇频繁出现,实现传统数字人文以项目制研究模式到众包模式的过渡和升级,是数字人文学科壮大发展的新成果。众包模式从商业环境过渡到科研领域,核心在于创新协作模式。首先,数字人文为跨学科研究领域,需要人文学科、计算机领域等学者通力合作才能实现研究和实践目标,因此众包应运而生。其次,数字人文项目源于人文资源和人文课题,项目实施过程中不能完全依赖机器语言和思维来处理的资料和工作,往往需要公众和志愿者参与贡献时间、精力和智力。因此,众包的出现是合乎数字人文学科本质和发展路径的。
4.3 数字技术:自然语言处理和可视化技术成为刚需
数字人文概念提出后,不少学者关注数字人文的技术路径并提出相应的技术体系。文中从语料库中析出较为突出的自然语言处理,在应用中对数字人文处理数据的结构化要求降低,意味着对自然语言处理技术要求的提高。自然语言处理技术的广泛应用可实现人类思维和计算机思维的有效通信,将大量纸质信息数字化是数字人文研究的基础,基于此,进行形态学、词汇、OCR识别、情感分析和命名实体识别等多层面的分析。另外,可视化技术可直观地对数据采集、关联和成果进行展示,并在此基础上通过视觉特征引申出新的研究课题。最后,数字人文研究成果可视化有助于提高公众的人文理解和激发公众参与数字人文研究的积极性。
4.4 研究导向:不断加强对人文性的重视
数字和人文两个词汇的频率变化使对人文性重视的语言现象昭然若揭。从2007年到2019年“人文”一词出现频率大幅提高,说明数字人文学者在采用数字技术进行研究和实践过程中,逐渐从数字技术为主的研究导向转向以人文性为主、技术为辅的研究导向,让以数字技术解决人文课题变得有温度。对于人文性的关注,有学者提出,我国关于数字人文的讨论最早来自传播领域对于数字时代人文精神缺失的批判;而Spence等[29]认为数字人文不只是以软件模型来代表人文学科的理论框架,数字人文的核心是人文学科,人文学科讲究人文性。可见国内外数字人文发展的不同阶段均对数字人文研究实践的人文性予以重视,利用数字技术解决人文课题的同时最大限度保留人文性是人文学者的初衷。
4.5 研究群体:对不同角色女性群体的关注
女性一词的首次出现值得关注,无论是女性人员参与数字人文研究和实践活动,还是以某个时期女性的研究目标,均体现了女性参与职业准入的自由性和开放性,以及女性在漫长的历史长河中实现角色独立的努力和变革,也是数字人文对人文性重视的外显。将女性作为研究对象,数字人文研究成果可为其他学科提供新的研究课题,女性参与此类数字人文项目和研究,对于研究的人文性关注是最大的体现。如我国有学者以慰安妇为研究起点,将增强现实技术引入南京地区侵华日军慰安所研究[30]。
5 结语
对于数字人文学科发展和热点趋势的研究,很多学者从关键词、作者合著、引用与被引等角度进行分析。但是在大数据视域下,数字人文学科的发展和实践方向要走“大科学”的理论和思想路线,将众多大规模、历时性的信息碎片糅合,构造数字人文大局面,因此,挖掘新方法、采用新模式、融合新技术是数字人文发展的必然趋势。文章以数字人文领域中具有同行代表性的期刊DHQ作为语料库的数据来源,对其进行语料库语言学分析,以反映数字人文领域的历时性语言现象。数据的形式化要求、众包新模式的探索、自然语言和可视化技术的应用、人文性的重视和对女性参与者及女性群体的关注,是本文从语料库语言学视角对DHQ进行历时语料库整体分析的五个维度的发现,为数字人文未来与语言学的融合发展起到抛砖引玉的作用。
李慧楠等[31]对2019年数字人文年会各种形式的信息整理,基于“语料库”一词的频率很高,提出语料库建设一直是数字人文的核心工作之一。但是,目前数字人文领域还未构建专门语料库,对于语义域赋码很难做到专业的标记,而包含隐喻现象的词汇处理准确率问题仍亟待解决,这也是本文的不足之处。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
海外华文教育(2016年1期)2017-01-20 08:21:56
现代语文(2016年21期)2016-05-25 13:13:44
语言与翻译(2015年4期)2015-07-18 11:07:45
大连民族大学学报(2015年2期)2015-02-27 08:28:11
当代修辞学(2011年2期)2011-01-23 06:39:12
外语学刊(2011年1期)2011-01-22 03:38:33
当代外语研究(2010年3期)2010-03-20 14:36:38
