
相邻帧光流约束的视频异常行为检测
2021-09-22 09:35:20张战成
苏州科技大学学报(自然科学版) 2021年3期
崔 捷,张战成,方 骞,殷 歆
(苏州科技大学 电子与信息工程学院,江苏 苏州215009)
异常行为检测是智能公共监控的重要任务,对于提高监控系统的智能性有明显的实际意义。该任务的难点在于异常事件的发生非常罕见且异常行为类别很多难以定义,环境因素影响下某些看似正常的行为也可以被认为是异常。由于没有很好的异常训练样本,异常数据量相比正常数据量极度不平衡,业界普遍采用无监督或半监督机器学习算法来处理。其中无监督算法不需要样本标注,因此数据预处理较为简单且非常适合样本缺乏的情况,其通常的思路是:由于正常样本是非常充足的,因此训练时可以让模型学习正常的行为模式,当测试时输入包含异常的样本,由于模型没见过异常数据,算法会产生明显区别于正常状态的输出。
深度学习在计算机视觉任务中取得了卓越的表现。自编码器可用于无监督的图像重构,Hasan等人[1]使用3D卷积自编码器(ConvAE)重建正常帧。Shi等人[2]考虑到长短记忆网络(LSTM,Long Short-Term Memory)适合处理时间序列数据而CNN能够提取视频外观信息,将长短记忆网络的CNN变种Convlstm[3]引入做为自编码器的层,取得了更高的精度提升。稀疏编码常被用于异常检测,这些方法假设视频中只有一个很小的部分包含异常事件,因此,可将视频用于构建正常事件的学习词典。Luo等人[4]提出ShanghaiTech无监督数据集并提出时序相干稀疏编码(TSC,Temporal Sparse Coding)对相似的相邻帧用相似的重建系数进行字典编码,同时用堆叠循环神经网络sRNN学习参数。以上方法都基于无监督重构,即假定异常帧有更大的重构误差,然而由于神经网络良好的泛化性能,有时即使是异常帧也会得到较好的重构,因此这类算法往往有一定的漏检率。Sultani等人[5]提出弱监督数据集UCF-Crime并将异常检测视为回归问题,基于多示例学习将多个视频帧视作一个多示例包并通过C3D[6]网络进行特征提取,之后以多示例排序作为损失的多层全连接网络预测多示例包中包含异常与否。这种方法精度很高,但是C3D[6]网络计算量太大导致了实时性能略显不足。肖进胜等人[7]使用Convlstm[3]和卷积-正则-激活的网络代替C3D[6]提取空间和时间特征,同时引入基于隐空间的包级注意力机制,在提升速度的同时又提高了精度。
光流是物体运动映射在成像平面上像素点运动的瞬时速度,它可以反映物体运动的真实变化。Liu等人[8]加入Flownet[9]网络的光流约束并提出一种基于GAN的历史帧预测未来帧的异常检测方法,该方法只使用正常帧训练。Sun等人[10]基于光流的亮度不变假设提出一种快速而鲁棒的光流引导特征(OFF,OpticalFlow Guided Feature)用于有监督的人员行为识别。Isola等人[11]基于条件GAN[12]提出图像转换模型pix2pix,该模型使用匹配的图像作为输入而不是随机噪声。尹一伊等人[13]基于GAN网络求解运动学方程。受Liu等人[8]、Sun等人[10]、Isola等人[11]研究的影响,基于无监督学习笔者提出了一种使用多个相邻的历史帧预测未来帧的网络模型。由于考虑到正常相邻视频帧之间的光流引导特征变化是微小的,文中搭建了一种双流生成器,并在其中设计了一种光流引导子网,它能学习到输入帧之间光流引导特征的稀疏变化,同时计算OFF的稀疏约束。实验结果表明,该约束的引入提高了视频异常行为检测的精度。
1 文中提出的网络结构
为了提升生成器帧生成的质量同时又能引导网络学习到时间特征信息。笔者设计了一个端到端的基于生成对抗网络的异常检测网络,流程图如图1所示。预处理程序从摄像头采样监控的连续t+1帧(t必须是大于2的偶数),其中奇数标号和偶数标号的帧分别做为上部和下部流的网络输入。生成器内部通过光流引导子网计算OFF的损失,生成器生成的帧记为I^t+1,它将与真实的帧It+1计算帧强度和边缘损失,最终的生成器输出帧在组合损失的作用下接近It+1使鉴别器难以区分。Patch鉴别器则区分生成器生成的帧和真实帧。
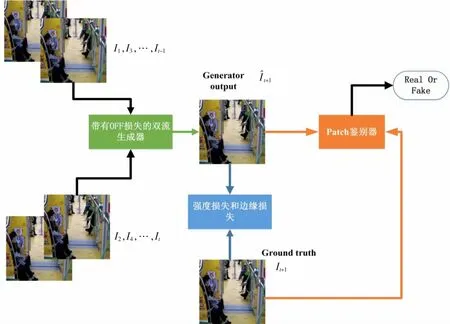
图1 异常行为检测网络流程图
1.1 双流生成器及其约束
现有工作中帧或是图片生成的网络大都基于两种结构:一是类似自编码器的编码解码结构,通过对称的编码-解码重建出原输入大小的图片,但这种结构的生成器随着网络层数的增加存在梯度消失和信息丢失的问题;二是将U-net[14]做为生成器,它拥有多种分辨率的跳连接层解决了自编码结构的弊端。文中基于引入相邻帧光流约束的原则构造了如图2所示的生成器。
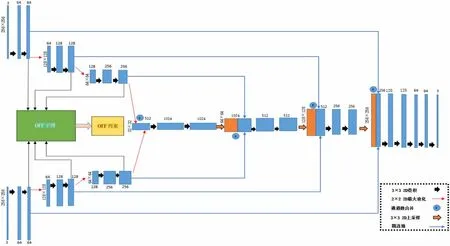
图2 带有OFF约束双流生成器
1.1.1 光流引导特征(OFF)约束和光流引导子网
光流法是通过相邻图像帧中像素点的运动对应情况来描述场景中物体运动的一种方法。光流法的优点就在于即使不了解场景的信息也可以准确地检测识别运动目标的区域。且在监控设备处于运动的情况下仍然适用,因此在深度网络中引入光流相关特征是提高运动物体检测精度的有效手段。
光流法中一个最重要的假设是亮度不变原理,即相邻的视频帧亮度不变,它可以用以下公式表示

其中I(x,y,t)代表t时刻视频帧,位置(x,y)处像素的亮度值;而与之对应的是下一个t+Δt时刻的视频帧位置(x+Δx,y+Δy)处像素的亮度值。其中Δx和Δy代表在x和y方向上的小位移距离。将这个公式从像素层面推广到图像特征层面,显然可以得到
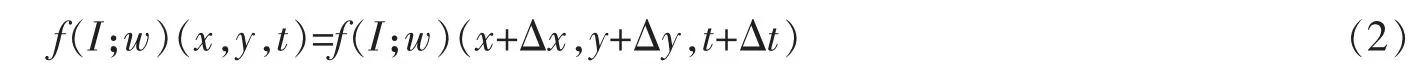
其中f(I;w)是任意的可微映射函数,I代表被f函数提取特征的图像,w代表可微函数f中的参数。f(I;w)也可以是一个包含卷积或是循环神经网络的深度网络。(x,y,t)表示为像素P点,则两边同时进行泰勒展开可以得到以下等式
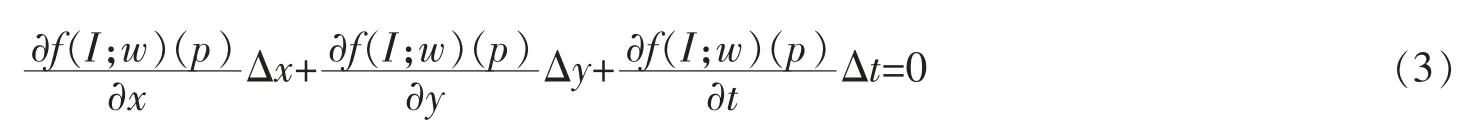
两边同时除以Δt可以得到
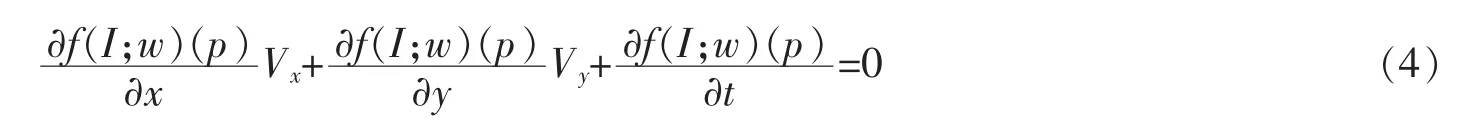
其中(Vx,Vy)表示特征像素点P的瞬时速度。∂f(I;w)(p)/∂x,∂f(I;w)(p)/∂y分别表示∂f(I;w)在点P处x和y方向上的空间梯度。∂f(I;w)(p)/∂t代表的是点P处沿着时间轴上的时间梯度。(Vx,Vy)所代表的就是特征级别的光流。从公式可以看出点P处的瞬时向量(Vx,Vy,1)所代表的特征级光流变化,始终与梯度向量[∂f(I;w)(p)/∂x,∂f(I;w)(p)/∂y,∂f(I;w)(p)/∂t]存在正交关系,该梯度向量随着特征级光流的变化而变化。该梯度向量称之为光流引导特征(OFF)。由于只使用正常帧进行训练,相邻时间段内的OFF变化应当稀疏。
光流引导子网则基于光流引导特征,并将这个特征的计算推广到深度网络结构,如图3所示,该网络抽取上下流各跳连接层特征作为输入,且不同分辨率级别的跳连接层特征对应相应的OFF单元。该单元使用1×1卷积分别提取t时刻及t+Δt时刻的特征,并将它们的特征通道数调整到128。水平及垂直方向的sobel卷积因子随即对t时刻特征提取水平及垂直方向的特征空间梯度,该空间梯度即为OFF的前两项。OFF单元的另一路将t+Δt时刻与t时刻的特征相减,由于Δt非常小,因此这步操作近似于对特征求时间梯度,这一路的输出即为OFF的第三项。第一个OFF单元的输出是128个OFF向量,该向量可用下面公式表示上个OFF单元输出经过Resnet20提取后的特征输入t时刻特征
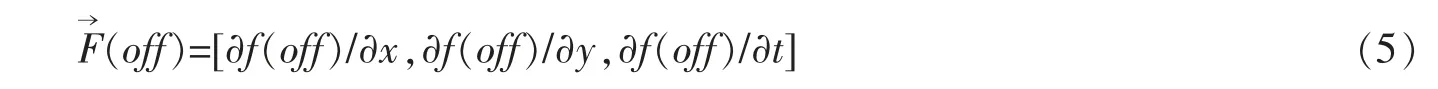
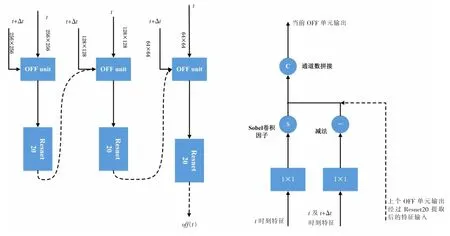
图3 OFF子网
每个OFF单元的输出通过Resnet20[15]提取并将该特征作为下一个分辨率OFF单元的信息输入,它将与下一分辨率OFF单元的输出信息进行通道数合并。OFF子网中最低分辨率的OFF单元输出将通过最后一个Resnet20[15]输出特征。这里的Resnet20[15]均是在Imagenet[16]预训练的,没有批归一化层且网络输出是最后一个残差Block单元的输出。子网最终的输出特征记为off(t),它与光流场正交,且反映了输入帧之间特征图随时间和空间的变化率。
用于预测未来帧的多个正常帧之间的OFF变化应该是稀疏的。将任意时刻的OFF约束损失定义如下

1.1.2 强度损失
强度损失保证了生成器生成的帧和真实帧在RGB空间内所有像素的相似性。在文中使用常用的L2范数损失函数来最小化生成帧和真实帧差值的平方和。该损失可以用以下公式表示

1.1.3 边缘损失
Sobel算子常用于图像的边缘检测,它可以锐化生成的图像,Sobel卷积因子分为水平方向和垂直方向的,它们可以计算图像水平方向和垂直方向的梯度,文中将水平方向设为x方向,垂直方向设为y方向,对应方向的Sobel卷积因子同时作用于生成器生成帧和真实帧,其描述公式如下
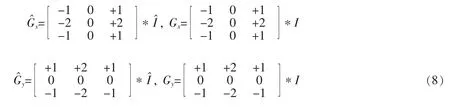
使得预测的图像更加清晰的策略就是直接对预测图像梯度进行约束,基于Liu等人[8]和Mathieu等人[17]之前工作的研究结论,文中将边缘损失定义如下

1.1.4 对抗训练损失
生成对抗网络中包含一个生成器和一个鉴别器,训练生成器的目的是生成鉴别器难以区分的图片,而训练鉴别器的目的是能够区分当前这一帧是来源于真实数据集还是生成器的输出。文中的双流生成器在训练中能够生成质量清晰的图片,为了能够区分出生成器的输出,文中使用了马尔科夫鉴别器(Patch discriminator),该鉴别器采用了全卷积的结构。所有Patch鉴别概率的均值为整个图片的预测输出。基于上面的原则,由I1,I2,…,It多个视频帧经过双流生成器预测的输出(未来帧)应被Patch鉴别器判别为0,而将来源于真实数据的It判别为1,0和1分别代表虚假和真实的概率。
文中引入了最小二乘GAN[18]的对抗损失函数,将均方误差引入,鉴别器的对抗损失如下生成器要
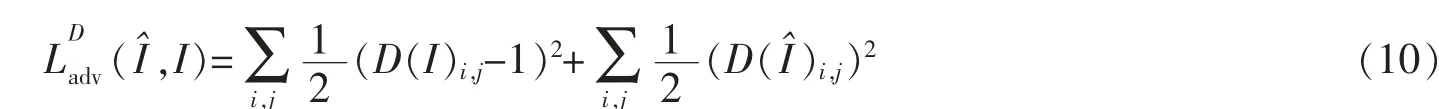
生成能够骗过鉴别器的图像,因此,生成器的对抗损失可以描述为

1.2 整体损失函数和训练方法
综上所述,文中的网络的整体优化目标函数可以描述为:
(1)生成器
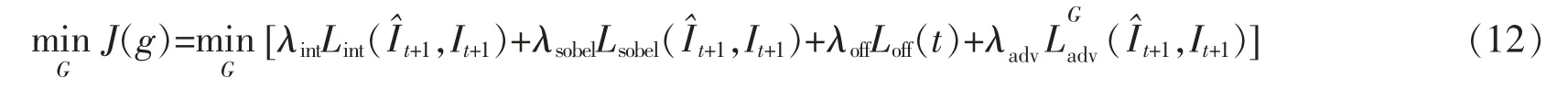
(2)判别器

生成对抗网络需要不断博弈才能达到纳什平衡。因此,训练时生成器和判别器的权重需要相互固定。文中网络的帧输入分辨率被调整为256×256,与Liu等人[8]采用的类似的方法,采样程序一次打包5帧。文中方法的区别在于前4帧分为上下各2帧作为双流生成器的输入,训练时将batch-size调整为4。当RGB的图像作为输入时,学习率被设置为从0.000 2开始;当灰度图像作为输入时,学习率被调整为0.000 1开始,相同于RGB输入时的动态衰减率。此外针对不同数据集,对λint,λsobel,λoff,λadv这几个超参数设置了不同的值,一种简单的设置方法是λint,λsobel,λoff,λadv分别设置为1.0,1.0,1.0和0.05。
1.3 网络的预测和异常行为检测
由于该网络只在拥有正常事件的训练集上进行训练,因此,网络无法对异常事件生成清晰的视频帧。在测试集上测试时,只有生成器参与到网络的预测,生成器生成的帧与真实的帧在RGB空间的像素接近程度可以成为对异常事件的判别标准。一种简单的方法是直接计算RGB像素值之间的欧式距离,但根据Liu等人[8]、Mathieu等人[17]的研究表明,峰值信噪比更适宜计算生成图片的质量,因此,文中采用峰值信噪比PSNR误差来判别异常。生成帧和真实帧之间的峰值信噪比PSNR误差可以用下面的公式计算,即
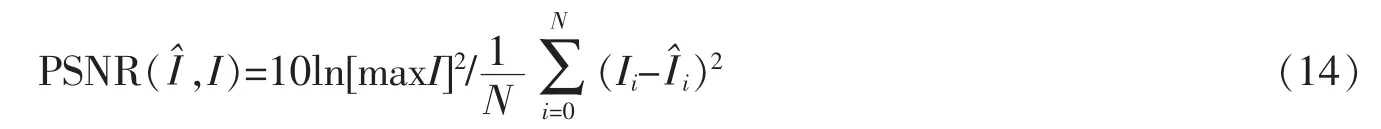
正常情况下PSNR的波动很小,当PSNR误差突然变化,则意味着这些视频帧里可能存在着异常。在计算完一个视频的PSNR误差后,将其值归一化为介于[0,1]的正常得分。它反映了视频帧的正常程度,可以用下面的公式表示

S(t)越接近0,则说明帧越异常,通过对S(t)设定相应的阈值,则可以定位出异常的帧具体发生的时间段。
2 实验过程与分析
2.1 数据集
2.1.1 公开数据集
为了评估异常检测准确性,文中的网络分别在3个公开的标准数据集上做了测试,这些数据集都有真实值文件来评估准确率。此外为了检验OFF约束在异常检测中的作用,笔者对比了网络增加OFF约束前后的准确性和误报率。
(1)CUHK Avenue数据集的场景设定在轨道交通的出口,该数据集包含16个训练视频和21个测试视频。训练视频均是正常的行人出入车站,而异常视频包含有人扔东西,突然奔跑等47种异常。
(2)Shanghaitech[4]是一个设定在校园监控场景内的多视角较高难度的数据集,该数据集包含330个正常的训练视频,测试视频则是有人在汽车马路上打架、玩滑板等130个异常事件。
(3)Ucf-crime[5]是一个同时包含正常以及异常的超大型弱监督数据集,它包含1 900个共128 h时段的视频。其中正常视频900段,其余均是包含盗窃、枪击、抢劫、斗殴等13种异常的视频。图4展示的是CUHK Avenue和Shanghaitech[4]测试数据中的正常和异常帧,图中显示的异常分别是有人在只允许步行的步行道上骑自行车、有人在地铁站出口处乱扔杂物。

图4 数据集中的正常和异常
2.1.2 实时监控
为了体现该网络的实际应用性,笔者还从实时监控中挑取了一些典型时段的画面作为测试,由于异常在监控中的发生十分罕见,因此,通过视频合成的方法,在正常的视频中插入有人打架、摔倒等异常事件的片段得到包含异常的测试监控视频。图5显示测试监控片段中有人在地铁站厅摔倒和在电梯打架的异常事件。

图5 监控中的异常事件
2.2 网络训练
训练及测试代码基于Tensorflow1.14的框架下编写。GPU使用NVIDIA GeForce GTX1080,代码在Linux 64位系统下运行,生成器和鉴别器训练均采用Adam[19]优化器,网络超参数的设置如1.2部分所述。训练迭代30 000次。为了降低噪声产生的干扰,对输入的训练图像数据做了归一化处理。
2.3 评估方法
2.3.1 算法的准确性AUC和错误率EER评估
ROC是一个用于度量分类中的非均衡性的工具,由于异常行为检测的正负样本存在不平衡性,正负样本的分布也可能随着时间而变化,而采用ROC曲线来检测可以保持不变性。ROC空间将假阳性率FPR定义为x轴,真阳性率TPR定义为y轴,因此曲线越接近坐标(0.0,1.0)说明准确率指标越好。文中的错误率EER定义为假阳性率数组中FPR+TPR-1的绝对值最小数为索引的值。
图6 显示了文中方法包含OFF约束前后的预测未来帧网络与其他三个异常行为检测算法:卷积自编码ConvAE[1]、ConvlstmAE[2]以及TSC_sRNN[4]在CUHK Avenue数据集上的准确性。根据测试加入OFF约束后网络准确率最高为84.3%,对比未加入OFF约束时准确率为82.3%,精度提高了2%。

图6 算法在CUHK Avenue上的准确率对比
以上测试的准确率和错误率见表1。

表1 CUHK Avenue上的准确率和错误率
表2 显示文中网络与目前主流的算法在3个公开测试数据集CUHK Avenue、Shanghaitech[4]、Ucf-crime[5]上的准确率。

表2 准确率对比
文中网络与目前主流算法使用相同的显卡,在同一个测试短视频下进行的速度比较,结果为:Ours(with OFF)(180 ms),TSC_sRNN(270 ms),ConvlstmAE(183 ms),ConvAE(238 ms)。
2.3.2 场景异常情况测试
文中的网络可以通过检测峰值信噪比PSNR的变化来实现异常事件发生区间段的定位,也可以通过归一化后的异常得分设定报警阈值。图7显示的是网络在典型视频上的检测情况。图7(a)是CUHK Avenue测试集中发生异常的视频,网络在某人突然在地铁出口处抛洒杂物,网络检测到PSNR的突然变化即发生异常。图7(b)显示的是一段实时监控中原本正常的电梯场景里有人突然开始打架并争吵,其PSNR误差归一化后为正常得分发生的变化。文中设定阈值为0.6,当低于0.6时视为发生异常。基本能够实现在现实场景中实现监控报警的功能。图7(c)显示的是生成器在正常和有人摔倒异常时产生的帧输出对比。可见摔倒异常事件明显产生了模糊的图像生成。
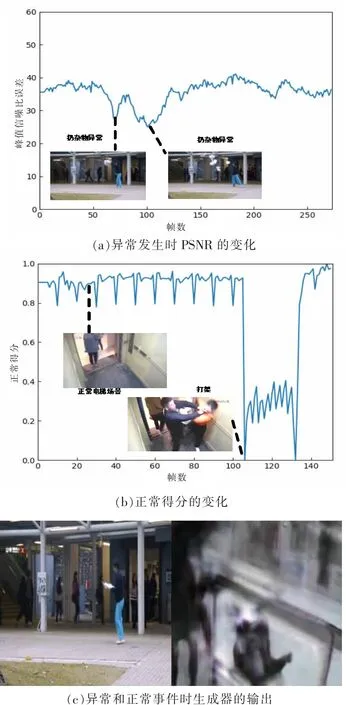
图7 网络在典型视频上的检测情况
3 结语
基于视频监控场景中正常事件光流变化平滑的假设,设计了一种相邻帧的光流约束子网络,在条件生成对抗网络中加入相邻帧的光流约束,提出一种基于未来帧预测的视频异常事件检测模型。训练后的生成网络对正常事件的视频可以清晰的生成,异常事件的视频帧由于不满足光流平滑变化的假设,生成的对应的视频帧会有较大的失真和模糊,以生成视频帧的归一化信噪比误差作为异常事件检测指标。在CUHK Avenue、Shanghaitech、Ucf-crime三个数据集上的实验检验了相邻帧光流约束的有效性,引入光流引导特征约束后的异常行为检测准确率优于传统卷积自编码器ConvAE、ConvlstmAE、稀疏编码TSC_sRNN等方法。
猜你喜欢
通信学报(2022年10期)2023-01-09 12:33:40
导航定位学报(2022年5期)2022-10-13 08:35:28
加油站服务指南(2021年4期)2021-07-21 02:29:22
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
国防科技大学学报(2019年4期)2019-07-29 03:40:14
电光与控制(2018年10期)2018-10-13 08:19:00
系统工程与电子技术(2016年5期)2016-11-02 00:37:48
人生十六七(2015年6期)2015-02-28 13:08:38
中国铁道科学(2014年6期)2014-06-21 06:35:32
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
