
基于图卷积神经网络的隐式篇章关系识别
2021-10-12 04:39阮慧彬吴成豪周国栋
中文信息学报 2021年8期
阮慧彬,孙 雨,洪 宇,吴成豪,李 晓,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
篇章关系识别旨在研究同一篇章内两个文本片段(短语、子句、句子或段落,简称论元)间的逻辑关系。作为自然语言处理(natural language processing,NLP)领域的一项基础研究,篇章关系识别在上层自然语言处理应用中具有重要价值[1],如情感分析[2-3]、机器阅读理解[4]、文摘提取[5]和机器翻译[6-8]等。篇章关系识别的任务框架如图1所示,给定一个论元对(Arg1,Arg2),使用篇章关系分类模型来识别两者间的篇章关系。

图1 任务框架
目前,篇章关系识别研究领域最大的权威语料库是宾州篇章树库[9](penn discourse treebank,PDTB),其根据不同粒度,将篇章关系定义为一个三层的语义关系类型体系。其中,最顶层的四类语义关系是:比较(comparison)关系、偶然(contingency)关系、扩展 (expansion)关系以及时序(temporal)关系。同时,根据两个论元表述间是否具有连接词(也称为线索词,如“because(因为)”等)作为衔接手段,PDTB将篇章关系分为两类:显式篇章关系(explicit discourse relation)和隐式篇章关系(implicit discourse relation)[1]。其中,显式篇章关系是可直接通过显式连接词推理得到的篇章关系类型。如例1所示,此显式偶然关系论元对包含显式连接词“so(所以)”,这一线索指明Arg2是由Arg1导致的结果,因此,我们可直接推理出例1中的论元对具有偶然关系。
例1 [Arg1]: and will take measures
(译文:并将采取措施)
[Arg2]:sothis kind of thing doesn’t happen in the future
(译文:所以这类事情不会再发生)
[篇章关系]: Contingency.Cause.Result
相对地,隐式篇章关系论元对中缺少显式连接词,所以其更依赖于词法、句法、语义以及上下文等特征,如下述例2中的“hurricane (飓风)”是需要落实“precautionary mechanisms (预防机制)”的原因,因此,可推导出此论元对包含的篇章关系为偶然关系。
例2 [Arg1]: With a hurricane you know it’s coming
(译文:你知道飓风将要来了)
[Arg2]: You have time to put precautionary mechanisms in place
(译文:你有时间把预防措施落实到位)
[篇章关系]: Contingency.Cause.Result
显式篇章关系研究目前已取得较高分类性能,Pitler等[10]采用显式连接词与篇章关系的映射即可达到93.09%的准确率。然而,隐式篇章关系识别性能相对较低,现有最优方法在四大类关系上的F1值仅达53%[11]。因此,本文针对隐式篇章关系识别任务展开研究。
前人将注意力机制用于论元表示的计算[12-16],来评估论元间词义信息的关联性,借以捕获重要的词义特征来辅助隐式篇章关系识别。然而,相关研究仅关注论元自身或论元间的词义特征关联性,因此,这种单一特征无法全面地表征论元语义信息。若仅关注论元交互信息,如例3中的词对信息“good-wrong (好的-错误的)”和“good-ruined (好的-毁坏的)”,其很容易导致此论元对被识别为对比关系[12]。但是如果论元捕获了自身信息,关注到Arg1中的词“not (不)”和“good (好的)”,再结合论元间的交互信息,关注到Arg2中的词“ruined (毁坏的)”,那么基于词“not (不)”和“ruined (毁坏的)”的双重否定[17]可推理出此论元对包含的篇章关系为偶然关系。
例3 [Arg1]: Psyllium’s not a good crop
(译文:车前草没有好收成)
[Arg2]: You get a rain at the wrong time and the crop is ruined
(译文:错误时间下的雨毁坏了庄稼)
[篇章关系]: Contingency.Cause.Reason
为了捕获论元自身信息和论元间的交互信息,借以辅助隐式篇章关系识别,本文提出了一种基于自注意力和交互式注意力机制的图卷积神经网络(self-attention and inter-attention based graph convolutional network, SIG),用于构建隐式篇章关系分类模型。此模型基于自注意力机制(self-attention)及交互式注意力机制(inter-attention)来构建邻接矩阵,因此,这一模型可利用论元自身的语义特征,同时还能够捕获论元之间的交互信息,以编码出更好的论元表征,来提升隐式篇章关系识别性能。
本文采用PDTB 2.0[9]数据集进行实验和测试,结果证明本文所提模型SIG在隐式篇章关系分类上的表现优于基准模型,且其在多个关系上优于目前的隐式篇章关系识别模型。
1 相关工作
现有的隐式篇章关系识别研究主要分为两个方向:构建复杂的分类模型和挖掘大量的训练数据。其中,模型构建主要包括基于特征工程的机器学习模型以及基于论元表示的神经网络模型。
前人采用多样化的语言学特征来构建统计学习模型。在PDTB 数据集上,Pitler等[18]第一次尝试使用多种语言学特征对顶层四类隐式篇章关系进行识别,其实验性能超越随机分类方法;Lin等[19]基于上下文特征、词对特征、句法结构特征以及依存结构特征设计篇章关系识别模型;Rutherford和Xue[20]提取布朗聚类特征来缓解词对稀疏性问题。Braud和Denis[21]基于浅层词汇特征,使用现有的无监督词向量,训练最大熵模型来进行隐式篇章关系分类;Lei等[17]挖掘每类关系的语义特征,结合话题连续性和论元来源这两种衔接手段,训练朴素贝叶斯模型,在四路分类上达到47.15%的F1值,其性能超过大部分现有的神经网络模型。
现今的隐式篇章关系识别研究大多构建复杂的神经网络模型来提升分类性能。Ji和Eisenstein[22]基于论元以及实体片段的向量表示,使用两个递归神经网络(recursive neural network, RNN)进行隐式篇章关系识别。Zhang等[23]提出了仅包含一个隐藏层的浅层卷积神经网络,避免了过拟合问题;Chen等[12]基于双向长短时记忆网络(bidirectional long short-term memory network, Bi-LSTM)获取词向量表征,使用门控相关网络(gated relevance network)捕捉词对间的语义交互信息。Qin等[24]在卷积神经网络的基础上,增加了门控神经网络(gated neural network,GNN)来捕捉论元之间的交互信息(如词对);Lan等[16]采用基于多任务注意力机制的神经网络模型,使用未标注外部语料库BLLIP生成伪隐式篇章关系语料,来识别隐式篇章关系,将其作为辅助任务以提升PDTB隐式篇章关系识别性能。Bai和Zhao[13]构造了复杂的论元表征模型,融合不同粒度词向量、卷积、递归、残差和注意力机制抽取论元特征;Nguyen等[11]采用了Bai和Zhao[13]的模型,此外,基于知识迁移对关系表示及连接词表示进行映射,使其处于同一向量空间,从而辅助隐式篇章关系识别。
针对隐式篇章关系语料不足的问题,前人使用不同手段来扩充PDTB的隐式语料。朱等[25]通过论元向量,从其他数据资源里挖掘在语义和关系上与原始语料一致的实例;Wu等[26]发现双语语料中存在显隐式不匹配的情况,即英文语料中没有连接词,但其对应的中文语料中却有显式连接词,基于此,Wu等[26]从FBIS和HongKong Law语料库中提取了伪隐式篇章关系语料;Xu等[27]用显式篇章关系语料构造伪隐式样例,基于主动学习方法挑选含高信息量的样例,来扩充隐式篇章关系语料;Ruan等[28]采用问答语料库中的WHY式问答对,基于“问句陈述句转换”生成伪隐式论元对,以扩充隐式因果关系语料。
2 方法
本文提出的基于自注意力和交互式注意力的图卷积神经网络(self-attention and inter-attention based graph convolutional network, SIG)框架如图2所示。
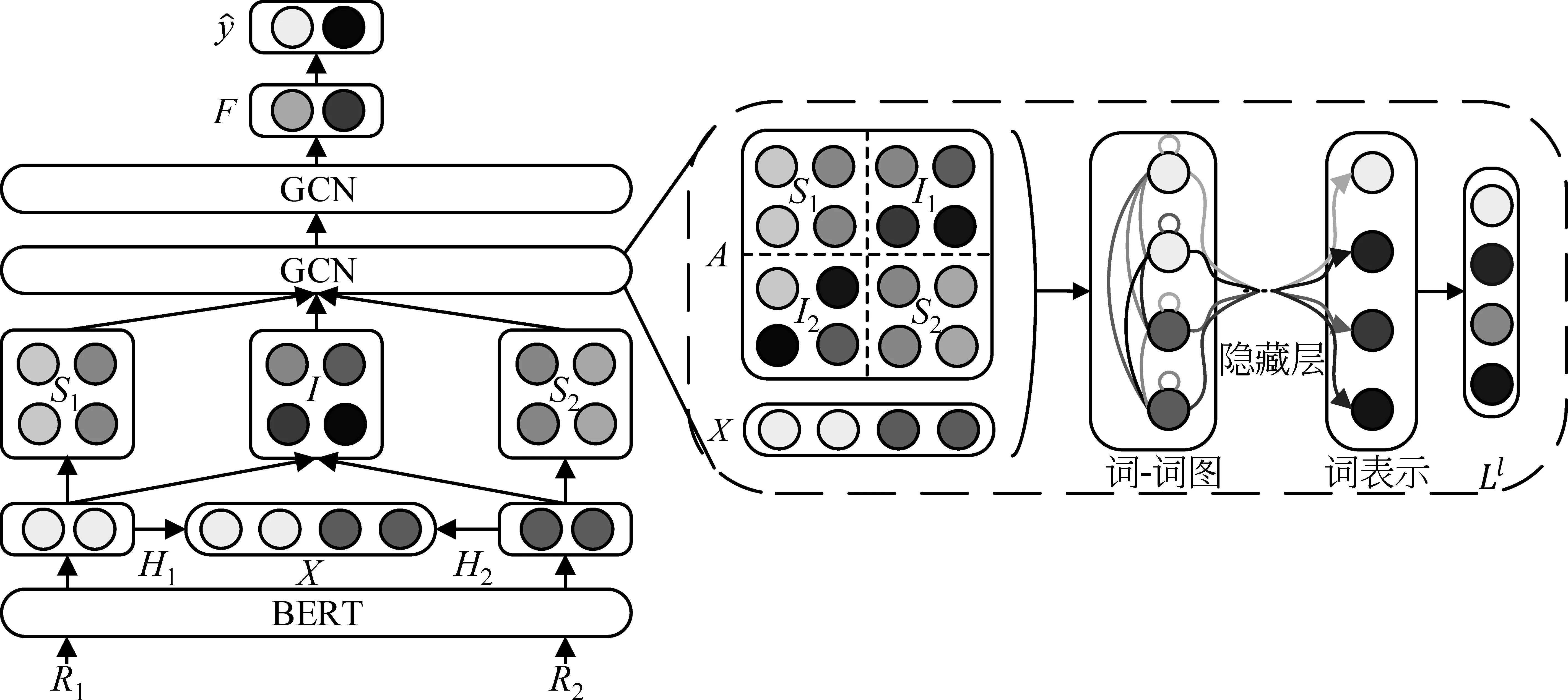
图2 SIG模型框架图
首先,通过微调的BERT语言模型[29]获取两个论元的论元表示;其次,通过拼接构造特征矩阵和邻接矩阵,从而得到全连接的“词-词”图,作为图卷积神经网络(graph convolutional network,GCN)的初始特征,通过双层GCN的隐藏层对词特征进行卷积和非线性变换操作,以得到最终的词表示;最后,将词表示送入全连接层进行降维,并使用softmax函数对其进行归一化,得到最终分类结果。
2.1 向量表示层
其中,CLS为专用分类符号,可使用其经过BERT编码的向量表示,作为整个输入序列的向量表示;SEP为专用符号,用于分隔输入序列中的两个论元。
2.2 图卷积神经网络
本节简单介绍图卷积神经网络,这一模型架构由Kipf和Welling[30]设计并在2016年提出,可对图结构数据直接进行计算。具体地,给定一个图G=(V,E),V是包含N个节点的顶点集,E是包括自循环边(即每个顶点都与自身相连)的边集。Kipf和Welling[30]使用X∈N×dk作为特征矩阵,其中,每个节点的特征维度为dk,矩阵中第i行向量xvi∈dk表示第i个节点vi的特征。其邻接矩阵A∈N×N中的元素aij表示图中第i个节点与第j个节点间是否存在连接。一般情况下,若两个节点之间存在连接,则aij值为1,否则为0[31]。在实际应用中,多层GCN表现往往优于单层,由于其可融合更广范围的节点信息。具体地,第l层对第l-1层的输出进行编码,计算如式(4)所示[31]。
其中,Wl∈dk×dk是可学习的参数矩阵,bl∈dk是偏置项,f为激活函数,其可对输出进行非线性变换。l表示GCN的层数,第0层的GCN输出为节点特征矩阵X,即L0=X。
图卷积神经网络通过共享参数Wl对特征矩阵进行卷积操作。由于共享局部参数,GCN在一定程度上能够防止过拟合。在对文本进行处理时,构建以词特征表示为节点的GCN,则可通过节点A感受野范围内的邻居节点来对节点A的语义特征向量进行更新,以得到包含邻居节点语义信息的特征表示。
2.3 基于自注意力和交互式注意力的图卷积层
本文使用多层GCN对论元表示矩阵进行更新。具体地,拼接两个编码后的论元表示作为节点特征矩阵,同时,拼接论元的注意力分数矩阵来构造邻接矩阵。
•节点特征矩阵
给定两个编码后的论元表示H1和H2,本文将其拼接作为节点特征矩阵X∈2L×dk,即X=[H1,H2]。在此基础上,可对两个论元表示同时进行图卷积操作,借以得到富含论元自身信息和交互信息的特征矩阵。
•邻接矩阵
考虑到篇章关系依赖于深层次的文本理解和论元间的信息交互,本文基于论元的自注意力分数矩阵和交互式注意力分数矩阵,来构造图卷积神经网络的邻接矩阵,以得到一个以论元表示为节点的全连接图。下面分别介绍本文所用的自注意力机制和交互式注意力机制的计算方法。
本文对论元表示H1和H2分别使用自注意力机制[32],来衡量其自身每个单词表示的重要程度,以得到论元的自注意力分数矩阵S∈L×L。以Arg1为例,具体计算如式(5)~式(7)所示。
其中,WQ1∈dk×dk和WK1∈dk×dk是可学习的参数矩阵,以为分母防止内积过大。同理,可计算得到Arg2的自注意力权重分布矩阵S2。
同时,在得到两个论元的向量表示H1和H2后,本文对其使用交互式注意力机制[12],来计算得到论元对的交互注意力矩阵I∈L×L。具体地,对I进行归一化可得到Arg1对Arg2中每个词的交互式注意力分数I1,同理,对IT进行归一化可得到Arg2对Arg1中每个词的交互式注意力分数I2,具体计算如式(8)~式(10)所示。
其中,可学习的参数矩阵WI∈dk×dk是Arg1和Arg2信息交互的媒介。
通过上述计算可得到自注意力分数矩阵S1和S2以及交互式注意力分数矩阵I1和I2。基于此,本文拼接S1、S2、I1和I2,以得到融合论元自身信息和交互信息的邻接矩阵A∈2L×2L,具体拼接方式如式(11)所示。
•图卷积操作
基于以上公式得到图卷积神经网络的节点特征矩阵X和邻接矩阵A,我们参照公式(4)来计算节点特征矩阵X的图卷积特征[31],此处采用的GCN层数为2,具体计算如式(12)所示。
2.4 全连接层

通过将F输入全连接层,计算Arg1和Arg2间具有关系r的概率,具体计算如式(14)所示。
其中,W∈n×dk,b∈n是可学习的参数,W可对最终特征表示F进行降维。是预测此论元对是否具有关系r的概率。
2.5 训练
本文为PDTB语料四大类关系中的每一类分别构造一个二分类器。在训练过程中,本文采用交叉熵损失函数作为目标函数,使用Adam[34]优化算法更新所有模型参数。对于给定论元对(Arg1, Arg2)及其关系标签yi,其损失函数计算如式(15)所示。
3 实验
3.1 实验数据
本文在宾州篇章树库[9](penn discourse treebank,PDTB)语料上用SIG模型进行隐式篇章关系识别实验。PDTB由Prasad等在2008年提出,其来源于《华尔街日报》(Wall Street Journal,WSJ)的2 304篇文章,共标注了40 600个篇章关系样本,其中,隐式篇章关系实例占16 224个[1]。为了与前人工作保持一致,本文以section 02-20为训练集,section 00-01为开发集,section 21-22为测试集。顶层四类语义关系Comparison(COM.)、Contingency(CON.)、Expansion(EXP.)和Temporal(TEM.)的数据分布如表1所示[1]。
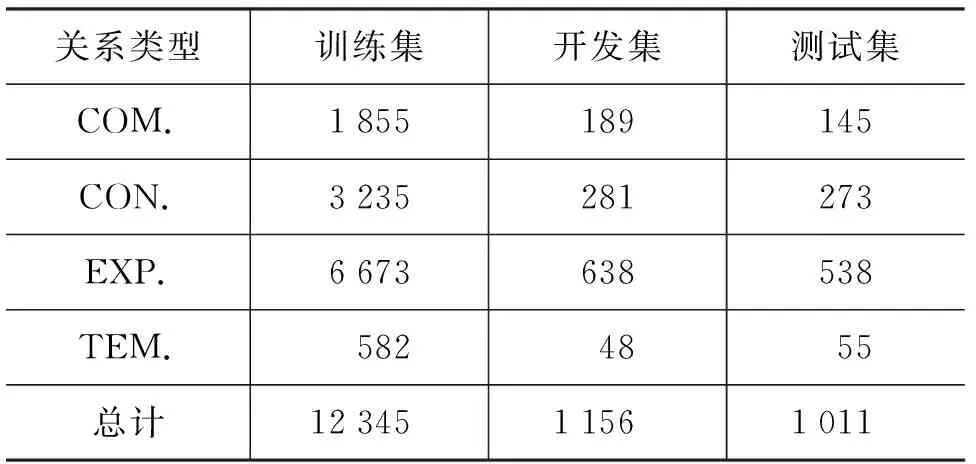
表1 PDTB四大类隐式篇章关系数据分布
由表1可知,在PDTB数据集中,除EXP.之外的其他三类篇章关系数据量都较少[18],类间不平衡问题使得研究者通常为各个关系类型单独训练二分类器[11-17,23-24]以进行评估。所以,本文参照前人工作,基于不同篇章关系的训练集分别训练二分类模型,一共得到4个二分类器,分别用于判断样例是否包含该篇章关系,并通过F1值对其性能进行评估。本文跟随前人工作[11-17,23,24,36]未对同一个样例的四次二分类结果进行整合,在进行二分类时仅讨论单类篇章关系的是或否问题。此外,由于PDTB数据集存在正负例样本不均衡的问题,本文对负例进行随机下采样[24],来构造正负例平衡的训练数据集。同时,为了更好地与前人工作进行比较,本文在PDTB数据集上进行了四路分类实验,基于训练集训练一个四分类器,并采用Macro-F1值和准确率(Accuracy)对其进行评估。
3.2 实验设置
为了证明使用GCN融合自注意力和交互式注意力机制有助于隐式篇章关系识别,本文设置了以下六个对比系统。
•BERT(Baseline):通过微调BERT模型得到Arg1和Arg2的隐层输出后,分别对其进行裁剪,以得到两个论元表征。然后通过逐词求和获取句级论元表征,通过拼接这两个句级表征得到最终特征,并输入至全连接层进行分类。
•Self:使用BERT获取Arg1及Arg2的论元表征后,分别计算其自注意力分数,并将自注意力权重作用到论元表征上;然后分别对更新后的论元表征进行逐词求和,以获取句级表征;最后拼接句级表征作为全连接层的输入。
•Inter:得到BERT输出的论元表征后,对其使用交互式注意力机制,来获取交互式注意力权重分布矩阵,并作用于论元表征;然后再通过对新论元表征逐词求和及拼接得到句对级论元表征,输入全连接层进行隐式篇章关系分类。
•Concatenate:通过拼接上述Self和Inter系统分别生成的句级表征得到句对级论元表征,输入到全连接层进行隐式篇章关系分类。
•Transformer:拼接通过BERT编码得到的Arg1和Arg2的论元表征,作为具有8头注意力机制的双层Transformer[32]的输入,再对Transformer编码后的词特征进行逐词求和,借以得到论元对的句级表征,将其输入到全连接层进行隐式篇章关系分类。
•SIG:使用BERT得到Arg1和Arg2的论元表征后,分别计算两者的自注意力权重分布矩阵和交互式注意力权重分布矩阵;然后拼接两个论元表征得到特征矩阵,再拼接注意力权重分布矩阵得到邻接矩阵,来构建双层GCN;对最后一层GCN的输出进行逐词求和,以得到两个论元的句级表征,并将其输入全连接层进行隐式篇章关系分类。
3.3 参数设置
本文使用微调的BERT[29]隐层输出作为论元表示,其中,我们设置隐层向量维度dk为768,论元最大长度L为80。基于论元表示构造的特征矩阵,本文拼接论元自注意力和交互式注意力权重分布矩阵得到邻接矩阵,构造2层(l=2)GCN神经网络,并使用tanh函数作为模型的激活函数。构建Transformer模型时,我们采用了Vaswani等[32]工作中Transformer的编码器作为本文的一层Transformer。本文采用了双层Transformer对编码后论元表示进行变换,且设置其前馈神经网络的隐层维度为768,并采用GeLU[33]作为激活函数。在训练过程中,使用交叉熵作为损失函数,采用基于Adam[34]的批梯度下降法优化模型参数,其中,批大小为32,学习率为5e-5。本文在最后一层GCN后进行了dropout计算,其随机丢弃的概率为0.1。
3.4 实验结果
本文采用六种不同结构的神经网络模型,来分别对PDTB四大类隐式篇章关系进行分类,具体分类性能如表2所示。其中,本文所提模型SIG在多个关系上的表现优于其他五个对比模型。其原因主要在于SIG融合了两种注意力机制的优点,在关注两个论元自身信息的同时,还能够关注到两者间的交互信息,并通过这样的信息来更新论元表示。因此,SIG能够生成更符合隐式篇章关系分类任务特性的论元表示。

表2 不同模型在四大类篇章关系上的分类结果 (单位: %)
然而,模型Transformer采用了8头注意力机制来捕捉多方面的论元自身信息和论元间的交互信息。但是, Transformer在模拟论元之间的信息交互时,仅采用论元点积矩阵作为注意力分数矩阵,而SIG可使用的注意力机制则较为灵活,本文采用了双线性模型来模拟两个论元之间的线性交互。此外,Transformer使用8头注意力机制,而SIG仅采用单头自注意力机制;同时,Transformer的注意力分数矩阵在不同层数值不一致,而SIG中不同层的GCN共享同一邻接矩阵,其元素值的大小表示不同词节点之间连接的强弱;且每层Transformer在使用注意力机制更新论元特征后,还需使用包含两个全连接层的前馈神经网络对其进行变换,并采用了残差机制。相较之下,SIG模型结构更为简单,在一定程度上防止了过拟合。因此,Transformer在数据量较多的Expansion关系上表现优于SIG,而在其他关系上表现稍弱。
此外,模型Concatenate在几乎所有篇章关系上,性能劣于Self和Inter,我们认为主要由以下两方面原因造成:其一,仅拼接的方式过于简单,难以模拟两个论元之间的复杂关系和两种注意力机制间的平衡;其二,此模型存在一定的过拟合问题。相对地,本文所提模型SIG应用GCN来权衡两种注意力机制。其中,GCN模型固有的权重共享特性在一定程度上能够防止过拟合情况的发生,因此SIG几乎能够在四类篇章关系上分类性能超越其他模型。
为了证明本文所提模型SIG的有效性,我们与现有先进模型进行了对比(见表3)。其中,Bai和Zhao[13]使用字符级(Character)、子词级(Subword)和基于ELMo[35]的词级(Word)表示构建多粒度论元表示,结合卷积操作、残差机制、交互式注意力机制和多任务学习思想构建复杂的深度神经网络。在Bai和Zhao[13]的基础上,Nguyen等[11]基于知识迁移思想,映射关系向量与连接词向量到同一向量空间。此外,Lan等[16]借助BLLIP等外部数据训练多任务模型。在同一篇章内,从上而下的篇章关系间存在一定关系,Dai和Huang[36]深入挖掘这一特点,利用集成学习的方法构造隐式篇章关系分类器。

表3 SIG与现有先进模型对比结果 (单位: %)
相较于前人工作,本文所提模型SIG较为简单,仅使用了标准PDTB数据集进行训练,而其能在多个关系上分类性能超越目前最优方法。其原因主要在于:①BERT预训练语言模型中已含有大量先验知识,其对需要常识知识的隐式篇章关系识别具有一定帮助; ②前人工作通常使用交互式注意力机制抽取论元间的交互信息,但忽略了论元自身信息的重要性,而SIG融合了自身信息以及交互信息。
表4展示了本文所用的PDTB四大类篇章关系上的词汇分布。其中,每类关系中都含有大量未登录词(Out-Of-Vocabulary,OOV)。研究者通常将这些未登录词用特殊符号“UNK”表示,并统一初始化得到一致的词向量,这虽能打破未登录词词向量查找的困境,但是其削减了一定的信息量,且对隐式篇章关系识别带来一定影响。

表4 四大类篇章关系上的词汇分布
如例4中,未登录词“steamed (推进)”在训练集中未出现过,在没有词“steamed (推进)”的情况下,仅靠“paused (暂停)”和“reaching its high (到达高点)”难以推导出因果关系。然而,BERT能够使用词的上下文信息为未登录词进行词向量初始化,且“steamed forward (向前推进)”是“reaching its high (到达高点)”的原因,因此,可推导出此论元对包含的篇章关系为偶然关系。
例4 [Arg1]: Instead, the rally only paused for about 25 minutes and thensteamedforward as institutions resumed buying
(译文:反而,股票价格的涨势仅停了25分钟左右,然后股价的涨势便随着机构恢复购买股票而加速前进)
[Arg2]: The market closed minutes after reaching its high for the day of
(译文:股市在股票交易量达到当日高点的几分钟后就关闭了)
[篇章关系]: Contingency.Cause.Result
为了证明模型SIG的有效性,本文使用模型Self、Inter和SIG对例3进行注意力权重分布计算,并对注意力权重数值逐词求平均来绘制灰度色块,分别获取三个模型通过例3计算得到的注意力分布灰度图(图3)。由图3可知,模型Self和SIG都关注到了Arg1中的单词“not (不)”和“good (好的)”。然而,只有模型SIG对Arg2中的单词“ruined (毁坏的)”赋予了较高权重。因此,模型SIG能够通过单词“not (不)”和“ruined (毁坏的)”的双重否定[17]来推理得到这两个论元之间包含的隐式篇章关系为偶然关系。

图3 例3由不同系统得到的注意力分布灰度图
本文对使用不同层数GCN构造的模型进行了实验,其性能如表5所示。

表5 基于不同层数GCN的模型分类性能 (单位: %)
其中,在GCN层数为2时(即GCN2),二分类器在F1值上达到最大值,而在GCN层数为4时,四路分类的Macro-F1值和准确率分别是53.86%和59.48%。这主要是由于二分类模型训练集样本量低于四分类模型,因此,当GCN层数较多时,二分类器易于出现过拟合现象。
4 结论
本文针对隐式篇章关系识别展开研究,提出了基于自注意力和交互式注意力机制的图卷积神经网络模型,用以对隐式篇章关系进行识别。实验结果表明,本文所提模型SIG表现优于基准模型BERT,且其在多类关系上性能优于现有先进方法。
从实验结果可知,隐式篇章关系识别任务仍具有极大挑战性,除EXP.外的其他三大类关系的分类性能皆较低,远达不到实际应用需求。下一步工作中,我们将从两个方面展开研究:①针对数据不平衡问题,从外部挖掘高质量的隐式篇章关系语料; ②构建更复杂且符合隐式篇章关系识别任务特性的分类模型。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
渭南师范学院学报(2017年22期)2017-11-22
传媒评论(2017年3期)2017-06-13
海外华文教育(2016年3期)2017-01-20
第二课堂(课外活动版)(2016年2期)2016-10-21
玉溪师范学院学报(2014年6期)2014-03-28
电视技术(2014年19期)2014-03-11
