
基于高斯混合模型的相关子空间投影聚类分析
2021-10-14 10:24:04武政平荀亚玲
太原科技大学学报 2021年5期
武政平,荀亚玲
(太原科技大学 计算机科学与技术学院,太原 030024)
聚类分析[1]作为数据挖掘中应用较为广泛的无监督技术之一,被广泛应用于文本挖掘[2]、模式识别[3]和Web搜索[4]等领域。随着大数据涌现,高维数据的聚类成为大家关注的重难点之一,传统聚类分析方法都会受到“维灾”影响,使聚类分析效果较差。子空间聚类作为一类聚类分析方法,选择一些对聚类分析贡献价值高的属性所构成的子空间,并对数据对象之间存在的相似性度量,有效地克服“维灾”的影响[5],提高了聚类效果。
投影聚类作为一类子空间聚类,有效降低了冗余属性或无关属性对聚类分析的影响,但选择簇所在的投影子空间时,未充分考虑各属性维自身所具有的特征,从而降低了聚类分析效率。本文采用高斯混合模型定义下的相关子空间,充分体现了各属性维自身所具有的特征,并提出了一种投影聚类分析算法。
1 相关工作
传统的聚类方法,例如基于划分,基于密度,基于模型等会受到“维灾”影响,不再适用于高维数据集。投影聚类作为一类子空间聚类分析方法,通过将数据集投影到若干属性维构成有意义的低维子空间上,并根据数据间的相似性实现聚类分析[6],有效降低了“维灾”影响,已成为高维数据聚类分析的研究热点之一。
如何寻找簇所在的有意义子空间是投影聚类的难点,目前的典型研究工作为:CLIQUE[7]算法采用密度和网格的思想,可以自动发现聚类簇所在的子空间,但子空间剪枝会丢失部分密集区域。Aggarwal等人用SVD寻找簇所在的相关子空间,提出了ORCLUS算法,既可以发现轴平行的子空间聚类簇,也可以发现非轴平行的子空间聚类簇。但需要预先指定子空间的维数,使聚类分析随着空间维度的增加伸缩性变差。Procopiuc等人用超立方体方法,提出了DOC[8]算法,进一步提高了聚类簇的质量,但设置全局的间隔宽度使其缺乏灵活性;聚类迭代过程需遍历整个数据集,时间复杂度呈现指数增长。Yip等人通过自动调整最小相似和最小相似维参数来指导聚类族的合并和相关子空间的确定,提出了HARP[9]算法,优点每个簇可以自动确定相关维,凝聚过程仅在确定的相关维中进行,有效提高了凝聚效率。此外,层次聚类固有的高时间复杂度也很难应用于大数据分析。此外,Mohamed等人用稀疏因子得到原始数据的稀疏度矩阵,结合伽玛分布,找到该聚类的轴平行的线性相关子空间,提出了PCKA[10]算法,优点是寻找相关子空间变得容易,但忽略了每个维度自身的特点以及无关属性对聚类精度和效率的影响。
综上所述,投影聚类是高维数据聚类分析有效途径之一,有效地降低了“维灾”影响,但在确定簇所在的相关子空间时,具有较高的时间复杂度;预先设定的参数值选择不合适时,导致聚类精度无法保证,限制了投影聚类的适用性;选择子空间时,未充分考虑各属性维自身所具有的特征,从而降低了聚类效率。
2 相关子空间
随着高维数据维度的增加,“维灾”现象和数据自身的稀疏特性对聚类分析效果影响也越来越明显。在高维数据中,数据对象只有在其有意义的属性维集合中,才能体现出贡献价值高的信息。在聚类分析中,将数据对象分布较集中或聚类簇中各数据对象的密度差异较小构成的子空间,称为相关子空间或稠密子空间,即相关子空间可以反映聚类簇所在属性维上的有用信息,而数据集在此区域分布比较稀疏或数据对象的密度差异比较明显构成的子空间,称之为不相关子空间或稀疏子空间,即不相关子空间未能充分反映与聚类簇的有用信息。
在文献[10]中,采用稀疏度因子,寻找与聚类分析有关的属性维子集构成的相关子空间。设伽玛分布的组件为q,数据集DS是由n条d维数据对象obj的组成的任意数据集,其中obji表示第i个数据对象,Aj表示第j个属性维,Xij(i=1,2,…,n;j=1,2,…,d)表示第i个数据对象obji在第j个属性维上的取值,yij是第i个数据对象obji在第j维属性(Aj)的稀疏度因子,对每一维度稀疏度的频率进行统计,并用伽玛分布进行拟合。locq代表组件q的位置,loc代表每个维的所有locq值在整个数据集中的集合,即loc={loc1,…,locq,…,locmtotal}.通过MDL选择技术和EM算法来识别每个数据对象obj每个维度稀疏度因子y出现频率所在的子空间来判断。如果子空间是稠密子空间,Zij赋值为1;如果子空间是稀疏子空间,Zij赋值为0.称向量Zi={Zi1,Zi2,Zij,…,Zid}是obji的子空间定义向量。向量Zi中,由Zij=1属性维集构成的子空间称之为obji的相关子空间,由Zij=0属性维集构成的子空间称之为obji的不相关子空间[11]。
在文献[12]中,利用数据对象的KNN寻找其所在的相关子空间。由数据集DS中的各个数据对象及其局部数据集LDS,可以有效地确定各个数据对象所在相关子空间形成的簇。对于数据集中任意一个数据对象obji,LDS是由数据对象obj本身与其KNN得到的K个数据对象组成的局部数据集。因此,将计算数据对象各属性值Xij相对于LDS的局部稀疏度因子计算公式定义如下:
(1)
(2)
其中:pj(xi)代表的是数据对象xi的局部数据集LDS在其j维属性上取值构成的集合,cij代表的是pj(xi)的平均值。
由公式(1)可知,yij代表的是局部数据集各属性维的平均值偏离程度,yij较大时代表此属性维的分布比较分散,表明xij在其局部数据集中密度较小,xij所在的子空间为稀疏子空间(不相关子空间);yij较小时代表此属性维的分布比较集中,表明xij在其局部数据集中密度较大,xij所在的子空间为稠密子空间(相关子空间)。由此可见,稀疏度的引入可以更加方便地度量数据空间的稠密和稀疏区域,进而发现空间高维数据的相关子空间。
3 高斯混合模型与无关属性剔除
3.1 高斯混合模型与相关子空间
在文献[10]中,通过引入稀疏度因子来度量高维数据集中的相关子空间和不相关子空间,却忽略了每一维度稀疏度因子自身的属性特征;通过对每一维度稀疏度出现的频率进行统计,而每一维度各稀疏度出现的频率分布可以用伽玛分布进行拟合,虽然也能较好地体现数据的分布,但是PCKA算法通过探测伽玛组件来确定稠密区域时,是基于所有伽玛组件在所有维度上的中位数是可比的。当数据集中包含的簇密度差异很大或者一部分簇分布在稀疏区域时,却会丢失部分相关属性维,导致所确定的相关子空间不够准确,适用性降低。
由公式(1)可知,由数据集的各属性值对应的局部稀疏因子,可生成整个数据集的稀疏因子矩阵。在稀疏因子矩阵中,每个维度的稀疏度yij由稀疏子空间和稠密子空间两部分混合而成。高斯混合模型可以精确地量化事物,其灵活性可以很好地拟合各属性维度稀疏度的分布,同时体现各维度中稠密区域所在的位置,且不需要在全维度上进行相似性度量,有效解决了当聚类簇间密度差异很大或者聚类簇分布在稀疏区域时造成相关属性维的丢失问题,为聚类分析提供更多有价值的信息。仅需考虑各维度稀疏度自身特点,且适应于分布不同数据集。EM算法作为一种常用的迭代算法,具有良好的可操作性和收敛性,高斯混合模型的各个参数可以通过EM算法来得到。因此,采用高斯混合模型和EM算法可以有效地识别每个数据对象在各属性维度上的稀疏程度,并确定所在的子空间是稀疏子空间还是稠密子空间,并将其识别得到的稠密子空间视为相关子空间。刻画和描述数据对象维度的稀疏度因子的高斯混合模型定义如下:
(3)
(4)
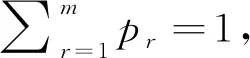
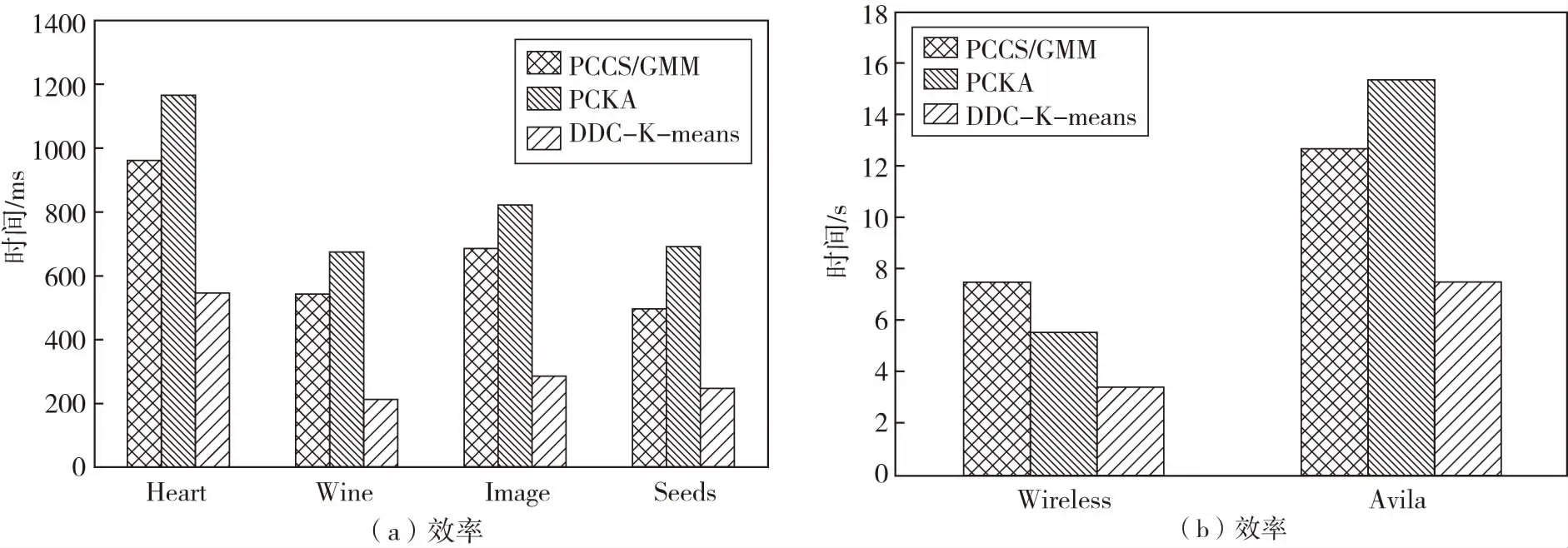
采用高斯混合模型对数据对象的每一维度的稀疏度因子进行拟合时,由于稀疏度因子由两部分组成,即稀疏部分和稠密部分。将稀疏度较小的数据构成的稠密子空间定义为相关子空间,稀疏度较大的数据构成的稀疏子空间定义为不相关子空间,因此将组件个数设为m=2.通过EM算法对参数进行估计就可以得到每一维度稀疏度因子属于两个高斯分布的概率值pi1和pi2.如果pi1>pi2,则该稀疏度属于第一个高斯分布;如果pr1 将Zij定义为一个二元矩阵,Zij∈{0,1},Zij代表的是第i个数据对象第j维度所对应的值,如果yij属于稠密子空间,则Zij=1;如果yij属于稀疏子空间,则Zij=0.Zi定义为子空间向量,在Zi中,值为1的所组成的属性维构成的是第i个数据对象对应的相关子空间,值为0的所组成的属性维构成的是第i个数据对象对应的不相关子空间。由此得到了每个数据对象的子空间向量。显然,利用公式(3)就可以得到数据集中各个数据对象的子空间向量。 在投影聚类中,无关属性主要包括:离群点、无关或冗余属性维等。如果数据集中包含有离群数据、无关或冗余属性维则会严重影响聚类效果。无关属性则是不同于其它数据对象或属性维的集合,不属于任何一个已识别的相关空间,而是属于不相关子空间中,为有效剔除高维数据集中的无关属性,可以充分利用二进制矩阵Z,因为二进制矩阵Z中包含了聚类分析所需要的有意义子空间和原数据集的位置有用信息。为了通过二进制矩阵的权重来识别那些相似的数据点,可以计算如下Jaccard相似系数来度量: (5) 其中:a=|Z1j=Z2j=1|;b=|Z1j= 1&Z2j= 0|;c=|Z1j= 0&Z2j=1|;j∈{1,2,…,d};JC的取值为0到1,当JC=0时代表两数据对象不完全相似,JC=1时代表两数据对象完全相似。如果两数据对象的JC值超过了预先设定的λ=0.7,则两数据对象相似需要保留。 综上所述,采用KNN生成每个数据对象的局部数据集,利用公式(1),计算数据集中每个数据对象每个维度的稀疏度因子,得到全局的稀疏度矩阵;每一维度稀疏度因子的分布可以用高斯混合模型进行拟合,利用EM算法对高斯混合模型中的参数进行估算,得到每个数据对象的相关子空间;然后,对数据集的无关属性进行剔除;最后,对处理后的数据集,采用K-means进行聚类。具体算法如下: 算法:PCCSGMM(Projection Clustering Analysis Algorithm Based on Gaussian Mixture Model and Correlated Subspaces) 算法 输入:数据集DS,条数为N,属性维度为d 输出:聚类结果 2) for(i=0;i 3) SPi = getSpd()/*依据公式(1)计算数据集DS中数据对象的稀疏度矩阵*/} 4) Z = getAllCorrelatedSubspace()/*计算相关子空间*/ 6) 对2个数据对象对应位置相减,得到多个位置的距离和矩阵,冒泡排序,得到每个数据对象的K近邻; 7) 利用公式(1)计算得到每个数据对象的稀疏度,通过EM计算每个数据对象每个维度属于k类别的概率; 8)在相关子空间中,将一个数据对象与剩余数据对象相应位置进行比较,每比较完一次,就将对应位置是1的个数进行求和,记录在result中; 9)基于步骤8)利用公式(5)计算相似度,如果相似度大于0.7且该数据对象的K近邻个数大于等于K则保留该数据对象,否则,剔除该数据对象; 10)基于步骤9)得到条数为n1数据集与矩阵,对每一维进行处理,如果某一属性全是0或全是1则说明该属性维对聚类影响不大,剔除该属性维; 11)处理后得到条数为n1维数为d1数据集进行基于K-means迭代L次输出k个簇,计算距离要考虑相关子空间中相关属性对簇形成的贡献。 12) ENDPCCSGMM PCCSGMM算法在计算每个数据对象的K近邻时,时间复杂度为O(N*logN),求稀疏矩阵的时间复杂度为O(N*d*k),识别不相关子空间和剔除无关属性维度的时间复杂度为2O(N*d)+O(N^2*d)+O(n1*d)≈O(N*d)+O(N^2*d),最后聚类的时间复杂度为O(n1*d1*k*L).因此,PCCSGMM算法总的时间复杂度为O(N*logN)+O(N*d*k)+O(N*d)+O(N^2*d)+O(n1*d1*k*L). 实验环境:Intel(R) Core(TM) i3-4010U CPU,4.00GB内存,Windows 7操作系统,Eclipse作为开发平台,采用java语言作为开发工具,实现了PCCSGMM算法。实验数据为UCI标准数据集。 表1 UCI 数据集信息 图1给出了PCCSGMM、PCKA、DDC-K-means,在不同数据集上的标准互信息的变化趋势实验结果,表明PCCSGMM算法均比PCKA、DDC-K-means算法的标准互信息高,主要原因是PCCSGMM算法在构建相关子空间时,采用高斯混合分布可有效地分区每个维的数据且考虑了每个属性维自身的特点,得到的相关子空间准确率较高。图2给出了PCCSGMM、PCKA、DDC-K-means算法,在不同数据集上的调整兰德指数的变化趋势实验结果,表明PCCSGMM算法在Heart数据集上效果较差,原因是Heart数据量较小维度较大,利用KNN就会变差,基于距离的K-means也会变差,造成聚类结果与真实标签的相似性降低,其它数据集上PCCSGMM均高于PCKA、DDC-K-means算法。 图1 NMI标准互信息的比较 由图1和图2实验结果可以看出,数据集的维度对PCCSGMM影响较小,主要原因是PCCSGMM利用了相关子空间中的属性维,删除了不相关子空间对聚类的影响。 图2 ARI调整兰德指数 图3给出了PCCSGMM、PCKA、DDC-K-means算法在不同数据集上的调和平均(V-measure)变化趋势实验结果,并表明PCCSGMM算法在综合考虑均一性和完整性方面优于其他对比算法,其主要原因是PCCSGMM算法可以自适应地对每一维度的数据进行有效区分,且考虑了每个维度在数据空间中的重要性,并可以发现大部分隐藏数据所在的相关子空间。 图3 UCI数据集对算法V-measure影响 图4给出了PCCSGMM、PCKA、DDC-K-means,在不同数据集上运行时间。图4(a)给出了中低维数据集Heart、Wine、Image、Seed上PCCSGMM及对比算法的效率变化趋势实验结果,实验结果表明PCCSGMM的效率高于PCKA,原因是PCCSGMM在确定相关子空间时对每一维度的密度因子进行高斯拟合来确定相关子空间,而PCKA在对每一维的密度因子频率进行拟合在确定稠密区域时基于全维可比得到,需要基于全属性上各维度可比进行排序来确定相关子空间,使算法的效率降低。PCCSGMM聚类分析前进行了无关属性剔除,使得K-means在计算距离的时间缩短,提高了聚类效率,而PCKA聚类前没有进行无关属性剔除,因此聚类效率略低于PCCSGMM.PCCSGMM效率比DDC-K-means低,原因是维度较低时,PCCSGMM计算KNN和剔除无关属性时消耗了较多时间。 图4(b)给出了PCCSGMM、PCKA、DDC-K-means算法在Wireless、Avila数据集上的效率变化趋势实验结果,该实验结果表明PCCSGMM在Avila数据集上的效率比PCKA高。原因是聚类分析前对无关属性进行剔除,K-means计算距离时消耗时间减少。但没有DDC-K-means好,原因是剔除无关属性消耗了较多时间。PCCSGMM在Wireless上效果较差,原因是Wireless数据集本身的无关属性较少,PCCSGMM在剔除无关属性时消耗时间较长。 图4 UCI 数据集对算法效率的影响 文中针对高维数据出现的“维灾”和无关属性对聚类分析的影响,给出了一种基于相关子空间的聚类算法PCCSGMM,该算法充分了考虑了数据每一维自身的特点,有效减少了不相关子空间和无关属性对聚类效率和精度的影响。采用部分UCI标准数据集进行验证,证明了PCCSGMM算法的有效性和准确性。接下来将设计应用系统用于光谱数据聚类分析。3.2 无关属性剔除
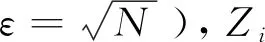
4 PCCSGMM算法描述
5 实验结果及分析
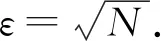
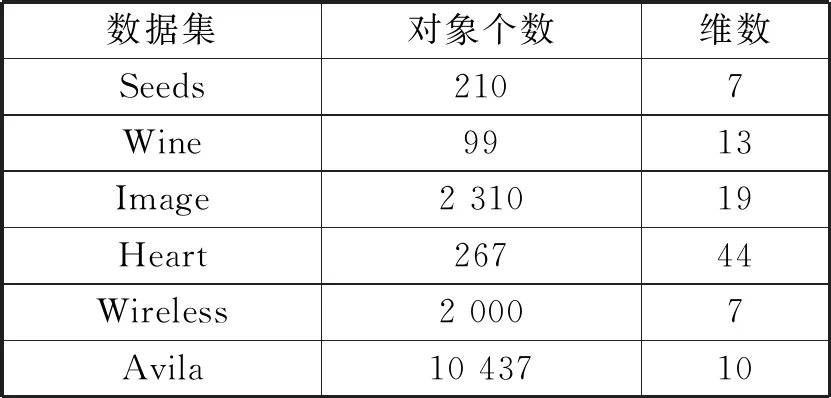
5.1 聚类精度

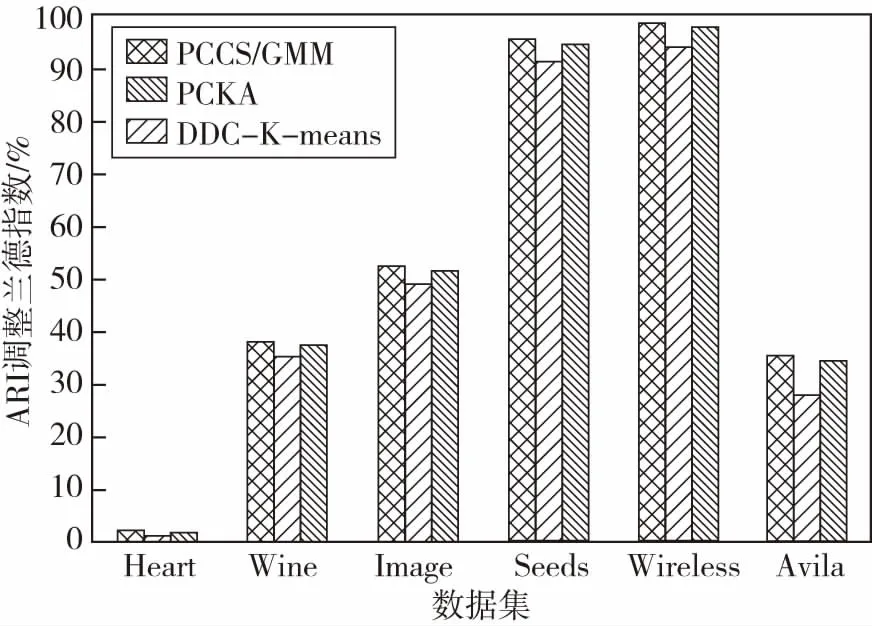
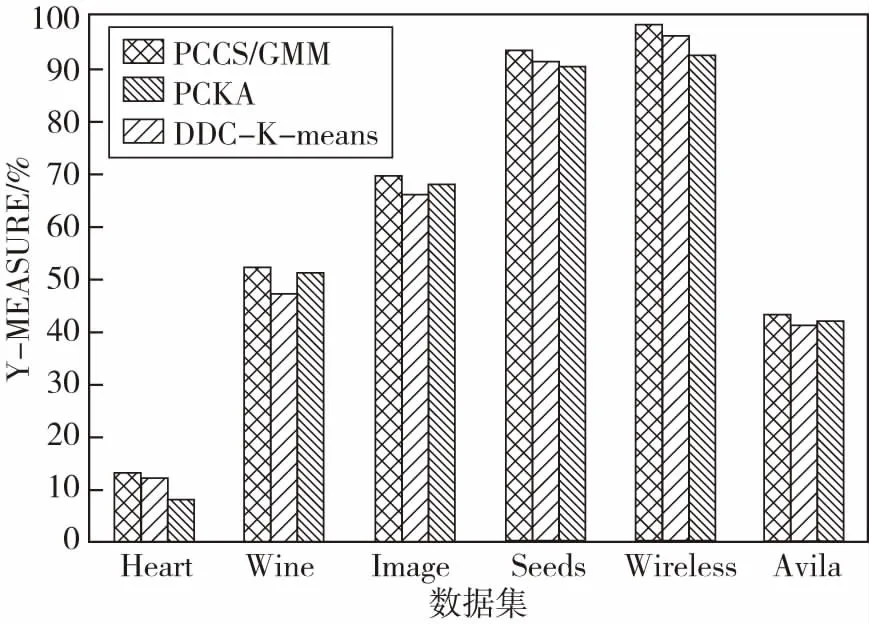
5.2 聚类效率
6 结论与展望
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10测控技术(2018年4期)2018-11-25 09:46:48电子测试(2017年15期)2017-12-18 07:19:27电信科学(2017年6期)2017-07-01 15:44:37智能系统学报(2015年4期)2015-12-27 09:38:39数学年刊A辑(中文版)(2015年3期)2015-10-30 01:56:52四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36电子设计工程(2015年6期)2015-02-27 12:04:53应用数学与计算数学学报(2014年3期)2014-09-26 12:03:56
