
基于多分辨率多类特征融合的梨叶小炭疽病斑识别
2021-09-27 03:52薛卫易文鑫康亚龙徐阳春董彩霞
南京农业大学学报 2021年5期
薛卫,易文鑫,康亚龙,徐阳春,董彩霞*
(1.南京农业大学人工智能学院,江苏 南京 210095;2.南京农业大学江苏省固体有机废弃物资源化高技术研究重点实验室/江苏省有机固体废弃物协同创新中心/教育部资源节约型肥料工程技术研究中心,江苏 南京 210095)
梨是世界第三大果树产业,仅次于柑橘和苹果。我国梨园面积和产量均居世界第一[1]。近年来,随着全球气候不稳定变化,我国南方的梅雨期加长,降雨量增大,导致梨主产区出现不同程度的早期落叶现象,尤其以长江流域以南的省份如福建、江西等砂梨(PyruspyrifoliaNakai)产区发生范围大,危害严重[2]。调查发现,南方梨树发生落叶的主要原因是炭疽病菌(Colletotrichum)侵染造成的,主要包括C.citricola、C.conoides、C.karsti、C.plurivorum、C.siamense和C.wuxiense共6种[3]。这些炭疽病菌在梨叶面定殖后可形成大量的黑色小斑点(直径小于1 mm或直径为1~2 mm)。在发病初期,直径小于1 mm的黑色小斑点不易被肉眼识别,随着侵染程度的加重,肉眼可见的黑色斑点越来越多,分布在整个叶面,叶片开始发黄,最终脱落。通常,梨叶片炭疽病发病程度的高低主要通过在显微镜下人工统计叶面黑色小斑点的数量进行评价[4-5],该过程费时费力、误差大,很容易错过防治的最佳时期。因此,快速、高效检测方法对及时诊断梨树炭疽病的危害程度并采取有效措施具有重要意义。
深度学习是近年来比较热门的图像识别方法,在农业病害[6]领域得到广泛的应用,例如烟叶病害识别[7]、苹果病害识别[8]与麦冬叶部病害识别[9]等。大部分病害检测针对整张叶片提取特征进而识别出病害,或者分割出叶片大块病斑,而梨叶炭疽病发病程度的高低则需要识别出叶片中每个细小病斑。梨叶炭疽病斑在整张图像中所占像素数极少,属于目标检测中一个难题。对于小目标,国际光学工程学会(SPIE)对它的定义是小于图像尺寸0.12%的物体[10]。梨叶单个炭疽病斑像素点数占比远小于0.12%,可归结于小目标检测的范畴。
当前较流行的目标检测框架如R-CNN(region-based convolutional neural networks)系列(R-CNN、Fast R-CNN和Faster R-CNN)[11-13]、YOLO(you only look once)系列[14-16]和SSD[17]等对于小目标检测的效果都不太理想。有学者提出利用多层特征、逐层预测等策略改善小目标检测效果。Hariharan等[18]摒弃了卷积神经网络最后一层作为特征表示,在前面几层进行精确定位,实现了既能精确定位又能获取较好的语义信息的效果。Bell等[19]从上下文信息和多尺度入手,提出了内外网络结构,通过ROI区域的内外部信息进行区域识别。Lin等[20]采用多尺度特征融合的方式,对不同特征层特征融合之后的结果进行预测。李就好等[21]修改区域建议框的尺寸与数量,并结合特征金字塔网络结构提高小目标检测能力。农业领域,马彦彦等[22]采用多尺度卷积提取深度特征获取病斑叶片区域,利用SVM进行像素分割得到病斑精准边界。Wiesner-Hanks等[23]提出专家标注结合卷积神经网络以及条件随机场的植物病害检测方法,实现病害的毫米级检测。从结果看,多尺度策略和修改建议框可以在一定程度上提高准确率,但受目标区域大小的影响,此类算法仍难检出很小的目标。因此,梨叶炭疽病斑小目标检测具有重要的研究价值。
本文构建梨叶炭疽病斑小目标识别算法,提出采用细粒度颜色矩(FG-CM)描述病斑的颜色特征,用LBP、HOG提取病斑的纹理和形状特征,然后基于随机森林对颜色、纹理和形状特征优化降维。最后在多分辨率下送入随机森林分类融合得出最终识别结果。与现有算法相比,优化后特征小目标表达能力更强,多尺度下分类融合可检测出更多小病斑。
1 材料与方法
1.1 图像采集
梨叶病害图像取自福建省三明市建宁县溪口镇枧头村福建省农业科学院果园试验站(34°04′N,108°10′E)。该试验站属于山地果园,地处亚热带季风气候,年平均气温约16.9 ℃,平均年日照时数1 720 h,无霜期230~280 d,年降水量1 850 mm。土壤类型为黏质红壤土,土壤有机质含量、全氮含量、速效钾含量以及速效磷含量分别为19.7 g·kg-1、 1.49 g·kg-1、 49.0 mg·kg-1和37.7 mg·kg-1,pH值为 5.33。
在试验园区进行梨叶采摘,采摘后在实验室用iPhone 6s智能手机后置摄像头拍照。摄像头正对叶片表面,距离叶片10 cm。图像格式为JPG格式,图像分辨率为4 032像素×3 024像素。将采集到的图像进行整理挑选,共挑选到200张拍摄效果良好的图像作为试验数据样本。为了探究在其他病害影响下炭疽病的识别准确率,增强模型的鲁棒性,需要采集其他病害样本。由于时间以及人力有限等原因,采用爬虫技术在网上爬取梨叶病害图片。其中包含白粉病、褐斑病、黑斑病、黑星病、轮纹病及锈病等6种常见病害,部分样例如图1所示。

图1 数据采集样本图Fig.1 Samples of data acquisition
1.2 数据增强
使用工具Labelimg标注样本,数量如下:炭疽病2 789个,白粉病810个,褐斑病591个,黑斑病269个,黑星病517个,轮纹病300个,锈病618个。各类病害样本数量极不均匀,影响模型识别的准确率[24],因此对数据做增强处理。数据增强有以下一些方法,例如裁剪、旋转、翻转、缩放、平移、添加噪点、亮度调整[25]、色度增强、对比度增强和锐度增强[26]等方法。选取6种方法进行数据增强,其中翻转为水平翻转和垂直翻转,旋转包括旋转30°、60°和90°。图2即为数据增强的样例,共产生58 940个样本。将样本混合,70%作为训练集,30%作为测试集,数据集增强方法和数量如表1所示。
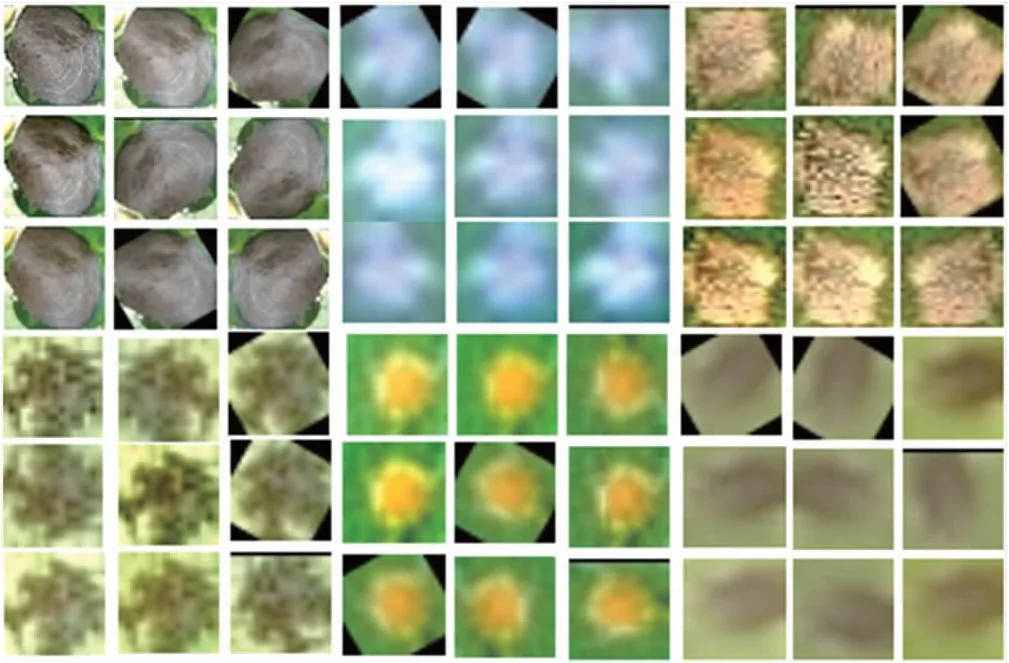
图2 部分数据增强样例Fig.2 Some data augmentation examples

表1 数据集增强前、后数量对比Table 1 Comparison of data sets before and after augmentation
1.3 梨叶炭疽病识别模型
1.3.1 模型流程模型由训练和病斑检测2部分组成。1)模型训练。首先提取各类病斑区域的颜色、纹理以及形状3类特征。颜色特征采用FG-CM表示,纹理、形状特征分别采用LBP和HOG表示。然后,将这3种特征进行融合,使用随机森林算法进行特征选择。最后送入分类器进行训练。2)病斑检测。输入梨叶图片,首先利用超绿特征空间分割算法,生成只含有叶片区域的图片。然后采用局部自适应阈值分割以及形态学算法提取多分辨率下的病斑区域,并提取病斑区域的最优选择特征进行病斑区域识别。最后在多分辨率下对识别结果去重融合,识别出炭疽病斑。模型流程图如图3所示。
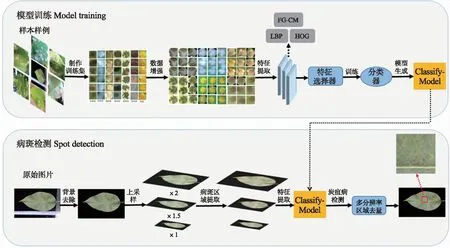
图3 梨叶炭疽病识别算法流程图Fig.3 Algorithm flow chart of pear leaf anthracnose recognition
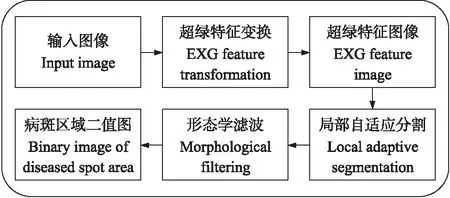
图4 炭疽病斑区域提取流程图Fig.4 Flow chart of anthracnose spot area extraction
1.3.2 病斑区域提取病斑区域提取主要由 2步组成:基于超绿算法将叶片与背景分割开,降低直接分离病斑图像的难度;再用局部阈值分割算法从叶片提取出疑似病斑区域。这样能减少大量的非病斑目标区域,极大降低了后续算法的时间复杂度,算法流程图如图4。
超绿特征[27]被广泛用于农业领域的植物叶片分割中。正常采集到的植物叶片中一般含有杂草、土壤等背景物体,超绿特征可抑制这些背景,将叶片从图像中分割出来。
超绿分割算法表达式如下:

(1)
式中:(x,y)代表像素点坐标;EXG(x,y)代表超绿化后灰度图的灰度值;G(x,y)、R(x,y)、B(x,y)分别表示彩色图像在G、R、B空间值,范围为[0,255]。
超绿灰度图中灰色像素区域为梨叶叶片区域,黑色部分为背景区域或部分病斑区域。将超绿灰度图进行阈值分割得到完整叶片区域,通过局部自适应阈值分割以及形态学算法即可得到病斑区域,如图5所示。
多分辨率下进行形态学操作时选择的是结构单元,分别为7×7、11×11以及15×15像素的矩形。

图5 病斑区域提取Fig.5 Disease spot area extraction 图(d)为从图(c)中截取的局部放大图,为便于观察提取出的病斑区域。Figure(d)is a local enlarged image intercepted from figure(c),in order to facilitate observation of the extracted disease area.
1.3.3 特征提取提取有效的图像特征是实现病斑准确识别的重要环节。本文提取病斑区域颜色、纹理以及形状3类特征,颜色特征采用FG-CM表示,纹理、形状特征分别采用LBP[28]和HOG[29]表示。LBP特征具有灰度不变性、旋转不变性且运算速度快等显著优点,可稳定描述梨叶病斑的纹理特征。采用HOG计算得到的描述子保持了几何和光学转化不变性(除非物体方向改变),因此适合局部形状的检测。
颜色是人眼最直观感受到的特征,颜色矩是Stricker等[30]在1995年提出的一种通过计算矩来描述颜色分布特点的方法。颜色矩基于简单数学计算,能够有效描述颜色特征,可表达病斑区域的颜色特征。考虑到颜色信息主要集中在低阶矩中[31],选取病斑区域的一阶矩、二阶矩、三阶矩来表达梨叶不同病斑的颜色特征。针对小目标病斑和对象粒度较小的问题,提出细粒度颜色矩计算方法,以增加数据维度,提高特征表达能力。
传统的颜色矩提取方法是将梨叶病斑区域从RGB空间转化为HSV空间,获取图像的 H、S、V 3个分量信息,分别计算图像的H、S、V 3个分量上均值、方差和斜度,然后进行最小值归一化处理,每张病斑区域图像得到9 维颜色矩特征FCM。
FCM=[μH,σH,ζH,μS,σS,ζS,μV,σV,ζV]
(2)
采用改进的颜色矩即FG-CM提取方法,用4×4大小的滑动方块以不重叠的方式提取颜色特征。由于图像都归一化到28×28大小,因此一共将图像分成49块,然后将所有方块的传统颜色矩特征进行串联融合,作为整张图像新的颜色矩特征,即细粒度颜色矩,每张病斑区域得到441维(9维×49)细粒度颜色矩特征FFG-CM。
FFG-CM=[F1,F2,F3,…,F49]
(3)
式中:F1到F49分别为第1到第49个方块的9维传统颜色矩。
1.3.4 特征选择将3种特征FLBP、FFG-CM和FHOG串联融合,得到841维融合特征F+。
F+=[FFG-CM,FLBP,FHOG]
(4)
直接将融合特征送入分类器进行分类,特征维数太高会导致运行过慢,过度占用系统资源,影响算法效率,故采用随机森林算法进行特征选择减小维度。
一般随机森林树的个数(n_estimators)越多,分类越准确,但是会导致模型过大,分类速度缓慢。通过试验分析n_estimators(10~200)与准确率的关系,如图6所示,当n_estimators为80时,分类准确率最高,且树的数量并不大,故80为最佳树的个数。
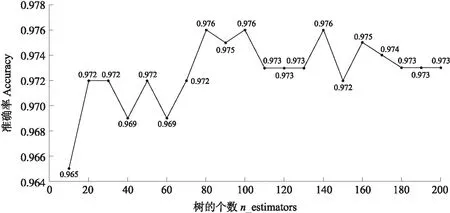
图6 随机森林最佳树的数量Fig.6 The optimal number of trees in random forest
用随机森林修剪最不重要的特征,直到最终达到所需特征的数量,在交叉验证中得到最佳特征的数量和特征重要度排名(图7)。排名前200的特征重要程度总和较大,后面641个特征重要程度近乎为0,故选择前200个特征作为最终特征,减小算法模型训练的时间复杂度。
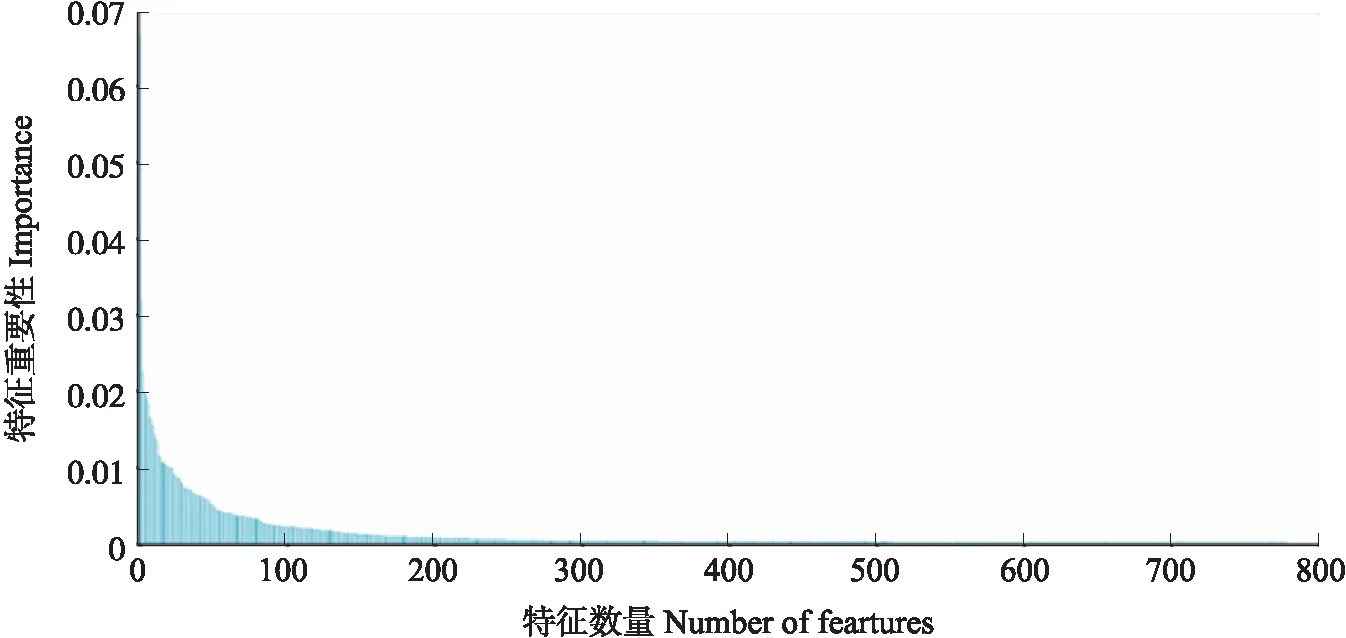
图7 随机森林特征选择重要性度量Fig.7 Importance measurement of random forest feature selection

图8 降维特征占比Fig.8 Percentage of each feature after feature selection
对上述随机森林选择的200维特征,按照特征重要性排序,得到如下结果:97维属于细粒度颜色矩向量,67维属于LBP特征向量,36维属于HOG特征向量。特征向量中细粒度颜色矩占比最大,达到了48.5%(图8)。由此可见,细粒度颜色矩在3类特征中重要性最大,在梨叶炭疽病检测当中起到关键性的作用,LBP特征和HOG特征分别占33.5%和18%,表明在炭疽病检测中HOG特征起的作用较小。
1.3.5 多尺度检测模型小目标检测的难点在于其所占像素极少,分辨率低,图像模糊,携带的信息少,由此导致特征表达能力弱。本文基于图像金字塔的思想,在图像3个尺度上进行随机森林识别融合(图3)。通过上采样的方法将图像分别放大1.5和2倍,在高分辨率下小目标被放大,从而更容易被检测到。在多分辨率下可能1个病斑存在多个检测框,根据重叠度(IOU)大小设置阈值为0.5,若IOU大于该阈值,则将该候选框去除,直到没有重叠的疑似病斑检测框,即为病斑识别结果。
IOU计算公式:
(5)
式中:U、V分别代表2个候选框,U∩V指候选框重叠区域面积,U∪V指2个候选框覆盖面积。
随机森林基于Python机器学习Scikit-Learn包中的sklearn.ensemble.RandomForestClassifier模块建立。部分参数设置如下:max_depth,决策树的最大深度,设置为10;min_size,子树的最小规模,设置为1;n_estimators,决策树的个数,设置为200;max_features,最大特征数,设置为300;random_state,控制模型的随机状态,设置为0。
2 结果与分析
2.1 模型训练
试验软件环境为Windows 10的64位操作系统,计算机内存为16 GB,搭载Intel Core E5-2650 v4处理器,并采用英伟达 GTX 1080Ti显卡加速图像处理。深度学习开源框架采用Pytorch 1.1.0,编程语言为 Python 3.6.4。
随机森林分类器生成树个数以及最大特征数分别设置为200和300,训练次数为200。对比试验中,BP神经网络模型的训练次数设置为100,设置有2个隐含层,节点数分别为80和50,神经元激活函数选择tansig函数。SVM分类器使用sklearn中的svc函数,核函数选用的是Rbf核函数,训练次数为100,C的取值为0.85,Gamma取值为9 000。R-CNN算法训练阶段的迭代次数为2 000,初始学习率为0.01,batchsize为200。Faster R-CNN算法选用 VGG16 网络作为特征提取网络的基础网络,包含 9 种锚框,其长宽比为 0.5、1、2,尺寸为8、16、32。训练阶段的迭代次数设置为30 000次,初始学习率设为0.001,batchsize为256,学习率的衰减系数和动量分别为0.1和0.9。SSD算法采用了VGG16模型作为基础模型,将VGG-16网络结构的2个全连接层改为卷积层,并增加4个卷积层来预测位置坐标的偏移和置信度,算法的输入是 300×300×3,采用 conv4-3、conv7、conv8-2、conv9-2、conv10-2 和 conv11-2 的输出来预测位置和置信度。训练阶段采用动量为0.9的随机梯度下降算法进行优化,共训练40 000次,batchsize为128,初始学习率为0.001,每4 000次进行学习率衰减,衰减系数为0.1。
2.2 评价指标
为了检验炭疽病识别效果,采用机器学习常见的5种指标,分别为准确率(accuracy),精准率(precision),召回率(recall),误报率(false positive rate,FPR),真负率(specificity)[32]。计算公式如下:

(6)

(7)

(8)

(9)
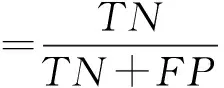
(10)
式中:TP为正确识别正样本个数;FP为错误识别正样本个数;TN为正确识别负样本个数;FN为错误识别负样本个数。
2.3 炭疽病识别
将炭疽病和其他病害分为2类,炭疽病作为正类,标签为0,其余6种病害标为负类,标签为1。将它们的颜色、纹理以及形状特征进行融合后,分别送入BP、SVM以及RF分类器中分类。数据集分为训练集和测试集,训练集与测试集的数据是独立不相同的。首先使用训练集数据对分类器进行训练,然后将测试集数据送入训练好的分类器中进行识别分类,计算测试集的准确率,最终得出梨叶炭疽病识别结果(表2)。

表2 炭疽病识别结果Table 2 Anthracnose recognition results
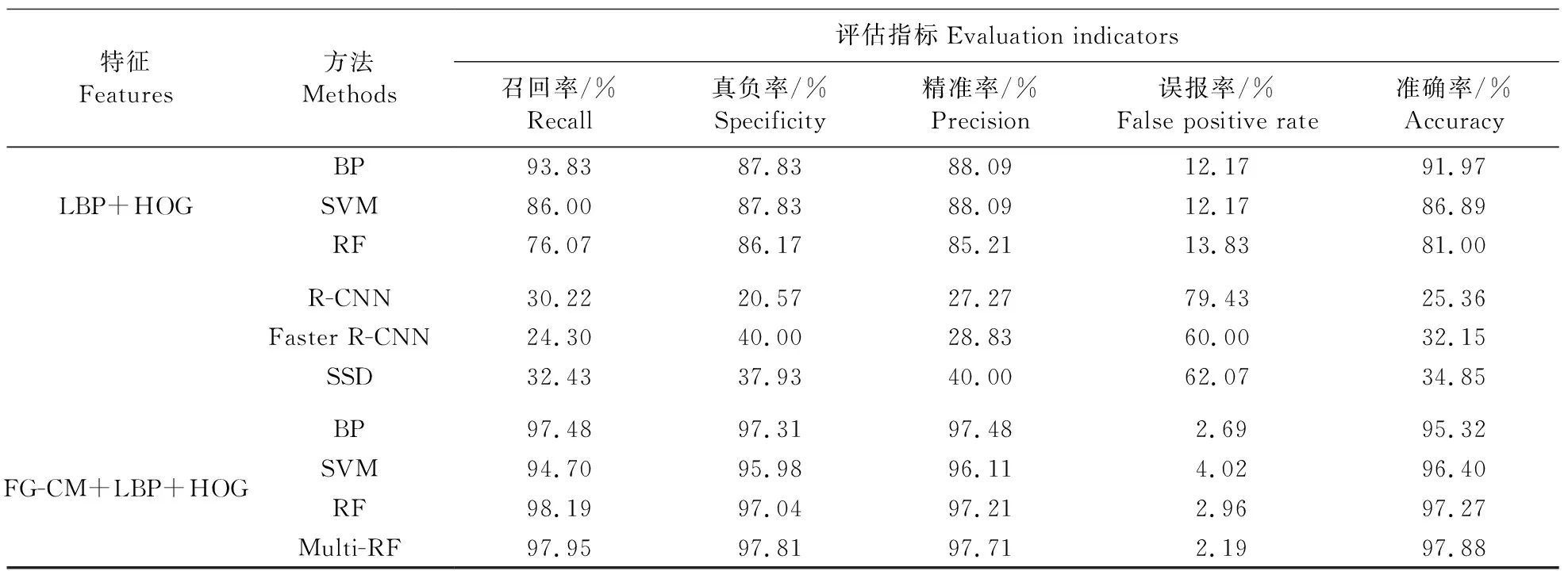
续表2 Table 2 continued
从表2可以看出,单特征中颜色特征的识别准确率最高,达到87%,HOG特征识别的准确率最低,可能原因是病斑大多都是类圆形,颜色和纹理差异比较明显造成的,这也刚好验证了在1.3.4节利用随机森林算法进行特征选择时,细粒度颜色矩FG-CM占比最大、LBP特征次之、HOG占比最小的结果。同时,对比其他识别算法,发现SVM算法的准确率比BP提高了大约2%,达到96.40%,单尺度随机森林算法比SVM算法的准确率提高了大约0.8%,达到97.27%。采用Multi-RF识别炭疽病,准确率达到97.88%,比不采用多分辨率方法提升了约0.6百分点。
深度学习算法R-CNN、Faster R-CNN以及SSD算法对炭疽病检测的效果非常差,准确率和召回率都在35%以下,这是由于本研究的炭疽病属于小目标,目标尺寸小。在上述目标检测模型中,基础骨干神经网络(VGG系列和Resnet系列)有几次下采样处理,导致小目标在特征图的尺寸基本上只有个位数的像素大小,小目标特征的感受野映射回原图将大于小目标在原图的尺寸,从而造成此类目标检测分类器对小目标的分类效果差。
为便于观察小病斑的识别效果,仅展示1张完整梨叶病害图像中截取的部分(图9)。原分辨率下,一些小的炭疽病斑点识别不出来,但是在上采样的图像中识别出来了,说明多分辨率策略是有效的。

图9 多分辨率试验结果Fig.9 Multi-resolution experimental results
2.4 细粒度颜色矩
标准颜色矩特征是区域整体计算,FG-CM将图像分块,分别提取每一小块的颜色矩特征,然后将它们融合形成一个新的颜色矩特征。
为了确定最佳分块大小提取颜色特征,试验分别对比了28×28图片中采用4×4、7×7分块大小,以及40×40图片中用4×4、7×7分块大小,试验结果如表3所示,其中40×40图片采用7×7分块来提取细粒度颜色矩特征,由于无法整除,采用了边缘填充2个像素的方法进行扩边。
从试验结果可看出,当病害图片大小为28×28且滑动窗口采用4×4大小时,准确率最高,达到97.27%,FG-CM比传统颜色矩方法效果提升了2百分点。
2.5 病斑特征差异对比分析
从各类病害中随机选取3张,如图10所示,直观上炭疽病与黑斑病比较相似,与其他病害的颜色、纹理和形状都有较明显的差异。

表3 基于随机森林分类方法的图像分块试验Table 3 Image block experiment based on random forest classification method

图10 选取的梨叶病害样本示例Fig.10 Selected pear leaf disease samples A1—A3. 炭疽病Anthracnose;B1—B3. 白粉病Powdery mildew;C1—C3. 褐斑病Brown spot;D1—D3. 黑斑病Black spot;E1—E3.黑星病Venturia;F1—F3. 轮纹病Ring rot;G1—G3. 锈病Rust.
为了进一步量化表达与分析梨叶炭疽病与其他几类病害的差异,随机在每类样本库中抽取20张病斑区域样本,分别提取FG-CM、LBP以及HOG,并取均值作为该类病害的特征,然后计算均方误差来度量它们之间的差异,RMSE代表均方误差,对比结果如图11所示。
(11)
式中:n为特征向量的维数;αi代表α特征向量的第i个值;βi代表β特征向量的第i个值。
由图11可知,从颜色、纹理以及形状差异上看,黑斑病与炭疽病均方误差分别为0.14、0.12和0.05,均小于其他病斑与炭疽病班的均方误差,这表明在所有病斑中,黑斑病与炭疽病最为相似。炭疽病与其他病害在颜色特征上的差异大于纹理,而纹理大于形状,表明使用颜色更易于区分病斑,结论与特征选择结果、单颜色特征分类结果一致。
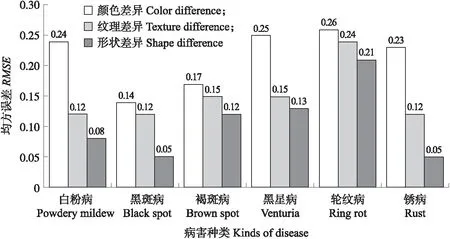
图11 各类病害与炭疽病之间的差异对比Fig.11 Differences between various diseases and anthracnose
3 结论
本文提出将适合小目标颜色特征表达的FG-CM、LBP 和HOG作为病斑区域特征,并通过多分辨率去重融合算法完成病斑识别。基于随机森林特征选择分析FG-CM、LBP和HOG 3种特征在炭疽病斑识别中的作用,发现FG-CM在融合特征中占比最高,达到48.5%,在识别过程中起到最关键的作用,LBP次之,HOG特征重要性最低;且炭疽病与其他病害在颜色特征上的均方误差差异也大于纹理和形状特征,体现出炭疽病与其他病害颜色差异明显,构建的特征参数有效。识别结果表明,融合特征随机森林识别效果优于单项特征以及两两融合的特征提取算法,Multi-RF优于单尺度随机森林和其他分类器;至于R-CNN、Faster R-CNN及SSD等代表性深度学习算法,由于受到下采样处理、建议框等制约,检测效果远低于本文算法。本文多分辨率融合特征识别算法较好解决了梨叶小炭疽病斑识别问题,可实现梨树炭疽病危害的有效诊断。
猜你喜欢
今日农业(2022年15期)2022-09-20
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
烟台果树(2021年2期)2021-07-21
现代畜牧科技(2021年4期)2021-07-21
计算机技术与发展(2020年12期)2020-12-25
今日农业(2020年19期)2020-11-06
江苏农业科学(2016年8期)2017-02-15
家庭医药(2015年8期)2015-09-10
家庭医药(2015年7期)2015-09-10
