
基于Squeeze-Excitation的音频场景分类研究
2021-10-10 03:56:12乔高杰廖闻剑
电子设计工程 2021年19期
乔高杰,廖闻剑
(1.武汉邮电科学研究院,湖北武汉 430074;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
音频场景分类(Acoustic Scene Classification,ASC)是计算机听觉场景分析(Computational Auditory Scene Analysis,CASA)[1]的子任务之一。声音场景特征是从来自不同声源的声音叠加所形成的一个复杂声信号中提取出来的一种高阶知识[2]。音频场景分类的目标是识别音频的环境,即将音频与语义标签关联起来[3]。
MIT 实验室早在1997 年提交了第一份有关于音频场景分类的技术报告[4],从那时开始人们逐步开展了对音频场景分类的探索工作。早期的音频场景分类长期受限于硬件计算能力和模式识别领域发展的瓶颈。当时,人们的主要研究思路和关注点都集中于音频信号的时间特征,因此他们通常都使用高斯混合模型(Gaussian Mixture Model,GMM)或者隐马尔科夫模型(Hidden Markov Model,HMM)[5-6]。随着持续不断提升的硬件计算能力以及深入研究的深度学习理论知识,很多研究者在音频场景分类任务中利用深度学习来进行研究。
奥地利约翰开普勒林兹大学计算感知系的研究人员开始尝试将深度学习方法应用到音频场景分类中[7],并且效果提升显著。在音频场景分类和声音事件检测(Detection and Classification of Acoustic Scene and Event,DCASE)挑战赛中,大多数参赛者均采用CNN[8-10]和RNN[11](Recurrent Neural Network)来进行实验。例如,在DCASE2016 音频场景分类任务中,研究者采用8 层VGG 样式的卷积层网络结构获得的平均准确率为83.3%[12]。在DCASE2019 音频场景分类任务中,研究人员采用8 层CNN 结合GNN(Generative Neural Network)等数据增强方法,获得了平均准确率为85.2%,并取得音频场景分类任务冠军[13]。
在2017 年的ILSVRC 图像分类任务中,参赛者提出了一种新颖的SE 模块,该模块能够提取特征图的通道间信息。在当时最优的CNN 模型中加入SE模块后,图片分类的top-5 error 下降到2.251%,因此参赛者获得了分类任务的第一名[14]。
目前,以对数梅尔谱为音频场景分类特征的任务与图像分类任务有相似之处,因此文中将SE 模块引入音频场景分类任务中。SE 模块能够得到不同特征通道的重要程度,并将这些信息加入原始特征中。
1 音频场景分类总体设计
1.1 声学特征
音频的特征多种多样,主要包括时间特征和频率特征,此外,相干声与环境声的提取[15]也获得了研究人员的关注。文中选取的声学特征为目前深度学习中普遍使用的对数梅尔谱图。因为对数梅尔谱图中包含了时间信息和频率信息,因此能够包含更多的音频特征。接下来对用到的主要内容进行简单介绍。
首先,将音频信号经过分帧、加窗和离散傅里叶变换,通过分帧和加窗可将时间跨度较长的信号裁剪为时间跨度小的帧,同时利用离散傅里叶变换将每一帧信号从时域转到频域,得到信号的频谱,之后将每一帧的频谱拼接成语谱图;其次,将上述语谱图的幅度谱通过设计好的梅尔滤波器组即可得到梅尔谱;最后,对梅尔谱取对数即可得到信号的对数梅尔谱图。
在相同距离的条件下,相较于高频信号,低频信号的衰减更小,并且人耳还存在掩蔽效应,基于以上特性,声学专家设计出了将声音频带从低到高按照临界带宽由密到疏地带通滤波器组,即梅尔滤波器组。
梅尔滤波器的设计首先将自然频率(fl,fh)通过式(1)转换到梅尔频率范围。
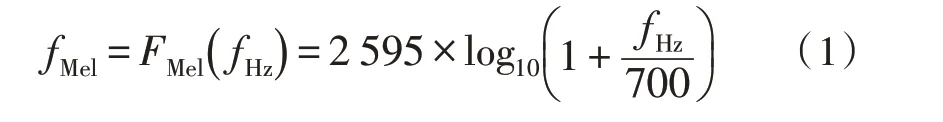
其次,在梅尔尺度下使用一系列等距的三角形带通滤波器组成梅尔滤波器组。假设M为滤波器的个数,第m个三角滤波器的频率响应如式(2)所示,其中,1 ≤m≤M。
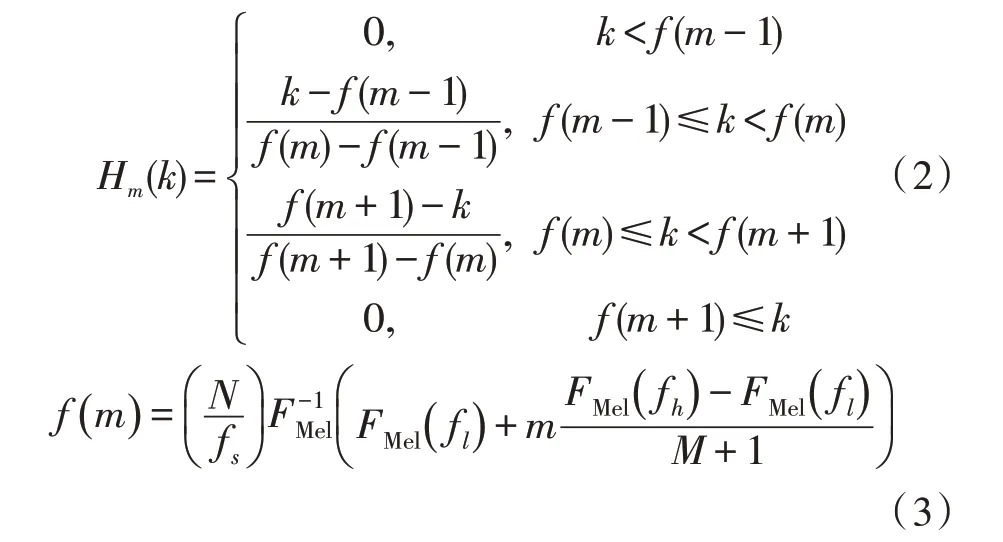
其中,f(m)为滤波器的中心频率,为式(1)的逆函数。
1.2 Squeeze-Excitation
卷积神经网络能够利用感受野感知空间并通过提升通道的数量对更深层次的特征信息进行提取,但通道与通道之间的信息却没有被关注到。为了考虑通道与通道之间的信息,在CNN 网络中加入Squeeze-Excitation 模块,并将通道信息加入到原始的特征中,进而神经网络可利用全局信息降低特征表达能力较弱的通道,而加强特征表达能力强的通道,并且可以自主学习到各通道对任务的重要性,从而提高网络对信息的表达能力。
Squeeze-Excitation的原理图如图1 所示,假设前面网络的输出的特征图为U,U的尺寸为(H,W,C),H、W、C分别为高、宽和通道数。首先将第c个特征图uc进行Squeeze 操作(记为Fsq),输出为zc,计算过程如式(4)所示。将所有特征图经过Squeeze 操作输出记为z,z的形状为1×1×C。
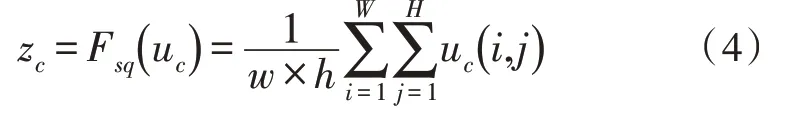
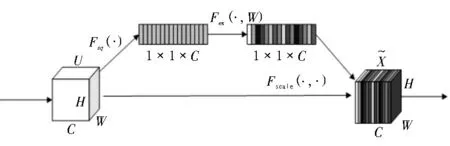
图1 Squeeze-Excitation的原理图
其次,将z进行Excitation 操作(记为Fex),结果为s,计算过程见式(5)。
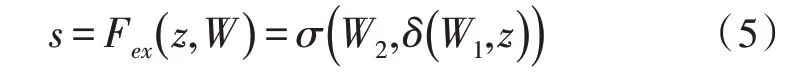
式中,W1和W2均表示全连接层的维度数,σ和δ分别表示sigmoid 和relu 激活函数。
最后,将经过式(6)Scale 操作(记为Fscale)的s加权给U,输出为。
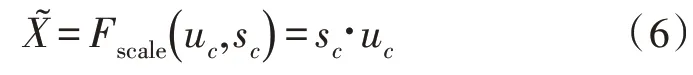
SE 模块的网络结构如图2 所示。首先,通过一个全局平均池化层压缩特征图的空间信息同时提取特征图的通道信息;其次,通过两个全连接层学习并融合通道维度的特征信息,与此同时,通过两个激活层Activation 1 与Activation 2 进行非线性地学习通道之间的信息并调整输出权重的数目。值得注意的是,Activation 1 和Activation 2 使用的激活函数分别是relu 和sigmoid。最后,将网络提取出来的通道信息以权重的方式添加到原来的特征中。
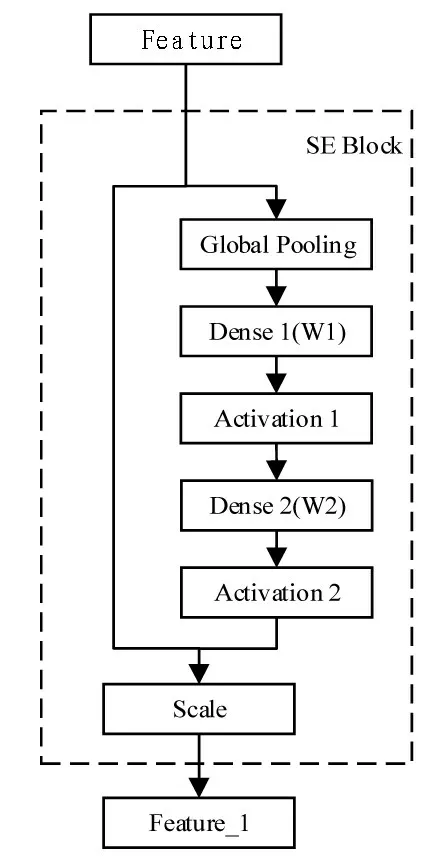
图2 Squeeze-Excitation的网络结构
1.3 网络结构
文献[9]通过实验证明了4 个卷积层的网络性能较6 个卷积层的网络性能好,同时浅层网络的计算效率高,占用资源少。文中采用两层CNN 作为分类器,基线系统的结构如图3 所示,两个卷积层均采用7×7的卷积核尺寸与全零填充,每个卷积层之后均采用了批标准化(Batch Normalization,BN)和Droupout 来防止过拟合。同时,除最后的分类使用softmax 作为激活函数外,网络均采用relu 作为激活函数。relu 函数相较于sigmoid 与tanh 等激活函数有着复杂度低、计算速度快和占用资源少等优点。
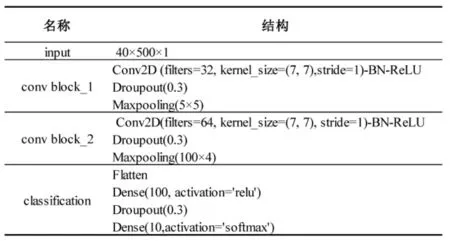
图3 基线系统的网络架构
实验的网络结构如图4 所示,Model A 和Model B在基线系统的conv Block_1 和conv Block_2 两个卷积块之后分别添加SE 模块;Model C 在基线系统的基础上,在conv Block_1 和conv Block_2 两个卷积块之后同时添加SE 模块。基线系统分别与Model A 和Model B 进行对比可以获取是否添加SE 模块的性能变化情况及添加SE 模块的位置对网络性能的影响;将Model A、Model B 和Model C 进行对比可以得到添加SE 模块数量对网络性能的影响。
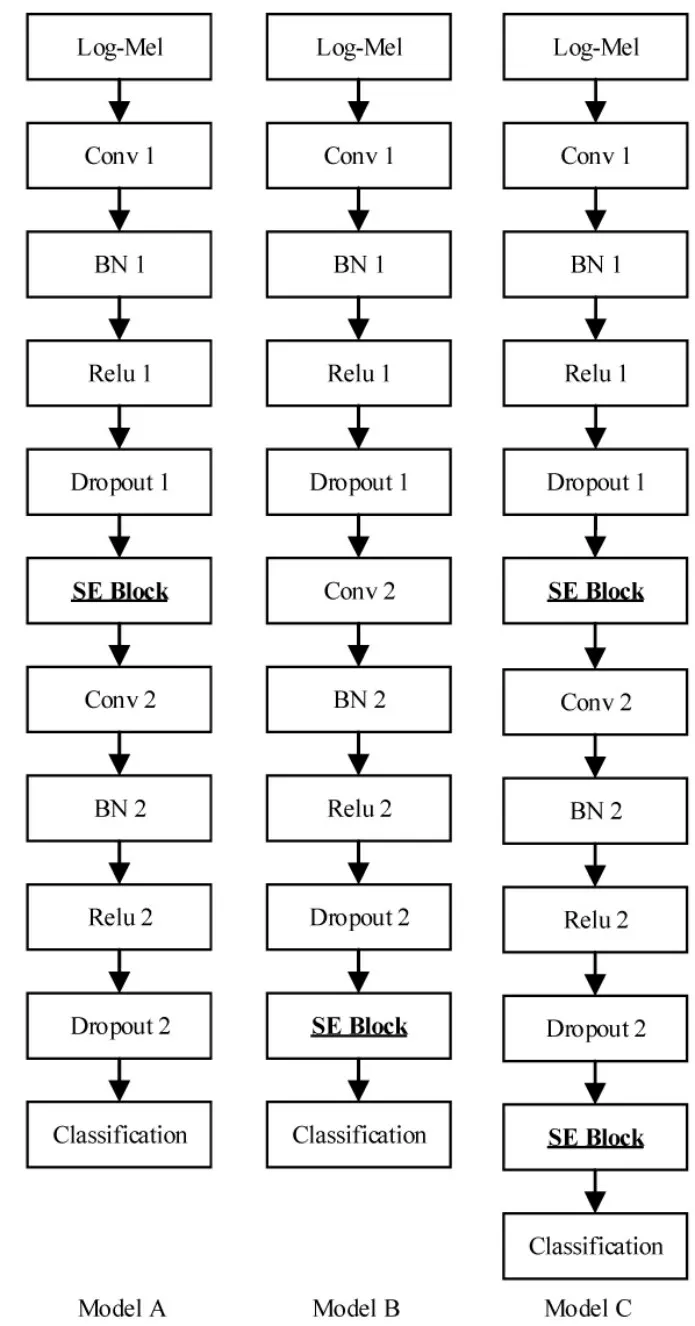
图4 实验中的模型结构图
2 实验数据和设置
2.1 实验数据
实验数据选择DCASE2019 中task1a的开发数据集[16-18]。数据采用的是双声道采样率为48 kHz,分辨率为24 Bit的设备进行采集。这些音频是在欧洲的阿姆斯特丹、巴塞罗那和伦敦等12 个城市进行录制的。整个数据集有14 400 个长度为10 s的音频数据,包括了飞机场、地铁站和广场等10 个音频场景。文中采用7∶3的比例划分训练集和测试集,同时训练集中30%的数据用于验证。
2.2 实验设置
首先,将10 s的原始音频信号转成单通道的音频,其次,对音频帧长为1 920 且帧移为960 进行分帧并使用汉宁窗,同时采用2 048 点的STFT 将信号转变到频域,得到语谱图,最后,对40 个梅尔滤波器组取对数得到音频的对数梅尔谱图。以上的特征均采用Python 音频处理的librosa 工具进行提取。最终,得到尺寸为40×500×1的对数梅尔谱图,并且将特征输入到CNN网络中进行进一步的深度特征提取。
实验硬件环境为Intel i7-9700K CPU、Nvidia GTX 1080Ti GPU 和16GB 内存。软件环境为Python 3.6、Tensorflow 1.12.0 和Keras 2.2.4。
3 实验结果与分析
文中通过相同的方式对上述的4 个网络进行训练,并利用测试数据测试模型的性能,具体的实验结果如表1 所示。根据表1 可知,基线系统的Model A准确率最低为62.1%,相较于基线系统准确率降低了0.6%;Model B的准确率最高为63.8%,相较于基线系统准确率提升了1.1%,相较于Model A 准确率提升了1.7%;Model C的准确率为63.0%,介于基线系统与Model B的准确率之间。

表1 不同模型的测试准确率
Model A 效果没有提升反而下降,究其原因或是加入SE 模块的位置过于靠前,通道数量不足而导致通道间的信息较少。而Model B的输入特征通道数量有明显增加,测试效果提升较大。Model C 中包含两个SE 模块,相较于Model B 性能有所下降,由此可见,并不是增加SE 模块的数量就能改善模型的分类性能,而相较于基线系统性能亦有所提升,再次证明了SE 模块能够提升网络的性能。
为了更详细地展现添加SE 模块后的模型分类效果提升,基线系统和Model B的详细分类结果分别如表2 和表3 所示。在基线系统中公园(记为park)场景的分类准确率最高为0.839,而Model B 中繁忙的街道场景(记为street_traffic)的分类准确率最高为0.846;在基线系统和Model B 中,分类准确率最低的场景均是公共广场(记为public_square),其中基线系统分类准确率为0.398,而Model B 中的分类准确率为0.452。
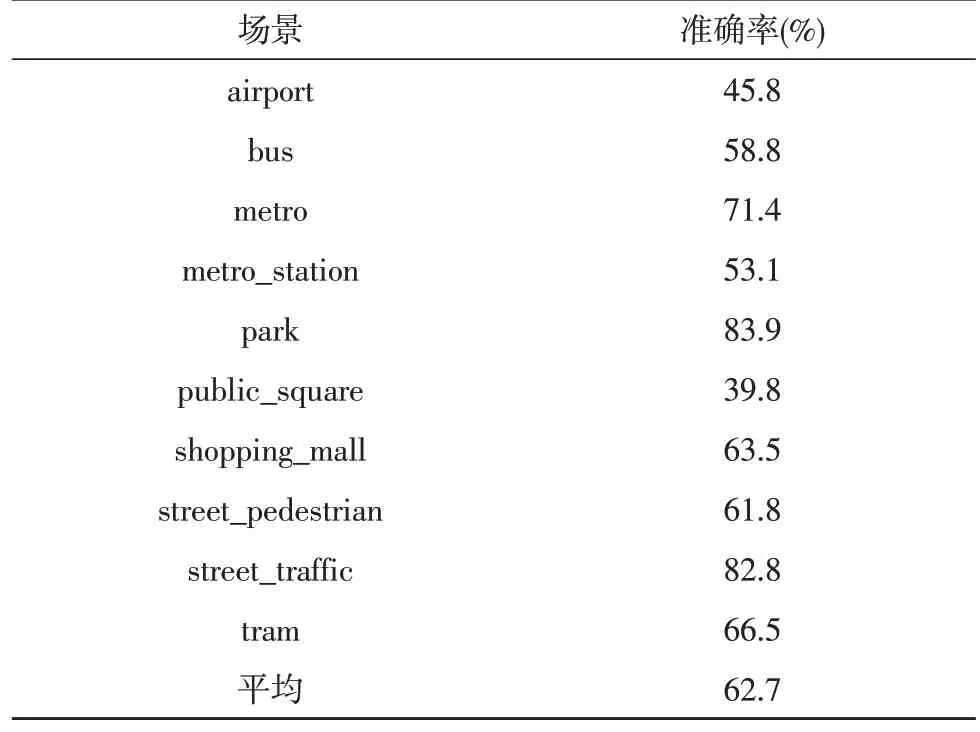
表2 基线系统分类结果
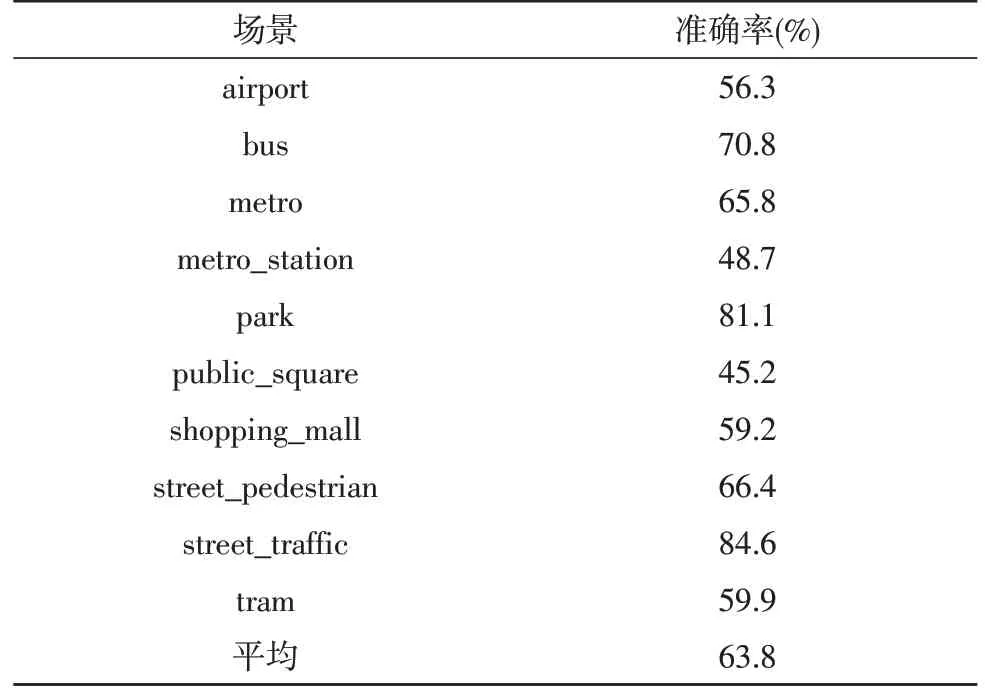
表3 Model B的分类结果
通过对比基线系统与Model B的分类结果可知,在飞机场、大巴、公共广场、步行街和繁忙街道5 个场景中,Model B的分类效果均优于基线系统;而在地铁、地铁站、公园、购物中心和电车5 个场景中,基线系统的分类准确率高于Model B。
上述分析表明,相较于基线系统,添加SE 模块在某些场景下的分类效果会下降,而在另外的场景下分类效果会得到较高的提升,总体上分类效果得到提高,且在通道数较多时添加SE 模块能更明显提升网络的分类效果。
4 结论
文中搭建了一个性能良好的音频场景分类系统,在基本的CNN 网络中加入SE 模块,充分地考虑了特征的不同通道间的信息,并对SE 模块在网络中的位置和数量进行了探究。通过实验对比可知加入SE 模块与普通的CNN 网络以及SE 模块添加位置和数量对整个模型分类效果的影响,验证了在通道数比较多时,加入通道间的信息能够提升模型的场景分类性能。
猜你喜欢
高技术通讯(2021年3期)2021-06-09 06:57:46
科学(2020年5期)2020-11-26 08:19:14
电子制作(2019年11期)2019-07-04 00:34:38
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电子制作(2018年16期)2018-09-26 03:26:50
电子制作(2017年9期)2017-04-17 03:00:46
舰船电子对抗(2016年5期)2016-12-13 08:41:14
系统工程与电子技术(2016年7期)2016-08-21 13:59:02
火控雷达技术(2016年2期)2016-02-06 02:29:00
