
结构特异N-糖蛋白质组学研究进展
2021-09-23 09:26田志新
质谱学报 2021年5期
毕 明,田志新
(同济大学化学科学与工程学院,上海 200092)
蛋白质是构成生物有机体的重要大分子物质,参与生命活动。在线粒体内经基因编码后,蛋白质序列翻译完成,但还要经过高尔基体的翻译后修饰(PTMs)。翻译后修饰是蛋白质重要的化学修饰,经翻译后修饰的蛋白质在调节活性和其他生物分子相互作用等方面具有功能性作用。翻译后修饰包括磷酸化修饰、糖基化修饰和泛素化修饰等。糖基化修饰在蛋白质折叠[1]、细胞粘附[2]、信号传导[3]等生命活动中发挥重要作用。真核生物中,一半以上的蛋白质可以发生糖基化形成糖蛋白,其中90%是N-糖蛋白[4]。N-连接糖中的N-乙酰葡萄糖胺连接在天冬酰胺的N原子上,其中天冬酰胺满足氨基酸序列Asn-X-Thr/Ser/Cys(X≠Pro)。构成N-连接糖的单糖种类多达700多种,在结构上,多种序列和连接方式使得N-连接糖的糖型复杂、异构体多;在位点上,相同的N-连接糖可以修饰同一蛋白的不同位点,同一位点也可以修饰不同结构的N-连接糖,具有宏观和微观不均一性。对N-连接糖的生物合成过程研究表明,初始糖型为Glc3Man9GlcNAc2,而后在多种糖苷酶的作用下剪切或连接上其他单糖,形成最终糖型[5]。N-连接糖的结构种类可以分为高甘露糖型、复杂型和杂合型,示于图1。这3类糖型共同享有核心五糖结构(Man3GlcNAc2),底部为N-乙酰葡萄糖胺与天冬酰胺连接,顶部为2个并列的甘露糖,其余单糖可连接在甘露糖上形成天线结构,天线数量可以是2、3或4。高甘露糖型在核心结构上只连接甘露糖或者葡萄糖;而复杂型则在核心结构上连接N-乙酰葡萄糖胺等其他单糖;杂合型同时含有高甘露糖型和复杂型的支链,是二者的组合。
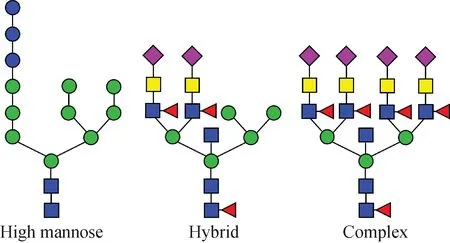
图1 N-连接糖类型Fig.1 N-linked glycan types
疾病条件下,蛋白质糖基化会发生糖型结构的改变及表达的差异变化。美国食品药品监督管理局(FDA)认证的肝癌诊断标志物甲胎蛋白(AFP)的诊断特异性可达90.6%,但灵敏度仅为60%[6];在一些良性肝病或者肝硬化患者中也能检测出AFP的高水平表达,所以临床上还需要配合使用影像学手段来确诊肝癌,增加了确诊难度。因此需要进一步挖掘更准确的诊断及预后标志物。扁豆凝集素(LCA)可以将AFP分为AFP-L1、AFP-L2和AFP-L3三个异质体,Breborowicz等[7]基于此,研究了AFP在不同患者中的微观异质性,其中2/3肝癌患者的AFP电泳谱图轮廓与良性肝病病人不同,通过脱脂AFP初步试验认为,微观异质性可能来源于不同的糖基化,与脂肪酸无关。Sato等[8]追踪了在肝硬化患者和肝癌患者中不同AFP异质体的含量随着病程发展的变化,发现AFP-L3在肝细胞癌中的特异性非常高。AFP是一种糖蛋白,在氨基酸序列251号位点(Asn251)上可以发生糖基化,核心岩藻糖基化的AFP,即AFP-L3与LCA有很强的结合能力[9],示于图2a。Kim等[10]采用液相色谱-质谱联用法研究了岩藻糖基化的AFP(Fuc-AFP)在肝癌患者和肝硬化患者血液中的表达水平,发现AFP在肝癌患者中岩藻糖基化率达到80%以上。类似的,Wu等[11]研究了多个蛋白在肝癌患者中的岩藻糖糖基化水平,在蛋白微阵列的帮助下,发现岩藻糖糖基化的甲胎蛋白、脱γ羧基凝血酶原(DCP)、磷脂酰肌醇蛋白聚糖(GCP3)在肝癌患者中明显高表达,由此可见,岩藻糖与肝癌细胞的形成存在关联。目前,在临床研究中,核心岩藻糖基化的甲胎蛋白(AFP-L3)被确定为肝细胞癌的诊断标志物,灵敏度为56%,特异性为95%[9]。除了诊断标志物,糖基化蛋白质也在药物治疗中彰显作用,策略是将蛋白质糖基化作为增强免疫检查点治疗。癌细胞上的程序性死亡配体-1(PD-L1)和T细胞上的程序性死亡受体-1(PD-1)使癌细胞能够逃过T细胞介导的免疫监视,Li等[12]在三阴性乳腺癌中发现PD-L1和PD-1的相互作用需要β-1,3-N-乙酰葡萄糖转移酶(B3GNT3)在PD-L1糖基化位点N192和N200上介导糖基化,在这一原理的基础上,合成可以特异性识别PD-L1上N192和N200上聚糖部分的单克隆抗体STM108,促使PD-L1内化和消解,示于图2b。除此之外,改变糖型也可以作为药物治疗的一种手段,免疫球蛋白(IgG)整体呈“Y”型,仅有的2个N-糖基化位点对称分布在可结晶段(Fc)的2条重链上,Fc是IgG与效应分子或细胞进行相互作用的部位,N-连接糖组成和结构会影响这种相互作用,研究发现,唾液酸化的IgG可以转化为体内抗炎介质,减弱体内自身免疫性炎症。Pagan等[13]利用唾液酸转移酶ST6GAL1将内源性IgG转化为体内抗炎介质,发现这种方法可抑制关节炎和肾毒性肾炎等由于IgG免疫过激而导致的免疫性疾病。ST6GAL1只能催化α-2,6唾液酸与N-连接糖上的半乳糖相连接,不能催化α-2,3唾液酸,而且连接方式不同的唾液酸具有不同的生物功能,α-2,3唾液酸修饰的IgG并不具备抗炎功效,可见N-连接糖的结构特异影响糖蛋白的生物功能,示于图2c。
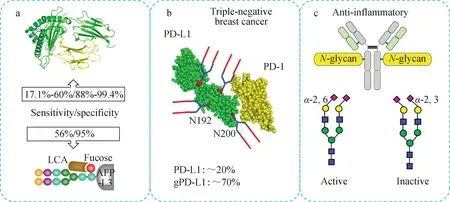
注:a.肝癌诊断中AFP-L3相对于AFP灵敏度的显著提高;b.三阴性乳腺癌靶向治疗;c.α-2,6唾液酸IgG的抗炎活性图2 N-糖基化功能的位点和结构特异性Fig.2 Site- and structure-specificity of the functions of N-glycosylation
在生命有机体中,器质性病变和药物环境的更改都会导致N-糖蛋白的明显变化,科学家们一直在研究N-糖蛋白在生命体内的合成通路和信号通路,以期寻找疾病诊断标志物、预后标志物和药物靶点等,促进精准医疗发展,解开生命的奥秘。随着分析仪器、实验方法和搜索算法的精进和完善,糖蛋白质组学的时代已经来临[14]。
1 基于质谱的N-糖蛋白质组学
可以根据样品的类型,将基于质谱的N-糖蛋白研究分为4种层面。第一种是完整蛋白层面,样本没有经过胰蛋白酶等酶切,保持氨基酸序列的完整,这种层面能够得到完整蛋白序列信息,也保留了聚糖结构的完整,但在质谱中由于糖的比例较少,信号较低,不利于分析聚糖结构;第二种层面是完整N-糖肽,利用酶的特异性,将蛋白切成多肽,并利用ZIC-HILIC、凝集素等富集方法获取糖肽,这种方法既可以保留糖基化位点信息,又可以解析糖的结构,在糖蛋白组学中应用较广;第三种是在含糖基化位点多肽层面进行分析,利用糖苷酶将聚糖从多肽上切除,保留多肽,这种方法保留了位点信息(糖修饰天冬酰胺变成天冬氨酸),但是丧失了糖的结构信息;第四种层面是利用糖苷酶将聚糖从多肽上切除,保留糖而舍弃多肽,这种方法能够更好地分析单糖组成和聚糖结构,但是会丢失位点信息。综上,完整N-糖肽更有利于N-糖蛋白组学的发展,有利于全方位地研究N-糖蛋白的组成和结构,所以本文阐述的研究进展倾向于完整N-糖肽的分析方法。
1.1 完整N-糖肽样本的制备、富集及定量标记
在完整N-糖肽的样品制备中,主要过程是酶切、富集、标记。富集是在酶切后的多肽中将糖肽和非糖肽分离并提纯糖肽的过程,通过富集可以排除非糖肽对糖肽的干扰。比较主流的富集方法包括亲水相互作用色谱法(HILIC)、凝集素亲和色谱法、二氧化钛(TiO2)富集、酰肼化学富集等。亲水相互作用色谱法的原理是润湿的色谱柱在表面形成水层,当疏水性流动相通过亲水性固定相时,亲水性的物质分配到水层中得以保留,糖肽的保留主要取决于聚糖部分的大小及其亲水性以及多肽主链的亲水性,增加流动相的水含量释放糖肽[15-16]。Zhang等[17]在研究小鼠脑部糖肽时,对比了5种富集方法,其中包括用0.1%三氟乙酸作为流动相中离子对试剂的ZIC-HILIC(IP-ZIC-HILIC),和用0.1%甲酸作为流动相的ZIC-HILIC(ZIC-HILIC-FA),结果表明,用IP-ZIC-HILIC富集鉴定到的糖基化位点为1 891个,明显高于其他方法,且错误发现率(FDR)值为3.29%,显示了较高的灵敏度和特异性。凝集素是从植物或动物中提取的物质,可以特异性识别和吸附蛋白质,而且凝集素具有可重复性和较好的提取率,因此,多种凝集素被开发出来用于特异性抓取糖蛋白[18]。Xue等[19]分别采用凝集素亲和色谱和酰肼化学的方法富集肝癌细胞中的糖肽,研究发现,凝集素方法鉴定到825个糖蛋白上的1 879个N-糖基化位点,而酰肼化学方法鉴定到522个糖蛋白上的1 014个糖基化位点,表明凝集素富集糖肽的效果优于酰肼化学。酰肼化学的作用原理是糖肽上顺式邻二羟基与高碘酸反应生成醛,醛基与酰肼树脂上的氨基反应生成共价腙键,由此可被酰肼树脂抓取,Zhang等[20]将此方法应用在大规模血清样本中糖蛋白的定性定量分析。二氧化钛作为一种两性金属氧化物,根据溶液的pH值和缓冲液类型,既可以发生阴离子交换也可以发生阳离子交换。Sheng等[21]在富集糖肽过程中用低浓度的氨水将非糖肽从TiO2分离,再用高浓度的氨水将糖肽洗脱。TiO2还常用于带有唾液酸的糖肽,在低pH值下,含唾液酸的糖肽与TiO2的结合效率提高[22]。寻找差异表达的完整N-糖肽可以借助标记方法对其进行定量分析,常见的标记方法有用于相对和绝对定量的等重标签(iTRAQ)、串联质量标签(TMT)和稳定同位素标记(SIL)。iTRAQ和TMT标记是利用不同样本带有的不同质量标签在二级质谱中强度差异进行相对定量,可同时对多个样本定量,可同时标记多个样本。利用iTRAQ标记定量分析,用山梨凝集素从10个乙肝相关的早期肝癌患者和100个健康对照者的血清中提取糖蛋白,共有17种糖蛋白存在明显差异表达,其中半乳糖凝集素3结合蛋白(Gal-3BP)的诊断能力最优,灵敏度和特异性分别是80%和93.75%。张会教授课题组研究了固定金属离子亲和层析(IMAC)在富集磷酸化多肽的最优pH值,虽无法避免磷酸化多肽和N-连接糖肽共富集,但是发现在pH 2的条件下,IMAC更倾向于富集含唾液酸的糖肽。因此,在此基础上对IMAC富集的洗脱液用阴离子交换柱MAX分离磷酸化多肽和糖肽,将此方法应用于定量分析2种乳腺癌异种移植模型的TMT标记的多肽,共鉴定到17 582种磷酸化多肽和3 468种N-连接糖肽,其中1 237种磷酸化多肽和236种糖肽明显差异表达[23]。本课题组基于稳定二甲基同位素标记的方法,开发了稳定同位素二乙基标记(SIDE),来源于对照组和疾病组的多肽经ZIC-HILIC富集后,完整N-糖肽的N端和赖氨酸(K)在乙醛(CH3CHO)和氰基硼氢化钠(NaBH3CN)混合溶液中反应上二乙基基团(—(CH2CH3)2),对照组采用乙醛(12CH312CHO),而疾病组采用重标乙醛(13CH313CHO)后可以产生4 u(若包含K,每增加1个K,增加4 u)的差异;在50倍的变化范围内,实际表达倍数与预期表达倍数呈良好的线性关系。Wang等[24]应用此方法对胃癌/癌旁组织的完整N-糖肽进行定量分析,在3组技术重复中,共定量得到993个完整N-糖肽,表达倍数在1.5倍以上,同时,p<0.05的644个差异表达的糖肽中共有155个上调和489个下调。
1.2 完整N-糖肽的LC-MS/MS分析
在完整N-糖肽进入质谱分析前分离样本,以防止高浓度物质对低浓度物质的信号抑制,是对样品中众多物质聚类提高灵敏度的方法,主要包括电泳法、液相色谱分离。电泳法是利用蛋白质等电点的不同对蛋白质进行分离的方法。Zhu等[25]优化了毛细管区带电泳(CZE)的方法,将CZE与ESI-MS/MS联用分析了大肠杆菌的多肽,在单次实验中,由100、10、1 ng样本分别鉴定到1 250、1 000和600条多肽,揭示了CZE可用于大规模复杂样本的鉴定。液相色谱分离法有反相色谱、尺寸排阻色谱、亲水作用色谱和离子交换色谱等,其主要依赖于聚糖化学结构和性质的差异。Kozlik等[26]将纳米级的RPLC和HILIC与质谱联用,鉴定血红素中的糖肽,由于糖肽在HILIC上的极性降低,其保留时间缩短,但nanoHILIC能够将多肽SWPAVGDCSSALR上岩藻糖的2种同分异构体分离出来,以此鉴定核心岩藻糖和支链岩藻糖。为了提高分辨率,多维分离方法更适用于复杂样本的鉴定。单克隆抗体在药物治疗方面具有极大潜力,糖基化与其生物功能息息相关,对单克隆抗体糖基化的研究极为重要。Dong等[27]研究了单克隆抗体标准品的完整N-糖肽,在一维液相分离中,含有1个漏切位点的多肽TKPREEQYNSTYR在分析结果中占主导地位,共有30种糖型,而采用二维液相色谱后,得到了247种糖肽,包含60种聚糖结构。
质谱中常见的解离方式主要有碰撞诱导解离(CID)、高能碰撞诱导解离(HCD)、电子转移解离(ETD)和紫外光解离(UVPD)。不同的解离方式会导致蛋白或糖肽产生不同的碎片。在完整N-糖肽分析中,研究者希望能保留位点信息,同时有足够的糖碎片离子用以分析聚糖种类和结构,因此HCD被广泛应用于N-糖蛋白质组学。HCD活化能较高,对多肽而言,可以产生b型和y型离子。Cao等[28]探究了当HCD设置不同的归一化能量(NCE)时N-糖肽产生的碎片类型,当NCE较低时,HCD优先将聚糖碎裂,从而推断聚糖组成和结构;当NCE较高时,HCD优先解离多肽,提供可靠的肽段序列信息,而后选择了交替HCD碰撞能量30%和50%分解标准蛋白的完整糖肽,并用GlycoFinder对其定性和定量,最终鉴定到38个完整N-糖肽和O-糖肽。相比于交替碰撞能量,阶梯碰撞能量(sceHCD)使用更广泛,在sceHCD中,每次前体离子的累积时间被等分为3段,每次单独的离子积累在不同的能量下碎裂。Riley等[29]比较了不同阶梯能量下完整糖肽的碎裂情况,能量分别是sceHCD25±15、sceHCD30±10、sceHCD30±18、sceHCD35±5和sceHCD35±15,利用Byonic[30]进行数据解析,其中sceHCD30±10、sceHCD30±18和sceHCD35±15都能提供较好的肽段和糖序列覆盖度,糖基化位点通过肽链骨架上残留的N-乙酰葡萄糖胺(GlcNAc)残基来确定,而HCD裂解下能够很好地鉴定糖基化位点。Wang等[31]进一步优化阶梯能量,发现选取阶梯能量为20%、30%、30%时的解离效果更好,在人体胃部组织中鉴定到的完整N-糖肽共有6 746个,位点决定离子有942个,有结构诊断离子的完整N-糖肽有3 495个;而选取阶梯能量20%、30%、40%时对应的数量分别为4 767、599和1 771,降低了42%、57%、97%,因此,阶梯能量为20%、30%、30%适用于位点和结构特异性完整N-糖肽的研究。
本课题组[32]采用LC-NCE-MS/MS分离分析完整N-糖肽,疾病与对照样本处理流程示于图3。以细胞为例,将肝癌细胞与对照样本人干细胞超声提取蛋白后,经还原烷基化后trypsin酶切得到多肽,多肽经ZIC-HILIC富集得到完整N-糖肽,采用1∶1稳定同位素标记后混合。标记后的混合完整N-糖肽2DLC-MS/MS分析流程和数据处理流程示于图4[32]。在反相液相色谱中将完整N-糖肽进行一维分离,再将分离的24个组分组合成8个组分(1,9,17;2,10,18;以此类推混合),得到的8个组分分别进行pentaHILIC-nanoESI-Orbitrap MS/MS分析,8份数据在GPSeeker中搜索轻标正库、轻标反库、重标正库和重标反库,控制FDR≤1%后得到ID,经3次技术重复后,汇总ID,并用GPSeekerQuan对数据进行定量分析,控制条件为3个技术重复中出现2次以上、差异表达倍数≥1.5和p-value<0.05,筛选得到定量结果(详见2.3节)。

图3 1∶1标记完整N-糖肽样本制备流程Fig.3 Experimental procedures for preparing the 1∶1 labeled N-glycopeptide mixture

图4 完整N-糖肽LC-MS/MS分析流程Fig.4 Experimental procedures for LC-MS/MS analysis of intact N-glycopeptides
1.3 完整N-糖肽生物信息学鉴定
1.3.1人类N-连接糖理论数据库 哺乳动物N-连接糖的生物合成过程已研究得较为透彻[5,33]。在内质网中,脂质连接寡糖在寡糖基转移酶的作用下,将糖转移至蛋白质的天冬酰胺残基上,单糖组成为Glc3Man9GlcNAc2[34]。葡萄糖转移酶将葡萄糖逐个切除形成Man9GlcNAc2,随后糖蛋白在内质网中折叠,并在α-甘露糖苷酶作用下失去1个甘露糖,正确折叠的糖蛋白进入高尔基体的顺面膜囊,继续丢失甘露糖直至形成Man5GlcNAc2,以上结构均为高甘露糖型。接着,N-乙酰葡萄糖残基与甘露糖残基相结合,形成杂合型聚糖结构;糖蛋白转移至中间膜囊时,2个甘露糖可切除形成双天线,并且在另一个天线上连接N-乙酰葡萄糖胺,形成复杂型聚糖结构;岩藻糖、半乳糖、唾液酸等单糖可在高尔基体的中间膜囊和反面膜囊中对聚糖进行修饰。基于生物合成过程,得知构成人类N-连接糖的单糖有7种,分别是岩藻糖(F)、葡萄糖(G)、甘露糖(M)、半乳糖(L)、N-乙酰葡萄糖胺(Y)、N-乙酰半乳糖胺(V)和唾液酸(S)。人类N-连接糖由于单糖组成、序列和链接位置的不同,导致其种类繁多。单糖组成相同,序列和链接位置的差别会导致序列异构和链接异构,如岩藻糖的序列异构导致了核心岩藻糖和支链岩藻糖的差异,唾液酸有α-2,3和α-2,6的链接异构体,由此可见,对人类N-连接糖的组成和结构解析具有较大难度。
质谱广泛用于研究N-连接糖的组成和结构,因此可配合质谱搜索引擎使用的N-连接糖理论数据库得以构建。N-连接糖理论数据库主要由聚糖在质谱中的参数构建,例如保留时间、质荷比(m/z)、峰强度等,与样本电离方式和裂解方式相关。多孔石墨化碳液相色谱(PGC-LC)对唾液酸化聚糖的选择性较高,能够很好地分离含唾液酸的异构聚糖。Abrahams等[35]建立在PGC-LC-ESI-MS方法下的糖洗脱时间库,作为GlycoStore中的一部分,同时参考m/z值确定单糖组成,但是这种方法的不足之处在于需要将糖从多肽上切除,缺少位点和多肽序列信息。GlyDB[36]适用于对完整N-糖肽分析时的糖结构解析,裂解方式是碰撞诱导解离,糖苷键断裂而单糖保持完整。Gao等[37]按4种核心结构部分和支链部分构建N-连接糖理论数据库Glyquest,其中包含所有单糖组成的分子质量和在碰撞诱导解离下的二级理论谱图,在匹配过程中,首先计算质子化多肽的分子质量,将前体离子的分子质量减去质子化多肽的分子质量得到糖的分子质量,接着将得到的糖的分子质量与Glyquest中糖的分子质量进行比对,在允许范围内得到候选聚糖结构,最后将候选聚糖结构的二级碎片理论谱图与实验二级谱图匹配,得出图形结果。
本课题组根据逆向合成策略构建人类N-连接糖理论数据库[38]。Xiao等针对3种糖型,基于最大理论N-连接糖,依次切除单糖,直至剩余核心五糖结构,从而构建所有可能的聚糖结构,并去除不符合生物合成过程的糖型,共得到75 888种糖型。人类的N-连接糖理论数据库包含73 516种(92%)复杂型、6 062(8%)种杂合型和33种(0.04%)高甘露型。基于本课题组的HCD裂解方式和单糖碎裂方式,总结每种糖型可能产生的碎片离子,Xiao等根据iMEF算法设计了Glyseeker[39],匹配前体离子和碎片离子的m/z、指纹轮廓用于鉴定N-连接糖的组成、结构拼合基于结构诊断离子,可鉴定到人正常干细胞(LO2)中共有214种N-连接糖,其中杂合型和复杂型占比较高,仅有8种高甘露糖型,另有80种聚糖包含岩藻糖,27种聚糖包含唾液酸,而有69种聚糖既有岩藻糖又有唾液酸。
基于质谱的N-糖蛋白组学研究的另一大挑战是对质谱数据的解析,从中得到多肽序列、糖基化位点和糖的组成和结构,这依赖于算法和搜索引擎的研发。截止目前,适用于完整N-糖肽的搜索引擎有Byonic[30]、GPFinder[40]、SugarQb[41]等,本文重点阐述GPQuest[42]、pGlyco 2.0[43]和GPSeeker[32,44]。
1.3.2数据库搜索引擎GPQuest GPQuest是一种基于质谱图数据库解析的软件,完整糖肽由LC-HCD-MS/MS检测。谱图数据库的建立依赖于Proteome Discoverer(PD)软件,含有糖基化位点的多肽在PD中检索并得到实验图谱(匹配到的碎片离子>4),集合成实验谱图数据库(SLB)。GPQuest的工作流程是:在所有完整N-糖肽的实验谱图挑选出包含2种及以上氧鎓离子(138(internal fragment of HexNAc)),145(Hex-H2O),163(Hex),168(HexNAc-2H2O),186(HexNAc-H2O),204(HexNAc),325(Hex2),366(HexHexNAc),274(Neu5Ac-H2O),292(Neu5Ac))的谱图,这些谱图与实验谱图数据库进行比对,匹配到的b-和y-离子满足一定比例要求,再控制错误发现率FDR≤1%;而后根据前体离子质量和匹配到的多肽离子质量得到聚糖质量,再将聚糖质量在糖数据库中搜索匹配得到单糖组成。GPQuest通过构建诱饵数据库来控制FDR,诱饵数据库的构成原理是将SLB中含有糖基化位点的多肽氨基酸序列打乱,再将其分组为与目标数据库中相同长度的诱饵肽序列。治疗性蛋白质,如促红细胞生成素(EPO)、凝血因子和抗体广泛应用于疾病治疗中,其中糖蛋白质数量较多,解析这些糖蛋白的位点和结构至关重要。中国仓鼠卵巢(CHO)细胞系是产生治疗性蛋白质的主要来源,张会教授课题组利用GPQuest解析CHO细胞系中糖蛋白质的位点和结构,共鉴定到10 338个完整N-糖肽,来源于530个糖蛋白质上的1 162个糖基化位点[45]。Sun等[46]对来源于100个以上志愿者的混合血清进行了完整N-糖肽的位点和结构特异性的鉴定,借助GPQuest鉴定到1 359个完整N-糖肽,涉及63种聚糖组成和370个糖基化位点,88%糖型为复杂型并且包含唾液酸,通过质谱图的解析,发现并验证了2种非典型N-糖基化位点,多肽序列LVNEVTEFAK(来源于白蛋白)和NGVAQEPVHLDSPAIK(来源于α-1B糖蛋白)均发生N-糖基化修饰,修饰糖型为N4H5S1和N4H5S2。
1.3.3数据库搜索引擎pGlyco pGlyco 2.0适用于SCE-HCD-MS/MS的完整糖肽解析,解析完整N-糖肽过程分为粗略评分、精细评分和糖肽谱图匹配FDR控制。聚糖数据库从GlycomeDB(www.glycome-db.org)下载。以1张质谱图为例,首先是粗略评分阶段,前体离子的质量减去聚糖数据库中每种聚糖的质量,得到多肽主链质量,由此可以推算出所有Y离子的质量,通过匹配到的Y离子数量给每种聚糖打分(涉及匹配的峰的数量、质量误差和三甘露糖核心离子数量),并且要求每种三甘露糖核心离子不少于2个,对分数排名在前100的候选聚糖进入精细评分步骤。在精细评分阶段,利用pFind对多肽骨架质量进行检索匹配出候选多肽,并对候选多肽打分(涉及匹配的峰的数量、质量误差和三甘露糖核心离子数量),候选多肽和候选聚糖组合成候选糖肽,候选糖肽的分数是候选糖分数和候选多肽分数的加权总和。FDR控制分为基于同位素的FDR控制和基于捕获的FDR控制。基于同位素的假阳性判断标准是一级质谱中错误鉴定的未标记与标记对,而基于捕获的假阳性判断标准是用其他物种来源的蛋白库和糖库鉴定到的糖肽。Zhang等[47]分别提取了51名前列腺癌(PCa)患者和45名前列腺增生(BPH)患者的血液IgG,并对IgG酶切后富集完整N-糖肽,利用LC-MS/MS分析并用pGlyco 2.0和MaxQuant进行定性和非标定量,发现IgG2上的EEQFNSTFR_H5N5S1在PCa中表达倍数是BPH的5.74倍,而EEQFNSTFR_H5N5在PCa中下调,认为EEQFNSTFR_H5N5S1是前列腺癌的潜在诊断标志物,AUC为0.702,优于现在的临床诊断标志物前列腺特异抗原。Lu课题组[48]对100名乙肝相关肝硬化患者和100名乙肝相关肝癌患者血清中的完整N-糖肽在H216O/H218O标记后进行LC-MS/MS分析后,用pGlyco定性定量检索,共鉴定到305种完整N-糖肽,在出现次数、FDR和打分等条件筛选下得到60种完整N-糖肽,其中来源于IgA2的TPLTANITK_H5N5S1F1/H5N4S2F1在肝癌患者中明显下调,多重反应监测(MRM)分析发现,这2种糖肽在乙肝相关肝硬化患者和乙肝患者中比健康志愿者都存在明显上调,推断IgA2在乙型肝炎的发病机制中存在某种介导作用。
1.3.4数据库搜索引擎GPSeeker GPSeeker搜索引擎是基于同位素质荷比和指纹轮廓(iMEF)算法对完整N-糖肽定性定量的软件,其整合了使用相同算法的完整蛋白质数据库搜索引擎ProteinGoggle2.0[49]和N-连接糖数据库搜索引擎GlySeeker[39]。从Uniprot中下载的人源蛋白数据库在遵循酶切规则和N-糖基化特征序列条件下建立Y1离子理论数据库,其中包含前体离子和碎片离子的理论同位素轮廓,而N-连接糖理论数据库包含根据逆向合成策略构建的75 888种N-连接糖的碎片离子。完整N-糖肽的鉴定流程是:选取包含1种及以上氧鎓离子的二级谱图,寻找这些二级谱图中信号强度前20峰的同位素峰m/z偏差值(IPMD)、同位素峰强度最低值(IPACO)和同位素峰强度偏差(IPAD)在允许范围内的Y1离子,同时经过三重核心离子匹配验证;接着搜索含有糖基化位点是多肽理论的碎片离子,匹配时碎片离子应满足一定比例,再从对应的一级谱图中找到完整N-糖肽的前体离子,同样进行指纹轮廓的比对,需满足IPMD、IPACO、IPAD的要求;对应的N-连接糖的实验碎片离子和理论碎片离子同理,N-连接糖匹配碎片离子数(MPs)、N-连接糖P score得分排名(TopN Hits)和同一个P score得分对应的N-连接糖匹配谱图的数量(NoHs)满足参数设置。糖基化位点由多肽骨架碎片离子推断,完整N-糖肽上的聚糖和多肽骨架在解离能量的碰撞下断裂,并在天冬酰胺上保留1个N-乙酰葡萄糖胺,从而改变m/z,即可以通过解析碎片离子上是否包含GlcNAc来确定位点。如来源于尿液中的完整N-糖肽EDIFMETLKDIVEYYNDSNGSHVLQGR_N4H5S2包含2个潜在糖基化位点,碎片离子y12*和y13*虽包含GlcNAc,但是无法区分位点,而y9*和y10*可以明确指出糖基化位点是N112,示于图5[50]。另外,GPSeeker在解析聚糖结构时,引用结构诊断离子,也称之为特征碎片离子,可以独立区分该结构与其他相同组成的结构,根据结构诊断离子可以准确推断N-连接糖结构。Shen等[50]对人体尿液中的完整N-糖肽进行鉴定,在多肽骨架WFSAGLASNSSWLR上鉴定到聚糖N4H5F1S2,在对糖碎片离子解析中找到结构诊断离子AI4/YI3/YI2/YI1和ZI4/YI3/YI1,由此推断出聚糖结构分别为01Y41Y41M(31M)61M(21Y(31F)41L32S)61Y41L32S和01Y(61F)41Y41M(31M)61M(21Y41L32S)61Y41L32S,示于图6。构建的诱饵数据库可以对鉴定结果进行假阳性控制,诱饵库是用反序的氨基酸序列产生含糖基化位点的多肽数据库和随机添加1~30 u的质量产生N-连接糖数据库。GPSeeker可以对同位素标记的样本进行定量分析,轻重标记的前体离子的同位素轮廓信息可与理论同位素轮廓进行比对,并得出相对比例,从而实现定量。

注:*表示包含GlcNAc图5 多肽骨架EDIFMETLKDIVEYYNDSNGSHVLQGR图形解离图[50]Fig.5 Graphical fragmentation map of the peptide backbone EDIFMETLKDIVEYYNDSNGSHVLQGR[50]
2 基于GPSeeker的结构特异N-糖蛋白质组学的应用
2.1 新冠病毒SARS-CoV-2重组刺突糖蛋白疫苗的结构特异性鉴定
严重急性呼吸系统综合症冠状病毒2(SARS-CoV-2)即新型冠状病毒(新冠)从2019年发现至今已在国际上造成了大流行,每日新增确诊人数屡创新高,变异病毒株变幻莫测,疫苗的接种能有效避免病毒的感染,因此疫苗的有效性和安全性需要大量实验论证。在病毒攻击人体过程中,SARS-CoV-2中刺突蛋白上的受体结合域(RBD)与宿主细胞上的血管紧张素转化酶2(ACE2)结合。根据这一特点,四川大学团队联手多个科研团队研发出一种包含刺突蛋白受体结合域氨基酸残基319-545位的重组疫苗[51],利用重组疫苗中的RBD结合ACE2,激发有效功能性抗体产生。在对重组RBD的表征中,通过对比分子质量发现蛋白发生了大量糖基化,因此,通过GPSeeker对完整N-糖肽进行鉴定,发现了3个N-糖基化位点N331,N334和N343,N-糖基化比例在30%左右。但是,对N-连接糖在SARS-CoV-2中所处位置研究发现,N-连接糖位点集中在RBD的核心子域中,与ACE2距离较远,所以不会影响抗体抗原结合。
2.2 癌症潜在N-糖蛋白标志物的结构特异性鉴定和定量
目前,癌症是全球第二大杀手,每日确诊癌症的人数屡创新高。随着医疗的飞速发展,癌症的诊断方式日新月异,精度不断提升,癌症标志物的种类也在不断壮大。在高精度分析仪器和新颖的搜索软件帮助下,结构特异的N-糖蛋白潜在癌症标志物被陆续发现。
Xiao等[44]首次使用GPSeeker对肝癌的结构特异N-糖蛋白组学进行描绘并定量分析,利用二甲基标记从HepG2和LO2细胞中提取完整N-糖肽,通过二维液相分离,Q-Exactive质谱分析,在3个技术重复中,共鉴定到1 077个糖蛋白上的5 405个完整N-糖肽,其中定量到的完整N-糖肽数量为2 593个,有720个完整N-糖肽存在差异表达(表达倍数≥1.5,p-value<0.05)。在这次鉴定中,不仅观察到相同N-糖基化位点上不同单糖组成的N-糖蛋白同方向上的表达差异,如表皮生长因子受体(EGGR)的361号N-糖基化位点(简写为N361)上的2种单糖组成N2H7F0S0和N2H8F0S0在肝癌细胞中分别出现了4.8~6.9倍的上调;还观察到相同N-糖基化位点上不同单糖组成的N-糖蛋白不同方向上的表达差异,如组织蛋白酶D的N263位点,单糖组成N2H5F0S0的完整N-糖肽在HepG2和LO2细胞中表达无差异,而单糖组成为N2H7F0S0的完整N-糖肽在HepG2细胞中有明显的低表达,表达倍数为10倍(0.1±0.0)。出乎意料的是,发现了相同N-糖基化位点上相同单糖组成但结构特异的N-糖蛋白表达差异,由于位置异构和连接异构的完整N-糖肽在penta-HILIC(2.7 μm, 90 Å)洗脱时间上存在差异,所以根据洗脱时间可以推断出结构差异,如整合蛋白α-3的N265位点上的单糖结构N4H5F0S1,其中唾液酸存在α-2,3和α-2,6链接异构体,在色谱图中可以看到洗脱时间相差约2.5 min的2个峰,较早洗脱出的α-2,3链接异构体在肝癌细胞中有1.7倍的上调,而较晚洗脱出的2,6-链接异构体没有明显的差异表达,示于图7。除了唾液酸的链接异构,岩藻糖的位置异构也可以被清晰分辨出来,整合蛋白α-3的N107位点糖肽的结构诊断离子Y1包含岩藻糖,较早洗脱出的核心岩藻糖结构存在1.5倍上调,而支链岩藻糖结构出现了2.5倍的下调,示于图8。单糖结构同时出现的位置异构和连接异构也可被分离并完整鉴定,如在洗脱时间为80~85 min的色谱图中,观察到4个色谱峰,对应的完整N-糖肽是NGSLFAFR_N3H6F0S1,根据之前的表述可以确定唾液酸的链接异构,而结构诊断离子BI2可以确定是由2个甘露糖相连接,玻连蛋白(VTN)上观测到的4种异构体在HepG2细胞上都存在明显上调,可以作为潜在标志物继续进行研究。

注:a,d.前体离子同位素指纹轮廓;b,e.二级多肽碎片离子和糖碎片离子;c,f.多肽骨架图形解离图;g,h.N-连接糖图形解离图图6 完整N-糖肽WFSAGLASNSSWLR_N4H5F1S2不同糖型图形解离图Fig.6 Graphical maps of intact N-glycopeptide WFSAGLASNSSWLR_N4H5F1S2 with different N-glycan structures
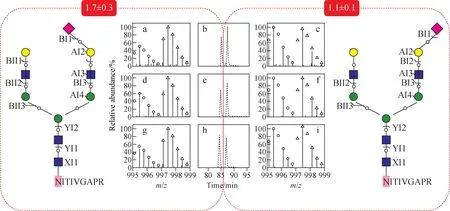
图7 完整N-糖肽NITIVTGAPR_01Y41Y41M(31M41Y41L)61M61Y41L32S(左,变化倍数1.7±0.3)和NITIVTGAPR_01Y41Y41M(31M41Y41L)61M61Y41L62S(右,变化倍数1.1±0.1)在3个技术重复中的积分色谱图(b,e,h),前体离子同位素指纹轮廓(a,c,d,f,g,i)和完整N-糖肽图形解离图Fig.7 Extracted ion chromatograms (b, e, h), isotopic envelopes of the precursor ions (a, c, d, f, g, i) and graphical fragmentation maps of the intact N-glycan moieties of the intact N-glycopeptides NITIVTGAPR_01Y41Y41M(31M41Y41L)61M61Y41L32S(left, fold change 1.7±0.3) and NITIVTGAPR_01Y41Y41M(31M41Y41L)61M61Y41L62S(right, fold change 1.1±0.1) in three technical replicates

图8 完整N-糖肽MNITVK_01Y41Y41M(31M21Y(31F)41L32S)61M61Y41L32S(左,下调0.4±0.1)和MNITVK_01Y(61F)41Y41M(31M41Y41L32S)61M61Y41L32S(右,上调1.5±0.1)的同位素指纹轮廓(a,b)和完整N-糖肽图形解离图和结构诊断离子Fig.8 Isotopic envelopes of the precursor ions (a, b), graphical fragmentation maps of the intact N-glycan moieties and structure diagnostic ions of the intact N-glycopeptides MNITVK_01Y41Y41M(31M21Y(31F)41L32S)61M61Y41L32S(left, fold change 0.4±0.1) and MNITVK_01Y(61F)41Y41M(31M41Y41L32S)61M61Y41L32S (right, fold change 1.5±0.1)
Xue等[52]研究了人乳腺癌细胞(MCF-7)和人正常乳腺上皮细胞(MCF-10A)中差异表达位点和结构特异的N-糖蛋白组学,提取2种细胞系中的蛋白,并用ZIC-HILIC富集完整N-糖肽,经二乙基标记后以1∶1混合,用C18-RPLC-ESI-MS/MS在线分析,技术重复5次,由GPSeeker和GPSeekerQuan进行定性、定量分析,最终鉴定了581个完整N-糖肽,归属于220个N-糖蛋白,包含114种糖型(59种单糖组成),其中73.84%为高甘露糖结构,10.67%为杂合型结构,15.49%为复杂型结构。糖基化的宏观异质性和微观异质性在MCF-7/MCF-10A中都有体现。如溶酶体相关膜糖蛋白1(LAMP1),其N84的聚糖结构01Y(61F)41Y41M(31M)61M由12个结构诊断离子确定(BII1,YI3,YI1等),N103的聚糖结构01Y41Y41M(31M41Y41L32S)61M61M由25个结构诊断离子确定(03AI2,BI1,YI1等),同时N103上还鉴定到N2H4F0S0和N2H5F0S0 2种单糖组成,分别有22和23种结构诊断离子。在相对定量分析中,定量了249种完整N-糖肽,113种在5组技术重复中出现3次以上,56种完整N-糖肽在细胞系中差异表达。经分析,部分糖蛋白被推测为乳腺癌的潜在标志物。NY-BR-1和α1酸糖蛋白只在MCF-7中表达,被认为是高度敏感标志物;在大多数癌症中都显示为下调的微纤维相关糖蛋白4(MFAP4),在MCF-7中的2种糖型N2H5F0S0和N2H6F0S0也都出现了相对下调;检测到CD276抗原存在于MCF7中,而在MCF-10A中缺失,此糖蛋白在乳腺癌组织中也曾被报道;对于MUC-16,15种完整N-糖肽被定性,而这种蛋白在其他癌症中也经常被报道,如卵巢癌、胃癌和乳腺癌;组织蛋白酶D(CATD)在MCF-7中上调。
胰腺癌作为一种恶性肿瘤,早期病症难以察觉,确诊多为晚期。从N-糖蛋白组学角度探究诊断标志物大有裨益。Lu等[53]开展了4组胰腺癌组织和癌旁组织中N-糖肽的位点和结构特异性研究,以期寻找合适的潜在标志物。利用对完整N-糖肽的分析流程,作者首次运用GPSeeker对胰腺组织复杂样本进行鉴定,共鉴定来源于3 437种糖蛋白的20 038个完整N-糖肽,其中有结构诊断离子的共有10 071种,在满足要求成对的前体离子中观察到6个同位素峰,同位素峰强度偏差和m/z偏差在误差范围内,定量得到并出现次数大于等于3的完整N-糖肽共有4 072个,差异表达的N-糖蛋白共有52个,表达上调38个,下调14个。针对每种糖肽的位点和结构分析,不同位点但具有相同糖型的情况引起了注意,高甘露糖型N2H5F0S0在多个差异表达的糖肽中出现,并且在癌组织中表现出明显上调,这一现象值得深入探讨。根据其他已报道的蛋白标志物以及糖蛋白质在癌症中的应用,对比筛选后,作者讨论了胰腺癌的潜在标志物。组织蛋白酶D(CATD)中不同糖基化位点的差异表达不完全相同,一系列高甘露糖结构N263_N2HxF0S0(x=4,5,6,7)在癌组织中出现了1.74~4.73倍不同程度的上调,而N2H5F0S0呈现0.37倍的下调,人前梯度蛋白2(AGR2)在胰腺癌中高表达,而AGR2通过CATD可以促进体内外癌细胞的增殖,揭示了CATD参与胰腺癌的发病机理;三肽基肽酶1(TPP1)和双糖链蛋白聚糖(BGN)在胰腺癌中出现了不同程度的上调,TPP1在胰腺癌的病变前体粘液性囊肿中水平显著增加,而BGN与胰腺癌细胞的增殖起反向作用,可为胰腺癌的治疗提供指导。作为一种新型癌症相关蛋白,神经细胞引领蛋白3(NAV3)首次在胰腺癌中出现6.26~9.71倍的高表达。
2.3 癌症耐药潜在N-糖蛋白标志物的结构特异性鉴定和定量
靶向药物的研发可以延长癌症患者的生存时间,改善患者的生存条件甚至治愈患者。耐药性是患者生存的一大绊脚石,耐药机理也成为现代医学的关注点之一。因此,从N-糖蛋白组学角度出发研究耐药机理并寻找潜在标志物颇有意义。
在对MCF-7/MCF10-A的N-糖蛋白组学研究的基础上,Wang等[54]和Xu等[55]合作研究人乳腺癌细胞耐阿霉素(MCF-7/ADR)和人乳腺癌干细胞耐阿霉素(MCF-7/ADR CSCs)中具有位点和结构特异性的N-糖蛋白。在细胞培养中选取1 000 μg/L阿霉素的人乳腺癌细胞群为MCF-7/ADR,利用CD24-和CD44-微珠抗体抓取MCF-7/ADR CSCs。
Xu等[55]将2种细胞分别裂解,提取蛋白并富集N-糖肽,二乙基标记后1∶1混合,由RPLC-ESI-MS/MS分析,GPSeeker鉴定。控制FDR≤1%后,鉴定到4 016个完整N-糖肽,来源于1 014个糖蛋白上的1 102个糖基化位点,其中有1 847个完整N-糖肽的结构特异打分≥1。在相对定量中,基于鉴定到6个同位素峰强度的前提,共有657个完整N-糖肽在3次技术重复中出现2次以上,其中表达倍数在1.5倍以上的有247个,其中196个上调,51个下调。从差异表达的糖蛋白中,发现3个ATP结合盒式蛋白(ABC)家族中的ABCC5、ABCA4、ABCB9分别在MCF-7/ADR CSCs下调0.46、0.22倍和上调1.89倍,ABC可以发挥药物外排泵的作用,这一结果可为未来的临床治疗提供更详细的糖蛋白信息。
Yang等[56]对人乳腺癌耐药干细胞(MCF-7 ADR/CSC)和人乳腺癌干细胞(MCF-7/CSC)中差异表达的完整N-糖肽进行了定性定量研究,寻找耐药潜在标志物。在3个技术重复中,共鉴定到5 515个完整N-糖肽,包含1 737个糖基化位点,来源于1 516个糖蛋白,380个差异表达的完整N-糖肽中共有87个上调,293个下调。其中有2种糖蛋白既观察到了上调,也发现了下调,长油酸二磷酸寡糖蛋白糖基转移酶亚基(STT3A)上的完整N-糖肽N548_N2H8F0S0上调(1.78±0.22)倍,而N548_N6H4F0S0下调(0.34±0.04)倍;锌指蛋白846(ZN846)中完整N-糖肽N544_N2H8F0S0下调(0.35±0.06)倍,而N117_N2H3F0S0上调(3.60±1.05)倍。通过分析信号通路,对差异表达的糖蛋白进行了聚类,寻找到与耐药相关的信号通路。首先是药物转运相关糖蛋白,溶质载体蛋白(SLC)可促进抗癌药物进入细胞,而SCL22 member 4上的完整N-糖肽LATIANFSALGLEPGR_N2H3F1S0和S40A1上的LANMNATIRR_N3H6F0S1、N2H6F0S0与N2H7F0S0都出现了不同程度的下调,抗癌药物的摄取受到限制;其次是药物代谢相关蛋白,棕榈酰蛋白硫酯酶1(PPT1)可调节脂质代谢,根据以往研究可知,PPT1上调会引发耐药性,GINESYKK_N2H7F0S0在本次研究中出现了2.26倍的上调;药物作用期间会导致细胞DNA损伤而使细胞凋亡,DNA损伤修复作用会产生耐药性,与DNA损伤修复相关的组蛋白-赖氨酸N-甲基转移酶在MCF-7 ADR/CSC中被糖型N2H8F0S0修饰,并出现明显下调。
2.4 癌症干细胞潜在N-糖蛋白标志物的结构特异性鉴定和定量
癌症干细胞在肿瘤的发生、转移、治疗中的耐药和治愈后的复发中起着重要作用。
Wang等[57]在人乳腺癌干细胞(MCF-7/CSC)和人乳腺癌细胞(MCF-7)全细胞裂解的差异表达N-糖蛋白中,共鉴定到了2 558个完整N-糖肽,涉及640个糖蛋白和727个糖基化位点。在定量结果中,144个完整N-糖肽在MCF-7/CSC中相对于MCF-7差异表达,其中上调的糖肽有53个,下调的糖肽有91个。上调的53个完整N-糖肽来源于16个糖蛋白,其中有7个在其他文献中已有报道;下调的91个完整N-糖肽来源于30个糖蛋白,其中有8个已有报道。CD14和氨肽酶N是乳腺癌干细胞的潜在标志物,在定量分析中鉴定到了这2种糖蛋白,其中CD14上的完整N-糖肽LRNVSWATGR_N2H7F0S0轻微下调(0.80±0.03),氨肽酶N上的完整N-糖肽AEFNITLIHPK_N2H7F0S0明显上调(12.03±1.07)。作者对比了MCF-7/CSC(与MCF-7差异表达)和MCF-7/ADR CSC(与MCF-7/ADR差异表达)2个体系中差异表达糖肽的结果,发现丝氨酸/苏氨酸蛋白磷酸酶4调节亚基3A(PPP4R3A)上的完整N-糖肽TNLSGR_N2H8F0S0和内质网融合蛋白3(ATLA3)上的完整N-糖肽EINGSK_N2H8F0S0在CSC体系中出现明显的差异表达,分别是下调(4.11±0.19)倍和上调(3.21±0.61)倍,而这2种糖肽在ADR体系中并未出现差异表达,这2种蛋白在干细胞体系和耐阿霉素体系中的不同生物功能有待进一步研究。
Wang等采用相同的策略分析了MCF-7/ADR和MCF-7/ADR CSCs细胞表面上的N-糖蛋白,共鉴定到1 336个完整N-糖肽,来源于289个N-糖蛋白,定量结果中差异表达的完整N-糖肽共有72个,其中64个上调,8个下调。64个上调的完整N-糖肽来源于8个糖蛋白上的8个糖基化位点,表达倍数由高到低分别是人中心体蛋白350(CE350)、含2-氧化戊二酸和铁依赖加氧酶域3(OGFD3)、凝血因子V重链(FA5)、跨膜蛋白132D(T132D)、ATP/GTP结合蛋白1(CBPC1)、(1,4-N乙酰葡萄糖胺转移酶(B4GN3)、GTP酶(GVIN1)和粘蛋白16(MUC16)。8个下调的完整N-糖肽来源于4个糖蛋白上的4个糖基化位点,表达倍数由低到高分别是非传统肌球蛋白VIIa(MYO7A)、免疫球蛋白受体2DL1(KI2L1)、丝氨酸/苏氨酸蛋白磷酸酶4调节亚基3A(P4R3A)和膜相关鸟苷酸激酶倒3(MAGI3)。
Xu等[55]在MCF-7/ADR和MCF-7/ADR CSCs全细胞裂解的研究中发现了一些干细胞的潜在标志物。如,人锌指蛋白GLI1位点N344上单糖组成N2H8F0S0在癌症干细胞中出现2.66倍的上调;CD63抗原位点N130上单糖组成在癌症干细胞中上调3.39倍;CD49F位点N323上单糖组成N2H6F0S0在癌症干细胞中下调0.77倍。同时,也定量到了一些尚未报道的糖蛋白。如,片段极性蛋白的同源物DVL-3、骨形成蛋白-7(BMP7)、缺氧上调蛋白1(HYOU1)和高速涌动组蛋白B4(HMGB4)。
Yang等[56]在MCF-7 ADR/CSC和MCF-7/CSC体系中鉴定到与耐药性相关的癌症干细胞潜在标志物CD63,锌指蛋白GLI1和CD33。来自CD63蛋白上的完整N-糖肽NNHTASILDR_N2H8F0S0出现0.44倍下调,而CD63上的完整N-糖肽NNHTASILDR_N2H6F0S0在MCF-7/CSC和MCF-7体系中被鉴定到0.44倍下调[57]。
3 结论与展望
N-糖蛋白质在细胞粘附、信号传导等方面发挥重要作用。N-糖蛋白质因其丰度低和复杂多变的结构,其结构特异性分析异常困难。多种富集方法克服了N-糖蛋白质丰度低的挑战,高效串联质谱和搜索引擎的快速发展使复杂多变的结构逐渐清晰。对完整N-糖肽上的N-连接糖结构解析的同时,还可以保留糖基化位点信息,是结构特异N-糖蛋白质组学研究的重要内容。本文从完整N-糖肽的样本制备流程、液相色谱-质谱联用分析方法和生物信息学数据解析等角度,对目前完整N-糖肽的结构分析进行概述。亲水相互作用色谱法、凝集素色谱法和二氧化钛富集法等富集方法可有效去除多肽对糖肽的信号干扰;等重标签、串联质量标签和同位素标记方法有助于多个样本的相对定量,在不同体系中寻找差异表达N-糖基化;N-连接糖理论数据库涵盖了N-连接糖的组成和结构,帮助数据搜索引擎解析结构信息;GPQuest、pGlyco和GPSeeker各自采用不同的算法,对数据的评判标准各有特点,其中GPSeeker基于同位素轮廓指纹比对来识别一级和二级质谱中的前体离子和碎片离子,以及通过N-连接糖部分的结构诊断性离子明确区分具有相同单糖组成的序列异构体,能够解析出完整N-糖肽的糖基化位点和N-连接糖部分的结构,在结构特异N-糖蛋白组学方面得到了广泛应用,被成功运用在细胞和组织等不同体系中。
基于GPSeeker对完整N-糖肽定性定量研究应用于癌症潜在标志物的发现和新冠病毒疫苗的功能研究,推进了结构糖蛋白质组学的进一步发展,也为生物医学领域提供了研究方向。但是,N-糖蛋白质组学仍然存在些许欠缺。首先是样本规模有待进一步扩大,从大数据角度分析差异表达的N-糖肽,结果才更具共性和广泛性;其次,需要丰富样本种类,对疾病的病灶组织分析应用于机理研究,从体液中分析更便于临床诊断,多种类型样本分析更能体现生物的整体性;同时各种生物学分析方法需配合使用,增加可信度。
越来越多的潜在糖蛋白质标志物和药物靶向糖蛋白被发现和证实,拓宽了精准医学应用领域,造福于被疾病困扰的人群,结构特异的N-糖蛋白质组学将会在这个全新的时代继续深入发展,帮助解开人体的奥秘。
猜你喜欢
河南化工(2022年5期)2023-01-03
食品安全导刊(2021年21期)2021-08-30
天然产物研究与开发(2019年1期)2019-03-01
中成药(2018年7期)2018-08-04
中成药(2018年1期)2018-02-02
现代检验医学杂志(2016年1期)2016-11-12
天然产物研究与开发(2016年1期)2016-06-05
中南民族大学学报(自然科学版)(2015年2期)2015-12-16
中国药理学与毒理学杂志(2015年3期)2015-12-16
食品科学(2013年17期)2013-03-11
