
基于谱聚类和隐语义模型的智能协同推荐方法
2021-10-11 13:09:18高子建张晗睿窦万春徐江民孟顺梅
计算机集成制造系统 2021年9期
高子建,张晗睿,窦万春,徐江民,孟顺梅+
(1.南京理工大学 计算机科学与工程学院,江苏 南京 210094;2.南京大学 计算机软件新技术国家重点实验室,江苏 南京 210023)
0 引言
随着云计算和移动互联网技术的飞速发展,社会进入高度信息化时代,网络中信息资源规模正以前所未有的速度快速增长。面对规模愈发庞大的信息资源,人们难以准确、实时地获取满足自身需求的信息,从而引发了“信息过载”问题[1]。推荐系统作为解决信息过载的有效途径之一,成为信息检索、数据挖掘等领域最为活跃的分支之一[2-3]。推荐系统能根据用户兴趣需求为用户推荐适合用户的产品,能有效减轻数据负载,帮助用户从海量信息中提取有效信息,准确作出推荐,对提高用户体验具有很重要的意义。在众多推荐算法中,协同过滤(Collaborative Filtering, CF)推荐算法是最有效的算法之一[4],其主要包括基于邻域模型的协同推荐算法[5]和基于矩阵分解的隐语义模型(Latent Factor Model, LFM)[6]。
近年来,网络中用户以及产品信息规模越来越大,庞大的数据信息成为丰富资源的同时也给现有协同推荐算法带来了极大挑战。面对海量、多源、异构且稀疏的用户行为数据,传统的基于邻域模型的协同推荐方法和LFM模型显得力不从心[7-8]。传统的基于邻域的协同推荐模型需要在计算所有用户对或者产品对间相似度的基础上挖掘用户相似信息,以确定目标用户的相似历史用户,但在面对代入上下文信息的维度较高、规模较大且数据稀疏的用户评论信息时,计算量庞大,推荐算法的效率是影响推荐性能进一步提高的瓶颈之一[9-10],同时冷启动问题也是协同推荐方法中亟待解决的问题之一[11-12]。尽管LFM模型能在一定程度上解决基于邻域模型的协同推荐算法中的数据稀疏性问题,但是随着数据规模的扩大,数据稀疏性问题日益严重,在处理数据日益稀疏的评分矩阵时,由于没有足够多的信息指导预测,传统的LFM模型的预测效果不尽如人意。
实际上,在网络中除了评分还有很多有用的用户或产品的标签信息,例如在MoveiLens评分网站中除了提供用户的评分信息还提供用户的性别、年龄、职业等标签特征信息以及电影的分类特征信息等。这些信息在一定程度也反映了用户的偏好信息或产品的特征信息,如果将这些标签特征信息与评分信息相结合能在一定程度上提高传统的仅基于评分矩阵的推荐算法的预测性能。此外,任何一种推荐算法都不会绝对地优于另一种推荐算法,因此,可将多种推荐模型有效融合,构建性能更高的混合推荐模型。
基于上述发现,本文提出一种基于谱聚类和隐语义模型的智能协同推荐算法。该算法在利用谱聚类算法挖掘用户或项目间相似信息的基础上,将基于隐语义模型的推荐模型与基于邻域的协同推荐模型相结合,以解决传统协同推荐算法中的瓶颈问题,从而提升推荐性能。该算法基于用户标签特征信息挖掘用户间的相似信息,对没有评过分的用户也能找到其相似用户,因此可以解决冷启动问题。具体而言,首先在获取用户(或项目)的标签特征向量基础上,利用谱聚类算法对用户进行聚类以获取目标用户的相似用户,同时基于谱聚类算法可将原始评分矩阵划分为多个较低维的子评分矩阵,然后在各子评分矩阵内利用基于隐语义模型的矩阵分解模型对缺失评分进行局部预测以解决数据稀疏性问题,最后利用改进的基于邻域的协同推荐算法为目标用户进行全局评分预测。本文在MovieLens实验数据集上将方法与现有几种协同推荐算法相比较,以验证所提方法的有效性。
1 相关工作
1.1 基于邻域模型的协同推荐方法
基于邻域模型的协同推荐方法主要是基于用户历史行为信息,为用户寻找偏好相似的最近邻对象,以“人以群分”或“物以类聚”的思想,为用户推荐可能感兴趣的物品。目前,国内外许多学者对基本最近邻模型进行了不同程度的改进,以提高模型推荐效果。CHEN等[13]基于用户对服务的服务质量(Quality of Service,QoS)属性进行评分,提出一种QoS感知的个性化服务推荐方法,通过建立区域模型为用户寻找QoS偏好相似的近邻对象。文献[14]通过情境感知信息来挖掘目标情境与特定情境中用户偏好之间的隐藏关系,根据用户情境为用户推荐其感兴趣的项目。MENG等[15]则通过挖掘用户文本评论数据,提取关键词向量构建用户偏好模型,基于语义信息改进原有近邻模型中基于评分的相似度计算方式。CAI等[16]则借鉴认知心理学中的“典型性效应”为用户寻找相似近邻。最近邻模型的构建思想简单易懂,但该模型对于样本数据稀疏或冷启动场景,推荐效果不佳,且不具有很好的可扩展性。
1.2 基于隐语义模型的推荐方法
相比于基于邻域的协同推荐模型,基于矩阵分解技术的隐语义模型能较好地应对数据稀疏性问题,且考虑了评分矩阵中隐含信息对推荐效果的影响。隐语义模型最早由KOREN在2009年提出[17]。文献[18]将二值化用户属性加入隐语义模型,利用分类模型评估其他用户属性的重要程度,找出目标用户的相似用户,并结合目标用户的评分信息进行预测推荐。此外,为提高推荐准确度,ZHANG等[19]将动态时间信息引入基本二维矩阵模型,提出一种基于张量分解的时间感知服务推荐方法。文献[20]基于BERT(bidirectional encoder representations from transformer)模型从评论中提取用户和项目的深层非线性特征向量,并将用户和项目的深层特征向量与潜在隐向量以一、二阶特征项的方式产生深度特征项来进行预测推荐。
1.3 基于聚类算法的协同推荐方法
聚类算法属于机器学习中的一种非监督学习方法,可以对样本数据进行有效分组。因此,聚类算法可以在协同推荐模型中用于搜寻目标用户的相似用户(最近邻)。文献[21]对标签特征进行聚类生成主题标签簇,并构建项目—主题关联矩阵与原始评分矩阵相结合计算项目间的相似度,最后利用基于邻域的协同推荐模型预测推荐。DENG等[22]则基于K-medoids聚类算法和概率模型改进传统推荐模型以提升推荐准确度。LIU等[23]提出一种基于聚类算法的协同推荐模型,引入时间衰减函数预处理评分信息,基于用户特征向量和项目属性向量对用户和项目进行聚类,然后利用改进的相似度计算方法寻找目标用户的相似用户进行预测推荐。WEST等[24]提出一种基于分层聚类方法的文献推荐方法。
2 系统模型
2.1 问题描述
给定一个样本数据集,每个样本(u,i,rui)表示用户u对项目i的评分为rui,样本数据中还包含用户标签特征[F1,F2,…,Ft],每个用户u都有一个标签特征向量与之对应,t表示用户标签特征向量的维数。本文的任务则是从用户标签特征信息及评分信息中挖掘出用户—用户,用户—项目间的交互信息,预测出目标用户对候选项目的评分。
如图1所示,本文提出的算法模型包括3个模块:模块一是基于从样本数据获取的用户标签特征向量,利用谱聚类算法对用户分组聚类;模块二利用在各子聚类内构建评分矩阵,利用基于矩阵分解的隐语义模型在各子聚类内局部预测缺失评分;模块三则利用改进的协同推荐模型进行全局预测推荐。该算法是基于用户标签特征信息挖掘用户间的相似信息,对没有评过分的用户也能找到其相似用户,因此可以解决冷启动问题。同时在模块二中在各子矩阵中对缺失评分进行局部预测,一定程度上解决了数据稀疏性问题。
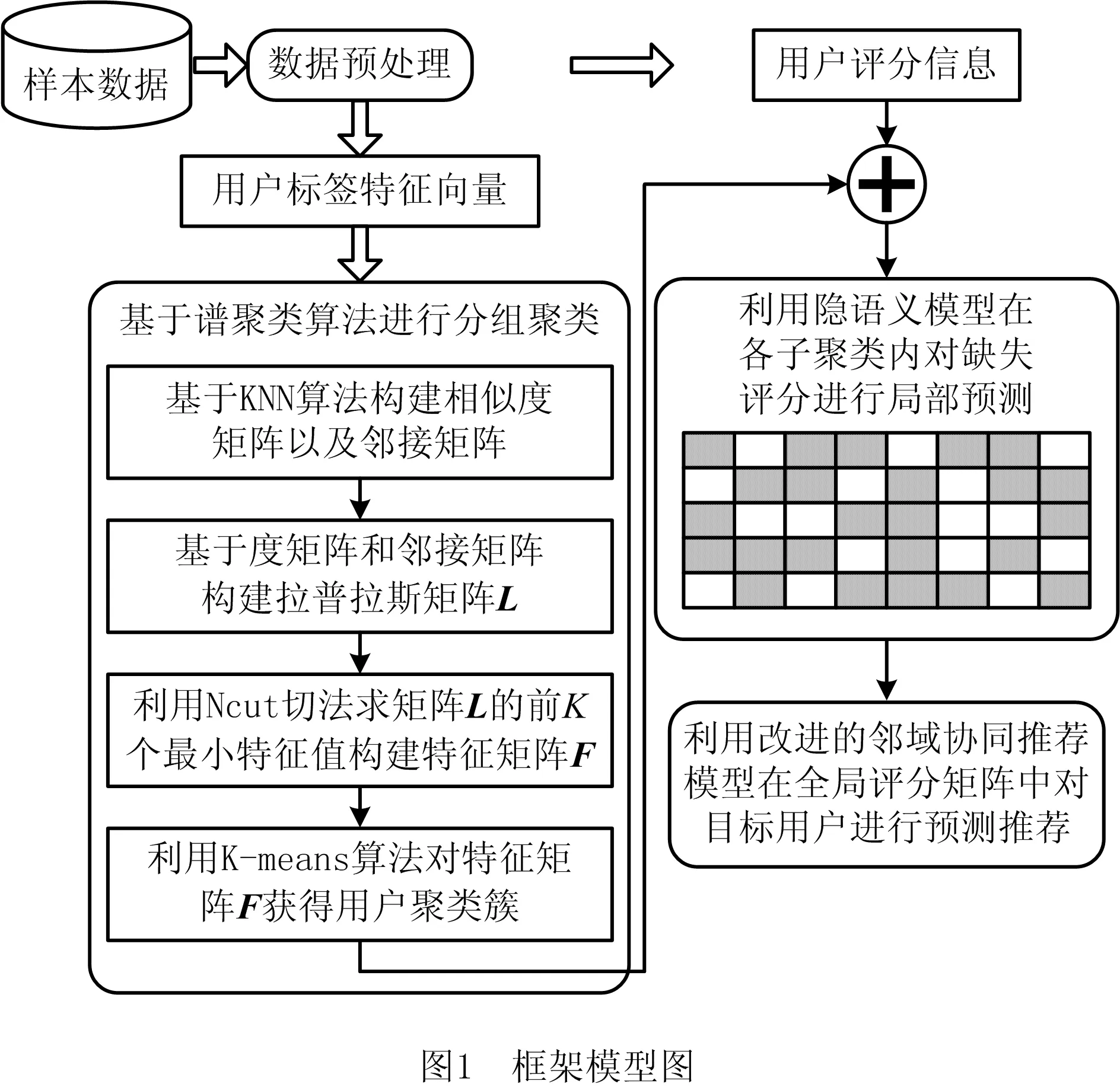
2.2 谱聚类算法
谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法[25]。在谱聚类中,将所有样本数据看作空间中的点,可以将这些点连接起来构成无向带权图,G=
利用K近邻(KNN)算法遍历所有样本点,将与每个样本点最近(利用高斯核函数度量距离)的K个点作为其近邻,可通过以下两种方式将其构建为对称邻接矩阵:

2.3 基于矩阵分解技术的隐语义模型
隐语义模型是由Simon Funk利用梯度下降(Gradient Descent, GD)改进奇异值分解(Singular Value Decomposition,SVD)算法而来的[17]。从矩阵分解角度而言,隐语义模型则是将评分矩阵R分解为两个分别与用户特征和项目特征相关的低维矩阵的乘积:
R=PTQ。
(1)
其中:P∈Rf×n,Q∈Rf×m,n和m分别为用户个数和项目个数,则用户u对项目i的评分可表示为:
(2)
其中,puf表示用户u的第f个特征值,qif则表示项目i的第f个特征值。为求得参数puf和qif,可通过最小化式(3)中的损失函数求得:
(3)

另外,在实际情况中,用户有些属性与项目无关,项目有些属性与用户无关,因此可以在预测模型中加入偏置项,增加了偏置项的SVD模型称为BiasSVD模型。
3 基于谱聚类和隐语义模型的协同推荐方法
3.1 基于用户特征和谱聚类算法进行用户聚类
(1)首先预处理获取的用户标签特征样本点X={x1,x2,…,xn},然后利用基于高斯核函数的K近邻算法和用户标签特征向量计算用户相似度矩阵S={sij}n×t,其中t为标签特征维数:
(4)
然后,基于相似度矩阵构建邻接矩阵W={wij}n×t,在该方法中由于利用K近邻方法构建的相似度矩阵中并不对称,因此利用下面方式构建对称的K近邻相似度矩阵,只要一个点在另一个点的K近邻中,则保留sij:
(5)
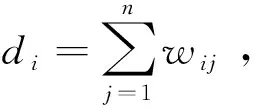
(3)计算拉普拉斯矩阵L:L=D-W。
(4)利用Ncut切法求拉普拉斯矩阵L的k个最小特征值构建特征矩阵F:
首先构建标准化后的拉普拉斯矩阵Ls:Ls=D-1/2LD-1/2=I-D-1/2WD-1/2,其中I为单位矩阵;
计算标准化拉普拉斯矩阵Ls的特征值,选取前k个最小的特征值(k为希望输出的聚类簇的个数),并计算前k个特征值所对应的特征向量f1,f2,…,fk;
将上述k个特征向量作为列向量组成的矩阵按行标准化,最终组成维度为n×k的特征矩阵T={f1,f2,…,fk},T∈Rn×k;
(5)令hi∈Rk为特征矩阵T的第i行向量作为新的中间数据样本点,其中i=1,2,…,n,然后利用k-means聚类算法将新的样本点H={h1,h2,…,hn}聚类成簇{A1,A2,…,Ak}。
(6)将新样本点的聚类簇转化为原始用户聚类簇C={C1,C2,…,Ck},其中,Ci={j|hj∈Ai}。
3.2 基于隐语义模型局部预测缺失评分
在基于上述步骤将用户分组聚类后,可将维度较高的原始评分矩阵分为k个规模较小的子评分矩阵,本文将利用基于矩阵分解的隐语义模型对评分矩阵中的缺失评分进行填充以解决数据稀疏性问题,对每个子评分矩阵操作如下:
设Rg×m为某个子评分矩阵,g为对应子聚类中用户的个数,m为样本中项目的个数,本文中基于BiasSVD算法对评分矩阵进行分解预测。BiasSVD算法假设评分系统包括偏置项和用户与项目交互影响因子两部分,如式(6)所示:
(6)
其中:偏置项包括全局平均值μ,用户偏置项bu,项目偏置项bi。
在隐语义模型中,通过最小化式(7)中的损失函数来学习求得式(6)中的参数bu,bi,puf以及qif。
(7)
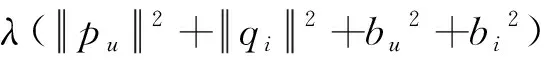
然后利用随机梯度下降方法(Stochastic Gradient Descent,SGD)求解上述损失函数,分别对各参数求偏导可得下式,

(8)
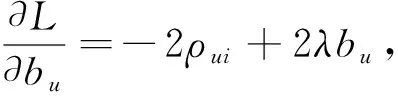
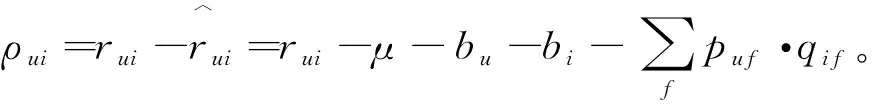
bu←bu+γ(ρui-λbu),
bi←bi+γ(ρui-λbi),
puf←puf+γ(qif·ρui-λpuf),
qif←qif+γ(puf·ρui-λqif),
(9)
通过上述基于BiasSVD算法的隐语义模型则可以在各子评分矩中局部预测缺失评分。
3.3 评分预测
在各子聚类内对缺失评分进行局部初次预测后,将子评分矩阵组合成原始评分矩阵,利用改进的基于邻域的协同推荐模型进行二次全局预测。由于在经过局部填充缺失评分后,评分矩阵变得很密集,若利用传统的基于邻域的协同推荐模型,则需计算所有用户对间的相似度值,计算量较为庞大。因此本文再次利用k-means聚类算法基于用户评分向量对用户进行聚类,将用户集再次划分为k′个类。然后在目标用户所在的聚类内,基于皮尔逊相关系数(Pearson Correlation Coefficient, PCC)计算目标用户u与子聚类内其他用户的相似度,计算公式如下:
(10)
(11)
4 实验
4.1 实验数据集
本文使用的数据集为movielens 100k数据集和movielens 1M数据集,实验环境为 PC 机; Windows 10 操作系统;编程语言为 Python 3.7。每个用户至少有20个评分,每个用户拥有的标签特征包括性别、年龄和事业。在实验中数据集划分为两部分:80%的训练数据集和20%的测试数据集。
4.2 评价指标
本文采用4种广泛使用的性能测量指标来评估推荐系统的预测准确度:平均绝对误差(MAE)、均方根误差(RMSE)、准确率(Precision)和召回率(Recall)。
平均绝对误差(MAE)是绝对误差的平均值,能更好地反映预测值误差的实际情况;均方根误差(RMSE)则是用来衡量预测值与真值之间的偏差;MAE和RMSE值越小说明算法的预测准确度越高。
其中:rij是真实评分,prij是预测评分。
下面给出准确率和召回率的公式:
其中:R(u)表示根据预测算法推荐给用户u的项目,T(u)则表示用户u在测试集合里面实际喜欢的项目。
4.3 实验结果分析
为了评价本文方法(记为SC_LFM_KCCF)的推荐准确性,将其与其他3种推荐方法进行比较,即基于用户的皮尔森相关系数算法(User-based Pearson Correlation Coefficient,UPCC)、矩阵分解算法(Matrix Factorization,MF)和基于k-means聚类的协同过滤算法(Kmeans-Clustering-based Collaborative Filtering,KCCF)。 UPCC[5]是一个典型的基于邻域的协同过滤推荐算法,MF是一种常用的基于矩阵分解的推荐算法[17],KCCF是一种基于k-means均值聚类改进的协同过滤推荐算法。
4.3.1 预测准确性分析(MAE&RMSE)
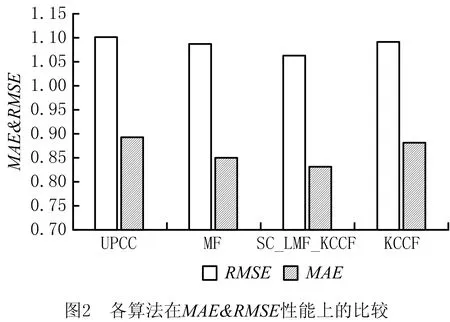
在这一部分中,为了评估SC_LFM_KCCF的预测精度,将其与其他3种方法(UPCC、MF和KCCF)在MAE和RMSE进行了比较。实验结果如图2所示。图2是在“movielens 1M”数据集上进行的,展现了4种方法的MAE和RMSE的预测性能。较低的MAE和RMSE意味着较好的预测性能,可以发现本文方法优于其他3种方法,MAE和RMSE最低。因此,与其他3种比较方法相比,本文方法,即SC_LFM_KCCF,是考虑数据稀疏问题和冷启动问题的最佳推荐策略。同时,可以看出本文方法的MAE值比KCCF方法低,因此采用谱聚类算法和隐语义模型改进CF推荐算法比直接采用k-means聚类算法改进CF推荐算法更有效。
4.3.2 Top-N推荐准确性分析(Precision&Recall)
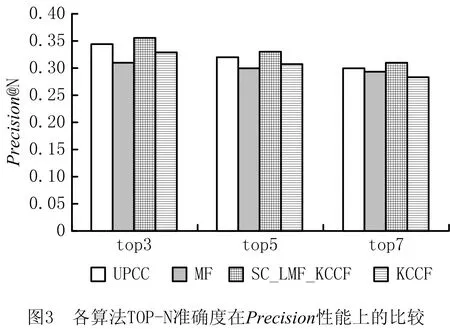
为了进一步评估SC_LFM_KCCF的预测准确性,将其与其他3种方法(UPCC、MF和KCCF)在Top-N推荐准确度上进行了比较。实验结果如图3、图4所示,该实验是在“movielens 1M”数据集上进行的。图3给出了4种方法在Top-N(N=3、5、7)推荐上的Precision值,图4中展示4种方法的Recall值。从实验结果可以看出,SC_LFM_KCCF在准确率和召回率方面都优于其他3种比较方法,进一步证明了SC_LFM_KCCF具有更好的预测精度。同时从实验结果可以看出,随着N值的增加,4种方法的精度降低,召回率增加。因此,较小的N意味着更高的Top-N预测准确度。

4.3.3 谱聚类算法中参数k对算法准确性的影响分析
本节旨在分析参数k(谱聚类算法中的聚类数)对推荐准确度的影响。实验是在“movielens 100k”数据集上进行的,图5给出了随着k值的变化本文方法的MAE值的变化情况,其中k以5为步长从5增加到25。从图5中可以看出,在前期随着聚类数k值的增加(5≤k<15),MAE值逐渐降低,算法的准确度逐渐上升;后期随着k值的增加(15≤k≤25),MAE值不断增加,推荐准确度降低;当k=15时,本文方法取得最佳推荐效果。这是因为当聚类数k值较大时,会导致聚类不均匀,影响算法的精确性,从而使得推荐准确度下降。因此,在本文提出的基于谱聚类和隐语义模型改进的协同推荐算法中,要选取合适的k值以获得最佳推荐效果。

5 结束语
本文基于用户标签特征信息以及用户评分信息,提出一种基于谱聚类和隐语义模型的智能协同推荐方法。该方法在获取用户的标签特征向量基础上,利用基于KNN模型的谱聚类算法挖掘用户间的相似信息,将用户进行分组聚类,然后基于聚类将原始评分矩阵划分为较低维的多个子评分矩阵,然后在各子评分矩阵内利用基于隐语义模型的矩阵分解模型对缺失评分进行局部预测,最后利用改进的基于邻域的协同推荐算法为目标用户进行全局评分预测。实验证明,改进后的算法与传统协同推荐算法以及基于k-means聚类改进的协同推荐算法相比,能够有效提升推荐准确度,并能较好地解决数据稀疏性问题以及冷启动问题。下一步工作改进思路主要包括利用知识图谱构建用户—项目实体之间关系图以获取更具体的用户及项目特征信息,并利用深度学习方法构建预测模型以进一步提升推荐准确度。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
开放教育研究(2020年2期)2020-03-31 01:54:14
汽车观察(2019年2期)2019-03-15 06:00:50
电子测试(2017年15期)2017-12-18 07:19:27
中国卫生(2016年5期)2016-11-12 13:25:26
现代语文(2016年21期)2016-05-25 13:13:44
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
大连民族大学学报(2015年2期)2015-02-27 08:28:11
生物进化(2014年2期)2014-04-16 04:36:26
