
基于GPU的OFDM波形外辐射源雷达信号处理研究
2021-09-24 05:32赵志欣张凯凯
现代电子技术 2021年17期
赵志欣,翁 涛,张凯凯,李 存
(南昌大学 信息工程学院,江西 南昌 330031)
0 引 言
外辐射源雷达是一种特殊的双(多)基地雷达系统,其利用第三方非合作民用辐射源对目标进行跟踪与定位。与传统双基地雷达相比,具有成本低、覆盖范围广、隐蔽性高、抗干扰性强等优点,并因此吸引了国内外相关学者对此进行研究[1⁃6]。一般来说,外辐射源雷达可以利用模拟、数字电视和无线电信号,以及移动电话基站、GPS卫星等信号作为照射源。而这些通信照射源大都采用正交频分复用(Orthogonal Frequency Division Multiplexing,OFDM)技术,再加上比特交织、编码纠错等手段,能有效减轻多径传输产生的问题,为外辐射源雷达提供了可靠的第三方照射源。
外辐射源雷达信号处理流程复杂、运算量大,对设备计算能力的要求也高[7],而随着高性能技术的高速发展,图形处理器(GPU)已经被广泛应用于深度学习、物理化学实验仿真、生物特征模拟、信号处理等领域的大规模高速并行计算[8]。NVIDIA公司是提供图形卡的生产商之一,它提供带有多核的GPU并推出了一种通用并行计算架构CUDA,开发人员可以使用C语言为CUDA架构编写程序,所编写的程序可以在支持CUDA的GPU上高性能运行,从而方便用户进行GPU编程。因此,利用GPU并行加速处理外辐射源雷达信号,为外辐射源雷达实时处理提供了可能。
目前,已有部分文献提出了在不同雷达体系下的信号处理GPU并行方案。文献[9]研究了GPU架构下阵列雷达信号处理的实现方案,但波束形成实现时未考虑线程的连续访存问题,还存在优化的空间。文献[10]研究了外辐射源雷达杂波抑制算法——分块扩展抑制算法(Extensive Cancellation Algorithm Bathes,ECA⁃B)[11]在GPU下的并行实现;文献[12]研究了基于CPU+GPU异构下的电视外辐射源雷达信号处理整体方案,并取得了较好的加速效果,但针对OFDM波形的外辐射源雷达信号处理,若能充分利用OFDM波形特征并行加速,则能进一步减少信号处理所需的时间。此外,对于有序长恒虚警检测算法(Order Statisic Constant False Alarm Rate,OSCFAR)的GPU并行实现上还具有较大的改进空间。基于此,本文将结合OFDM波形特性,通过选取更合适并行的信号处理算法,建立基于OFDM波形特征的外辐射源雷达并行化处理方案,并在充分利用共享内存等GPU高速缓存资源和减少访存的基础上设计出高效的核函数,以降低整个信号处理在GPU上运行的时间。
本文首先介绍OFDM波形外辐射源雷达信号处理算法的基本原理以及算法的选取思路;然后根据算法的结构给出CUDA架构下流程中每个算法的优化思路与具体实现方案;最后通过对比Matlab上程序的运行时间与数据,进行结果验证与性能对比。
1 OFDM波形外辐射源雷达信号处理
外辐射源雷达信号处理的主要目的是从接收到的信号中提取目标信息。而由于采用了地面广播电视信号作为照射源,其天线波瓣主要射向地面,导致空中的期望目标回波信号远小于直达波信号,以致目标被掩盖,故首先要抑制直达波信号和强多径回波,再对信号进行后续处理。针对OFDM波形外辐射源雷达,本文建立了从接收信号到恒虚警检测的并行化处理方案,具体流程如下:
1)假设多通道阵列接收信号Ssurv为M×N的复数矩阵,其中M为阵元数,N为时域采样点数。对阵列接收信号进行波束形成后得到M×1的复数参考信号Sref;
2)结合信号特性选用适合并行实现的分载波的扩展抑制算法(Extensive Cancellation Algorithm Carrier,ECA⁃C)[13]作为杂波抑制算法,将监测信号与参考信号按OFDM符号时间长度划分为K个载波,每个载波符号长度为L,对每个载波并行抑制直达波与多径杂波;
3)按同样的分段方式进行距离多普勒匹配滤波;
4)通过二维的OSCFAR恒虚警检测获取目标,流程图如图1所示。

图1 OFDM波形外辐射源雷达信号处理流程
1.1 参考信号的获取
在对信号处理前首先需要获得参考信号,对于OFDM波形外辐射源雷达来说,常见的有波束形成和信号重构两种方法,而GPU更适合大量的轻量级、控制简单的任务,因此本文选用简单且基本能满足OFDM波形无源雷达要求的波束形成方法来获取参考信号。
波束形成又称空域滤波器,通过设计滤波器权值,让某些期望方向的信号通过滤波器,同时抑制其他方向的信号。假设直达波方位为θtx,其对应的阵列导向矢量为a(θtx)。合适的阵列权矢量就是直达波信号的导向矢量,即:

为获取参考信号向量,将阵列权矢量W的共轭转置(其中(·)Η表示矩阵的共轭转置)与阵列监测信号Ssurv相乘,使阵列输出在直达波方向上的信号增益最大,得到参考信号向量:

1.2 直达波和多径杂波抑制
直达波和多径杂波抑制有多种实现方法,常见的有最小均方误差(LMS)类算法、递归最小二乘(RLS)算法以及基于时域正交子空间投影理论的扩展抑制方法(Extensive Cancellation Algorithm,ECA)[11]等算法,而从并行角度看,ECA类算法相比LMS、RLS等常规自适应时域算法,无需考虑收敛和迭代等问题,且数据之间的耦合性低,更适合于并行实现。此外,文献[13]通过利用OFDM波形的调制特性,在ECA算法的基础上提出了一种基于分载波ECA方法,即ECA⁃C,相比于ECA算法,其有以下优点:总体计算量大大降低;杂波子空间的维度仅为L×1,因此子空间投影计算时无需进行矩阵求逆运算,而矩阵求逆由于行变换、消元和列变换等操作存在的数据依赖性[10]会破坏子空间投影整体的并行性。故本文选取ECA⁃C算法作为直达波抑制的算法。
ECA⁃C算法的主要思想是对监测信号与参考信号有效数据部分进行离散傅里叶变换(DFT),将数据变换至载频域,通过矩阵运算将解调后的监测信号投影到参考信号的正交子空间,然后通过离散傅里叶逆变换(IDFT)恢复信号,从而得到滤除直达波与多径的信号。其中,子空间投影矩阵运算的公式为:
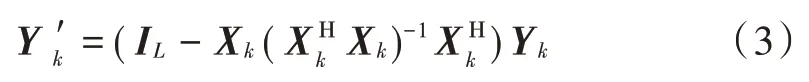
式中:Xk和Yk分别代表参考信号与监测信号的载波k(k=1,2,…,K)对应的频域信号向量;IL代表维度为L的单位矩阵;(·)′,(·)-1符号分别代表矩阵转置和矩阵求逆。
1.3 匹配滤波
雷达的匹配滤波就是将监测信号通过距离维与多普勒维的匹配滤波器后,使目标回波在其相应的延时和多普勒上形成最强增益,表现为单个尖峰,从而突显目标。
匹配滤波有多种实现方法,常用的有互模糊函数法、“距离相关+多普勒变换”法[14⁃16]。本文采用计算量更小、对内存要求低、便于并行的“距离相关+多普勒变换”法。此外,在并行实现的过程中,根据OFDM波形特性,通过设计合理的分段方式,还能实现数据复用,以减少系统整体的运行时间。具体操作为:将参考信号和经杂波抑制后监测回波的OFDM信号的N个采样点按符号划分成K个子段,每个子段长度为L,“距离相关+多普勒变换”法的二维匹配滤波过程可表示为:

由式(4)可看出,“距离相关+多普勒变换”的匹配滤波实现可视为将相干积累时间内的参考信号和目标回波信号分成若干段,每段先进行距离相关,从而将不同延迟信号分开,再利用特定延迟在段间的DFT变换获得多普勒信息,从而获取目标的时延τ与速度v。
1.4 恒虚警检测
恒虚警检测模块的功能是判断雷达接收信号中是否包含目标回波信号并确定目标距离,它在保持虚警概率恒定的同时,根据被检测点的背景噪声和杂波强度自适应调整检测门限,使目标检测概率最大。根据背景噪声和杂波功率的估计方法,常用的恒虚警算法主要包括单元平均(CACFAR)、选大(GOCFAR)、选小(SOCFAR)以及有序统计(OSCFAR)。在雷达复杂多变的工作环境下,OSCFAR方法对边缘检测和遮蔽效应呈现很好的适应性,因此本文选用适应力较强的二维OSCFAR方法进行恒虚警检测。
OSCFAR方法将参考单元按从小到大排序,并选取第m大的值经过门限因子校正后作为阈值与待检测的单元比较判决,通过遍历整个距离维与多普勒维,从而完成距离多普勒二维的恒虚警检测,其中参考单元的选取方式如图2所示。

图2 二维恒虚警检测窗
2 信号处理算法CUDA实现与优化
目前GPU编程模型最常用的是CUDA C,CUDA将并行任务分解到不同线程(thread)执行,若干个线程组成一块(block),每块block共享一份内存。此外GPU上还拥有丰富的数学函数库,例如线性代数库CUBLAS、傅里叶变换库CUFFT、CUSOLVER矩阵分解库等。基于此,本节将介绍OFDM外辐射源雷达信号处理算法在CUDA模型下的并行实现方案,并在考虑连续合并的访存、使用共享内存、去除冗余计算等优化思路下对算法的实现过程进行改进。
2.1 波束形成CUDA实现
监测信号Ssurv为M×N的复数矩阵,假设方向导向矢量a(θtx)为M×1的复数向量,波束形成所需的计算可看成矩阵与向量的乘法计算,那么便可直接利用CUBLAS库中的函数cublasCgemv实现这部分运算。但通常来说,CUBLAS函数库更适合用在矩阵大小都比较大的情况下,但此情境下N要远远大于M,且M一般在8~32之间,若直接使用库函数则无法充分发挥GPU的性能,因此考虑通过自己编写核函数实现。文献[9]中给出了波束形成的一种实现方法,但给出的方案没考虑到访存连续的因素,而GPU访存不连续会极大地影响并行效果。基于此,本文提出两种波束形成的并行实现方式,为方便对比,两种方法的核函数分别命名为DBF_1和DBF_2。
DBF_1方法的实现原理如图3所示,根据采样点数开辟N个线程,每个线程内通过M次循环累加计算参考信号的一个值。但需注意的是,由于监测信号通常以M所在的维度为主方向存储,实现时会出现同一块block下不同线程访存不连续的问题,且考虑到N一般较小,因此采用将监测信号进行转置的方法避免访存问题,其中,矩阵转置的实现还需考虑利用共享内存来避免不连续的数据存取问题。
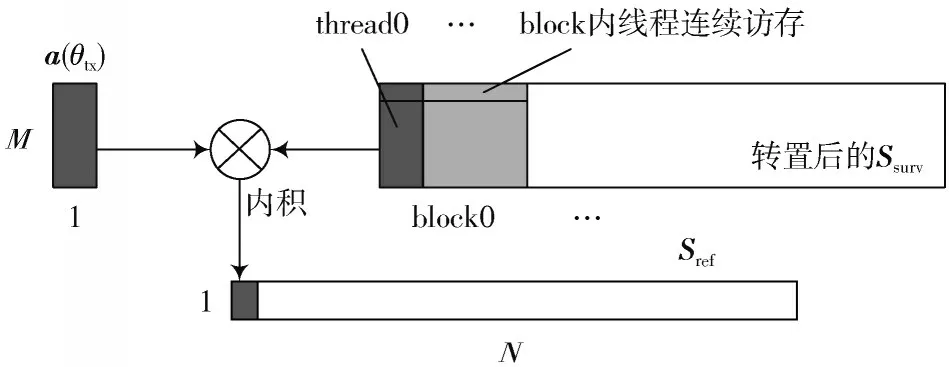
图3 波束形成内核实现过程(DBF_1)
DBF_2核函数实现思路如图4所示,通过考虑线程束的大小来固定block中的线程数,假设每块block中有t个线程,则每块block利用共享内存规约计算t M个参考信号元素,总共有N t块block。此外,GPU线程执行是以线程束(warp)为单位进行调度的,每个warp(32个线程)执行同一条指令,因此在通道数小于32的情况下还能进一步减少同步带来的开销。同时,此方法避免了第一种方法块中同一块block不同线程访存不连续的问题,且无需进行矩阵转置。
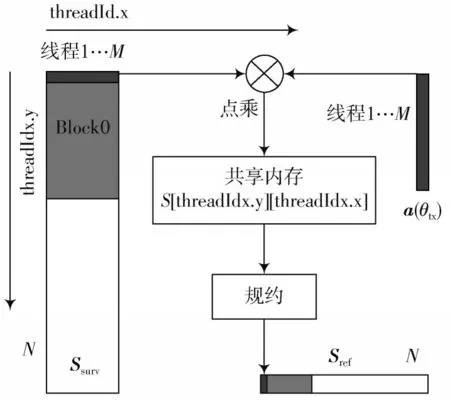
图4 波束形成内核实现过程(DBF_2)
2.2 ECA⁃C的CUDA实现
ECA⁃C算法流程大致可以分为两部分:一部分是对信号进行DFT与IDFT,此部分可以利用CUFFT库中的函数实现,通过使用cufftPlan1d函数指定进行快速傅里叶变换(FFT)和快速傅里叶逆变换(IFFT)的长度L和运算次数K;ECA⁃C算法另一部分为子空间投影的矩阵运算,而此部分的实现方式则是此算法能否高效移植的关键。
一般来说,对于ECA⁃C算法,每个载波下Yk与杂波子空间Xk为L×1的复向量,而式(3)中计算结果为一实数,其值为Xk中每一个复数元素模的累加。此外,对于与Yk的内积,其结果为一复数,值为与Yk中每一元素对应相乘的累加。因此式(3)可改写为:

核函数具体实现方法为:首先将整个任务分解为N个线程,并按载波长度将线程划分为K=N L块block,每块包含L个线程,这样就可以在同一block中进行同一载波下的矩阵运算,而不同载波即不同block之间的计算相互独立。核函数伪代码如下所示:

其中:输入形参x,y分别对应参考信号与监测信号的频域矩阵;sharedr与sharedc代表共享内存矩阵;XX函数功能为将输入元素自乘,XY函数为将输入的对应元素进行复数相乘。核函数通过在共享内存内同时进行两次低线程规约算出系数,最后经过一次复数运算得到Y′k对应的元素。此外,考虑到连续访存问题,核函数执行前后还需要两次矩阵转置。
2.3 匹配滤波算法的CUDA实现
根据式(4),匹配滤波分段进行距离相关,然后另一维变换至频域来获取多普勒信息,其中相关运算还可以利用FFT加速实现。这里FFT和IFFT运算依然使用CUFFT库实现,因此匹配滤波的处理步骤如下:
1)利用cufftPlan1d函数分别对直达波抑制后的监测信号SECA⁃C与参考信号补零并进行长度为2×L的FFT变换。
2)对变换后的信号通过核函数进行共轭相乘,接着通过IFFT运算完成距离维的相关运算。
3)对相关后的数据进行多普勒维上的FFT。
此外,需要注意的是,利用FFT实现互相关时,需要将互相关的两个信号至少补零至长度为2×L-1以上再进行FFT,而之所以设计为2×L的FFT运算,是因为在ECA⁃C实现过程中已经对参考信号进行了长度为L的FFT运算,而长度为L的FFT运算结果是补零至长度为2×L的FFT中的奇数元素,因此在考虑系统达到最好的加速效果条件下,可在将ECA⁃C实现时直接进行两倍长度的FFT来优化对此部分的计算。
2.4 恒虚警检测的CUDA实现
要将OSCFAR算法在GPU中并行实现,首先需考虑的是参考信号的读取,因为每个核函数除了读取自身的数据外,还读取了周围的数据,每一块block中存在数据复用的情况,因此可以先将块内所有的数据存入共享内存中进行加速。而对于超出矩阵维度的边界情况,本文采用边界镜像拓展处理。
OSCFAR的实现除了反复读取检测信号周围的数据外,耗时最长的操作就是对参考单元排序。而GPU相比CPU来说,GPU对逻辑判断和循环支持的执行效率较差,如果在每个核函数中都进行排序,必定影响并行的效率,故本文提出一种替代的方法对待检测的信号进行判决。
假设对于某个待判决的检测单元来说,其参考单元的数量为p,而OSCFAR算法是将第M大的参考单元值与待检测单元乘以门限值后进行比较,因此只需将待检测单元与每个参考单元进行1次比较,通过判断比检测单元大的参考单元数量是否大于M来判决目标是否存在。此方法的时间复杂度仅为O(N),且无需在核函数内部进行排序。核函数伪代码实现如下所示:

其中:形参x对应待判决的矩阵;coeff代表门限因子;p为参考单元的长度。
3 仿真结果分析与加速比测试
3.1 实验环境
本文使用的GPU型号为费米架构的NVIDIA GeForce 820M,计 算 能 力2.1,拥 有96个CUDA核 心(CUDA Cores),显存为2 GB,核心频率为625 MHz,CUDA版本为7.5。CPU型号为Intel I5⁃4200M,主频2.5 GHz。操作系统为Ubuntu 16.04,对比平台为CUDA与Matlab,之所以选用Matlab是因为Matlab在矩阵运算上实现了高效优化,例如在Intel上利用MKL(Math Kernel Library)加速,因此对比结果也更具有代表性。
实验数据采用OFDM调制的数字调幅广播模式B标准的仿真信号数据,并加入直达波、多径、目标和噪声来仿真监测。目标设定为两个,多普勒频移为8 Hz、-5 Hz,采样点延时数据为-50、10,通道数为16,每个通道采样点数为163 840,设定最大双基地探测距离为4 000 km,采样率为12 kHz,按照一个完整OFDM符号时间采样点长度可将各通道采样点数划分为320个载波域复数数据,每个载波共得到512个OFDM符号数据,这样监测信号可以看成16×320×512的复数矩阵。
3.2 结果分析
表1显示的是波束形成在不同环境下的运行时间,其中,未优化指的是按照文献[9]实现波束形成核函数,DBF_1和DBF_2分别代表本文提出的波束形成核函数的两种实现方法,其中,DBF_1方法的计时包括矩阵转置所需的时间。对比可以看出,在GPU上进行波束形成即使直接利用CUBLAS函数库,所需时间也优于Matlab版本的2.9倍,而本文提出的两种方法在此情景下性能都优于直接利用CUBLAS函数库计算。此外,对比未优化版本与DBF_1的核函数运行时间,可以看出非连续合并的内存访问对核函数性能有较大影响,DBF_1通过转置解决访存问题对性能有将近2倍的提升,而单从波束形成算法的实现来说,本文提出DBF_2实现方法明显要优于DBF_1,加速比达到了5倍多。
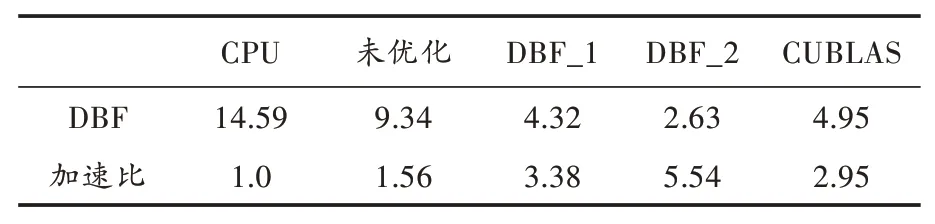
表1 波束形成运行时间对比 ms
表2是ECA⁃C算法与匹配滤波处理16个通道的数据所需的运算时间,其中ECA⁃C算法与匹配滤波算法在Matlab中的实现也已经按照2.2节、2.3节所提到的优化思路进行优化,对比可以看出,ECA⁃C加速效果良好,达到了25倍,而匹配滤波也有15倍的加速。

表2 杂波抑制与匹配滤波运行时间对比 ms
对于某一维度的OSCFAR,参考单元长度设置为20,保护单元长度设置为2,表3显示的是单张距离多普勒图经过二维OSCFAR所需的运行时间,其中表3中排序指的是按照OSCFAR原始算法对参考单元进行排序在对应平台下的实现,而优化版本是指根据2.4节所提出的不进行排序方法进行的优化实现。对比CPU上运行时间,可以看出本文针对OSCFAR算法提出的优化方法,在CPU上提升效果不明显,只有1.17倍的提升,而对比在GPU上的运行时间,优化后有140倍的提升,而对比CPU,加速比更是达到1 800倍,说明本文提出的方法能有效提高OSCFAR在GPU上的并行检测性能。

表3 OSCFAR运行时间对比 ms
图5为CPU和GPU上运行经过整个信号处理流程得到的目标检测图,可以看到设定的两个目标都被找到,证实了整个信号处理并行方案的有效性。
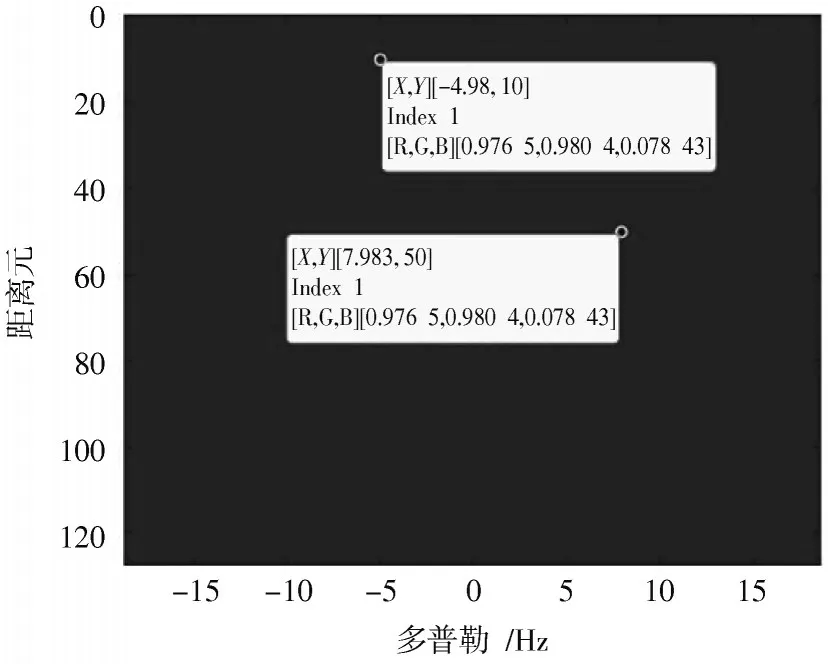
图5 CPU和GPU恒虚警检测判决图
4 结 语
本文设计了基于GPU的OFDM波形外辐射源雷达信号处理整体方案,并对各处理模块算法在GPU架构下的高效实现方法进行了深入研究。在考虑GPU访存连续的前提下提出了两种波束形成实现方案,实现了GPU下结合OFDM信号特性的杂波抑制方法ECA⁃C,完善了一种在GPU下的CFAR判决方法。相比于传统CPU实现方法,本文提出的GPU并行实现方案能有效地减少系统对信号处理所需的时间,对比来说,信号处理中波束形成、直达波抑制、匹配滤波法都有5~25倍的提升,而改进的OSCFAR算法加速比能达到1 800倍,极大地提高了外辐射源雷达系统运行的效率,为实时处理OFDM波形外辐射源雷达提供了可能。
猜你喜欢
北京航空航天大学学报(2020年10期)2020-11-14
雷达学报(2018年5期)2018-12-05
信号处理(2018年5期)2018-08-20
信号处理(2018年5期)2018-08-20
信号处理(2018年8期)2018-07-25
信号处理(2018年8期)2018-07-25
雷达学报(2018年3期)2018-07-18
环球市场(2017年36期)2017-03-09
电子设计工程(2017年20期)2017-02-10
计算机工程与科学(2013年2期)2013-06-07
