
An end-to-end multitask method with two targets for high-frequency price movement prediction
2021-09-29 09:04MaYulianCuiWenquan
中国科学技术大学学报 2021年3期
Ma Yulian, Cui Wenquan*
1.International Institute of Finance, University of Science and Technology of China, Hefei 230601 ,China;2. School of Management, University of Science and of Technology of China, Hefei 230026,China
Abstract: High-frequency price movement prediction is to predict the direction(e.g. up, unchanged or down) of the price change in short time(e.g. one minute). It is challenging to use historical high-frequency transaction data to predict price movement because their relation is noisy, nonlinear and complex. We propose an end-to-end multitask method with two targets to improve high-frequency price movement prediction. Specifically, the proposed method introduces an auxiliary target(high-frequency rate of price change), which is highly related with the main target(high-frequency price movement) and is useful to improve the high-frequency price movement prediction. Moreover, each task has a feature extractor based on recurrent neural network and convolutional neural network to learn the noisy, nonlinear and complex temporal-spatial relation between the historical transaction data and the two targets. Besides, the shared parts and task-specific parts of each task are separated explicitly to alleviate the potential negative transfer caused by the multitask method. Moreover, a gradient balancing approach is adopted to use the close relation between two targets to filter the temporal-spatial dependency learned from the inconsistent noise and retain the dependency learned from the consistent true information to improve the high-frequency price movement prediction. The experimental results on real-world datasets show that the proposed method manages to utilize the highly related auxiliary target to help the feature extractor of the main task to learn the temporal-spatial dependency with more generalization to improve high-frequency price movement prediction. Moreover, the auxiliary target(high-frequency rate of the price change) not only improves the generalization of overall temporal-spatial dependency learned by the whole feature extractor but also improve temporal-spatial dependency learned by the different parts of the feature extractor.
Keywords: multitask learning; fine-grained auxiliary target; feature extraction; sharing method; negative transfer; high-frequency price movement prediction
1 Introduction
The asset price movement prediction is an open and interesting problem. First of all, there are two contradictory perspectives on its predictability and both of them achieve the Nobel Memorial Prize in Economic Sciences. The one is the efficient market hypothesis(EMH) of Fama, stating that it is impossible to predict the asset price movement[1]and the other one is the behavioural economics of Thaler, implying that the asset price movement is somewhat predictable[2]. Compared with the EMH, the behavioural economics is based on the bounded rationality rather than the rational agent assumption, so it is more realistic in most cases[3]. For example, the famous monthly effect[4]and the small firm effect[5]are included in the behavioural economics, which show that the asset price movement can be predicted to some extent.
As a result, on the basis of the behavioural economics, a lot of solutions are proposed to predict the price movement[6-9]. On the whole, these solutions try to improve the price movement prediction either by using more diverse unstructured input data or by constructing more elaborate classifiers. On the one hand, besides the traditional structured data(e.g. technical indicators[10-12]), social media information like tweets and blogs[13-16]and company-related financial news[14,16-18]are utilized to predict price movement. On the other hand, more elaborate classifiers based on deep learning(e.g. the long short-term memory(LSTM)[19,20], convolutional neural network[20,21]), the reinforcement learning(e.g. deep Q-learning[22]) and the generative adversarial training[12]are proposed to improve the price movement prediction.
Although these solutions manage to improve the price movement prediction, most of them are single task method, which just construct the classification task by directly taking sign value of price change as the sole target and pay little attention to the related and more fine-grained rate of price change(containing the information about the magnitude of price change except the sign value). However, it has been empirically shown that the task with a fine-grained target probably synergizes with the task with a coarse-grained target[13], which indicates that the task with more fine-grained target can probably improve performance of the classification task with the coarse-grained price movement target. Besides, it can be proven that given the input variablesx, the two-target multitask learning method jointly modeling the distributions of two related targets(yandr)P(y|r,x) andP(r|y,x) will get the more certain optimal distributionP(y|x) than the single task method, which models the distributionP(y|x) without using the variablerso that the proposed two-target multitask method jointly modeling the distributions of two highly related targets(the high-frequency price movement and rate of price change)[24-27]can get the more certain distribution about high-frequency price movement to further improve its prediction. Specifically, we give the following proof. For the crossentropy loss function for classification task, the optimal distribution is the target distribution and the optimal value is the entropy of target distribution so that the optimal value of the two-target multitask learning method is the entropy
and the optimal value of the single task method is the entropy
Because ofH(y|r,x)≤H(y|x), the two-target multitask learning method will get a more certain optimal distribution for high-frequency price movement and get more certain prediction than the single task method. Furthermore, the differenceH(y|x)-H(y|r,x) is increasing with the relation between the two targets(yandr) and whenyandris independent, the difference reaches 0 and whenyis the same asr(totally related), the difference reaches the max valueH(y|x).
Given an extra variable(e.g. rate of price change), it is natural to take it as an the input variable[28,29], but the complex and poor linear correlation between the high-frequency rate of price change and price movement[30]and the high noise of the rate of price change[31,32]will probably deteriorate the capability of the back propagation to learn to use the rate of price change to predict price movement[28,33-35]. Different from directly taking the rate of price change as input, the proposed two-target method takes it as the auxiliary target to leverage its relation with the price movement and can bias the hidden layer to encode useful representation for price movement prediction even when the rate of price change is noisy and the linear correlation between them is weak[28]to get better price movement prediction[36]. Besides, when it comes to choose the concrete variable on behalf of the rate of price change, the two-target multitask method enjoys more flexibility than the method directly taking the variable as input[37]because the two-target multitask method can not only choose the variable accessible before the prediction time but also the variable accessible after prediction time, while the direct input method can only choose the variable accessible before the prediction time[38].
However, there are two challenges in designing the two-target multitask method: ① how to design its feature extractor to learn the noisy, nonlinear and complex temporal-spatial dependency; ② how to choose its sharing method to use the close relation between the two targets.
On one hand, it is an open problem to learn the temporal-spatial dependency between the historical high-frequency transaction data and the high-frequency price movement because of the intrinsic complexity, nonlinearity, dynamics and high noise of financial data[30,39-41]. As a result, we design the feature extractor from the global perspective rather than pursuing the optimal feature extractor applicable for all cases regardless of the other parts of the proposed method. Considering that the purpose of the method is to utilize the auxiliary target(high-frequency rate of price change) to learn the temporal-spatial dependency of more generalization of the main task to improve high-frequency price movement prediction, the feature extractor is supposed to be able to learn diverse temporal-spatial dependency for further processing of other parts of the method[42]so that the feature extractor is designed to be a combination of two different modules based on the convolutional neural network and recurrent neural network, which are the common core blocks for the feature extraction of price movement prediction task[10,19,21].
On the other hand, it is hard to choose the best sharing method suitable for all multitask method because the relation between tasks is variable and even unclear in most cases[38]. Considering that the feature extractor of the proposed method is designed to be complex to learn diverse temporal-spatial dependency, it is likely to learn from the noise rather than the true value, which is detrimental to the generalization according to the Occam’s Razor[43]so that the sharing method is expected to be able to deal with the noise[44,45]to improve the prediction. Finally, a newly gradient balancing approach(GradDrop)[46]is adopted as the sharing method, which merely updates the selected parameters for each iteration.
In summary, this paper has the following contributions:
(Ⅰ) Different from the most existing research on the high-frequency price movement prediction, which pays little attention to the close relation between the coarse-grained direction and the fine-grained rate of the price change, this paper proposes an end-to-end multitask method with two targets to incorporate the close relation to improve the high-frequency price movement prediction.
(Ⅱ) A feature extractor is designed to learn diverse temporal-spatial dependency from the historical transaction data for two targets for further processing of the other parts of the method.
(Ⅲ) A sharing method is adopted to use the close relation between two targets to filter the temporal-spatial dependency learned from the inconsistent noise and retain the dependency learned from the consistent true information to improve the high-frequency price movement prediction.
2 Methodology
The structure of the proposed multitask method is shown in Figure 1, which consists of three parts, the main task to predict the high-frequency price movement(see Section 2.1), the auxiliary task to enhance feature extraction of main task(see Section 2.2) and the sharing method to communicate information between tasks(see Section 2.3). Moreover, each task contains a feature extractor to learn diverse temporal-spatial dependency for further processing of other parts of the method and a prediction layer to fuse the dependency to get the specific prediction target. We will introduce them in detail step by step.

Figure 1. Structure of the proposed method.

Figure 2. Structure of the INTER module.
2.1 The main task
The main task is a classification task to predict the future price movement(up, unchanged or down) within a short time(e.g. one minute) with the raw historical high-frequency(e.g. one minute) transaction data. The input transaction data is a multivariate time series forTtime steps, denoted byX={X1,X2,…,XT}, with eachXt∈pcontainingpelements, such as open price, highest price, lowest price, close price, volume and position. The prediction target is the price movement, sign value of difference between close price and open price, denoted byY={y1,y2,…,yT},
(1)
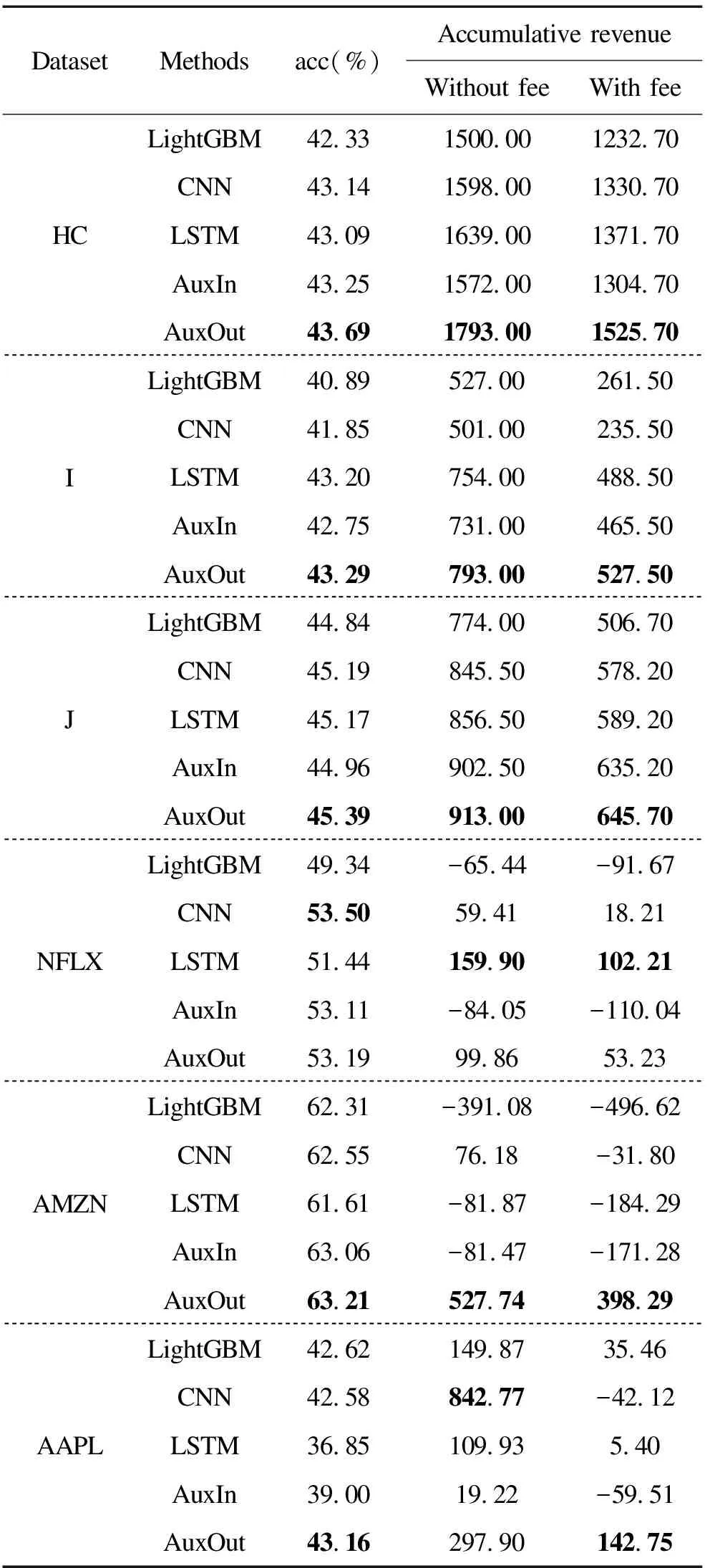
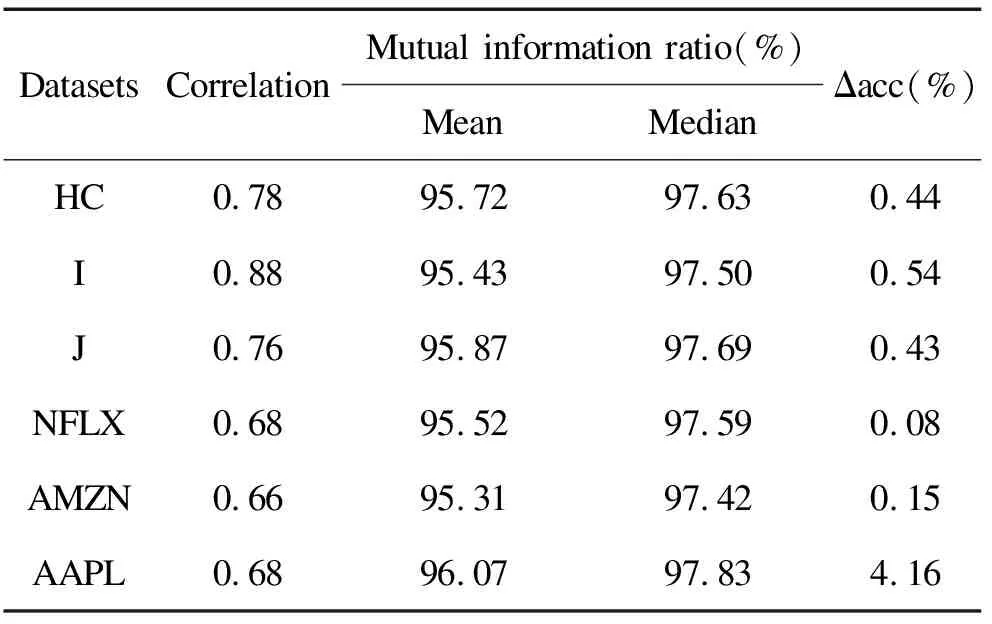
where close_pricetand open_pricetare elements ofXt. The goal of the main task is to learn a classifierP(yt+1|Xt,Xt-1,…,Xt-k+1),t=k,k+1,…,T-1 and thek 2.1.1 The feature extractor The feature extractor is the parallel combination of an INTRA module and an INTER module to learn diverse temporal-spatial dependency for further processing of other parts of the method[42]. Specifically, the INTRA module is based on the recurrent neural network to learn the dynamic sequential temporal-spatial dependency(see Section 2.1.1.1) and the INTER module is based on the convolutional neural network to learn static accumulative temporal-spatial dependency(see Section 2.1.1.2). On the one hand, the recurrent neural network and the convolutional neural network are of great learning capacity[47,48]to extract diverse temporal-spatial dependency[42]from the limited transaction input data because of their elaborate architectures(e.g. sequential calculation, shared weights and local connection). On the other hand, because the structures of the convolutional neural network and recurrent neural network are greatly different[49,50], the combination of them can probably extract more diverse temporal-spatial dependency than the single network[42], which can increase the possibility to provide the temporal-spatial dependency of generalization for further processing of other parts of the proposed method to improve the high-frequency price movement prediction[13-16]. 2.1.1.1 The INTRA module The INTRA module is designed to learn the dynamic sequential temporal-spatial dependency, which is implemented by the recurrent neural network with LSTM unit. A common LSTM unit contains forget gate, input gate and output gate to control the information flow. Specifically, given the inputXt,Xt-1,…,Xt-k+1and the LSTM unit’s hidden states sized, the outputht=INTRA(Xt,Xt-1,…,Xt-k+1) is calculated by equations (2) Due to the ranges of outputs of three gates are (0,1), they can be interpreted as the ratios for updating. More specifically, the input gateitis to protect the stored memory contents from perturbation by unrelated inputs and the forget gateftas well as the output gateotare used to protect other units from perturbation by presently unrelated stored memory contents[50]. As a result, the devotion of each input vector at different time to the final feature is decided in a data-driven way so that the devotion is totally temporally variable, which means that the feature is dynamic. Besides, with the sequential calculation of the features, the INTRA module can adaptively learn the global sequential temporal patterns. In summary, the INTRA module can learn the global dynamic sequential patterns. 2.1.1.2 The INTER module The INTER module is designed to learn the static temporal-spatial dependency, implemented by convolutional neural network. The structure of INTER is shown in Figure 2, the parallel connection of three one-layer CNNs, a temporal aggregation layer and the concatenation layer, where the CNNs are used to learn the local temporal-spatial features of temporal invariance, the temporal aggregation layer is to obtain the accumulative temporal effects of the local patterns to grasp the global temporal-spatial patterns and the concatenation layer is to concatenate the extracted features from three CNNs to an integrate feature vector. Specifically, the sizes of the filters of the three types of CNNs are different to extract the short-term, medium-term and long-term patterns. Given the input {Xt,Xt-1,…,Xt-k+1}, the output feature vector is denoted byvt=INTER(Xt,Xt-1,…,Xt-k+1). uiact=tanh(1′p(Wia⊙[Xc+t-k,…,Xc+t-k+Ti-1])1Ti+bia) (3) wherea=1, 2,…,Fandc=1, 2,…,k-Ti+1; the elements of vectors1pand1Tiare all one; {Wia∈p×Ti,bia∈,i=1, 2, 3,a=1, 2,…,F} are the set of learnable parameters, denoted byWyinter. Secondly, theF,i=1,2,3, (4) (5) OnceT1,T2andT3are given, the filter with size (T1,p) is designed to learn the short-term patterns, the filter with size (T2,p) is to learn the medium-term patterns and the filter of size (T3,p) is to learn the long-term patterns. Moreover, with the temporally local connection(with 0 2.1.2 The prediction layer The prediction layer is used to fuse the learned temporal-spatial dependency to predict the future price movement. Besides, due to the outputs of the main task are probabilities for the three classes(up, unchanged or down), the corresponding prediction layer is a fully connected layer with the softmax activation. (6) 2.1.3 The loss function (7) The auxiliary task is a regression task to improve the performance of the main task(high-frequency price movement prediction) by enhancing the learning of temporal-spatial dependency of the main task with the auxiliary target and the sharing method. Specifically, the input data and the structure of feature extractor of the auxiliary task are the same with the main task, but the prediction target is different. 2.2.1 The auxiliary target Choosing the high-frequency rate of price change as the auxiliary target can probably enhance the learning of temporal-spatial dependency of the main task to improve the price movement prediction[23]. Denote the high-frequency rate of price change byZ={z1,z2,…,zT},zt∈, (8) where close_pricetand open_pricetare the elements ofXt; theis a sufficient small positive number(e.g. 0.000001) compared with close price and open price to deal with the case when open price equals zero and cause little effect when open price is nonzero. Table 1. Close relation between the price movement and rate of price change. 2.2.2 The feature extractor 2.2.3 The prediction layer (9) 2.2.4 The loss function The auxiliary task is a regression task so that the mean squared error is utilized as the loss function. Suppose the true observation of rate of price change for the training dataset isz={zt1,zt2,…,ztN},ztn∈,n=1, 2,…,N, and its corresponding estimation is,n=1, 2,…,N, the training loss is calculated by equation (10) Through the sharing method, the main task is capable of communicating information with the auxiliary task so that the main task has the potential to incorporate the related information of the auxiliary task to learn temporal-spatial dependency of more generalization for high-frequency price movement prediction[51-54]. Moreover, the sharing method usually contains two parts: ① the sharing structure to decide the shared components and the task-specific components of different tasks; ② the sharing mechanism to decide concrete communication approach between the shared components. 2.3.1 The sharing structure The sharing structure of the proposed method is that the INTER modules of the two tasks are used as the shared components and the INTRA modules are used as the task-specific components. The shared components and the task-specific components are explicitly separated to alleviate the potential negative transfer caused by the multitask learning method[38,55]to use the relation between tasks to improve the performance of the main task(high-frequency price movement prediction)[56]. Although the high-frequency rate of the price change chosen as the auxiliary target is related with the main target(the price movement), both the targets are highly noisy[41,57]so that the multitask learning probably suffers the negative transfer[58], which will impair the high-frequency price movement prediction. Besides, the feature extractor designed to extract diverse temporal-spatial dependency is so complex that it is inevitable to incur more noise[43-45], which will probably further aggravate the negative transfer to degrade the generalization of multitask learning[58]. As a result, explicitly separating the INTER modules and the INTRA modules is probably to alleviate the potential detrimental interference between common and task-specific knowledge, which is helpful to use the relevant information of the auxiliary task to improve high-frequency price movement prediction[56]. 2.3.2 The sharing mechanism A soft sharing mechanism is utilized to communicate information between tasks not only by filtering inconsistent gradients to control the noise but also merely use consistent gradients for updation to learn the temporal-spatial dependency of generalization[46]to improve the price movement prediction. (11) (12) whereη(e.g. 0.01) is the learning rate for the INTER module. It is common that the rules with the generalization is learned from true values and the fake rules without generalization is learned from noise. For two highly related targets, it is reasonable to assume the true values of them to be consistent(the information learned from one target able to predict another target) and the noises of them to be inconsistent(the information learned from one target unable to predict another target)[46]. In addition, the multiplication of the indicator function is similar to the dropout method[59], both choosing some parameters absent from the parameters updation, but different from the dropout method, which chooses the parameters in a random way, the proposed method chooses the parameters based on the relation between the main target(price movement) and the auxiliary target(rate of price change) so that the sharing part of the proposed method can be seen as a special dropout method, which is valid to prevent overfitting[59]to improve the price movement prediction. This section evaluates the performance of the proposed method by the experiments on real-world datasets. In addition, LightGBM[60], CNN, LSTM and the direct input method(see Section 3.2.4) are used as baselines. For simplicity, we use the AuxIn to represent the direct input method and the AuxOut to represent the proposed auxiliary target method. In order to evaluate the performance of the proposed method for high-frequency trading, we conduct experiments on both future market and stock market. Specifically, we use the one-minute snapshot of the transaction data from 2014-3-21 to 2020-3-30 of three kind of Chinese futures (HC future, I future and J future), with each dataset containing the name of the future contract, the transaction date, intraday transaction time, open price, highest price, lowest price, close price, volume and position. Besides, we use the one-minute snapshot of the transaction data from 2019-1-1 to 2019-12-31 of three American stocks (AAPL and NLFX), with each dataset containing the transaction date, intraday transaction time, open price, highest price, lowest price, close price and volume. We firstly transform the raw dataset to the sliding-window format and normalize(zero mean and one variance), then separate samples after specific date(e.g. 2020-1-1 for three futures and 2019-11-1 for two stocks) as the testing dataset, ten percent of the rest samples are used as validation dataset and the rest ninety percent used as the training dataset because the number of parameters is so huge that more traning data is needed. Table 2 presents the number and ratio of three classes of the training, validation and testing dataset of different futures and stocks. Although the ratios of the up class and the down class of different datasets are relatively close, ratios of the unchanged class are slightly lower than the up class and the down class on HC, J and AAPL datasets but the slightly higher on the I, NFLX and AMZN datasets, which demonstrates that the overall distributions of training, validation and testing dataset are not extremely imbalanced. Table 2. Distributions of price movement on training, validation and testing datasets of different futures. 3.2.1 LightGBM This model tries to find the structure of the input data to predict the target based on gradient boosting decision tree[60]. The input of LightGBM is the one-dimension reshaped vector of the sliding-window data and LightGBM treats the input variables independently, which means that it ignores the spatial dependency and temporal dependency of the raw financial variables. 3.2.2 CNN It tries to learn temporal-spatial dependency of temporal-spatial invariance based on the local intersection and shared weights. Moreover, with the fixed sizes of the two-dimension filters of CNN smaller than the size of sliding-window data, CNN can extract the static and local temporal patterns. In addition, each output unit of the CNN involves information of all financial variables, which means that the features extracted by CNN are globally spatial. On the whole, the patterns extracted by CNN is statically and locally temporal and globally spatial. The input data is the sliding-window data and the target is the sole target, price movement. 3.2.3 LSTM It tries to learn the sequential structure or the context information of input by calculating the hidden states sequentially. Due to each output unit of the LSTM involves information of all financial variables and all the time points, the features extracted by LSTM are globally temporal and globally spatial. In addition, the temporal patterns are dynamic because of the three gates and the sequential calculation. On the whole, the patterns extracted by LSTM is dynamically, sequentially and globally temporal and globally spatial. The input and target is same as the CNN baseline. 3.2.4 AuxIn It is the traditional method to use a variable to predict the price movement by taking the variable as a input variable. The structure of the AuxIn is the same as the structure of the main task part of the proposed method(AuxOut) but it takes the auxiliary target as an extra input variable besides the original input variables. Although the AuxIn and AuxOut methods directly use the extra information of the auxiliary target to predict the price movement, the concrete ways are different so that we can know whether the proposed multitask method is more suitable to extract the extra information of the magnitude by comparing with the AuxIn. Accuracy rate and accumulative revenue are utilized to evaluate the performances of different methods. Given a specific minute, after getting the probability prediction for the three classes, the class of the highest probability is used as the final prediction at that time. As the price movement prediction is a three-class classification task and the overall distributions of training, validation and testing dataset are not extremely imbalanced(see Table 2), the accuracy rate is suitable to evaluate the performances of models. The accumulative revenue is used to evaluate the capability of making money. Specifically, we design a strategy to map the prediction to the accumulative revenue, that is to buy at the beginning of thetthminute and sell at the end of thetthminute when the prediction is positive, to sell at the beginning and buy at the end when negative and to not trade when zero. Besides, the accumulative revenue is the money at the end of the test period by trading following the above strategy with no initial capital. Besides, the transaction fee(e.g. 1 yuan per unit for future and 0.1% for stocks) is considered for the calculation of accumulative revenue. Particularly, the transaction fee is set two-side, which means that we should pay transaction fee whether to buy or to sell. All of the methods except LightGBM are trained based on PyTorch and the batchsize is 20% of the number of training samples. We train the models for at most 100 epochs, and choose the best parameters when the loss of the main task on the validation dataset is the smallest. As for the two-layer CNN baseline, the learning rate is 0.003 for three futures and 0.001 for two stocks, the number of filters of first layer is 128 and the number of filters of second layer is 64. As for LSTM baseline, the learning rate is 0.005 for three futures and 0.001 for two stocks, the number of layers is one and the size of the hidden units is 100. For the INTER module of the AuxIn, the learning rate is 0.005 for three futures and 0.001 for two stocks; the number of filters is 32; the parameters (S,M,L) for HC and I are set to (3,12,22) and set to (1,10,20) for J, NFLX and AAPL. For the INTRA module of the AuxOut, the learning rate is 0.01 for three futures and 0.001 for two stocks and the size of hidden states is 96. For the INTER module of the AuxOut, the learning rate is 0.005 for three futures and 0.001 for two stocks; the number of filters is 16 for the NFLX and 32 for rest datasets; the parameter (S,M,L) for HC is set to (5,15,25) and set to (1,10,20) for rest datasets. For the INTRA module of the AuxOut, the learning rate is 0.01 for three futures and 0.001 for two stocks and the size of hidden states is 16 for NFLX and 96 for rest datasets. As for the two-layer CNN baseline, we tune the number of filters and learning rate, with the number of filters of the first layer being {32, 64, 128} and that of the second being {8, 16, 64} respectively, and the learning rate being {0.001, 0.003, 0.005}. At last, the 128 filters of the first layer, 64 filters of the second layer and the 0.003 learning rate is the best. As for the LSTM baseline, we tune the number of layers and size of hidden states, with number of layers being {1, 2}, with size of hidden states being {50, 100, 192}. It turns out that one-layer and 100 hidden units are the best. As for AuxIn and the AuxOut, we tune the number of filters being {8, 16, 32, 64}, the parameter being (S,M,L) {(1,10,20), (3,12,22), (5,15,25)} of the INTER module and the size of hidden states being {16, 32, 64} of the INTRA module. Table 3 shows the performances of different models. Through comparable analysis, we can get the following results. Table 3. Comparisons of different methods. The prediction accuracy and accumulative revenue(with or without) of CNN and LSTM are higher than LightGBM in most cases so that CNN and LSTM perform better than LightGBM for high-frequency price movement prediction. This is probably because high-frequency financial data is temporal-spatial dependent so that CNN modeling static accumulative temporal dependency and LSTM modeling the dynamic sequential temporal patterns outperform LightGBM failing to consider the temporal-spatial dependency. These results also imply that the design of the feature extractor of the AuxOut is suitable for high-frequency price movement prediction because it is the combination of CNN and LSTM modeling the temporal-spatial dependency of the high-frequency financial data. The AuxOut outperforms LightGBM, CNN and LSTM on the accuracy and the accumulative revenue metrics in most of cases, which shows the two-target multitask method considering the related auxiliary target is better than the single task method failing to consider the related auxiliary target. Because the relation between the main target(high-frequency price movement) and the auxiliary target(high-frequency rate of the price change) helps the two-target multitask method to find a more certain distribution of the main target(high-frequency price movement) so that the two-target multitask method shows more generalization and gets better prediction performance. The AuxOut performs better than the AuxIn concerning the accuracy and the accumulative revenue metrics in all cases, which indicates that taking the high-frequency rate of price change as the auxiliary target is better than taking it as the direct input variable. Moreover, Table 4 adds that the closer the relation between the high-frequency price movement and the rate of the price change, the better the two-target multitask method performs than taking the extra variable as the direct input method. Table 4. Intensity of relation of the two targets and the performance difference of the two-target method and directly taking the extract variable as input variable. To explore the effects of the auxiliary target on the different temporal-spatial dependency learned by different parts of feature extractor in more detail, we conduct the ablation study by removing the link mechanism manually and comparing the performances of different modules with those of the original AuxOut. Specifically, we take the outputs of different modules as the input features to train LightGBM model and then evaluate their performances. In addition, the output of INTRA module is its last hidden states, the output of INTER module is the concatenation of outputs of three convolutional neural networks before the sum aggregation layer, and the output of the method is the concatenation of the above two outputs. Table 5 shows the changes of the prediction accuracy of the features of different modules after removing the auxiliary target. The auxiliary target can improve the generalization of the overall temporal-spatial dependency because the performances of feature combination of INTER & INTRA are worse after removing the auxiliary target. Moreover, the auxiliary target can improve the generalization of the static accumulative temporal dependency because the performances of feature of the INTER module are worse after removing the auxiliary target. Besides, the auxiliary target can improve the generalization of the dynamic sequential temporal dependency because the performances of feature of the INTRA module are worse after removing the auxiliary target. The two-target multitask method, with coarse-grained high-frequency price movement as the main target and fine-grained rate of price change as the auxiliary target, is proposed to utilize the close relation between its two targets to filter the high noise of targets and learn the rules with generalization from the true value to improve the high-frequency price movement prediction. On one hand, a feature extractor is designed to learn diverse temporal-spatial dependency for further processing of other parts of the method to predict the price movement, which consists of two modules based on recurrent neural network and convolutional neural network respectively to learn the dynamic sequential and the static accumulative temporal-spatial dependency of the high-frequency transaction data. On the other hand, a gradient balancing approach is adopted to use the close relation between two targets to filter the temporal-spatial dependency learned from the inconsistent noise and retain the dependency learned from the consistent true information to improve the high-frequency price movement prediction. Experimental results demonstrate that the method outperforms all the baselines in most cases, which shows that the method manages to incorporate the related information between high-frequency price movement and rate of price change to improve the prediction accuracy of the price movement. Moreover, through comparing the performance of different modules with and without the auxiliary target, we find that the auxiliary target not only improves the generalization of overall temporal-spatial dependency learned by the whole feature extractor but also improve temporal-spatial dependency learned by the different parts of the feature extractor. At last, we give some future research suggestions: ① to model more high-frequency data(e.g. five-minute data); ② to search more valid auxiliary target; ③ to design better feature extractors(e.g. deeper neural networks). Acknowledgments This work is supported by National Natural Science Foundation of China (No.71873128). Conflictofinterest The authors declare no conflict of interest. Authorinformation MaYulianis a master candidate at School of Management, University of Science and Technology of China. Her research field is financial engineering and quantitative investment. CuiWenquan(corresponding author) is an associate professor at School of Management, University of Science and Technology of China (USTC). He received the PhD degree of statistics from USTC. His research interests focus on multivariant survival analysis and machine learning.
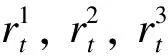
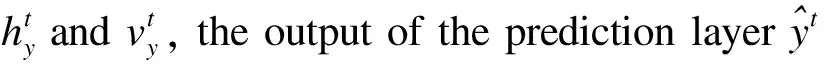

2.2 The auxiliary task
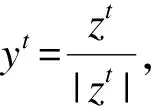


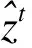
2.3 The sharing method

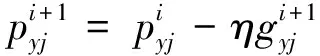
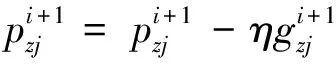

3 Experiments
3.1 Description of datasets

3.2 Compared methods
3.3 Evaluation metrics
3.4 Experimental settings
3.5 Experimental results and analysis
3.6 Ablation study
4 Conclusions
