
句对齐研究综述
2021-10-12 04:39黄佳跃熊德意
中文信息学报 2021年8期
黄佳跃,熊德意
(苏州大学 计算机科学与技术学院, 江苏 苏州 215006)
0 引言
机器翻译(Machine Translation, MT)是一门研究通过计算机实现人类翻译任务的学科,其在自然语言处理、人工智能领域中占有非常重要的地位。当下,机器翻译任务不仅在学术界得到了广泛的研究,工业界也有许多大型公司如谷歌、微软、百度在机器翻译的产品落地上投入巨资,并取得了鼓舞人心的效果,越来越多的人使用在线机器翻译系统跨越语言障碍进行交流。当前机器翻译领域的主流模型是神经机器翻译(Neural Machine Translation, NMT)模型,与传统的统计机器翻译(Statistical Machine Translation, SMT)模型不同,它基于编码器-解码器框架实现翻译任务,并在双语平行语料充足的多种语言对的翻译任务上性能显著超过了传统的统计机器翻译模型,甚至在“中-英”新闻领域翻译任务上取得了接近人类翻译的水准[1]。
然而,对于某些双语平行语料匮乏的低资源(low-resource)语言对的翻译任务,其翻译质量依旧不敌传统的统计机器翻译模型[2]。由此可见,拥有大量双语平行语料能使神经机器翻译模型在训练的过程中学习到更精确的翻译信息。句对齐任务作为一种获取双语平行语料的研究任务,也因此得到广泛的研究。
双语平行语料不仅在机器翻译模型的训练上扮演着重要角色,在双语词典编纂、术语研究应用、跨语言信息检索等方面也有很强的应用性。在术语应用方面,如果翻译人员发现待翻译的句子中含有不熟悉的术语,针对该术语的翻译可能就成为一个棘手的问题,此时双语平行语料可辅助翻译人员进行术语检索,供翻译人员参考相应术语进行翻译。例如,当一个对物理领域一窍不通的翻译人员要翻译“magnetic fields”这一术语时,由于缺少物理领域方面的专业知识,且考虑到“field”和“area”有相同的释意,在不借助辅助工具的情况下,翻译人员有可能就误认为其与“magnetic areas”表述的意思相同,将其翻译为“磁地区”,显然有失专业水准。而当拥有“中-英”双语平行语料时,翻译人员则从双语平行句对中检索“magnetic fields”一词的惯常翻译,便可准确地对其进行翻译,解决翻译过程中困扰心头的术语翻译问题。
早期的双语平行句对大多来自于国际会议机构,这些国际会议机构往往使用多种语言表述会议新闻内容,获取双语平行语料通常由人工对齐或根据比较规范的会议文档进行简单而高效的句对齐。例如,BAF语料库[3]是由加拿大政府研究实验室的研究人员根据加拿大议会的辩论稿、法庭誊本以及一些联合国报告等进行句子级别的人工对齐得到的“英语-法语”双语平行语料库;Europarl语料库[4]则是根据句子中的关键信息(如数值)以及句子长度信息对欧洲议会议事录(Proceedings of the European Parliament)的双语文本进行句对齐。相应的双语文本(早期共含有11种语言的文本)可通过爬取欧洲议会(European Parliament)网站中的文本得到,通常议会文本格式规范且段落篇幅较短,且双语平行文档间大多数句子依据前后顺序一一对应,根据句长信息即可实现高质量的句对齐。此外,还有各种公开数据集,如OPUS项目[5]免费提供了多领域、多种语言类别的平行语料,大部分平行语料来源于欧盟和其他联合机构的法律和行政文本,也有部分来源于新闻文本以及各种线上网络资源,如电影字幕标题文本、维基百科上保存的各个领域的文本等,该项目也支持用户线上上传相关的双语平行语料,使得该语料库得到不断扩充。随着在词对齐、句对齐任务上的不断进步,双语平行语料的数量也逐渐增加。
本文组织结构为: 第1节简单介绍句对齐任务;第2节介绍句对齐评测标准;第3节介绍句对齐任务的研究进展;第4节介绍句对齐相关任务及相关方法取得的对齐效果;第5节进行未来展望与总结。
1 句对齐任务
句对齐技术是从候选的双语句对中获取两两互为翻译的平行句对的技术。假设源语言端对应的文本的句子集合为S=(s1,s2,…,sn),目标语言端对应的文本的句子集合为T=(t1,t2,…,tm),由两个语言端文本对应的句子集合做笛卡尔乘积即可构成n*m对候选的双语句对。假设源语言端的第i个句子si与目标语言端的第j个句子tj互为翻译,则si与tj构成一对平行句对。句对齐任务的目标即从n*m对候选双语句对中将非平行句对过滤掉,并找出所有互为翻译的平行句对。
句对齐的实现过程意味着需要识别源端和目标端句子的语义并判断语义是否相同,这与机器翻译任务有一定程度的相似之处。用计算机实现智能语义理解具有很高的难度。此外,在句对齐任务中,当源端和目标端单语句数众多时,通过笛卡尔乘积构成的n*m组双语候选句对的数量也将会非常大,句对齐任务因此也需要消耗更多的计算资源与计算时间。假设源端句子数量n和目标端句子数量m都呈现线性增长趋势,则双语候选句对数n*m将会呈现指数型增长趋势。
为了快速、高效地实现句对齐,在实际的句对齐过程中往往会先限定源端和目标端单语语料的数量,将n和m限定在一定数量的范围之内。为了尽可能避免因限定源端、目标端单语语料的数量后造成平行句对的漏配,限定源端和目标端单语语料时还要求限定的单语语料中尽可能多地包含互为翻译的平行句对。因此句对齐过程往往是从双语平行文档或可比语料(comparable corpora)中抽取双语平行句对。
双语平行文档即互为翻译的文档,通俗地讲,就是“用两种不同语言表达同一个意思的文档”。尽管文档整体上表达的是相同语义,但由于不同语言的独特性,表达相同语义的文档间的句子也并非在逻辑顺序上一一对应,源端文档的一个句子可能与目标端的两个或更多个句子对应,也可能会出现倒装、省略等情况。可比语料(comparable corpora)即表述同一个主题的双语文档,虽然可比语料互为翻译的程度不如双语平行文档,但由于都是表述同一个具体的主题,文档间往往也包含不少的互为翻译的信息,如互为翻译的句子、互为翻译的语句片段(单词、词组、专有名词等)。
由于双语平行文档和可比语料之间的天然特性,很恰当地符合了句对齐任务中限定源端和目标端的单语句子数量,且使得限定的范围内尽可能多地包含互为翻译的双语平行句对,因此在句对齐的实际应用中,往往是在双语平行文档或可比语料基础上进行。如早在1991年Gale和Church[6]就提出基于句长信息从双语平行文档中获取双语平行语料。且1998年Resnik[7]就提出根据url链接匹配和HTML网页结构信息从互联网中获取双语平行文档或可比语料。
2 句对齐评测标准
句对齐任务的主要目的是从源端和目标端单语语料中抽取出互为翻译的平行句对。假设m个源端句子和n个目标端句子中含有x对相互平行的句对。通常分以下两种情况进行句对齐评测。
1)x已知
在x已知的情况下,可根据准确率P(Precison)、召回率R(Recall)和F1值来衡量句对齐的效果。其中,P、R、F1值的计算如式(1)~式(3)所示。
其中,TP(True Positive)表示句对齐模型认为是且实际上也是相互平行的句对数;FP(False Positive)表示句对齐模型认为是相互平行但实际上是非平行的句对数;FN(False Negative)表示实际上相互平行但句对齐模型认为是非相互平行的句对。由公式的定义可以看出,P值衡量句对齐模型抽取出的句对中正确的比率,即衡量句对齐模型抽取的准确度;R值衡量句对齐模型抽取出的真正平行的句对数占总平行句对数的比率,即衡量句对齐模型抽取的全面程度。如果仅仅追求准确度(即提高P值),则可通过提高抽取的标准(抽取出的句对数也相应减少),使得抽取出的句对中真正正确的比率显著提高,此时R值会相应地降低;如果仅仅为了追求抽取的全面程度(即提高R值),则可通过降低抽取的标准(抽取的句对数也相应增多),使得真正的平行句对也被大量地抽取出来,此时P值会相应地降低。因此,仅仅考虑P值或R值不足以全面衡量句对齐模型的综合性能。于是有了F1值,从公式定义中可看出,该值综合考虑了P值和R值,是P和R的调和平均数。通过F1值可较好地衡量句对齐模型的综合性能。
2)x未知
在x未知(即源端和目标端单语中双语平行句对的数量未知)的情况下,通常采用间接的方式衡量句对齐模型的性能。如将获取到的平行句对应用到机器翻译模型的训练中,并通过评测机器翻译模型的性能指标间接评测句对齐模型。
机器翻译模型的性能通常由BLEU(Bilingual Evaluation Understudy)[8]指标衡量。BLEU是由IBM在2002年提出的一种基于精确度的相似性度量方法,广泛应用于机器翻译领域的译文自动评测;它的基本观点是越接近人工翻译的译文,其翻译质量越高。具体算法描述如下: 假设待翻译句子为si,候选译文为ti,参考译文集为Ri={ri1,ri2,…,riM},n-grams[9]为n个单词长度的词组集合,令wj表示第j组n-grams,hj(ti)表示wj在候选译文ti中出现的次数,hj(rik)表示wj在参考译文rik中出现的次数,则候选译文和参考译文的重合精度可由式(4)计算得到。
(4)
其中,i表示的是评测集中句子的序号,j表示的是n-grams中单词组的序号,M表示的是参考译文的数量。
除了计算候选译文的n-grams精确度之外,研究者还引入了BP惩罚因子,以此调节候选译文相对于参考译文的完整性和充分性。惩罚因子如式(5)所示。
(5)
其中,lt表示候选译文t的长度,lr表示参考译文r的长度。通过引入惩罚因子,候选译文的最终评测结果如式(6)所示。
(6)
3 句对齐任务的研究进展
本节介绍面向神经机器翻译句对齐任务的相关研究进展。
早期针对句对齐任务的研究往往依赖于句子间简单的特征,如句长信息特征;随着研究的不断深入,句对齐过程中使用到的特征也随之增加,如基于双语词典的双语词对照特征、同源词特征等基于文本内容的特征;随着深度学习在各个领域不断地取得突破,基于神经网络的句对齐方法随之得到广泛的研究,并且取得了很好的句对齐效果。本节将从传统的基于特征工程的句对齐、基于神经网络的监督式句对齐和无监督句对齐三个方面介绍句对齐任务的研究取得的进展。
3.1 基于特征工程的句对齐
基于特征工程的句对齐方法主要是基于“平行与非平行的双语句对之间的特定特征存在着显著差异性”这一思想,从双语句对之间抽取出相应的特征,并依据已有数据的已知特征训练相应的判别模型,使得模型能根据句对的特征判别其是否为平行句对。
3.1.1 基于句长特征的句对齐
早期的句对齐任务通常结合以句子长度为主要特征的特征工程从双语平行文档中进行句对齐。
早在1991年,Gale和Church[6]就基于“句子长度较长的源端句子往往被翻译为较长的目标端句子,较短的源端句子也往往被翻译为较短的目标端句子”这一事实,提出使用基于句子长度特征的概率统计模型从双语平行文档中进行句对齐,该方法最初用于从加拿大议会平行文档中实现句对齐,由于该平行文档内容规范,且文档段落相对简短,仅仅根据句长特征也取得了很好的对齐效果。随后,Simard等人[10]指出Gale 和Church提出的基于句长特征的对齐算法之所以能取得较好的对齐效果,是因为其仅仅解决简单的对齐任务;当对齐任务变得复杂时,如源端或目标端文档存在对某一句的翻译省略且后续句子与原翻译句子的长度特征类似时,很可能由于一处的误匹配导致后续匹配的错误率上升。作者表示使用少量的语言学知识可以有效避免此类错误的产生,并提出使用同源词(cognates)作为该语言学知识来改进句对齐效果,同时提出一种简单高效的同源词自动构建方法。
3.1.2 融入双语词组对照特征的句对齐
句长特征在句对齐任务上起着举足轻重的作用,但仅仅依据句长特征并非总是可靠,特别是对含有较大噪声的双语平行文档进行句对齐时;因此开始出现基于双语词典的句对齐方法。
Wu[11]和Moore[12]开始基于双语词典的词对照特征进行句对齐。与Wu提出的方法不同的是,Moore采用的方法中使用到的双语词典由双语平行语料自动构建得到: 首先使用平行语料训练IBM Model-1模型[13],通过该模型构建出双语词表。Varga等人[14]提出的“Hunalign”句对齐算法则在Moore方法的基础上,为含有足够高比例的相同数字字符的双语句对附加一个奖励项分值,使得平行得分更高,研究表明该方法针对法律平行文档进行句对齐时效果尤为明显。Munteanu[15]则结合已有的平行语料自动构建双语词表,并根据已有双语平行句对的长度、长度比、长度差及基于双语词表的词重叠率等特征训练最大化交叉熵分类器,使用该分类器判断一组双语句对是否平行。
与此前基于双语词典的句对齐方法不同的是,Ma[16]提出的“Champollion”方法为不同的双语对照词组动态赋予不同的权重。该方法基于这样的一个事实: 文档中出现越频繁的双语词组在双语句对平行与否的判别中的重要性相对较低;而出现频率低的双语词组的重要性则更高,因此提出基于TF-IDF算法为文档中出现频率低的双语词组赋予更高的权重,并使用动态规划算法允许存在“1-0”“1-1”“1-2”“2-1”“2-2”“3-1”“1-3”“4-1”“1-4”多种对齐类型(其中“n-m”表示源端的连续n个片段与目标端的连续m个片段组成双语平行句对)。随后,Li等人[17]表示Champollion方法使用动态规划算法的时间复杂度为O(n2),当源端和目标端文档增大时,会严重影响对齐效率,并采取特定方式将待对齐的平行文档切分成多组小的平行片段再进行对齐,提高总体的对齐效率。
3.1.3 结合扩充双语词表的句对齐
先前使用的固定双语词表很难覆盖双语中的所有词对照特征,于是开始有研究者利用词性对照特征或结合机器翻译模型或其他技巧对原有双语词典的词对照特征进行扩充实现句对齐。
Adafre和Rijke[18]提出基于双语词表或机器翻译模型的方法从维基百科语料库中抽取平行语料(VIC方法)。值得注意的是,基于双语词表的方法中使用的双语词表是根据维基百科页面上特定名词对应的超文本链接结构推导而得到的;维基百科网页文档包是一种超文本文档,文档中的特定的词条(名词实体、专有名词等)含有相应的超链接,指向对该词条进行解释说明的页面;不同语言版本的相同网页描述也包含着超链接,对应的超链接页面也有相应的词条描述超链接,根据这些超链接的结构特征,即可推导出相应词条的不同语言表述,从而获取词条的双语对照信息;通过该方式获得的双语词表大多都是人名或实体名称,在进行双语文本对照时拥有更显著的优势。 基于机器翻译模型的方法则使用在线免费的机器翻译模型。两种方法都是将源端句子翻译为目标端句子,计算杰卡德相似系数(Jaccard similarity coefficient)以衡量双语句对的相似性。 随后,Mohammadi等人[19]使用与Adafre和Rijke相同的方法并在该方法的基础上增加双语文本之间的长度相关特征作为约束条件对原先的句对齐结果进行过滤,并取得更好的效果。
前人提出的句对齐工具基本都针对不同的平行文档或可比语料进行句对齐,对齐效果各异。Sennrich[20]指出,先前的工具都难以在难对齐(噪声大)的平行文档中取得较好的对齐效果,并提出一个基于机器翻译和BLEU值评价指标的对齐方法(Bleualign),将源端句子翻译成伪目标端句子并计算与候选目标端句子的BLEU值,将该值作为相似度得分,进而判断其是否平行。该方法严重依赖于翻译模型的翻译质量,当缺少翻译质量良好的翻译模型时,该对齐方式可能还不如Gale和Church[6]提出的基于句长特征的对齐算法。Rauf等人[21]则先采用基于句长特征的对齐方法获取得到平行语料,再使用得到的平行语料训练出统计机器翻译模型(SMT),接着使用Bleualign对齐方法进行句对齐。与Bleualign方法相比,该方法不需要预先拥有一个翻译模型,但同样有其缺点: 当错误对齐的句子应用到SMT的训练中时,可能会导致错误的对齐信息传递到后续的对齐步骤中。
Kutuzov[22]提出采用基于词性标注(Part-Of-Speech tagging,POS-tagging,即名词、动词、形容词、代词等)的对齐方法改善Varga等人[14]提出的Hunalign方法的对齐效果。该方法基于这样的事实: 互为翻译的平行句对中相应的POS及其对应的顺序有某种程度上的相似之处。具体地,该方法首先用Hunalign方法得到初始对齐结果;接着对初始对齐的双语句对进行词性标注,用不同的字符标签表示不同的词性标注结果,将双语句对转换为一个由词性标注结果组成的字符串,最后计算两个字符串的编辑距离以衡量字符串间的相似度。实验结果表明该方法取得一定的效果,但也会出现一些误判。
Etchegoyhen和Azpeitia[23]提出基于扩充的双语词组对照特征并采用杰卡德相似系数(Jaccard similarity coefficient)衡量双语句对的相似性的句对齐方法(STACC)。该方法首先使用GIZA++ 工具[24]和IBM model-1模型[13]从已有的少数平行语料中获取双语词表,并采用字符串最长公共前缀匹配算法(LPC,longest common prefix matching)将源端和目标端中含有n个相同字符前缀的单词扩充到原有双语词表中,同时,将经过预处理(tokenize、truecase)后的平行语料中两端字母大写的单词依然不存在双语词表中的词组及相同的数值类型单词(如时间类型数值)加入词表中使得词表得到扩充。随后Azpeitia等人[25]在该方法的基础上做出改进: 结合词频为扩充的词表中的每一对词组赋予一个范围为0到1的权重,进一步改进句对齐结果。
3.2 基于神经网络的监督式句对齐
基于特征工程的句对齐方法的特征提取过程往往相对繁琐且不能保证提取到的特征足够准确、全面。如双语词组对照特征往往不能准确、全面地覆盖所有词的一词多义特性,且该特征通常不能考虑句子中的词序特征。不同于基于特征工程的方式,基于神经网络的句对齐方式由神经网络的训练过程自动地对相应的特征进行提取,尽可能地避免繁琐的特征工程。
3.2.1 基于词向量拼接的句子向量化表征
Bouamor和Sajjad[26]提出使用句子向量化表征结合机器翻译或者分类器模型进行句对齐(“H2”方法): 首先,使用multivec(1)https://github.com/eske/multivec开源工具结合已有双语平行语料训练得到源端和目标端的双语词向量,使得互为翻译单词的词向量的余弦相似度比较接近。源端和目标端的句向量则由相应的词向量累加求平均得到;得到句子向量化表征后,通过余弦相似度获取与源端最相似的top-N个目标端候选句子,其余的则过滤掉。接着,使用神经机器翻译模型将源端句子翻译为目标端句子,并将翻译结果与候选的目标端句子进行配对并计算其BLEU值,将BLEU值得分最高且不低于50的句对视为平行句对。
3.2.2 基于神经机器翻译模型的句子向量化表征
以上方法虽然得到了双语句向量,但句向量的构建过程比较粗糙,在句对齐任务中也仅仅是作为过滤器使用。Schwenk和Douze[27]提出基于神经机器翻译架构的多语句子向量化表征模型。机器翻译模型的训练依赖于平行语料,通常针对源端句子编码形成句向量。为得到多语句向量,作者使用UN语料库[28]中6个语言间都相互平行的语料(6-way parallel corpora, fr-en-es-ru-ar-zh),训练一个mini-batch时,将一个源端(如en)句子作为输入进行编码,并尝试将其解码为多个语言的目标端(fr、es、ru)句子;一个mini-batch训练完成后,将原来的源端(en)句子替换为其他语言(如fr)所属句子,并尝试将其解码为其他多个语言目标端(en、es、ru),通过该训练过程得到的编码器能对多种语言进行编码,将不同语言间的句子映射到同一向量空间上,且语义比较接近的句子对应的句向量的距离也比较接近,如图1所示(此处以4种语言对进行说明)。

图1 多语句向量训练语料匹配示例
句表征模型使用3层堆叠的Bi-LSTM神经网络作为模型的编码器和解码器,其中编码器对句子编码时得到的最后一个隐层向量经过max-pooling得到的向量为句向量。
结合以上的多语句子向量化表征模型,以及Johnson等人[29]提出的谷歌多语言神经机器翻译系统的训练过程,Schwenk[30]进一步提出多语句向量表征模型(“MultiSentEmbed”方法)。与Schwenk和Douze[27]不同的是,每个mini-batch训练完成后不要求交换不同语言对,而是对所有源端语料采用同一个编码器进行编码。谷歌多语言神经机器翻译系统训练时也采用同一个编码器对不同语言对应的语料进行训练,并在平行语料的源端语句前面附上目标端语言标签,使得训练时能区分不同语言;而该模型在训练过程中不需要对训练语料标记相应的语言标签,因此,编码器对不同语言的语句进行编码时,并不能识别其所属语言,使得编码器将所有语言的语句都编码到同一向量空间上。在BUCC-2018句对齐任务中,该方法虽然未取得最优的对齐效果,但该方法不依赖于繁琐的特征工程或相关分类器的训练,且训练出的模型可应用于多个语言的对齐任务,而针对每一组语言对,需要训练一个相应的对齐模型。
随后Artetxe和Schwenk[31]进一步提出一个多语句子向量化表征模型(“Margin-based”方法),模型架构如图2所示,该模型的编码器端类似于Schwenk[30]中采用的编码器,同样将最后一层的隐藏层向量经过max-pooling处理后的结果作为句向量,不同之处在于该模型用编码器的句向量对解码器的第一个隐藏层状态进行初始化,同时编码器的句向量也与目标端的词向量和一个代表不同目标端语言的向量进行拼接,使得尽管采用同一个解码器也能对不同语言的目标端进行解码。使用多组不同语言的平行语料交替地训练出一个句表征模型,模型训练完成后,不同语言的句子经过编码器编码后形成在同一向量空间表示的句向量。通过向量间的余弦相似度结合一个固定阈值即可区分不同语言的句子间语义是否相同。在实际应用中作者发现,采用余弦相似度结合一个固定阈值的句对齐方法会产生相似度得分范围不一致(scale inconsistency)问题,即不同平行句对的余弦相似度得分可能不在同一个分值范围内,且余弦相似度得分最高的也不一定就是互为翻译的句对。因此,作者根据该相似度衡量方式在实际应用中出现的相似度得分范围不一致(scale inconsistency)问题,进一步提出基于近邻的相似度得分衡量方法(margin-based scoring),如式(7)所示。

图2 多语句向量表征模型
score(x,y)=
(7)
其中,NNk(x)表示源端句向量x的所有k近邻目标端句向量。在BUCC-2018句对齐任务中,相比于先前的其他方法,该方法在4组语言对的句对齐任务上的F1值都达到了90%以上。Artetxe和Schwenk[32]使用该模型在多组语言对的平行语料上训练得到一个多语句子向量化表征模型,使得多种语言对应的句子可被映射到同一向量空间上;并将训练得到的多语句表征模型LASER(2)https://github.com/facebookresearch/LASER开源,供公开使用。训练过程中使用的多组语言对囊括了93种语言、30多个不同的语系,使得训练得到的模型可用于包括低资源语言对在内的句对齐任务上,并通过实验表明,该模型可进一步提升BUCC-2018的三种语言对的句对齐任务上的对齐效果。Schwenk等人[33]使用该模型从维基百科语料库的85种语言对应的文档中获取包含低资源语言对的多种语言对的双语平行语料,总共获取包含1 620组语言对的平行语料;平行语料数量总共有1.35亿句对,其中仅有3 400万句对中的一个语言端为英文,且最少的语言对的平行语料数也超过一万句对,并使用得到的包含45种语言的平行语料训练神经机器翻译模型,在TED语料集[34]上进行验证,表明通过该方式获取的平行语料能训练出一定翻译性能的机器翻译模型。
3.2.3 基于双编码器的句子向量化表征
不同于基于机器翻译模型的端到端模型架构,Gr’egoire和Langlais[35]提出使用基于神经网络的句子向量化表征实现句对齐(“RALI”方法): 使用基于门控机制的双向循环神经网络(Bi-GRU)将源端和目标端句子都编码为指定维度的句向量,使用得到的句向量训练句对齐概率模型,当模型的输出概率值超过指定阈值时则认为该句对相互平行。通过该方法在BUCC-2017句对齐数据集上取得了一定的对齐效果。
Guo等人[36]使用双编码器模型对源端和目标端句子进行编码、获取双语句子向量化表征,编码器的模型架构使用Iyyer等人[37]提出的深度平均网络(Deep Averaging Networks,DAN),并将句子中的所有词向量和bigram词组向量的均值作为DAN的输入;源端和目标端句子经过编码器后得到的句向量做点乘(dot-product)得到一个分值∅(x,y),并通过最大化以下训练目标函数对该模型进行训练,如式(8)所示。
(8)
其中,xi和yi表示一对平行句对组成的源端和目标端句向量;假设一个batch组成的N对平行句对的源端和目标端句向量矩阵分别为U和V,则通过U和VT的矩阵乘积得到的N×N矩阵结果的对角线的值即为平行句对的点乘结果∅(xi,yi),而非对角线上的值则为非平行句对的点乘结果。训练过程中作者引入一些存在一定程度的语义相似但并非互为翻译的双语句对,这种特殊的双语句对被称做硬负样例(hard negatives),使得训练得到的模型能更准确地辨别语义相似的句对是否为真正的平行句对;使用训练得到的模型对UN平行语料[28]进行重构,在en-fr和en-es语言对上的实验分别取得48.9%和54.9%的准确率。
Yang等人[38]同样使用双编码器模型进行句对齐,不同的是作者采用的编码器基于Transformer编码器模型架构,训练目标是最大化P(yi|xi)+P(xi|yi),即双向最大化对齐概率;并对原有源端和目标端句向量点乘∅(x,y)做适当修改,修改为∅′(x,y),如式(9)所示。
(9)
通过以上方式对训练得到的模型在UN平行语料的重构任务上,均取得了86%以上的准确率,大大改善原先的双编码器模型的句对齐效果。在BUCC-2017句对齐数据集上,通过训练得到的模型并结合cosine相似度衡量指标在4组语言对上取得的F1值均达到86%以上。在以上的基础上作者提出一个与Artetxe和Schwenk[31]提出的近邻相似度评分方法类似的句向量间相似度衡量方法,如式(10)、式(11)所示。
结合该句向量相似度评分机制,该模型在BUCC-2017句对齐数据集上取得了与Artetxe和Schwenk[31]相近的句对齐效果。作者进一步训练一个基于微调过的多语BERT模型[39]的重评分分类器,将该分类器应用到平行句对的筛选中,并在BUCC-2017句对齐数据集上取得当前最优的句对齐效果(本文称该方法为“Score-BERT”方法)。
3.3 无监督句对齐研究进展
尽管当前基于神经网络的监督式句对齐方法取得了很好的对齐效果,但该方法仍依赖于已有的双语平行语料,对于低资源领域,往往由于双语平行语料的欠缺使得相应的下游任务无法取得有效的进展。无监督句对齐是一种不依赖于已有双语平行语料实现句对齐、获取双语平行句对的技术,对于改善低资源领域的相关应用有着至关重要的作用,因此也得到了相应的研究。
随着基于词向量的无监督词对齐技术[40]取得不错的进展,Hangya和Braune[41]提出采用无监督方式(“Unsup”方法)在BUCC-2017的“fr-en”“ru-en”“de-en”句对齐任务上进行句对齐。首先,使用大量fr、ru、de、en单语语料训练出所属语言的单语词向量,再通过无监督词对齐技术对fr和en单语词向量进行对齐(针对ru-en和de-en采取同样方式),使得两个语言端的单语词向量被映射到同一向量空间,且语义相近的单词的向量比较接近。得到双语词向量之后,句子也由相应的词向量进行同等维度上的累加求平均得到,源端和目标端句子因此也被映射到同一向量空间,通过向量间的距离即可判断双语句对是否平行。为了避免句向量构建过程中对语义不相关的单词赋予太高的权重,在依据词向量构建句向量的过程中,去除了句子中的停用词、数值和标点符号。为了确定源端和与其相似度得分最高的目标端是否平行,提出一个动态阈值设定方法,其确定方式如式(12)所示。

(12)
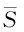
4 句对齐相关任务
为了进一步推动句对齐任务研究的发展,Zweigenbaum等人[42]根据Wikipedia和News Commentary(3)http://www.casmacat.eu/corpus/news-commentary.html数据集构建出了BUCC-2017句对齐数据集,该数据集主要用于对不同句对齐模型的性能评测。
4.1 BUCC句对齐任务数据集
BUCC(Building and Using Comparable Corpora)共享任务(BUCC Shared Task)旨在构建和使用可比语料。第一届BUCC共享任务[43]主要是针对跨语言可比语料的获取。第二届BUCC共享任务则主要针对从跨语言可比语料中获取平行句对;由于先前的从可比语料中获取平行句对的方法通常依赖于语料的特定特征,如从互联网中获取“中文-日文”新闻领域可比语料和平行句对时采用的日期特征[44]、从维基百科中获取平行语料时采用的网页文本的超链接特征、文档标题特征[18]等。前人提出的句对齐模型在特定语料中获取平行句对时采用的特征并不都是广泛存在于所有的可比语料中的,相应的句对齐模型应用到不同语料的对齐任务时对齐效果也有所差异。句对齐任务的目的是识别出不同语言间语义相同的平行句对,应该关注基于文本内容的特征,而不是文本以外的其他特征。因此Zweigenbaum等人[42]针对BUCC-2017的共享任务构建了从可比语料中获取平行句对的数据集(“BUCC-2017句对齐数据集”),用来衡量不采用文本内容以外的其他特征的句对齐模型的对齐性能。
BUCC-2017句对齐数据集是由维基百科上不同语言相同主题的单语语料文本和News Commentary①双语平行语料构建而成的,主要是将维基百科单语文本语料进行分句、去除相应的文本标签后,有选择性地将News Commentary双语平行语料的语句插入到单语语料中,并记录插入的位置信息,详细的数据集构建过程可参阅文献[42]。该数据集总共包含四组语言对的对齐任务: 法语-英语(fr-en)、德语-英语(de-en)、俄罗斯语-英语(ru-en)、中文-英语(zh-en),每组语言对包含三个类型的数据集: 样例集(sample)、训练集(training)、测试集(test),每一类数据集下包含三个文件,例如,“fr-en”对应的sample数据集包含存放fr的单语文件、存放en的单语文件和存放两个单语文件中包含的平行句对的文件(gold文件);其中,单语文件的每一行由一个单语句子以及该句子对应的编号组成,gold文件的每一行存放一个源端单语句子的编号和目标端单语句子的编号,表示对应编号的源端句子和目标端句子互为翻译。数据集统计信息如表1所示。
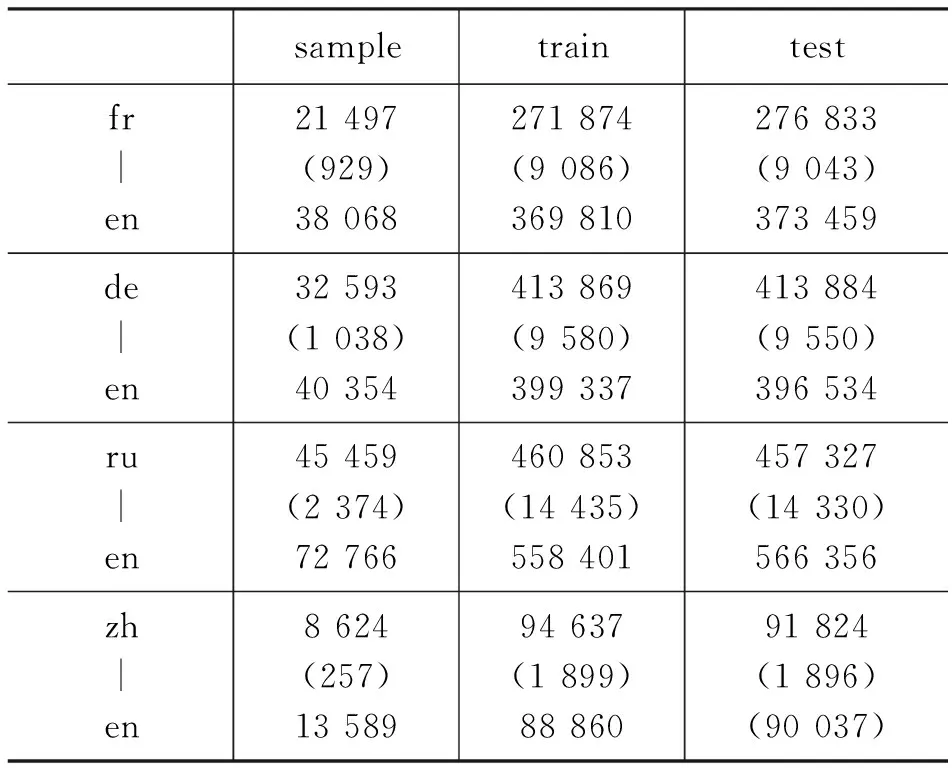
表1 BUCC-2017句对齐数据集统计信息
4.2 句对齐系统结果描述
由于先前的句对齐任务大多都在不同的语料(不同的双语平行文档/双语可比语料)上进行双语句对获取,语料所含噪声不一致、句对齐任务难易程度不一,往往某个句对齐模型在特定的语料中效果显著,而应用于其他句对齐语料时则显得效果一般。此处主要介绍在BUCC-2017句对齐数据集上的句对齐模型。
共有四个团队在BUCC-2017句对齐共享任务上提交13组句对齐模型,主要针对“fr-en”“de-en”“zh-en”句对齐任务进行对齐,在“ru-en”句对齐任务上暂且没有相关对齐系统提交。四个团队提交的系统中对齐结果汇总如表2所示。

表2 不同方法在不同数据集上的句对齐结果
• RALI方法
该方法主要依赖于深度神经网络,详细介绍见3.2.3节。该方法在BUCC-2017的“fr-en”句对齐任务上取得的P、R、F1值分别为12、63、20。
• JUNLP方法[45]
该方法主要基于Moses[46]统计机器翻译模型,在“fr-en”句对齐任务上进行对齐,取得的P、R、F1值分别为3、11、4。
• zNLP方法[47]
该方法针对BUCC-2017的“zh-en”句对齐任务,主要是采用双语词典将中文端单语语句翻译为英文端,再使用Solr(4)http://lucene.apache.org/solr/搜索引擎将英语译文作为关键词从英文候选句子中筛选出候选翻译,最后以Solr搜索引擎搜索得分、词重叠率、句长信息为特征训练一个支持向量机(SVM)分类器模型,对候选句对进行分类,判别是否属于平行句对。采用该方法取得的P、R、F1值分别为42、44、43。
• VIC方法
该方法主要基于自动训练得到的双语词表和杰卡德相似性得分,具体实现介绍见3.1.3节。在BUCC-2017的“fr-en”句对齐任务上取得的P、R、F1值分别为80、79、79,在“de-en”句对齐任务上的相应分值分别为88、80、84。
此后,BUCC-2018共享任务依旧是从可比语料中获取平行句对,其使用的数据集仍为BUCC-2017句对齐数据集。其中“H2”方法(方法详情介绍见3.2.1节)在“fr-en”句对齐数据集上取得的P、R、F1值分别为82、72、76。Azpeitia等人[48]在VIC方法的杰卡德相似得分基础上,针对命名实体错误匹配给定一个惩罚分值(“VIC_enhanced”方法),进一步提升对齐的准确率。Schwenk[30]提出的“MultiSentEmbed”方法(详情见3.2.2节介绍)在BUCC-2017句对齐任务上也取得了显著的效果: 该方法相比于“VIC_enhanced”方法,虽然未取得最优的对齐效果,但该方法不依赖于繁琐的特征工程或相关分类器的训练,且训练出的模型可应用于多个语言的对齐任务,而其他对齐方法针对每一组语言对需要训练一个相应的对齐模型。Artetxe和Schwenk[31]提出的“Margin-based”方法(详情见3.2.2节介绍)极大地改善BUCC-2017句对齐数据集上的句对齐效果;Yang等人[38]提出的基于微调的多语BERT模型的“Score-BERT”方法(详情见3.2.3节介绍)则在该数据集上取得当前最佳的句对齐效果。相关方法及其句对齐F1结果汇总如表3所示。
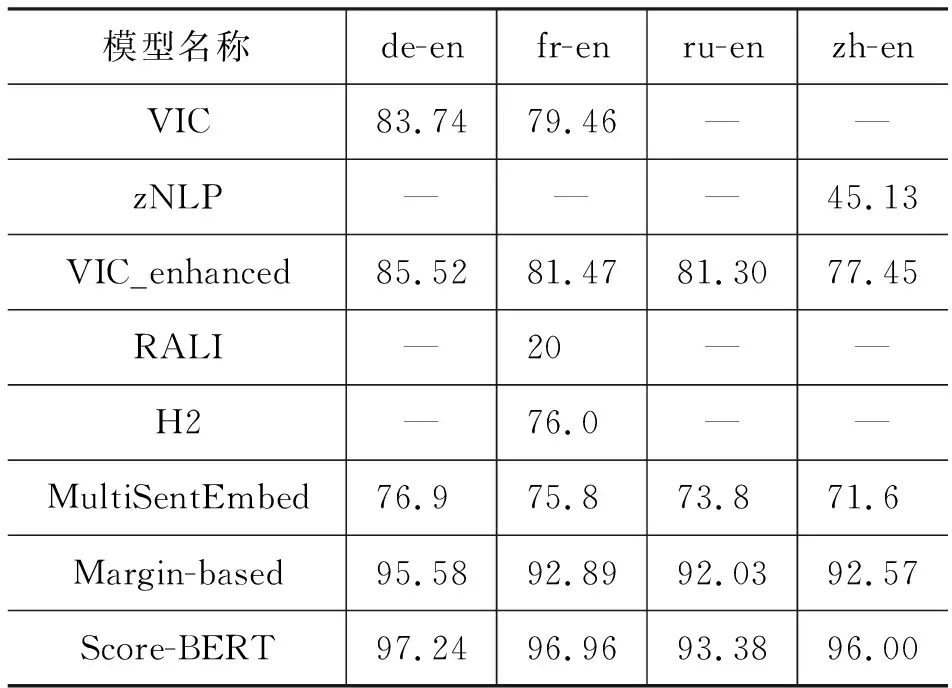
表3 不同句对齐模型在不同数据集上的F1值 (单位: %)
其中,VIC、VIC_enhanced和zNLP方法主要基于特征工程;RALI和H2方法基于深度学习获取得到句向量,得到的句向量用于分类器的训练或句过滤过程中;MultiSentEmbed和Margin-based方法则直接将多语间句子向量化表征,结合句向量的相似性衡量方法,直接得到对齐结果。
此外,无监督句对齐方法“Unsup”在BUCC-2017句对齐任务中取得的对齐效果见表4。
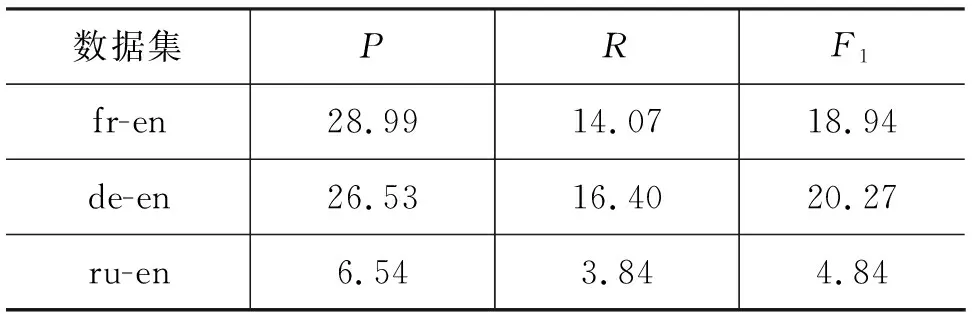
表4 无监督方法“Unsup”在不同数据集上的对齐结果 (单位: %)
5 总结与未来展望
从不同句对齐模型的对齐结果来看,在BUCC-2017句对齐数据集上实现句对齐任务有一定的难度。先是基于特征工程的句对齐方法取得了最佳的对齐效果,接着开始出现基于神经网络的句对齐方法。起初的对齐效果不如基于特征工程的方法,随着基于神经网络的句对齐方法的不断改进,句对齐任务也取得了很大突破;当前,与基于特征工程的句对齐方法相比,基于神经网络的句对齐方法取得了更好的句对齐效果。而无监督方法由于不依赖已有的双语句对,对齐效果相对较差。
尽管基于神经网络的句对齐方法已经取得了很好的对齐效果,但仍有改进的空间;同时,由于其依赖大量已有平行语料,往往也难以应用到低资源领域的对齐任务中;对于不依赖于平行语料的无监督方法,由于当前对齐效果差,也难以在低资源领域进行有效的句对齐。因此,如何针对低资源领域实现有效的句对齐有待进一步研究。
基于神经网络的句对齐方法往往借鉴于神经机器翻译模型,当前基于神经网络的句对齐方法借鉴基于RNN的神经机器翻译架构,如何借鉴当前主流的完全基于注意力机制的神经机器翻译模型实现句对齐任务,是我们下一步的研究方向。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
小哥白尼(神奇星球)(2021年4期)2021-07-22
新世纪智能(语文备考)(2020年4期)2020-07-25
海外华文教育(2016年1期)2017-01-20
汽车观察(2016年3期)2016-02-28
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
语文知识(2014年4期)2014-02-28
