
基于机器学习算法的网络空间拟态安全分层检测技术
2021-10-10 03:55赵继业
电子设计工程 2021年19期
赵继业
(广东省中医院 信息处,广东广州 510120)
拟态安全防御主要针对网络空间中信息单一化的系统进行动态安全防御,以互联网为基础,构建防御体系一体化的基本拟态安全防御结构。应对基于未知漏洞后门或病毒木马等未知攻击时存在防御体制和机制上的脆弱性。由钓鱼、在服务软件中捆绑恶意功能、在跨平台解释执行文件中推送木马病毒代码、通过用户下载行为携带有毒软件等不依赖拟态界内未知漏洞或后门等因素而引发的安全威胁,拟态防御效果不确定。
文献[1]中应用以安全性能基本信息测试的方式融入互联网载体中,再应用互联网自身的防火墙系统进行网络空间拟态安全防御检测,这种方式下的网络空间拟态安全分层检测能够渗入至更深层的指令系统中,满足安全分层检测的深度性要求。文献[2]中的拟态安全分层检测技术主要基于动态化目标防御体系,在整个防御系统中引用动态化与随机性信息阻断技术,在黑客攻击的过程中需要突破阻断技术的拦截,且需要提高攻击成本。文中提出的基于机器学习算法的网络空间拟态安全分层检测技术,是一种既能防御又能检测的拟态安全分层检测技术。
1 网络空间拟态安全数据层提取
目前的网络空间具有多维性、高覆盖性特点,其中含有大量的审计数据以及分层数据,在高维度和大数据量环境下进行拟态安全防御与检测工作,将会需要巨大的时间与资源成本,为此需要将网络空间中的部分数据进行分层提取与降维处理,减少后期检测数据的划分困难程度[3-5]。
在机器学习算法中,进行网络拟态安全数据分层提取需要具体分析数据的种类特征,根据数据类型将数据归纳为标准数据样本,采用数据机器训练的方式对标准数据样本进行分类,但是面对网络空间中的高维度数据样本,需要随着维度的上升而提高机器算法的计算空间复杂度[6-8]。在机器学习算法中进行数据分层提取的过程中需要先确定数据,图1所示为降低数据维度技术实现流程图。

图1 降低数据维度技术实现流程图
数据特征的选择主要从子数据集合中提取具有相关安全性的特征子集,可以选择标准的数据样本作为数据分层的模板,通过对模板的特征分析能够区分分层数据中哪些数据具有哪些特征;还可以选择数据检索方式,在具有数据特征的网络空间中寻找最佳特征子集,实现此技术需要应用穷举算法,应用机器学习技术能够提升该算法的效率,但是在普通的分层数据安全检测技术中很难实现[9-10]。
在机器学习算法中,可以将数据特征类型划分为过滤式数据、包裹式数据以及嵌入式数据,针对过滤式数据特征的提取,需要选用一组标准的过滤式数据特征集合来评定过滤式数据的平衡状态,特征选取的过程是具有独立性的,在正常的数据维度状态下保证整个数据特征集合不出现最优的特征子集,将全部特征进行简单排序,再根据过滤数据中所需要的特征类型进行数据预处理,快速地排除数据特征中的干扰因子和噪声特征数据,逐渐排除非特征数据子集以及数据,实现数据过滤[11-12]。
包裹式数据特征的选择同样需要依靠机器学习进行初步的特征分类,在一定程度上确定特征包裹的重要性,根据包裹数据中内含数据结构与特征子集,判断数据提取过程中能够达到的分类精准度,此过程需要大量的数据迭代过程,具有较高的算法精准性与复杂性。嵌入式数据特征选择是机器学习算法中的分类过程之一,整个数据分类过程中需要结合特征子集的综合评价来进行,具有一定的智能性,不需要人为操作,同时也具有包裹式数据提取的精准性[13-14]。如图2 所示为数据特征选取流程图。

图2 数据特征选取流程图
2 拟态安全分层数据加密储存
网络空间中的数据储存拟态安全问题一直备受关注。是整个网络空间中存在潜在安全问题的关键部分,随着网络空间中的数据储存量不断增大,数据储存技术也随之改善,为了保障网络空间拟态安全分层数据的数据检测完整性,应用机器学习算法设计一套网络空间拟态安全分层数据加密储存方案[15-16]。
网络空间中的数据具有流动性,根据数据流动特征能够将数据加密方式划分为相应的角色,分别为可信密钥数据、网络数据用户集合、数据储存管理服务器以及数据访问管理员。数据网络中的用户可以通过相应的密钥数据对未知储存数据进行解析,将解析后的数据上传至访问文件中,数据访问管理员能够对文件中的数据进行提取并通过服务器对数据重新加密,方便后期的数据处理与网络空间分层数据的安全检测。加密储存方案的整体运行是通过动态实时控制加密实现的,具体的加密储存方案如图3 所示。

图3 加密储存方案
方案实现过程中首先需要通过网络空间中的用户创建数据储存信息,应用相应的加密公式完成密钥的设计,加密公式如下所示:

其中,M代表加密数据的储存密钥参数,m代表网络空间中用户的密钥管理服务器生成的序列,F代表随机生成序列中的加密文件。整个加密过程中出现的密钥相关数据均可以保存在公式中,通过公式中的用户端口与网络空间拟态空间数据加密信息进行密钥与私钥之间的相互转化。
整个网路空间拟态安全分层数据上传与储存的过程中需要对可访问信息的用户身份进行确认,通过可信第三方的精准确认方可利用机器算法中的相应公式来生成数据储存密钥。密钥可以交给服务器管理,同时还可以进行密钥备份,但经过备份的密钥同样需要依靠服务器的精准控制,修改权与调节权均需要通过服务器才能更改。网络空间拟态安全分层数据储存后的读取过程同样需要依靠网络用户的识别认定,文件系统中待读取的访问数据获取文件名称后需要针对访问对象进行元数据的控制层处理,控制层请求合法操作,向网络空间用户发送相关请求,用户接受请求后方可进行储存数据读取,此后储存数据编码层便可以根据编码与密钥之间的参数进行数据拼接,可以退出源文件,还可以继续加载源文件,将源文件中的加密数据传输给解密文件,最终利用解密程序完成储存数据的读取。
3 拟态安全分层检测算法
机器学习算法在数据识别与预测功能中有着较强的优势,广泛分布性与容错性均能较快地适应相关数据环境,在网络空间拟态安全分层检测过程中应用反误差式机器学习算法能够更有效地识别安全异常数据状态,该算法包含拟态安全数据的输入层、隐藏层与输出层,具体的神经网络结构如图4所示。

图4 神经网络结构图
神经网络结构中机器学习算法的实现主要分为两个过程,首先是将算法中待计算的数据传输到输入层,应用隐藏层内存在的网络节点进行数据运算,其中隐藏层只能接收网络节点中的输入层数据,此时输出层内的处理算法为等待状态,实时接收检测算法的数据代入;另一过程是应用输入层的待计算权值逐层地对误差进行修正处理,不断反馈误差与目标函数之间的距离,最终达到拟态安全数据检测的标准值即停止算法的继续运算。设定算法中的输入层样本数据为x=1,2,3,…,网络结构中的维数为N,神经网络中节点数据输出值为O。
网络节点中计算误差距离的函数为:
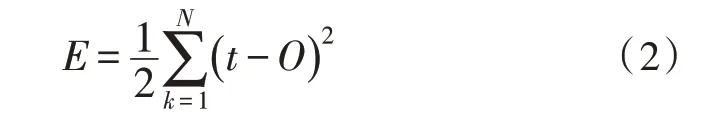
其中,E代表误差权值,t代表误差代入系数。网络空间结构中会因机器算法的应用而识别出隐藏数据节点,节点中数据安全检测输出函数为:

其中,w、y代表节点数据中的输出参考系数。
4 实验研究
为了能够具有更稳定的实验环境,在Windows平台上利用Python 3.6.4 进行实验,编程工具为Pycharm,CPU 为Intel i5-6300HQ,内存为8 GB。以IEEE-33 节点为例,额定电压为12.66 kV,共有37 条支路,5 条馈线处于常开的状态,各馈线的备用容量为300 kW,全部负荷的有功功率为3 715 kW,无功功率为2 300 kVar。节点模型如图5 所示。
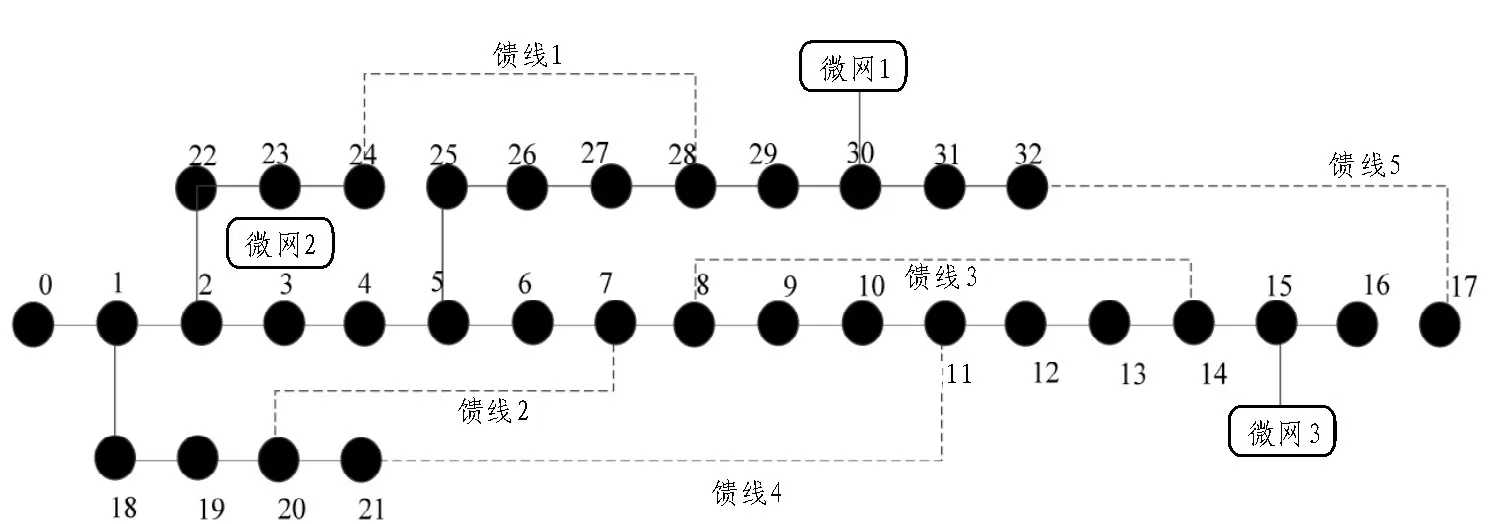
图5 节点模型
文中在3 种技术的检测信道中添加拟态控制协议,有利于数据的变化与运行,协议中主要通过协议消息的数据类型判断数字型与文字型的安全等级,协议与协议之间需要插入相应的交换机与虚拟机进行数据转换,保障安全拟态环境检测的顺畅。
首先对文献[1]技术、文献[2]技术、文中技术的拟态安全分层检测范围进行比较分析,结果如图6所示。

图6 拟态安全分层检测范围比较结果
根据图6 中的对比结果可知,文中技术对网络空间的拟态安全分层检测范围更广,相比于其他两种技术提升近10%。在相同的数据环境下文中技术能够及时对不同种类特征的数据进行识别与检测,且能够降低相应的数据维度,能更加广泛地进行检测数据拓展,随着检测时间的增加,该文检测范围以每十秒20 MB的数据量拓展,而文献[1]技术、文献[2]技术检测范围变化较为平稳。
误差的消除率是检测技术成本的重要决定因素,图7 为误差消除率对比结果图。

图7 误差消除率对比结果
根据对比结果可知,文中技术的误差消除率较高且稳定,始终保持在70%左右,而文献[1]的误差消除率会随着数据类型的变化而变化,变化范围较大,在20%~70%之间浮动,文献[2]的误差消除率较稳定,在50%左右浮动。
图8 是故障中含微网的配电网供电恢复后各节点的电压与故障前的节点电压对比结果。

图8 各节点电压的分布
采用微网和馈线共同对失电区进行供电恢复后,最低电压节点的电压明显升高,系统电压的整体运行水平有所提高,系统稳定性增强。
5 结束语
网络空间中攻击手段的多样化,为网络用户的信息安全造成较大的威胁,为此需要在网络空间中进行拟态安全分层检测,提高网络空间中的攻击手段识别度,该文基于机器学习算法研究网络空间拟态安全分层检测技术,从数据维度、安全特征以及加密储存程序方面进行设计,改善了传统技术中存在的缺陷。
猜你喜欢
小哥白尼(趣味科学)(2021年5期)2021-08-13
今日农业(2020年24期)2020-12-15
公民与法治(2020年4期)2020-05-30
学苑创造·A版(2019年12期)2019-01-10
传媒评论(2018年8期)2018-11-10
北方文学(2018年2期)2018-01-27
中国公共安全(2017年5期)2017-09-04
网络与信息安全学报(2016年2期)2016-06-15
中国现代医学杂志(2015年26期)2015-12-23
新闻传播(2015年10期)2015-07-18
