
基于轻量化网络的眼部特征分割方法
2021-10-15 12:42郑戍华南若愚李守翔王向周陈梦心北京理工大学自动化学院北京100081
北京理工大学学报 2021年9期
郑戍华,南若愚,李守翔,王向周,陈梦心 (北京理工大学 自动化学院,北京 100081)
高分辨率眼部图像中瞳孔和虹膜等结构具有绝对面积占比小、自身颜色接近、易受到外部因素遮挡和干扰等特点,精准检测很难实现. 随着深度学习的兴起,基于CNN的语义分割网络能有效对输入图像完成空间分类和像素级精细分割[1],在眼部特征检测领域得到了广泛研究. YIU等[2]在UNet[3]的基础上,提出一种改进分割网络,可较为精准分割完整瞳孔区域,为视线估计提供了可靠保障,但对分辨率为240×320的图像单帧检测速率仅有30 FPS. ARSALAN等[4]将残差模块引入编码器-解码器结构,所设计的网络能从可见光和红外眼部图像有效分割出虹膜部位,但网络规模达9.7 Million,需占用大量计算资源.
为了提高网络计算速度,ENet[5]、LEDNet[6]采用空洞卷积、金字塔注意力模型等方案,以一定分割精度损失为代价,大幅缩减了网络参数. 在眼部特征分割领域,PERRY等[7]利用扩张卷积和非对称卷积重新设计了ENet瓶颈模块,保持眼部特征较高分割精度的同时网络体积仅有原来的0.63倍,但在镜片反光等复杂环境条件下的分割能力较弱. CHAUDHARY等[8]利用跳级连接思想增强了高、低级语义特征的联系性,但对模糊和失焦图像的分割性能较差.
本文针对深度学习的眼部特征检测在算力有限的PC、嵌入式系统等设备上的应用,研究一种基于双输入注意力机制的轻量化眼部特征分割网络DIA-UNet,在满足较高的分割精度要求下实现实时处理.
1 方 法
语义分割网络通常为单输入网络,需使用大量卷积计算分析图像中含有的物体颜色、边界及纹理信息,提取对应有效特征,由于深度学习端对端的黑盒学习机制,网络中部分特征图存在高度冗余性[9],如图1(a)中的①和②所示. 大型网络通常利用体积优势提高有效特征绝对数量,进而减小冗余特征影响,而轻量化单输入网络结构通常较小,没有体积优势. 为解决冗余特征问题,DIA-UNet使用双路输入方案,在网络输入端设计两路结构近似的对称通道,利用不同图像下目标信息表征不同的特点,通过不同输入端分别对相应潜在特征学习提取,利用更多的原始信息变相增加有效特征的数量,从而保证了网络的分割性能.
双路输入通常使用多设备采集方案[10],需实现信息同步采集与校准,硬件精度偏差会导致模型准确率大幅下降,使用复杂度和训练成本都相对较高. 受传统图像处理领域轮廓滤波启发,轮廓图能最大程度忽略色彩影响,以非常低的算力消耗获取物体边界信息,提供对应边界特征. 图1(a)和1(b)是眼部灰度图及其轮廓图分别在UNet编码端第二层的部分特征可视化效果图,由于轮廓图提供物体轮廓边界,网络在训练过程中习得的特征向量为边界特征,为分割网络在目标边界处理时提供与灰度图差异化的信息. 基于轮廓滤波的特点,使用灰度图-轮廓图作为双路模式的输入可实现单一设备采集,该方案近似对传统单路输入网络的卷积层线性切分,根据输入类型分别进行引导式特征提取,可有效减少端对端模型冗余特征数量.
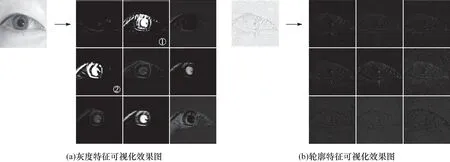
图1 中间层可视化效果图Fig.1 Visuallzation of the middle layer
双路输入结构能有效提取差异化特征,但在网络轻量化过程中,大幅缩减卷积计算和网络深度仍会导致整体学习性能下降,而注意力机制[11]能较好解决过度轻量化带来的精度损失问题. 为此,本文提出了一种双注意力模块,利用编码端灰度和轮廓特征对解码端特征实现同时聚焦,快速筛选出少量关键特征而忽略非关键信息,迫使网络增强对局部细节的关注,有助于进一步缩减网络体积,加快处理速度,提升推理效率.
2 实 现
2.1 总体框架
DIA-UNet为编码-解码跳级连接结构,详见表1.
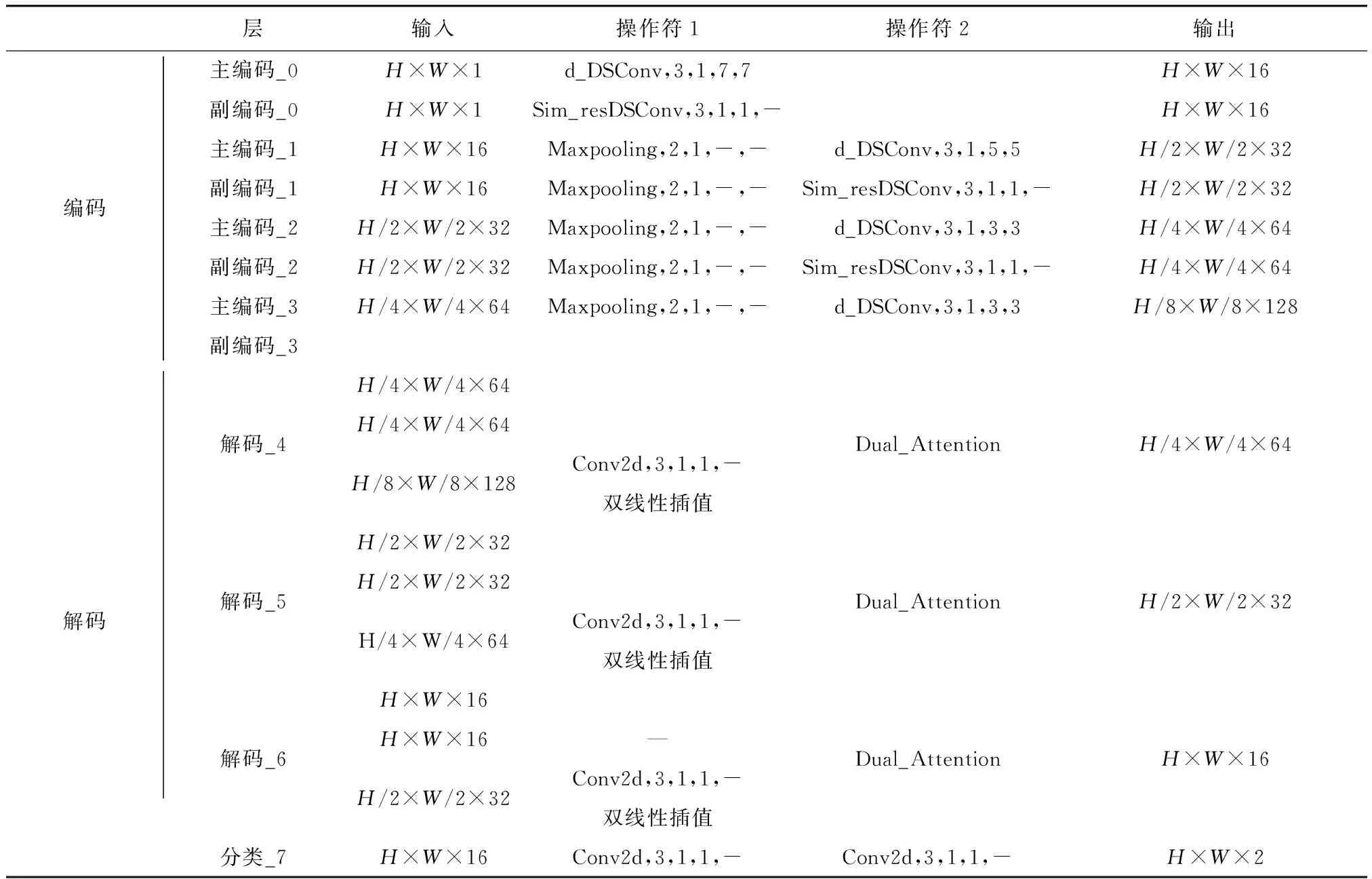
表1 DIA-UNet结构Tab.1 Structure of DIA-UNet
编码端分为主、副两路编码路径,分别输入灰度图及其轮廓图,形成镜像对称结构. 主、副编码路径中目标图像通过快速卷积模块初次提取得到大小为H×W×16的特征,再经过连续的下采样操作和快速卷积模块,分别获取不同大小编码特征. 解码端整体结构与编码端呈轴对称,通过双注意力模块逐层恢复特征图至目标尺寸,其中双注意力模块的三路输入分别为经卷积上采样后的前一级高级语义特征、轴对称端同一级灰度图特征以及轮廓图特征. 最后由分类层计算实现目标分割.
2.2 快速卷积模块
① d_DSConv模块.
d_DSConv模块针对灰度图,以深度可分离卷积为基础改进设计,减少卷积计算负担;将分组卷积的卷积核更改空洞卷积核,增大卷积核感受域以获取更多灰度图像细节特征. 模块实现如表2所示.

表2 d_DSConv模块Tab.2 d_DSConv module
② Simple_ResDSConv模块.
针对轮廓图边界信息清晰但信息总量稀少的特性,设计了简化的深度可分离残差卷积模块,Simple_ResDSConv模块结构如表3所示.

表3 Sim_ResDSConv模块Tab.3 Sim_ResDSConv Module
除去残差结构中旁路信息增维部分,避免深层卷积引入不必要计算而造成轮廓特征快速衰减. 此外由于轮廓特征分布相对松散,RELU等常用非线性操作的负数归零性质会使副路径大量神经元快速失活,为获取更多副路径特征信息,使用RRELU对负数部分随机缩放.
2.3 双注意力模块
针对灰度图-轮廓图双路输入模式,提出了能充分保留和利用轻量化网络高级语义特征的双注意力模块,采用编码特征增强解码特征方案,详细结构如图2.
图2中双注意力模块以上采样后的编码特征

图2 双注意力模块结构图Fig.2 Structure diagram of dual attention module
xdec为主干,由卷积降维后得到中间特征xmid,再分别与灰度图编码特征xmain和轮廓图编码特征xbranch结合,通过注意力生成路径,形成两张注意力权重图. 注意力生成路径为含有批量归一化的逐点卷积模块fi(xj),再对相加后的中间特征进行RELU6和Sigmoid非线性变换生成尺寸为H×W×1的
i,j∈{main,branch,dec,mid}
(1)
r∈{main,branch}
(2)
利用权重图分别指导主干路径中由随机对称裁剪得到的编码特征,形成以轮廓信息增强和灰度信息增强的注意力特征yr. 最后与xdec拼接生成双注意力融合特征z
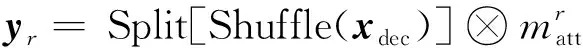
(3)
z=Shuffle(ybranch|ymain|xdec)
(4)
在对称剪裁之前和特征拼接之后均采用了channel shuffle操作[12],在不同注意力模块中按组均匀分配特征通道,进一步打破了轻量化网络自身深度浅、特征学习单一的局限,同时防止了编码端深度可分离卷积使用分组卷积带来的边界效应,加强目标细节分割捕获能力.
3 实 验
3.1 数据集
CASIA-Iris-Interval数据集:虹膜分割实验使用由中科院收集整理并开源的CASIA-Iris-Interval数据集. 采集设备为圆形近红外LED阵列相机,分别对249个实验者进行双眼虹膜采集,总计2 639张图像,图像分辨率为280×320.
高分辨瞳孔数据集:现有开源的瞳孔数据集相对较少,CASIA-Iris-V4等虹膜数据集虽然含有瞳孔细节,但存在数据采集环境固定、仅精选眼部细节完整非模糊的静态图像和没有真实标注等问题. 为解决上述缺陷,本文建立了专用于瞳孔分割的高分辨率瞳孔数据集. 使用帧率为18 FPS、分辨率为3 648×5 472的近红外相机对多位受试者进行连续面部采集,考虑不同光照条件、面部转动、是否佩戴眼镜等外部因素,从15段采集的视频中随机选取2 000帧进行眼部图像切割并完成瞳孔部分精标定,图像分辨率为360×480,采集总量为4 000张.
3.2 实施细节
实验环境:整个网络基于Pytorch1.2框架搭建,实验平台为MSIGT62VR笔记本电脑,使用装有CUDA10.1和CuDNN9.0的单块GTX1070训练和评估,GPU显存为8 G.
参数设置:训练网络时单次批量处理大小设置为10;使用交叉熵损失和Adam优化器进行网络损失计算和参数更新;初始学习率设为0.001,更新方法采用自适应调整法,衰减倍数为0.85,容忍度为3,更新指标为验证集目标交并比;训练次数设置为100 epoch;训练、验证和测试集以7∶1∶2的比例随机选取;由于两种数据集总量限制,对训练数据集通过随机翻转和0.8~1.4倍尺度缩放等手段进行数据集扩充.
3.3 评估指标
为验证网络的性能,对比实验选取4个轻量化语义分割网络,包括:ENet[5]、LEDNet[6]、minENet[7]及RITNet[8]. 从网络评估指标和网络综合评判标准两个方面进行性能对比.
网络评估指标包括实施效率和目标分割性能,实施效率包括运行速度v、可训练参数数量T和网络大小S;分割性能为预测分割P和真实背景L的交并比PIOU,计算公式如下
(5)
网络综合评判标准采用OpenEDS数据集提出的综合尺度M,数值越大,整体性能越高,计算公式如下
(6)
(7)
3.4 实验结果
3.4.1虹膜分割实验
CASIA-Iris-Interval数据集虹膜分割效果对比如图3所示,其中虹膜内边界明显,不同网络均能实现较好的虹膜-瞳孔边界分割,分割效果基本持平. 对色彩对比度相对较小,且多存在外部遮挡的虹膜-巩膜边界,DIA-UNet拥有更精细的边界分割能力,相较于其他网络错误分割概率更低,不存在图3中minENet 1,3,5行和RITNet 2,3行所示的分割缺失或多余情况;对复杂遮挡问题,也能最大程度接近真实边界,整体情况分割能力优于ENet、LEDNet.

图3 CASIA-Iris-Interval数据集虹膜分割效果(灰色、黑色代表正确、错误预测)Fig.3 CASIA-Iris-Interval dataset iris segmentation results (gray and black represent correct and incorrect predictions)
表4给出CASIA-Iris-Interval数据集网络性能定量比较结果. 不同网络的虹膜分割精度均能达到95.5%及以上,本文所提网络达到了96.05%,优于MinENet和RITNet,仅比性能最优的LEDNet低0.42%,拥有优异的虹膜内外边界分割能力. 在分割精度基本持平的情况下,本网络计算参数T仅0.076 Million,比LEDNet少12倍,相较剩余网络计算参数至少提升177%;处理速度为123.5 FPS,是LEDNet的1.98倍,比RITNet仍快约20 FPS;网络综合评价达98.03. 实验结果表明本文提出的轻量化网络能快速高效地进行虹膜语义分割.

表4 CASIA-Iris-Interval性能评估Tab.4 CASIA-Iris-Interval performance evaluation
3.4.2瞳孔分割实验
轻量化网络瞳孔分割效果对比如图4所示. 由于瞳孔数据集采集环境复杂、瞳孔面积占比小、存在部分快速眼动导致的模糊数据,不同网络检测性能较虹膜分割均有一定程度下降. 如图4第1,2,4行这类瞳孔边界清晰的图像,DIA-UNet分割结果更接近真实标注. 图4第3,5行所示的睫毛遮挡、眼镜反光等情况,所有网络预测能力均会下降,瞳孔边界都出现了不同程度的多余分割,但本文所采用的双输入方案和注意力机制有效减少了多余分割的总数.
表5为瞳孔分割定量性能评估结果. 本文提出的网络在各项评估指标中均占优,其中瞳孔分割精度可达92.29%,相较于其余网络至少提升0.48%. 由于瞳孔数据集分辨率高于CASIA-Iris-Interval数据集,所有网络整体处理速度均略有下降,但DIA-UNet仍可达100 FPS.

表5 高分辨率瞳孔数据集性能评估Tab.5 High-resolution pupil dataset performance evaluation
3.4.3结构有效性探究
为研究双路结构和注意力机制对网络轻量化精度的影响,使用瞳孔数据集对UNet[2]、AttentionUNet[11]、DI-UNet和DIA-UNet进行网络体积-分割精度对比,结果如图5所示.
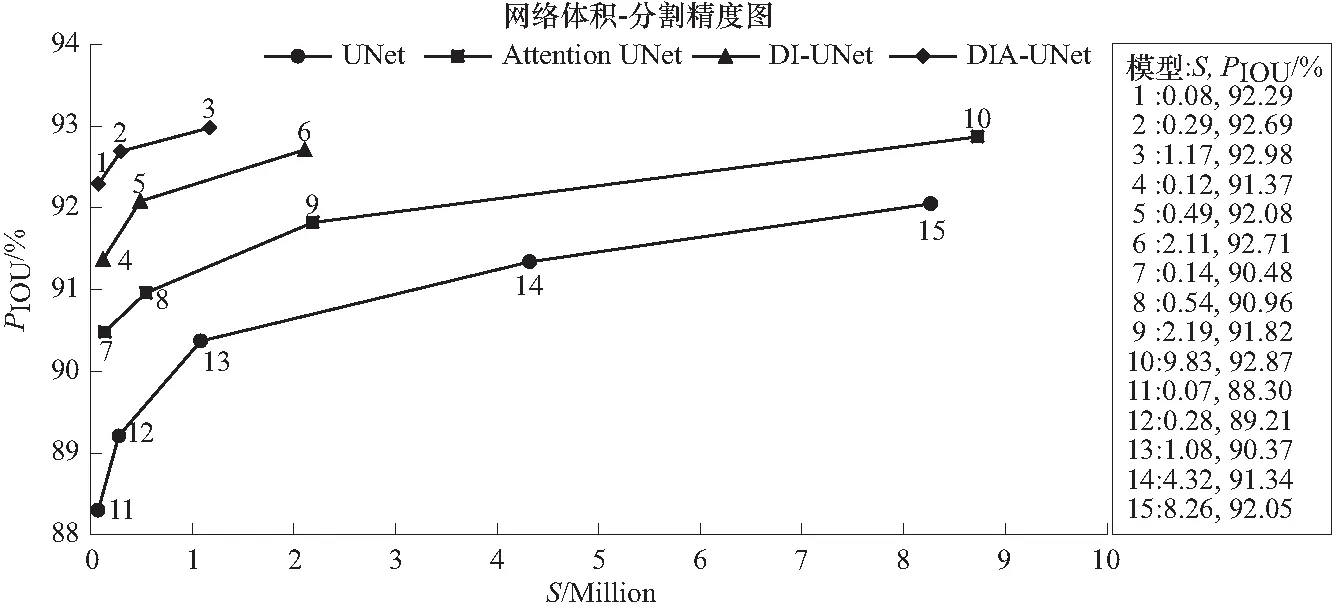
图5 网络体积-分割精度对比Fig.5 Network size-segmentation accuracy comparison
各网络大小和精度呈正相关,不同网络在体积结构缩减的情况下会造成一定程度的精度下降. 其中UNet最高PIOU仅有92.05%,且对体积减小敏感,精度降幅可达3.75%. 注意力机制能在有效帮助网络轻量化的同时可提高对目标的聚焦,一定程度上减小错误分割比例,模型7能保证精度在90.48%左右. 由于在输入端提前获取了轮廓信息,DI-UNet相较于同体积Attention UNet有1%左右的精度提升. 本文提出的DIA-UNet保证了网络轻量化时,分割精度至少在92.2%以上,整体损失小于0.7%,优于其余3种网络.
4 结 论
针对在算力有限的PC或嵌入式设备上对高分辨率眼部图像中瞳孔、虹膜实时准确分割,提出一种基于双输入注意力机制的轻量化眼部特征语义分割网络DIA-UNet. 利用灰度图及其轮廓图的潜在特征差异性,设计了双路输入结构和双注意力模块分别实现了不同细节特征提取和多特征融合. 在CASIA-Iris-Interval和高分辨率瞳孔数据集上测试结果显示,DIA-UNet网络计算参数仅0.076 Million,对虹膜和瞳孔分割准确率分别能达到96.05%和92.29%,推理速度最高为123.5 FPS,拥有更轻量化的结构体积、高速网络推理能力和较高分割精度.
猜你喜欢
兵器装备工程学报(2022年8期)2022-09-13
北京航空航天大学学报(2022年6期)2022-07-02
中国典型病例大全(2022年11期)2022-05-13
集装箱化(2021年1期)2021-04-12
中国信息技术教育(2020年2期)2020-02-02
快乐作文(7.8年级)(2019年6期)2019-09-10
汽车实用技术(2019年6期)2019-04-11
文萃报·周二版(2018年51期)2018-08-04
阅读与作文(初中版)(2017年6期)2017-07-05
恋爱婚姻家庭·养生版(2015年2期)2015-05-14
