
异构环境下改进的Hadoop调度算法
2021-10-19 06:32林金羽
闽南师范大学学报(自然科学版) 2021年3期
林金羽,闫 格
(1.闽南师范大学计算机学院,福建漳州363000;2.福建省粒计算及其应用重点实验室,福建 漳州363000)
随着大数据时代的到来,非结构化的数据在以指数级的速率增长的同时,逐渐成为数据处理中的主流,占80%以上,从而针对海量的非结构化数据处理将是一个巨大的挑战[1].目前,雅虎在2008年发布的分布式应用Hadoop被广泛应用于处理各种结构化和非结构化的数据[2],其框架主要核心由如下三部分组成:Hadoop 分布式文件系统(HDFS),MapReduce 并行计算框架以及资源管理YARN.MapReduce 在计算以及处理数据的过程中需要占用大量的I/O资源,如将被处理的数据分发到各个节点并存储在本地磁盘中,根据节点资源使用情况将任务分配到各个节点上执行是作业调度的主要作用.作业调度是实现高性能处理大数据的关键因素,影响作业调度性能的因素有很多,如数据量、数据格式、数据传输速率、数据安全性等.因此,使用改进调度算法的策略来提升Hadoop应对处理非结构化数据的性能就成为了亟待解决的问题.
在Hadoop 中,文件在HDFS 上被分成一个或多个数据块,这些数据块存储在多个节点中,当进行MapReduce 工作时,需要将其他节点上的数据传输到实际计算的节点上.为了解决数据由一个节点传输到另一个节点需要时间以及消耗大量的网络带宽的问题,数据局部性的概念应运而生.调度算法需要通过增强数据局部性,将计算任务放在输入数据的节点上来避免不必要的数据传输[3].
Hadoop MapReduce 计算框架中有3 种自带的调度算法:先进先出(FIFO Scheduler)调度算法、公平(Fair Scheduler)调度算法和计算能力(Capacity Scheduler)调度算法.FIFO Scheduler 是Hadoop1.0 默认使用的调度策略,该算法采用队列,将所有作业都提交在队列中,按照作业的提交时间顺序执行作业,该算法不关注作业的处理时间和处理的优先级,存在数据局部性的问题.Fair Scheduler支持多个队列,为每个队列中的作业分配均等的资源,存在配置复杂、未考虑作业的重要程度等问题.Capacity Scheduler 是Hadoop2.7.2及以上默认使用的调度策略,该算法支持多个队列,每个队列可以共享集群的部分资源,做到最大化吞吐量及集群资源利用率[4].
1 相关工作
现有的研究集中于对调度算法进行改进,从而更好地做到集群的负载均衡[5].文献[6]提出一种异构环境下基于节点计算能力的调度算法,即给每个服务器节点的性能分配不同的权值,Reduce 任务根据不同的权重进行任务调度,该算法考虑到了节点的异构性,能较好地做到负载均衡;文献[7]考虑节点与任务两种因素,提出一种能够将节点性能高低进行实时排序且按将相似的任务进行归并的算法,该算法将复杂的任务分配给性能强的节点执行,减少了任务执行时间;文献[8]提出一种在Reduce 阶段,考虑网络带宽、Map输出结果的数据偏移量和节点计算能力等因素,选取合适的节点进行计算,该算法能够动态地获取节点信息,提高了资源的利用率.
文献[9]提出一种根据节点的处理能力将输入的数据块分配给节点,根据节点的计算能力将map 与reduce 任务进行分配;文献[10]提出一种新的基于HDFS 分割的索引框架,该框架减少MapReduce程序的IO 开销,提高了资源利用率,但框架较为复杂;文献[11]深入Hadoop内存管理,优化内存的分配,在任务执行过程中优化垃圾处理机制,但该方法学习成本高,需要一定的Java内存优化基础.
本算法在为作业分配资源时考虑了节点和作业的异构性,在任务到达前设置监听器获取作业到达时消息及资源空闲时消息,根据作业到达率和平均作业执行时间将作业分类,考虑作业所需资源的最小资源数量,优先将本地任务分配给节点,确保每个节点都能公平地获取到任务,当收到作业到达消息或资源空闲消息时,将任务进行分类并分配给空闲的资源.
2 算法设计
2.1 算法思想
算法在初始化阶段设置两个监听器分别用来监听系统资源空闲时消息及作业到达时消息,当监听器收到监听消息后,调度算法根据消息的类型进行相应的处理.当新作业到达后,调度算法根据作业估计完成时间及数据到达率将作业进行分类、处理,当系统中有空闲资源时,调度算法将合适的作业分配给该资源.
2.2 作业估计执行时间
提出的算法根据作业的估计完成时间对作业进行分类,因为在集群中大部分作业是重复的,优先级相同且等待时间相似,根据作业的估计完成时间将作业分为两类,能够更好地进行调度,做到负载均衡,提高资源利用率.
MapReduce 执行作业可以分为三个阶段:Map 阶段,Shuffle 阶段,Reduce 阶段.Map 阶段读取数据并处理,Shuffle阶段对Map输出进行整合,Reduce阶段对任务进行整合、输出.本节给出计算三个阶段的估计完成时间的过程.
2.2.1 Map阶段的作业估计执行时间
Map 通过RecordReader 读取输入的键值对,将输入的数据进行分片,为每个分片构建map 任务,map函数完成自定义的任务后输出新的键值对,map将输出的结果写入本地磁盘,根据键值进行排序.Map阶段输出的是中间结果,该中间结果要由Reduce处理后才会输出到HDFS中.
当提交任务后,定义该作业的输入数据大小记为S,将输入数据分为n块等长的小数据块,对于任务的每一个map任务,将第i个map任务的输入数据大小定义为εi,则输入数据的大小S可以表示为:

将处理第i个map任务的时间定义为ti,那么Map阶段估计完成时间为:

2.2.2 Shuffle阶段的作业估计执行时间
Shuffle阶段把所有map任务输出的中间结果中相同键值的键值对组合在一起,组合后的键值对作为输入传给reduce函数.Shuffle 阶段所传输的数据与Reduce阶段的输入数据相同,设该阶段所传输的数据为δ,传输一个数据单元需要时间ts,则Shuffle阶段所需要的时间为:

2.2.3 Reduce阶段的作业估计执行时间
Reduce 阶段以Shuffle 的输出结果作为输入,根据键值对中的键值进行合并、排序.当所有的任务完成后,将输出结果写入到HDFS 中.在Reduce 阶段需要处理的数据为δ,设处理第i个reduce 任务的数据单元所需要花费的时间为tri,则Reduce阶段所需要的时间为:

因此,完成每个作业的估计完成时间为:

2.3 作业平均执行时间
如式(6)所示,Ti表示每个作业的平均完成时间,l表示共有l个作业提交到集群,已完成的所有任务运行时间与作业个数的比值可以计算出每个作业的平均完成时间,每当有作业完成,平均执行时间就会重新计算一次并更新数值,这样可以使得结果更加准确.

2.4 作业到达率
当Map 阶段执行到第k个map 任务时,smap表示为已经完成的map 任务数据量,则每个map 任务平均所需要的时间可以表示为:

得到单个map 任务的平均完成时间后就可以计算出正在运行的作业以及即将运行的作业所需要的时间.m表示目前集群中正在执行map任务数量,tused表示作业已运行的时间.则作业到达率φ表示为:

2.5 作业分类及资源分配
算法利用作业平均完成时间以及作业到达率将作业分为短作业类以及公平类.每个作业的估计完成时间为Ti,集群中作业的平均完成时间为,将Ti与进行比较,如果作业的估计完成时间小于集群作业的平均完成时间,将该作业的分类标记为短作业类,即满足式(9),反之将该作业的类标记为公平类.

Hadoop在分配任务时,默认所有的节点都是完全相同的,但是在实际的环境中无法实现这一点,因此就会发生负载不均衡的情况,导致资源的浪费.当用户请求资源来执行作业时,系统会立即给予每个作业最小资源数量,最小资源数量不是一个确定的数值,但是调度器常用它对资源分配进行优先排序.在本算法中,调度器将资源优先分配给短作业类以及其它作业的最小资源数量,最后将多余的资源分配给公平类.在公平类的资源分配中,资源总是优先分配给本地任务,如果在第一个作业中没有找到本地任务,调度器将继续搜索下一个作业,直到找到本地任务为止,在分配完本地任务后,将资源分配给剩余的作业.当有新作业到达时,监听器向调度算法发送作业到达消息对作业进行处理.当出现资源空闲时,监听器向调度算法发送资源空闲消息,将合适的作业分配给资源进行处理,这种调度策略在一定程度上解决了数据局部性的问题.
3 实验过程及结果分析
3.1 实验环境
为了验证提出的改进后的算法正确性,实验搭建4个节点的异构Hadoop集群,Hadoop版本为2.6.4,如表1所示4 个节点的性能不完全相同,集群设有1 个NameNode 节点和3 个DataNode 节点,1 个ResourceManager节点和3个NodeManager节点.集群的总资源量为:内存12 GByte,虚拟CPU 12个,磁盘60 GB.本实验所采取的数据集为BigDataBench生成的键值对数据.

表1 节点参数表Tab.1 Description of node sets
选取各种类型的Hadoop 基准程序进行测试有利于评估调度算法的性能.实验采用WordCount、TeraSort、Grep这3种不同类型的MapReduce任务.WordCount程序属于计算密集型,对内存、CPU 以及IO的资源需求较低;TeraSort 程序适用于大量数据的处理,对于内存、IO 以及CPU 有较高的需求;Grep 程序在进行模糊搜索时需要占用大量的CPU资源,对于其他资源的要求较低[14].测试程序类型如表2所示.

表2 测试程序类型Tab.2 Type of test program
3.2 实验结果与分析
本实验将从2 个方面来衡量改进后的算法的性能:任务执行时间以及Shuffle 阶段传输的数据.将Hadoop 自带的Fair Scheduler 和Capacity Scheduler 与改进后的调度算法作为对比,执行不同的作业类型并多次实验取实验结果的平均值.实验1结果如图1所示.

图1 任务执行时间Fig.1 Task execution time
由图1可知,本文算法在执行计算密集型以及IO 密集型的程序时执行时间有所减少,执行效率相对于Fair Scheduler分别提高了12%、20%,相对于Capacity Scheduler分别提高了27%、11%,执行效率的提高说明本文算法的作业以及资源分配更合理.CPU 密集型任务的执行时间相比Capacity Scheduler 有所提高,这是因为在运行过程中动态资源使用的不确定性以及作业的初始优先级不同.
MapReduce的Shuffle阶段跨节点传输数据会占用大量的网络带宽,造成网络堵塞,影响框架性能.图2、图3所示为Shuffle阶段跨节点传输数据量,由此可知,本文算法在资源需求一般的作业以及资源需求较大的作中,跨节点传输的数据量均有所减少,证明了本文算法能够减少数据的跨节点传输,提高了数据本地性.

图2 WordCount基准程序Shuffle阶段跨节点传输数据量Fig.2 The amount of data transferred across nodes in shuffle phase of wordcount benchmark program
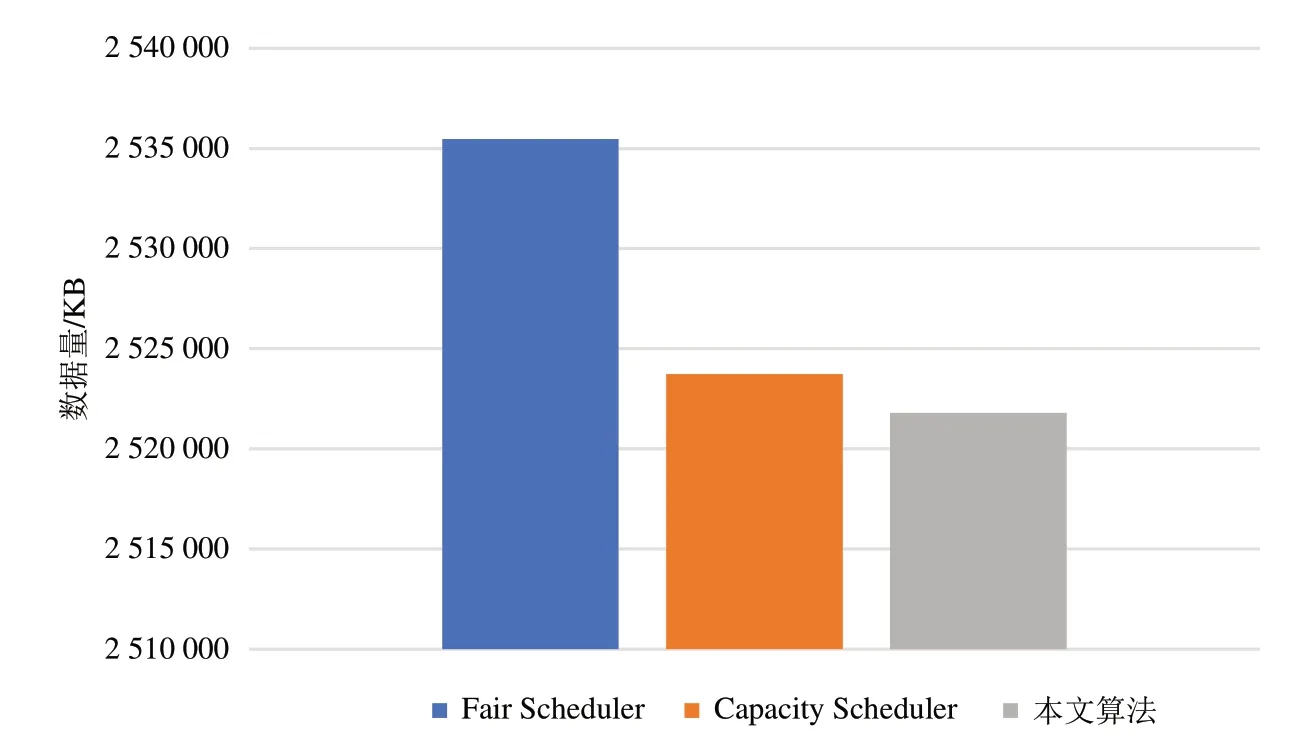
图3 TeraSort基准程序Shuffle阶段跨节点传输数据量Fig.3 The amount of data transferred across nodes in shuffle phase of TeraSort benchmark program
4 总结
主要研究了Hadoop原生的资源调度器,提出原有的调度算法存在数据本地性以及负载均衡的问题.针对以上问题,提出根据作业估计执行时间将作业分类,给不同类别的作业提供资源的改进算法,通过与Fair Scheduler和Capacity Scheduler实验对比,实验结果证明本文提出的算法在异构环境下减少了任务执行时间以及数据迁移量,提高了资源利用率.在现实的生产环境中,影响负载均衡的原因还有很多,如用户的优先级、作业的优先级等,未来的研究可在本研究的基础上加入更多影响负载均衡的因素使得集群性能有更大的提高.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
计算机应用与软件(2021年10期)2021-10-15
北京航空航天大学学报(2021年6期)2021-07-20
电脑爱好者(2020年18期)2020-09-26
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
北京航空航天大学学报(2019年9期)2019-10-26
计算机测量与控制(2019年6期)2019-06-27
电脑爱好者(2017年9期)2017-06-01
