
电网故障处置预案文本中的命名实体识别研究
2021-10-11 01:45:36江叶峰孙少华仇晨光王波戴则梅李杰
电力工程技术 2021年5期
江叶峰,孙少华,仇晨光,王波,戴则梅,4,李杰
(1.国网江苏省电力有限公司,江苏 南京 210024;2.南瑞集团(国网电力科学研究院)有限公司,江苏 南京 211106;3.国电南瑞科技股份有限公司,江苏 南京 211106;4.南瑞集团有限公司智能电网保护和运行控制国家重点实验室,江苏 南京 211106)
0 引言
电网故障处置预案文本广泛应用于指导设备故障后电网状态监测和故障处理。故障发生后,传统处置方式通过人工查阅预案文本,手动处置故障[1—2],难以满足故障处置的高效性、及时性。随着电网智能化进程的不断推进,电网故障处置机器人[3—4]应能结合调度系统模型“阅读”文本内容,正确理解故障预案文本,实现相关涉事设备的自我调控。而预案文本由调度员人工编写,每条文本质量参差不齐[5]。因此,对文本进行命名实体识别(named entity recognition,NER),解析预案中关键信息序列,对于提升文本的机器可读性具有重要意义。
近年来,国内外学者针对NER任务展开了大量研究,文献[6—7]通过建立领域词典,提升了领域内文本实体词识别能力。文献[8]采用统计分类方法识别实体词。随着词向量技术的发展,专家学者逐渐将神经网络引入NER任务中,文献[9]采用拓展卷积神经网络对文本序列建模,关注了文本局部知识与全局信息。文献[10]分别利用循环神经网络(recurrent neural network,RNN)以及长短期记忆网络(long short-term memory,LSTM)标注文本,进一步提升了NER效果。在电力领域研究中,针对规范性文本浅层学习,文献[11—12]分别以规范的告警文本、停送电计划为研究对象,参考调度平台数据库匹配关键字符,实现了关键实体词与变量的识别。文献[13]基于专家知识库规则自动生成工作票安全措施。对于非规范性电网缺陷文本的深层挖掘,文献[14—17]基于准确的分词库或者高质量的文本数据,识别近义词或同义词,虽实现了文本分类,但均未详细剖析理解文本信息。预案文本的规范性因人而异,文本匹配显然无法满足实体词识别的要求。因此,预案文本中的关键信息学习识别亟待解决。
文中首先分析了预案文本特征,采用字向量表征文本中汉字,将注意力(attention,ATT)机制引入双向长短期记忆网络(bidirectional long short-term memory,BiLSTM),并结合条件随机场(condition random filed,CRF)提出基于ATT+BiLSTM+CRF的电网故障预案文本NER方法,实现了文本中涉事电气设备、电气参数词等细粒度的关键实体识别。之后,以F1值为评价指标,对比分析了文中模型与常用NER模型的识别效果。实验证明,文中所构建模型对于预案文本具有更强的适用性与鲁棒性。
1 电网故障处置预案文本特点
电网故障处置预案文本是电力调度人员通过离线模拟电网事故,监测故障后薄弱点状态参数信息,并结合电网运行状态人工制定的故障处理方案,既包含电网故障时涉事的电厂、机组等电力设备及其状态参数,也包含设备调控、负荷投切等处置操作。图1为预案文本及NER标注示例。
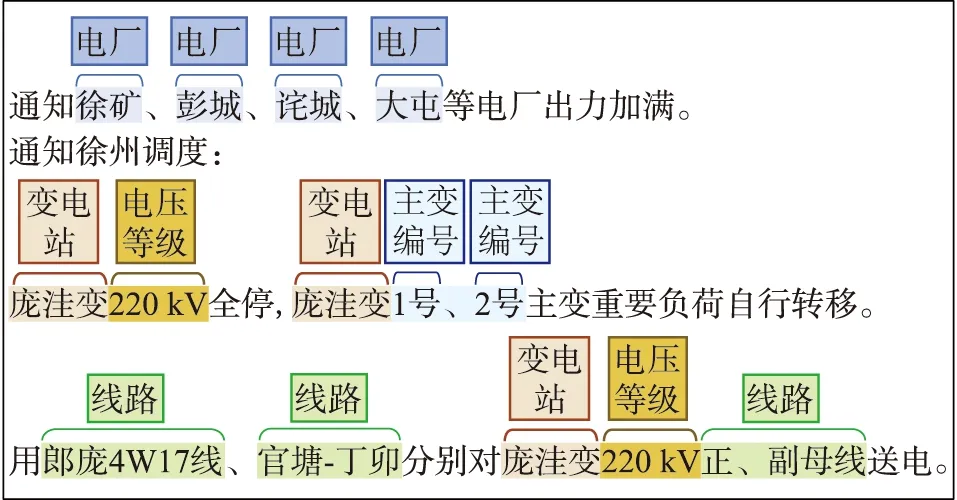
图1 预案文本及NER标注示例Fig.1 Example of preplan text and NER annotation
根据故障处置的应用需求并结合调度系统中模型划分的实体对象类型,文中将预案文本中电压等级、线路、变电站、开关、母线编号、分区、电厂、机组编号、主变编号作为NER的对象,共计9类。
不难发现,预案文本中的实体类别是细粒度的。例如,变电站、电厂和分区这3类存在很大的相似性,在常规的NER任务中通常被粗粒度地划分为“地名”类,然而粗粒度的识别并不适用于电网故障处置的实际需求。
此外,预案文本的表述存在较大的专业性和不规范性,例如电厂名的表述:“华能苏州燃机”“中电滨海风电”等电厂实体词,可细化为所属发电集团、电厂所在地名、电厂类型等复合型电厂实体词;或者在并列表达时仅采用地名代称电厂,如“射阳、彭城等电厂”,其实体词含义及其类别需要结合上下文来分析理解。
同样,线路实体词表述的结构也多种多样,如能量管理系统中标准线路词:“官丁2569线”,表述为“官塘-丁卯”“官丁线”。同时线路实体词可能掺杂数字、字母以及用于表达连接的符号“-”、并列的符号“/”等,如“庆安-倪村线”“红柳4W45/46双线”等。
综上可以看出,电网故障处置预案文本存在细粒度类别划分、实体词专业性强、语言表述不规范等特点,给NER过程带来巨大的困难。
2 基于ATT+BiLSTM+CRF的电网故障预案文本NER
针对电网故障处置预案文本中实体对象的特点,文中采用基于ATT+BiLSTM+CRF框架的NER方法来进行故障预案文本实体词的辨识与提取。
2.1 数据预处理及文本标注
预案样本数据来自于某电网调度机构140个典型故障的预案文本,并根据符号分隔为4 067条短句训练样本。通过正则表达式匹配剔除序号、助词等无关词,降低NER过程中的噪声。
预案文本中9类NER对象的标签定义如表1所示。对所有预案文本采用“BIO”格式进行标注,标注样例如表2所示。

表1 9类NER对象的标签定义Table 1 Label definitions of nine NER objects
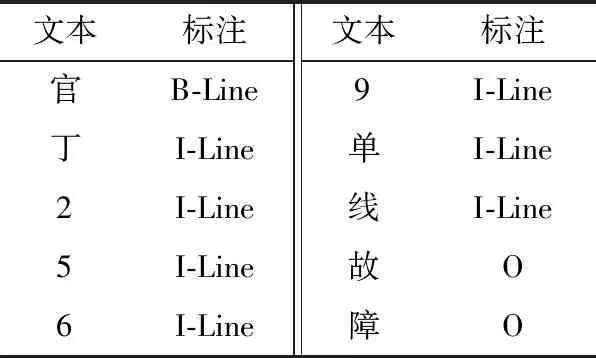
表2 BIO标注样例Table 2 Annotated example of BIO
其中,B为实体词起始词,B-Line为线路名的起始字;I为实体词非首字,I-Line为线路名的非首字;O为非实体词。
2.2 字向量
文本所用的识别框架需要先将语料中的文字表示成向量形式作为模型的输入,目前学术界主要有2种方式:一是词向量形式,将句子切分成多个词,对每个词进行向量化;二是字向量形式,直接将句子中的每个字表示成向量。由于通用领域的分词词典在电力领域适用性较低,会出现明显的分词错误,进而导致模型的性能指标下降,所以文中采用字向量的方式,对语料进行向量化。
字向量化表示的方式有2种:One-Hot方式和分布式方式[18]。但是One-Hot方式生成的字向量没有融入任何的语义信息,而且字汇表过大,会造成维度爆炸。分布式方式是将字映射为连续稠密的低维实值向量,较好地解决了One-Hot的缺陷问题,所以文中采用分布式方式对字进行向量化。
目前,基于通用语料的预训练模型生成字向量的方式已经在多个通用领域中取得了优异的成绩。但在电力系统领域,由于语料不匹配,效果并不理想。故文中使用目前在NER任务中最优的Bert预训练模型[19],在某调度机构的大量相关电力文档上进行训练,得到适用于电力领域的专用预训练模型,将字映射为768维的字向量。
字向量表征的文本可以在模型训练中自动获取文本的字符级特征,从而提升NER模型在工程领域文本的适用性和准确率。
2.3 ATT+BiLSTM+CRF模型
2.3.1 BiLSTM模块
BiLSTM[20]是双向结构在LSTM上的应用,其每个单元结构与常规LSTM的单元相同,只是整体上多了一个按照反方向处理序列的隐层。BiLSTM模型的结构示意如图2所示。
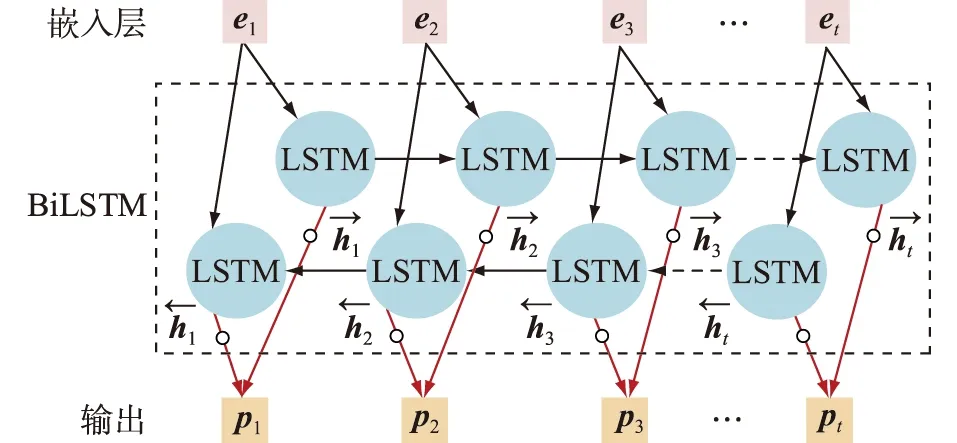
图2 BiLSTM结构示意Fig.2 Schematic diagram of BiLSTM
BiLSTM的训练方法也采用通过时间的反向传播算法,其前向与反向传播的过程与常规的RNN类似。在t时刻,BiLSTM的正向计算过程一般遵循下式:
σ(x)=1/(1+e-x)
(1)
tanhx=(ex-e-x)/(ex+e-x)
(2)
(3)
(4)
(5)
(6)
(7)


对于序列化文本数据,BiLSTM通过引入门级控制调控序列数据传输,选择性丢弃和保存前序与后序数据,用以更新神经元,有效地解决了RNN中长文本梯度弥散的问题。
2.3.2 CRF模块

定义每一种预测序列的得分如式(8)所示。
(8)
式中:A为(k+2)×(k+2)的矩阵,加2是为了提升鲁棒性,在句子首尾添加了起始状态和终止状态;Ayt,yt+1为类别yt到yt+1的转移得分,代表了实体各标签类别之间的依赖关系;y0,yn+1分别为起始状态和终止状态;P为BiLSTM的输出矩阵;Ppt,yt为第t时刻的输出向量pt与yt类对应的得分。
(9)
训练好的模型对测试数据进行预测即可得到最佳标签序列,其计算公式如下:
(10)
目前,BiLSTM+CRF模型在NER领域已经取得了广泛的应用,在网络开源语料数据集上也取得了领先的识别效果。然而电网故障处置预案文本与一般性文本存在巨大差异,具有很强的专业性,BiLSTM+CRF模型难以取得理想的识别效果。文中针对目前BiLSTM+CRF模型在电网故障处置预案文本上识别效果的不足,提出一种引入ATT机制的ATT+BiLSTM+CRF模型。通过在电网故障处置预案文本NER中对实体词关键部分分配较多的注意力,从而提升电网故障处置预案的NER效果。
2.3.3 ATT机制
预案文本的部分内容具有关联性的特征,例如:“在徐州西分区进行事故拉限电”,其中“徐州西分区”的字符间关联性更高,“徐”和“在”字的关联性很弱,这说明对于识别文本中的命名实体,每个字符的影响程度不同,在数学中表示为分配的权重不同。因此,文中在BiLSTM计算过程中引入ATT机制[22]。
注意力模型对BiLSTM的输出特征向量序列P进行处理,对每个特征向量赋予不同大小的权重,相加后产生新的特征向量,包含文本全局和局部特征。
注意力模型的当前状态ct由P中的所有特征向量加权后得到,计算如下:
(11)
式(11)中特征向量分配权重αtj通过式(12)和式(13)计算得到。
(12)
(13)
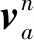

2.3.4 ATT+BiLSTM+CRF模型框架
引入ATT机制后的模型整体框架如图3所示。
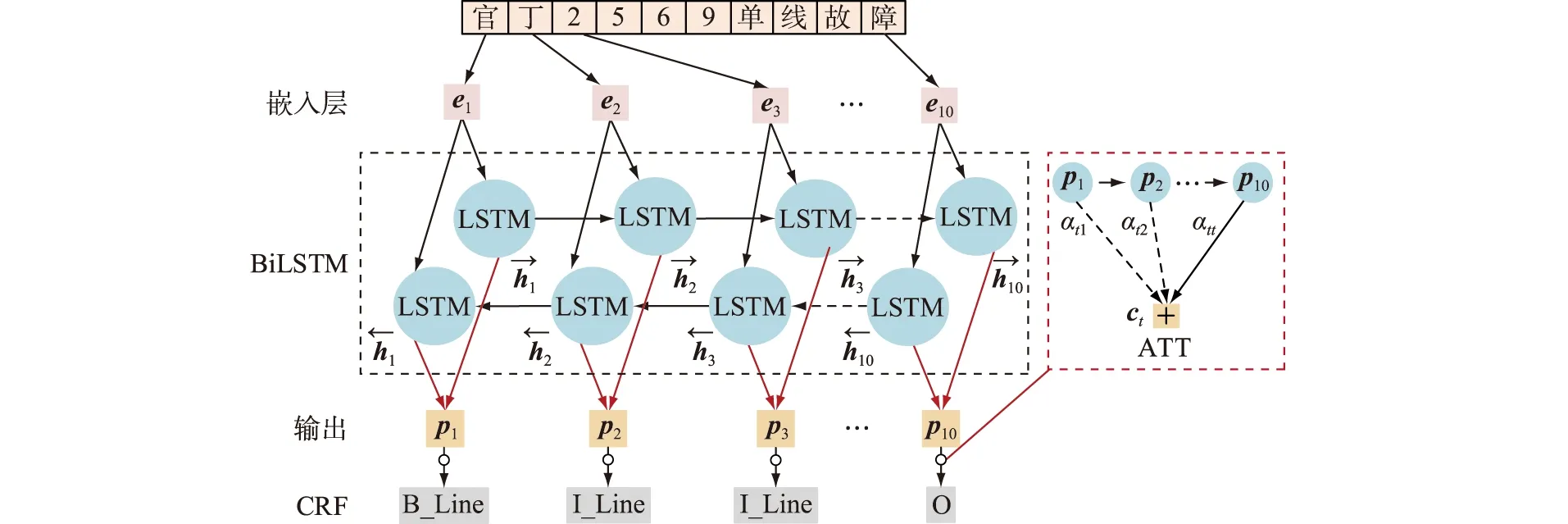
图3 基于ATT+BiLSTM+CRF的NER流程Fig.3 The process of NER based on ATT+BiLSTM+CRF
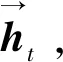
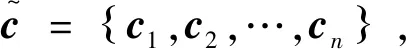
CRF模型计及标签之间的约束以及相关性,在所有备选标签序列中求得标签序列的最优解。最终识别“官丁2569单线”属于线路“Line”。
文中模型训练相关参数设置为:优化器为Adam;学习率取10-4;在 BiLSTM 两端增加比例为0.2的Dropout;最大迭代次数限制在100 000次;最大容忍次数earlystop设为5;批处理大小为50。
3 实验分析
3.1 实验数据和评价指标
文中研究的实验环境为 Intel(R)Core i7-8700 CPU 3.2 GHz处理器,16 GB内存,GPU NVIDIA 1080Ti,Windows10操作系统。字向量与训练语料为某电力调度机构的各类电力工作文档,选择开源Bert模型作为输入的分布式表示模型;BiLSTM网络由Tensorflow实现。NER语料为某电网故障处置预案2015年的历史版本,文本已分句并经人工标注,共计5 230条故障预案例句,按8∶1∶1的比例分为训练集、验证集、测试集。
电网故障处置预案中文NER的评价指标采用综合考虑查准率、查全率的F1测量值。
(1)查准率。查准率P计算公式为:
P=TP/(TP+FP)
(14)
式中:TP为正确识别为正样本的实体词数量;FP为错误识别为正样本的实体词数量。
(2)查全率。查全率R计算公式为:
R=TP/(TP+FN)
(15)
式中:FN为正样本中识别错误的实体词数量。
(3)F1测量值。F1值计算公式为:
F1=2TP/(2TP+FP+FN)
(16)
F1值综合考虑了查全率与查准率,能够更加全面地分析分类效果。
3.2 不同模型实验设计及性能对比
为了验证文中提出的故障预案文本NER框架的优越性,分别设计了6组实验。6组实验使用了相同的电网故障处置预案命名实体语料、字向量输入。实验1为基于BiLSTM的模型;实验2为基于人工特征提取的正则表达式添加CRF作用的模型;实验3为将实验2中的人工特征替换为RNN的RNN+CRF模型;实验4为将RNN替换为LSTM的LSTM+CRF模型;实验5为BiLSTM+CRF模型,实验6为文中模型即基于ATT+LSTM+CRF模型。
6组实验中的不同模型分别对电网故障处置预案中的9类实体词进行识别,获得的综合评价指标F1记录值见表3。
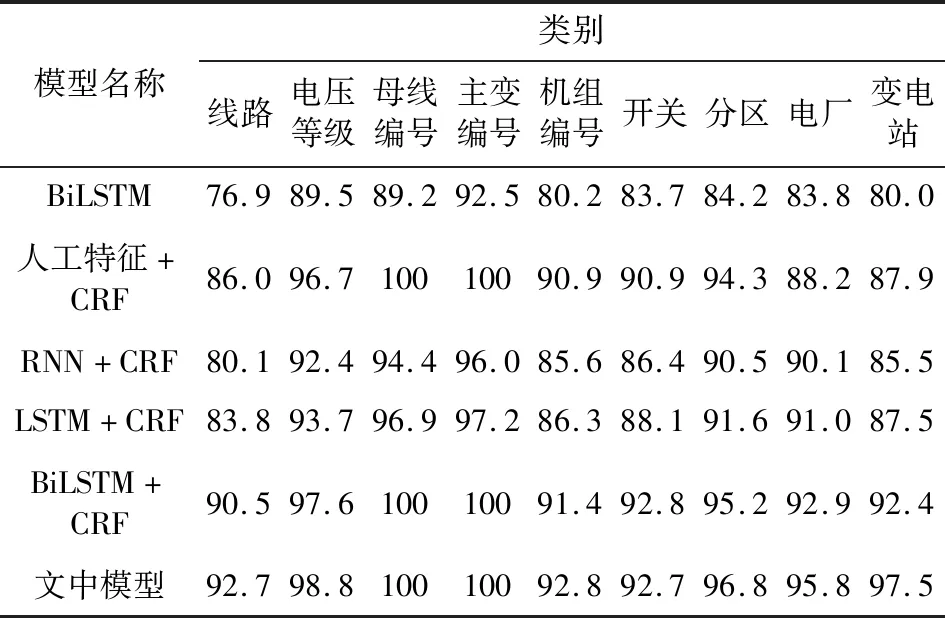
表3 各模型F1记录表Table 3 Record chart of F1 of each model %
由表3分析可知:
(1)LSTM+CRF模型的NER实验效果优于RNN+CRF模型,其中线路、变电站、电厂实体词识别效果值提高了3.7%,2.0%,0.9%,但是两者对线路、电压等级、主变编号等类别的识别效果未能超过基于人工特征提取的CRF模型,没有很好地体现自动特征提取的优势。而BiLSTM+CRF模型在识别线路、变电站、电厂等类别的实体词过程中较LSTM+CRF网络模型表现更加优异,F1值分别提升了6.7%,4.9%,1.9%,并且实现了对人工特征+CRF模型的超越。这是因为BiLSTM同时考虑了前序和后序内容,结合上下文语义信息更加充分地提取了文本字符特征。
(2)单独的BiLSTM模型取得的识别效果最差,而结合CRF模型后,识别效果显著提升,其中线路实体词的识别效果提升最高,F1值提高了13.6%,变电站、机组编号分别提升了12.4%,11.2%。结合具体文本内容分析,这是由于CRF模型计及了相邻标签关联性约束,从而能够更好地识别线路词中的长距离实体词。
(3)BiLSTM+CRF模型在电网故障处置预案文本中确实可以取得较好的识别效果,F1值可以达到90%以上,而引入了ATT机制后,实体词识别整体效果进一步提升,模型识别线路、电厂、变电站的F1值分别提升了2.2%,2.9%,5.1%,更加符合电网处置预案的识别要求。
4 结语
文中针对电网故障处置预案文本中关键信息辨识的任务,搭建了基于ATT+BiLSTM+CRF的电网故障处置预案文本NER模型,实现了故障处置预案文本关键信息的NER。
通过采用字向量特征表征文本,规避了专业领域词向量训练对于人工的依赖以及专业领域词向量表达能力差的缺陷。同时采用字向量可以更好地识别“官塘-丁卯2569单线”“官丁线”“官塘-丁卯”“官丁2569”等不同表述形式的线路实体词,提升了模型对于含复杂实体词电力文本的适用性。
基于ATT+BiLSTM+CRF模型可以综合考虑电网故障处置预案文本中的实体词长度较长,并列实体词的简写表达随意性大以及文本长距离造成信息丢失的问题,通过引入ATT机制以及BiLSTM,有所侧重地、自动地学习获取文本特征信息,降低了人工成本,提升了模型的泛化能力。算例表明文中所提模型可以满足电网故障处置预案文本的NER任务要求,为电力文本的NER提供有效路径。
通过故障预案文本中实体词序列准确识别,文本内容即可实现准确切分和词义理解,进而简化了文本句法结构和语义分析,为机器学习非结构化故障预案文本,搭建电力故障处置预案垂直知识图谱打下重要基础。
猜你喜欢
江苏安全生产(2024年1期)2024-03-07 09:31:26
新高考·高一数学(2022年3期)2022-04-28 07:02:46
仪器仪表用户(2021年10期)2021-11-27 08:26:02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
海外华文教育(2016年1期)2017-01-20 08:21:58
中国民政(2016年9期)2016-05-17 04:51:33
故事作文·低年级(2016年6期)2016-05-14 10:40:20
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
