
基于Informer的长序列时间序列电力负荷预测
2021-10-09 01:09:26刘洪笑周丙涛段亚穷伏德粟
湖北民族大学学报(自然科学版) 2021年3期
刘洪笑,向 勉,周丙涛,段亚穷,伏德粟
(湖北民族大学 信息工程学院,湖北 恩施 445000)
电力负荷预测其实是为了电力系统的准确运行和规划而提出的一个时间序列预测的问题,不仅要提高预测的电力负荷的精准度,而且要考虑预测的时间和模型运行时间的长短,做到这样才能实现更加高效的管理以及对能源的调度和更加及时的优化.电力负荷预测模型近几年得到了广泛的应用,Li等[1]通过压缩其子层(Transformer的基本构建块)来简化架构,并实现更高的并行性.Hsiao等[2]通过在音乐建模中使用更短的训练和推理时间生成了与Transformer-XL质量相当的完整钢琴曲.Liu等[3]去掉了暂停单元,提前估计所需深度,这产生了更快的深度自适应模型.Fu等[4]提出了一种基于对比学习的知识蒸馏方法LRC-BERT,从角距离方面拟合中间层的输出,这是现有蒸馏方法没有考虑的.李震等[5]通过数据驱动线性聚类的方法解决因负荷波动大而导致的预测精度低的问题,从而获得更加精准的预测结果.文献[6-8]提出了基于改进优化循环神经网络来短期的电力负荷预测的准确度.周哲韬等[9]提出了基于Transformer模型轴承RUL预测方法,利用了自注意力机制与编码器-解码器的结构优势,解决了预测序列过长的记忆力退化问题.李开卷[10]考虑了不同历史时段对组合权重值,对模型进行权重量化.王军[11]用人工神经网络的最小二乘支持向量机的方法与灰色预测法、人工神经网络预测法对比,证明了均方误差整体上比其他两种预测法要小.孙建梅等[12]使用改进的灰色模型,增强了波动负荷序列的抗干扰能力.贾庆兰[13]采用基于概率主分量分析模型的电力运行数据预处理方法,去除冗余数据,从而提高预测精度.刘雨竹等[14]通过讨论在用气象因素来提高负荷预测精度,再用回归分析法分析参数.费熹[15]利用免疫遗传算法(IGA)对加权最小二乘支持向量回归机(WLSSVR)的关键参数进行全局快速寻,进而提高短期的负荷预测准确度.这些研究都无法解决长序列的输入输出问题,特别是Transformer在计算注意力时会计算其中一个点与其他所有点的注意力,使得每一层的计算复杂度为O(L2),当序列长度增长时,计算开销会成指数倍的速度增长.Informer模型首次被Zhou等[16]提出应用在长时间序列预测上,通过改进Transformer在预测过程中不能直接适用于长序列时间序列(LSTF)的问题,而Informer模型能够准确地捕捉输出与输入之间的长期依赖关系.本文使用Informer模型来对电力负荷做出预测,在Transformer模型中改变了编码器-解码器体系结构固有的局限性、二次时间复杂度和高内存使用量,使得改进后的Informer模型提高了电力负荷预测的准确度,并且可以获得较高的Pearson相关系数,而且更能够有效捕捉输入和输出之间的精度的长程相关性耦合.

图1 Transformer的整体框架Fig.1 The overall framework of Transformer
1 Tranformer网络模型
Transformer中的Attention机制在处理大量信息时,不会关注全局的信息,而更加关注某一部分,自注意力的机制已经在NLP和CV领域取得了很好的成果,Transformer在长序列预测问题上,相比其他模型,最大的优势就是序列中点与点之间的最大路径是最短的,输入和输出之间的求导单元最少,所以路径越短,有效的梯度信息才会保留越多,就会传递得越准确,而Transformer模型会用最短的距离进行回传,但是原生的Transformer不能支持长序列的输入输出,因为在计算注意力的时候会计算其中一个点与其他所有点的注意力,每一层的计算复杂度变大,导致Transformer无法支持超长序列的预测.
Transformer之所以和经典的CNN和RNN模型有很大的差距,是因为Attention机制完全构成了整个网络的结构.由于RNN相关的模型算法的机制都是从左向右依次计算(从右向左依次计算),RNN(LSTM)的计算顺序被Attention机制继承了下去,这样便出现了以下两个问题:①t-1时刻的计算结果会被t时刻的计算结果所依赖,也就是会很依赖上一时间,无法使模型的并行能力显现出来,使得运行时间变长;② 在顺序计算的过程中,一旦发生信息会丢失,虽然LSTM等门机制的结构在一定程度上有能力减轻长期依赖的情况,当遇到那种特别长期的依赖现象时,LSTM处理的依旧显得捉襟见肘.直到Transformer的出现,上面两个问题才得到完美解决:一是它使用了Attention机制,巧妙地将序列中的任意两个位置之间的距离缩小为一个常量,使得过分依赖上一时刻的问题得以解决;二是它与RNN的顺序结构大不相同,因此它的并行性就展现了出来,与现有的GPU框架相吻合,提高了运行的效率.编码组件部分由一堆编码器(encoder)构成,解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的.Transformer的模型框图如图1所示.
目前Transformer具有较强的捕获长距离依赖的能力,但传统的Transformer依然存在以下不足,因此Informer做出了一些改进.Transformer的不足有:① self-attention平方级的计算复杂度高;② 堆叠多层网络,内存占用瓶颈;③ 逐步(Step-by-Step)解码预测,速度较慢.而Informer模型的改进有:① 提出了稀疏自注意力(ProSparse Self-attention),筛选出最重要的query,降低了计算的复杂度;② 提出了自注意力蒸馏(Self-attention Distilling),减少了维度和网络参数量;③ 提出了生成式风格解码器(Generative Style Decoder),一步得到所有预测结果.
2 构建Informer长期电力负荷预测模型
2.1 Informer模型的输入
整个问题被定义为如下方式,即t时刻的输入数据为:
(1)
目的是预测相应的输入数据,即:
(2)
而对于LSTF(长序列时间序列预测)问题,要求更长的输出序列长度Ly.
2.2 Informer模型的自注意力机制(self-attention mechanism)
首先,传统的自注意力(self-attention)机制输入形式是(Query,Key),然后进行缩放点积(scaled dot-product),即:
(3)
其中,Q∈RLQ×d,K∈RLK×d,V∈RLV×d,d是输入维度,第i个Query的注意力系数的概率形式是:
(4)

self-attention机制使用二次时间复杂度的点积运算来计算上面的概率p(qi,kj),并且计算需要O(LQ,LK)的空间复杂度,所以这是提高预测能力的主要障碍.另外,在概率研究上,self-attention的概率分布具有潜在的稀疏性,并对所有的p(qi,kj)都设计了很多以“选择性”为目的计数方式策略,而对性能没有明显的影响.因此,首先要定性的评估典型self-attention的学习模式,即它的“稀疏性”,self-attention的结构分布为长尾式的分布,也就是少数的点积对主要的attention的贡献比重大,其他的点积的贡献可以忽略不计.
为了度量Query的稀疏性,作者用到了KL散度.其中第i个Query的稀疏性的评价公式是:
(5)
其中,上式的第一项是qi对于所有的key的一个Log-Sum-Exp (另一种求取最大值的方法即LSE),第二项则是它们的算数平均值.基于上面的评价方式,就可以得到ProbSparse self-attetion的公式,即:
(6)
其中,Q是和q具有相同尺寸的稀疏矩阵,并且它只包含在稀疏评估M(q,M)下top-u的询问,u的大小通过一个采样参数来决定.这使得ProbSparse self-attention对于每个query-key只需要对O(lnLQ)点积计算进行操作.另外在文献[16]中有引理证明,其对稀疏评估进行了上边界的计算,从而保证了计算的时间和空间复杂度为O(LlnL).Informer的整体架构如图2所示,左侧的编码器Encoder接收了大量的长序列输入,并已经使用稀疏自注意力取代了经典的自注意力机制.蓝色的梯形部分为自注意力提取操作,可以大幅度的减轻网络的规模,并且一层层的叠加又增加了模型的鲁棒性.右侧的解码器Decoder接收了长序列的输入,将目标元素填充为零并测量特征图的加权注意力组成,然后快速以生成式的格式输出元素.

图2 Informer的整体框架Fig.2 The overall framework of Informer
2.3 Informer模型的编码器(Encoder)
Encoder是为了提取长序列输入的远期的依赖性而设置的结构.Encoder作为ProbSpare自注意机制的结果,encoder的特征映射存在值V的冗余组合,因此,利用distilling操作就是将更高的权重赋予给具有主导特征的优势特征,并在下一层生成focus self-attention特征映射.从j到j+1层的distilling操作的过程如下:
(7)
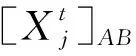
2.4 Informer模型的解码器(Decoder)
在Decoder的部分中使用了一个标准的decoder结构,是Vaswani等[17]在2017年提出的,它是由两个一样的多头注意层组成的.此外,还被用来缓解长期生成推理预测的速度下降.我们向decoder提供如下输入向量:
(8)
其中,问题稀疏的自注意力(probsparse self-attention)在计算中应用了隐藏多头注意力(masked multi-head attention),隐藏多头注意力机制不会使每个位置都注意到下一个位置,从而避免了自回归.一个全连接层最后获得了最终的输出,并且预测进行的是单变量预测还是多变量预测决定了它的输出维度.该方法提出的在编码器Decoder结构中使用生成式结构,能够一次生成全部预测序列,使得预测解码时间极大的缩短.
3 长期电力负荷预测
3.1 实验环境与数据
实验环境为python 3.7,pytorch 1.6框架,Windows 10,12.0 GB,Intel(R) Core(TM) i5-7200U CPU @ 2.50 GHz,NVIDIA GeForce 940MX显卡.
实验选取了澳大利亚电力负荷与价格来预测数据,其中数据每0.5 h采集一次数据,分别包括日期、实时气温、湿度、电价和用电户负荷等信息,并以日期、温度、湿度、降雨量和电力负荷数据作为输入构建Informer模型电力负荷预测的模型.第一组数据使用2006-2009年电力负荷数据中的70 128组数据作为训练集,17 521组数据作为测试,用第一组数据对第二组2010年1-12月的电力负荷的数据进行预测.
3.2 数据预处理
长期电力负荷受时间因素、气象因素和电力价格方面的影响尤为明显.为了提高模型预测精度,归一化处理数据.利用StandardScaler原理去均值和方差归一化,不是针对样本去均值和方差归一化,而是针对每一个特征维度来做的.标准差标准化(StandardScale)使得经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
(10)
其中,μ为所有样本数据的均值,σ为所有样本数据的标准差.
3.3 实验评价标准
以下通过两个指标评价Informer的性能:① 在CNN、LSTM、Informer模型下,观察实际的序列和预测的序列的拟合效果图;② 归一化均方根误差(RMSE)和皮尔森相关(Pearson correlation test).
(11)
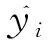
皮尔森相关系数是描述两个变量的线性相关性的强弱程度的,即反映两个变量线性相关程度的统计量.皮尔森相关系数用字母r来表示,而且r的绝对值越大表明相关性越强.
(12)

3.4 实验结果及分析
构建不同的模型,观察实验图像参数的归一化均方根误差(RMSE)和皮尔森相关(Pearson correlation test),并通过修改不同的批尺寸(mini-batch)、学习率(learning rate)、迭代次数(epochs)来确定模型的最佳的参数.由于LSTM模型、CNN模型与基于Transformer的Informer模型的框架有很大的差距,导致因两类模型在数据处理时方法不同,所以通过RMSE误差指标与皮尔森相关系数两个评价指标进行对比,并分析模型.
对比表1和图3和图4的结果,Informer模型始终能够获得较高的拟合度,而且Informer模型的误差更小,而LSTM模型与CNN模型训练后得到的拟合度则相比Informer模型要小,且误差指标均在Informer模型的误差指标之上.从对比试验可以看出,CNN模型、LSTM模型、Informer模型的均方根误差分别为54.22%、36.63%、32.32%,Informer模型的比LSTM模型的均方根误差减少了4.31%,LSTM模型比CNN模型的均方根误差减少了17.59%;三个模型的Pearson 相关系数分别为84.61%、89.23%、91.30%,且Informer模型的比LSTM模型的Pearson 相关系数增加了2.07%,LSTM模型比CNN模型的Pearson 相关系数增加了4.62%.由图3可知,LSTM模型与CNN模型在波峰和波谷的真实值与预测值的偏差较大,拟合度随着波动在波峰和波谷下降,而Informer的波峰与波谷的真实值和预测值的偏差较小,且拟合度较高.Informer模型在对长时间序列的预测时,解决了输出和输入之间由于距离长而导致依靠关系没有被很好捕捉的问题,并且Informer模型优化了原来Transformer中的注意力机制的时间和空间复杂度,使得Informer模型可以得到较高的预测精度.由表1可知,本文的方法对负荷预测的精度最高.其中,LSTM模型、CNN模型方法由于其自身的结构限制,预测的精度较低.

表1 CNN、LSTM、Informer模型参数Tab.1 CNN,LSTM,Informer model parameters
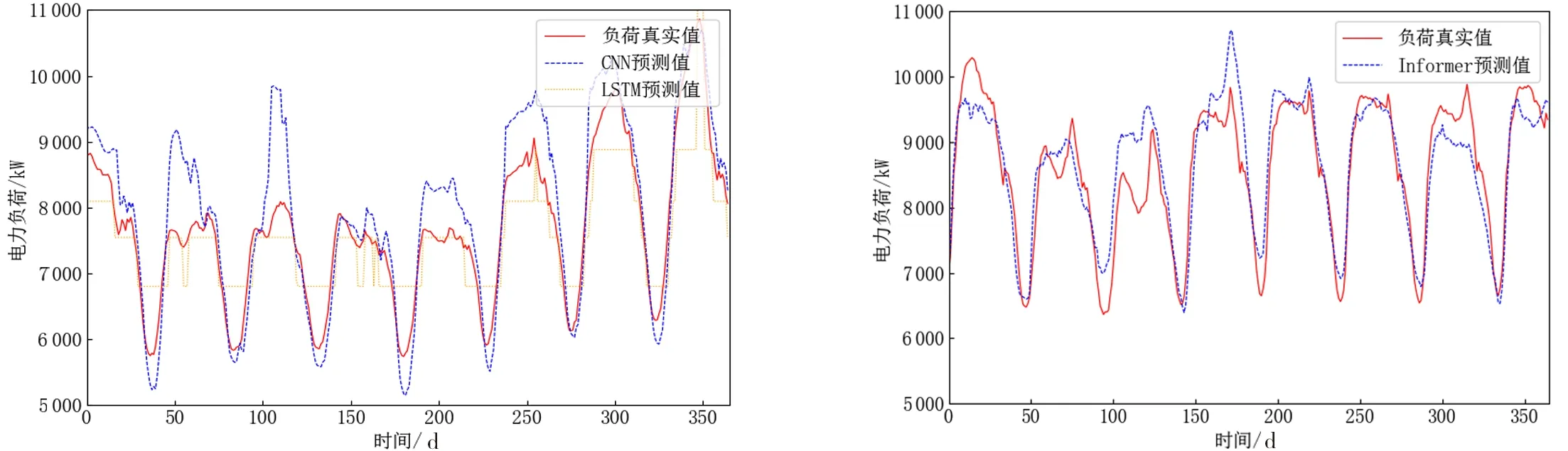
图3 CNN和LSTM模型电力负荷预测 图4 Informer模型电力负荷预测Fig.3 CNN and LSTM model power load forecasting Fig.4 Informer model power load forecasting
4 结语
为了提高长期电力负荷的预测精度,应用了一种基于改进的Transformer的模型informer来预测长期电力负荷.Informer模型本质上是用一种概率稀疏自注意机制和蒸馏操作来处理Transformer的二次时间复杂度和二次内存使用的问题,并且生成式解码器减轻了传统的编码器-解码器体系结构的局限性.试验结果表明,相比较于传统的CNN、LSTM模型,Informer模型在预测的精度上更高、泛化能力更强,适应于长期电力负荷预测.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
传媒评论(2017年3期)2017-06-13 09:18:10
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
火控雷达技术(2016年3期)2016-02-06 02:30:28
