
基于情感倾向性分析的重点受众人群识别
2021-09-24 05:32潘伟民张海军
现代电子技术 2021年17期
周 杰,潘伟民,张海军
(新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830001)
0 引 言
微博随着互联网的快速发展成为对舆情相关研究的重要对象。微博话题下的一些用户在热点话题下成为了中心点,被称为该话题下的重点受众群体,由于网红效应成为明星,在舆情下产生巨大作用。重点受众人群形成的传播对社会的舆论导向存在重大影响,因此对重点受众人群的准确定位,掌握这些人群会对舆论进行积极方向的引导,及时准确分析舆情发展动态具有重要的作用。
文献[1]通过对LeaderRank算法的改进,考虑到其活跃性并且减少了其中恶意注册用户的影响,提取了排名前20的重点受众人群,结果表明影响用户的覆盖率更广泛。文献[2]针对微博平台加入了LDA主题模型并运用了随机森林的算法优点,对面向主题的重点受众群体建立领袖预测模型,为舆情控制增加了精确化算法。文献[3⁃5]把用户的情感倾向性加入到重点受众人群的识别中去。其中,文献[3]考虑其综合倾向,对只考虑节点权重的传统方法进行改进,提高算法效率。
根据现有研究现状,有以下两个方面的问题需要深入分析:
1)受众群体的基础属性特征简单,应加入传播网络信息的过程中个人情感因素来提高重点受众人群的识别准确率;
2)在对影响力最大化计算时加入受众群体的交互行为与潜在影响力多个因素,可以更大程度提高影响力算法准确度。
针对上述问题,为了提高微博受众用户的影响力计算,在用户基本属性上考虑到对用户交互行为以及博文内容的情感[6⁃7],对舆情网络传播影响力进行计算。通过百度开源的深度学习平台PaddlePaddle[8],设计博文情感分析神经网络LSTM,结合改进的IKAG(Identification of Key Audience Groups Rank)算法,建立了一种基于情感倾向性的微博舆论事件重点受众群体预测模型。
1 重点受众人群识别模型
微博话题中受众群体繁多,其中关键的受众用户影响力原因复杂。在考虑受众用户的特征时,如果对其情感的倾向以及其互动行为进行忽略,会影响最后重点受众用户的排序结果。
本文算法的基本流程为:
1)爬取微博话题下受众用户的基本特征,如粉丝量、历史微博数、话题微博中的回复数和转发数等,计算受众用户的初始影响力值。
2)算出受众用户的情感倾向构出受众情感值矩阵。
3)通过受众群体之间的互动行为得出受众用户的最大影响力值。
4)与受众用户潜在影响力值相结合得出最终的重点受众人群。重点受众人群算法计算图如图1所示。
1.1 微博博文的情感倾向性分析
本文根据RNN的网络结构进行LSTM模型改进。在情绪倾向性的识别中,联系句子的整个语境进行判断,能够建立前后时刻输入的联系,综合前后信息识别受众群体的情绪倾向,如图2所示。图2中,H为信息的词向量,O为输出向量值,S为隐含层的向量值,U为权值的矩阵,W为隐含层前后输入值的矩阵,V为隐含层到输出层的权重矩阵。其中St由Xt与前一段的隐含层中的值决定,用来构建特征向量之间的关系。从图2中可以看出,各个时刻权值矩阵都会共享,因而可以减少训练的次数,并可以把不同的特征向量放到隐含网络层中进行相同的训练操作。
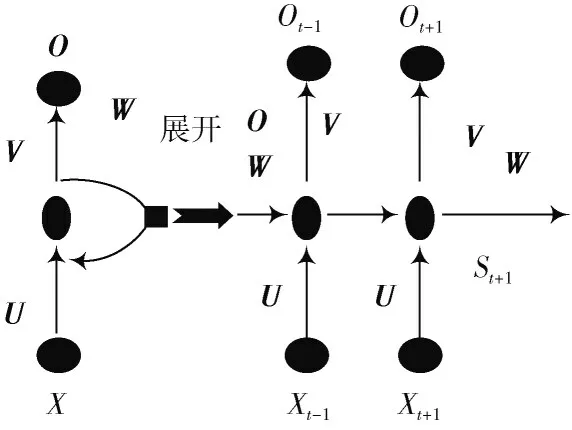
图2 RNN模型展开图
本文利用博文语句前后联系和微博情感词语极性得出句子情感值并对其构出矩阵。利用受众群体情感基本属性,以排查特征较弱的短句,如式(1),b为句子特征,a为b的情感客、主观c1,c2的互动量,如果结果高于f提出a。当句子基本特征提取结束,运用LSTM对其进行博文倾向分类。

通过NII(Node Information Interaction)的短句情感倾向算法,在语料中用基础词与现有词的重复比率计算感情的倾向性。两两词性值计算如下:

式中:I(V),I(V′)为词V,V′出现的重复次数;I(V&V′)为V,V′同时出现的概率。设正向基础词为word1={word11,…,word1n},负向基础词为word2={word21,…,word2n},新出现的newword的情感值计算为:
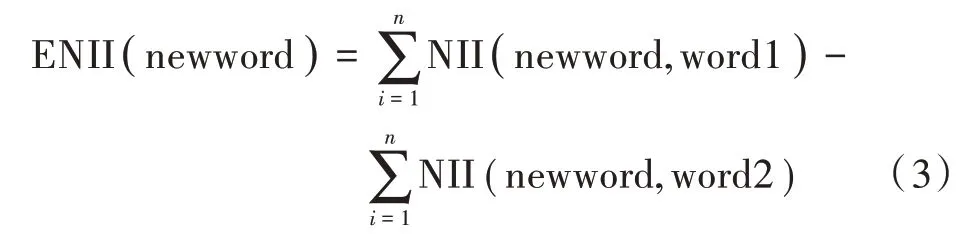
通过词句情感倾向算法计算基础词与新型词的相似度,得出新型词句的情感性。设V,V′有k,l个基本结论,其中各自的总集合为{D11,D12,…,D1n}与{D21,D22,…,D2n},则newword的公式为:
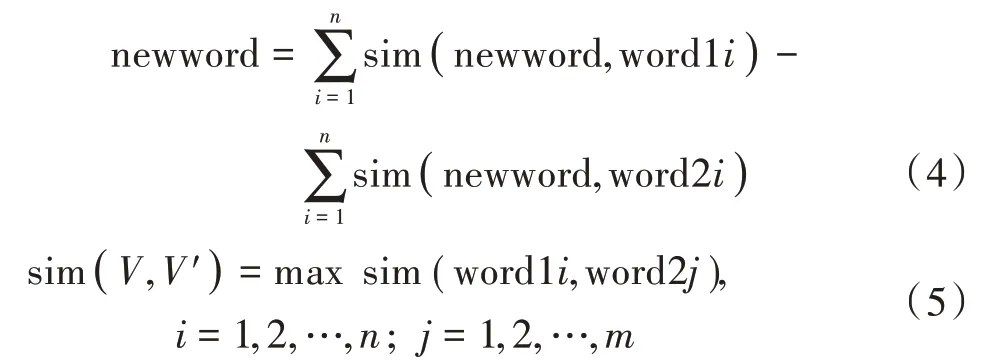
式中sim(V,V′)表示V,V′之间的相近程度。
博文情感公式为式(6)。其中,RP(vi)为词句vi的感情值,b,n为数量,对其进行分化,在[-2,2]当中。
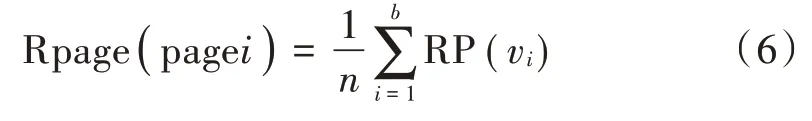
博文互动的受众群体量较大,受众群体p,l的计算与互动来往的次数权重相关,其中p对l的主动情感倾向为:
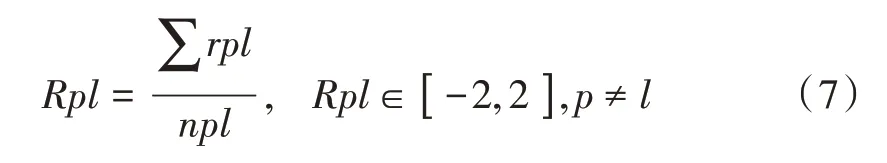
式中:rpl为p,l之间的情感互动权重之和;npl为博文互动中p,l之间的交互数。
1.2 潜在影响力与博文影响力计算
微博在进行信息传播的过程中,意见领袖影响力在整个传播过程中起到很大的影响。影响力的计算构成指标需要考虑到多个因素,不能忽视受众用户的潜在影响力,它是受众用户的静态影响力。受众用户的潜在影响力包括用户的粉丝、关注以及历史博文数目,用户影响力是潜在影响力与博文影响力的综合。
1.2.1 初始影响力计算
在本文IKAGR算法计算中,需要输入初始受众用户的影响力值进行迭代,在计算之前要对实时微博的因素进行分析,由于采集的特征数据跨度较大,如一些明星大V用户的粉丝很多,然而作为受众用户在某一热点话题下所产生的影响力并不一定比普通用户高。为了削减因受众用户个别指标过于突出而使综合结果偏高,因此需要使用变异系数法对各个基本属性的权重比进行计算,各项指标的变异系数为:

式中:M t是第t项指标的变异系数;σt是第t项指标的标准差;yt是第t项指标的平均值。各项特征属性指标的权重为式(9),通过计算综合评分进行排序如式(10),在得到总分之后归一化,方法采用max⁃min归一化如式(11)所示。

在进行实时博文初始影响力计算时,其特征属性考虑到转发、评论以及点赞数。定义以式(12)计算用户u的自身影响力值。
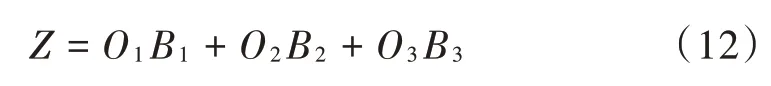
式中:Z值为用户u的初始影响力值;B1,B2,B3分别为点赞数、评论数、转发数;O1,O2,O3分别为上述的权重系数。
本文三个特征通过上述算法进行权重赋值得出结果如表1所示。

表1 受众用户交互属性权重
1.2.2 潜在影响力计算
本文采用变异系数法计算权重,确定受众用户潜在影响力和实时博文影响力的权重赋值。先计算每个指标的所有平均值、标准差;然后计算每个指标的变异系数;接着计算每个指标的权重,以及每个部落的总分,对总分进行max⁃min归一化,将总分值映射成0~100之间的分数作为部落的热度值;最后对所有热度值从大到小排序。根据式(8)~式(11)和式(13),得出α权重因子,用来调节用户的潜在影响力Pb和博文影响力Pc各自所占的权重比值,其计算结果见表2。
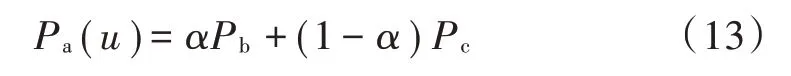
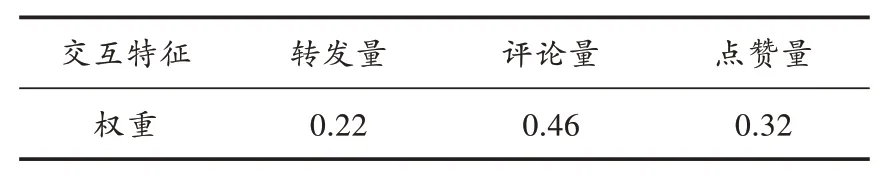
表2 受众用户影响力Pa的权重指标
1.3 IKAGR算法
本文在PageRank算法的基础上改进了重点受众群体的发现算法并加入了受众群体之间的情感特征以及初始影响力和潜在影响力等,简称IKAGR算法,基本思想为:
1)如果受众人博文内容的回复为本人,那就不建立连接点;
2)如果受众人博文内容没有人回复,或仅自己则取消连接点;
3)如果博文内容只为连接或表情符号,则取消连接点;
4)如果受众人a评论受众人b,则建立指向关系,其中的权值为b对a的情感值Rab和本博文的互动量,具体如式(15),式(16)所示。受众用户的迭代结果为IR(u)。算法通过用户之间的交互特点设置阻尼值d为0.7。HRu表示与用户被转发、点赞、评论的用户集合。G(u,v)表示用户u在用户v的交互集合中占的比重。HEv表示与用户v交互的人的集合。把用户u的基础影响力设为ZI(u),传播概率设为FITE(u),Ovu和Ovk为评论的受众v对u和k的情感数值的计算,可由式(7)得出。相比传统算法,本文考虑到了初始影响力值ZI(u)的计算,以及用户之间的交互行为HEv和受众群体之间的情感交互Ovu和Ovk。IKAGR算法考虑较为综合,得出的结果更为客观。
本文将主要与UIRank算法做对比,检验本文算法的效果。UIRank[9]基于随机游走理论及改进PageRank算法,以新浪微博为实验平台,考虑到了用户转发影响力和信息传播能力,是一种基于用户跟随关系图模型的数学算法。其中,Followers(u)是u跟随的用户集合;a是衰减因子。UIRank排名方程定义为:

针对本文IKAGR算法,假设微博网络中发表博文的用户为N,其中M为指向N的用户,ZI作为当前用户的初始影响力。设置判断条件a值为0.01,表示每个个体前后的影响力值差,即当前IR(u)值和上一次迭代结果IR(u)old值的差值阈。代码满足迭代结束的条件后得出最终IR(u)值,返回maxlist集合为IR(u)值的逆序排序。具体如算法1。
算法1:IKAGR算法


该算法在实际操作中需要对输入值进行预处理,其阻尼因子、迭代次数等条件并不唯一,可以进行调试,通过对比结果的F1值确定设置的参数;构造有向图模型,可以根据实际需求设定M值为从零开始的n+序列。综上所述,本文改进的IKAGR算法适用于微博受众用户的影响力计算,可收敛。
2 实验结果与分析
2.1 数据获取与处理
本文先选取UIRank[9]算法的原始数据集与之相比较,其次本文把疫情期间的新浪微博作为数据源,在新的数据集上再进行比较,更能得出本文算法的实际效果。对数据集依据与“新冠肺炎”相关的10个主题关键词进行数据采集,抓取了2020年2月10日—20日期间共计33 641条微博数据,为了减少不必要的计算,把爬取到的数据中粉丝、历史发博、关注量低于15的删掉,如表3所示。

表3 数据集概要
经过上述处理,提取33 641条待评估的微博样本。首先对这些微博的博文内容用jieba分词和哈工大停用词表进行数据预处理,并写入csv文件对应ID的clearntext列。然后对该列使用本文情感倾向性分类模型,得到含有12 451条持有肯定态度的集合K1,11 812条持有否定态度的集合K2,得到9 378条中立态度的集合K3。
2.2 结果分析
本文选择了目前大众认可的重点受众人群影响力算法与IKAGR算法进行实验对比。如UIRank[9]算法,该算法通过受众用户之间的交互关系以及情感倾向的取舍对重点受众人群进行计算。其次选取的是PageRank算法,该算法是基于用户基本属性的迭代,计算出用户排名,本文IKAGR算法是基于该算法的改进,通过对比更能体现出本文算法的优点。最后是基于微博用户粉丝数对用户影响力的排名算法。
仅通过粉丝数、转发数判定重点受众群体是不准确的,所以参照文献[10]定义的算法F1值来评估各个算法的效果。

式中:A1代表各个算法总的博主排名集合;AIKAGR,AUIRank,APageRank,AFans分别表示本文、UIRank、PageRank以及粉丝排名下的重点受众博主的集合。
算法评估的准确率、召回率和F1值计算公式如式(18)~式(20)所示。
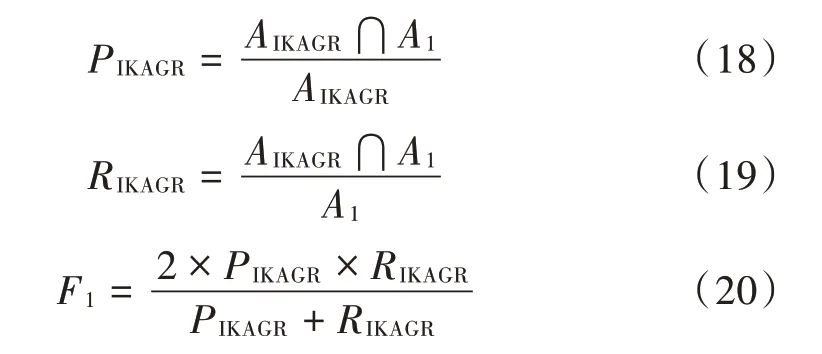
由图3可以看出,在准确度的对比中虽然个别算法有波动,但是总体而言都是随着排名人数的增加其准确率在提高,在排名100时UIRank算法高于本文IKAGR算法,但在实际考量中影响不大。

图3 不同算法的准确率对比
从图4召回率的对比结果可以看出,在用户排名为100时,IKAGR算法与UIRank算法相持平,PageRank算法与Fans算法相持平。总体而言,IKAGR算法的召回率效果还是不错的。

图4 不同算法的召回率对比
在图5的F1值对比上,本文用户IKAGR算法总体取得了不错的效果。由于用户在某个领域和话题中的交互性较低,活跃度不高,所以Fans算法实际的影响力并不高。

图5 不同算法的F1值对比
本文针对微博热点话题“校园保安打狗”这一实例数据进行处理,得出了表4,表5的处理结果,列出了其中的用户粉丝数排名,以及PageRank算法、UIRank算法和本文的IKAGR算法中用户影响力的前10名用户。

表4 IKAGR算法和UIRank算法的受众用户影响力
从表4,表5可以看出,这些算法计算出来的重点受众群体偏向于娱乐、大V、还有像张继科这样的体育明星。说明了微博中的普通受众用户对这些群体的关注度比较高,这些重点受众群体在微博的信息扩散和舆论引导、广告投放等方面都有着重要的作用。从粉丝排名来看,得出的结果和前两种的用户重合度不是很大,虽然粉丝数目较多,但是这些用户的活跃度不是很大,与自己的粉丝交互较少,因此仅仅靠粉丝数目来计算影响力大小是不准确的。本文前两种的重合度较大,因为UIRank算法重视用户之间的交互程度,因此挖掘出来的都是近期博文更新颇为频繁的用户,而PageRank仅仅考虑到用户的基本属性值,所以与粉丝排名重合度较高,而本文提出的IKAGR算法考虑到了情感的因素,一些正能量的东西往往点赞数目多,其影响效果其实并不突出,而一些消极、负能量的东西,其转发数和点赞数相对较少,因为其中内容的争议性,评论内容和被@的次数较多,因此本文模型考虑到的问题更为全面。

表5 PageRank算法和Fans排名的受众用户影响力
本文引入覆盖率作为评估指标,用来估量重点受众群体算法的影响力广度,直接或间接影响其他用户的覆盖范围比,如式(21)所示。
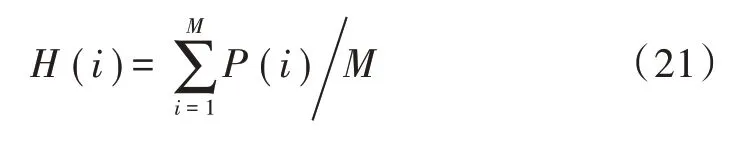
式中:H(i)为topi个用户的覆盖率;M为数据集中所有受众用户;P(i)为重点受众人群影响的节点。
图6中,本文的IKAGR算法在23 446个受众用户构成的微博交互网络中达成最高的67%覆盖率。
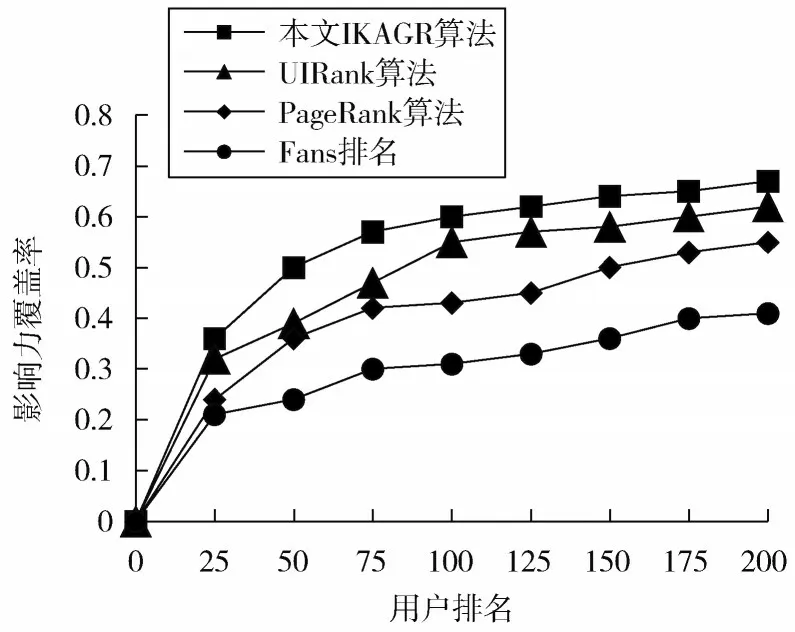
图6 不同算法的覆盖率对比
由结果可以看出,微博中重点受众人群关乎到博文内容的情感倾向,比如虽然有一些消极的博文其转发和点赞远远不如一些正常的微博内容,但其评论中的争论较多,其影响效果更大。因此不能单一的只考虑用户的粉丝、博文常规属性特征,也要考虑到博文的内容性质以及博文的潜在影响力。
3 结 语
基于长短时记忆(LSTM)神经网络,本文将情感倾向性因素加入到了微博重点受众群体的识别模型中,考虑到了微博用户的潜在影响力,并提出了改进后的IKAGR算法。该算法考虑到了更广的微博特征属性以及属性之间的权重赋值,其F1值和覆盖率等都较为良好。然而微博中往往存在大量的“水军”,如果能排除“水军”的干扰因素,并考虑到时间的因素,加入微博话题的周期性,摸清发博转博的时间变化趋势,得出的最终结果会更加客观。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
NBA特刊(2018年14期)2018-08-13
小学生作文·小学低年级适用(2018年12期)2018-04-11
电信科学(2017年6期)2017-07-01
人大建设(2017年11期)2017-04-20
校园英语·下旬(2016年2期)2016-03-18
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
