
结合用户长短期兴趣的深度强化学习推荐方法
2021-10-12 04:52:56阎世宏马为之刘奕群马少平
中文信息学报 2021年8期
阎世宏,马为之,张 敏,刘奕群,马少平
(清华大学 计算机系 北京信息科学与技术国家研究中心,北京 100084)
0 引言
随着信息技术的快速发展,互联网中的信息总量激增与用户有限的认知能力间的矛盾构成了严重的信息过载问题。推荐系统作为一种个性化服务,能够向用户主动推荐其感兴趣的信息、商品等(以下统称“物品”)来缓解信息过载问题。近年来,推荐系统已被广泛应用于电子商务、电影音乐、新闻推荐、社交网络等多个场景。
在推荐系统研究中,如何准确刻画用户兴趣是最重要的一步。在真实场景下,用户兴趣是非常复杂且多变的。一方面,用户会有长期的偏好与兴趣,在相当长的一段时间内保持稳定。另一方面,用户在一个时间段内可能对部分内容更感兴趣,随着时间推移产生实时的需求与兴趣点。因此,从长期与短期两个角度学习用户的潜在兴趣对提高推荐系统的性能非常重要。
深度强化学习(DRL)[1-2]自提出以来在多种具有挑战性的连续决策场景中展现出巨大优势。在推荐场景中,深度强化学习能够实时学习用户的潜在兴趣,并且能够交互式地更新用户的潜在兴趣表示与推荐策略。除此之外,深度强化学习还有很强的长期连续决策能力,能够考虑未来推荐过程中累计的效益。近年来,强化学习的工作在推荐领域中得到应用并被重视,获得了良好的效果。
然而,我们注意到在现有的基于深度强化学习推荐方法中,绝大部分方法过于强调短期内的用户兴趣,对长期稳定的用户兴趣学习不足。例如,DRN方法[3]使用用户在不同时间段内点击新闻的特征统计信息来表示用户状态,进而学习用户的短期兴趣;Deep Page方法[4]与DEERS方法[5]通过门控循环单元(GRU)从用户最近的交互历史序列中学习用户的短期兴趣;在FeedRec方法[6]利用分层的长短时记忆网络(LSTM)从用户最近的交互记录序列以及停留时间等附加信息中学习用户的短期兴趣。尽管这些方法能够很好地学习用户的短期兴趣,但由于缺乏对用户长期兴趣的学习,可能会陷入用户实时的兴趣点中,导致严重的有偏推荐,使得给用户推荐的内容最终集中于很小的兴趣点,难以满足用户的真实信息需求。
针对这一问题,本文研究了如何在深度强化学习中同时学习用户的长期兴趣与短期兴趣,并提出了一个可以应用于深度Q网络(Deep Q-Network)及其后续变种的Q-网络框架(Long andShort-term Preference Learning Framework based on DeepReinforcementLearning, LSRL)。该框架使用协同过滤技术[7]学习用户的长期兴趣,并利用门控循环单元(GRU)[8]从用户近期的正反馈和负反馈交互行为中得到用户的短期兴趣,再结合两个模块学习到的信息对用户的反馈做出预测,最后生成面向用户的推荐结果。
本文的主要贡献是: ①提出在深度强化学习的推荐方法中应当引入用户长期兴趣,从而更精准地建模用户兴趣; ② 提出了基于深度强化学习的LSRL框架,实现了结合用户的长期兴趣与短期兴趣的模型; ③在真实数据集的实验表明,LSRL框架在归一化折损累计增益(NDCG)与命中率(Hit Ratio)上比其他基线模型有显著提升。
本文的组织结构如下:第1节形式化地定义了推荐任务并介绍LSRL框架的结构与训练方法;第2节给出实验设置,分析实验结果并探究不同因素对模型性能的影响;第3节介绍本文相关工作;第4节总结本文工作并展望未来的研究思路。
1 LSRL框架
在本节中,首先定义本文研究的推荐任务,然后介绍LSRL框架的结构与训练方法, 最后对比LSRL框架与其他基于深度强化学习方法的异同。
1.1 任务定义
本文将推荐过程视为推荐系统选择待推荐物品与用户给出对推荐物品的反馈的交互序列,并建模该交互序列为马尔可夫决策过程(MDP),最大化推荐过程中的长期累积奖励。建模后的马尔可夫决策过程(MDP)包含形如(S,A,R,P,γ)的五元组,五元组中每个元素的定义如下:
(1)状态空间S: 时刻t下状态st∈S的定义是用户在时刻t之前最后N个正反馈交互记录与最后N个负反馈交互记录分别构成的序列,如果不足N个则使用虚拟物品补全。其中,N是模型超参数。
(2)动作空间A: 时刻t下状态at∈A的定义是推荐系统在时刻t时推荐给用户的项目。
(3)奖励空间R: 时刻t下状态rt∈R的定义是用户在时刻t的反馈对应的即时奖励值。本文中奖励值取值范围为{0,1}:如果用户给出正反馈,则rt=1;如果用户给出负反馈,则rt=0。
(4)状态转移P: 时刻t下状态转移被定义为形如(st,at,rt,st+1)的四元组。
(5)衰减因子γ: 衰减因子γ的定义是每间隔一个时间步长,即时奖励值衰减到原值的γ倍。

1.2 框架结构
LSRL框架基于深度Q网络(DQN)[1]算法,本节首先简要介绍DQN算法并指出LSRL相对于DQN的主要改进,然后详细描述LSRL框架的结构。
1.2.1 深度Q网络(DQN)
深度Q网络是一种基于价值优化的深度强化学习算法。该算法通过学习状态—动作值函数Q(s,a)(以下简称“值函数”)来估计推荐系统在状态s下向用户推荐项目a的长期累积奖励。最优值函数Q*(s,a)是最佳推荐策略π*对应的值函数。
根据强化学习的假设,最优值函数Q*(s,a)应该遵循Bellman方程,如式(1)所示。
深度Q网络的损失函数L(θ)定义为:
其中,在计算Qtarget时,需要使用上一训练周期的参数θ—来降低训练的不稳定性,通常使用两个结构相同的Q-网络并定期同步参数来实现。
深度Q网络的训练过程如图1所示,带底纹的两个框代表两个结构相同的Q-网络,LSRL框架重新设计了该部分来同时学习用户的长期兴趣与短期兴趣表示。
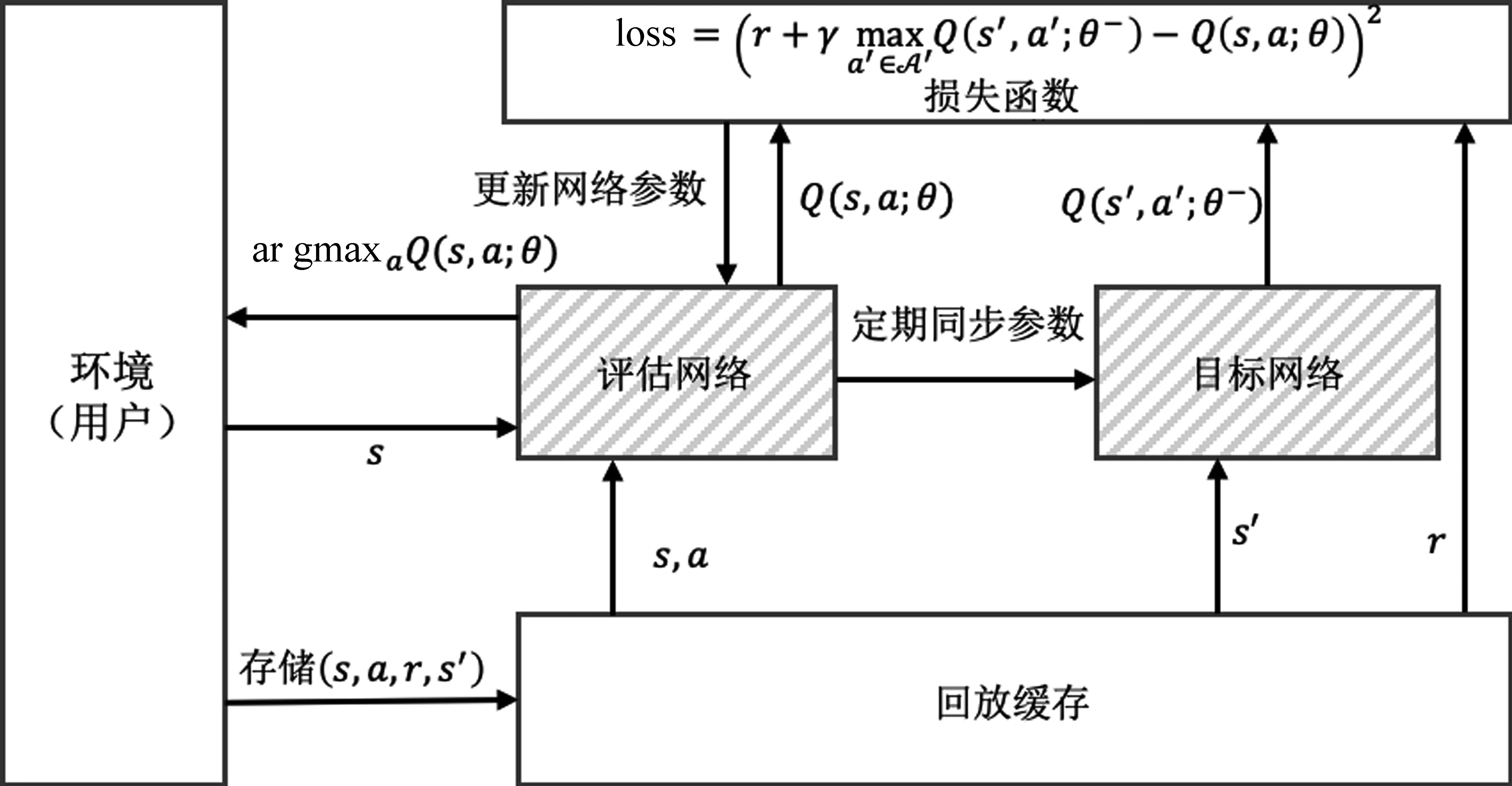
图1 深度Q网络的训练过程
1.2.2 LSRL框架
LSRL框架分为长期兴趣模块、短期兴趣模块与预测模块。Zhao等人的工作[5]指出负反馈交互行为能够提高深度强化学习推荐方法的推荐准确度,因此在短期兴趣模块我们令其同时学习正反馈交互序列与负反馈交互序列中隐含的用户短期兴趣。LSRL框架结构如图2所示。
1.2.3 长期兴趣模块
图2中左侧部分为长期兴趣模块。用户的长期兴趣是使用基于协同过滤的方法学习的,用户的向量表示在学习过程中利用所有的交互历史信息,能够代表用户长期的兴趣偏好特征。最底层为嵌入层,用户u与待推荐物品i分别通过用户嵌入层与物品嵌入层,得到用户向量表示pu与物品向量表示qi。与传统的协同过滤方法[9-10]做内积运算不同,为了更好地学习用户向量表示pu与物品向量表示qi之间的交互,LSRL模型选择使用与He等人工作[7]中类似的多层感知机(MLP)结构。拼接pu、qi两个向量作为第一层向量,并在该层向量后添加多层隐藏层。长期兴趣模块的形式化如式(4)所示。
其中,Wk、bk、ak是第k层隐藏层的权重矩阵、偏置矩阵与激活函数。根据测试,激活函数设置为线性整流函数(ReLU)[11]。最后,得到长期兴趣模块的输出vlongL。
1.2.4 短期兴趣模块
图2右侧部分为短期兴趣模块。在短期兴趣模块中,对正反馈交互历史序列的处理与负反馈交互历史序列的处理是类似的,这里只介绍对正反馈交互序列的处理。用户的最近N个正反馈交互记录{i1,i2,…,iN}组成正反馈交互序列。为了降低模型复杂度与参数数量, 正反馈交互历史 序列与负反馈交互历史系列与待推荐物品共享同一个物品嵌入层。正反馈交互序列经过物品嵌入层后得到物品表示向量序列{qi1,qi2,…,qiN}。Hidasi等人的工作[12]指出:门控循环单元(GRU)[8]在推荐任务中学习序列信息能力通常优于长短时记忆网络(LSTM)[13],且计算量更低。因此LSRL框架使用门控循环单元(GRU)从正反馈交互历史序列中学习用户的短期兴趣。门控循环单元(GRU)引入了更新门控zn与重置门控rn控制循环神经网络的记忆能力,具体计算如式(5)~式(8)所示。

图2 LSRL框架结构
LSRL框架使用GRU的最后一个隐层向量hN+作为正反馈交互序列的向量表示。与长期兴趣模块类似,将正反馈交互序列的向量表示hN+与待推荐物品向量qi拼接作为多层感知机(MLP)的输入vshort+1,经过多个隐层后,得到短期兴趣模块的正反馈输出vshort+L。
LSRL框架使用结构相同但是参数不同的门控循环单元(GRU)与多层感知机(MLP),从用户的最近N个负反馈交互记录{j1,j2,…,jN}组成负反馈交互序列中得到短期兴趣模块的负反馈输出vshort-L。
1.2.5 预测模块
预测模块的作用是利用长期兴趣模块与短期兴趣模块的输出,计算当前用户正反馈交互序列与负反馈交互序列(状态)与待推荐物品(动作)间的值函数Q(s,a)。
因为在长期兴趣模块与短期兴趣模块内部用户兴趣向量都与待推荐物品向量间通过多层感知机(MLP)进行了充分的交互,所以预测模块的结构比较简单。首先拼接长期兴趣模块的输出vlongL与短期兴趣模块的输出vshort+L、vshort-L,接下来通过多层感知机(MLP)得到最终输出Q(s,a)。
1.3 参数学习
如1.2节所述,LSRL框架通过重新设计深度Q网络(DQN)中Q网络的结构来同时学习用户的长期兴趣与短期兴趣,即只更改了值函数Q(s,a)的计算方式。因此,我们可以继续沿用深度Q网络模型的损失函数与训练方法。
由于真实场景中的状态空间S与动作空间A通常规模巨大,式(2)中的期望值难以直接计算。实际训练中通常采用小批量梯度下降方法 (Mini-Batch Gradient Descent),随机选取小批量状态转移过程集合P,然后计算该集合上的期望值,并使用Adam优化器优化模型参数。
深度Q网络(DQN)中使用深度网络拟合值函数Q(s,a),这通常会导致模型训练不稳定。为了降低模型训练难度,用户嵌入层与物品嵌入层使用预训练向量初始化,并在之后的训练过程中保持固定,不再随反向传播更新。经过对比测试,选择概率矩阵分解(PMF)方法[9]并使用二分类交叉熵(Binary Cross Entropy)损失函数训练得到的嵌入层权重。除此之外,为了限制模型表达能力,稳定训练过程并防止过拟合现象,LSRL框架在损失函数中引入L2正则化项。
算法1中给出了LSRL框架的训练方法。

算法1:LSRL框架训练方法1:初始化回放缓存D2: 随机初始化评估网络参数并设置预训练嵌入层权重,同步评估网络参数到目标网络3:对每一个会话(Session)循环:4: 根据用户之前的会话初始化状态s05: 对每一个推荐项目循环:6: 从离线数据中观察状态、动作、反馈7: 根据反馈更新状态8: 存储状态转移(st,at,rt,st+1)到回放缓存D中9: 从回放缓存中采样小批量状态转移集合P10: 在小批量状态转移集合P上最小化损失函数L(θ)11: 更新评估网络模型参数12: 如果距离上次同步达到一定时间:13: 同步评估网络参数到目标网络14: 结束条件判断15: 结束循环16:结束循环
2 实验
2.1 实验设置
2.1.1 数据集
MovieLens[14]: MovieLens是一个被广泛使用的电影评分数据集,包含不同规模的评分记录。本文选取MovieLens-100K、MovieLens-1M与MovieLens-10M三个规模的数据集,数据集的统计数据见表1。每一条评分记录包括用户与物品的序号、用户对电影的评分与评分的确切时间。用户对电影的评分范围是1-5分,本文认为小于等于3分为负反馈,大于3分为正反馈。数据集中每个用户交互数量均大于等于20。

表1 数据集概况
对每一个用户u,根据评分时间信息确定用户交互记录序列Su。将Su以如下方式划分[15]:①用户最后一次正反馈交互记录用于测试,舍弃该记录之后的负反馈交互记录; ②用户倒数第二次正反馈交互记录用于验证,舍弃验证记录与测试记录间的负反馈交互记录; ③所有剩余交互记录用于训练。测试集的交互序列输入中包含验证集的交互记录。对于验证集与测试集中的每一个正反馈记录,分别随机从物品集合中抽样出该用户没有交互过的99个物品作为负例,构成长度为100的候选物品集合。为了公平比较,在训练过程前采样出候选物品集合,并应用于所有模型的验证与测试过程。
2.1.2 基线方法
为了测试提出的LSRL模型的性能,选取了三组方法作为基线方法。
不考虑用户交互记录时间序列的推荐方法:
(1)PMF[9]:概率矩阵分解方法,是一种隐向量方法。将用户交互矩阵分解为低秩的用户隐矩阵与物品隐矩阵的乘积,从概率角度解释矩阵分解过程。PMF只考虑存在记录的用户—物品对。
(2)SVD++[10]:SVD++改进了概率矩阵分解方法,结合隐向量方法与邻域方法的优势,在预测函数中考虑用户所有隐式交互行为。
(3)NCF[7]:神经协同过滤方法,结合深度神经网络与协同过滤方法,使用多层感知机(MLP)学习用户—物品交互信息。
基于用户交互记录时间序列的推荐方法:
(4)GRU4Rec[12];首个应用循环神经网络(RNN)的推荐方法,使用门控循环单元(GRU)从短期的会话数据中刻画序列信息,并提出新的排序损失函数。
(5)SASRec[16]:利用自注意力机制(Self-Attention Mechanism)学习用户交互序列的方法,从相对较短的序列中学习历史交互过的物品间的相关性并预测下一个物品。
基于深度强化学习的推荐方法:
(6)DQN[1];深度Q网络,首个结合深度神经网络的基于价值优化的强化学习方法,使用神经网络拟合状态—动作值函数。
(7)DEERS[5]:首个同时从正反馈交互序列与负反馈交互序列中建模用户状态的基于深度强化学习的推荐方法。
表2中比较了LSRL框架与所有基线方法的异同。
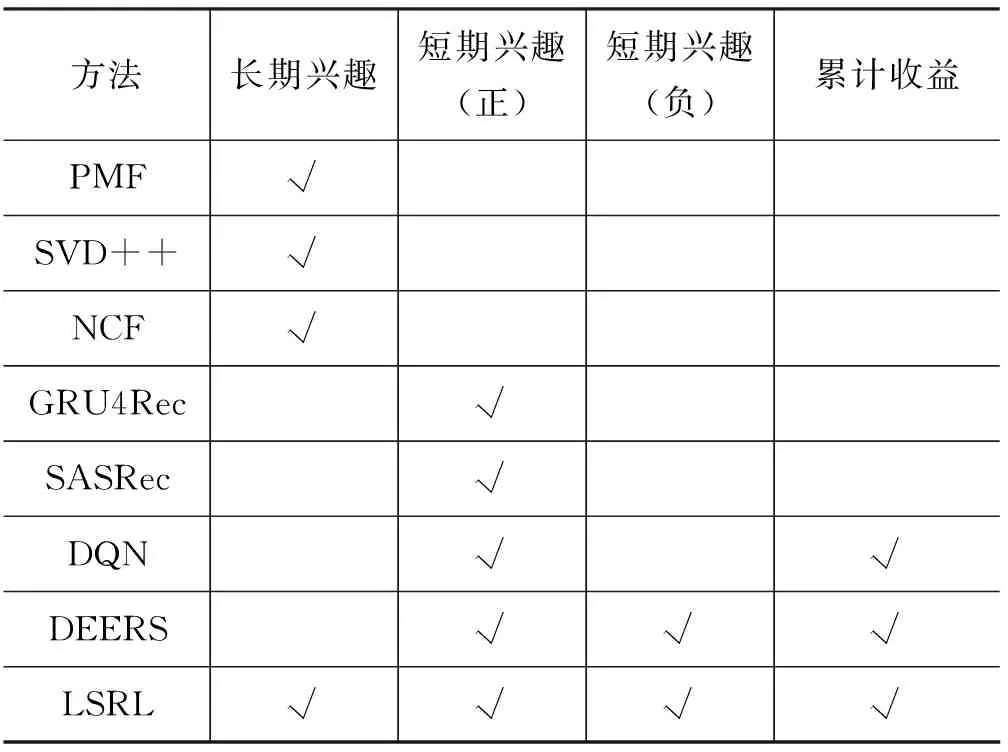
表2 基线方法与LSRL框架比较
2.1.3 评价指标
在验证与测试阶段,对每个候选物品集合,排序其中的物品。为了评价排序后的推荐列表质量,我们选择命中率(Hit Ratio, HR)与归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)作为评价指标。
如果使用a表示某个候选物品集合中用户给出过正反馈的唯一物品的序号,xi表示排序后推荐列表里第i个物品的序号,那么推荐列表前k个物品的命中率(HR)可以通过式(9)计算:
其中,I(xi=a)是指示函数,如果第i个物品是用户给出过正反馈的物品,返回1,否则返回0。命中率(HR)衡量了用户给出过正反馈的物品是否在推荐列表的前k个物品中。为了衡量该物品的位置,首先计算折损累计增益(DCG),如式(10)所示。
然后我们计算正反馈物品处于第一位的推荐列表的DCG并令其为理想折损累计增益(IDCG),则归一化折损累计增益(NDCG)可以通过式(11)计算:
对验证集或测试集中的每一个候选物品集合计算排序后推荐列表的评价指标,并汇报所有候选物品集合的平均值。
2.1.4 实现细节(1)实验代码在如下链接:https://github.com/THUyansh/LSRL
我们使用PyTorch实现了所有的推荐方法,并使用Adam优化器学习模型参数,直至验证集上NDCG@10评价指标连续20轮次不再提升,最大训练轮次为100。对于每一种推荐方法,我们应用验证集上NDCG@10最高的轮次对应的模型参数在测试集上测试。每个推荐方法使用不同的随机种子重复运行5次,并汇报5次试验结果的平均值。
为了公平地对比不同的推荐方法,批量大小均设置为256,嵌入层维度均设置为64。特别地,所有基于深度强化学习的推荐方法,衰减因子γ设置为0.9。其他的超参数被设置为推荐方法论文作者的推荐值,或者根据验证集上NDCG@10的结果来选择。
2.2 实验结果
表3~表5展示了LSRL框架与所有其他基线方法在不同数据集上的实验结果。其中,粗体的实验结果表示在该规模数据集下所有推荐方法中最高的评价指标值,标注下划线的实验结果表示在该规模数据集下所有基线方法中最高的评价指标值;标注“*”符号的实验结果标明该结果在双侧t检验中比基线方法的最佳结果有显著性的提升。显著性检验中p<0.01。
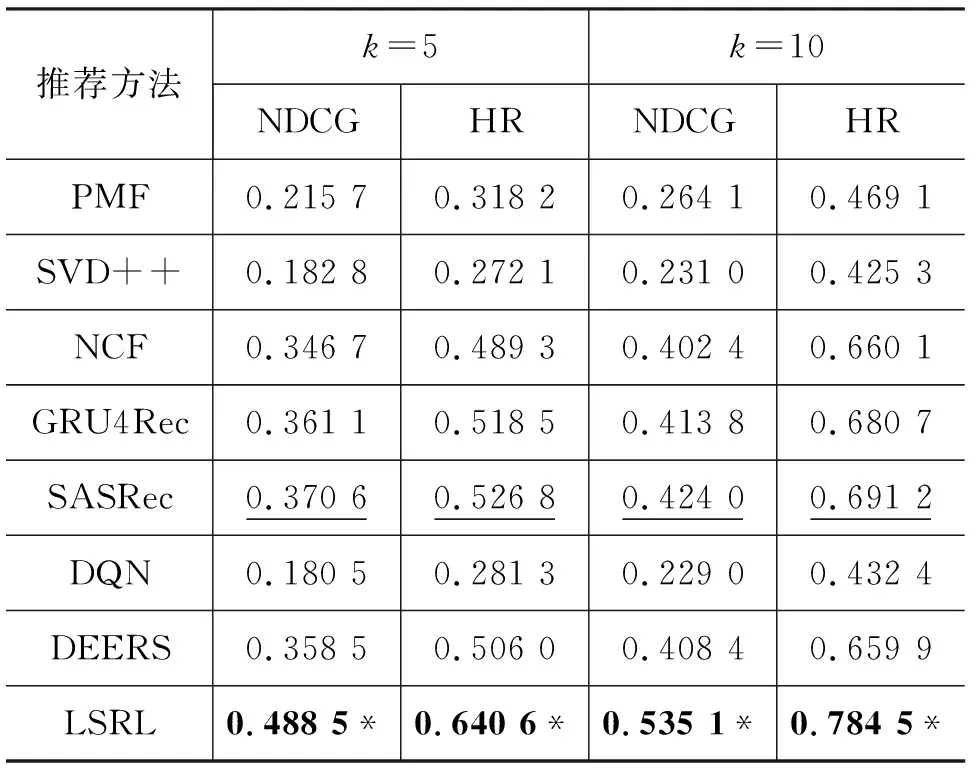
表3 MovieLens-100K实验结果
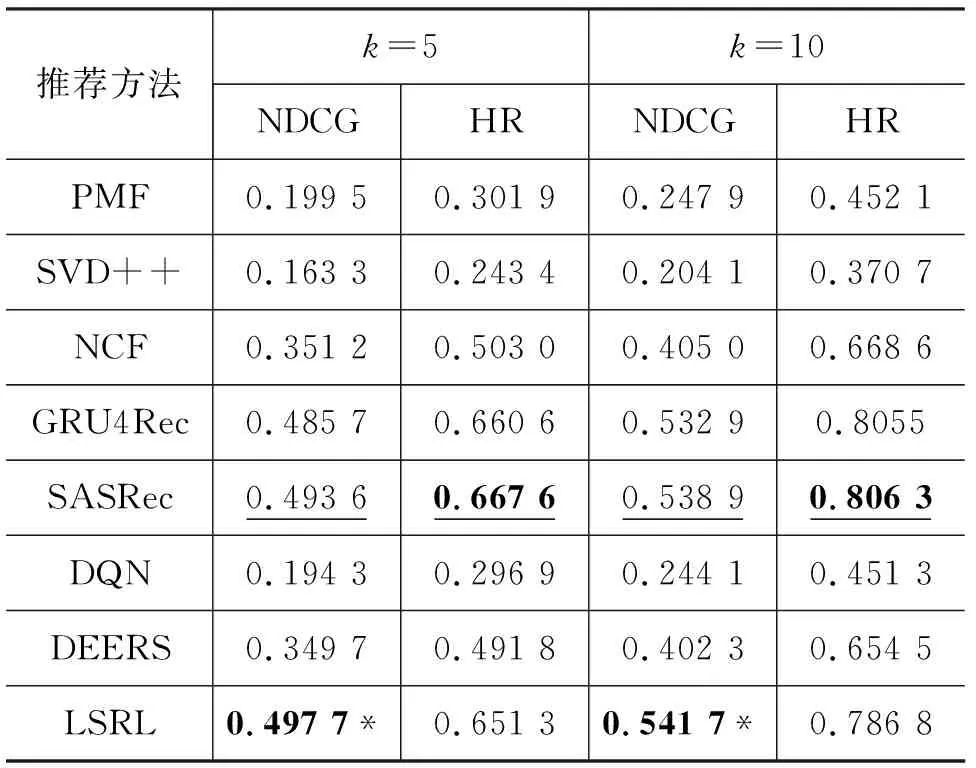
表4 MovieLens-1M实验结果

表5 MovieLens-10M实验结果
在不同规模的数据集上,每种推荐方法的表现都有所差异。
在不考虑用户交互记录时间序列的推荐方法中,NCF方法在三个规模的数据集上都获取了最佳表现。这表明NCF方法在结合了深度神经网络之后,模型的表达能力比PMF与SVD++方法中的内积运算更强,能够从训练数据中学习出更多的信息。
所有基于用户交互记录时间序列的推荐方法的表现都比不考虑用户交互记录时间序列的推荐方法好。其中,SASRec方法在三个数据集上的表现始终是所有基线模型中最优的。这说明了建模用户短期兴趣可以帮助推荐系统更准确地推荐物品。
基于深度强化学习的三个推荐方法效果差异较大。DQN方法的表现与基础的PMF模型类似。DEERS方法的表现要显著好于DQN方法,这验证了在深度强化学习中引入用户负反馈交互信息是有效的。LSRL方法的表现明显优于DEERS方法,这证明融合用户长期兴趣与短期兴趣能够显著提高推荐系统的性能。
综合所有基线模型,LSRL方法只在MovieLens-1M数据集上的HR评价指标上没有获得最佳数值,比SASRec方法稍差。这可能是因为MovieLens-1M数据集的数据特征与其他两个数据集不同,横向比较三个数据集上不同方法的实验结果,发现只有MovieLens-1M数据集上基于时间序列建模用户短期兴趣的推荐方法与能够同时建模用户长期兴趣与短期兴趣的LSRL方法非常接近,这说明该数据集中用户兴趣以短期兴趣为主导因素,LSRL方法中的长期兴趣模块会引入一定程度的噪音,使得命中率(HR)指标稍差。但在NDCG评价指标上,LSRL方法依然优于SASRec方法,根据两个评价指标的计算方式可以发现,在推荐列表排序能力上,LSRL方法更有优势,更倾向于将用户感兴趣的物品排序到靠近列表头部的位置。LSRL方法在其他所有评价指标上都相对所有基线模型有显著性的提升,表现出了良好的排序能力与推荐准确性。
2.3 消融实验与分析
为了验证LSRL框架中强调两个因素(用户长期兴趣与短期兴趣)对框架推荐效果的影响,我们进行了消融实验,分别保留长期兴趣模块、短期兴趣模块(正反馈)与短期兴趣模块(负反馈)中的一个或几个模块,在MovieLens-100K与MovieLens-1M数据集上测试推荐效果。表6直观地给出不同模型使用的信息。

表6 消融实验中使用的模型
消融实验的结果如表7所示,表中只汇报NDCG@10的结果。其中,LSRL-P方法在三个数据集上都显著优于SRL-P方法,LSRL方法也显著优于SRL方法,这表明无论短期兴趣模块是否引入用户的负反馈交互序列,融合长期兴趣模块都会提高推荐准确度。而LSRL-P方法与LSRL方法比LRL方法有更好的表现,说明短期兴趣模块同样重要。

表7 消融实验结果
3 相关工作
3.1 推荐系统中的用户兴趣建模
在推荐系统研究中,准确刻画用户兴趣是非常重要的。随着推荐系统的发展,建模用户兴趣的方式也在不断变化。用户兴趣建模方式大概可以分为三种:只建模用户长期兴趣、只建模用户短期兴趣与同时建模用户长期兴趣与短期兴趣。
只建模用户长期兴趣的代表性推荐方法有矩阵分解(Matrix Factorization, MF)方法与其变种[9-10]。矩阵分解方法将用户交互矩阵分解为低秩的用户隐矩阵与物品隐矩阵,通过训练学习出一个固定的用户隐向量来表达用户兴趣。在预测时,由于用户向量表示固定不变,矩阵分解方法无法通过用户实时的交互行为来推荐项目。
只建模用户短期兴趣的代表性推荐方法是仅利用用户最近交互行为的模型。Covington等人的工作[17]利用平均池化(Average Pool)的方法从无序的用户交互行为中学习用户兴趣。Hidasi等人提出的GRU4Rec模型[12]使用门控循环单元(GRU)从有序的用户交互行为序列中建模用户短期兴趣。Zhou等人提出的DIN模型[18]利用注意力机制(Attention Mechanism)计算不同用户交互行为的权重,获得了比平均池化方法更好的表现。Kang等人提出的SASRec方法[16]使用自注意力(Self-Attention Mechanism)从有序的交互行为中挖掘用户兴趣。这些推荐方法的共同特点是利用用户最近的交互行为进行推荐,容易受用户实时的兴趣点影响,难以给用户推荐更全面的物品列表。
除此之外,部分推荐方法可以同时建模用户的长期兴趣与短期兴趣。An等人提出的LSTUR模型[19]提出两种方式融合用户兴趣并进行新闻推荐:使用用户嵌入向量初始化循环神经网络的隐藏层;将用户嵌入向量与循环神经网络的输出拼接。Hu等人提出的GNewsRec模型[20]结合了注意力机制与图神经网络用于新闻推荐。Wu等人提出的LSPL模型[21]结合了注意力机制与循环神经网络。
3.2 基于深度强化学习的推荐方法
近年来强化学习算法在推荐领域中受到重视,一些基于深度强化学习的方法被提出。这些方法将用户历史交互行为视为环境状态,将推荐物品视为动作用户,根据模型训练方式的不同可以分为两类:基于价值优化的算法与基于策略优化的算法。
基于价值优化的算法在训练中学习状态—动作值函数Q(s,a),在所有的候选动作中选出当前用户状态下具有最大Q值的待推荐物品推荐给用户。 Mnih等人提出的深度Q网络模型(Deep Q-Network, DQN)[1],首次结合深度学习技术到强化学习中,使用深度网络拟合状态-动作值函数,并引入经验回放技术与目标网络技术稳定的训练过程。 Zheng等人提出的DRN模型[3],将DQN应用到新闻推荐场景中,将用户在不同时间段内浏览新闻的统计信息作为用户状态,并引入用户活跃度信息。Zhao等人提出的DEERS模型[5],利用门控循环单元(GRU)同时从用户正反馈与负反馈历史交互序列中建模用户短期兴趣,并提出了引入成对排序正则化项的损失函数。Zou等人提出的FeedRec模型[6]使用分层的长短时记忆网络(LSTM)从用户的点击、停留、重新访问等多种行为中建模用户短期兴趣,并提出了一些新技术稳定深度强化学习训练中的不确定性。
基于策略优化的算法在训练中学习推荐策略,输入用户当前状态后,推荐策略输出待推荐的物品。Zhao等人提出的DeepPage模型[4]扩展了深度确定性策略梯度模型(DDPG)[22],并研究了推荐一个页面的物品的排序优化方法。
以上绝大多数方法仅使用循环神经网络(RNN)等方法学习用户的短期兴趣,忽略了用户的长期兴趣,导致对用户的兴趣建模存在不足。因此我们在LSRL框架中引入了用户长期兴趣,从而更精准地建模用户兴趣。
4 结语
本文提出了基于深度强化学习的LSRL框架,成功地引入了用户长期兴趣,更加准确地建模用户兴趣。具体地,LSRL框架使用协同过滤技术(CF)与循环神经网络(RNN)分别建模用户长期兴趣与短期兴趣,并设计了新的Q-网络融合不同模块学习到的信息。在多个真实数据集上的实验结果表明,我们提出的LSRL框架能够实现同时学习用户的长期兴趣与短期兴趣,并比所有的基线推荐方法在不同的评价指标上有显著的性能提升。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
数学物理学报(2020年3期)2020-07-27 01:19:46
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
法大研究生(2017年1期)2017-04-10 08:55:06
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
