
基于混合神经网络的语言文本分类方法
2021-10-10 03:55谷文静
电子设计工程 2021年19期
谷文静
(西安航空职业技术学院,陕西西安 710089)
随着互联网信息技术的发展,海量数据是其最显著的特征之一。同时,随着互联网媒体平台的建设与发展,移动互联网的日趋普及,人们逐渐喜欢通过互联网平台来发表自己的观点,这也造成了网络文本数据的激增。对这些数据进行有效的筛选和分类,有助于网络提供商对用户的喜好进行发掘。因此,对自然语言的文本数据分析已成为当前业界研究的热点[1]。
单从文本分类而言,其指的是在人为规定好的分类标准下,根据文本自身含义对文本数据进行分类的过程[2]。文本分类是搜索引擎、消息过滤等功能的重要实现部分,其应用场景比较广泛,例如消息分类、评价分类以及分析垃圾消息等。
传统的文本分类方法使用机器学习技术,这些方法对于英文自然语言通常有文本特征不明显、训练周期长、词序丢失等缺点[3]。针对以上不足,文中对Word2vec 算法与TF-IDF 算法进行融合,改进为TF-Word 算法,同时应用卷积神经网络组成混合神经网络模型实现文本分类,该方法可以有效提高传统文本分类方法对于英语语言的处理精度。
1 文本分类方法
图1 是当前文本分类的主流处理过程,分为文本预处理、文本特征提取、文本特征表示以及文本表示几大步骤,各个步骤的研究现状介绍如下。

图1 文本处理流程图
文本预处理:该步骤为文本分类前的预处理步骤,主要是对句子进行成分的分离。句子分离算法分为基于语义句法和基于统计学的方法,而随着人工智能技术的发展,目前基于机器学习的算法,例如LSTM、CRF 等,成为当前主流的算法[4]。
文本特征提取:一般常用的算法为信息增益法与卡方检测法,即通过检测词频,对出现频率较低的特征词进行删除和区分处理。而随着技术的发展,基于Word2vec 向量的算法成为该阶段热门的选择,较多学者均使用该方法提高特征提取的精度[5-7]。
文本特征表示:常用的算法为组网法和逆词频法。组网法指的是对当前已知的词汇词性进行分类,之后组成语义网,对文本的特征进行表示。该算法可以提升句子本身的语义性质,但计算量庞大,算法成本相对较高。而逆词频法通过对词语的重要性进行排序,进而实现特征表示,也有学者使用该方法对词语进行词性、聚类分析,效果较优[8-9]。
文本表示:该方法包含离散表示法和独立表示法。常见的算法为词袋模型,该模型将分割好的词语看作是没有规则顺序的词语集合,通过分类器(神经网络、向量机、KNN 等)训练这些集合,进而达到文本表示的目的[10-11]。
2 基础算法模型
2.1 Word2vec模型
Word2vec 模型是统计语言学模型的一种,该模型由Mikolov 提出[12],模型可以对句子单词与单词中的关联程度进行衡量。同时可以准确、高速地对词向量模型进行训练,该模型的目的是从大量的文本数据中对高质量的词向量进行训练。模型内部架构关系如图2 所示,该模型的内部由CBOW 与Skip_gram 两个子模型构成,该算法在特征提取方面具有突出的优势。
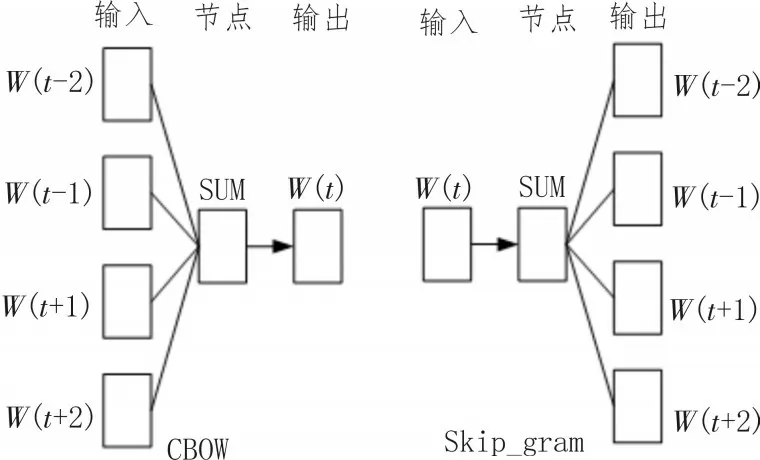
图2 CBOW模型和Skip_gram模型示意图
2.2 TF-IDF模型
在句子中,最基本的元素就是单词,单词的词频指的是某一个特定的单词在句子中出现的次数。统计学公式如式(1)所示。
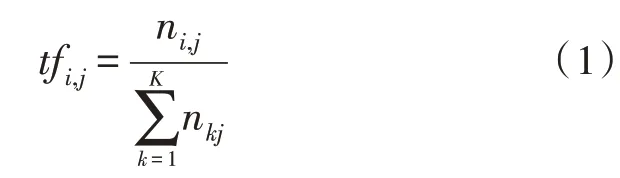
而逆向文档频率(IDF)表示的是某一个单词在句子中的特殊性与重要性,具体表示为句子总数目和包含此单词句子数目的比值,如式(2)所示。
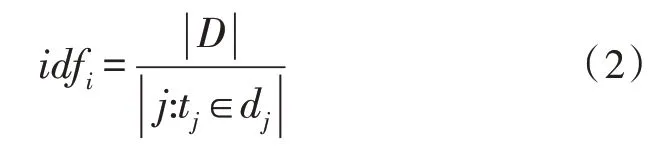
在使用时,若一个单词在句子中出现的频率较高,则该单词可以对句子的特征进行表示,即该单词的TF-IDF 值较高;若一个单词在句子中出现的频率较低,则单词的TF-IDF 值较低,该单词不能对句子的特征进行表示。
2.3 文本卷积神经网络模型
文本卷积神经网络(TextCNN)是文本分类领域中被广泛使用的承载算法模型,下面对其结构进行介绍[13]。
神经网络模型的主要结构有:
1)嵌入层:该层为模型的输入层,输入数据格式为词语向量矩阵。
2)卷积层:该层使用卷积计算对文本的特征进行提取,是神经网络的算法核心。词卷积的计算,如式(3)所示。
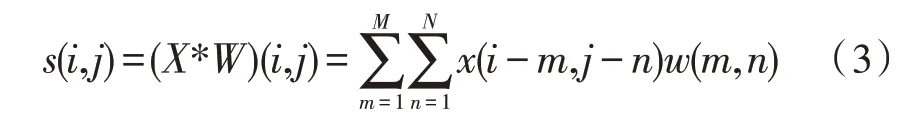
3)池化层:该层是对卷积层的输出结果进行简化采样,进而优化卷积层的运算步骤,减少模型中的参数,通常使用的池化模型为K-max,即选择卷积层输出的k个特征,对这些特征进行分析,使用最大的特征向量代替其他向量。
4)输出层:输出层为最终输出的词向量,输出概率分布结果,该结果使用梯度下降公式进行计算,如式(4)所示。
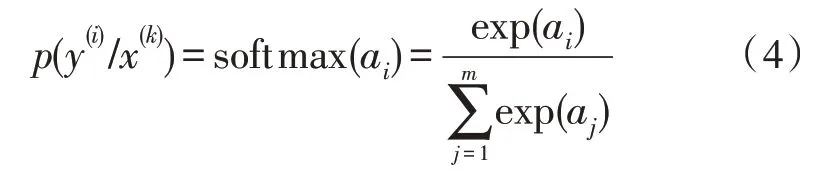
3 模型构建
3.1 基于TF-IDF和Word2vec的改进算法
由上文分析可知Word2vec和TF-IDF算法的优缺点。Word2vec 算法可以对句子中单词与单词的关系进行表示,但是却无法反映单词在句子中的重要程度。而TF-IDF 算法却恰好相反,该算法可以反映单词在句子中的重要程度,却无法反映单词与单词之间的关系。因此,文中将这两种算法的优势结合,如式(5)所示。
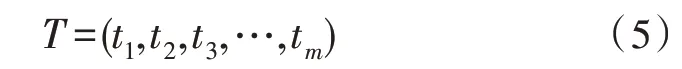
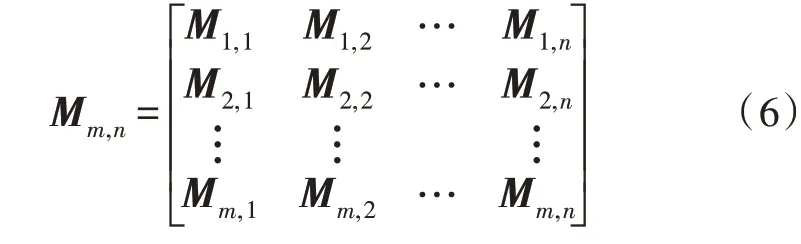
对于某个单词数量m个的句子而言,使用TFIDF 算法的判断,可以得到长度为m的向量,上式中tm为单词的TF-IDF 值。而在Word2vec 模型中,句子中的词语均可以被一个固定长度的向量进行表征。因此,可以得到如式(6)所示的矩阵。
对这两种模型进行结合,即对每个词语的TFIDF 值和Word2vec 值进行结合,得到如式(7)所示的矩阵。
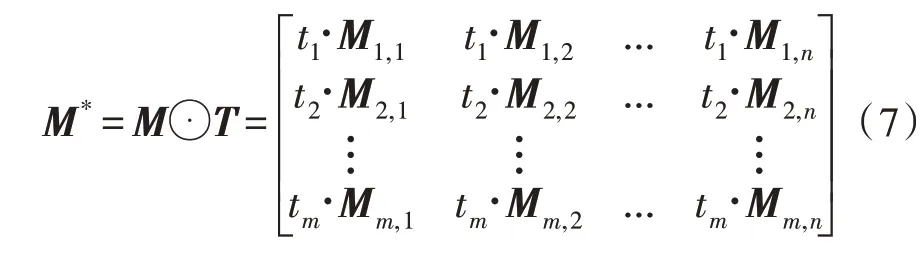
该矩阵既可以对单词之间的相互联系进行表征,又可以对单词的词频进行表示,将改进后的模型命名为TF-Word 算法。
3.2 基于TF-Word的混合神经网络模型
将TF-Word 作为神经网络的输入层,构建混合神经网络模型,如图3 所示。
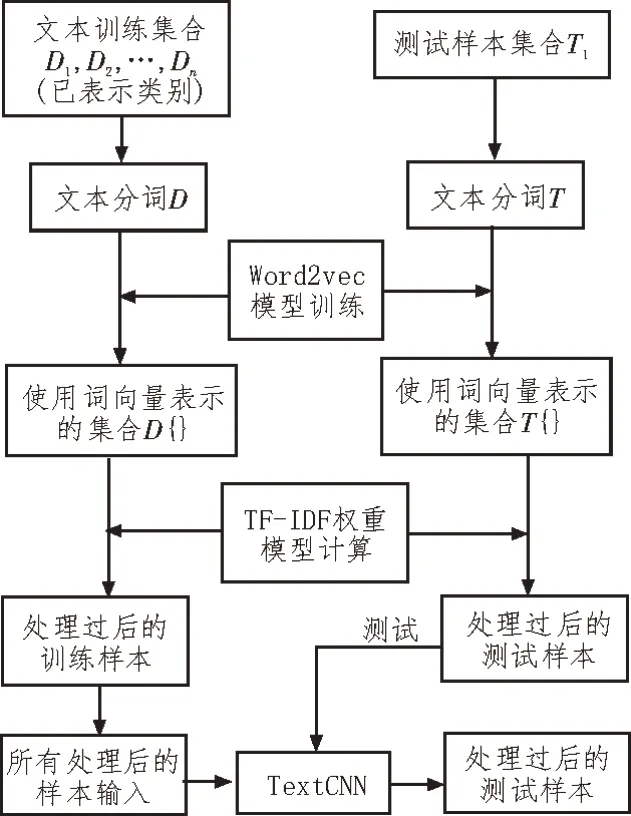
图3 整体模型构建示意图
算法的执行过程如下:
1)单词库构建。单词库包括训练所需的样本集合,单词库的获取一般有两种方式,包括使用开源的词汇库以及自行训练词汇库。该文使用RCV1-V2数据集合,该数据集中的内容大多为英文的新闻文本,数据集合数量约为70 万个,足够算法训练模型使用。
2)得到模型的权重公式。首先对输入的数据进行分词处理,处理完后计算单词的权重数据,如式(8)所示。
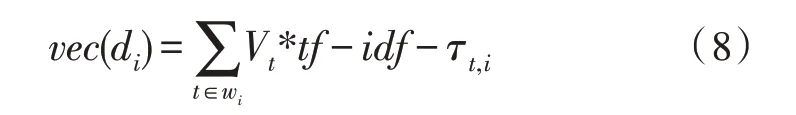
3)构建卷积网络模型。卷积网络模型如图4所示。
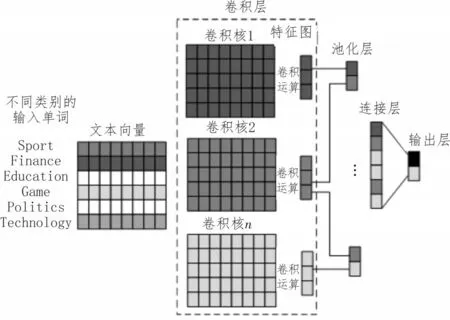
图4 卷积神经网络示意图
卷积网络模型如上文所述,由输入层、卷积层、池化层、输出层四部分组成。其中,输入层数据为经过TF-Word 算法处理过后的数据,则输入模型为一个单词向量矩阵。卷积层使用长卷积方式,如式(9)所示。
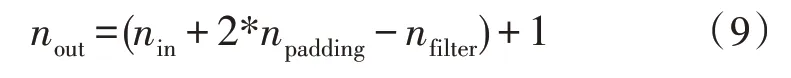
池化层使用1/2 池化算法,这样可以将卷积层输出的数据长度减少一半,有效减少模型计算的工作量。
4 实验与分析
4.1 实验环境搭建
该次实验数据集选择RCV1 数据集合,实验环境使用PyTorch 对卷积神经网络进行编程。RCV1 数据集合为新闻文本数据集,该集合有大约70 万条的新闻文章条数。文中测试环境如表1 所示。

表1 测试环境说明
卷积神经网络按照3.2 节中所述进行搭建。神经网络的参数如表2 所示。
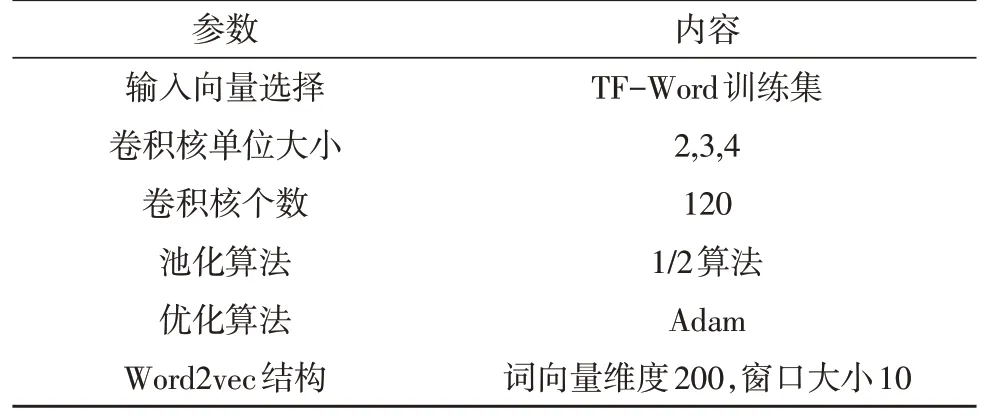
表2 神经网络参数说明
4.2 实验测试
通过构建卷积神经网络模型,使用RCV1 训练集对该次搭建的模型进行训练,再使用测试集合对模型进行多个方面的测试,测试指标分别为精确度、召回率以及F1测量值[14-15]。其中,精确度定义为在分类之后,样本能被正确归类的比率;召回率指的是分类后正确的测试样本个数占据所有正确测试样本的比率;F1 即为精确度和召回率的综合加权结果。对不同领域的词进行分类评价,评价指标如表3 所示。
由表3 可知,此次测出的精确度、召回率以及F1测量值指标平均值为96.92%、95.43%与96.22%。
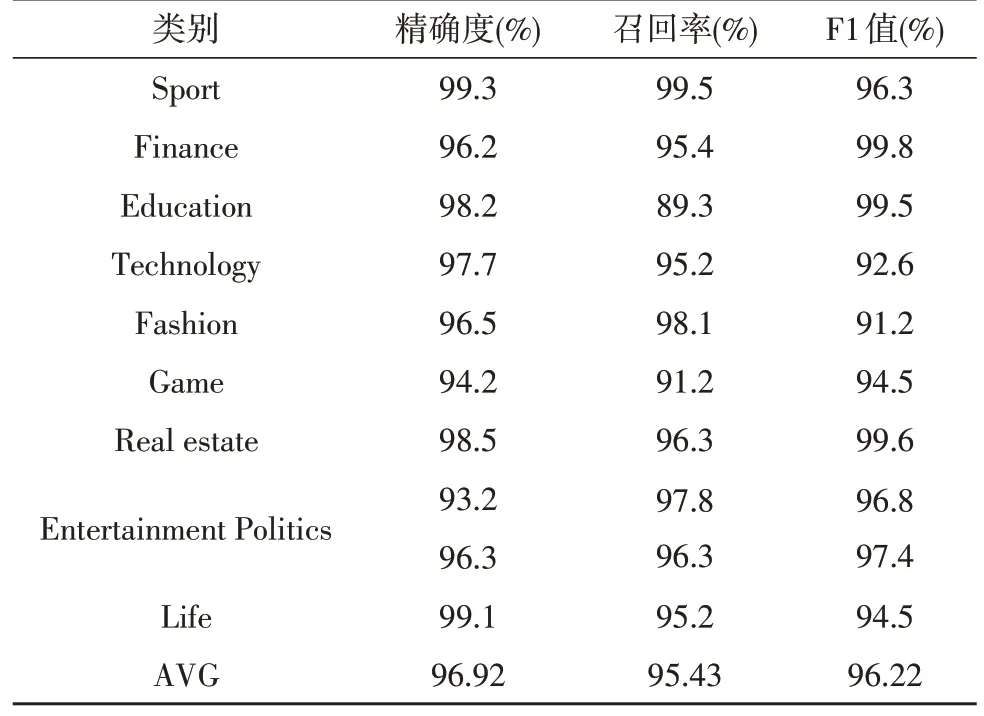
表3 模型测试结果
对比的实验方法使用传统机器学习文本分类方法,对英文自然语言进行处理,分别采用朴素贝叶斯算法(NB)、支持向量机(SVM)、K 近邻法(KNN)展开测试[16]。测试结果如图5 所示。
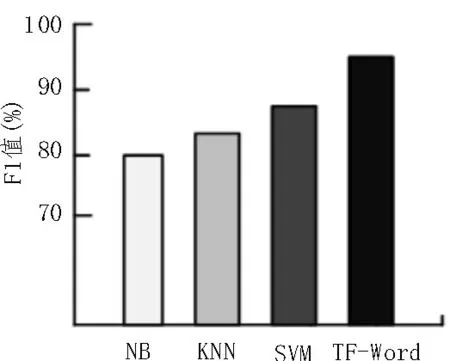
图5 对比测试结果
由图5 可知,文中所构建算法模型的F1 值相比于NB 算法提升了18.5%,相比于KNN 算法提升了14.3%,相比于SVM 算法提升了12.9%。
图6 所示为训练的文本数量对F1 值的影响。由图可知,训练文本数量越多,算法准确度越高。
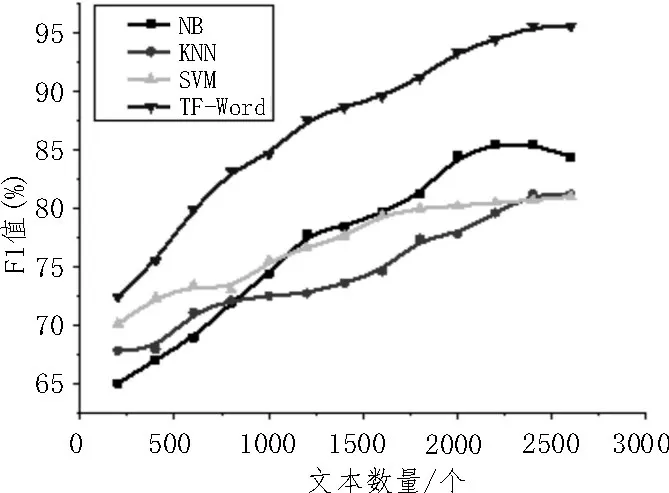
图6 文本数量对F1值的影响
综上所示,文中构建的模型准确度要优于传统的机器学习算法。故将文中所提出的自然语言处理方法应用在机器翻译领域时,可以有效提高英文长句的翻译准确度。
5 结束语
传统文本分类方法对英语语言进行智能分析处理时,存在文本特征不明显、训练周期长、词序丢失等缺点,文中通过将Word2vec 算法与TF-IDF 算法进行改进融合,提出了一种TF-Word的新算法。同时应用卷积神经网络组成混合神经网络模型,最终实现文本分类。由实验结果可以看出,对英文自然语言的智能化处理而言,文中所构建的算法模型相比于传统算法模型,在性能上有显著提高。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
阅读(快乐英语高年级)(2020年8期)2020-01-08
电子制作(2019年11期)2019-07-04
智慧少年·故事叮当(2018年11期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
意林(绘英语)(2017年5期)2017-05-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
