
云际协作环境下能耗与成本感知的工作流调度方法
2021-10-11 13:37文一凭王志斌刘建勋许小龙康国胜
计算机集成制造系统 2021年9期
文一凭 , 王志斌 , 刘建勋 , 许小龙 , 康国胜
(1.湖南科技大学 知识处理与网络化制造湖南省普通高校重点实验室, 湖南 湘潭 411201;2.南京信息工程大学 计算机与软件学院, 江苏 南京 210044)
0 引言
随着云计算技术的深入发展与大数据时代的到来,云计算逐渐成为一种新的社会基础设施。亚马逊、微软、阿里云、谷歌、华为、腾讯、百度等知名企业纷纷推出了各自的云服务产品。但是,单个云提供者 (cloud vendor)拥有的计算与存储资源总是有限的。即使是阿里云这样的龙头企业,每年“双十一”也要减少对外的资源供给,将一些与网购无关的云服务消费者(cloud service consumer)暂时迁移到其他云上[1]。如果云提供者根据其突发峰值业务需求配置资源,将带来巨大的资源效费比问题:资源利用率低而成本显著增加。而云提供者之间的协作不仅有助于应对突发峰值业务需求,还可规避用户依托单一云提供者带来的平台锁定等问题。因此,使用多方的云资源,近年来成为了云服务消费者的主流选择[2-3]。而且,随着云业务与云资源需求的不断扩大,云服务提供者之间的开放协作成为必然,新一代云计算将是围绕云际协作的云计算,学术界和工业界也已针对云际协作环境的构建等问题开展了大量研究[1-2]。
云工作流调度是映射并管理一组相互依赖的任务在云资源中执行的过程。在云际协作环境中,不同云服务提供者部署的云数据中心、提供的虚拟机种类及收费方式都不相同,可更好地满足一些复杂工作流(例如,医疗应用领域中的DNA测序工作流[4])对云资源的需求,并可为用户按需、高效、低成本地获取云资源提供更好的解决方案。另一方面,从云服务提供者的角度看,通过协作管理所共享的资源,将任务分配到不同的数据中心,即有可能更好地提升云数据中心的资源利用率,从整体上实现所有云数据中心的节能减排。但是,现有云工作流调度研究却并未考虑在云际协作环境中,如何在为用户节约云资源租赁成本的同时,降低或节约工作流执行能耗。而该问题是源于实践、符合云计算实际应用需求的新问题,且与传统云计算环境中的工作流调度相比,具有更大的挑战性。
针对该问题,本文在现有云工作流调度研究的基础上,提出一种云际协作环境下能耗与成本感知的工作流调度方法。该方法可在满足工作流截止时间约束的前提下,优化多个工作流的执行费用与能耗。
1 相关研究
任务调度一直是云计算领域的研究热点,而成本是其中的重要考虑因素之一,文献[5]对此进行了综述。近年来,随着云基础设施规模的持续扩张,云数据中心的能耗不断增长,如何实现云计算环境中任务的节能调度,成为学术界和产业界共同关注的重要问题[6]。在此背景下,提出了许多以降低或节约能耗为目标的云工作流调度方法。目前,这些方法主要利用关闭/休眠、动态电压调整(Dynamic Voltage Scaling,DVS)和虚拟化(virtualization)等技术实现任务执行时的节能。
基于DVS的云工作流节能调度方法主要根据互补金属氧化物半导体(Complementary Metal Oxide Semiconductor,CMOS)电路动态功率公式及任务截止时间等约束,通过降低或动态调整处理器的电压以实现节能。例如,文献[7]基于多目标离散微粒群优化与DVS技术设计了一种可最小化完成时间、成本和能耗的多目标云工作流调度方法。文献[8]则结合DVS与虚拟化技术,给出一种计算工作流执行能耗的新方式,并提出了一种云工作流节能调度方法。
但是,DVS技术在应用时存在仅能降低处理器能耗等局限性[9]。因此,近年来,基于关闭/休眠或虚拟机迁移技术设计云工作流节能调度方法成为主流。文献[10]从科学工作流应用在云环境中执行的角度,提出一种能耗感知的资源分配方法,可在任务执行过程中利用虚拟机实时迁移技术对虚拟机进行动态调度,从而实现科学工作流在动态执行过程中的高能效目标。文献[11]考虑了工作流在执行时的截止时间约束,提出一种成本与能耗感知的科学工作流调度算法。该方法根据成本效用的概念,通过虚拟机选择、序列任务合并、并行任务合并、空闲虚拟机重用等策略来降低工作流执行成本与能耗。笔者的前期工作[12]则通过引入物理机资源利用率预测等策略,提出一种能耗与成本感知的实例密集型工作流调度算法。但是,这些方法主要适用于由一个云提供者管理或者单个云数据中心构成的传统云计算环境。
与传统云计算环境相比,云际协作环境中的工作流调度更具挑战性,现有研究成果也相对较少。在云际协作研究方面,《中国计算机学会通讯》以“云际计算:面向云际协作的云计算”为专题介绍了云际计算研究情况[1],文献[2]提出了云际协作环境的体系结构模型。在相关云工作流调度研究方面,文献[13]最早考虑了异构多云计算环境的特点,提出了两种动态资源分配算法以执行可抢占式任务并提升云资源利用率。文献[14]考虑了多个不同类型工作流应用在异构多云计算环境中的调度问题,并以最小化完成时间与最大化云资源利用率为目标,提出了3种调度方法。在此基础上,文献[15]进一步利用归一化技术对这些方法进行了改进,但是,这些算法均未考虑执行任务所需要的成本问题。对此,文献[16]以最小化科学工作流在多云环境中的执行成本为目标,利用离散微粒群优化等技术优化计算成本与数据跨云传输成本,提出一种截止时间约束下基于元启发式策略的科学工作流调度方法。文献[17]则进一步综合考虑了多云环境下工作流调度的可靠性约束等因素,以最小化完成时间与执行成本为目标,提出一种基于微粒群优化的多目标科学工作流调度方法。但是,这些方法均未考虑如何降低工作流执行过程中的能耗,而如何实现兼顾成本与能耗的云工作流调度是云际协作应用中的重要问题。为此,本文在上述研究的基础上,进一步提出一种云际协作环境下能耗与成本感知的工作流调度方法。
2 问题描述
2.1 系统模型
定义1一组工作流应用。一组工作流应用可描述为WS={W1,W2,…,Wi,…,WI}为工作流应用集合。Wi为第i个工作流应用,可以描述为Wi=(Ti, CEi,DEi,Di),其中:
(1)Ti是一组工作流任务的集合,Ti={tij|tij=〈Iij,Wij,Oij,〉},Iij、Oij分别为任务tij的输入与输出数据集,Wij描述了任务tij的计算量大小。
(2)CEi为一组有向边的集合,用以描述工作流任务间的控制流依赖情况,CEi={〈tia,tib〉|〈tia,tib〉∈Ti×Ti};若〈tia,tib〉∈CEi,则称tia为tib的前驱任务,称tib为tia的后继任务,任务tia的前驱任务集合可以表示为pre(tia),它的后继任务集合可以表示为succ(tia);没有前驱任务的工作流任务被称为开始任务,它可以表示为ti, entry。没有后继任务的工作流任务被称为结束任务,它可以表示为ti, exit。
(3)DEi为工作流任务间的传递数据的集合,它可以表示为DEi={dei,ab|〈tia,tib〉∈CEi},其中dei,ab为任务tia向tib传递的数据量大小。
(4)Di为工作流的截止时间。
定义2云服务提供者。一组云服务提供者可描述为PRO={pro1,pro2,…,prom,…,proM}。
定义3云数据中心。云服务提供者prom(1≤m≤M)所提供的云数据中心可表示为DCm={dcm,n|1≤n≤N},其中dcm,n表示云服务提供者prom的第n个数据中心。
定义4物理机资源。云数据中心dcm,n所提供的物理机资源可表示为PMm,n={pmm,n,p|cpm,n,p,ωm,n,p,1≤p≤P},其中pmm,n,p表示云数据中心dcm,n的第p台物理机,cpm,n,p表示物理机pmm,n,p的计算能力,ωm,n,p为物理机pm,n,p的运行时间。
定义5虚拟机资源。云服务提供者prom可提供不同租赁价格与配置的虚拟机类型,可表示为VMm={vmm,k|vmm,k=〈vcpm,k,ctm,k,cm,k〉, 1≤k≤K},其中vmm,k表示云服务提供者prom提供的第k类虚拟机资源,vcpm,k表示vmm,k的计算能力,ctm,k表示vmm,k的计价时间单位,cm,k表示vmm,k单位时间内的收费。
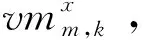
2.2 能耗计算模型
工作流执行过程中的总能耗E可表示为物理机能耗Eexe与传输能耗Etra两部分:
E=Eexe+Etra
(1)
基于笔者的前期工作[12],物理机pmm,n,p产生的能耗Em,n,p可按式(2)和式(3)进行计算:
(2)
(3)
其中:PEm,n,p(t)为物理机pmm,n,p在时间t的能耗率;usm,n,p表示物理机pmm,n,p在t时刻的CPU利用率;bem,n,p表示物理机pmm,n,p的基础能耗;αm,n,p是一个常数,αm,n,p=bem,n,p/7。
在传输能耗的计算方面,为简化问题,本文不考虑同一物理机中虚拟机之间数据通信所产生的能耗。同一数据中心内不同物理机之间数据通信所产生的能耗CEsd,不同的数据中心间数据通信所产生的能耗CEdd可分别按式(4)和式(5)进行计算:
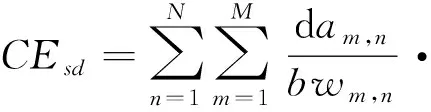
(4)
(5)
其中:dam,n、bwm,n和ϑm,n分别表示数据中心dcm,n中物理机之间的数据通信量、通信带宽及数据传输能耗率;DAmn,m′n′、BWmn,m′n′和ηmn,m′n′分别表示数据中心dcm,n与数据中心dcm′,n′之间的数据通信量、通信带宽及数据传输能耗率。
综上所述,工作流执行过程中所耗费的物理机能耗Eexe与传输能耗Etra可表示为:
(6)
Etra=CEsd+CEdd。
(7)
2.3 工作流完成时间计算模型
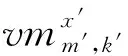
(8)
(9)
(10)
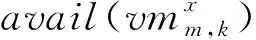
因此,工作流Wi的完成时间可通过式(9)计算其结束任务ti,exit的完成时间获得。
2.4 云资源使用成本模型
用户执行工作流的成本主要包括虚拟机的租赁成本costrent与数据传输成本costtrans,可表示为:
cost=costrent+costtrans。
(11)
按照云服务提供者的定价方式,虚拟机的租赁成本可以表示为:
(12)
(13)
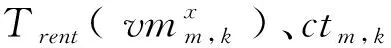
执行工作流所需数据传输成本costtrans可以表示为:
(14)
(15)
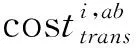
3 能耗与成本感知的云工作流调度算法
3.1 算法介绍
在云际协作环境中,将工作流在不同云中执行有助于应对突发峰值业务需求,并可兼顾云资源租赁成本与能耗,但需要满足工作流截止时间约束。为此,本文提出一种云际协作环境下能耗与成本感知的工作流调度方法(Energy and COst aware workflow scheduling in joint cloud cooperation environment, ECO)。该算法的基本思想是根据截止时间约束,将工作流任务分组后再分配资源,以减少能耗与成本。其中,关键路径与任务组是该算法的重要概念,具体定义如下:
定义7工作流路径。工作流路径是工作流中一个连通的子图。给定一个工作流Wi, 其工作流路径集合可描述为SPwi={spi,j|spi,j=〈STi,j,SCEi,j,sti,j,entry,sti,j,exit〉,STi,j⊆Wi.Ti,SCEi,j⊆Wi.CEi,sti,j,entry∈STi,j,sti,j,exit∈STi,j},其中sti,j,entry与sti,j,exit分别为该路径中的开始任务与结束任务。
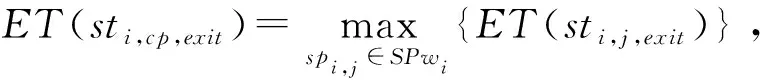
基于上述定义,ECO算法的主要步骤可用算法1进行描述。
算法1ECO算法。
输入:PM: 物理机资源,
VM: 虚拟机资源,
WS: 一组工作流应用,
DC: 一组云数据中心,
PRO: 一组云服务提供者,
RC:一组虚拟机资源位置记录;
输出: 资源调度结果。
1: for each Wi∈WS
2: {Wi,un=Wi,dc=NULL, pro=NULL
3: while Wi,un≠Ødo
4: {select the critical path spi,cpin Wi,un, and add all the tasks in spi,cpto nt
5: if ti,exitin Wi,unthen
6: Dnt=Di
7: else
9: if VMReuse(nt,RC,Dnt,dc)==Failed then
10:if dc==NULL then
11:AssignVM_PM_DC_PRO (nt,PRO, DC, PM,VM, RC, Dnt,dc,pro)
12:else
13: AssignVM_PM (nt,PRO, DC, PM, VM, RC, Dnt,dc,pro)
14: Wi,un=Wi,un- spi,cp}
15: }
ECO算法的主要步骤如下:
步骤1(语句1~2)对每一个待调度的工作流Wi,首先为其生成一个临时工作流Wi,un,然后设置其所分配的虚拟机资源所属的数据中心dc与云服务提供者pro等信息,以便后续操作。
步骤2(语句3~8)从临时工作流Wi,un中挑选出一条关键路径spi,cp,根据该关键路径生成一个任务组nt,并计算任务组的最晚完成时间Dnt。其中,对于Wi,un生成的第一个任务组,Dnt设置为Wi,un的截止时间Di;其他任务组则通过已分配资源的后继任务的最晚开始时间计算得出Dnt。语句8中,LST(tia)为任务tia的最晚开始时间,succ(nt)为任务组nt的后继任务集,即succ(nt)={succ(tij)|tij∈nt}。
步骤3(语句9)尝试通过复用空闲虚拟机为任务组分配资源,如果不能复用,则进入步骤4。复用空闲虚拟机的具体步骤为:
首先生成尚存在空闲时间、可复用的虚拟机候选集,并限制同一工作流的任务只能复用同一数据中心dc中的虚拟机;然后,在满足任务组的最晚完成时间约束下,从虚拟机候选集中选择执行成本最低的虚拟机进行复用。
步骤4(语句10~13)通过资源动态管理,为任务组nt分配合适的虚拟机。具体步骤为:
首先判断当前数据中心dc信息是否为空,如果为空则执行AssignVM_PM_DC_PRO子过程(语句11),即根据不同云服务提供商所提供的虚拟机类型与租赁费用、不同数据中心中物理机的负载与能耗情况以及任务组的最晚完成时间约束,选择或创建一个成本最低的虚拟机,并确定其所属的物理机(其能耗最低)、数据中心dc与云服务提供者pro等信息,更新或新增相关虚拟机资源位置记录,然后将该虚拟机分配给任务组nt。
如果当前数据中心dc信息不为空,则执行AssignVM_PM子过程(语句13)。具体步骤为:首先尝试在数据中心dc中,根据任务组的最晚完成时间约束、物理机的负载情况,选择或创建一个成本最低的虚拟机,并确定其所属的物理机;如果数据中心dc中无合适的虚拟机或物理机(即数据中心dc能提供的虚拟机无法满足最晚完成时间约束,或者物理机已满负荷),则调用AssignVM_PM_DC_PRO子过程。
步骤5(语句14)从Wi,un中删除包含在当前关键路径spi,cp中的任务与边,以便生成下一个任务组。
3.2 算法复杂度介绍
算法一共分为5个步骤,步骤1的算法复杂度为O(J),其中J为工作流的任务数;步骤2的最坏算法复杂度为O(J×J!);步骤3的最坏算法复杂度为O(MNKJ);步骤4的最坏情况为先尝试数据中心的虚拟机,失败后调用AssignVM_PM_DC_PRO子过程,尝试数据中心虚拟机的算法复杂度为O(K),AssignVM_PM_DC_PRO子过程的算法复杂度为O((MNK)2);步骤5的算法复杂度为O(J)。因此,总体的最坏算法复杂度为O(I(J×J!+MNKJ+(MNK)2))。
4 仿真实验
4.1 实验参数设置
为分析和评估本文提出的ECO算法的性能。假设各个数据中心均使用3种不同规格的物理机器来构建云仿真环境,参照文献[18]中的实验方案,设置了3个云服务提供商、共15种不同类型的虚拟机实例进行仿真实验,详细参数如表1~表3所示。实验时设置各个数据中心均使用3种不同规格的物理机,物理机的具体结构和相关的能耗设置如表4所示。每个云服务提供者均拥有3个数据中心,数据中心内部带宽为200 MB/s,属于同一云服务提供者的不同数据中心之间的数据传输带宽为100 MB/s,属于不同云服务提供者的数据中心之间的数据传输带宽为50 MB/s。
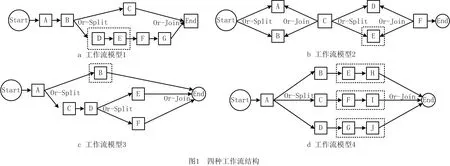
此外,实验中使用的4种不同的工作流如图1所示,这些工作流实例的到达时间服从泊松分布且λ=0.01,任务所需的计算量大小服从范围[10 000,50 000] MIPS的均匀分布。而且,参照文献[17]中的设置,任务输入/输出数据的大小服从[50,350] MB的均匀分布。
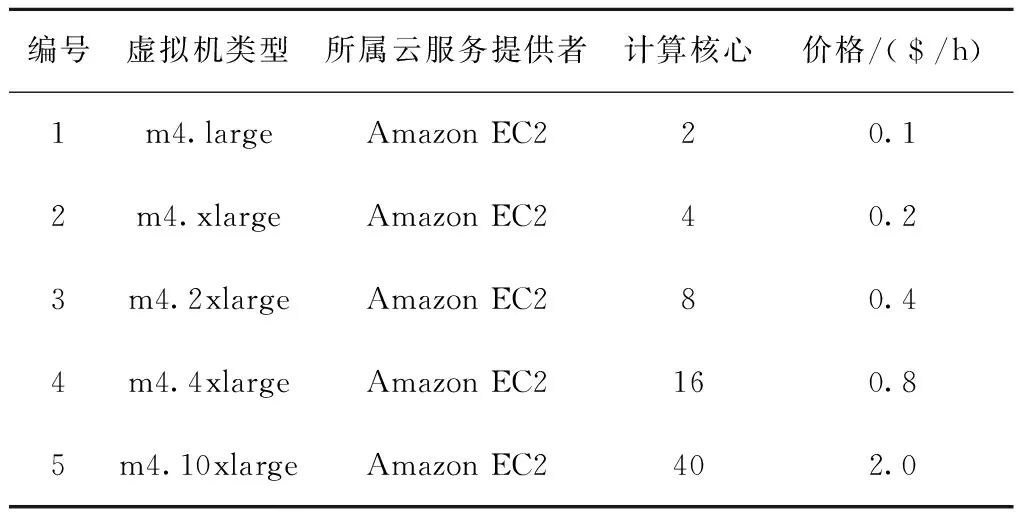
表1 云服务提供商1虚拟机实例参数设置
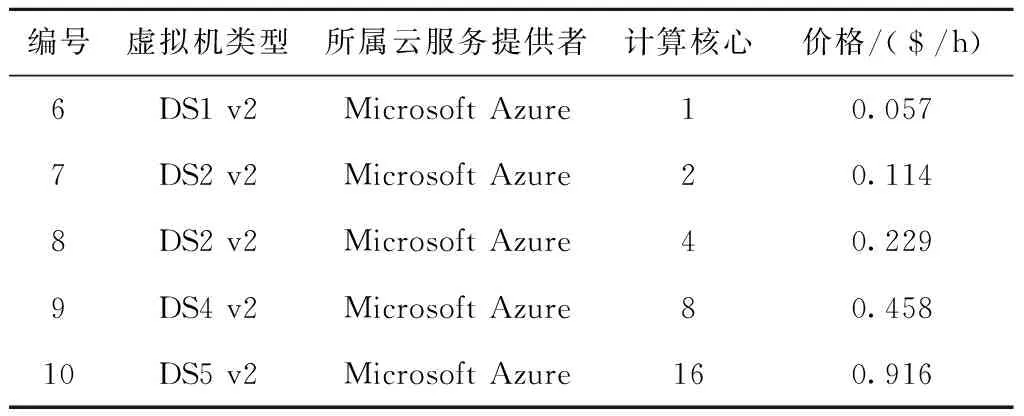
表2 云服务提供商2虚拟机实例参数设置

表3 云服务提供商3虚拟机实例参数设置
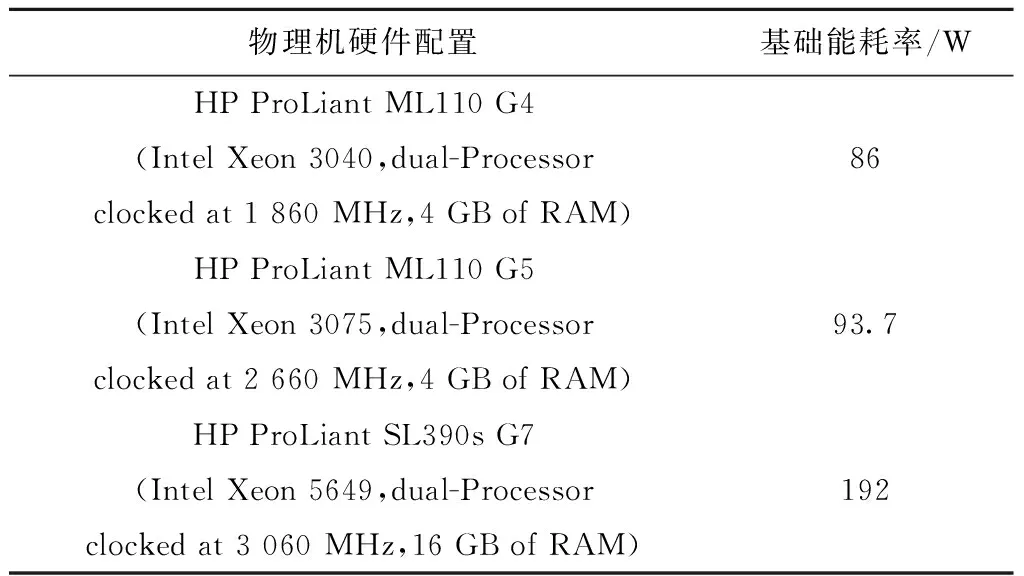
表4 物理机参数设置
为评估ECO算法的性能,选用以下5个算法作为对比算法:
(1)在线多工作流调度框架[19](onliNe multi-workflOw Scheduling Framework,NOSF)。通过采用本文中的能耗计算模型,ECO算法与该算法比较执行工作流所需成本与能耗。
(2)能耗感知的虚拟机调度方法[20](Energy-aware VM Scheduling method,EVMS)。该算法参数设置与文献[20]相同,ECO算法与该算法比较所需能耗。
(3)改进的微粒群优化算法[21](Improved Particle Swarm Optimization, Improved PSO)。该算法参数设置与文献[21]相同,ECO算法与该算法比较所需能耗。
(4)异构计算环境下最早完成时间算法[22](Heterogeneous Earliest-Finish-Time algorithm,HEFT)与异构计算环境下多目标最早完成时间算法[22](Multi-Objective Heterogeneous Earliest-Finish-Time algorithm,MOHEFT)。这两种算法的参数设置均与文献[22]相同,ECO算法与其比较所需成本。
4.2 对比实验结果
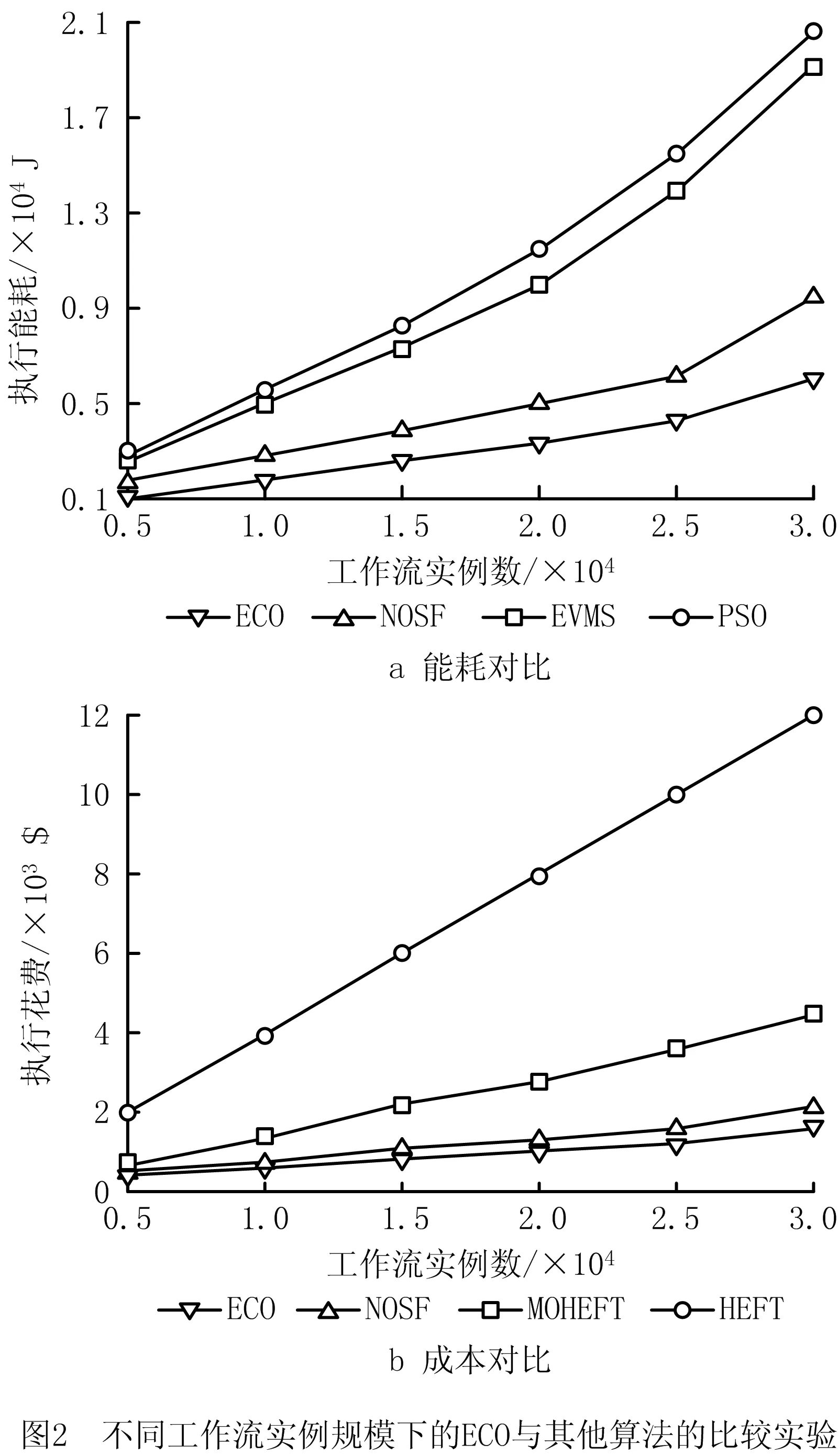
如图2所示为在工作流实例数量变化的条件下各算法性能比较实验结果。由图2a能耗对比可以看出,ECO算法比其他算法在节能方面的性能优于其他算法,这是因为Improved PSO算法与EVMS算法虽然为任务找到了合适的虚拟机类型,但未考虑虚拟机复用,虚拟机的计算资源闲置导致资源浪费;NOSF算法虽然考虑到了虚拟机复用,但是忽略了输出数据集对算法性能的影响。由图2b成本对比可以看出,ECO算法在降低或节约成本方面也优于其他对比算法。而且,通过图2中的实验结果可知,随着所调度的工作流实例数量的增长,ECO算法相对其他算法在降低能耗与成本方面的效果越明显。
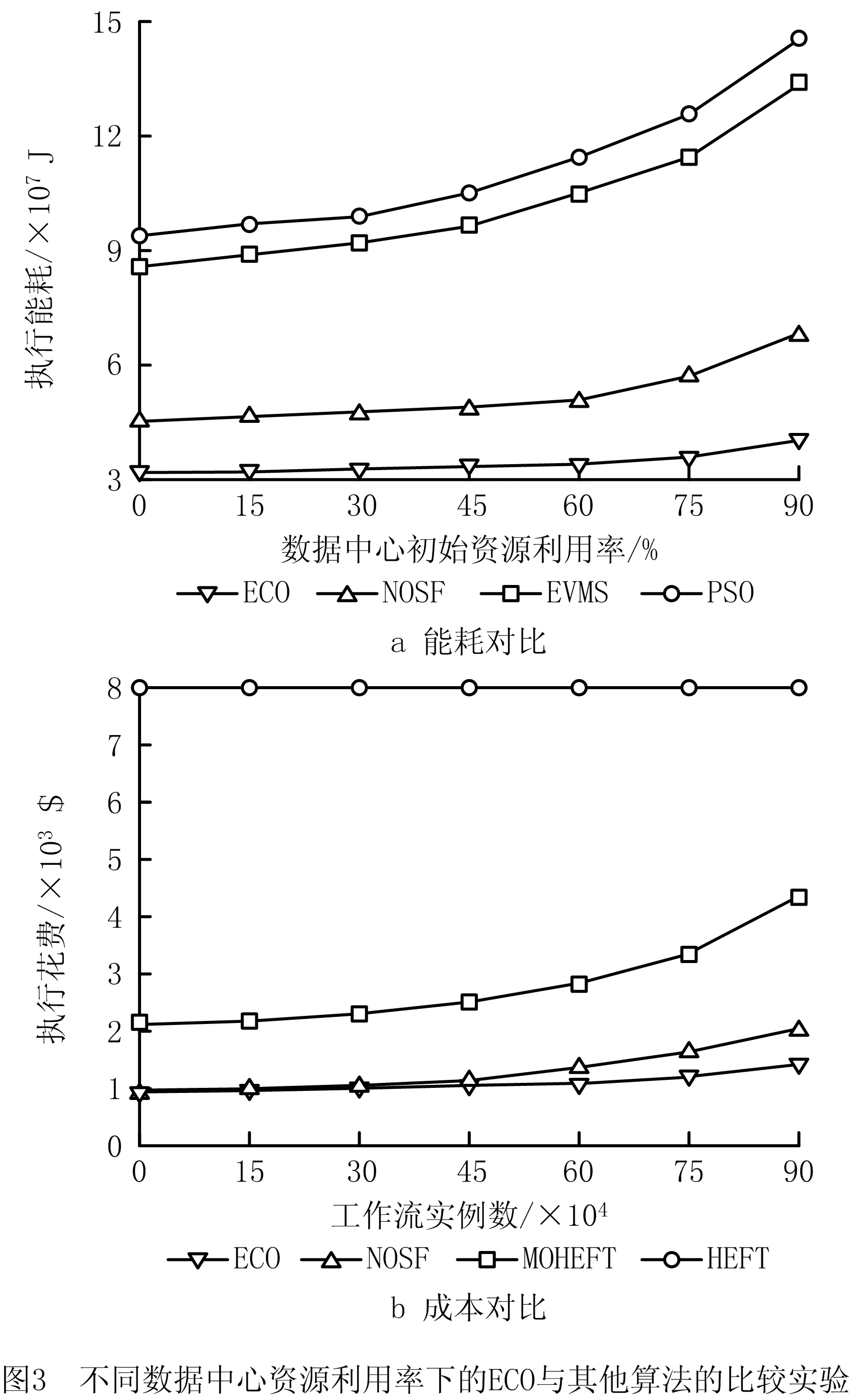
图3展示了在不同的数据中心资源利用率情况下各算法性能比较实验结果。其中,60%的初始资源利用率意味着在待调度的工作流任务未到达数据中心之前,已有60%的物理机资源被占用。从结果对比可以看出,随着数据中心初始资源利用率变高,任务不能在同一数据中心处理的概率的越高,因此所有算法的结果曲线的增长速率一直在增长,但可以看出ECO算法是增长最缓慢的,这是因为ECO中的任务组选择策略将多个连续任务交由同一虚拟机执行,大大减少了数据传输损耗。值得一提的是HEFT算法的执行花费不会随着数据中心初始资源利用率变化,这是因为HEFT算法为每个任务分配的最高级的虚拟机,所以虚拟机存在大量空闲时间可用于跨数据中心的数据传输,则执行花费不变。而且,通过图3中的实验结果可知,随着数据中心利用率的增长,ECO算法相对其他算法在降低能耗与成本方面的效果越明显。
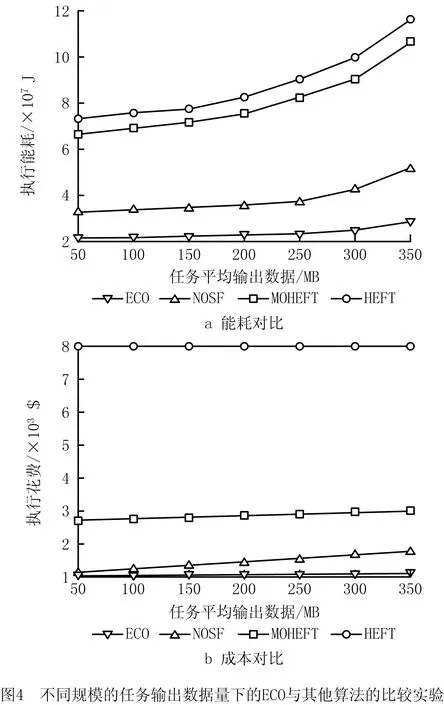
图4展示了在不同规模的工作流任务输出数据量情况下各算法性能比较实验结果。由图4a能耗对比可以看出,EVMS和PSO算法随任务平均输出数据量的增大变化较小,这是因为它们没有虚拟机复用策略导致虚拟机存在空闲时间,而输出数据量增大时所形成的传输数据的时间可以由这些虚拟机的空闲时间完成。而且,ECO算法结果曲线比NOSF算法更为平缓。这说明ECO算法中的任务组选择策略能有效降低由数据传输导致的能源与成本。由图4b对比可以看出相似的规律。
5 结束语
针对如何在云际协作环境中高效实现兼顾成本与能耗的云工作流调度问题,本文在前期研究工作的基础上,建立了该问题对立的工作流调度模型,并设计了一种云际协作环境下能耗与成本感知的工作流调度方法ECO。在今后的工作中,将结合数据中心资源利用率预测方法,进一步研究云工作流节能调度问题。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年7期)2021-07-16
建材发展导向(2021年23期)2021-03-08
法制博览(2020年11期)2020-11-30
华人时刊(2018年15期)2018-11-10
山东大学法律评论(2018年0期)2018-08-04
法制博览(2017年16期)2017-01-28
湖湘论坛(2015年4期)2015-12-01
