
基于VMD-NCWOA-LSSVM的短期电力负荷预测方法
2021-09-24 03:13:04胡文波陈璟华赖伟鹏
宁夏电力 2021年4期
胡文波,陈璟华,赖伟鹏
(广东工业大学 自动化学院, 广东 广州 511400)
0 引 言
在现代经济飞速发展的今天,全国各地用电量也随之增长,负荷预测的精度影响着电网的经济调度,甚至影响系统的安全运行,故提高负荷的预测精度对于确保电力系统的可靠运行具有十分重要的意义[1-4]。近年来,随着智能算法的不断发展,人工神经网络和支持向量机(support vector machine,SVM)为代表的机器学习方法开始在电力负荷预测上得到应用[5]。孟凡喜[6]等人针对人工神经网络在小样本、非线性回归问题中的预测精度不高的问题,建立支持向量机的负荷预测模型,验证了SVM预测模型在负荷预测中的精度比人工神经网络高、训练时间更短等优点,但SVM求解复杂、计算耗时且对缺失数据不敏感。针对SVM的弱点,杜颖[7]等人提出一种基于最小二乘支持向量机(least square support vector machine,LSSVM)的预测模型,使用等式约束代替不等式约束,将二次规划问题转为求解线性方程,降低了求解复杂性,解决了SVM求解难的问题,同时用平方差损失函数代替SVM中的不敏感损失函数,解决了SVM的数据敏感性问题,提高了预测的精度。针对LSSVM参数依靠经验选取的问题,赫晓弘[8]等人使用粒子群优化算法(particle swarm optimization,PSO)优化LSSVM的正则化参数和核函数参数,解决了参数选择的盲目性问题,但是由于PSO的寻优性能的局限性,故存在收敛速度慢、易陷入局部最优的问题。对此,陈友鹏[9]等人提出使用鲸鱼优化算法(whale optimization algorithm,WOA)优化LSSVM参数的负荷预测模型,提高了优化算法的收敛性能,但WOA的收敛因子是线性变化的,因此算法前期的全局寻优能力以及后期的局部探索能力不强,而且初始化种群时采用的是随机化机制,使得算法易受初值的影响,容易陷入局部最优。
上述预测模型虽然在一定程度上提高了预测精度,但是都忽略了原始负荷数据具有非线性、非平稳性、时序性等特点,针对这个问题,徐少波[10]等人提出了一种经验模态分解(empirical mode decomposition,EMD)来处理电力负荷数据,依据电力负荷数据自身的时间尺度特征进行分解,再根据预测模型重构得到预测值,负荷预测模型的精度在某些时候得到了提高,但是EMD分解数据时存在过包络、欠包络、端点效应和模态混叠,分解过程需多次迭代及停止迭代条件缺乏标准等问题,导致预测精度降低。为此赵凤展[11]等人提出采用变分模态分解(variational mode decomposition,VMD)来处理电力负荷数据,通过寻找约束变分模型的最优解来实现原始负荷数据的自适应分解,将历史负荷数据分解为它的多尺度分量之和,解决了端点效应和模态混叠的问题,使分解序列可筛选,有效提高了负荷预测精度。为此,本文采用VMD对原始负荷数据进行处理。
此外,针对WOA后期的局部开发能力不强和算法受初值影响易陷入局部最优的问题,采用混沌映射策略和非线性收敛因子改进WOA,最终构建基于VMD-NCWOA-LSSVM的短期负荷预测模型,算例仿真结果验证了本文所提预测模型的有效性。
1 变分模态分解
VMD方法可有效地抑制端点效应和模态混叠现象,适用于非平稳信号的分解;同时,VMD可以根据信号本身的频率特性,将复杂信号分解为一系列中心频率不同的模态分量,具有精度高、分解速度快和对噪声具有很强的鲁棒性的优点[12-13]。分解步骤如下。
1.1 建立约束变分方程
VMD将函数F(t)分解为K个固定频率的模态函数uk,模态之和等于F(t)2个约束条件,其数学描述为
(1)
式中:t—时刻;
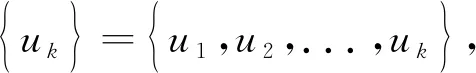
k—模态函数个数;

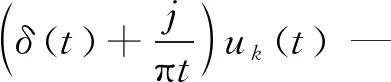
δ(t)—狄拉克分布。
1.2 建立无约束变分方程
通过引入惩罚因子α和拉格朗日算子λ,将方程(1)的约束变分问题转化为无约束变分问题,其数学描述为
(2)
1.3 交替更新确定最优解
为了求解第二步中方程(2)的uk,可根据方程(3)和(4)求解。
(3)
(4)
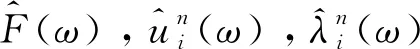
n—迭代次数;
ω—频率值。
变分模态分解算法流程如下:
1)输入分解数列F(t)。
2)初始化,令n=0。
(5)
5)重复计算迭代,直到满足式(6)
(6)
2 最小二乘支持向量机(LSSVM)
LSSVM是标准SVM的改进和扩展,它将标准SVM的不等式约束转化为等式约束,将损失函数和误差平方作为训练样本的经验损失;同时,将二次规划问题转化为求解线性方程组的问题。在求解问题时,与原方法相比,有效降低了模型的复杂度,提高了运算效率和收敛精度[14]。其回归过程如下:
1)给定样本集合
式中:xi—输入量;
yi—输出量;
n—样本总数。
LSSVM回归模型可表示为
F(x)=ωTφ(xi)+b
(7)
式中:ω—特征空间中的权系数向量;
b—偏差向量,b∈R;
φ(xi)—将原始样本映射到高维特征空间的非线性映射。
2)将式(7)转化为如下的二次规划问题:
(8)
式中:c—惩罚系数,可以调整泛化能力与训练的准确性;
εi—回归误差向量。
3)构造拉格朗日函数可得:
(9)
式中:λi—拉格朗日乘算子。
4)分别对ω,b,ε,λ求偏导,可得下述等式约束:

消去ω和εi可得LSSVM的最终模型为
(11)
式中:k(x,xi)—核函数。
本文选取径向基核函数作为模型的核函数:
(12)
3 改进鲸鱼优化算法
2016年,Mirjalili和Lewis从座头鲸的捕食行为中得到启发,提出一种新型群智能优化算法——鲸鱼优化算法(WOA)。该算法用螺旋函数来模拟座头鲸的攻击机制,用随机或者最佳搜索粒子来模拟追逐猎物的狩猎行为,其算法原理简单,参数较少,可操作性强[15]。
3.1 包围猎物
标准WOA算法在模拟座头鲸在捕食时,假设当前的最佳候选解为最优解,以此为基础更新位置,其位置更新数学模型如下:
(13)
式中:t—当前迭代次数;
X*(t)—当前最佳的解向量;
X(t)—当前解向量;
D—当前解向量与最佳解向量之间的随机距离;
A和C—系数向量,系数向量A和C的更新公式如下:
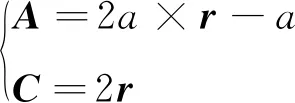
(14)
式中:r—(0,1)区间内的随机向量;
a—在(0,2)区间内线性减少的收敛因子,a=2-2t/Tmax,其中,Tmax为最大迭代次数,t为当前迭代次数。
3.2 狩猎阶段
标准WOA算法在模拟座头鲸捕猎时,建立1个螺旋位置更新数学模型。首先计算鲸鱼群到猎物的距离,模拟座头鲸的螺旋游动行为创建1个螺旋运动数学模型。数学模型如下:
(15)
式中:D—鲸鱼与目标之间的距离;
b—常系数;
l—[-1,1]区间内的随机数。
标准WOA算法模拟座头鲸狩猎时,会出现泡泡包围或者螺旋上升进攻猎物两种攻击行为,因此采用50%概率决定使用哪种攻击方式。其数学模型为
(16)
式中:p—(0,1)区间上的随机数。
3.3 搜索捕食阶段
标准WOA算法在模拟座头鲸搜索猎物时,可以根据向量A的随机变化模拟鲸群个体位置随机搜索猎物,搜索捕食的数学模型如下:
(17)
式中:Xrand—随机的鲸群位置向量。
3.4 混沌鲸鱼优化算法(chaotic whale optimization algorithm,CWOA)
鲸鱼优化算法在初始化种群时,均匀地分布在解空间有助于算法对地空间更完整的探索,同时避免因初始化不均匀导致算法过早地陷入局部最优。混沌策略的改进能得到更好的初始化种群,因此本文采用Piecewise映射对鲸鱼算法进行改进。在混沌映射的改良方法中,Piecewise和Tent映射在面对单峰函数和多峰函数时均能改善标准WOA算法的性能,但Tent映射在迭代序列中存在0,0.25,0.5,0.75等不稳定周期点,经过一定的迭代次数,可能会迭代到不动点[16]。Piecewise映射避免了不稳定周期点的出现;因此本文采用Piecewise映射来改进WOA,提高算法的性能,从而提高负荷预测的精度。Piecewise映射数学模型如下:
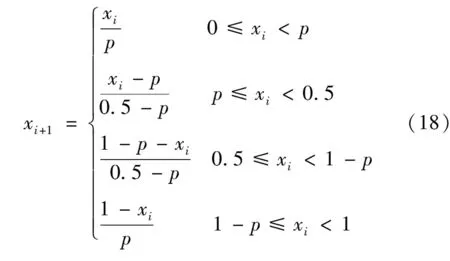
式中:p=0.25。
将LSSVM的正则化参数的可行域设为[0.1,100],核函数宽度设为[0.01,10],他们的初始位置如图1和图2所示。可以明显看出通过Piecewise映射处理的初始种群位置更均匀地分布在可行域中。

图1 CWOA初始种群位置

图2 WOA初始种群位置
3.5 非线性收敛因子的混沌鲸鱼算法(NCWOA)
WOA中系数向量A=2a×r-a,收敛因子a=2-2t/Tmax,假设Tmax=100。A的作用是调整WOA的全局寻优和局部开发能力,A随a的变化而变化,a越大,算法跳出局部最优的能力越强;a越小,局部开发能力越强[17]。由于a在迭代过程中线性递减,因此导致算法在收敛过程中A的变化不足,无法适应实际情况。对此,本文使用式(19)代替a=2-2t/Tmax。收敛因子曲线如图3所示。
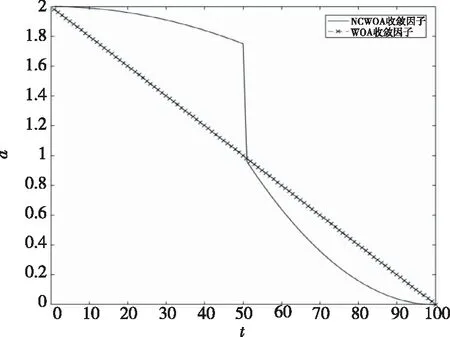
图3 收敛因子曲线

a在寻优初期较大,具有快速的遍历解空间和跳出前期局部最优解的优点;a在寻优后期较小,可以更细致地探索最优解附近空间,避免因a过大错过最优解。使用非线性的收敛因子代替线性的收敛因子,用于改善算法的寻优能力。
图4与图5是将预测值与实际值之间的平均绝对百分误差作为适应度,利用WOA和非线性收敛因子的混沌鲸鱼算法(nonlinear convergence factor of Chaotic whale optimization algorithm,NCWOA)对LSSVM的核函数宽度和正则化参数在可行域内寻优得到的适应度曲线。NCWOA在寻优初期由于初始种群更加均匀分布在可行域内,使得算法在第一代的适应度为1.674%与1.675%之间,而WOA则是在4代才得到,说明混沌策略改进的有效性。NCWOA在寻优初期适应度基本不变,是因为寻优初期收敛因子较大,牺牲适应度变小,达到完整遍历解空间的目的。在寻优中期,根据向量A的随机变化模拟鲸群个体位置随机搜索猎物,所以NCWOA在第50代与WOA在第23代的适应度会发生突变。在WOA的23代WOA到80代之前一直陷入局部最优适应度1.674%,第80代时收敛到1.672%,NCWOA在25代时收敛适应度为1.668%,说明WOA收敛因子无法适应收敛过程中的变化,以及寻优后期更小的收敛因子可以更精确地探查到最优解附近的空间,得到最优适应度,因此非线性收敛因子能有效提高算法收敛性能。
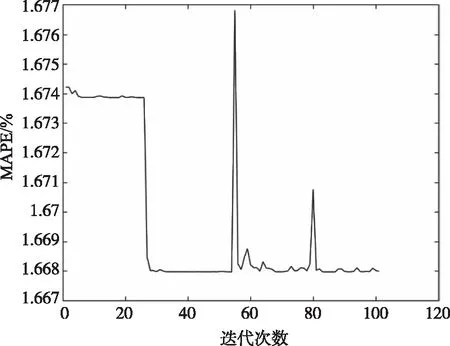
图4 NCWOA适应度曲线

图5 WOA适应度曲线
NCWOA的算法流程如图6所示。

图6 NCWOA算法流程
4 VMD-NCWOA-LSSVM预测模型
由于电力系统负荷呈现出不规则性、不平稳性和随机波动性等特点,为了有效提高负荷预测精度,进行历史数据的预处理很有必要[18]。
4.1 短期负荷的影响因素
一般而言,短期电力负荷预测的影响因素有以下方面:气候因素包括温度、空气湿度、气压、日照强度、空气质量、风向风力以及日出日落时间等;日期类型包括重大活动、节假日、工作日等;典型负荷为不同的地区,支柱产业不同,典型负荷不同,负荷的稳定性不同;随机意外事故包括极端天气的大范围影响、洪水泥石流等自然灾害侵袭等。
4.2 训练特征
4.2.1 负荷数据
采样频率为1 h的实际电力负荷数据,记作L。
4.2.2 天气因素
(20)
为了统一量纲,将Ci中的每种气象特征分别归一化到[0,1]。
4.2.3 日期类型
因为是短期负荷预测,时间跨度有限,故本文将不考虑季节更替,仅仅采用工作日和非工作日两种日期类型。工作日令D=1,非工作日D=0。
因此,本文训练特征集为
(21)
4.3 模型构建
根据上述分析,本文构建短期负荷模型流程如图7所示。
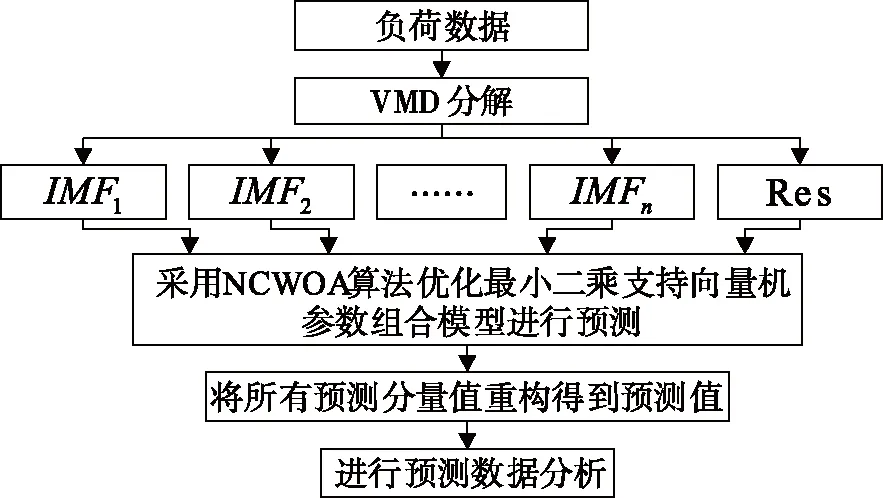
图7 预测模型流程
(22)
式中:IMFi—模态函数分量;
Res—余量,满足式(22)。
IMFi是中心频率不同的模态函数,故基于VMD-NVWOA-LSSVM组合算法的短期电力负荷预测步骤如下:
1)仿真实验表明,随着分解模态函数的增加,最终预测值的误差减少量趋于稳定,故对原始数据采用VMD进行分解时,将其分解为具有4个不同中心频率的模态函数和1个余量分量Res的训练集。
2)采用Piecewise映射初始化种群同时设定鲸鱼算法各参数范围。
3)通过式(23)计算鲸鱼粒子初始适应度,确定最优鲸鱼粒子位置。
(23)
4)根据标准WOA算法更新鲸鱼粒子位置,同时采用非线性收敛因子更新收敛粒子。
5)再次根据式(23)计算鲸鱼粒子适应度,确定当前最优鲸鱼粒子位置。
6)若迭代次数小于最大迭代次数返回步骤3)继续优化,否则跳出优化,输出最优参数。
7)将参数赋予LSSVM,得出预测结果。
8)误差分析,本文利用平均绝对百分误差(mean absolute percentage error,MAPE)和最大相对误差(maximum relative error,Emax)来评判预测效果,定义如下:
(24)
(25)
式中:P(D,t)—预测日某时刻真实值;
P*(D,t)—预测日某时刻预测值;
N—采样数。
5 算例分析
本文选取浙江某地区2013年3月1日到3月30日的30×30=900个数据作为训练样本,其中包含30×24=720个电力负荷数据,如图8所示,可以看出该负荷具有明显的非线性、不规律性和随机性特征。测试集为31日的气象特征数据和30日24 h负荷数据,测试集输出为31日24 h的负荷。为验证VMD-NCWOA-LSSVM模型的有效性,本文采用VMD-LSSVM、EMD-LSSVM、VMD-PSO-LSSVM和VMD-WOA-LSSVM 4种预测模型与之对比,算法采用MATLAB2016a编程实现。

图8 3月负荷数据
在算例中,VMD的模态分量个数选取通过先将原始数据分解层数设为[2,10]层,再以预测结果和真实值的平均绝对百分误差作为依据选取,如图9所示:当分解层数不足,不能将原始数据特征很好地提取;当分解层数过多,过多的随机高频分量导致预测效果不升反降,所以针对本文样本,选取分解层数为6层。
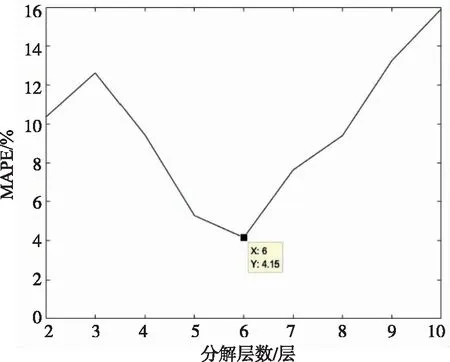
图9 分解层数曲线

表1 各模型平均绝对误差和最大相对误差

图10 负荷数据VMD分解结果
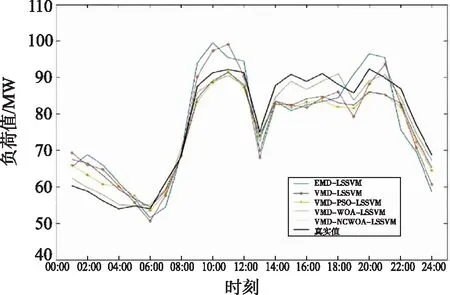
图11 原始负荷值与模型预测值
从表1可以看出,本文提出的VMD-NCWOA-LSSVM模型与其他4种预测模型相比,该模型的Emax和MAPE均为最小,分别为4.95%和4.15%,该模型的MAPE和Emax比VMD-WOA-LSSVM模型分别提高0.77%和0.67%,说明经改良后的鲸鱼算法使预测结果波动性更小,满足负荷预测所需要的稳定性,同时可以有效提高负荷预测的准确性。该模型比VMD-PSO-LSSVM模型的MAPE和Emax分别提高1.28%和2.68%,说明NCWOA比PSO的参数寻优能力更强。与采用经验选取参数的VMD-LSSVM模型相比,VMD-NCWOA-LSSVM模型的MAPE和Emax分别提高1.91%和4.31%,说明通过NCWOA选取LSSVM的参数能有效避免盲目选取参数对负荷预测精度的消极影响。VMD-LSSVM模型比EMD-LSSVM模型的MAPE和Emax分别提高0.64%和1.16%,说明相较于EMD而言,VMD拥有更好的数据分解能力,分解后的电力负荷数据具有更好的规律性,有效提高了本算例负荷预测的精度。
从图11能看出VMD-NCWOA-LSSVM模型的预测结果与真实负荷曲线最为贴合,在实际负荷数据波动较频繁的14:00—22:00,VMD-NCWOA-LSSVM模型的预测值最接近真实值,说明VMD-NCWOA-LSSVM对负荷波动预测最准确。
6 结 论
通过使用VMD预处理负荷数据降低数据不规律性对预测结果的干扰,采用非线性收敛因子代替标准WOA的线性收敛因子,提高了标准WOA的全局寻优和局部探索能力,采用Piecewise模糊映射策略改进鲸鱼算法随机初始化机制,提升标准WOA的收敛速率及减少初值对最优值搜寻的影响,利用LSSVM优良的非线性回归问题的处理能力,综合考虑VMD,NCWOA,LSSVM各自的优点,提出VMD-NCWOA-LSSVM模型。算例结果表明,与其他4种预测模型相比,VMD-NCWOA-LSSVM在短期负荷预测中最大相对误差更小,精度更高,具有很好的实际应用价值。
猜你喜欢
幼儿100(2022年41期)2022-11-24 03:20:20
计算机仿真(2022年8期)2022-09-28 09:53:02
数学大王·趣味逻辑(2020年9期)2020-09-06 14:17:17
小天使·二年级语数英综合(2019年4期)2019-10-06 02:44:36
动漫星空(2018年4期)2018-10-26 02:11:54
中国塑料(2016年11期)2016-04-16 05:26:02
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
教育与职业(2014年16期)2014-01-19 01:24:36
