
面向合成孔径雷达图像任意方向舰船检测的改进YOLOv3模型
2021-09-23 09:12徐英谷雨彭冬亮刘俊陈华杰
兵工学报 2021年8期
徐英, 谷雨, 彭冬亮, 刘俊, 陈华杰
(杭州电子科技大学 自动化学院, 浙江 杭州 310018)
0 引言
海面舰船目标检测对于维护我国海洋权益、促进海洋资源开发起到至关重要的作用。目前,用于舰船目标探测的主要数据来源包括雷达一维距离像、合成孔径雷达(SAR)图像、卫星或无人机拍摄的遥感图像、近岸或海面舰船搭载的光电平台拍摄的视频图像等[1]。
SAR是一种主动式微波成像传感器,具有全天时、全天候工作能力,对土壤、植被和云雾等具有一定的穿透性,在军事和民用领域具有广泛的应用[2]。目前,国内外研究学者在SAR图像舰船目标检测与识别方面开展了大量的研究工作,建立了较为成熟的SAR图像舰船目标监视系统[3]。
恒虚警(CFAR) 算法是一种经典的SAR图像目标检测算法,其利用待检测像素的邻域信息估计背景分布模型,然后基于恒虚警率计算分割阈值,基于贝叶斯理论实现目标和背景像素的分类[4-6]。根据杂波类型不同,可采用的背景像素分布模型包括对数正态分布、威布尔分布、K分布等。根据背景区域划分策略不同,可分为单元CFAR、单元平均选小CFAR、单元平均选大CFAR、有序统计CFAR和可变窗口CFAR等。虽然CFAR算法在工程上应用已经相对成熟,但仍存在以下问题:1)算法计算量较大,需进行优化处理;2)背景模型选择带有一定的主观性,且在复杂背景下检测虚警率较高。
随着深度学习理论和优化技术的发展,基于卷积神经网络(CNN)的目标检测识别模型取得了远超传统方法的性能[7]。用于目标检测的深度模型可分为一阶段检测模型和两阶段检测模型[8]。一阶段检测模型,如文献[9]提出的一阶段多框检测(SSD)模型和文献[10]提出的YOLOv3模型,直接根据输出的特征图进行回归,输出目标位置、置信度和类别等信息。两阶段检测模型,如文献[11]提出的Faster R-CNN,一般包含一个区域建议网络(RPN)和一个基于区域的识别网络(R-CNN)。RPN网络用于筛选候选目标区域,R-CNN用于目标类别分类和位置精调。虽然一阶段算法具有实时性好的优势,但检测精度相较两阶段算法略低。
目前研究学者已成功将深度CNN模型应用于SAR舰船目标检测[6]。将深度模型应用于SAR图像舰船目标检测首要解决的是数据问题,我国学者在这方面做了大量基础性工作。李健伟等[12]构建了星载SAR图像舰船检测数据集(SSDD),共包含不同分辨率、极化、海况等条件下的1 160幅SAR图像。上海交通大学建立了OpenSAR云平台,先公开了OpenSARShip舰船分类数据集[13],后又公开了一个包含10幅大范围海域SAR图像的舰船目标检测数据集。文献[14]发布的SAR图像舰船目标检测数据集包含102幅高分三号卫星和108幅哨兵一号卫星的 SAR图像,共有43 819个舰船切片。最近,孙显等[15]公开了一个面向高分辨率、大尺寸场景的SAR图像舰船检测数据集AIR-SARShip-1.0,该数据集包含31幅高分三号SAR图像,场景类型包含港口、岛礁、不同级别海况的海面等。上述数据集大部分采用视觉目标分类挑战赛(PASCAL VOC)的标注格式,即采用目标包围盒左上角和右下角像素坐标共4个参数描述目标的垂直框信息。在SSDD基础上构建的SSDD+采用8参数倾斜框标注格式描述任意方向的舰船目标,这8个参数为描述目标倾斜框的4个顶点像素坐标。高分辨率SAR图像数据集(HRSID)[16]采用微软上下文中常见目标(MS COCO)标注格式,标注方式采用和SSDD+一致的倾斜框方式,总共包含5 604张高分辨率SAR图像,共有舰船目标16 951个,可用于舰船目标检测和实例分割等验证。
目前研究学者致力于提高垂直框标注格式下的SAR图像舰船目标检测精度。文献[17]采用基于阈值分割的感兴趣区域(ROIs)提取方法实现目标初步定位,然后通过构建低复杂度的CNN模型实现目标的精确分类与定位,但该方法不是端到端结构,检测结果很大程度上受ROIs提取方法的影响。为解决对数据集利用不充分的问题,文献[18]采用Fast R-CNN框架,提出一种基于生成对抗网络和线上难例挖掘的SAR图像舰船目标检测方法,在SSDD上将检测精度提升了2.1%. 文献[12]首次将Faster R-CNN应用于SAR图像舰船目标检测,实现了端到端的模型训练与预测。通过实验验证了特征聚合、迁移学习和损失函数优化等对于提升舰船目标检测准确率和速度的有效性,目标检测平均精度均值(mAP)达到了78.8%. 文献[19]也采用Faster R-CNN框架,选择ResNet101作为特征提取网络,采用密集连接结构融合了高分辨率特征图的空间特征和低分辨率特征图的语义特征,提高了对不同尺度、不同场景SAR图像中舰船目标的检测能力,对SSDD进行验证mAP达到了89.6%. 文献[20]提出一种层叠耦合CNN模型引导的视觉注意力方法实现SAR图像舰船目标检测。文献[21]提出一种基于视觉注意力机制的深度CNN结构,采用类似YOLOv3的一阶段检测框架进行SAR图像舰船目标检测,对扩展SSDD进行验证,实验结果表明提出的方法检测精度优于YOLOv3和SSD框架,但低于结合特征金字塔结构的Faster R-CNN检测精度。文献[22]采用SSD框架,提出了一种轻量级特征优化网络,通过采用双向特征融合模块和注意力机制提高了舰船目标检测精度。文献[23]同样采用SSD框架,基于SSDD验证了融合上下文信息、迁移模型学习对于提高舰船目标检测精度的有效性。文献[24]提出一种新型金字塔结构用于多尺度特征提取,然后对传统注意力模块采用密集连接方法对提取的特征进行变换,并对这些特征进行融合,实现不同尺度舰船目标的检测。
在一些应用场合,舰船目标的方位角信息具有重要的参考价值,因此学者开始研究能够输出目标方位角估计的深度检测模型。文献[25]采用一阶段检测框架,设计了一个多尺度自适应校正网络来检测任意方向的舰船目标。设计的模型采用目标中心点坐标、长宽和方位角共5个参数描述目标旋转框信息,其中目标方位角定义为水平轴沿逆时针方向旋转到与目标旋转框相交的角度,范围为(-90°,0°]。与传统的一阶段检测模型不同,采用旋转锚框以解决目标方位角估计问题,但锚框角度和长宽比需通过实验进行优化设置,其对检测结果影响较大。通过对旋转非极大值抑制(RNMS)算法进行改进,以更好解决目标重叠问题。文献[26]基于SSD框架,采用和文献[25]一致的旋转锚框策略实现目标方位角预测,但目标方位角范围定义为[0°, 180°)或[0°, 330°),综合利用线上难例挖掘、Focal损失等解决正负样本不均衡问题。
考虑到检测精度和实时性两方面的需求,本文基于YOLOv3框架,提出了一种能够同时输出垂直框和旋转框的SAR图像舰船目标检测模型,设计的检测模型具有如下特点:1)定义了更加有利于模型参数训练的目标方位角区间,检测网络能同时输出垂直框和旋转框的预测结果;2)基于垂直框和旋转框预测结果设计了多任务损失函数;3)针对可能存在的目标方位角估计偏差,在采用RNMS剔除重叠目标的同时,基于垂直框和旋转框预测判定方位角估计的准确性,并进行校正。最后,基于Tensorflow深度学习框架实现上述模型并进行参数训练,采用SSDD+和HRSID SAR舰船目标检测数据集、可见光高分辨率舰船目标识别数据集HRSC2016[27]分别进行了提出改进模型的性能、迁移性和适用性测试,验证了提出模型的有效性。
1 YOLOv3基本原理
YOLOv3[10]目标检测模型兼顾了检测精度与实时性的需求,通过重新设计特征提取网络(记作Darknet-53),采用特征金字塔网络(FPN)[28]的设计理念构建多尺度检测网络,提高了对不同尺度尤其是小目标的检测性能。
1.1 特征提取网络
Darknet-53网络结构共包含53个卷积层,它借鉴了残差网络的设计思想,在一些层之间设置了旁路连接,能够保证网络结构在很深的情况下仍能收敛,有利于提高特征表达的性能。
1.2 多尺度检测网络
YOLOv3目标检测模型如图1所示,图中N为批大小。当输入图像分辨率为416×416时,经过32倍的下采样后输出的特征图分辨率为13×13. 用于目标检测时,分别从分辨率为13×13、26×26、52×52的最后一个特征图引出分支,设计了多尺度检测网络。由于在每个尺度特征图的网格均设置3个锚框,故YOLOv3模型总计输出13×13×3+26×26×3+52×52×3 =10 647个预测。YOLOv3模型结构采用了不同尺度特征融合策略。如图1所示,为实现细粒度检测,将分辨率为13×13的特征图经卷积后进行上采样,然后与分辨率为26×26的特征图进行融合。采用同样操作得到分辨率为52×52的特征图。由于融合了高层的语义特征,因而更有利于小目标的检测。

图1 YOLOv3模型结构Fig.1 Model architecture of YOLOv3
1.3 预测输出及损失函数定义
定义网络输出参数为(xt,yt,wt,ht,pt,pc),其中:xt、yt分别为目标中心横坐标、纵坐标偏移量的预测值,wt、ht分别为目标宽度、高度的预测值,d=(xt,yt,wt,ht)为变换后的目标坐标;pt为检测目标置信度,理想情况下目标为1,背景为0;设目标类别总数为C,则pc为C维向量,pc为目标属于某一类别的概率分布。分别采用逻辑回归损失、二值交叉熵损失、均方误差损失计算目标置信度估计误差Lt、类别预测误差Lc、位置估计误差Ld.
设分辨率为S×S的特征图中锚框的长、宽分别为ha、wa,则根据网络预测输出结果,利用(1)式计算得到距离特征图左上角坐标为(xlt,ylt)的目标坐标预测值(xb,yb,wb,hb),进而能够得到在归一化图像分辨率下的目标预测结果。
(1)
式中:σ(·)为sigmoid函数。
设用于每个特征图的锚框个数为B,在分辨率为S×S的特征图中计算目标置信度估计误差Lt的具体公式为
(2)

类别预测误差Lc的公式如(3)式所示:
(3)
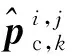
采用均方误差计算位置估计误差Ld的公式为
(4)

2 同时输出垂直框和旋转框的改进YOLOv3模型
针对检测过程中对目标方位角估计的需求,同时兼顾SAR图像中不同尺度舰船目标的分布特性,对多尺度检测网络、损失函数等3个方面进行了改进。
2.1 旋转框描述及目标方位角定义
在采用垂直框描述目标坐标的同时,采用文献[25-26]的5参数形式定义旋转框,具体为(rx,ry,rw,rh,rθ),其中,rx和ry为目标中心点的横坐标和纵坐标,rh和rw为目标的长和宽,目标方位角rθ定义为x轴沿逆时针方向旋转到与目标长边重合的角度,如图2所示。与文献[25-26]不同,本文定义目标方位角范围为(-180°, 0°],其充分考虑了舰船目标的特点,由于rh≥rw,因而更加有利于回归训练过程的收敛。文献[25-26]由于选择了旋转锚框机制,但由于舰船目标角度、长和宽分布范围广,设置锚框时需考虑舰船目标不同角度和长宽比情况,以达到满意的检测结果。本文重新定义检测网络预测输出为(xt,yt,wt,ht,rxt,ryt,rwt,rht,rθt,pt,pc),此时各尺度特征图检测分支的输出维数由[S,S,B×(C+5)]增加为[S,S,B×(C+10)]。由于本文在训练时仍采用YOLOv3模型的垂直锚框机制进行正负样本采样,仅在预测时同时输出垂直框和旋转框结果,故采用本文的目标方位角定义能够提高检测网络中参数回归学习的稳定性,从而提高预测的准确性。

图2 旋转框及目标方位角定义示意图Fig.2 Schematic diagram of rotated bounding box and definition of target’s aspect angle
2.2 融合垂直框和旋转框预测的多任务损失函数
对于旋转框的预测损失计算,可采用均方误差损失计算旋转框位置坐标估计损失Lrd,rd=(rxt,ryt,rwt,rht)。 目标方位角估计损失La可采用余弦损失,也可采用均方误差损失,本文选择后者,具体定义为
(5)

一般情况下,目标旋转框应位于垂直框内部,如图3所示。故可将垂直框估计损失作为旋转框估计损失的约束,设计的改进YOLOv3模型多任务损失函数共包含5部分,具体为

图3 与旋转框对应的垂直框示意图Fig.3 Schematic diagram of vertical bounding box corresponding to rotated bounding box
L=Ld+Lrd+Lt+Lc+La,
(6)
式中:Lrd的计算参考(4)式Ld的计算公式。为解决正负样本不平衡的问题,采用Focal损失计算类别预测损失Lc,以提高目标检测的召回率。
2.3 基于旋转框的非极大值抑制及目标方位角校正
训练阶段,对正负样本进行采样,采用的是基于垂直框的IOU判定准则,因此不会显著降低训练速度。测试阶段,采用同文献[25]一致的 RNMS. 因为需要输出目标旋转框估计结果,若采用垂直框估计结果剔除重叠目标,则当目标比较密集时,非极大值抑制(NMS)阈值难以确定,容易漏检目标。
由于设定的目标方位角范围为(-180°, 0°],当目标处于水平方向时,角度估计会出现较大偏差。为解决该问题,计算估计得到的旋转框外接矩形,将其与基于检测网络输出的垂直框计算IOU值,若IOU值小于某个阈值(本文设定为0.5),说明旋转框中角度参数估计不准确,此时将目标方位角估计值设定为 0°.
3 实验结果分析
基于Tensorflow深度学习框架实现提出的改进YOLOv3模型,硬件配置为:Intel i7 8700K CPU,GTX1080TI GPU,32 GB内存。采用SSDD+验证提出模型的性能,并基于HRSID进行模型迁移测试。为进一步验证提出模型的适用性,采用HRSC2016进行可见光图像舰船目标检测实验。训练时对输入数据除进行常规增强,包括水平翻转、随机裁剪和mixup[29]等,还进行了旋转增强,主要是因为对目标方位角进行回归学习,应尽量使训练集中目标方位角覆盖(-180°, 0°],增强后训练数据集数量变为原来的11倍。实验过程中采用的其他训练超参数如表1所示。

表1 训练超参数Tab.1 Training hyperparameters
3.1 基于SSDD+的性能测试实验
SSDD+描述如表2所示。由于对原始的SAR图像人为进行了裁剪,故该数据集的图像分辨率相对较低。相比于SSDD采用(xmin,ymin,xmax,ymax)4参数形式来描述垂直框,SSDD+采用(x1,y1,x2,y2,x3,y3,x4,y4)8参数形式描述任意角度的目标框。采用最小包围盒估计算法能够将上述参数转换为本文描述目标旋转框采用的5参数形式(rx,ry,rw,rh,rθ)。当采用文献[25]定义的旋转框描述时舰船目标长和宽分布如图4所示。由于文献[25]并没有像本文一样区分目标的长度和宽度,故从图4中可以看出,目标长宽比集中分布在两个主要方向上。

表2 SSDD+数据集描述Tab.2 Description of SSDD+dataset
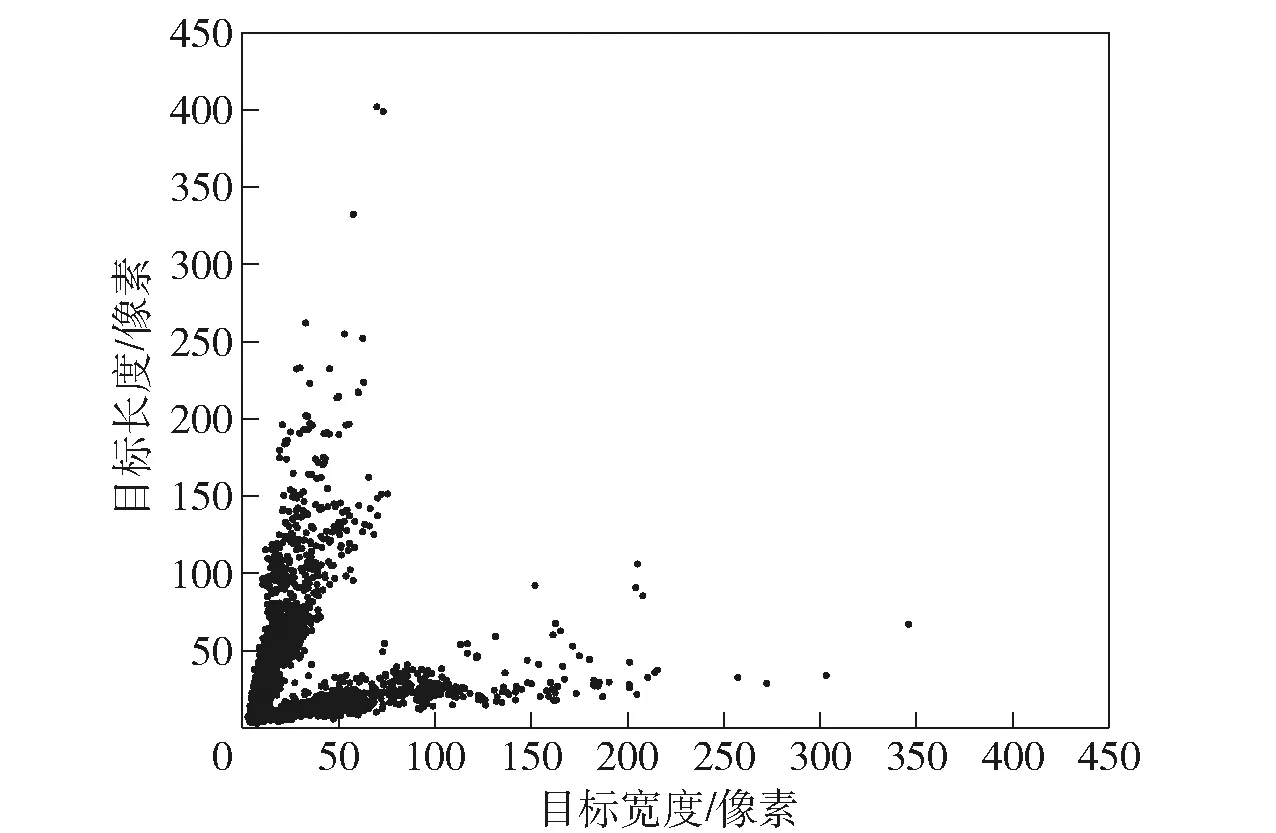
图4 基于文献[25]定义旋转框描述下SSDD+舰船目标长和宽分布图Fig.4 Scatter diagram of ship target’s width and height in SSDD+dataset under the definition of rotated bounding box in Ref.[25]
参照文献[25],将SSDD+按照7∶1∶2比例随机划分成训练集、验证集和测试集。完成模型参数训练后,对测试集进行测试时,设定检测阈值为0.45,设定NMS阈值为0.3. 舰船目标检测结果如图5所示。

图5 SSDD+舰船目标检测结果Fig.5 Ship detection results in SSDD+dataset
从图5(a)和图5(b)中可以看出,在纯海洋背景下,即使目标尺寸很小,目标仍能够被全部检出,且目标方位角估计准确。图5(c)中的靠岸舰船目标没有被检出,这是因为舰船与周围具有较强后向散射系数的背景区域连在一起,此时很难分辨目标。图5(d)中虽然为近岸情况,但是舰船目标周围背景具有较强的对比度,故也能检测出大部分目标,仅有一个虚警。
mAP是检验检测器对于图像中目标召回能力的一个指标,当设定IOU阈值为0.5,置信度阈值为0.05,NMS阈值为0.45时,采用本文改进模型对测试集进行测试可得,mAP0.5=0.819,mAP0.5为IOU阈值设定为0.5时的mAP值。F1分数指标综合考虑召回率和精确率结果,故计算该指标时需设置一个合适的检测阈值。设定IOU阈值为0.5,置信度阈值为0.45,NMS阈值为0.3时,召回率Recall=0.889,精确率Precision=0.868,则F1分数为2×Precision×Recall/(Precision+Recall)=0.879. 文献[25]对SSDD+进行了适当扩充,当采用同样数据集划分比例的情况下,取得了mAP0.5=0.762 4的检测性能。文献[26]没有采用验证集,测试集数量与本文相同,mAP0.5能够达到0.928 1. 由于数据集随机划分导致的纯海洋背景和靠岸情况下舰船目标比例不同,故会导致不同模型之间精度存在一定差异。另外,本文提出改动模型在训练和测试阶段均能利用垂直框预测结果提高旋转框的预测精度,因此在没有对特征提取网络做改动的情况下,mAP0.5值略高于文献[25]结果。
为验证本文提出改进模型中各模块的有效性,进行了消融实验,具体如表3所示。表3中实验2未采用多任务损失函数,仅预测目标的旋转框预测结果,因没有垂直框预测结果,无需进行目标方位角校正,故此时算法耗时较少。比较表3中实验2和实验5结果可以看出,采用多任务损失显著提高了mAP0.5和F1值,提高了目标检测性能。比较表3实验4和实验5结果可以看出,采用本文定义的目标方位角范围也能在一定程度上提高检测性能。由于本文模型采用的是基于回归思想的一阶段模型,故进行旋转增强以生成不同目标方位角下的训练样本,有利于提高训练模型的泛化性能,提高目标检测精度。由表3可以看出,本文算法处理一帧图像耗时约为25 ms,采用现有硬件条件能够满足舰船目标检测实时性的需求。

表3 消融实验Tab.3 Ablation experiment
为验证本文算法的舰船目标方位角估计精度,采用计算F1分数的参数计算目标预测结果。当预测结果和目标真值的IOU值大于阈值0.5时,计算方位角预测值与真值之间差的绝对值,在测试集上统计并计算其均值与标准差。当采用表3中实验5结果时,目标方位角预测值与真值差绝对值的均值为9.35°,标准差为18.41°. 从图5可以看出,本文算法在纯海洋背景下目标方位角估计相对准确,而在近岸情况下性能有所下降,故该差值绝对值变化较大,导致目标方位角估计的标准差略大。
为进一步提高对小目标的检测性能,如图1右上虚线框所示,对原始YOLOv3的3个检测分支进行扩充,采用分辨率为104×104的特征图检测更小的目标,同时对应锚框尺寸设定为(5, 6)、(8, 15)、(16, 10)。当进行图像增强和不进行图像增强的目标检测性能如表4所示。对比表3和表4可以看出,当训练数据有限时,采用3检测分支由于需训练模型参数少,因此检测性能略优。当对训练数据进行旋转增强后,一定程度上增加了小样本的比例,故采用4检测分支的性能略优。检测性能不仅与模型相关,而且受训练超参数影响较大,故表4结果只能一定程度上说明采用4检测分支的有效性。由于增加了1个检测分支,推理耗时比3检测分支高。当采用表4中实验5结果时,目标方位角预测值与真值差绝对值的均值为6.22°,标准差为12.93°,这与表4中实验5的mAP0.5结果高于表3中实验5的结果相符合。

表4 采用4检测分支的目标检测性能Tab.4 Object detection performance using 4 detectionbranches
3.2 基于HRSID的模型迁移实验
HRSID同样采用8参数形式描述任意方向的SAR图像舰船目标,图像分辨率均为800×800. 当采用该数据集进行模型迁移测试实验时,由于与SSDD+的图像分辨率存在差异,故当采用3种不同模型输入分辨率时,采用3检测分支和4检测分支在其他参数设置相同的情况下分别计算mAP0.5,具体如表5所示。从表5中可以看出,随着模型输出尺寸的增加,当SSDD+的图像分辨率和HRSID中的图像分辨率接近匹配时,目标检测精度最优。采用3检测分支略优于4检测分支,这主要是增加一个检测分支虽然能够提高更小目标的召回率,但是同时虚警率也显著增加,故mAP0.5值降低。综合表3~表5结果,由于3检测分支具有更好的迁移性能,故本文后续结果均采用3检测分支模型计算得到。当模型输入分辨率为832×832时,部分检测结果如图6所示。对于纯海洋背景,虽然仅采用SSDD+训练模型参数,但仍能得到较为满意的检测结果,如图6(a)所示。对于靠岸情况,与SSDD+类似,舰船目标检测结果不理想,图6(b)中一个目标也没有检测到,仅有一个虚警。一方面是由于靠岸情况下舰船目标及其周围背景的像素分布复杂,两个数据集间目标分布差异大,会导致训练模型泛化性能下降;另一方面是靠岸情况下HRSID中舰船目标更加密集,且目标相对于SSDD+小,更加难以区分,导致目标检测率下降。

表5 HRSID舰船目标检测精度mAP0.5Tab.5 Ship detection accuracy mAP0.5 using HRSID

图6 HRSID舰船目标检测结果Fig.6 Ship detection results using HRSID
3.3 基于HRSC2016的模型适用性实验
HRSC2016提供了划分好的训练集和测试集,共包含3个不同水平的识别任务:第1级任务仅识别舰船;第2级任务识别航母、潜艇、商船和其他军船4个类别;第3级任务对舰船目标类别进行了进一步细分。本文仅关注第1级任务,即检测图像中的舰船目标。采用同样的训练超参数基于增广后的训练集进行模型参数训练,然后采用同样的参数计算mAP0.5,结果为mAP0.5=0.888. 文献[27]对于第一级任务给出的测试基准为0.797,文献[30]中对该任务的检测结果为mAP0.5=0.875,与本文大致相当。文献[30]是在Faster R-CNN的基础上引入了同文献[26]一致的旋转框描述方法,以解决遥感图像中任意方位角下舰船目标检测问题。这也说明本文提出的改进模型具有一定的通用性,相比于文献[30],由于本文模型采用的是一阶段的检测结构,因此具有推理耗时少的优势。对HRSC2016中部分图像的检测结果如图7所示。从图7(a)和图7(b)可以看出,在不存在密集目标的情况下,对于场景中的不同尺度目标均具有较高的检测精度,且舰船目标的方位角估计准确。从图7(c)可以看出,提出的模型具有一定的泛化性能,对于场景中的未标注舰船目标仍能检测到,且目标旋转框预测准确。提出的改进模型对于密切目标情况检测效果较差,尤其是目标方位角不是垂直和水平的情况,如图7(d)所示。这主要是因为在目标外观相近的情况下,影响了目标垂直框预测精度,且此时垂直框预测区域包含了更多的临近目标像素,对目标方位角预测精度也产生了影响,即使融合垂直框和旋转框进行目标方位角校正也很难处理目标密集情况。

图7 HRSC2016舰船目标检测结果Fig.7 Ship detection results using HRSC2016 dataset
4 结论
本文提出了一种能够同时输出垂直框和旋转框的改进YOLOv3目标检测模型,通过设计多任务损失函数,以及利用垂直框和旋转框预测结果校正目标方位角估计偏差,提高了SAR图像舰船目标检测及方位角估计精度,同时保留了YOLOv3模型推理速度快的优点。实验结果表明,对SSDD+的mAP0.5能够达到0.841,当网络输入尺寸为416×416时处理一幅图像耗时约为25 ms. 提出的改进模型对于纯海洋背景具有较高的舰船目标检测精度,且目标方位角估计准确。对于靠岸情况舰船目标检测精度不高,可通过注意力机制、更加有效的多特征融合策略等进一步提高特征提取和利用能力,这也是目前SAR图像舰船目标检测研究的主要方向之一。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
速读·下旬(2021年11期)2021-10-12
舰船科学技术(2021年12期)2021-03-29
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
中学生数理化·七年级数学人教版(2017年1期)2017-03-25
商情(2017年1期)2017-03-22
科技创新与应用(2016年9期)2016-05-14
光学仪器(2014年6期)2015-01-22
