
基于分段注意力匹配网络的跨领域少样本关系分类
2021-10-12 04:53:12戴尚峰孙承杰单丽莉刘秉权
中文信息学报 2021年8期
戴尚峰,孙承杰,单丽莉,林 磊,刘秉权
(哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
0 引言
关系分类是自然语言处理中重要的研究内容,目的是从给定的句子中判断两个实体的关系类型。现有的关系分类任务多依赖于人工标注语料,不仅花费大量的人力和物力,而且由于标注成本高,存在着标注语料匮乏问题。远程监督的方法使用知识库对文本进行启发式标注,部分解决了标注语料匮乏问题,但是远程监督获得的语料存在噪声,并且知识库中的长尾分布问题在语料中同样存在,因此少样本关系分类任务被提出。在少样本关系分类任务中,模型需要在未训练过的关系类型上仅用极少数据进行关系分类。然而,在实际应用中,测试数据通常与训练数据来自不同的领域,这会导致模型在同领域测试数据上表现较好,而在不同领域测试数据上效果较差。针对上述问题,本文就跨领域少样本关系分类任务进行研究,模型需要进一步在不同领域的测试数据上进行少样本关系分类。
在当前的少样本关系分类方法中,以句子级别表示为主,这类方法首先编码句子向量,然后使用不同算法进行聚合和少样本关系分类,如Prototypical Network[1]、Graph Neural Network[2]等,但是预测性能均差强人意。这是因为基于句子级别表示的方法往往难以精确地通过一个向量表示句子信息,而基于单词级别表示的方法,可以更为细粒度地表示文本信息,如多层次匹配聚合网络MLMAN[3],在少样本关系分类任务FewRel 1.0[4]上取得了较好的效果。基于文本相似度计算的方法可以降低领域差异性带来的影响,文献[5]构建了跨领域测试数据集的少样本关系分类任务FewRel 2.0,并提出了BERT-PAIR方法,使用BERT[6]模型计算句子间单词的交互信息,通过计算文本相似度选出与查询实例(query instance)最相似的支持集合(support set),在FewRel 2.0领域适应任务中,取得了该任务基线模型中的最好效果。
本文提出了模型PAMN(Piecewise Attention Matching Network),在BERT-PAIR[5]的基础上进一步融合句子相似度计算方法,针对关系抽取问题,将句子分段进行匹配,能够更准确地计算关系实例间的相似度。PAMN在编码层使用BERT[6]模型,将句子根据实体位置分为三段,针对段长分布的跨领域差异性,使用动态段长进行段长领域自适应,在句子匹配层使用基于分段注意力机制的句子相似度计算方法,PAMN取得了目前FewRel 2.0领域适应任务测评榜单上的最好效果。
1 相关工作
近年来,基于度量的方法在少样本学习任务中被广泛研究。基于度量的方法使用映射函数对查询实例和支持集合进行映射,并对映射后的向量通过度量函数分类。Prototypical Network[1]将查询实例和支持集合中的实例映射到同一空间,使用支持集合中实例向量的中心来表示该支持集合向量,距离查询实例向量最近的支持集合向量为查询实例所属的类别;Siamese Network[7]使用孪生结构对查询实例和支持集合中的实例进行编码,并使用距离度量函数衡量距离的远近;Matching Network[8]引入了注意力机制和外部记忆,使模型可以更好地融合支持集合的特征;Graph Neural Network[2]加强了实例间的信息交互,将查询实例向量和所有支持集合中的实例向量置于图中,通过图神经网络进行向量的交互和更新;Induction Network[9]则通过动态路由的方式对支持集合中的实例特征进行聚合。由于少样本关系分类任务属于少样本学习任务中的一种,上述提到的少样本学习方法都可以迁移到少样本关系分类任务中,但需要将编码方式针对关系分类实例进行更改。
对于少样本关系分类任务,研究人员提出了更具有针对性的方法。基于预训练的方法通过针对性预训练来加强模型对关系分类任务的预先理解,Soares等[10]认为相同的实体对中存在着相似的关系类型,并基于这个假设使用大量无监督数据进行预训练,取得了当时FewRel 1.0少样本关系分类任务测评榜单上的最好效果。基于句子相似度计算的少样本关系分类方法属于少样本学习中基于度量的方法,可以减少模型在对句子编码时损失的特征,有较好的领域适应性,多层次匹配聚合网络MLMAN[3]使用基于单词级别与实例级别的注意力机制对查询实例和支持集合进行多层次匹配聚合;BERT-PAIR[5]方法使用BERT[6]模型计算句子相似度,取与查询实例相似度最高的支持集合为查询实例的预测类别,取得了当时FewRel 2.0领域适应任务基线模型中的最好效果,证明了基于句子相似度计算的跨领域少样本关系分类模型的有效性。
2 问题定义
在少样本关系分类任务中,由于训练集与测试集没有关系类型交集,在测试集上进行预测时,对于给定的待分类查询实例(query instance),通过N个支持集合(support set)来表示N种关系类型,每个支持集合中有K个相同关系的实例。判断查询实例属于给定支持集合中的哪一个,这样一次预测称为一次NwayKshot分类。在训练集中我们以同样的方式进行数据构建,通过训练来提升模型在测试集中的效果。
我们将关系类型实例表示为(x,e1,e2,r),其中,x为该实例的句子,e1、e2分别为该句子中的头实体和尾实体,r为e1、e2间存在的的关系类型;N个支持集合表示为S={Si={sij=(xij,ei,j,1,ei,j,2,ri)|j=1,…,K}|i=1,…,N},sij表示支持集合Si中的第j个实例;待分类关系类型的查询实例表示为q=(x,e1,e2,rt),t∈{1,…,N},t为需要进行预测的类别。表1列举了FewRel 1.0数据集中一次3 way 2 shot少样本关系分类,我们需要判断查询实例中的实体(Anjani Putra,harsha)的关系类型与哪一个支持集合(S1,S2,S3)中的实体关系类型相同。

表1 FewRel 1.0数据集 3 way 2 shot例子
3 分段注意力匹配网络(PAMN)
3.1 模型总体架构
在少样本关系分类任务中,对于给定的查询实例q=(x,e1,e2,rt),t∈{1,…,N}与N个支持集合S={Si={sij=(xij,ei,j,1,ei,j,2,ri)|j=1,…,K}|i=1,…,N}。我们通过句子相似度计算的方式来计算查询实例和支持集合的相似度。首先,我们计算查询实例q和第i个支持集合Si中第j个实例sij的相似度simij,并取均值Simi=mean(simij),j∈{1,…,K}作为q与Si的相似度,最后取t=argmax(Simi)作为预测类别。在计算simij时经过编码层和句子匹配层。编码层使用预训练模型BERT[6]对q与sij进行单词级别的编码,句子匹配层使用分段注意力机制计算编码后的q与sij的相似度simij。分段注意力匹配网络PAMN结构如图1所示。
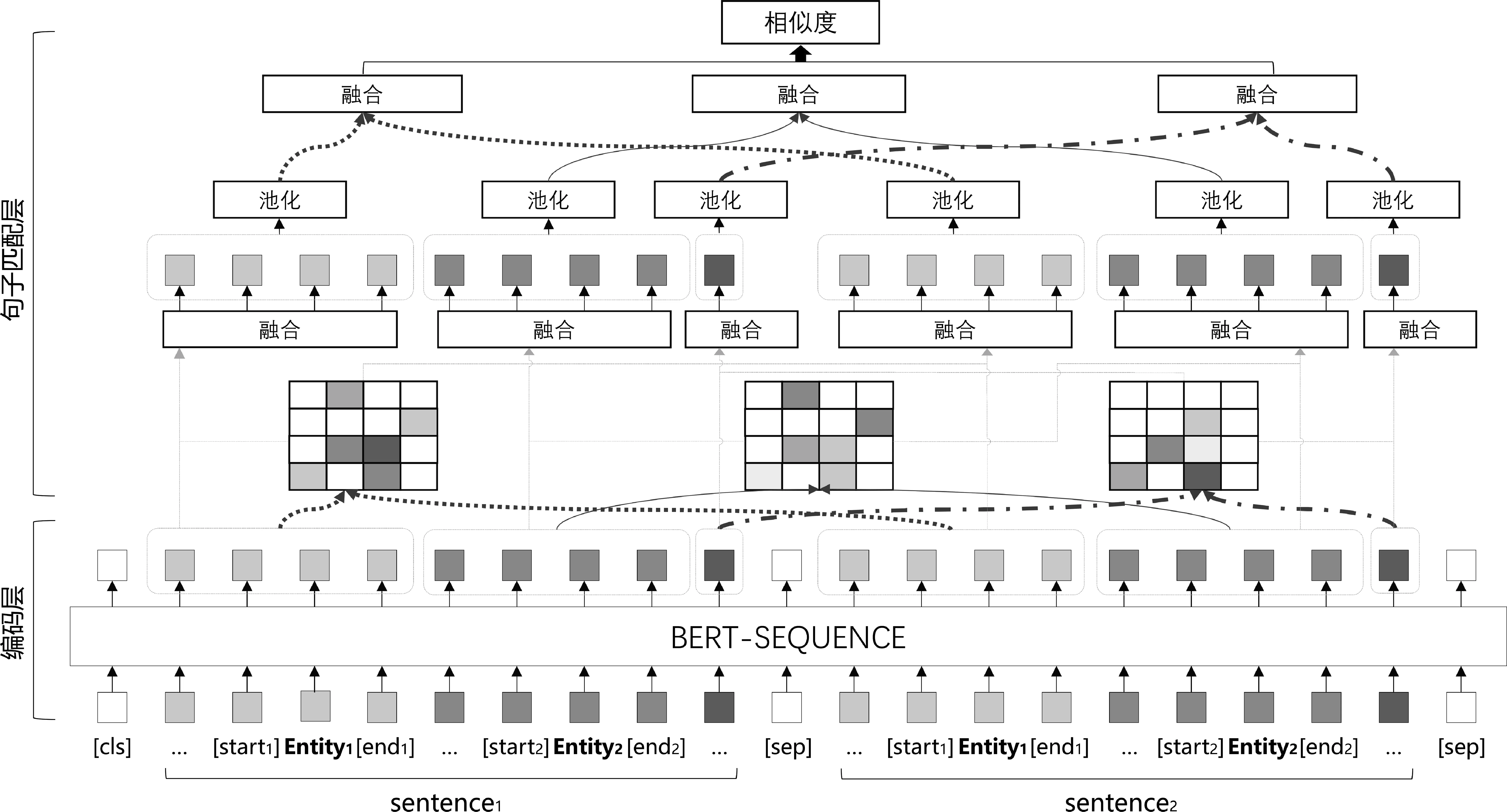
图1 分段注意力匹配网络PAMN结构
3.2 编码层
在计算支持集合Si中的第j个实例sij与查询实例q相似度时,我们使用预训练语言模型BERT[6](BERT for sequence classification)对sij、q进行编码,输入BERT的句子对编码方式与BERT-PAIR[5]相同。句中的头实体、尾实体周围分别使用
特殊符号[e1,start]、[e1,end]、[e2,start]、[e2,end]进行标识,将两个句子分别表示为如下序列(头实体在前,尾实体在后),如式(1)、式(2)所示。
其中,sentence1、sentence2表示sij和q构成待匹配的句子对,m为经过填补或截取后的固定句长,w1,1、w1,m分别表示sentence1的第一个和最后一个单词。输入BERT之前,在句子对前面加入BERT中的[cls]符号,中间和末尾加入[sep]符号,拼接如式(3)所示。
(3)
使用BERT中的segment_label对两个句子中的单词进行区分,如式(4)所示。
(4)
将input_sequence和每个单词的segment_la-bel转化为词向量和segment_label向量,对应位置相加后输入BERT,得到sentence1、sentence2对应的单词向量序列v1∈Rm×d、v2∈Rm×d,m为句长,d为BERT输出单词向量的维度。与PCNN[11]类似,将向量v1,v2按照两个实体结束符位置e1,end,e2,end分为三段,并使用动态段长m1,n,m2,n(见3.5节)进行填补或截断,得到:v1,n∈Rm1,n×d,v2,n∈Rm2,n×d,n∈{1,2,3}。我们认为对应段间的相似单词更具有针对性,并且可以减少跨段的无意义相似单词对于句子相似度计算的影响,接下来,在句子匹配层,我们将通过分段注意力机制计算sentence1与sentence2的句间相似度。
3.3 句子匹配层
对于3.2节得到的段矩阵v1,n∈Rm1,n×d,v2,n∈Rm2,n×d,n∈{1,2,3},在句子匹配层使用分段注意力机制计算句间相似度,对于对应段[v1,n,v2,n],首先分别将v1,n和v2,n输入全连接层,并使用tanh激活函数,如式(5)、式(6)所示。
分段注意力机制中,我们认为对应段间单词的相似度更有意义,使用矩阵乘法得到对应段注意力矩阵Mn,其中,Mn,i,j表示sentence1第n段的第i个单词v′1,n,i和sentence2第n段的第j个单词v′2,n,j的相似度,i∈{1,…,m1,n},j∈{1,…,m2,n},如式(7)所示。
Mn,i,j=(v′1,n,i)Tv′2,n,j
(7)
使用交叉注意力获取对应段中的相似特征表示。对于sentence1中第n段sentence1,n的每个单词向量的相似特征,使用sentence2的对应段sentence2,n中单词向量的加权和来表示,sentence2,n中每个单词向量的相似特征以同样的方式通过sentence1,n表示,加权权重为对应段注意力矩阵Mn中的单词相似度。
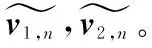
接下来,将对应段的特征表示进行融合,如式(16)所示。
mn=tanh([v1,n,max;v1,n,avg;v2,n,max;v2,n,avg]W5+b5)
(16)
对于所有对应段使用上述相同的操作,不同段的全连接层使用不同参数(全连接层参数为W1~W15和b1~b15,其中,W1~W5、b1~b5为第一段参数;W6~W10、b6~b10为第二段参数;W11~W15、b11~b15为第三段参数),得到m1,m2,m3,拼接得到m,如式(17)所示。
m=[m1;m2;m3]
(17)
最后经过全连接层将m映射为1维向量,即表示sentence1与sentence2(sij与q)的句间相似度,如式(18)所示。
simij=(tanh(mW16+b16))W17+b17
(18)
3.4 预测方法与损失函数
在预测阶段,根据查询实例q与支持集合Si中每个实例sij的相似度simij的均值,表示q与Si整体的相似度Simi=mean(simij),j∈{1,…,K}。取相似度最大的支持集合St的下标t=argmax(Simi),i∈{1,…,N}作为预测标签。使用交叉熵损失函数计算预测相似度Simi与标签yi间的损失值,如式(19)、式(20)所示。
3.5 段长分布与动态段长
在实验阶段,我们发现虽然FewRel 1.0训练集、FewRel 1.0验证集与FewRel 2.0验证集(数据集介绍见4.1节)均没有关系类型交集,但是由于FewRel 2.0验证集领域不同,导致它与其他两个数据集句长分布差异较大(经过BERT Tokenizer[6]处理后的句长),我们统计了三个数据集的句长均值、标准差,以及句子根据实体分为三段后不同段的段长均值和标准差,如图2所示。
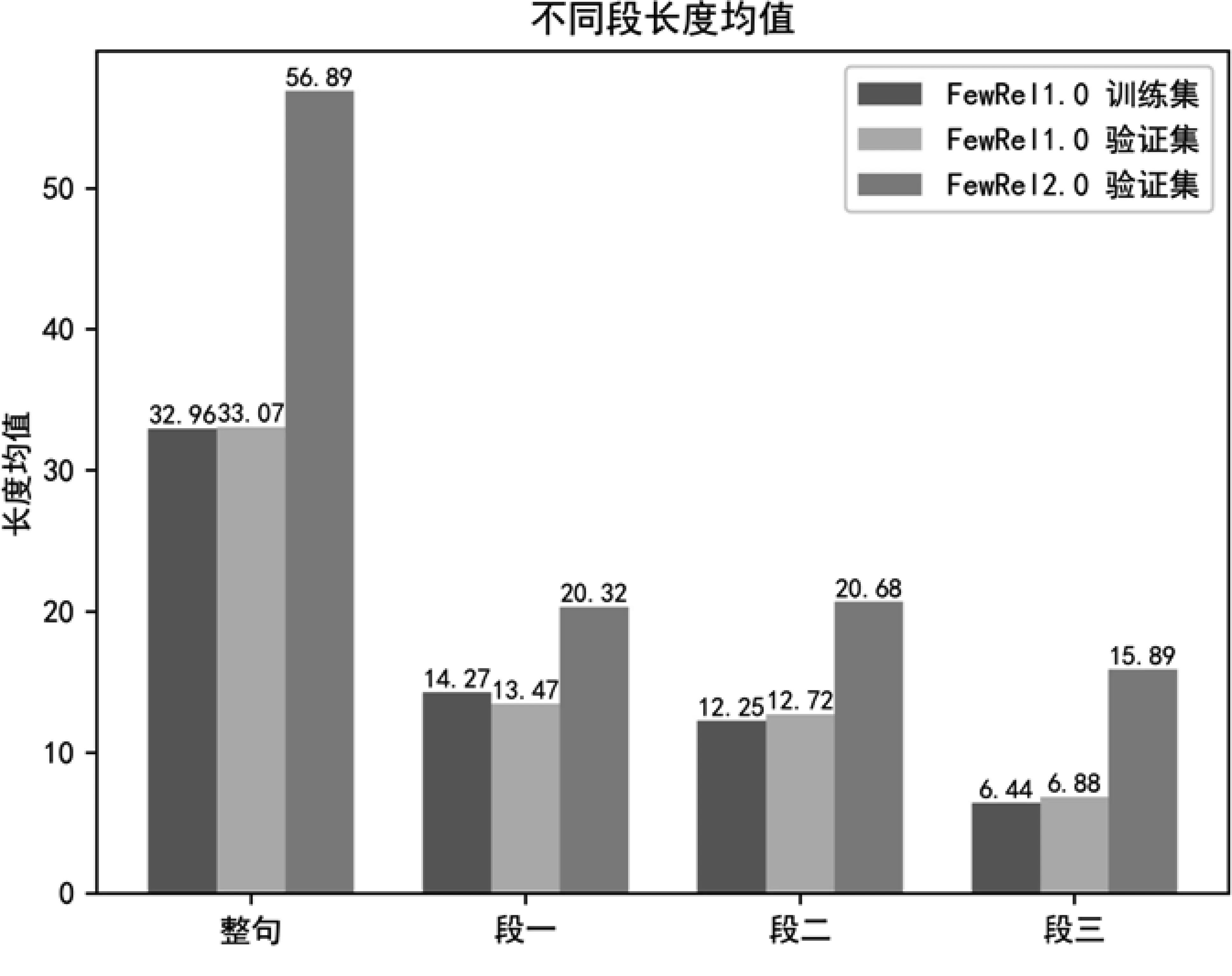
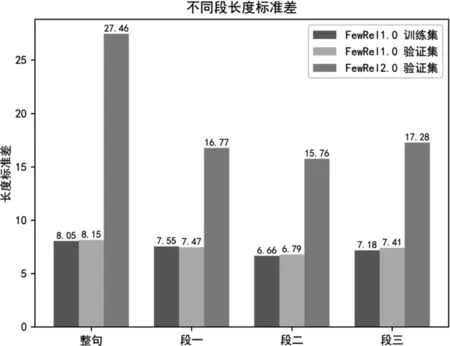
图2 FewRel1.0训练集、验证集和FewRel 2.0验证集不同段的长度均值、标准差
从图2可以看出,段长分布存在着较大的跨领域差异性,无论是句长还是每一段的段长,FewRel 2.0验证集都存在长度较长且标准差较大的问题,我们使用动态段长实现领域适应。首先,输入BERT的句子对长度从训练集的115(单句长m=56,加上头部的[cls]与中间和尾部的[sep]标识符后,句长由(115)修改为验证集的243(单句长m=120),同时,在NwayKshot分类时共有Q×N×K(Q为预测的Query数目)个句子对,在分段进行填补或截断时,我们将长度设置为Q×N×K个句子对中该段段长均值的1.5倍,如式(21)所示。
(21)
其中,1≤i≤Q×N×K,1≤n≤3,m1,n,m2,n分别表示第i个句子对中第一个句子sentencei,1与第二个句子sentencei,2每段的动态段长,leni,1,n,leni,2,n表示sentencei,1与sentencei,2根据实体分为三段后每段的长度,这样每次NwayKshot分类时动态段长会根据段长均值进行自适应,使得填补或截断后的段长可以覆盖大部分段长,同时不会变得过长或过短,当我们在不同领域数据集上进行实验时,段长会根据领域进行自适应。
4 实验
4.1 数据集
我们的训练集为FewRel 1.0训练集,共有64种关系类型,每类有700个关系实例;验证集为FewRel 1.0验证集和FewRel 2.0领域适应任务验证集,其中,FewRel 1.0验证集有16种关系类型,每类有700个关系实例,FewRel 2.0验证集共有10种关系类型,每类有100个关系实例;测试集由Few-Rel 2.0领域适应任务测评提供,共有15种关系类型,每类有100个关系实例,其中,训练集、验证集、测试集没有关系类型交集,最后我们将验证集上效果最好的模型提交到FewRel 2.0领域适应任务测评中,得到测试集结果。
4.2 数据构建
在训练与测试时,均需要将数据构建为少样本NwayKshot分类数据,构建算法如表2所示。

表2 N way K shot 分类数据构建算法
4.3 训练细节与参数设置
我们的模型在5 way 5 shot上进行训练,在5 way 1 shot(5-1)、5 way 5 shot(5-5)、10 way 1 shot(10-1)、10 way 5 shot(10-5)上进行验证和测试,通过分类准确率来评估模型性能。
由于每次NwayKshot分类数据构建使用随机抽样的方式,为了能够充分地学习训练集信息,使得训练集的每个数据都经过模型训练,我们将训练次数设置为30 000次,同时每训练1 000次,使用验证集对模型进行验证,验证次数设置为1 000次,并保存验证集准确率最高的模型参数。设置较高的验证频率是因为模型拟合速度较快,为了保存模型领域适应性最好的参数,需要在整个训练期间保持较高的验证频率,防止得到的模型参数过拟合。训练完成后,为了准确评估模型在验证集上的效果,使用被保存的模型参数在验证集上进行5 000次验证,把得到的准确率作为验证集评估结果。
我们使用BERTbase参数对BERT模型进行参数初始化,对BERT之外的参数使用Xavier[12]进行初始化,学习率设置为10-5,优化器使用Adamw[13],同时在BERT模型后以0.2的概率对单词序列向量进行dropout,防止模型对数据过拟合。BERT模型输出维度d为768,全连接层W1~W15输出维度为460,W16、W17输出维度分别为230和1。
4.4 实验结果
我们在FewRel 2.0领域适应任务测评中提交模型,与FewRel 2.0论文中的模型Proto(BERT)、Proto-ADV(CNN)、BERT-PAIR进行对比,结果如表3所示。
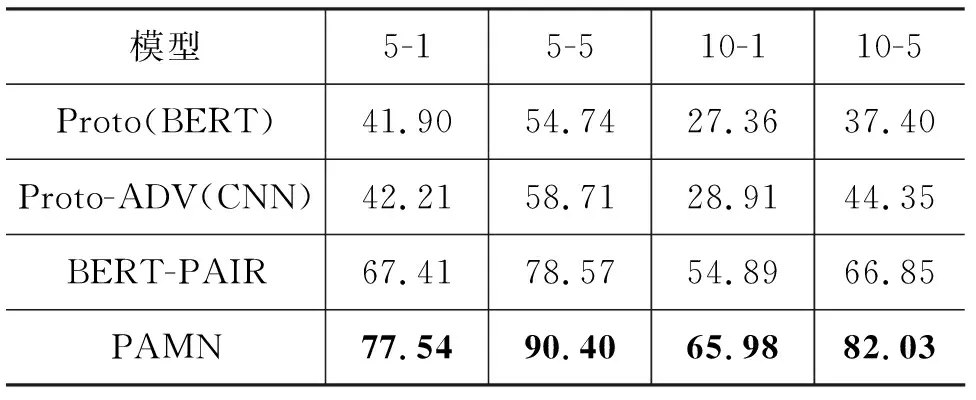
表3 不同模型在FewRel 2.0测试集上的准确率 (单位: %)
PAMN在FewRel 2.0领域适应任务测评中取得了当前榜单上的最好效果,相较于FewRel 2.0领域适应测评中最好的模型BERT-PAIR,准确率提升超过10个百分点,证明了PAMN在领域适应任务中的有效性。同时我们将在dropout=0.1时训练的模型提交到FewRel 1.0测评中,并与FewRel 1.0测评中效果最好的模型BERT-PAIR、MLMAN进行对比,由于MTB[10]使用了大量额外数据对实体关系预测进行针对性预训练,所以这里不与MTB进行比较,实验结果如表4所示。
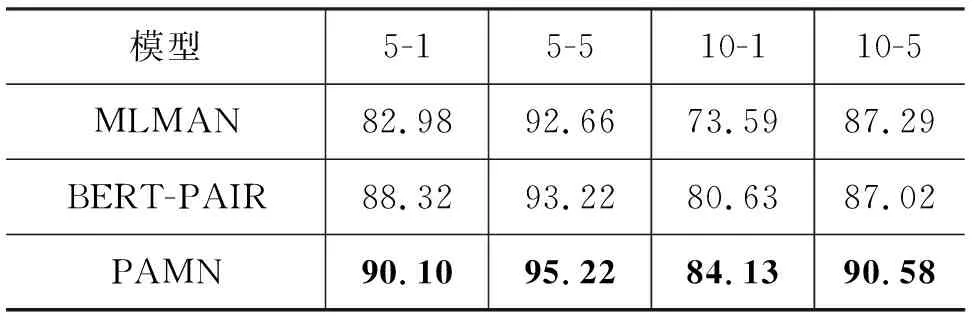
表4 不同模型在FewRel 1.0测试集上的准确率 (单位: %)
由于FewRel 1.0偏向于特定领域,我们没有针对FewRel 1.0对PAMN进行过多调整,仅调低dropout,降低模型的泛化性,与BERT-PAIR[5]模型相比,PAMN在FewRel 1.0任务上同样有着2至3个百分点的提升。
4.5 对比实验
为了分析PAMN中各部分结构对于模型的影响。我们在FewRel 2.0验证集上设置了两组对比实验。对比实验中的标准模型将句子分为三段,并使用非孪生结构的PAMN。第一组实验研究分段注意力机制对模型的影响,我们分别使用不将句子分段的PAMN,将句子分为四段(第四段为整个句子)的PAMN与标准模型进行比较。第二组实验研究孪生结构对模型的影响,孪生结构有着较好的泛化性,我们将网络结构调整为孪生结构,即对两个句子的对应段使用共享参数的全连接网络,与标准模型进行比较。
第一组实验研究分段注意力机制对模型的影响,其中分三段为标准模型,在FewRel 2.0验证集上的结果如表5所示。
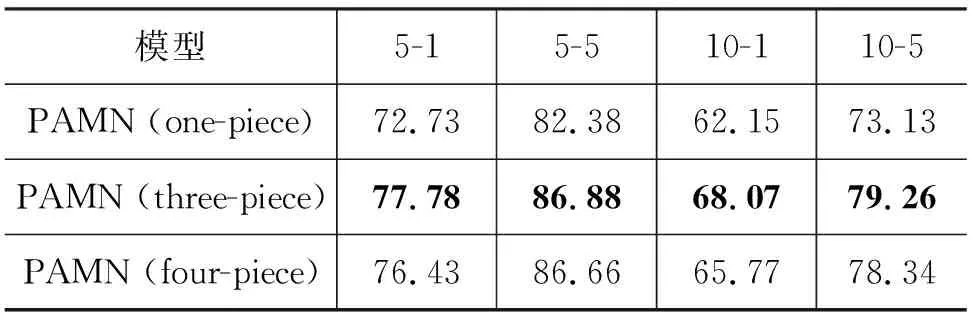
表5 不同分段数模型在FewRel 2.0验证集上的准确率 (单位: %)
从表5可以看出,将整个句子分为三段比不分段效果要好,分析原因可能有: ①在少样本关系分类问题中,同一关系分类实例,不同段各司其职,表达不同的内容,段与段间的表达方式、数据分布存在较大差异。PAMN模型的分段匹配结构,能够更精准地利用每一段的语义信息。②不同关系分类实例间分布差异较大(句长标准差大),相较于匹配长度较长、句式复杂的整句,PAMN匹配长度更短、句式简单且分布波动较小(标准差小)的段,可以获得更好的匹配结果。下面的句1和句2即为一对关系分类匹配实例:
句1: [CHKT]e1is a Canadian radio station, airing at 1430 AM in [Toronto]e2,Ontario.
句2: [WSFF]e1is licensed to [Vinton, Virginia]e2, serving Metro Roanoke.
根据实体位置进行分段后,“[CHKT]e1”和“[WSFF]e1”为第一段,“is a Canadian radio station, airing at 1430 AM in [Toronto]e2”和“is licensed to [Vinton, Virginia]e2”为第二段,“,Ontario”和“,serving Metro Roanoke”为第三段,对应段之间存在着较强的匹配关系,符合模型匹配时的期望。
但是不分段时可以额外匹配到两个句子中不同段间单词的相似特征,这部分特征是将句子分为三段时所缺少的。将句子分为四段(第四段为整个句子)相当于在三段的基础上加入了整个句子不同段间相似单词的特征,既考虑了相同段间的特征,又考虑了不同段间的特征,但是实验结果却表明,分为四段比分为三段模型准确率要低,这说明引入不同段间的特征反而影响了模型的表现,我们认为这是因为不同段间特征中噪声较多,即无意义的相似特征较多,导致真正能对文本匹配起作用的特征混在噪声中,因而无法起到预期的作用。
第二组实验研究孪生结构对模型的影响,其中,非孪生结构为标准模型,在FewRel 2.0验证集上的结果如表6所示。
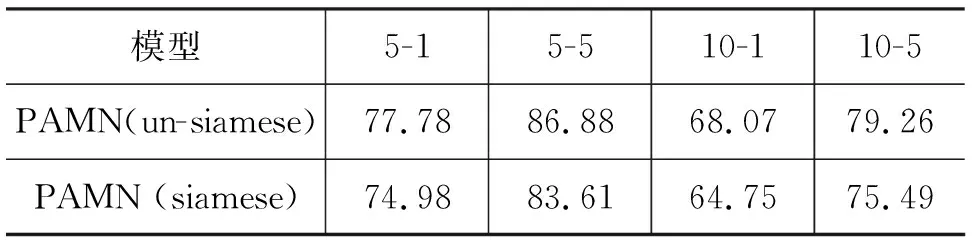
表6 非孪生与孪生结构模型在FewRel 2.0验证集上的准确率 (单位: %)
在孪生结构测试部分,不同模型性能差异非常大,使用非孪生结构时效果较好,而使用孪生结构时效果较差,我们认为使用相同的参数对向量进行映射会导致向量相似度增加,向量的部分特征会被减弱,导致在句子匹配层误差增加,模型性能降低。
5 总结
本文提出了基于分段注意力机制的跨领域少样本关系分类方法PAMN,通过句子相似度计算的方法计算查询实例和支持集合实例间的相似度,具有良好的领域适应性,同时针对关系分类实例使用分段注意力机制进行分段匹配,使得模型可以更准确地计算关系分类实例间的句子相似度,最后针对不同领域间段长分布差异的问题,使用动态段长进行段长领域自适应。PAMN取得了目前FewRel 2.0领域适应测评榜单的最好效果。
猜你喜欢
数学物理学报(2021年4期)2021-08-30 08:28:02
科学与财富(2019年7期)2019-10-21 08:04:22
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
红领巾·探索(2017年8期)2017-08-04 19:09:52
太空探索(2016年9期)2016-07-12 10:00:04
小雪花·成长指南(2015年5期)2015-05-25 17:43:43
中国塑料(2014年1期)2014-10-17 02:46:33
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
中国当代医药(2013年35期)2013-12-10 10:45:48
