
基于聚类和关联规则的煤炭项目挖掘
2021-10-10 03:56商新新牟莉
电子设计工程 2021年19期
商新新,牟莉
(西安工程大学计算机科学学院,陕西西安 710048)
近年来,随着兖矿集团经营管理系统的不断应用,系统中积累了大量的历史数据。同时,集团每天都会产生大量的数据信息,不科学的数据处理方法会造成大量数据浪费。文中从数据本身出发,对传统管理系统产生的庞大数据进行提取、分析,从中筛选出能够影响企业发展的关键性数据。从大量数据中心发现隐藏的数据价值能够为集团的科学管理提供有效的数据支撑[1]。
在对数据进行离散化时,文中采用优化的K-means算法,主要针对项目完成属性描述,为关联规则挖掘提供有效的数据支撑。采用这种优化过的Kmeans 算法的原因是在传统的K-means 聚类[2]应用中存在收敛速度慢、收敛效果差以及分析结果不准确等缺陷,故文献[3]中提出改进退火算法,改进了K-means 算法的收敛问题。文献[4]为解决利用Kmeans 算法计算学生成绩不准确的问题,改进并提出了标准偏移量的K-means 算法。文献[5]中提出基于样本分布聚类中心强度的改进,并取得了较好的成果。因此,采用改变初始聚类的K-means 算法实现了对数据的聚类分析。
关联规则分析算法主要是为了发现答案量数据之间的关联性从而描述事物出现的规律[6],同时Apriori 算法也是关联规则中最常用的算法。但是传统的Apriori 算法只有支持度和置信度两个评估标准,导致挖掘的规则有时是人们不感兴趣或错误的。文献[7]中为了提高Apriori 算法的挖掘效率,提出利用分割-垂直数据格式整合的思想,对Apriori 算法提出改进。文献[8]中提出了基于二分法的改进Apriori 关联算法研究。文中提出了一种引入差异性思想的Apriori 算法对兖矿集团的项目信息进行关联规则分析。
1 算法建模
1.1 改进的K-means算法
K-means 算法是聚类算法中的经典算法,并得到广泛的应用。但是也存在许多缺陷,例如在运算过程中输入的参数范围越大越容易导致算法分散等。传统的聚类算法K-means 有两个参数;1)初始聚类中心,2)聚类数目[9]。且参数1)的选择是随机的,所以容易导致聚类的不稳定性。针对此问题,文中将采用文献[10]中的K-means 改进方法。通过改变初始聚类中心,寻找一个类内密集程度大的作为聚类中心,强度越大说明聚类的效果越好。
目标函数如(1)、(2)所示:
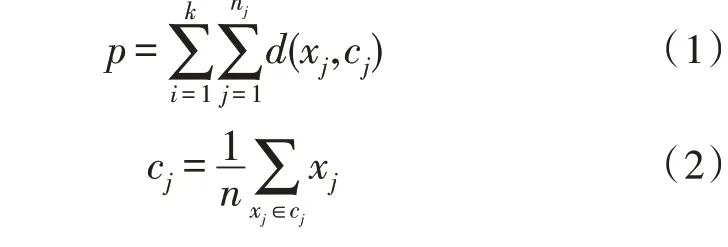
式中,p是所有数据的平方误差总和,由此可知同一聚类中的对象相似度较高;而不同聚类中的对象相似度较低。其中,ci是所有标记为i的数据xj和与标记为i的数据个数nj的比值,d(xj,cj)是数据xj与标记i的簇中心的欧氏距离。
改变初始聚类的K-means 算法步骤如下:
1)选择较可靠的数据样本集;
2)输入K值,选择初始聚类中心参数;
3)进行K-means 算法至迭代结束;
4)计算pi;
5)选择不同的聚类中心,循环2)、3)过程,直到p的值最小;
6)输出与最小p值相对应的结果,即为类内密集程度。
1.2 改进的Apriori算法
关联规则算法可以找出庞大数据库中不同因子之间的有趣关系[10]。假设关联规则描述为(X⇒Y),X为规则前件,Y为规则后件,规则支持度S(X⇒Y)如式(3)所示,置信度C(X⇒Y)如式(4)所示[12]。
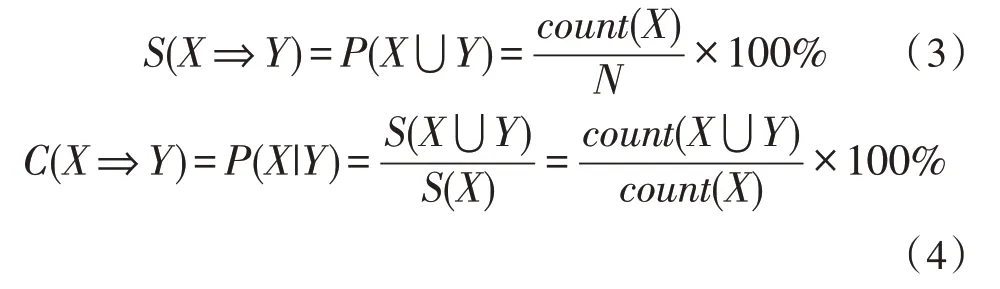
在频繁项集中,强规则是根据最小支持度和最小阈值来判断的。最小支持度一般是由经验丰富的管理者来制定,记作min_s(0 <min_s<1)。最小置信度表示Apriori 算法的最低可靠性,记作min_c(0 <min_c<1)。强规则要同时满足最小支持度和最小置信度。
1.2.1 差异思想兴趣度
文献[12]中收集整理了多个关联规则挖掘兴趣度模型的计算公式,包括影响兴趣度模型、信息量兴趣度模型、差异思想兴趣度模型、相关性兴趣度模型和基于概率兴趣度模型[11]。根据各方面的对比,文中将采用该文献中的差异思想兴趣度模型计算公式。将关联规则(X⇒Y)兴趣度表示为:
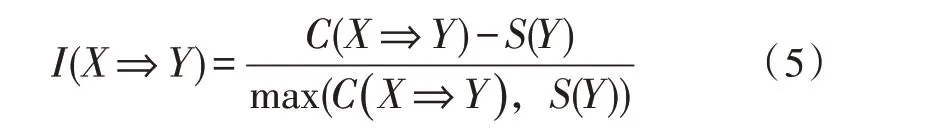
其中,C(X⇒Y)是关联规则(X⇒Y)的置信度,如式(4)所示;S(Y)是关联规则(X⇒Y)中Y的支持度,其值为count(X)/N。I(X⇒Y)的取值范围为[-1,1]。基于差异思想兴趣度模型的思想是由规则置信度和后项支持度的差异来定义的,其优点是可以删除不感兴趣的规则,消除规则后项的高支持率对规则的影响[12]。
1.2.2 引入差异思想的Apriori算法
经典的关联规则算法Apriori 算法,其核心是一种递推算法思想。传统的Apriori 算法的关联规则强度是由它的支持度和置信度来衡量的。但是仅凭支持度和置信度找不到准确、完美的关联规则。
针对以上问题,引入差异思想的Apriori 算法,再构建筛选后频繁项集的关联规则。兴趣度能够反映用户对规则感兴趣的程度,是针对用户兴趣综合性考虑的[13-14]。引入差异性思想的Apriori 算法的运行步骤如下:
输入:输入数据集D、置信度阈值、支持度阈值、兴趣度阈值。
1)找出所有频繁1 项集,通过扫描数据集D,设置K=1;
2)挖掘频繁K项集;
3)K=K+1,执行2)。
输出:将符合条件的规则输出。
2 挖掘案例集及结果分析
2.1 数据源
分析兖矿集团的六大资金模块中的项目信息,其中有207 个单位近5 年来积累的项目信息。六大资金数据包括技术改造、基础建设、科技开发、维检、修理费、生产安全。例如科技开发模块中项目信息包含单位名称、建设类型、建设规模、开工时间、投产年月、计划资金、调整资金、调整类型、完成投资等17个项目信息属性。科技开发模块部分原始数据如表1所示。
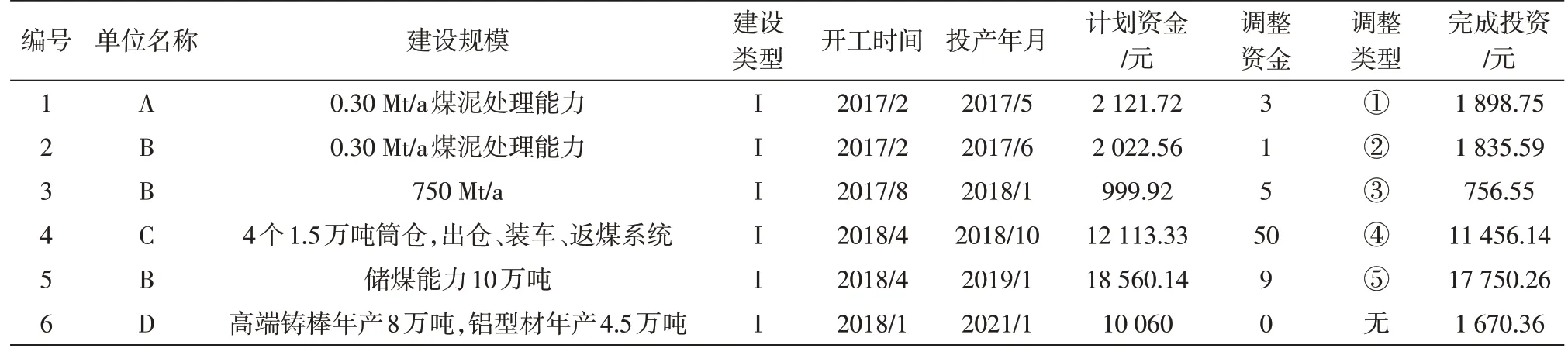
表1 部分原始数据集
2.2 数据预处理
由于现实中的数据是有缺陷的,所以为了使挖掘更加准确,就要对数据进行预处理。数据预处理如下:
数据清洗:去噪声和无关数据;
数据集成:将不同来源、格式、特点的数据集中存储;
数据变换:把原始数据转换成为适合数据挖掘的形式;
数据规约:缩小数据集规模。
2.2.1 数据清洗
为了方便研究,要对不同的项目属性信息进行调整统一。例如科技开发模块中的项目类型是由文字描述的;定义资金时单位为“万元”或是“元”,资金的单位标准统一;基本建设中的建设规模等。此外原始数据中存在大量的冗余数据,因此应将不涉及的数据项删掉。
2.2.2 数据离散化
原始数据经过数据清洗以后再进行筛选和转换,得到可利用的待测数据。由于文中研究的项目初始信息是按六大资金数据区分的。因此,针对这六大数据分别进行分析。将直方图划分成5 个部分:很低、很高、高、低、中,再将其转换为Apriori 算法的输入值[15],运行结果如图1 所示。
其中,技术改造数据398 组、基础建设397 组、科技开发399 组、维检409 组、修理费458 组、生产安全450 组。
项目的实施可能会受到不同因素的影响,例如施工单位、项目性质等因素,项目是否能按时完成的情况并不稳定,可能存在一些特征。图1 是按值划分后各类分布的直方图,从图中可以看出,项目信息的4 种情况中量级分化不是很明显,一般情况下都是按时完成,只有极少数的项目可能在某些因素下拖延完成、调整以后完成或是未完成。
从图1 中可以看出,六大资金项目的完成情况是比较稳定的。其中科技开发模块中项目是偏向调整后完成,且该模块中未完成项目比其他模块多。技术改造模块和基础建设模块中项目正常完成情况较平稳。
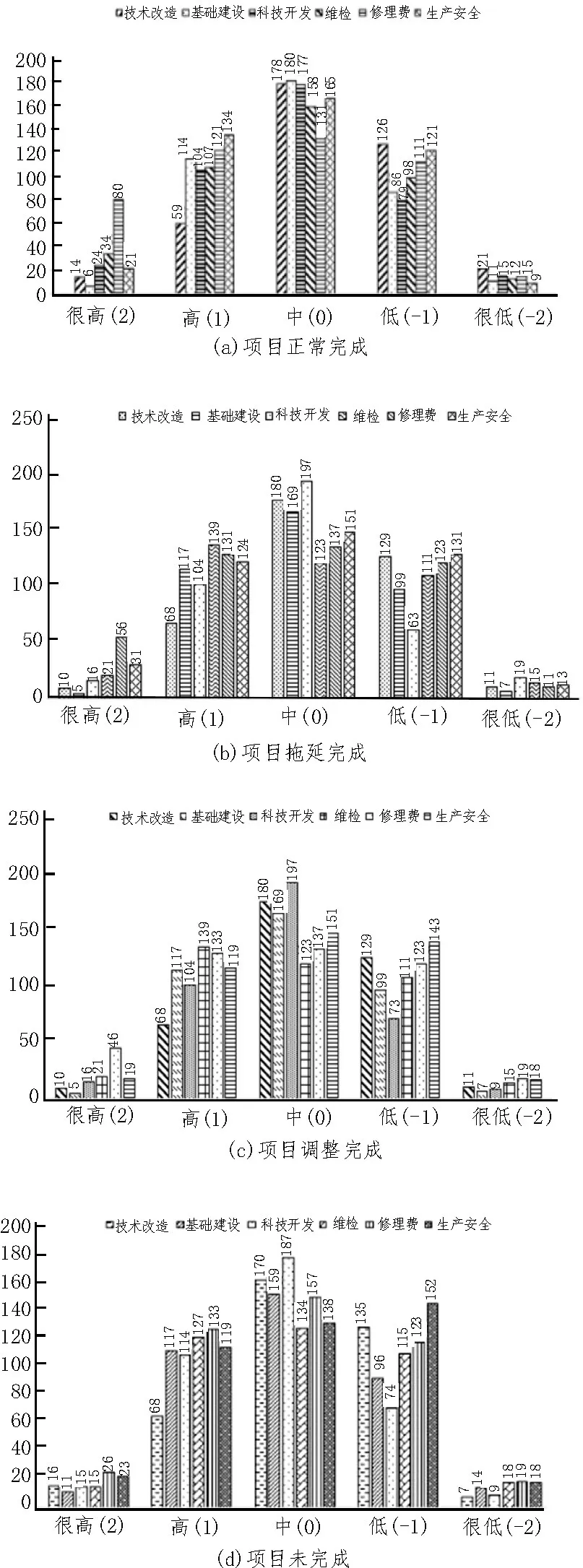
图1 六大资金项目完成情况划分
将K-means 数据离散结果交给集团管理者,为今后项目的管理提供参考数据。
2.3 挖掘规则及分析
文中引用差异思想兴趣度的Apriori 算法,通过对比传统的Apriori 算法[16]和引入差异思想兴趣度的Apriori 算法,可以看出引入差异思想的Apriori 算法的优点。组成3 种不同的参数,第一组:最小兴趣度Imin=0.5,最小置信度Cmin=0.3;第二组:最小支持度Smin=0.06,最小兴趣度Imin=0.5;第三组:最小支持度Smin=0.06,最小置信度Cmin=03。图2~4 所示为两种算法的规则变化情况。
从图2~4 中可以看出,改进后的Apriori 算法可以降低规则数量,提高挖掘的效率和质量。设Smin=0.065,Cmin=0.36,Imin=0.5,得110 条强规则,部分规则如表2 所示。
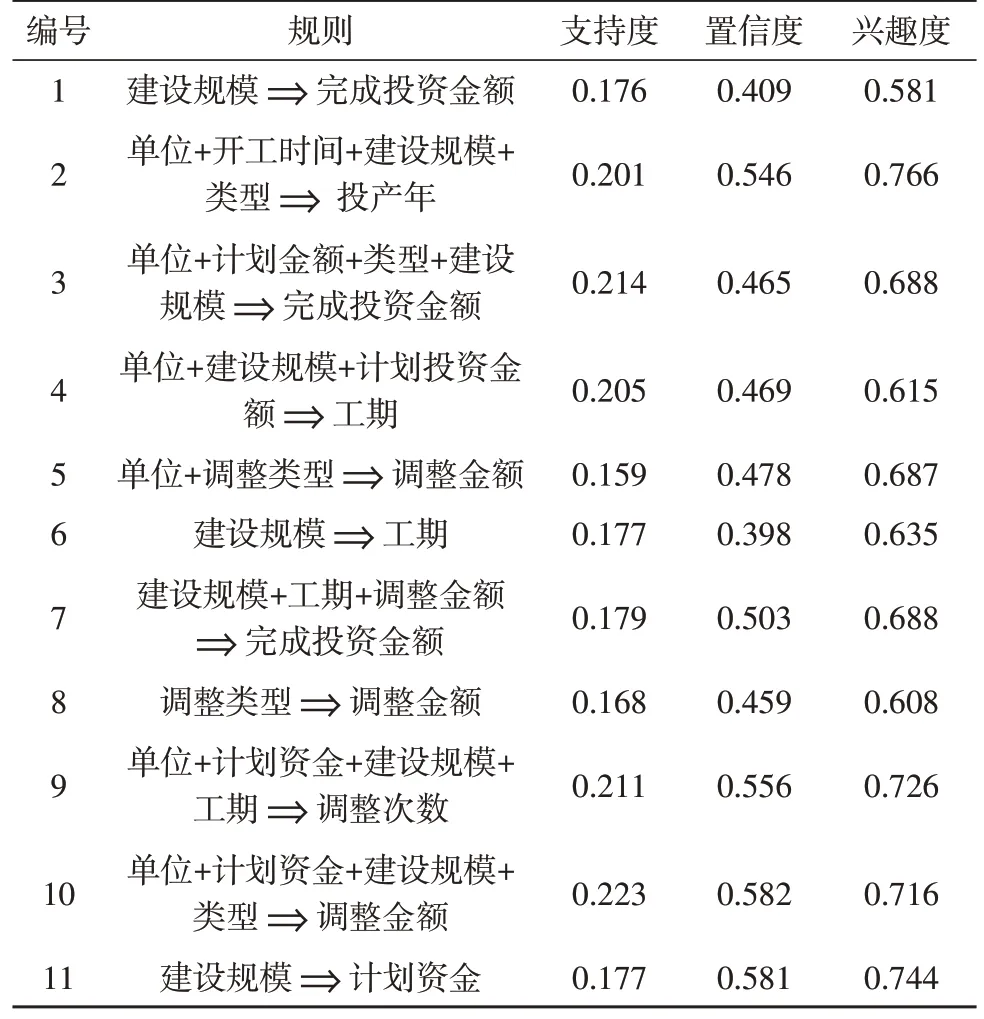
表2 科技开发挖掘规则部分展示
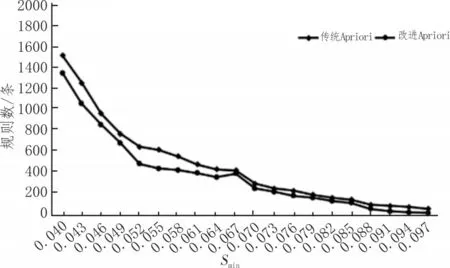
图2 不同的支持度下两种方法规则比较
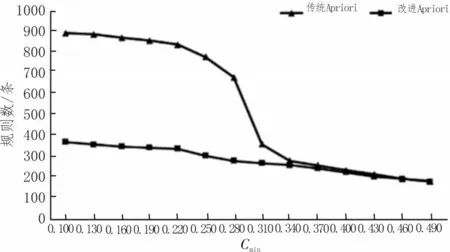
图3 不同置信度下两种方法规则比较
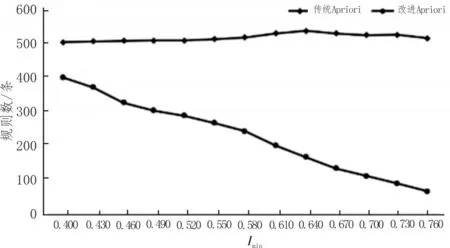
图4 不同的兴趣度下两种规则比较
从表2 中的规则1、6、11 可以看出,在得知建设规模的情况下,建设的规模越大该项目的投资金额越大,计划申报的资金额度越大,完成工期越长。项目的建设规模是在项目计划阶段最先考虑和最先确定的项目属性。同时从表中的规则2、3、4、9、10 可以看出,项目的建设规模完全影响管理者对项目其他信息的判断,例如项目的投产年分、工期长度、具体计划资金额度和最终完成该项目所需要的资金数。对项目的整体把握情况和根据此类型的项目预测其他相同类型的项目时,可以避免一些重复性的错误,提高项目完成效率。因此,集团应该加强项目前期工作中对项目规模的把控,正确判断建设规模。同时作为施工单位,根据项目规模更加精准地预测项目的计划数据,例如计划资金的申报等。
由表2 中的规则5、8、9 可知,项目在实施过程中,调整金额、调整次数受项目类型、单位、建设规模的影响。项目类型同样可以影响项目其他属性的重要项目属性,因此集团管理者应该加大对这些项目属性的重视,减少建设规模和项目类型对未来项目实施带来的不良影响。
3 结束语
历史数据的充分利用,对企业管理有着重要的作用,提取其中隐藏的有价值的信息,对今后企业集团的发展和管理有着战略性的意义。根据兖矿集团的实际情况和需求,采用改进后的K-means算法,引入差异思想的Apriori 算法对集团的历史项目数据进行离散、挖掘。首先在对历史数据进行离散时,采用改变初始聚类中心的K-means 方法,收到了较好的效果。再通过引入差异性思想的Apriori 算法对每一个模块中的数据进行针对性挖掘,提高了挖掘的质量。最后,得到的相关数据结果对今后集团项目的管理和未来项目的计划、审批有着重要的意义,提高了集团的决策力。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
新世纪智能(数学备考)(2021年9期)2021-11-24
铁道通信信号(2019年6期)2019-10-08
当代陕西(2019年15期)2019-09-02
计算机应用(2018年5期)2018-07-25
学苑创造·A版(2018年11期)2018-02-01
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
轴承(2015年2期)2015-07-25
电子设计工程(2015年6期)2015-02-27
