机器学习辅助高熵合金设计的研究进展
2021-09-18 08:21赵鼎祺乔珺威吴玉程
中国材料进展 2021年7期
赵鼎祺,乔珺威,吴玉程
(太原理工大学材料科学与工程学院,山西 太原 030024)
1 前 言
机器学习的目的是挖掘大数据背后隐藏的价值,某种程度上可以看成是一种经验式地对实验结果的抽象概括。还有的人认为机器学习是一种唯象理论(唯象理论是对实验现象的总结与凝练,其先于理论架构,又被称为前科学)。有关唯象理论的一个著名的例子便是牛顿的万有引力定律:开普勒利用天文学家第古积累下的资料,通过仔细的分析研究,从庞大的数据中抽象出了模型并提出了著名的开普勒定律,被人称为天空的立法者;而牛顿又在此基础上更进一步提出了牛顿定律,建立了经典力学体系。然而,在牛顿的万有引力背后同样有着更深层次的概念:相对论与量子力学。相对于更深层次的概念来说,现有的概念都可以看成是唯象理论。在信息时代,数据极度丰富,建立在大数据基础上的机器学习,必将迎来爆发式的发展。
高熵合金又名多组分合金,自提出以来便备受关注。传统的合金设计多以一种元素为主,而高熵合金最初的设计理念则是试图将多种元素同时视为主要元素,用构型熵抑制金属间化合物相的形成。随着高熵合金的发展,设计理念逐渐从第一代高熵合金发展到第二代高熵合金,越来越多的探索从寻找单相固溶体转移到对高熵合金微观结构的调控。毋庸置疑的是,在多组分合金设计理念的指导下不仅诞生出了许多性能卓越的合金成分,更进一步激发了人们对合金设计的全新思考。这种设计理念在扩展合金成分设计空间的同时也给我们带来了更大的挑战。传统的实验试错法在面对如此巨大的可探索空间时明显缺乏效率。因此,合理的高熵合金探索策略便显得尤为重要。常见的一些模拟计算方法,比如从头算和基于热力学数据库的方法可以提高科研工作者的探索效率,但与传统合金相比,高熵合金中元素的数量以及微观结构的多样性使计算的复杂性与密集程度大幅增加。近年来,材料科学相关的计算活动已经由纯粹地对材料的计算研究转移到结合计算结果和大数据来指导新材料的设计上来。机器学习是以数据为中心的方法中最活跃的生产工具,正在与高熵合金的探索设计相结合,这种学科交叉展现出了巨大的潜力。
2 材料科学中的机器学习简述
前两次工业革命将人类从繁琐的体力劳动中解放出来,进一步我们希望解放脑力,机器学习便源于对人工智能的追求。人工智能经历了多次繁荣与衰落,在20世纪80年代有三大学派:符号学派、连接学派、行为学派。最初人们认为人工智能源于数理逻辑,希望机器可以通过使用各种模式或符号来模拟人类的智能活动[1],紧接着受大自然的启发,人们进一步研究了基于连接原理的方法,例如神经元网络[2]和感知器[3]。几种建立在严谨的统计学理论上的方法也被发扬光大,例如支持向量机[4]和决策树[5]。还有学者将目光聚焦到了低等动物的快速反应能力上,致力于有关控制论的研究。人工智能在经历了一系列的曲折发展后,沉寂多年的连接学派东山再起,大数据结合基于神经元网络的深度学习成为现在最热门的人工智能解决方案,并引发了一场逐步向各个领域渗透的革命,这一革新同样引起了材料学界的关注。打败围棋高手李世石的Alphago就是一个基于神经元网络的深度学习案例。机器学习横跨计算机科学、工程技术、统计学等多个学科,作为一个强有力的工具应用于从生物学到社会学等多个学科。凡是产生数据的学科都可以应用机器学习。
同高熵合金概念一样,蓬勃发展的学科会不断扩展初始概念的含义,因此历史上对机器学习定义的解释都有片面性。在这里将采用汤姆米切尔的观点来解释机器学习:机器学习的本质是对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们就称这个计算机程序在从经验E中学习。机器学习可以看成是对数据的挖掘过程,通过分析数据彰显数据背后的价值,在材料科学中常见的用途是分类、回归、聚类、密度估计、降维等。
如图1所示,构建机器学习系统分为3个步骤:样本构建、模型构建和模型评估。样本构建包括数据预处理和特征工程两个部分,其中数据预处理是指将原始数据转换为样本以及进一步的数据清理。数据清理将识别不完整、不正确和不相关的数据,然后替换、修改或删除这些数据。特征工程包括特征提取、特征选择、特征构建和特征学习,是通过领域内的专家知识来创建特征的过程。特征工程是机器学习中至关重要的一环,有种说法是,特征工程决定机器学习的上限,而算法则是不断逼近这一上限。在样本构建的过程中还可以采用探索性数据分析的方法,获得对数据的初步了解,提前对数据进行透视、分组、过滤。数据质量将对最终模型产生非常重要的影响,通常来讲,数据处理将花费整个建模过程的绝大部分时间。模型构建包括制定具体的机器学习算法和模型优化算法等,需要根据实际情况来决定使用哪种算法,没有免费午餐(no free lunch, NFL)理论告诉我们任何算法的预期都是相似的[6],而且没有任何算法可以通用于所有领域。对于材料科学的典型研究而言,条件因素与目标属性之间通常存在复杂的关系,而传统方法难以处理。我们不仅希望模型能在现有的数据集上取得很好的效果,还希望在未知的数据集上同样能保留很好的泛化能力,因此我们需要对模型进行评估。过拟合与欠拟合都是训练模型中经常遇到的两种问题,需要根据具体问题采取不同措施。误差、时间与空间复杂度、稳定性、迁移性等也是模型评估的重要因素。
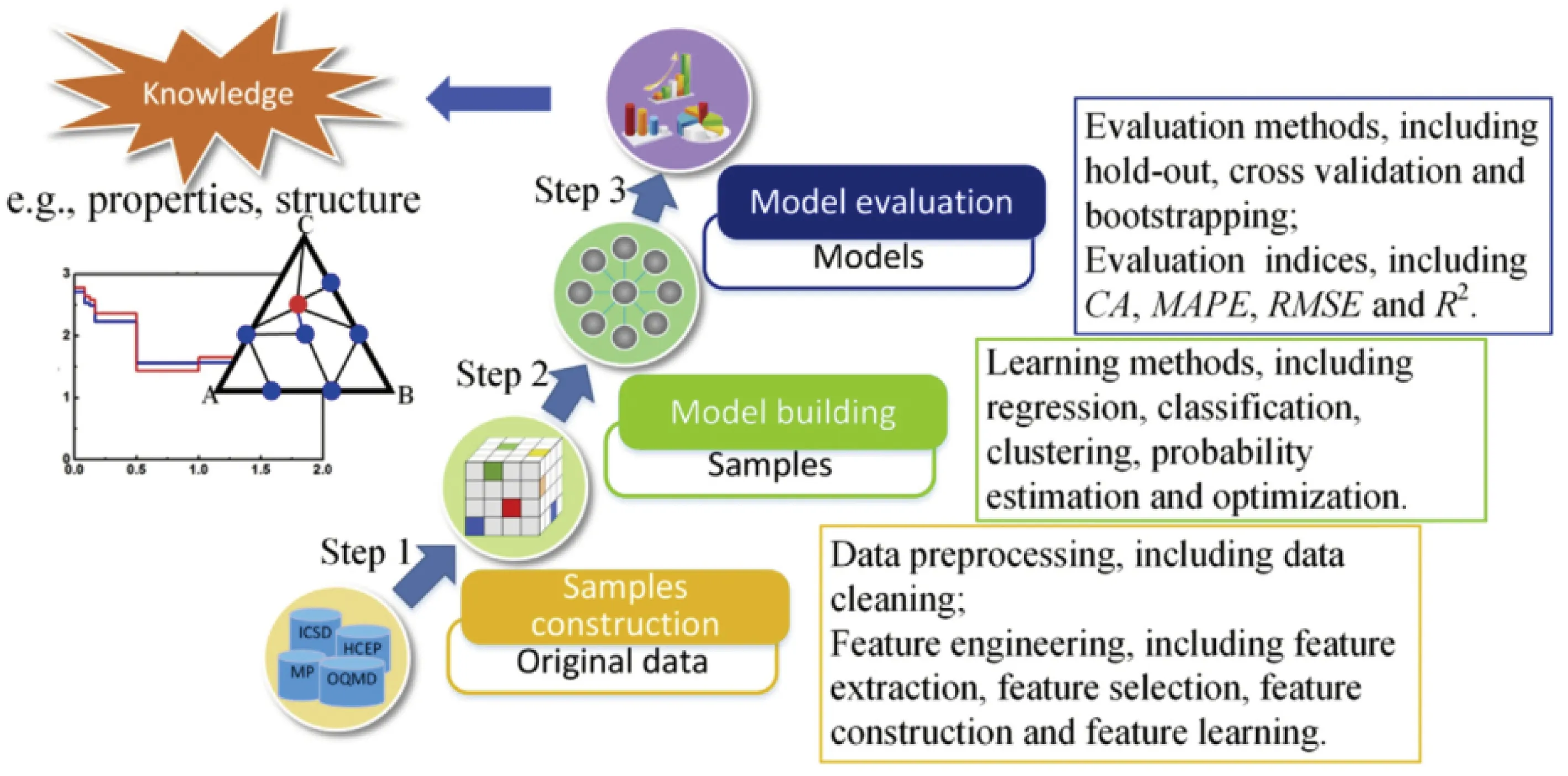
图1 机器学习步骤[7]Fig.1 Machine learning steps[7]
如图2所示,机器学习在材料发现和设计中的应用可以分为3大类:材料属性预测、新材料发现以及各种其他用途。在关于材料属性预测的研究中,通常使用回归分析的方法预测宏观和微观特性。在新材料发现时使用概率模型来筛选结构和成分的各种组合,还可以配合从头算等方法对材料进行预测。此外,机器学习还可用于材料科学中的其他方面,例如制造过程中参数的优化[8]。机器学习已经广泛应用于材料学领域的各个方面[9-19],包括成分设计、材料制备工艺以及对机理研究等等。
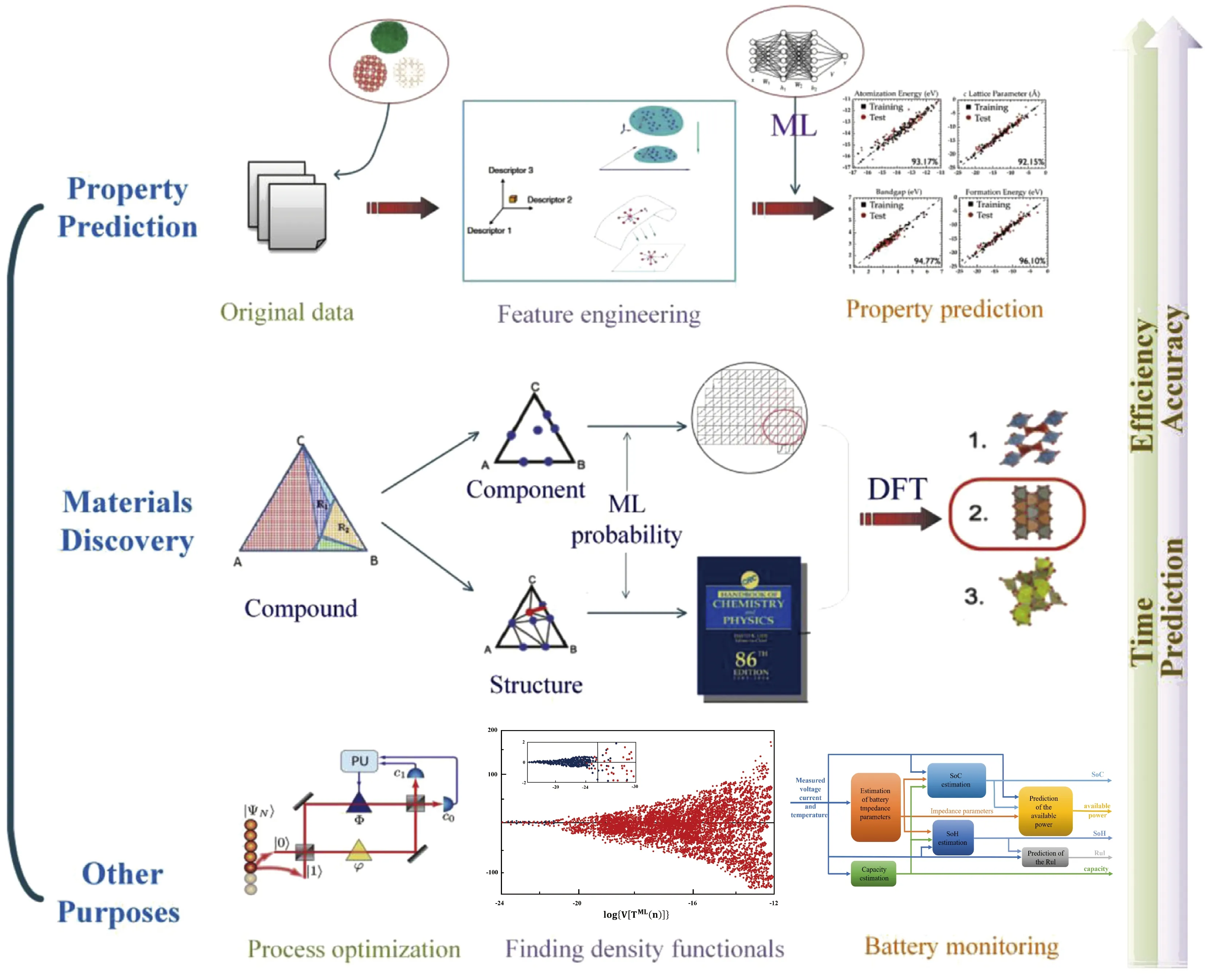
图2 材料科学中的机器学习[7]Fig.2 Machine learning in materials science[7]
机器学习属于一种以数据为中心的方法,它可以从大量数据中挖掘价值。人们很早便注意到了这一方法的重要性,在材料相关学科中同样建立了大量的数据库。材料基因组计划便是一个很好的例子,通过结合高通量实验[10, 20, 21],利用高通量计算开发大规模数据库,然后从众多的材料数据中提取价值,预测新材料的性质并指导下一步实验。这种方法将助力于新材料的发现。
3 高熵合金简述
传统的合金大多以一种成分为主,比如镁合金、铝合金、镍基合金等,通过添加少量的其他元素来获得良好的性能。而高熵合金[22, 23]是21世纪初引入的一种新的合金设计理念,在这种理念中,元素以等原子比或近等原子比混合,试图最大化构型熵。在高熵合金概念提出之前,人们往往认为这些由多主元元素组成的合金中会形成大量金属间化合物相或其他复杂相[24]。与预期相反的是,研究发现很多高熵合金仍然是单相的固溶体结构,主要是面心立方(FCC)、体心立方(BCC)或两者的混合物。这种结构使高熵合金具有优良的性能,包括低温韧性、高温下的强度和热稳定性、良好的耐腐蚀和耐磨性以及在极端条件下良好的服役性能[25-28]。
图3为传统合金与高熵合金的晶胞结构对比图[29]。多主元合金的设计理念使得科研人员对金属材料的选择从相图的边角区域转移到了相图的中心区域,同时这种理念提供了更庞大的成分选择空间,五元高熵合金便将可选择方案数量扩大到了原先的近百倍。在研究高熵合金的早期阶段,有学者提出高熵合金中有四大效应:高熵效应、迟滞扩散效应、晶格畸变效应、鸡尾酒效应。随着后来的进一步实验,认为这些效应的重要性可能并没有当初所想的那么大。熵效应的效果被明显夸大了[30-33],很多对高熵合金中相稳定性的研究结论并不支持高熵效应的观点,很多高熵合金在中间温度退火会分解成多个纯金属和金属间化合物[34],这种相分解一定程度上影响着高熵合金在高温中的应用。同样,也没有足够的证据能说明高熵合金与传统的钢铁材料相比有很大的晶格畸变。在许多高熵合金中同样能观察到快速的相析出,因此迟滞效应也受到一定的挑战。而鸡尾酒效应并不属于效应,只是一个描述的角度。因此,对高熵合金的命名也产生了新的争论。然而对金属研究领域来说,这是一个令人振奋的机会。合金组成成分的复杂性意味着存在发现更多不同寻常性能的机会。对复杂成分合金行为的理解有助于提高对金属领域基础科学的认识。因此,高熵合金是目前材料科学中最具启发性和前景的研究领域之一。

图3 传统合金(a)与高熵合金(b)的晶胞结构[29]Fig.3 Lattice structures of conventional alloy (a) and high entropy alloy (b)[29]
高熵合金的命名来源于玻尔兹曼的公式,熵是系统内无序性的一种度量。整个宇宙的一切事物都将从有序转变为无序,这也叫做熵增定律。熵的概念经过克劳修斯、玻尔兹曼、吉布斯、香农等人的深入研究,应用领域从热力学扩展到了信息学。如果将原子点阵看成是钢球模型,并假设微观状态等概率分布,那么它们倾向于形成宏观状态的高斯分布。
当组成金属的原子形成无序排列的时候,系统的构型熵最大,与之相对应的合金相称为固溶体相。而金属间化合物相属于长程有序状态,高熵效应会抑制这种有序状态。最初人们对高熵合金的研究热衷于对单相固溶体的寻找,随着研究的进展,注意力转移到了微观结构设计。现在对高熵合金的研究仍然属于起步阶段,很多研究都是将对钢铁材料和镍基合金的设计思路延续到了高熵合金中,比如孪晶诱导塑性和相变诱导塑性等。对高熵合金中很多微观机理的探究仍待深入,复杂的成分理论上可以提供更广阔的微观机制调节空间。比如,同镍基合金相比,高熵合金中的固溶体要更为复杂。最开始的研究认为固溶体既可以提升强度又能保留很大塑性,后来发现,只要能对微观组织进行很好的调控,即使是两种金属间化合物相也能具备很好的性能[35],金属间化合物相也并非总会使合金脆化。复杂的成分和更多的微观结构可能性依旧是未来对高熵合金最具吸引力的研究动机。
4 高熵合金设计中的机器学习
随着高熵合金的发展,越来越多的成分被开发出来。高通量溅射沉积实验是目前常用的高通量的合金制备方案,如图4[36]所示,这种方法可以将材料从作为源的“靶”喷射到基板上,控制工艺参数,可以在基板上形成所需的物质。控制工艺参数可以对薄膜的生长结果和微观组织进行精确调控。这种方法很适合高熵合金薄膜的制备,通过工艺参数的调控可以对薄膜选定区域的元素分布实现梯度变化。通过不同元素分布的梯度变化可以实现合金成分的连续变化,实现材料的高通量制备,研究成分变化对合金性能的影响。

图4 高通量溅射沉积实验示意图[36]Fig.4 Schematic of high flux sputtering deposition experiment[36]
这些新兴的方法可以很大程度上提高新合金成分的开发速度。随着合金成分探索加快和合金数据库的不断增大[12, 13, 37, 38],材料科研人员需要一种能够帮助他们快速评估、分析这些大数据的方法。而机器学习无疑可以与高熵合金探索策略相辅相成[39, 40]。
4.1 机器学习同传统方法相比较
高熵合金概念自提出以来便伴随着对相形成规律的讨论[41],相在高熵合金设计中一直起着关键作用[42-45]。在高熵合金的设计策略中,对未知合金成分相的组成以及相稳定程度的预测是一个很重要的设计角度。很多高通量的探索策略取得了不错的效果,一种是基于从头算[46, 47]的方法,比如Yoav等[48]利用从头算的方法,通过判断固溶体的形成能力来预测合金成分的有序无序转变。Troparevsky等[49]利用从头算计算二元合金子系统的形成焓,并通过这些焓来估计多组分系统的稳定程度。另一种是基于相图计算(CALculation of PHAse Diagram,CALPHAD)方法[50, 51],比如Senkov等[33]利用高通量的CALPHD方法预测合金可能存在的相,快速评估了130 000余组合金成分。Abu-Odeh等[52]利用约束满足算法缩小遍历空间,再利用CALPHAD对所得的结果加以验证。
上述两种通过计算机对新材料进行评估和筛选的方法无疑可以将材料科研人员从繁琐的实验中解放出来,但这两种方法有很大的局限性:准确性极度依赖于数据库以及模拟的精确程度,并且无法与实验结果建立直接关系。每次计算与模拟都是单独的,无法从前面的计算中获得经验。这与以数据为中心的方法不同,以数据为中心的方法并不是独立的,它可以与面向材料的计算相结合。Curtarolo等[53]使用主成分分析与从头算相结合,根据晶体结构的能量与化学系统之间的相关性预测材料的结构并取得了很好的效果。Kim等[54]结合原位中子衍射、第一性原理计算和机器学习研究了Al0.3CoCrFeNi高熵合金的弹性性质、弹性模量和各向异性,使用梯度提升树在数据库中6826个有序无机化合物上进行训练,预测了体积模量和剪切模量的平均值。他们构建的梯度提升树模型使用了结构特征和组合特征:每种化合物的性质,如密度和原子的结合能被表示为结构特征;对与元素有关但与化合物无关的属性进行加权组合(如原子半径和基团数)生成组合特征;对每种化合物均生成67个特征。并使用多目标优化遗传算法生成优化模型对特征进行筛选。与传统的第一性原理计算相比,机器学习的速度要快很多。
4.2 统计学方法
高熵合金领域很早便开始从数据的角度出发解决问题,比如利用启发式方法提出一些简单的物化判据来预测高熵合金或非晶中的相形成规律[41, 44, 55-63]。奥卡姆剃刀原理并非放之四海皆准,传统的简单线性组合方法已经无法满足预测需求。早在2013年,Nong等[64]利用固溶体物理参数:原子尺寸差、混合焓、电负性差和价电子浓度,研究了铸态高熵合金立方相的稳定性并作出预测。但该研究中采用的数据集太小,缺乏统计学意义。以数据为中心的方法中,数据库的大小与质量是相当重要的。Tancret等[65]采用统计学方法,提出了一个基于热力学与高斯过程的统计模型,该模型使用9个参数识别单一固溶体相,文章还评价了不同的热力学数据库。然而高熵合金的热力学数据库很大程度上继承于镍基合金的数据库,多组元的数据库仍需进一步完善。
Domínguez等[66]首次对高熵合金数据集进行了主成分分析,并在此基础上对一系列合金做出了预测。作者从原始数据中提取有用信息,再将信息用于预测。文章所用数据集比较小,只有79个。其中主成分分析属于降维算法,目的是将高维度的数据降低维度,进而保留最重要的特征,去除噪声和不重要的特征。这种方法可以使数据集更易使用,降低计算开销,使结果易于理解。但需要强调的是,该方法会使初始维度的原始特征消失,重组后的特征会发生根本变化。类似的降维方法还有奇异值分解、因子分析和独立成分分析。
4.3 人工神经元神经元网络与其他方法
Islam等[67]使用机器学习对高熵合金数据集做出了相应的分类。该研究选取了5个特征,数据提高到了118个。对原始数据集进行了过拟合训练,准确度达到99%。不经评价的预测模型缺乏意义,算法会学习大量的噪声,缺乏泛化能力。随后的多折训练中准确率只有86%。多折训练是一种常用的方法,可以减少小数据集中训练集的选取对最终结果造成的误差。举例来说,将一个数据集分为4份,其中一份为测试集,其它3份为训练集;这样重复4次,让每个数据集都成为一次测试集,最后对4次的评价结果求均值。在选取特征时,文章计算了5个特征之间的皮尔森系数。皮尔森系数是用来描述两个特征之间相关性的变量,当两个特征的皮尔森系数的绝对值越接近1时,他们的线性相关程度也就越高。需要注意的是,皮尔森系数对高维中变量的描述效果比较差,不能描述3个特征之间的关系,只能用于特征的初步筛选。图5为利用皮尔森系数分析5个不同特征的结果,右上角的数字为皮尔森系数的大小,皮尔森系数的绝对值作为线性相关系数描述了不同特征值的线性相关程度。皮尔森系数分析法可以作为数据预处理和数据探索性分析的一种方法。当不同特征值相关性过大时说明两个特征蕴含的信息相似,在预处理中需要对这一特征做处理或者删除这一特征。从图中看出最高的皮尔森系数为0.73,说明晶格畸变与电负性差是特征值中最相似的两个特征值。不必要的数据关联会增加模型的复杂程度,引入噪音,造成过拟合,这时候减少相似的特征可以降低过拟合程度。当然,也可以在算法中采取不同方法降低过拟合,比如正则项、惩罚函数、神经元网络中的Dropout方法等。

图5 采用皮尔森系数分析特征的结果[67]Fig.5 Characteristics analysis results by Pearson coefficient[67]
Huang[68]使用机器学习算法对一个包含401个合金成分的数据库进行聚类和预测。文章中采用了3种不同的机器学习算法:K近邻、支持向量机和人工神经元网络。他们采用的数据库基于Miracle的一篇综述[29],数据库的质和量提高了很多。该数据库将合金分为3类:固溶体、金属间化合物以及二者的混合。相较于对晶格结构的分类,这种关于高熵合金微观结构的长程有序程度的分类难度更大。文章三分类的最高准确率只有74%。他们还评估了5个输入特征在影响测试精度方面的相对重要性。采用人工神经元网络中的自聚类算法对特征进行评价,自聚类算法可以看成是非线性的主成分分析,对高维变量的描述效果更好,而且易于可视化。自聚类是无监督机器学习的一种,聚类会将数据集划分成几个不同的子集,分类之前算法本身并不了解分类样本的标记信息。这种算法能用于寻找数据内在的分布结构。比较常见的自聚类算法还有K均值聚类、均值漂移聚类、基于密度的聚类、高斯模型的最大期望聚类、凝聚层次聚类等。文章对人工神经元网络的超参数做了详细的调试,与支持向量机和K近邻算法相比准确度更高。图6为人工神经元网络中的自组织算法原理,可以通过分析输入空间中的数据来生成一个低维、离散的映射网络。应用竞争性学习(具有梯度下降的反向传播)而非纠错,并且通过创建类似于多维缩放的高维数据的低维视图的方法,用邻域函数来保留输入空间原有的拓扑属性。受启发于生物神经元特性,自组织学习通过使网络不同部分对不同输入模式做出相应的响应来模拟生物的大脑皮层,比如香味会引起大脑皮层特定区域的兴奋。首先将训练数据输入到网络,然后计算它们所有权重向量的欧几里得距离。通过竞争得出最佳匹配单元,然后将所有权重进行迭代产生新的权重。在迭代过程中,相似的神经元会沿相同的方向移动,并激活相邻的神经元。
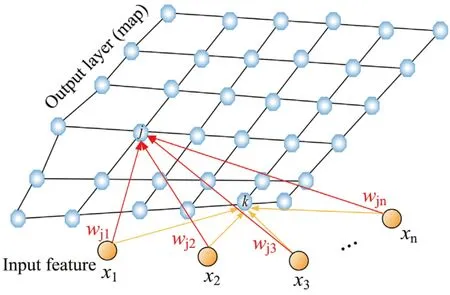
图6 人工神经元网络中的自组织算法原理[68]Fig.6 The principle of self-organizing algorithm in artificial neural network[68]
Li等[69]用同样的数据库,选出322个铸态合金的成分,使用支持向量机将数据集分为3类:43个面心立方,18个体心立方,以及261个NSP相(包括多相、金属间化合物、非晶)。这样的数据分类很不平衡,文章也相应地采取了一些手段,比如利用算法扩增原始数据集,但仍然会导致预测区间严重缩小。最终交叉验证的精确度可达90%,而且通过训练好的算法预测了一些合金成分。预测的很多都是难熔高熵合金,常见的难熔高熵合金绝大多数为BCC结构。同时应当说明的是,文章利用密度泛函理论对预测结果做出了检验,但密度泛函预测的结果是热力学平衡态的高熵合金,这种验证缺乏说服力。Abhishek等[70]将人工智能的自适应神经模糊接口系统应用于高熵合金的相预测。自适应神经模糊接口是利用人工神经元网络和模糊逻辑构造的混合智能系统。图7为他们设计的混合系统算法框架,改变模糊逻辑可以改变知识获取的方式,通过神经元网络的学习能力来优化模糊规则。图7描述了一个具有2个输入和1个输出的系统:输入为m和n,输出为f。自适应神经模糊推理系统模型由一组称为模糊if-then规则的灵活规则控制,其中输入根据其行为映射到一系列输出(也称为隶属函数)。隶属函数是定义如何在输出中为每个输入参数指定隶属度的曲线或函数。隶属度的范围从0到1,隶属度0表示输入不是模糊集的一个成员,0.5表示部分隶属,1表示完全隶属。对于一个有2个输入的模型,每个输入映射到2个隶属函数。第1层被称为模糊层或输入层,因为输入使用隶属函数被映射到模糊范围。第2层被称为产品层,标记为P,它从模糊层计算各个参数,这个层有时也被称为输入成员功能层。第3层被称为模糊规则层或规范化层,标记为N,通过将第2层的输出函数和第2层的所有输出函数之和来执行函数权重的规范化。第4层被称为解模糊层或输出隶属函数层,它将值解模糊以给出清晰的输出。第5层是总输出层,标记为R,输出从先前层获得的所有单个参数之和。

图7 模糊逻辑系统结合人工神经元网络Fig.7 Artificial neural network combined with fuzzy logic system
神经元网络是一种利用简单的数学模型模拟生物大脑功能进行决策的非线性算法,而模糊逻辑是一种捕捉系统中随机性和模糊性的数学方法,二者相互结合可以使系统本身朝着自适应、自组织、自学习的方向发展。
Pei等[71]基于包含1252个多组分合金的大数据集,利用算法识别固溶体及它们的晶格结构。数据库不仅包含高熵合金,还包含二元、三元合金。文章中没有给出对数据库的进一步说明,将高熵合金与传统合金放入同一个数据集会模糊复杂固溶体特有的机制。文章利用高斯径向基函数对数据进行分析和预测,预测准确度可达93%。他们希望用机器学习找出新的关于相形成的统一判据,新的预测量有一定的统计学意义,但还需要在物理背景上进一步说明。Zhou等[72]利用人工神经元网络、卷积网络、支持向量机对基于601个高熵合金成分的数据库做出分类,将合金分为3类:固溶体、金属间化合物和非晶相。与文中Huang等的工作[68]相比,分类难度小很多。文章加入了一些实验来验证预测结果,大数据结合高通量实验将会是以后高熵合金开发的重要方向。Zhang等[73]利用遗传算法对高熵合金进行了设计,落脚点同样是相形成问题。文章中加入了主动学习方案,用机器学习指导实验后,再利用新得到的实验数据对算法进行迭代。相较于之前利用密度泛函或热力学数据库来检验算法的预测结果的方案更为合理。因为数据库中的大部分高熵合金都属于热力学非平衡状态,而且传统方案预测的准确率也不能保证,实验才是检验真理的唯一标准,实验与算法的结合可以让两者相得益彰。
Cheng等[74]通过机器学习与实验相结合,经过两轮迭代在Al-Co-Cr-Cu-Fe-Ni体系中寻找到了更高硬度的高熵合金成分。数据库包含155个体系中的硬度数据,其中包括22个四元合金、95个五元合金和38个六元合金。由于实验数据可能来自不同的实验室,而且硬度数据很可能存在一定波动,同时数据库的样本量比较少,高硬度的数据会对算法的预测结果有锚定效应。文章中特征选取基于统计学意义,可以进一步对特征背后的物理机制进行讨论。Qi等[75]提出了一种从二元相图中提取特征并与机器学习相结合对高熵合金相进行预测的方法。数据库来自679个铸态或退火态的高熵合金的成分。作者利用相形成温度定义与元素有关的相参数和相分离参数,将它们作为特征,并大规模提取二元相图的信息建立数据库。该算法在预测中取得了不错的效果。作者在特征工程建立上别出心裁,将相图转变为一系列的参数描述,类似于SISO[68]方法。其中特征构建很大程度上决定了最终的预测结果,但文章中特征建立过程基于一定的假设,相图信息不可避免地有一定损失。同密度泛函中的交换关联函数一样,在机器学习中同样存在妥协,比如欠拟合与过拟合,以及效率与精确性,还需要在可解释性与统计学意义上做妥协。特征的建立同样是一个妥协的过程,这是一个需要材料科研人员发挥智慧与创造力的领域。
5 结 语
目前高熵合金中的机器学习主要集中在对相的预测方面,一方面是因为相可以很大程度上决定高熵合金的性能,另一方面是先前已经有很多工作在物理判据或者说特征工程上做出了很大贡献。机器学习不仅可以挖掘原有数据的价值,更能指导实验,缩短实验周期。高通量的实验与计算将会是未来发展的重要方向。机器学习不同于传统方法对方程求精确解,对设备与软件的需求大大降低,可以将训练好的模型搭建在网站上。此外,这种以数据为驱动的方法还可以从失败的案例中挖掘价值。随着数据量的增多,机器学习的精确性可以大幅提高。目前应用于高熵合金领域的算法仍很基础,不应该为了追求噱头,盲目引入不合适的算法;也不能只关注相关性而不去关注因果性,片面地追求高的预测准确率。就目前的高熵合金数据库而言,大部分的数据都取自文献,使数据被幸存者偏差影响。同时,高熵合金成分开发很多都围绕着仅限几种成分展开,同样会对数据有锚定效应。建立联合数据库是一个很好的解决办法。
随着数据库质量的提高,未来高熵合金中的机器学习会向深度学习发展。用领域内的知识发现和创造特征将成为交叉领域中最重要、最有创造力的一环。同时,在利用机器学习挖掘大数据价值的同时,应该注重背后的物理背景,像艾萨克牛顿一样,从唯象理论中再进一步。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
粉末冶金技术(2021年3期)2021-07-28
河北工业大学学报(2020年6期)2020-01-16
电影(2018年8期)2018-09-21
中国有色金属学报(2018年2期)2018-03-26
电子科技(2016年6期)2016-07-04
动力学与控制学报(2016年6期)2016-05-19
焊接(2016年8期)2016-02-27
表面工程与再制造(2014年2期)2014-02-27