
基于文章和近答案句信息的问题生成模型
2021-10-12 04:53:02刘瑞芳刘欣瑜陈泓宇
中文信息学报 2021年8期
石 航,刘瑞芳,刘欣瑜,陈泓宇
(北京邮电大学 人工智能学院,北京 100876)
0 引言
问题生成(Question Generation, QG)是指对给定的一段文本,生成一个合理的问题。问题生成的一个潜在应用在教育领域[1]。也可以在问答系统和聊天机器人,例如,Siri、Alexa、Cortana、小爱、小度等中帮助它们启动对话和继续对话[2]。在问答系统(Question Answering, QA)领域,Zhu等[3]利用问题生成系统自动生成大量的问题答案对来提升机器阅读理解系统的F1值。Sultan等[4]阐述问题生成的多样性对QA的重要性。
目前,学者们对问题生成任务已经展开了大量的研究,主要分为基于规则的问题生成、基于深度神经网络的问题生成以及基于预训练语义模型的问题生成。
基于规则的问题生成,例如,Heilman等[5]和Mannem等[6]使用严格的启发式规则或基于模板的方法。但是,这些方法严重依赖于人工生成规则,不易被其他领域采用,有时生成的句子也不如人类表达那样流畅。近年来,一种基于序列到序列框架的端到端的神经网络在问题生成任务中被普遍采用。其中编码器将带有语义特征(例如,命名实体识别(Named Entity Recognition, NER)标签)的文章或句子进行编码,解码器利用编码器生成的语义表示生成问题。Du等[7]使用一个或两个包含答案的句子作为问题生成模型的输入,而Zhao等[8]使用整篇文章作为编码器的输入。谭红叶等[9]使用答案及其上下文信息进行问题生成。不管输入是一两个句子还是整篇文章,都只能捕获到一个层次和答案相关的信息,从而导致生成非理想的问题。Jia等[10]将释义知识整合到问题生成中生成问题。Kriangchaivech等[11]基于Transform的结构在问题生成任务上取得了很大的进展。Dong等[12]提出了一种新的预训练模型UNILM,通过训练序列到序列的语言模型(Language Model, LM)实现问题生成。但是这种方法需要大量的数据,而且模型参数太多,需要大量的算力进行训练。
本文主要解决针对给定文本中的指定内容提问的问题生成任务,即生成的问题是可以根据原文用目标答案来回答的问题。为了从句子级别和全文信息中捕获与答案相关的语义信息,我们提出一种新的多输入序列到序列框架,框架的编码器同时输入全文信息和答案上下文信息。因为文章常常能提供比句子更丰富的内容,Zhao等[8]发现在SQuAD数据集[13]中有20%的问题需要依赖文章级别的长文本信息,使用全文信息可以提升问题生成的BLEU_4值。Liu等[14]比较训练集每个训练样本中复制的单词与答案之间的句法依赖距离和顺序单词距离的分布,发现答案词与被复制词之间的平均距离分布为10.23。整篇文章能够帮助提高生成问题的质量,但是一般与答案相关的信息主要来自它的上下文,我们把包含答案及其前后十个词的上下文信息称为近答案句子。本文结合这两个层次的信息来提升生成问题的质量。
在问答系统中,给定一篇文章和一个问题,我们可以在文中找到一个独一无二的答案。但是对于问题生成任务,在一篇文中指定一部分内容作为答案,我们可以有多种方式来对其进行提问,即问题生成是一对多的任务。因此如何评估一个问题是不是好问题,我们不仅需要将生成的问题和人工生成的源问题进行对比,也需要判断这个问题是否是针对文中答案内容进行提问的。本文通过问题的可回答率来评估问题和答案的相关程度。本文采用BERT-base-uncased[15]预训练模型训练一个问答系统,将测试集中的源问题替换成系统生成的问题,然后根据问答系统的回答情况评判问题的可回答率。以下是本文的主要贡献:
(1) 本文提出了近答案句子的概念。基线系统通常是输入包含答案的整个句子,而数据中与要提问的答案相关的信息不一定和它在同一个句子,而是与其位置相近的词,这些词也可能和答案是跨句子的。所以近答案句子可以提供更多与答案相关的信息,同时减少了噪声。
(2) 本文提出了一种新的端到端的模型框架。传统端到端框架的编码端输入是一个序列,输出到解码端解码生成句子。本文输入两个序列,通过多层次的注意力机制编码后获得更丰富的语义表示,然后输出到解码端解码生成问题。
(3) 问题生成是一对多的任务,传统的评估方法只能将生成的问题和参考问题进行对比评判,对于问题类型出错的惩罚不大,也不能包容更多的可能性。本文把一个问答系统作为判别器,根据问答系统的回答情况评估生成问题的可回答率,以此来评价问题的质量。
1 相关工作
目前,问题生成技术的研究方法一般分为三种,第一种是基于规则的方法,即将陈述句转化进行问题生成;第二种是基于端到端的编码—解码结构的神经网络问题生成方法;第三种是借助预训练模型的强语义表示进行问题生成任务。
为了在创建问答系统和对话系统的大规模数据集中减少人工标注的工作量,自动生成问题是非常重要的。大多数早期的自动问题生成都是基于规则的,例如,将人名替换成“谁”,根据语法调整语句可以产生大量问题。Heilman等[4]依据制定的规则将简化后的陈述句转化成问题,然后通过逻辑斯蒂回归对生成的问题进行重排序。然而这些方法非常依赖人为设置的规则,所以不能很好地拓展到其他领域,迁移性较差,有时生成的句子不能像人类的语言那样流畅。
受益于SQuAD数据集的三元组(文章、问题、答案)和端到端的神经网络模型,摒弃了大量规则制定的工作,并生成了更高质量、更流畅的问题句子。Du等[7]第一次尝试了基于注意力机制的序列到序列模型,利用神经网络的方法使得问题的得分在自动评估和人工评价中都超过了基于规则的方法。Zhou等[16]在模型中充分利用答案位置特征和词汇实体特征,并引入复制机制解决生成词表外的词,进一步提升了神经网络在问题生成任务中的BLEU_4和ROUGE_L值。Zhao等[8]提出门控注意力机制,增强编码端的语义表示能力,结合最大输出指针复制机制,改进了神经网络对长文本作为输入表现不佳的现象。Kim等[17]提出分离答案的序列到序列模型,帮助模型捕获答案相关的信息。
随着BERT[15]预训练模型在自然语言处理中的广泛应用,最近Dong等[12]提出了统一语言模型UNILM。借助大量的训练数据和复杂的网络结构,设计了一种序列到序列的语言模型训练方法,让模型在端到端的任务上获得了很大的进步,大大提升了问题生成的质量。但对实验条件要求比较高,很难迁移到一般机器中运行。
神经网络模型有着比基于规则方法更好的效果和迁移性,比预训练模型更具有可实现性和可拓展性。因此,本文采用编码—解码的框架研究问题生成任务。并在预训练模型UNILM上做了对比实验,证明本文提出的近答案句子信息对提高问题生成的质量是有效的。
2 问题生成模型和方法
2.1 模型架构
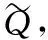

(1)
本文模型的整体架构如图1所示,模型左边是编码端,主要包括三层,右边是解码端。
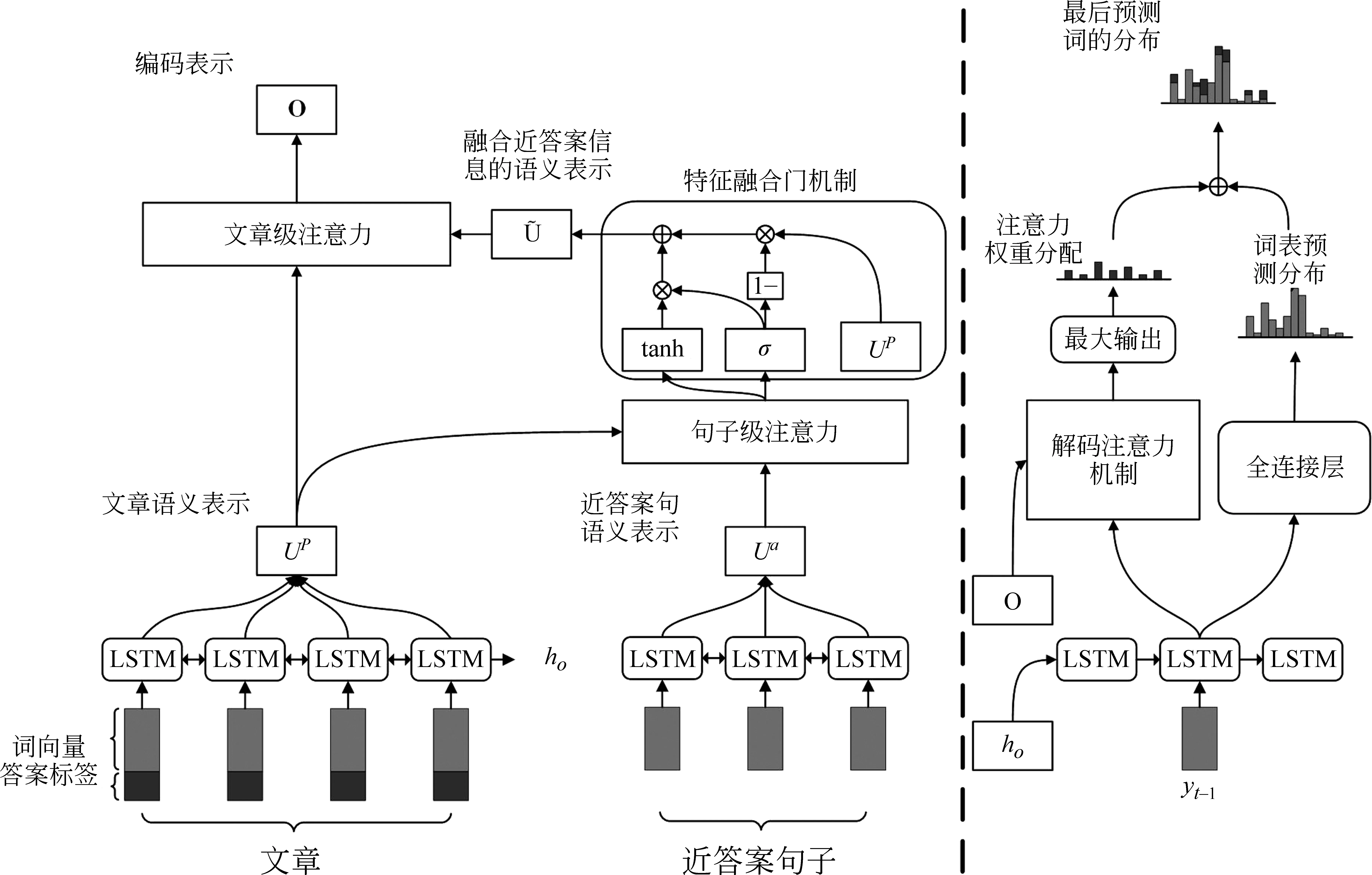
图1 模型总体框架
2.2 多序列输入编码层
其中,ut表示Bi-LSTM第t步的隐藏层,et表示预训练的词向量编码,mt代表答案的位置信息编码。通过编码层后得到文章的语义表示UP和近答案句子的语义表示Ua。
2.3 句子级别的注意力机制层
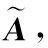


2.4 文章级别的注意力机制层
这一层在得到了融合近答案语义信息的文章表示后。受益于Wang[18]提出的自对准注意力在长文本中的优势,本文采用了自注意力融合机制对文章表示做进一步的信息融合,最终得到两层语义信息的编码表示O,如式(9)~式(11)所示。
2.5 解码层
在解码阶段,首先将编码器的最后一个隐藏状态作为解码器的初始化隐藏状态。第t步解码根据t-1步的解码单词和隐藏状态作为输入,通过LSTM获得解码器隐藏状态st。将st做线性变化后利用softmax预测词表里每个单词的概率Pvocab如式(12)~式(14)所示。

考虑到输入的是整篇文章,某些词在文章中出现的次数比较多,最后的注意力权值相加后会导致一些不重要的词分得的权重比较高,从而影响生成问题的质量。本文采用了最大输出的注意力复制机制,即在对注意力权值的计算中对同一个词只选最大权值作为最后的权重分配,如式(18)所示。
(18)
将式(14)中的sgt换成sct获得复制分数Pcopy(w),最后得分由生成得分和复制得分相加得到P(w),如式(19)所示。
P(w)=Pvocab(w)+Pcopy(w)
(19)
3 实验结果与分析
3.1 数据集
本文提出的多层次注意力端到端的神经网络模型在SQuAD数据集上进行了实验,该数据集利用众包的方式生成,其中每个问题的答案来自对应文章的一段文本,共有超过100k个问题和536篇维基百科的文章。实验依据整篇文章和包含答案前后10个词的句子来进行问题生成,输入包括整篇文章和近答案句子以及答案的位置信息。输出是人工提出的问题。我们数据集的分割方式参照Zhao[8]来划分训练集、验证集和测试集。
3.2 实验设置
我们从训练集中收集词表并保存前45 000频次的词,其他的用特殊字符@UNK代替。我们使用的GloVe[19]预训练词向量来将每个单词初始化为300维的向量。在编码和解码中,我们都使用了两层双向LSTM,隐藏单元的大小为600,两层中间设置丢弃率为0.3。对答案的位置信息编码维度是3。对于模型的优化算法,我们采用随机梯度下降(Stochastic Gradient Descent, SGD)进行更新参数,初始学习率是为0.1,从第八轮训练开始每两轮学习率减半,批量(Batch Size)的大小为32。在解码过程中,Beam search设置为10。我们使用谷歌的BERT-base-uncased[15]训练QA模型。
3.3 基线系统
本文采用了4个基线系统进行比较:
(1)Seq2Seq+Attention[7]: 该模型使用基于全局注意力机制的RNN编码器—解码器框架来生成问题。
(2)NQG++[16]: 该模型第一次引入了注意力机制和复制机制在序列到序列框架中,并在编码端增加了丰富的特征信息。
(3)s2s-a-at-mcp-gsa[8]: 该模型在编码端引入门注意力机制,在解码端采用了最大输出指针网络,并且能处理长文本作为输入的问题生成。
(4)ASs2s[17]: 该模型提出答案分开的序列到序列模型,并指出原文中哪些潜在词在生成问题时可以用来替代目标答案。
3.4 评价指标
实验结果采用的评价标准有BLEU值[20]、METEOR值[21]、ROUGE_L[22]。BLEU是自动翻译常用的评估方法,通过统计生成的句子和标准句子之间匹配片段个数来评价生成句子的充分性和流畅性,METEOR则是依据评价指标中的召回率的意义提出的评估方法,计算对应生成句子和标准句子之间的准确率和召回率的调和平均,ROUGE_L通过使用基于最长公共子序列的统计量来衡量生成句子和标准句子中出现的数量。此外,我们训练了一个QA模型,通过QA模型评估生成问题的可回答率来评估问题的质量。
3.5 实验结果和分析
通过实验对比,我们的模型对比基线系统的问题生成各项指标都有明显的提升。如表1所示,表中w/o表示在基线的情况下减少一层结构,par.代表文章级别的注意力机制,tag.代表答案的位置编码信息。从实验结果来看,Seq2Seq + Attention模型在问题生成任务中有一个不错的表现。NQG++模型在编码端增加一些答案的特征信息,增加复制机制去处理小概率出现的词采用预训练的词向量后,生成问题的BLEU_4值提升了1.01%。而s2s-a-at-mcp-gsa 模型提出的门控注意力机制能够很好地对长文本的输入进行一个语义编码表示,解决了长文本作为输入在问题生成任务中的挑战,不管是以长文本作为输入还是句子作为输入,都取得了历史最好的效果。ASs2s模型相比于NQG++,可以看出分离出答案的有用信息对问题生成的各项指标也有明显的提升。

表1 问题生成结果 (单位: %)
本文和s2s-a-at-mcp-gsa一样,都以长文本作为输入生成问题。但是因为我们多层次地结合了全文信息和近答案句子信息,最后问题生成的各项指标达到了最好的效果。为了进一步印证多层次的语义编码,本文在编码端器端减少了一层文章自注意力机制,结果的指标有小幅下降,但是仍然比s2s-a-at-mcp-gsa 要好,说明全文的层次信息有助于答案的理解和问题生成,全文的自注意力机制可以捕获到全文中对答案有用的信息,而减少了答案的位置信息时性能下降明显,因为系统不知道要提问的对象具体是什么,但是由于结合了近答案句子信息,也能取得比Seq2Seq + Attention更好的效果。通过两个消融实验证明多层次的语义信息可以辅助提升问题生成任务的性能。
问题生成的任务是: 根据给定的文章,将文章中的一部分作为答案来进行提问。这是一对多的问题,因为针对同一部分内容提问,我们可以从不同的角度来提出风格不同的问题。而传统的评估方法都是将系统生成的问题和数据集中人为生成的参考问题来进行比较,进而评估问题生成的质量。这种方法对一个系统生成的可以用给定的答案来回答,但对于与参考问题不一样的问题是不公平的。因此,本文评估生成问题可回答率时,先训练一个问答系统,用训练好的问答系统来判断生成问题的可回答率。
BERT-base-uncased在不同的训练集和测试集上的表现如表2所示。用原始数据集时BERT-base-uncased的F1得分是88.61,EM得分是81.33。本文将我们的系统和Zhao[8]的系统进行了对比,首先将验证集中的所有问题用两个系统生成的问题替换,然后让训练好的QA系统来回答替换后的问题。最后我们系统的F1得分是73.38,可回答率是82.81%(73.38/88.61),结果都比Zhao[8]的系统高,表明我们系统生成的问题不仅在流畅度和精确率上比基线系统更好,而且生成的问题和指定的答案之间的匹配度也是更高的,生成的问题和答案相关度更高。

表2 BERT-base-uncased的结果
换而言之,我们系统生成的问题可以作为大规模生成数据集提供给QA模型训练。为了验证这一点,本文还将训练集的问题换成系统生成的问题。结果BERT-base-uncased在SQuAD测试集中的F1得分是79.24,这已经超过了经典QA神经网络模型BiDAF[23]的F1得分77.32。
本文从实验结果中分析了本文系统和基线系统的差别,并且也参照了人工提问的源问题。具体例子如表3所示,其中,下划线部分是要提问的答案,括号部分是近答案句子信息。通过对比发现,我们多层次注意力机制的问题生成模型整体结果相比于基线系统要更接近人类生成的问题。例1中,由于和答案相关的信息在近答案句中,本文生成的问题很接近参考问题。而基线系统由于长文本的输入带来的噪声导致生成的问题把注意力分散到更远的信息,复制生成了更多和答案不相关的词。例2中,我们系统能够根据近答案的语义信息捕获到时态上的细节信息,而基线系统不能捕获这些细节信息。例3中,我们生成的问题中有1 758的信息,这一信息近答案句中没有,是由长文本提供的,我们的系统和基线系统也都能捕获到全文中距离答案相对较远的信息以辅助提升生成问题的质量。但是我们要提问的词是一个数量,基线系统生成的问题则是一个“什么”类型的问题,这个问题明显不是一个好的问题,但是这种情况在之前的BLEU或者ROUGE_L的评估方法上是不能体现出来的,因此评估一个问题的可回答率也是评估问题质量一个重要指标。

表3 分别由本文模型和基线模型生成问题样本
最后,为了验证本文提出的近答案句的可靠性,我们在统一语言模型UNILM上进行了对比实验。我们利用Dong等[12]提供的unilm-v1中问题生成任务的unilmv1-base-cased参数进行微调实验。我们在输入中近答案句子的前后增加两个分隔符,如图2所示,实验结果如表4所示。

图2 近答案句输入图

表4 UNILM的结果
实验结果显示,增加了近答案句子信息特征后,问题生成的ROUGE_L值相比UNILM提升了0.121%,说明我们提出的近答案句子对问题生成任务的性能提升有效果。我们进一步对比了本文基于神经网络模型和UNILM的问题生成时间。实验结果如表5所示。

表5 生成问题时间结果
我们对比生成5 285个问题,Batch Size为1,不同Beam search大小的结果。实验结果显示,Beam search为1时,本文模型的生成问题的时间是UNILM的9.03%。当Beam search为10时,本文模型的生成问题的时间是UNILM的25.46%。可见,本文模型要比UNILM轻量很多,能够更好地迁移到更小设备或者百毫秒级响应的需求中。
4 总结与展望
本文提出了一种多输入多层次注意力机制的序列到序列框架的神经网络模型,用于解决在问题生成任务中神经网络系统无法有效结合文章和答案句信息的问题。本文通过句子级别的注意力机制和文章级别的注意力机制融合文章信息和近答案句子信息,获得语义信息更丰富且更注意答案的编码表示,提升了模型对答案的语义理解。本文还提出一种新的评估方法,根据生成问题的可回答率评判问题与答案的相关程度。
虽然本文模型在BLEU等指标上取得了较好结果,但问题生成是一个一对多的任务,在问题多样性上还没有很好的评价方法,未来我们会对此做进一步的研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
传媒评论(2017年3期)2017-06-13 09:18:10
中华手工(2017年2期)2017-06-06 23:00:31
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中外会展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
