
基于改进CMA-ES算法的无人驾驶运动行为智能训练
2021-10-09 01:09马亚丹邹佳丽
湖北民族大学学报(自然科学版) 2021年3期
马亚丹,邹佳丽
(郑州西亚斯学院 电子信息工程学院,郑州 451100)
在日常生活中,车辆的驾驶控制不仅枯燥而且存在着危险[1],驾驶员需要时刻保持注意力集中,且存在自身疲劳、大意等身体局限性,无人驾驶技术可以在一定程度上让驾驶员从枯燥繁琐的驾驶行为中解脱出来[2-3],实现无人驾驶车辆智能驾驶这种新的控制方式,对于增强人们生活的幸福感有极其重要的意义.
近些年,国内外也有许多学者从不同角度对无人驾驶进行了许多研究并积累了丰富的成果[4].然而目前无人驾驶车辆在特殊路段难以快速做出合适动作行为且训练周期长,问题在于:现有智能驾驶大多采集真实数据训练驾驶行为,许多特殊路段场景数据很难采集到,尽管可以通过真实环境演习来采集数据,但是这种数据采集的成本较高,需要耗费大量的人力、物力和财力;在无人驾驶车辆驾驶行为强化学习训练过程中,由于车辆智能体对它所处的世界中的先验知识是一无所知的,只能在智能体探索了状态空间之后才能确定空间的值,这意味着智能体必须搜索所有的空间来寻找最优行为[5].因此,对无人驾驶车辆运动行为的训练需要时间较长.
针对上述问题,本文提出了基于改进CMA-ES算法的无人驾驶运动行为智能训练.该方法将车辆运动模拟得到的优良数据作为相关经验,拟合得到CMA-ES算法的初代种群,避免了原算法初代种群选取的随机性,使无人驾驶车辆能够快速学到良好运动行为,加快了无人驾驶车辆运动行为的训练过程.
1 无人驾驶车辆运动行为训练方法
目前国内外已经积累了丰富的无人驾驶车辆运动行为研究经验,有基于深度强化学习的、基于模仿学习的,近几年也出现了基于神经进化的方法的.
基于深度强化学习方法的原理是:深度学习负责对环境信息的感知和特征提取,强化学习负责决策、控制,通过与环境的不断交互实现深度和强化部分参数的更新,从而获得最优的表征和控制动作输出的神经网络的良好参数.Chae等[6]提出深度Q网络(Deep Q-Network,DQN)算法对自动刹车系统展开研究,经过多次模拟试验证明车辆可以实现自主刹车.Kendall等[7]使用变分自编码器(Variational Auto-Encoder,VAE)对输入图像进行压缩,采用深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)的强化学习算法构建车辆驱动系统.余伶俐等[8]结合DDPG训练车辆动力学模型,得到了最优智能驾驶的强化学习模型.
基于神经进化方法是将神经网络强大的学习能力和进化算法高效并行的特点结合在一起,使用进化算法训练神经网络,可以通过修改神经网络的权重、拓扑结构来学习无人驾驶车辆运动行为任务[9].Ha等学者提出了一种世界模型,采用VAE和混合密度循环神经网络(Mixture Density Network-Recurrent Neural Network,MDN-RNN)组成大的世界模型,用于提取和预测环境中的信息,利用CMA-ES进化算法与神经网络结合训练控制智能体车辆快速产生行为动作[10].Cardamone等[11]提出了一种线上神经进化的方法在赛车模拟器TORCS(The Open Racing Car Simulator)中学习驾驶行为.使用增强拓扑的神经进化方法(NeuroEvolution of Augmenting Topologies,NEAT)进化赛车的驾驶技能.
基于模仿学习的方法原理是:通过引入一部分相关经验,指导无人驾驶车辆运动行为的智能训练过程,提高强化学习的收敛速度,提升学习效率.Acerbo等[12]将基于机器学习的控制和基于模型的控制结合到模仿学习框架中,该框架模仿专家的驾驶行为,同时获得安全,平稳的驾驶.Kim等[13]提出了一种通过预学习来初始化智能体的神经网络,从而实现自主车辆智能体快速适应环境的框架经过测试发现学习速率提升了20%.Zaghari等[14]收集真实驾驶行为数据指导网络学习驾驶员对不同位置的障碍物的响应,经过验证证实了该方案能够展现出较高的预测准确性.
综上所述,上述无人驾驶车辆运动行为训练方法存在奖励稀疏、收敛速度慢、初始种群选取随机、现实世界特殊路段数据难采集等缺点.通过模仿学习方法进行预学习能很好的加速无人驾驶车辆运动行为的训练过程.车辆运动模拟技术具有便捷、可收集大量特殊路段的车辆运动行为数据的优点,但很少有学者利用车辆运动模拟技术获得经验数据来指导无人驾驶车辆运动行为智能训练的强化学习过程,融合车辆运动模拟方法的无人驾驶车辆智能训练有待进一步的研究.
2 无人驾驶车辆运动行为智能训练算法
基于改进CMA-ES算法的无人驾驶车辆运动行为智能训练框架图如图1所示,无人驾驶车辆运动行为智能训练算法主要分为车辆运动模拟、基于车辆运动模拟的环境-运动行为映射关系拟合、基于CMA-ES算法的环境-运动行为映射关系优化三个部分.首先进行车辆运动模拟,在虚拟环境场景下,建立车辆行为运动模型,进行全面科学的车辆运动模拟,为后期加速车辆运动行为训练打下基础;然后提取环境图像信息,再将环境图像信息和对应的行为动作采用交叉分组的方法进行分组;随后根据环境-运动行为的映射关系,采用多元线性拟合方法拟合无人驾驶车辆策略神经网络的初始权重参数,实现智能体对场景的预学习;最后采用CMA-ES算法基于拟合参数对智能体的决策控制神经网络进行优化,得到表现良好的网络模型,使无人驾驶车辆能够快速学到良好运动行为.
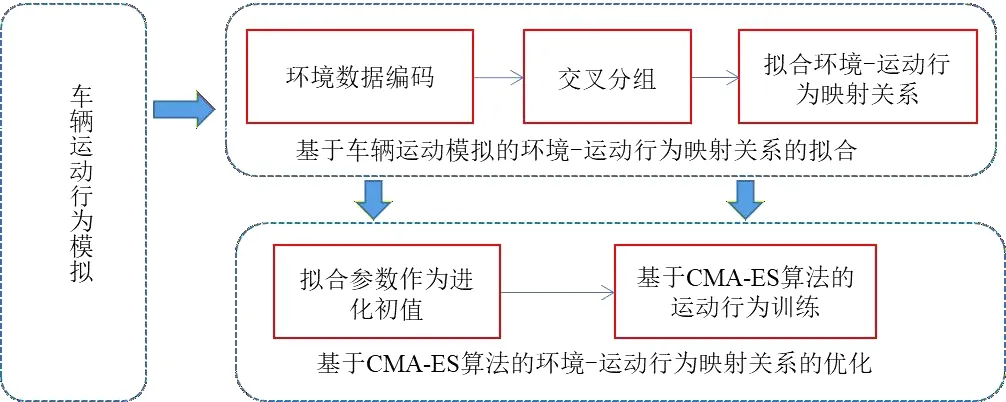
图1 基于改进CMA-ES算法的无人驾驶车辆运动行为智能训练框架图Fig.1 Intelligent training framework diagram of driverless vehicle motion behavior based on improved CMA-ES algorithm
2.1 车辆运动行为模拟
车辆运动模拟是指在虚拟场景中,建立车辆行为运动的模型,根据车辆运动模型模拟车辆在虚拟场景的运动行为.主要分为两个部分环境信息获取和模拟车辆运动行为.
2.1.1 环境信息获取 模拟车辆运动行为,需要对车辆所处的环境进行分析,获取场景信息,利用场景信息指导车辆的运动行为.首先获得所处环境的场景图像,通过将场景图像进行预处理将其转化为场景图像的对应的灰度像素图如图2所示,获取场景图像每一点对应的RGB三通道对应的像素值,可通过判断点对应的RGB通道的3个像素值获取车辆的位置信息和车辆所处位置的道路信息.

图2 车辆与道路的灰度像素数据图Fig.2 Grayscale pixel data map of vehicle and road
步骤1 从场景图像的对应的灰度像素图中可以得到车轮位置的像素值为76,对整个灰度像素图进行遍历,若某点RGB通道的3个像素值相等且数值等于76,则判断该点为车辆前轮所处的位置,即车所在的位置,并记录车辆前轮所在的行.
步骤2 以车轮所在的行为起点,选取灰度像素图中的紧邻车辆车头的一段像素,设该段像素的范围为(xa,xb),xa,xb∈(p,q),通过对该范围内每一点的RGB三通道的像素值进行分析,从xa行开始,从每一行的第q列开始,从后向前检索,若连续三个的RGB值相等且R通道像素值不等于255时,则该点为道路边界,记为(x1,y1);若连续三点的RGB像素值不相等,更新行指针和列指针继续寻找.
步骤3 在上边界xb行,第q列开始,从后向前检索,按照上述方法判断是否为路的边界,找到下一个路边界点的位置记为(x2,y2),用点的斜率值表示路的弧度,提取场景中的道路信息.
2.1.2 模拟车辆运动行为 根据获取的环境信息来模拟车辆的运动行为,车辆的运动行为主要有左转、右转、加速、减速.定义车辆转弯行为是用前轮控制的,车辆的角速度主要由道路的弧度信息决定,通过为角速度添加一个负号来控制车辆左转或者右转,定义角速度为负时车辆发出左转动作,角速度为正时车辆发出右转动作.a1定义为直行路段的加速度,b1为转弯路段的加速度.a2定义为直行路段的减速度,b2为转弯路段的减速度.
直行路段下,车辆的角速度为道路的斜率值,角速度定义为式(1),加减速信息定义为式(2)、(3).
(1)
其中(x1,y1),(x2,y2),为环境信息获取部分得到的道路边界点坐标.
直行加速度=a1.
(2)
直行减速度=b1.
(3)
转弯路段下,车辆的角速度为道路边界点的斜率值,角速度定义为式(1),加减速信息定义为式(4)、(5).
转弯加速度=a2.
(4)
转弯减速度=b2.
(5)
在虚拟场景中的所有轨道场景中,利用车辆行为运动模型,完成所有场景的模拟.针对每个场景将模拟生成的动作行为与当前帧对应的场景图像作为模拟数据集.
2.2 基于车辆运动模拟的环境-运动行为映射关系拟合
利用环境-运动行为映射关系式(6)进行无人驾驶车辆运动行为的智能训练.
at=w[zt,ht]+b,
(6)
其中,at表示t时刻无人驾驶车辆行为动作信息,如加速、减速、左转、右转等,zt,ht分别表示t时刻环境信息向量、环境信息上下文关系,w,b分别为未知参数.
采用CMA-ES算法对无人驾驶车辆进行运动行为决策训练,优化生成策略神经网络的权重参数w,b.为了加快CMA-ES算法迭代进化效率,采用拟合基于车辆运动模拟的环境-运动行为关系权重参数的方法.利用车辆运动模拟得到的模拟数据拟合出环境-运动行为关系的权重参数.
根据方程式(6),拟合得到参数w,b,首先需要有环境信息、环境上下文关系、以及当前环境对应的无人驾驶车辆行为动作信息.这里的环境信息和无人驾驶车辆行为动作信息可以通过2.1小节的车辆运动模拟得到.令其分别为Λt和at,其中t∈(0,T),其中Λt为t时刻的环境信息,为t时刻的车辆所处环境的高维图像,at表示t时刻的无人驾驶车辆运动动作,T表示模拟过程总时长.
为了避免计算量过大和提升拟合参数质量,这里首先采用环境信息编码方式对环境图像信息进行提取;然后为了使用于拟合的每组模拟数据尽可能的覆盖所有场景,这里采用交叉分组的方法对2.2.1小节得到的环境信息编码后的数据对进行分组;最后利用上述方程(6)的环境-运动行为的映射关系拟合策略神经网络的权重参数,得到包含环境-运动行为映射关系信息的权重参数.
2.2.1 环境信息编码 这里首先采用VAE[15]提取环境图像特征,然后采用MDN-RNN提取环境信息的上下文关系,实现对环境数据的编码.
针对上述环境高维RGB图像Λt,t∈(0,T),这里通过VAE模型对其特征压缩编码为zt,表示t时刻环境高维RGB图像Λt的压缩向量,zt的维数根据需要获取图像特征的数量确定.
首先按照第2.1部分的方法采样数据作为数据集,训练VAE模型,然后使用VAE模型将上述的高维RGB图像Λt编码为e维的压缩向量zt.
接下来采用MDN-RNN模型根据上述环境压缩信息集zt,t∈(0,T),计算得出环境信息上下文关系ht,t∈(0,T).
经过上述处理,可以得到场景内任意时刻的仿真数据的低维表示(zt,ht),(t∈(0,T)).
2.2.2 环境-运动行为数据分组 假设经过环境信息编码后得到数据对的数据形式为(zt,ht,at),根据式(6)拟合W组基于车辆运动模拟的环境-运动行为映射关系的权重参数,并且拟合一组权重参数需要的数据对规模为Z,则需要W×Z个数据对来拟合得到基于车辆运动模拟的环境-运动行为映射关系的权重参数.
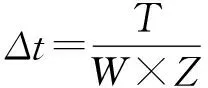
A={(zΔt,hΔt,aΔt),(z2Δt,a2Δt,h2Δt),…,(zkΔt,akΔt,hkΔt)}.
(7)
为了使得用于拟合数据(zt,ht,at)要尽可能的覆盖所有的场景,本文采用交叉分组的方法,将W×Z个数据对分成W组,每组的规模为Z,交叉分组的方法是对W×Z个数据对每隔Z个取一个组成一组,这种方法可以保证每组数据中都包含不同过程段的数据,分组后得到的一组数据记为Ai,将数据集合A分为W组,记为A=(Ai).
Ai={(ziΔt,hiΔt,aiΔt),(z(Z+i)Δt,h(Z+i)Δt,a(Z+i)Δt),…,(z(Z*(W-1)+i)Δt,h(Z*(W-1)+i)Δt,a(Z*(W-1)+i)Δt)} ,
(8)
其中i为正整数,i∈[1,W].
2.2.3 基于车辆运动模拟的环境-运动行为映射关系拟合 在这里,根据式(6),使用线性回归中的最小二乘法,求出权重参数w,b.
将输入向量zt,ht定义为d维的向量X,其中d=e+v,w为s×d的矩阵,b为s×1的向量,把w,b合为增广矩阵w′=(w,b),相应的把输入向量X扩大一维,值默认为1,定义为(d+1)×1.由于输入数据为(d+1)维,输出数据为s维,因此增广矩阵为s×(d+1)的矩阵.定义拟合函数f(xi)=wi1×x1+wi2×x2+…+wid+1×xd+1,定义目标函数为yi,其中i∈[1,s].
为进行向量计算定义输入数据为向量X,增广矩阵w′,y形式如下:
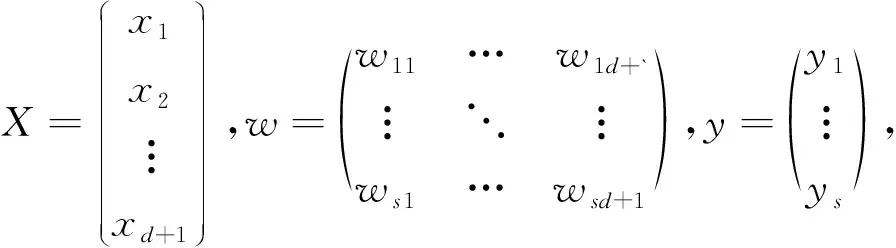
(9)
采用最小二乘法最小化f(xi)和yi的误差,利用多元线性回归函数,将向量X作为自变量数据,向量y作为因变量数据,拟合求出参数w,b.
2.3 基于CMA-ES算法的环境-运动行为映射关系优化
CMA-ES算法的种群新个体是从多元正态分布中采样得到的[16].个体的采样主要是以均值为中心,进行正态分布得到的,在其周围采样得到初始种群.初始种群的参数具有随机性,本文在原CMA-ES算法进化的过程中引入基于车辆运动模拟的环境-运动行为关系拟合的权重参数,使CMA-ES算法在拟合权重参数的基础上进行训练,避免了初始种群选择不当的问题.引入拟合参数的CMA-ES算法的流程图如图3所示.
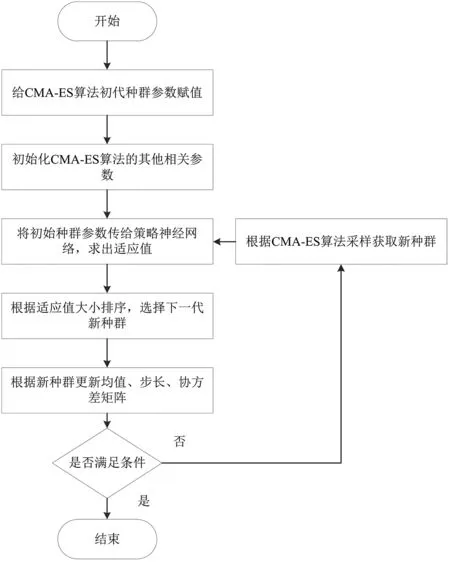
图3 基于CMA-ES算法的环境-运动行为映射关系优化流程图Fig.3 Optimization flow chart of environment-motion behavior mapping based on CMA-ES algorithm
利用改进的CMA-ES算法的进化步骤如下.
步骤1 将拟合出来的参数赋值给无人驾驶车辆的策略神经网络,与环境信息场景输入数据做加权运算,生成车辆运动行为,与虚拟环境进行交互通信,得到车辆运动行为的奖励值.
步骤2 对车辆运动行为的奖励值(适应值)进行排序,选择奖励值较高的μ组权重参数值.
f(x1:λ)≤f(x2:λ)≤…≤f(xμ:λ)≤…
≤f(xλ:λ)i∈[1,λ],
(10)

步骤3 更新均值mg.前μ组奖励值较高的拟合参数种群与对应的权重系数做加权运算,具体式如(11)所示.
w1≤w2≤…≤wμ,
(11)
其中,μ≤λ,是最优解种群的大小,wi是重组后每个种群的权重,为奖励值较大的个体分配较大的权重,促进均值偏向最优个体的方向,使生成最优解的概率增大.xi:λ是在λ个种群中排名为i的种群.
步骤4 更新协方差矩阵Cg.分别进行秩1的更新和秩μ的更新.利用更新后的均值与当代均值差异引导进化方向对秩1进行更新,利用前μ组奖励值较高的拟合参数种群信息进行秩μ的更新.
在秩1的策略中,是利用进化路径来更新协方差矩阵的.进化路径pc的初始值为0,进化路径主要利用了更新后的均值和当代均值之差,除以步长是为了消除整体步长对突变方向的影响,更新如式(12)所示:
(12)
其中,cc为pc的学习率,区间为[0,1].秩1的更新公式如式(13),其中,c1为C的在秩1更新机制中的学习效率.秩μ的更新式如式(14),其中cμ为C的在秩μ更新机制中的学习效率.
(13)
(14)
(15)
结合秩1的更新和秩μ的更新,协方差矩阵C的更新公式如式(16)所示:
(16)
更新步长σg,利用更新后的均值与当代均值差异来扩大或缩小步长搜索的范围,为了控制步长,引入秩1更新的进化路径来实现步长的控制,引入与进化路径pc共轭的路径pσ来控制步长,具体公式如式(17),步长的更新公式如式(18),其中,dσ为阻尼系数,约等于1.cσ步长的学习效率.然后,将更新后的均值mg,Cg,σg代入公式,形成新的分布.
(17)
(18)
步骤5 利用前μ组奖励值较高的拟合参数种群更新过均值、步长、协方差矩阵后,按照原CMA-ES的方法生成新的种群个体.方法如式(19)所示:
(19)
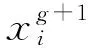
3 实验分析
为验证本文方法的有效性,这里展示车辆运动模拟的效果以及基于车辆运动模拟的CMA-ES算法与原CMA-ES算法对无人驾驶车辆运动行为智能训练的结果对比分析.
3.1 车辆运动模拟
首先在虚拟环境里进行车辆模拟,使车辆在虚拟环境中运行多次,收集16组数据作为模拟数据,每组数据为1 000帧.通过引入车辆行为运动模型,保证车辆每次都能顺利通过整个场景轨道,得到运动行为较优的模拟数据.图4显示了车辆运动模拟的结果.
从图4(a)中可以看出车辆进入转弯路段,由于车辆倾斜,因此前车轮没有做出转弯动作;图4(b)中车辆已经进入转弯路口,根据道路与车身的倾斜度,车辆前车轮做出右转动作;图4(c)中车辆度过第一个弯,根据道路与车身的倾斜度,车辆前车轮做出轻微右转动作;图4(d)中车辆正在驶离转弯路口,根据道路与车身的倾斜度,车辆前车轮做出左转动作,顺利通过连续转弯路口.车辆在转弯路口有良好的行为决策,把该模拟的动作行为和对应的环境信息保存下来作为模拟数据.

图4 模拟效果截图(四幅图按照时间顺序排列)Fig.4 Simulation effect screenshot (The four pictures are arranged in chronological order)
3.2 基于改进CMA-ES算法的无人驾驶车辆运动行为智能训练方法验证
利用车辆运动模型模拟车辆运动行为,基于车辆运动模拟的CMA-ES算法来进行实验分析,研究了时间与得分的变化关系、模拟数据采样与得分的关系,其中模拟数据采样与得分的关系中包含了对模拟数据采样的规模、采样的范围与得分之间的关系.
3.2.1 时间与得分变化关系 通过车辆运动模拟,让车辆在场景中完成16次任务,每次任务收集1 000组数据,得到16 000组数据集,通过VAE得到环境信息的特征向量 ,用预处理数据和与之对应的训练MDN-RNN得到表示环境序列信息的向量,将通过最小二乘法拟合得到,用于后期无人驾驶车辆运动行为的训练过程中.
限于机器的性能,为CMA-ES算法分配了8个CPU进程,每个CPU进程运行2个种群个体,每次生成16个种群,每个种群个体在环境中随机运行4次,每隔25代对权重进行评估.经过500代的进化,本方法在长期迭代后平均得分长期保持在600分左右.但是从结果图可以很明显的看出,CMA-ES算法可以很好的适应引入车辆运动模拟拟合出的初始种群,在进化的初期能迅速得到一个比较高的分数,且由于初始参数解的质量较优,前期进化速度也非常快,在前50代的时候就能达到相对不错的分数,在算法进化前期很好的引导后代种群快速向最优解靠近.
图5中的(a)(b)(c)三图分别展示基于车辆运动模拟的CMA-ES算法得与原CMA-ES算法在种群在进化过程中每一代的最优得分、平均得分、最差得分与迭代进化时间的变化关系对比图.不管在哪种得分中,基于车辆运动模拟的CMA-ES算法在进化初期的性能都大致为原CMA-ES算法的二倍.可以看出在进化初期引入了包含环境-运动行为信息的拟合参数,初始种群起点都要比原算法要高,且进化速度快,能迅速的取得一个相对较优的得分.
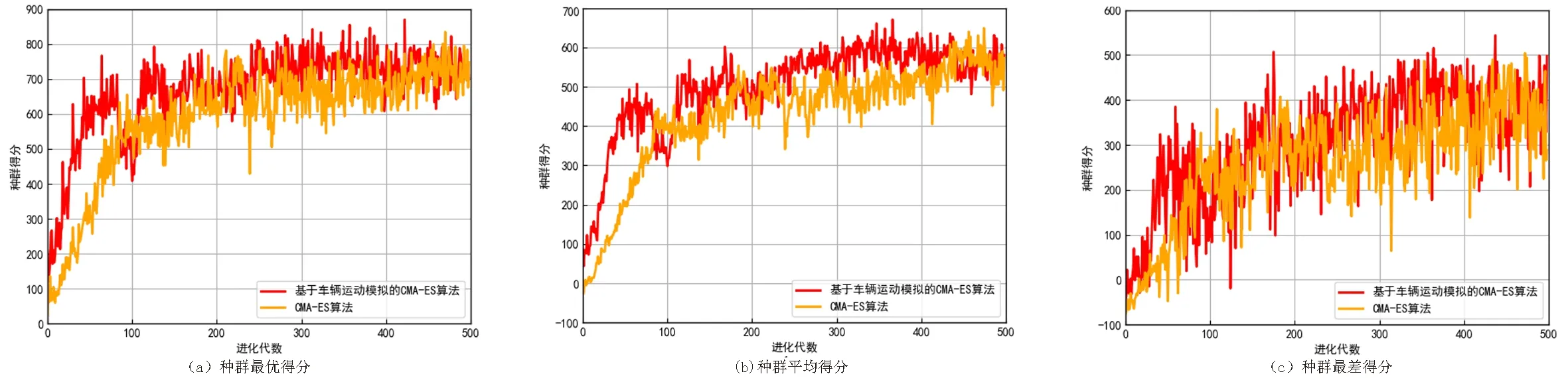
图5 时间与得分关系对比图Fig.5 Comparison of time and score
3.2.2 采样规模和得分的关系 采用两种采样规模进行对比,车辆每完成一次场景任务采取1 000步动作,首先对整个运行过程进行全采样,对每一轮任务采1 000帧,然后进行均匀采样,每间隔3个时间步采一帧数据,每一轮任务采300帧数据,将两种采样数据分别代入基于车辆运动模拟的CMA-ES算法,来分析采样规模与得分之间的关系得到了种群在进化过程中每一代种群的最好得分、平均得分、最差得分的结果图.
从图6中可以得出每圈采300帧均匀采样得到的初始参数值的表现能力比对整圈进行全采样略差.是因为300帧的均匀采样,拟合得出参数值所包含的环境-运动行为关系信息相对较少,对场景预学习的程度较轻,整体表现能力逊色于全采样拟合出的参数值,且在进化初期进化的增长速度相对没有全采样的快,因此得出采样规模与进化得分的关系呈正相关.
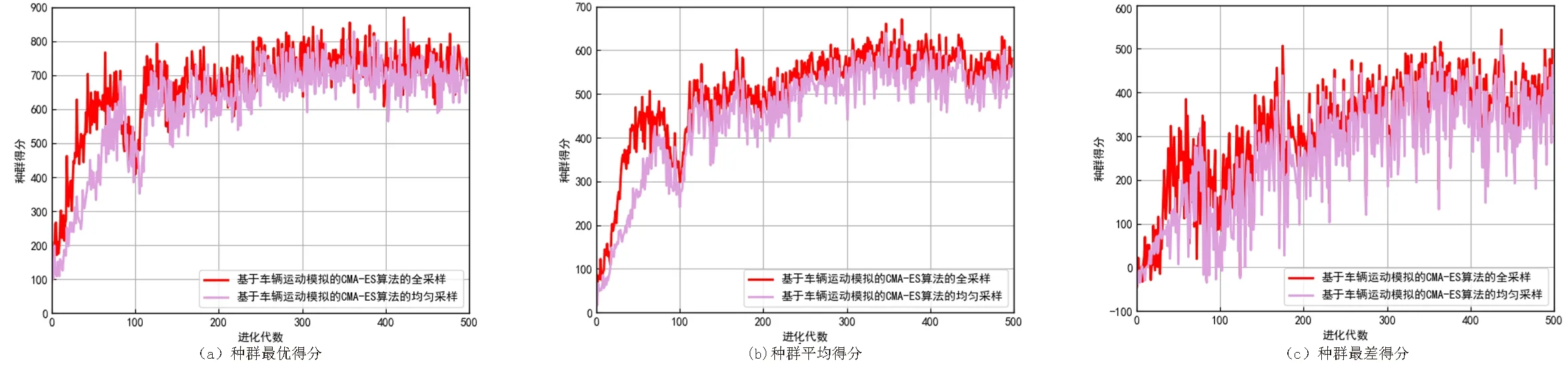
图6 全采样与均匀采样种群得分结果对比图Fig.6 Comparison of population scores between full sampling and uniform sampling
3.2.3 采样范围和得分的关系 采用两种采样范围进行实验对比,首先对车辆的整个运行过程进行全采样,然后对车辆运行的前半段进行全采样,将两个采样范围的数据带入基于车辆运动模拟的CMA-ES算法,进行分析得到了种群在进化过程中每一代种群的最好得分、平均得分、最差得分的结果图.
从图7中可以看出,对前半过程采样得到的结果紧贴全过程采样的结果曲线,但是结果稍逊于对整个过程进行采样的结果.由于对前半过程采样得到的信息没有覆盖整个场景,没有对场景后半段的环境-运动行为关系进行预学习,包含的场景信息不全,性能不如对全过程采样得到的结果,由此可以得出采样范围与得分的关系呈正相关.
图7 全过程与前半段采样种群得分结果对比图Fig.7 Comparison of population score results of the whole process and the first half of sampling
4 结论
首先建立车辆行为运动模型模拟车辆运动行为,然后对所提出的基于车辆运动模拟的无人驾驶车辆运动行为智能训练的方法进行验证分析.结果表明,基于车辆运动模拟的CMA-ES算法加速了无人驾驶车辆运动行为智能训练过程,主要体现在训练速度相对较快.通过分析进化时间与得分之间的关系、模拟数据的采样范围与得分的关系和采样规模与得分的关系,经过对比分析证明包含环境-运动行为信息多的拟合参数对无人驾驶车辆运动行为的训练过程的指导较好,生成的运动行为较优.
猜你喜欢
今日农业(2022年15期)2022-09-20
作文小学中年级(2022年9期)2022-09-08
湖南电力(2021年1期)2021-04-13
科学(2020年3期)2020-11-26
小哥白尼(军事科学)(2020年8期)2020-05-22
小太阳画报(2018年3期)2018-05-14
中学生物学(2018年8期)2018-03-01
阅读与作文(小学低年级版)(2016年12期)2016-12-22
汽车文摘(2015年11期)2015-12-02
海外英语(2013年11期)2014-02-11
