
基于数据挖掘的上市公司高送转预测
2021-10-09 15:47谢忠群
中国管理信息化 2021年19期
谢忠群
(贵州财经大学,贵阳 550002)
1 研究背景
近年来,我国证券市场的高速发展催生了一批题材股。在这些题材中间,高送转这一题材无疑是中小投资者强烈追捧的对象。实施高送转后股价将做除权处理,投资者可以通过填权行情从二级市场的股票增值中获利,而等除权后再买入可能面临很大的回撤风险。如果我们能准确预测下一年可能实施高送转的上市公司并提前买入,这对我们投资的安全性具有很大的现实意义。经过研究,影响上市公司实施高送转的因子主要有两类:一是基本因子,包括股价、总股本、上市年限等;二是成长因子,包括每股未分配利润、每股资本公积、每股现金流、每股收益等。除此之外,还有其他因子等待挖掘。
本文利用相关数据,筛选出对上市公司实施高送转方案有较大影响的因子,建立模型预测哪些上市公司可能会实施高送转,并对提供的数据用所建立的模型来预测第8 年上市公司实施高送转的情况。
2 因子选取
本文研究数据为3466 家上市公司7 年的各种高送转相关因素,包含了年数据、日数据、基础数据,原始数据共24262 个样本。在实际建模前对数据作预处理,删除或补全缺失值、统一量纲,将数据规范化。
从数据挖掘角度在所有特征中挑选出了前8 个影响较大的因子,分别为归属于母公司净利润同比增长(%)(A)、每股收益(期末摊薄,元/股)(B)、基本每股收益(C)、每股净资产(元/股)(D)、稀释每股收益同比增长(%)(E)、基本每股收益同比增长(%)(F)、上市年限(G)、总资产净利率(%)(H)。将这8 个影响因子绘制特征重要性排名,从高到低为:B、A、D、C、H、E、F、G,且每个特征的重要性较为均衡。
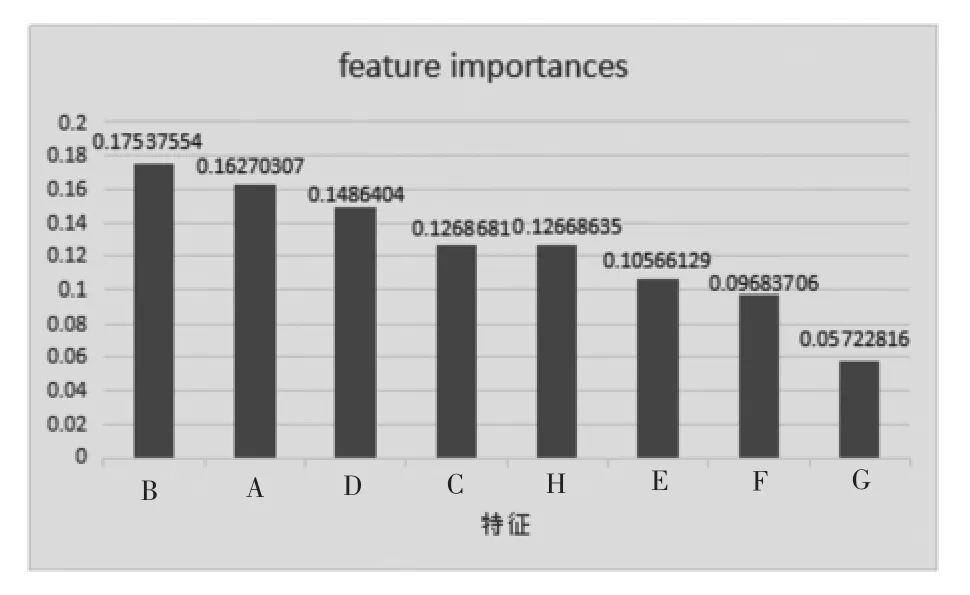
图1 因子重要性排名
3 模型训练
通过数据处理,特征选择以及提取影响因子,我们得到了高质量的训练和测试数据集,现在要通过运用得到的数据和xgboost 算法正式进入“高送转”预测模型的构建工作中。
本文将挑选出的这8 个因子放入xgboost 模型中,从AUC结果来看,通过数据挖掘出的因子计算出的AUC 值高达0.96,说明利用数据挖掘挑选出的因子配合xgboost 模型的分类效果较好。
4 模型预测
xgboost 算法由GBDT 算法演变而来,在GBDT 的基础上通过改变目标函数来避免GBDT 存在的问题,例如:当数据量很大时,减少计算时间等。
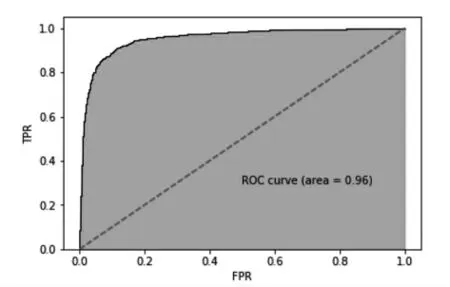
图2 ROC 曲线
在测试结果展示的部分,我们使用混淆矩阵来展示模型的分类效果。混淆矩阵也称作误差矩阵,是表示精度评价的一种形式。对于二分类下的混淆矩阵,标签有两种,分别为0 和1,横坐标代表通过模型分类出来的测试集的结果,纵坐标表示数据集中给定的数据集的结果。对角线上的数据代表被正确分类的数据的个数,另外的数代表被错误分类的数据的个数。通过这些数据,计算出模型的精确率(precision)、召回率(recall)、准确率(accuracy)、f1-score,f1-score 值是将精确率和召回率的值合并,计算其调和均值,计算公式为:
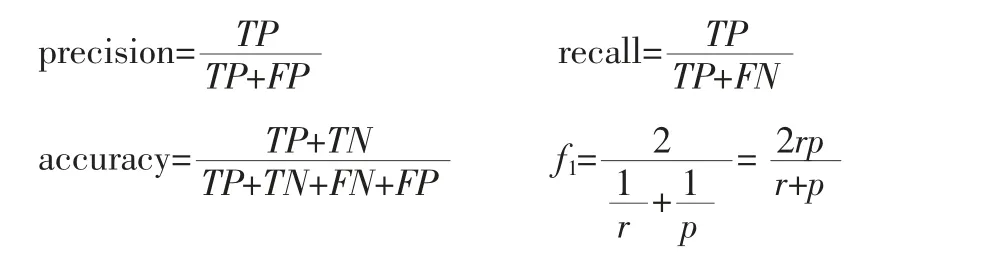
其中,TP 为被分类模型正确预测的正样本数,TN 为被分类模型正确预测的负样本数,FP 为被分类模型错误预测为正类的负样本数,FN 为被分类模型错误预测为负类的正样本数,分别对应于混淆矩阵的(0,0)(1,1)(0,1)(1,0)位置。
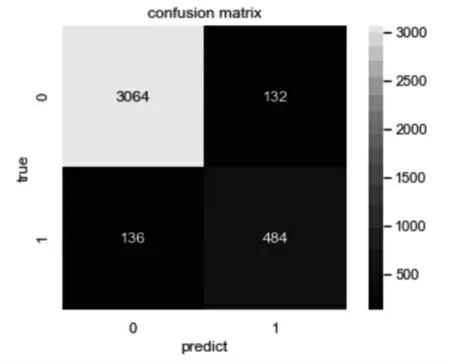
图3 预测值与真实值的混淆矩阵
根据混淆矩阵计算出各个值:负类0 的精确率(precision)为0.96、召回率(recall)为0.96、f1-score 的值为0.96;正类1 的精确率(precision)为0.80、召回率(recall)为0.81、f1-score 的值为0.80;模型准确率(accuracy)为0.93,统计如下表1。
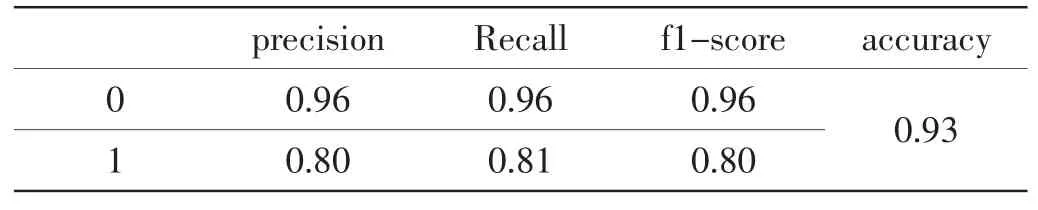
表1 分类准确率
猜你喜欢
湖南林业科技(2021年3期)2021-12-02
医学食疗与健康(2021年27期)2021-05-13
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2018年5期)2018-08-21
电力与能源(2017年6期)2017-05-14
计算机应用与软件(2016年6期)2016-07-19
信息通信技术(2015年6期)2015-12-26
计算机工程与应用(2015年19期)2015-04-16
电子设计工程(2014年18期)2014-02-27
中国农业信息(2013年10期)2013-09-05
