
基于特征加权词向量的在线医疗评论情感分析
2021-10-15 12:42高慧颖公孟秋刘嘉唯北京理工大学管理与经济学院北京100081
北京理工大学学报 2021年9期
高慧颖,公孟秋,刘嘉唯 (北京理工大学 管理与经济学院,北京 100081)
情感分析是利用自然语言处理、文本分析等技术识别和分析语料库中主观信息的过程[1]. 国内外学者致力于利用情感知识和机器学习的方法获取用户情感倾向,一些学者通过扩展语义相似的情感词扩充了情感词典[2],一些学者研究了中文文本及短文本特征提取的方法[3-5],为后续的研究打下了良好基础. 医疗行业属于数据密集型行业,部分学者对医疗在线语料进行了文本分析. 高慧颖等[6]曾利用改进的主题模型对医疗评论进行主题挖掘;DEVGAN 等[7]分析在线医生评论来了解正面和负面评论的特征; LIU等[8]通过挖掘医疗评论确定文本主题以及患者的情感态度;GREAVES等[9]基于NHS上的评论选取三个维度进行了情感分析;向菲等[10]运用基于规则的主题挖掘及情感分析方法获取医院评论中的情感.
虽然情感分析技术已经比较成熟,但是目前对医疗评论的情感分析依然面临上下文语境和情感词典直接影响分析的准确性、医疗评论的专业性及表述差异性等问题,因此本文从医疗评论的特点出发,进一步完善医疗服务领域情感词典,构建主题特征集及医疗评论规则,并建立特征加权词向量模型,提高在线医疗评论情感分析的有效性.
1 基于特征加权词向量的情感分析方法
1.1 研究方法
根据在线医疗评论的特点,提出一套基于特征加权词向量的在线医疗评论情感分析方法. 研究方法如图1所示,分为4个步骤:①从在线医疗信息平台中提取评论,通过筛选、分词、词性标注等预处理建立规范的医疗评论语料库. ②运用隐含狄利克雷分布模型(latent dirichlet allocation,LDA)进行医疗服务质量主题抽取,结合改进的K-means聚类算法进行主题聚类,形成医疗服务主题特征集. ③基于规范的医疗评论语料库,以HowNet与NTUSD情感词典为基准,利用Word2vec训练情感词集合,构建更专业和完善的医疗服务领域情感词典. ④依据句法关系识别主题词与情感词的依存关系,构建主题评价规则,建立特征加权词向量模型,识别情感强度与倾向并进行方法的对比验证与应用.
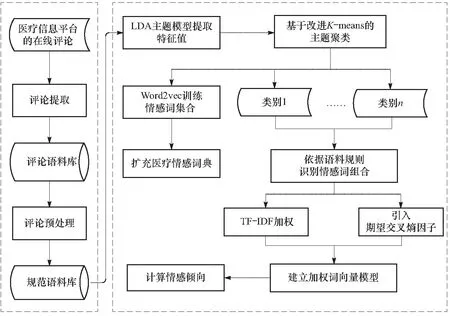
图1 基于特征加权词向量的情感分析研究方法Fig.1 Sentiment analysis research method based on feature weighted word vector
1.2 基于LDA模型和聚类算法的主题集建立
本文利用LDA主题模型获取患者关注的医疗服务质量主题[11],其参数α和β根据经验值设置,主题数K基于困惑度(perplexity)设定,困惑度越高,模型表达效果越好. 同时,主题数也对模型有较大影响,主题数过小容易导致内聚性差,主题数过大容易产生过拟合问题. 由于收敛下的最优主题数往往较大,冗余性强,影响后续情感分析的效果,因此需要主题聚类.K-means是应用最广泛的聚类算法之一,但初始簇中心的选择具有随机性,因此引入最小生成树Kruskal算法,利用最小连通距离性质使簇内样本对象连通距离最小,为初始簇中心的选择提供参考. 其主要思想是,利用Kruskal算法构建最小生成树,形成k个连通子图并计算各个连通子图中对象的均值,将其作为初始簇中心点,计算各个主题词与中心点的距离,基于最小距离性质进行聚类,不断重复这一过程直至算法收敛. 选取邓恩指数(Duun index,DVI)来确定最佳分类数k,利用“肘部法则”选取对DVI值改善效果最明显的k值作为最佳分类数.
1.3 医疗服务领域情感词典的扩充
本文利用Word2vec方法实现情感特征的向量化表达,可以充分考虑潜在的语义关系,高效、准确、快速地识别出医疗服务领域情感词,构建较为专业、准确和完善的医疗服务领域情感词典. 具体步骤如下:
① 构建基准情感词典,合并HowNet与NTUSD中文情感词典并去重.
② 权重赋值. 将情感词权重统一赋值,正向情感权值赋为1,负向情感权值赋为-1.
③ 构建词向量模型并计算相似度. 利用Word2vec方法构建词向量模型,计算语料中的候选词与基准情感词典的基准词的余弦相似度,选取与基准情感词相似度排名前10的词语作为新候选词,将新的词语加入基准情感词典,形成医疗服务领域情感词典Healthcare-Dictionary,同时构建程度副词词典和否定词词典. 相似度公式为
(1)
式中:X和Y分别代表基准词向量和候选词向量;Xi和Yi分别代表维度i上的取值.
④ 效果评估,选取准确率、召回率和F1值作为其效果评估指标.
1.4 基于主题规则和特征加权词向量的情感分析
1.4.1主题评价规则的构建

表1 医疗服务领域常见依存句法关系Tab.1 Common dependency syntax in medical services
存在否定词或者转折词时,权重设置为-1;存在副词时,加强型权重取值大于1,减弱型权重取值在[0,1]区间. 同时需要考虑否定词、副词和情感词的位置,如式(2)所示为
(2)
式中:Si为总情感值;Wi为极性强度;Ai为程度副词的权重;Ni为否定词的权重;θi为情感修正系数,表示情感词与否定词间的物理距离.
1.4.2特征加权词向量模型的构建
在医疗领域,不同词的情感强烈程度是存在差异的,需要对特征词赋予相应的权重. 加权处理前,常用基于向量空间的方法进行文本表示,此传统方法具有数据稀疏、丢失词序信息等缺点. 为了解决上述问题,本文以词向量为基础,将文本表达引入到词向量空间. 特征加权处理常使用TF-IDF算法,通常是计算每个词的TF-IDF权重值,并对每个词的词向量进行加权平均. 但发现TF-IDF算法将文档集合作为整体衡量,倾向于过滤掉整个文件集合中的高频词,没有考虑到特征项词频的类间分布情况,若某个特征项在某类文档中大量分布,而在其它文档中少量分布,那么该特征项具有较多的类别信息,能很好地作为区分特征,但在TF-IDF中该特征就会受到抑制. 因此,本文中引入期望交叉熵因子,它表示文本中一个类别的概率分布与某特征下类别的概率分布间的距离,如式(3)所示,
(3)
式中:P(t)为文本中出现特征t的概率;P(ci)为出现ci类文本的概率;P(ci|t)为t属于类别ci的概率;|c|为类别总数. 当特征t和类别强相关,即P(ci|t)大,并且相应的P(ci)相对较小,表明特征t分类影响大,则相应的期望交叉熵值也大.
基于期望交叉熵因子的权重计算公式如式(4)所示:
(4)
文档向量的计算公式如(5)所示:
(5)
式中:wt为特征t的词向量;v(d)为文本d的向量表示. 基于期望交叉熵因子改进特征权重,使得类别间表征能力越强的词语具有相对较高的权值,权重分布更合理.
2 实验分析
2.1 实验数据
当前中国主流的医疗信息平台中,好大夫在线网和39健康网上的用户评论侧重患者寻医问诊过程的体验;第三方综合服务评价网站大众点评网上的医疗评论侧重对某家医疗机构服务的满意度. 三个平台的在线评论各有侧重但都体现了用户对医疗服务质量的综合评价. 为了使情感分析更为全面,本文利用Python综合爬取这三个网站上某三甲医院2018年6月1日前的全部评论,共计74 660条,并随机抽取20 000条进行实验. 利用Jieba扩展包对数据进行预处理,得到含有19 795条评论数据的规范语料库,词语总数为391 923个.
2.2 实验结果及分析
2.2.1主题特征集的建立
基于规范评论语料库,利用LDA模型进行评论主题抽取. 根据经验值[11],α取50/K,β取0.01,迭代次数取1 000,通过计算不同K值下的困惑度,发现当主题数为170时,困惑度趋于平稳,基于实验的时间和空间成本,选取最佳主题数K=170. 采用本文提出的基于Kruskal的K-means算法对主题特征进行聚类,计算DVI值变化的斜率,利用“肘部法则”得知k为13时DVI值变化的斜率最大,因此确定最佳分类数k为13. 依据中国《医院评价标准(征求意见稿)》[12]对13个类别进行命名,主题特征集示例如表2所示.
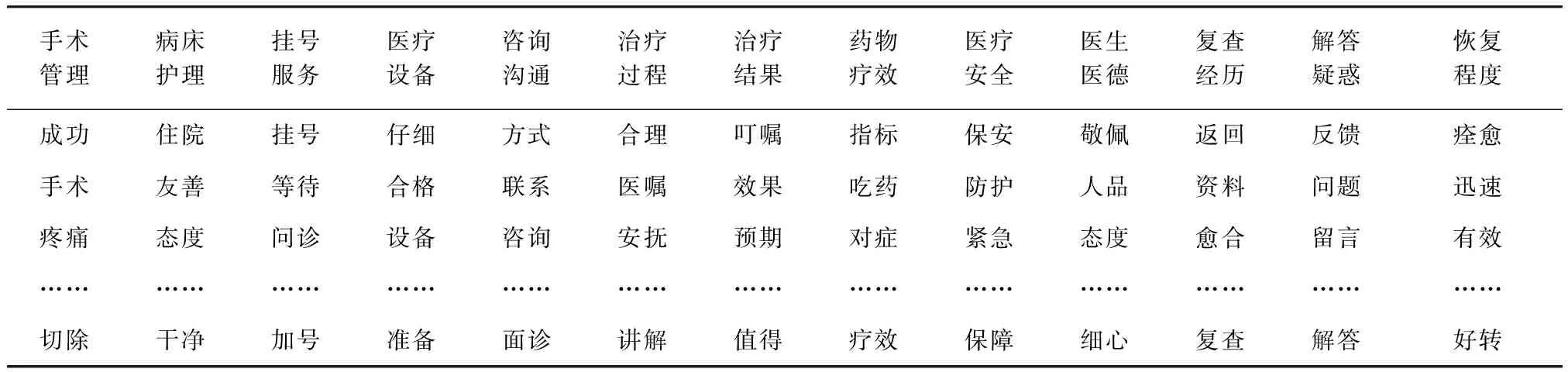
表2 聚簇的主题特征集Tab.2 Clustered topic feature set
2.2.2医疗服务领域情感词典的扩充及评价
利用Word2vec工具,参考经验值[13],选用CBOW模型,词向量维度设置为200,近邻窗口设定为6. 将词语转化为词向量,再计算语料中的候选词与基准情感词典的基准词的余弦相似度,为了提高准确度分别保留相似度前10的词语,筛选去重后得到157个新扩充的医疗领域情感词,部分示例如表3所示,最终构建医疗服务领域情感词典Healthcare-Dictionary. 同时抽取程度副词和否定词,构建程度副词词典和否定词词典,并赋予权重.

表3 部分新扩充的情感词Tab.3 Part of the new expansion of sentiment words
选取HowNet情感词典、NTUSD情感词典与本文扩充的Healrhcare-Dictionary作比较,实验结果如表4所示. 通过分析表4可以发现,在准确率、召回率和F1值方面,Healthcare-Dictionary都高于基准的HowNet情感词典和NTUSD情感词典,说明基于词向量扩充医疗情感词典的方法相对符合医疗服务领域的特点,对在线医疗评论的情感分析的有效性更高,在医疗服务领域具有良好的可行性.

表4 不同情感词典用于医疗评论语料的情感分析结果Tab.4 Results of sentiment analysis of online healthcare reviews with different sentiment lexicon
2.2.3基于特征加权的词向量的情感分析
为了验证本文提出的基于特征加权词向量的情感分析方法在情感分类上的有效性,引入支持向量机(support vector machine,SVM),将本文提出的方法在SVM分类上的效果与传统的基于主题规则、基于TF-IDF加权的情感分析方法在SVM分类上的效果进行对比,选择准确率、召回率和F1值三个指标进行评估. 对规范语料库的数据进行人工标注,使用其中人工标注的5 000条差评和5 000条好评,分别取出4 000条评论作为训练集,1 000条评论作为测试集,进行模型训练和评估. 对比实验结果如表5所示,其中“期望交叉熵+SVM”一行代表本文提出的基于特征加权词向量的情感分析方法在SVM分类上的效果.

表5 不同情感分析方法结果Tab.5 Results of different sentiment analysis methods
通过对结果的分析发现,针对医疗服务领域在线评论文本的专业性强、差异大、不够规范等特殊性,本文提出的基于特征加权词向量的情感分析方法表现出良好的分类效果,在准确率、召回率和F1值上均优于传统的基于主题规则的情感分析方法和基于TF-IDF加权的情感分析方法. 而且本文提出的情感分析方法得到的结果中正面情感词和负面情感词的F1值均超过88%,说明此情感分析方法在分析在线医疗评论情感倾向上性能更优且有效性更高.
2.2.4结果分析
本文通过Word2vec方法扩充医疗服务领域情感词典,共新扩充了157个医疗服务领域情感词,使情感词典更具有领域性、专业性. 其中,正面情感词占比高达56.6%,负面情感词占比43.4%,说明此三甲医院的在线医疗评论正面情感词居多. 在正面情感词中,包括“仁心仁术”、“妙手回春”等词语;在负面情感词中,包括“加塞”、“倒票”、“黄牛”等词语,体现了此三甲医院存在倒票加塞的情况.
通过计算各个主题的情感倾向,发现患者对此医院的13个主题的正面情感占比均在60%以上,说明患者对该医院的医疗服务质量较为满意. 采用本文提出的情感分析方法计算13个主题的情感强度如图2所示,可见每个主题的情感倾向都是正面的,说明患者对该三甲医院的医疗服务质量的情感是积极的. 主题中“医生医德”情感强度相对较高,其次是“医疗设备”和“治疗结果”,说明患者对于该医院的医生医德、医疗设备和治疗效果较为满意. “挂号服务”主题的情感强度相对较低,其次是“病床护理”和“手术管理”. 因此,此三甲医院需要有针对性地提高挂号服务、病床护理、手术管理等方面的服务质量.
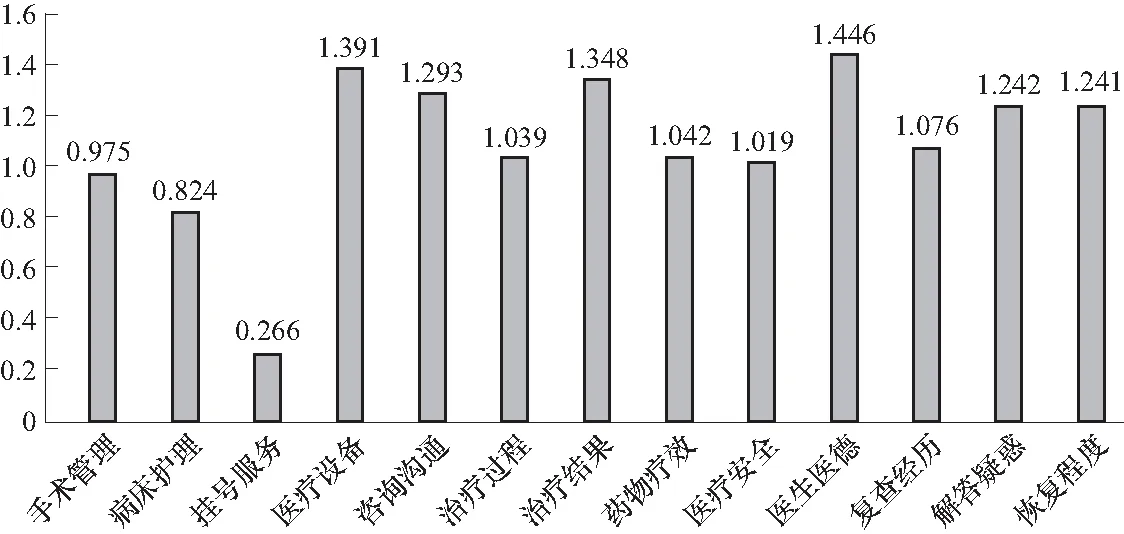
图2 主题情感强度Fig.2 Thematic sentiment intensity
3 结束语
针对在线医疗评论文本的特殊性,本文提出了一种基于特征加权词向量的情感分析方法. 该方法首先利用LDA主题模型和改进的K-means算法获取医疗服务主题特征集,然后利用Word2vec扩充医疗服务领域情感词典,最后依据依存句法关系,引入期望交叉熵因子,建立特征加权词向量模型来识别医疗评论的情感倾向. 实验结果表明,本文提出的基于特征加权词向量的情感分析方法对于在线医疗评论具有良好的适用性,能有效适应在线医疗评论文本专业性强、差异性大和不够规范等特点,提高了在线医疗评论情感分析的准确率,并且通过该方法的实际应用,为某三甲医院提升服务质量提出了建议. 本研究依然存在一些有待改进之处,后期实验数据可以针对多家医疗机构展开研究,同时引入医药学词典、符号表情等内容,使医疗领域情感词典更加专业. 未来的研究可以进一步利用此情感分析方法从时间、地域等维度进行医疗服务患者满意度的对比分析.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
分析化学(2019年3期)2019-03-30
