
如何利用ArcGIS对面拓扑错误批量修改
2021-10-14 07:47黄思明
林业勘查设计 2021年5期
黄思明
(黑龙江省林业和草原调查规划设计院绥化院,黑龙江 绥化 152000)
引言
ArcGIS (地理信息软件)自诞生以来,其应用越来越广泛,它不仅能够管理空间信息数据,还能对庞大的数据进行各种分析和处理。ArcGIS被广泛应用于林业工作中,能够轻松地实现栅格数据的镶嵌以及裁剪、矢量化,对于各种矢量数据也能够根据不同的需求,进行处理和分析,形成各类成果。
随着林业技术的进步和发展,大数据时代应时而生,云端让大数据的应用更加具有实用价值。利用大数据进行全国林地落界和林地变更,整合林地基础信息资源,开发建设我省林业大数据前置平台,为林业管理工作提供了信息化手段。基础数据的真实可靠,是平台应用的前提和必要条件。在以往的林业管理工作中,很多数据没有进行过系统的检查和综合分析,特别是拓扑分析,导致大数据时代的数据应用出现很多错误和问题,降低了数据使用效率,浪费了历史调查数据的参考价值,甚至导致数据完全不可用。因此数据的拓扑检查,特别是大数据时代的拓扑检查效率尤为重要。
1 拓扑检查
自ArcGIS 8以后,Geodatabase(地理数据库)已成为一种全新的空间数据模型。它是一种开放的空间数据结构,能存放并处理矢量、栅格、多种格式图片、三维地形等。可是Geodatabase中不能直接建立拓扑关系,需要通过数据集去构建拓扑关系。同一种要素类(点、线、面)之间的公共点、公共边等要素是在建立拓扑之后,通过拓扑的编辑过程中动态地检测到的。例如,我们想对两个面的公共边进行修改或者编辑,那么Geodatabase将自动检测到与此公共边要素具有公共几何关系的所有其它要素,当我们修改该条公共边要素或者该公共边上的某个点时,系统会自动对该公共边或公共点所涉及的所有面要素进行维护,以保持其原有的拓扑关系。这种方法的优点在于可以对特定部分,有选择的维护和修改拓扑关系,但是对于大量的数据修改就显得不快捷,耗时费力。
1.1 建立拓扑关系
建立拓扑关系最重要的就是注意投影与坐标设定。由于拓扑关系只能在要素数据集里操作,所以在导入数据的时候,投影的设定一定要与矢量数据保持一致。同时添加拓扑规则,如不能有面空隙、不能有面重叠。表1是某两个林场数据在拓扑错误检查时,显示的错误类型和数量。

表1 拓扑错误类型和数量Tab.1 Type and Quantity of Topology Errors
1.2 面重叠的修改方法
面重叠可以通过以下几种方法进行修改。首先可以直接修改要素节点,去除重叠部分。第二种方法是在错误检查器中的相应错误上右键选择merge(合并),将重叠部分合并到其中相邻的一个面里。第三种方法是在错误的右键选择create feature(创建要素),将重叠部分生成一个新的要素,然后利用editor(编辑器)下的merge(合并)把生成的面合并到相邻的面中。第四种方法是用editor(编辑器)下的clip(裁剪)功能,直接将重叠部分裁除。
1.3 面空隙的修改方法
面空隙可以通过以下几种方法修改。第一种去节点,可以直接修改空隙面上的节点要素;第二种方法,在该空隙错误上右键选择create feature(创建要素),此时空隙部分会生成一个新的面要素,然后利用editor(编辑器)下的merge(合并)把生成的面合并到相邻的面里。第三种在task(创建要素)菜单下选则auto-complete polygon(自动完成面)工具,用草图工具功能自动生成多边形,此时空隙区域会自动生成一个新面,按照上述办法,再将面合并到相邻的面里。
无论基于以上哪种办法,都需要对7000多个错误逐一修改,工作量无疑是巨大的而且不能保证全部正确。
2 批量修改
拓扑检查出来的面错误,想要实现批量操作并不能在拓扑数据库里进行操作,而是需要用数据管理工具中要素工具进行操作。
2.1 添加识别字段
在属性表中添加字段“编号识别”,利用字段计算器计算该字段,令其等于FID或者OBJECTID,得到如图结果。此步的操作目的有二,一是将原始地块和即将要新生成的面区别开来,二是为了下步属性的空间链接做准备。
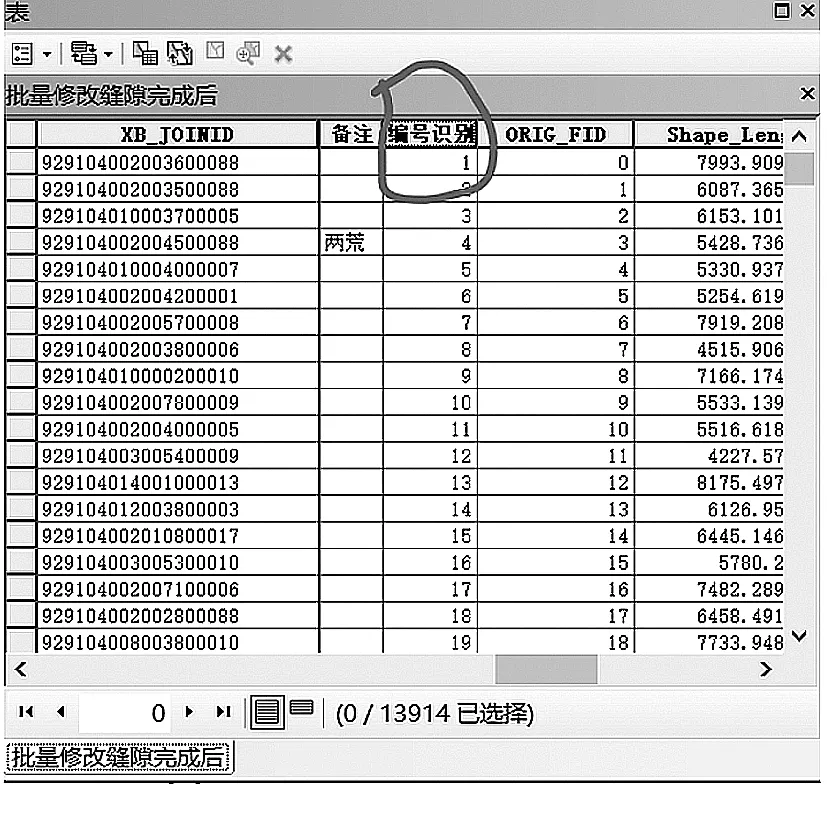
图1 编号识别Fig.1 Number Identification
2.2 要素转点
打开工具箱,数据管理工具目录下要素转点。这一步操作的目的是每个小班面转成其内部点。因为此处的点和原始的面属性是一一对应的,为了便于与最后形成的面在同一位置保证属性链接。注意,转点时要将“内部”项勾上,这样能保证每个小班所转的点都会落在小班面内部,避免很多不规则的小班将中心点落在外面,而影响下一步操作。
2.3 要素转线
同样的路径下,要素转线。注意,是要将原始小班面转线。
2.4 要素转面
此步的操作是将上一步转成的线层再生成面层。这样做的结果就是将重叠和空隙的部分都将生成独立的面状小班。此时的面要素已经不存在空隙和重叠部分。
2.5 结果检查
此时可以将拓扑关系中检查出来的错误导出,作为参考,对照相应位置错误是否已被修复。具体操作如下:数据管理工具下-拓扑-导出拓扑错误。此时会形成两个新的图层,一个是线层,一个是面层。线层代表的是空隙错误,面层代表的是重叠错误。
2.6 点面空间链接
这一步的操作目的是实现属性的链接。此时生成面层,属性是空值,没有属性。而且原始面原有的属性和字段都不存在,属性表只有系统自动生成字段。第一步转成点层的目的就是为了此时将属性进行链接。具体操作分析工具-叠加分析-空间连接,所得结果图2所示。

图2 空间连接Fig.2 Spatial Connection
筛选编号识别字段,“0”值为新形成的面。其中重叠部分单独成面,空隙部分也被创建成要素面。
2.7 消除空值
此步的操作就是要消除这些“0”值。有两种方法,第一种可以逐个点取,选择相邻的适宜的面进行逐个合并。第二种方法就是利用数据管理工具中制图综合的消除工具。具体操作数据管理工具-制图综合-消除。此步操作需注意要素的选择,必须从属性表中选出属性为空值的进行操作,将面与具有面积最大或公用边界最长的邻近面合并来消除面。具体操作属性表-按属性选择-编号识别=0。
编号识别中空值字段已经全部被合并。此时可以再建拓扑进行检验。
图3 消除空值Fig.3 Eliminating Null Values
3 不足与改进
这种方法虽然操作简单快捷,准确率高,但是对那些面两端都跨多个小班的狭长缝隙和重叠面的操作有一定不准确,可能会形成尖锐角。
这种现象主要见于各个林场的接界处,由于早些年没有先进的检查软件和技术支持,导致各个林场的数据“各自为政”,汇总全局图的时候就会出现这种肉眼难以察觉的狭长缝隙或重叠。虽然此时拓扑错误已经纠正,但是对于数据的美观来讲还存在的一定的瑕疵。需要另一样工具对其修正。扩展模块下的Data Reviewer工具具有检测急锐角化的功能。实际操作中对于角度要求一般需大于30度。
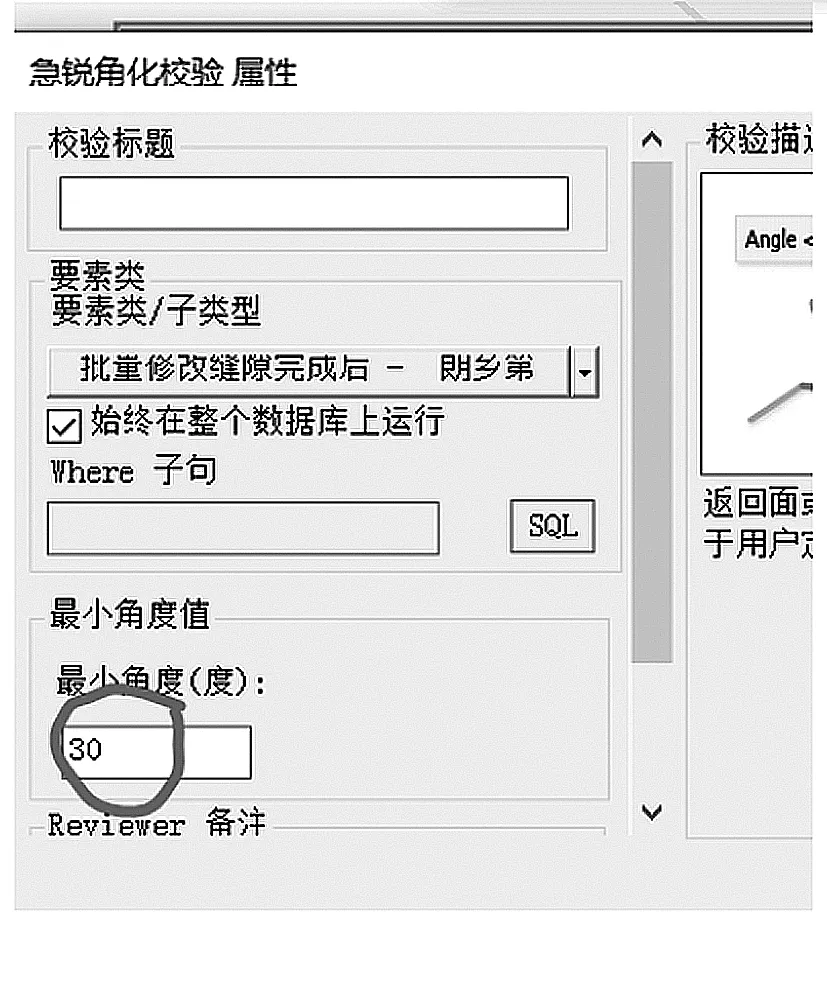
图4 急锐角化校验Fig.4 Sharp Angle Verification
这样就可以对整个数据库里的急锐角化误差进行检测并对其改正。
4 结语
拓扑关系被用来描述要素之间的几何错误,在确定要素之间的空间位置关系之后,才能进行相应的查找和修改,但是需要对其手工逐一检查,对技术人员的技术和水平也有相应的要求,出错率也相对高些。大数据平台的应用加快我省实现数字化林业的进程,对生态林业的发展具有非常重要的价值,大数据是需要庞大的数据作为基础支撑,具有大量、高速、真实等特点。同时生态林业的生存和发展是一个长期且不断更新的事业,离不开大数据的支撑,只有通过大数据不断的积累和演算分析,才能够更好地为生态林业提供更加合理的资源配置方案。这些要求决定了我们对数据的处理在保证其准确和精确的前提下,提高效率非常重要。利用上述方法属性的操作基本实现零失误,同时对于矢量面上角度的要求,可以得到任意角度的检测和改正,最重要的是通过批量处理拓扑存在的问题,可以高效提升作业效率。
猜你喜欢
课程教育研究(2021年24期)2021-04-14
幼儿教育·教育教学版(2020年8期)2020-12-23
当代水产(2020年4期)2020-06-16
甘肃教育(2020年8期)2020-06-11
满族文学(2019年5期)2019-10-08
领导决策信息(2017年14期)2017-06-21
山东青年(2016年2期)2016-02-28
债券(2015年9期)2015-09-29
散文百家(2014年11期)2014-08-21
筑路机械与施工机械化(2014年8期)2014-03-01
