
基于双向门控尺度特征融合的遥感场景分类
2021-09-18 06:22宋中山梁家锐刘振宇
计算机应用 2021年9期
宋中山,梁家锐,郑 禄*,刘振宇,帖 军
(1.中南民族大学计算机科学学院,武汉 430074;2.湖北省制造企业智能管理工程技术研究中心(中南民族大学),武汉 430074;3.中南民族大学资源与环境学院,武汉 430074)
(*通信作者电子邮箱lu2008@mail.scuec.edu.cn)
0 引言
遥感场景分类是航空和卫星图像分析领域的一个活跃的研究课题,它根据图像内容将场景图像划分为不同的类别。由于遥感图像场景的地物类型较为复杂,因此对其精确分类是一项艰巨的任务[1-2]。
遥感场景分类的早期研究主要是基于手工制作的特征,利用手工提取后的特征对其进行分类。如Swain 等[3]提出的颜色直方图和Lowe[4]提出的尺度不变特征变换(Scale Invariant Feature Transform,SIFT)等分别利用了图像的颜色特征以及形状特征。为了弥补手工制作特征的局限性,通过从图像中学习特征而不是依靠手动设计的特征,如Hotelling[5]提出了主成分分析(Principal Component Analysis,PCA),Olshausen 等[6]提出了K-均值聚类、稀疏编码方法,能在降低手工设计特征成本的同时更精准地对图像进行分类。而在深度卷积神经网络上,从Hinton 等[7]在深度特征学习方面取得了突破,以及Krizhecsky 等[8]提出的AlexNet的巨大成功开始,研究工作相继在卷积神经网络(Convolution Neural Network,CNN)模型上有进一步的发展,如Simonyan 等[9]提 出 的VGGNet,Szegedy 等[10]提出的GoogleNet。在优化深层次神经网络提高可训练以及训练的速度上,He等[11]提出了ResNet残差网络和Cheng 等[12]提出了DenseNet,解决了深层网络训练难和训练慢的问题。近来研究已经开始利用这些功能强大的CNN 来对遥感场景进行分类。如Liang[13]采用转移学习的方法来微调现有的CNN 用于遥感场景分类;王鑫等[14]利用CNN结合多核学习的方法进行分类;赵春晖等[15]采用视觉词袋结合CNN 的方法进行分类;Wang 等[16]利用预训练的ResNet 的完全连接层来提取遥感场景表示;陈雅琼等[17]等利用微调的AlexNet模型对遥感场景图像进行分类,其结果表明利用深度学习的方法优于传统遥感场景分类方法。但是,在直接利用CNN 最后一层进行分类的方法中会忽略来自CNN 不同层次层的功能。而受到RestNet 以及DenseNet 等多层卷积特征的互补性启发,研究工作开始利用不同层的特征组合进行分类。同时,许多研究[18]也证明了顶部卷积层可以有效地捕获语义特征,而底部卷积层可以提取外观特征,为此也有一部分工作通过聚合不同的卷积层特征互补的方式来提高分类的精度。如Wang 等[19]提出了一种递归注意网络结构来捕获遥感场景关键区域的特征;Sun 等[20]提出了一种端到端的门控双向网络(Gated Bidirectional Network,GBNet),以在统一的卷积网络中进行分层特征聚合和干扰信息消除。
文献[20]提出的方法局限于网络中的卷积特征部分,而且在做底层与顶层特征互补时,在统一特征尺寸的过程中,浅层卷积特征的信息丢失过多。而浅层卷积特征是遥感场景外观特征较丰富的一部分,若能充分利用浅层的外观特征信息,对于解决遥感图像数据集存在的纹理、形状和颜色上存在较大差别,以及因拍摄高度和角度不同存在的尺度差异导致的模型分类精度不高的问题,提高遥感场景分类精度会有一定的促进作用。
为此,本文提出了一种端到端的,利用主动旋转聚合来融合不同尺度特征,并通过双向门控提高浅层特征与顶层特征互补性的特征融合补偿卷积神经网络(Feature Aggregation Compensation CNN,FAC-CNN),以在进行分层特征聚合时减少浅层卷积特征信息的丢失,提高网络捕获不同旋转信息以及尺度信息的能力,从而提升模型的泛化能力。
1 遥感影像特征
由于遥感影像的获取时间、位置的不同,导致对同一类场景的获取时存在因为方向不一致而产生的纹理不一致、形状大小有明显的差异;同时也因为光照等环境因素的影响使得同一类别的地物类型颜色差异大。如图1 所示为同一类别的地物类型遥感图像在纹理、形状和颜色上存在的差别。

图1 同类图像的类内差异示例Fig.1 Examples of intra-class differences of similar images
拍摄是在不同高度、多个角度和多个方向拍摄的,也会导致获取到的图像有着尺度上差异,如图2所示。
2 经典特征聚合
经典和有效的特征聚合操作可以分为两类:级联聚合和算术聚合。级联聚合是指在特征通道上堆叠卷积特征图,如图3 所示;算术聚合是指在相同的空间位置和通道上进行卷积特征的和、乘或平均等运算,如图4 所示。其中图3 与图4的feature1、feature2 和feature3 为待聚合特征,feature4 为聚合后的特征。

图3 级联聚合示意图Fig.3 Schematic diagram of cascade aggregation

图4 算术聚合示意图Fig.4 Schematic diagram of arithmetic aggregation
1)级联聚合。
由于CNN 的固有层次结构,不同的卷积特征xi可以串联以生成具有丰富特征的。在进行级联聚合操作之前,为了通过堆叠卷积特征图来实现聚合,需要将要聚合的所有卷积特征调整为相同大小[H,W],由于是堆叠方式的聚合所以通道数C可以是任意的。级联聚合可以表示为:

2)算术聚合。

3 基于双向门控尺度特征融合分类模型
遥感场景分类可以理解为通过提取场景特征,再以不同的特征区分为不同的类别的过程。本文以VGG-16 作为特征提取器,根据文献[20]所做先验工作,选取conv3-3、conv5-1和conv5-3作为顶层高级语义特征组合,以用作特征互补。同时,通过定量分析方法(本文以conv3-3 之前的卷积特征做定量分析),在浅层卷积特征中选取3 个卷积特征层进行聚合提取浅层的外观卷积特征,并将提取到的高级语义特征、外观卷积特征与全局特征合并。最终通过sofmax 层进行场景分类。模型结构如图5 所示,左框部分为浅层特征编码提取浅层外观卷积特征,右边点虚线框部分为密集连接提取高级语义特征,实线框部分为门控连接,促进两个卷积特征的互补性,其中conv3-1 为多尺度特征融合后得到的特征图,图5 中省略了多尺度特征提取部分的另两个分支结构,最后的1×1×C中的C为分类的类别数。

图5 FAC-CNN模型结构Fig.5 FAC-CNN model structure
3.1 主动旋转特征融合
针对遥感图像由于拍摄的位置和方向不同产生的形状纹理差别较大的问题,本文提出了一种主动旋转特征融合的方式,通过主动旋转后结合级联聚合的方式来使融合后的特征图包含不同的方向信息,以使模型拥有对从未见过的旋转样本的泛化能力。
通过数据增强的方式(如旋转)扩充数据集可以使模型具备获得全局或局部旋转的捕获能力,同样,通过主动旋转的聚合方式可以在未进行数据增强的情况下有效地捕获旋转信息。如图6 所示,将特征图旋转不同的角度后进行级联聚合使不同的维度上保留了方向信息,增强特征图的浅层特征表达能力。聚合特征由每个卷积特征xi经过主动旋转后串联生成。主动旋转聚合可表示为:


图6 主动旋转变换示例Fig.6 Active rotation transformation example
图7(a)可视化展示了浅层外观卷积特征提取融合得到的特征图,图7(b)展示了未改进前VGG 的底层特征图,可以发现融合后的特征能有效地捕获到图像的结构特征并具有方向性。

图7 浅层卷积特征可视化Fig.7 Visualization of shallow convolution features
3.2 多尺度特征提取
针对遥感图像由于拍摄高度和角度的不同存在的尺度差异的问题,与其他方法利用图像金字塔将不同尺度图像输入多个网络后将最后的全连接层特征融合不同的是,本文探讨了一种直接通过改进的网络分支结构形式来提取不同尺度特征方式,以此来提高模型对不同尺度图像的识别能力,如图8所示。对于加州大学默塞德分校(University of California Merced,UC Merced)数据集、西北工业大学遥感场景分类数据集(Northwestern Polytechnical University REmote Sensing Image Scene Classification,NWPU-RESISC)中的原始图像大小为256×256 像素,采用原图缩小为224×224 像素后采用拉普拉斯金字塔向上采样与高斯图像金字塔向下采样分别得到448×448 像素和112×112 像素的图像。对于航空影像数据集(Aerial Image Dataset,AID)以及武汉大学遥感影像WHURS19(Wuhan University Remote Sensing)图像数据集原始图像大小为600×600 像素,进行等比例缩小至448×448 后采用高斯图像金字塔进行向下采样得到224×224 和112×112 像素的图像。将获取到的不同尺度的图像输入到网络的不同分支中提取特征,分支网络可以提取到网络的底层特征所包含丰富的形状和纹理信息。上部分为大尺度图像的特征提取网络,中间部分的为VGG-16的网络前5个卷积层,下部分为小尺度图像的特征提取网络,最后通过主动旋转融合方式将提取到的不同尺度的特征表示进行融合,并作为conv3-2 的特征输入。

图8 多尺度特征提取结构Fig.8 Multi-scale feature extraction structure
通过上、中和下三个分支的卷积池化操作将图像尺寸改变为56×56×256,提取图像不同尺度下的特征后利用主动旋转聚合的方式将不同尺度的特征融合在一起得到浅层特征表达能力强的特征图。该特征图经过1×1 卷积改变通道数为256 后作为conv3-1 继续输入网络conv3-2 中进一步提取高层次的语义特征,同时该特征也作为下文中的浅层卷积编码的一部分加强特征的表达能力,促进模型分类精度的提升。
3.3 浅层外观卷积特征提取
对于遥感场景分类,不同层的卷积特征是互补的。有效地利用不同层次卷积特征所包含的空间结构信息,可以提高分类精度。如文献[21-22]利用浅层的外观信息与顶层的高级语义信息来提高分类精度。因此,设计特征聚合操作充分利用不同层的辅助信息对于提高分类精度至关重要。针对顶层与底层特征聚合过程中浅层信息丢失过多的问题,本文提出了浅层卷积编码的方式以提高模型捕获浅层外观信息的能力。浅层卷积编码与传统的分别编码各层特征的编码方法不同,浅层卷积特征编码同时将所有中间卷积特征作为输入以生成卷积表示。首先,通过池化操作将不同卷积特征大小都统一成一个尺寸。其次,通过1×1 卷积操作将不同通道数的卷积特征统一成同一通道数,再利用线性整流函数(Rectified Linear Unit,ReLU)操作增强通道上卷积特征之间的互补性。1×1 卷积后紧跟ReLU 运算是一种简单有效地增加跨通道特征非线性相互作用的操作[10,23]。最后,利用主动旋转聚合的方式将各卷积特征聚合。
通过外观补偿特征选取的定量分析中,得出conv1-2、conv2-2 和conv3-1 的组合对于各数据集的准确率影响最高。选取的conv1-2、conv2-2、conv3-1 尺寸分别为224×224×64,112×112×128 和56×56×256。conv1-2 经过两步2×2 的最大池化,conv2-2 经过一步2×2 的最大池化,conv1-2 与conv2-2 的长宽都变为56×56,再利用主动旋转聚合将不同的卷积特征合并,得到56×56×448 的卷积特征,这个卷积特征再经过1×1 的卷积以及ReLU 操作后,将通道数统一成1 024,以便于与密集连接层提取到的顶层卷积特征进行互补,并利用4×4 的最大池化操作将卷积特征大小调整14×14。最终得到编码好的大小为14×14,通道数为1 024 的浅层外观卷积特征。此外,采用L2 归一化对通道间的卷积特征进行归一化[24]。因为不同卷积特征的值的大小是完全不同的,L2 归一化可以有效地避免过拟合问题。通道L2归一化的公式表示为:

3.4 高级语义特征提取
串联的层次网络在深度增加时,当输入或者梯度的信息通过很多层之后,可能会出现梯度消失或梯度爆炸。文献[11-12]通过利用残差网络与密集网络等跳跃连接的机制,很好地解决了此问题;同时,由于不需要重新学习冗余特征图,这种密集连接相较于传统连接方式只需要更少的参数也更易于训练。本文的高级语义特征提取部分基于此思想,在端到端的FAC-CNN 提取顶层高级语义卷积表示的过程时,采用密集连接机制,将conv3-3作为conv5-1的输入,conv3-3和conv5-1 作为conv5-3 的输入,最后得到的卷积特征表示作为顶层高级语义卷积特征,如图9 所示,其中:x1、x2和x3分别对应conv3-3、conv5-1、conv5-3。具体细节如下。

图9 密集连接Fig.9 Dense connection


最终得到的作为顶层高级语义卷积特征表示,作为最终的场景分类的一部分卷积特征。
3.5 双向门控连接
通过门控机制,可以有效地利用浅层外观卷积特征与顶层高级语义卷积特征的互补性以提高遥感场景分类的精度。本文采用了文献[20]中的门控机制,以更好地提升浅层外观卷积特征与顶层高级语义卷积特征的互补性。
利用门控函数控制浅层外观卷积特征xs互补信息向传递,如图10所示。

图10 双向门控连接Fig.10 Bidirectional gated connection
激励门控函数的结构,生成C(C为xs的通道数)维门控向量gs∈R1×C,每个元素取值{0,1}。xs的第i个通道乘以gs的第i个元素,消除干扰信息。将xs馈送到一个全局平均池化层,生成一个向量,将这个1×1×C的向量馈送到一个与ReLU激活函数相结合的全连通层,以及一个与sigmoid 激活函数相结合的全连通层,生成gs。gs可以表示为:

经过门控连接获得浅层卷积特征xs的补偿信息后,最终可表示为:

3.6 场景分类
将得到的浅层外观卷积特征与xs顶层高级语义卷积特征通过全局平均池化操作,将两个特征池化为1×1×1 024的特征向量,合并后与全局特征合并得到1×1×4 096 的特征向量,最后采用线性softmax 分类器进行分类。本文的FAC-CNN 采用交叉熵损失函数。如下所示:

其中:xcon是浅层外观卷积特征与高级语义特征连接后的特征;y是分类场景标签;θ是线性分类器的参数;K是遥感场景类别的数量;N是训练批次的大小;1{⋅}是一个指标函数(如果yn等于j,则1{yn=j}=1;否则1{yn=j}=0)。
本文场景分类方法的总体技术路线如图11所示。
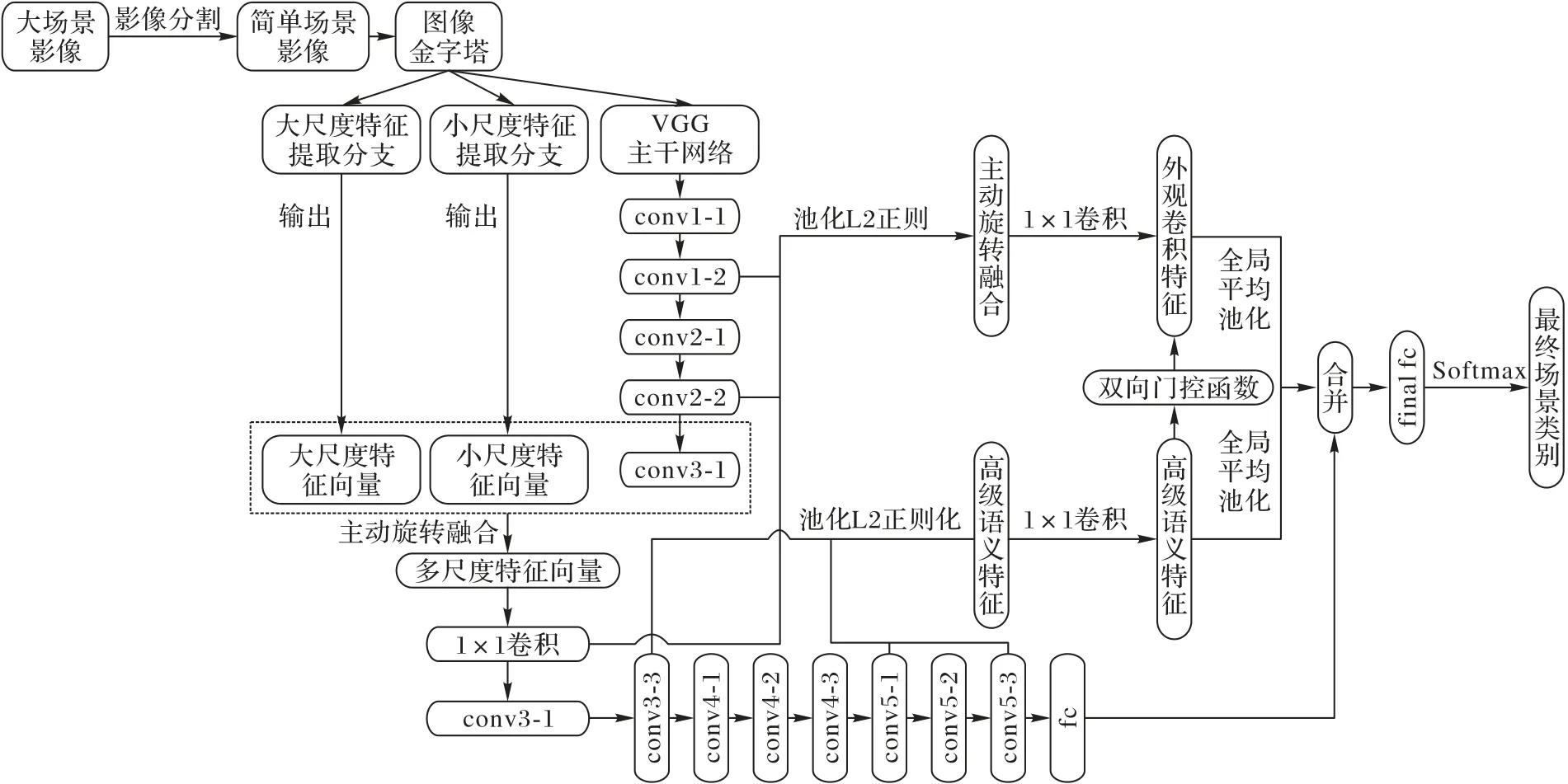
图11 总体技术路线图Fig.11 Overall technology roadmap
4 实验与结果分析
4.1 数据集
为验证本文方法有效性,在UC Merced、NWPU-RESISC、AID 和WHU-RS19 四个数据集上进行实验。为公平比较,数据集的设置与其他方法一致,选取指定比例的数据,将一部分作为训练样本剩余部分作为测试样本,UC Merced 采用50%和80%的数据作为训练样本,NWPU-RESISC 采用10%和20%的数据作为训练样本,AID 采用20%和50%的数据作为训练样本,WHU-RS19采用40%和60%的数据作为训练样本。
UC Merced 数据集从美国地质勘探局(United States Geological Survey,USGS)国家地图城市地区图像集[25]下载。该数据集包含21 个土地使用场景。每个场景包含100 张图像,共2 100 张256×256像素,空间分辨率为1ft(1 ft=30.480cm)。图12给出了部分示例。

图12 UC Merced数据集21类遥感图像示例Fig.12 Examples of 21 types of remote sensing images in UC Merced dataset
NWPU-RESISC数据集[26]是由西北工业大学(Northwestern Polytechnical University,NWPU)创建的遥感图像场景分类(RESISC)的公开基准。该数据集包含31 500 张图像,涵盖45个场景类别,每个类别700个图像。
AID数据集是由华中科技大学和武汉大学于2017年发布的遥感数据集,它包含30 个遥感场景类别,每个类别有220~420张,整体共计10 000张600×600像素的图像。
WHU-RS19 数据集是由武汉大学于2011 年发布的遥感数据集,它包含19 个遥感场景类别,总共有1 005 张,每个类别至少包含50张600×600像素的图像。
USGS数据集大小为10 000×9 000像素,空间分辨率为2 ft的大幅遥感影像如图13 所示,主要包含居住区、农场、森林和停车场四个类别。
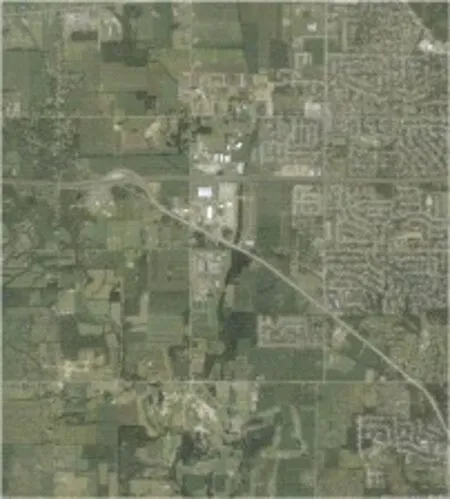
图13 USGS遥感影像Fig.13 USGS remote sensing image
4.2 实验参数设置
本文提出的FAC-CNN 中端到端训练的详细参数设置如表1 所示。初始学习率设置为0.001,在经过50 个epoch 后学习率除以10,批大小设置为32,采用随机梯度下降算法训练参数且动量设置为0.9,使用ImageNet 上预训练的VGG-16 初始化网络模型的权重参数。分支网络权重初始化采用XAvier初始化。

表1 超参数设置Tab.1 Hyperparameter setting
4.3 评价指标
实验结果采用平均总体分类准确率、标准差和混淆矩阵作为分类性能的评估方法。总体分类准确率计算方法如式(13)所示:

其中:N为测试样本的总数;T为各类型分类正确数的总和。
平均总体分类准确率和标准差的计算公式如式(14)~(15)所示:

其中:M为重复实验的次数,本文M为10。
混淆矩阵从不同的侧面反映了图像分类的精度,可以直观地展示各类型之间的混淆比率。其中行为真实类型,列为预测类型。矩阵的对角线元素为各类型的分类准确率,其他任意元素xi,j代表第i类被误识为第j类场景占该类型的比率。
4.4 外观卷积特征选取定量分析
分析conv3-3 之前的conv1-1、conv1-2、conv2-1、conv2-2、conv3-1 以及conv3-2 共有6 个卷积特征,从中选取3 个特征,共20 种组合。在仅作为特征信息辅助,验证不同组合对场景分类的结果影响。在表2 中,展示了对数据集准确率影响前三的浅层特征组合。

表2 每个数据集准确率前三的浅层特征组合Tab.2 Top three shallow feature combinations for each dataset in accuracy
从表2可看出:对于UC Merced数据集准确率影响最高的组合是conv1-2、conv2-2、conv3-1,达到了97.98%,可以发现conv2-2 与conv3-1 对该数据集的准确率影响较高。对于NWPU-RESISC 数据集准确率影响最高的组合是conv2-1、conv2-2、conv3-2,达到了93.32%,top3 中有两个较高准确率的组合都包含了conv1-2 与conv3-1。对于AID 数据集准确率影响最高的组合是conv2-1、conv2-2、conv3-1,达到了94.05%,对于WHU-RS19 数据集准确率影响最高的组合是conv1-1、conv2-2、conv3-1,达到了98.34%。
图14 展示了卷积特征的不同组合的分类结果,组合序号1 表示conv1-1、conv1-2 和conv2-1 的组合;组合序号2 表示conv1-1、conv1-2 和conv2-2 的组合2;依此类推,组合序号20表示conv2-2、conv3-1 和conv3-2 的组合。从图14 中可以看到不同组合对不同数据集的准确率影响变化情况。根据实验结果提出的模型采用了对四个数据集都有较高的准确率提升的conv1-2,conv2-2,conv3-1的组合作为外观卷积特征。

图14 卷积特征的不同组合的分类结果Fig.14 Classification results of different combinations of convolution features
4.5 消融实验
在四个数据集上的结果表明,本文方法分类准确率在UCMerced 与WHU-RS19 数据集上与最先进的ARCNet-VGGNet16 相当,而在NWPU-RESISC 与AID 数据集上则高于其他方法。为进一步分析本文方法的性能,在NWPU-RESISC数据集上对组合方式进行了消融实验。在消融实验中,随机选择每个遥感场景类别中20%的图像进行训练。
1)只通过浅层特征编码提取浅层外观卷积特征,并将该特征与第二个全局特征(Globle Feature,CF)层合并,特征编码模块采用算术和聚合。
2)只通过浅层特征编码提取浅层外观卷积特征,并将该特征与第二个FC 层合并,特征编码模块采用算术最大值聚合。
3)只通过浅层特征编码提取浅层外观卷积特征,并将该特征与第二个FC层合并,特征编码模块采用算术乘聚合。
4)只通过浅层特征编码提取浅层外观卷积特征,并将该特征与第二个FC层合并,特征编码模块采用主动旋转聚合。
5)只采用密集连接机制提取高级语义卷积特征作为补偿信息,并将该特征与第二个FC合并。
6)只采用特征编码与密集连接机制分别提取浅层特征与顶层特征,两类特征聚合后直接作为分类的特征。
7)只采用特征编码与密集连接机制分别提取浅层特征与顶层特征,并通过门控机制将两个卷积特征进行互补,进行合并后得到的特征直接作为分类特征。
8)只采用特征编码与密集连接机制分别提取浅层特征与顶层特征,并通过门控机制将两个卷积特征进行互补,进行合并后得到的特征与全局特征合并,再通过softmax进行分类。
9)利用图像金字塔和分支网络提取多尺度特征,采用特征编码与密集连接机制分别提取浅层特征与顶层特征,并通过门控机制将两个卷积特征进行互补,进行合并后得到的特征与全局特征合并,再通过softmax进行分类。
实验结果如表3 所示。本文的FAC-CNN 在NWPURESISC 上的准确率达到了94.96%。在采用的聚合方法中,采用主动旋转聚合的方法准确率比采用算术和聚合的方法高0.86 个百分点,比算数最大值聚合方法高1.63 个百分点,比算数乘聚合的方法高2.24 个百分点,验证了提出的主动旋转聚合的有效性。从表3 可以看出,密集连接相较于只用浅层卷积编码要高是由于浅层卷积特征作为辅助信息会对分类结果有提升精度的作用,若浅层卷积特征直接作为分类特征,则精度会比高层语义卷积特征低。门控函数的引入有效地促进了浅层外观卷积特征与顶层高级语义卷积特征的互补,使精度有一定的提升,而结合多尺度特征后使模型的准确度达到了94.96%。

表3 在NWPU-RESISC数据集上的消融实验结果Tab.3 Ablation experiment results on NWPU-RESISC dataset
4.6 结果与分析
在4 个公共遥感场景数据集上,将FAC-CNN 的性能与一些最新方法进行了比较,并在USGS 大幅遥感影像上可视化展示了模型的分类结果。各数据集验证集验证过程中的准确率变化曲线如图15所示。
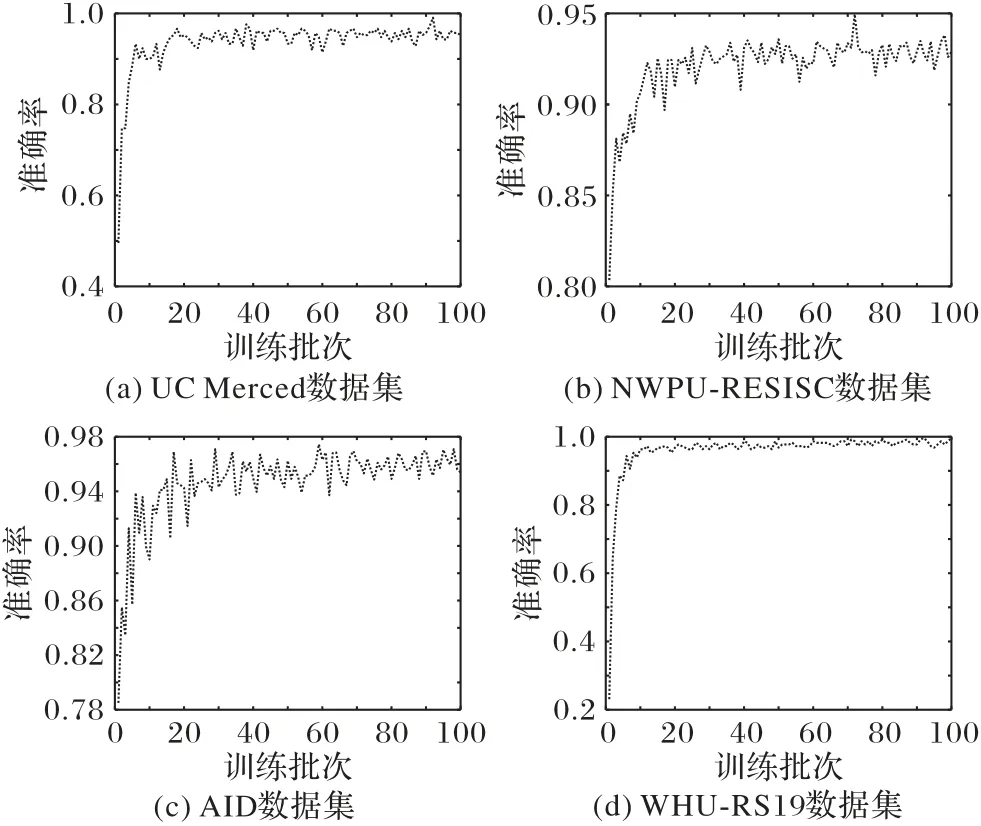
图15 各数据集的准确率变化曲线Fig.15 Accuracy change curve for each dataset
如表4 所示:在80%的训练比率下,本文的FAC-CNN 分类准确率比AlexNet高4.09个百分点,比VGG-16和ResNet分别高3.88 个百分点和2.9 个百分点,与已在UC Merced 数据集上对超参数进行了优化的基于VGGNet 的注意循环卷积网络(Attention Recurrent Convolutional Network,ARCNet-VGGNet)方法相当;在50%的训练比率下,优于ARCNet-VGGNet与GBNet约1.56个百分点与1.32个百分点。

表4 不同方法在UC Mereced数据集上的分类准确率 单位:%Tab.4 Classification accuracies of different methods on UC Mereced dataset unit:%
NWPU-RESISC 数据集是一个新的遥感场景分类公开基准。此数据集包含45类场景,场景非常的复杂。如表5所示:在20%的训练比率下本文的FAC-CNN 分类准确率比VGG-16和ResNet 高4.31 个百分点和3.70 个百分点;比ARCNet-VGGNet16 和GBNet 高2.05 个百分点和2.69 个百分点;在10%的训练比率下,分别比ARCNet-VGGNet16 和GBNet 高2.43个百分点和2.71个百分点。

表5 不同方法在NWPU-RESISC数据集上的分类准确率 单位:%Tab.5 Classification accuracies of different methods on NWPU-RESISC dataset unit:%
如表6 所示:在AID 数据集50%的训练比率下本文的FAC-CNN分类准确率与最新遥感场景分类方法之一ARCNet-VGGNet16 相比高出3.24 个百分点,与GBNet 方法相比高出0.86 个百分点;在20%训练比率下则分别高于这两个方法4.14个百分点和0.69个百分点。

表6 不同方法在AID数据集上的分类准确率 单位:%Tab.6 Classification accuracies of different methods on AID unit:%
如表7 所示,在WHU-RS19 数据集60%的训练比率下本文的FAC-CNN 分类准确率VGG-16 和RestNet 相比分别高出3.10 个百分点和2.66 个百分点,但却略低于ARCNet-VGGNet16与GBNet。
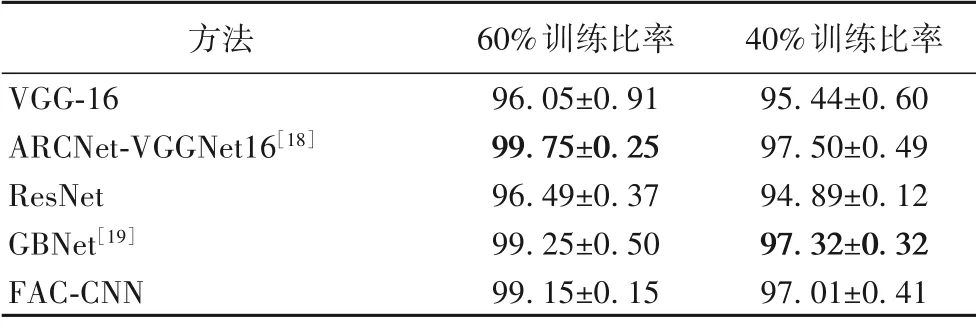
表7 不同方法在WHU-RS19数据集上的分类准确率 单位:%Tab.7 Classification accuracies of different methods on WHU-RS19 dataset unit:%
各数据集的混淆矩阵结果因版面限制,仅展示FAC-CNN在AID 数据集50%训练比率下的混淆矩阵。FAC-CNN 在UC Merced 数据集80%训练比率下的混淆矩阵平均准确率为99.09%。FAC-CNN 在NWPU-RESISC 数据集20%训练比率下的混淆矩阵平均准确率为94.96%。FAC-CNN 在AID 数据集50%训练比率下的混淆矩阵如图16 所示,平均准确率为96.34%。FAC-CNN 在WHU-RS19 数据集60%训练比率下的混淆矩阵平均准确率为99.15%。

图16 FAC-CNN在AID数据集上的训练比率为50%下的混淆矩阵Fig.16 Confusion matrix of FAC-CNN on AID dataset at training ratio of 50%
对于遥感图像数据集类间主要依靠形状、纹理和颜色来区分的图像,浅层的外观卷积特征所包含的形状以及纹理信息往往能辅助模型区分这些类别。如图17(a)所示从左到右分别为NWPU-RESISC 数据集中的圆形农田、矩形农田和梯田三个类别,整体颜色基本都以绿色为主,而其主要区别就在于形状纹理的不同。从NWPU 数据集的混淆矩阵可以得出,这三个类别的分类准确率分别达到1.0、0.99和0.99,三个类别的平均识别准确率与复现的ARCNet-VGGNet16 以及GBNet三个类别识别准确率平均值相比分别高出了0.04个百分点和0.03 个百分点,相较于原始VGG-16 模型提高了0.06个百分点。如图17(b)所示为AID数据集的沙漠与裸地类别,其中前两张图为沙漠而后两张图为裸地,沙漠类别呈现出规则的纹理形状,而裸地呈现出不规则的纹理形状,这也是区分这两类的重要特征之一。从文献[18-19]的实验结果中看出沙漠类别较多地被预测错误为裸地,错误识别比率达到0.05。而从图16 的混淆矩阵可以看出,本文在浅层卷积特征的辅助下沙漠并没有被错误地预测为裸地,错误识别比率为0。
如图17(c)所示从左到右分别为AID数据集中的学校、旅游胜地和公园三个类别。在文献[18-19]与本文的实验结果混淆矩阵可以发现,学校被较多地错误预测为旅游胜地类别,旅游胜地被较多地预测错误为公园类别。在这类无法通过形状以及纹理等浅层特征去有效区分的类别上,本文在没有采用数据增强,而是通过主动旋转融合以及多尺度特征提取来提升模型的泛化能力的情况下,识别准确率与ARCNet-VGGNet16和GBNet效果相当。
对于如图1 所示类别的颜色和形状纹理本身以及如图2所示的因为拍摄角度、方向或高度不同导致类内产生较大差异的遥感影像,FAC-CNN、ARCNet-VGGNet16 和GBNet 在纹理差异较大的UC Merced 数据集的农田类别中,都达到了1.0的准确率,在尺度差异较大的存储罐中,在尺度特征的辅助下FAC-CNN分类准确率达到0.97,相较于ARCNet高了0.02,但略低于GBNet。
USGS大幅遥感影像实验中,居住区、农场、森林和停车场的四个场景类别分别包含143、133、100 和139 个小图像。从每个场景类别中随机选择总共50 张图像作为训练样本,其余图像用于测试。本文将USGS 分割为150×150 像素的简单场景图像,同时为了能较好保留在大影像在采样期间丢失的空间信息,将两个相邻分割图像之间的重叠设置为25 个像素。将分割好的影像分别输入到训练好的4 分类模型中,USGS 最终的分类结果如图18 所示。为了定量评估分类的结果,将分类结果与USGS 标签样本的像素数量进行了对比,四个场景的带标签样本像素数量如表8 所示,按最终分类正确的像素数计算得到平均分类准确率为96.28%,主要错误来源于道路部分不属于任何一类的影像。

表8 各场景类别中的带标记像素量Tab.8 Number of labeled samples in each scene category

图18 USGS分类结果Fig.18 USGS classification result
实验结果表明,本文提出的主动旋转融合以及多尺度特征可以有效解决遥感影像数据集的图像在形状、纹理和颜色上存在较大差别,以及因拍摄高度和角度不同存在的尺度差异导致遥感场景分类精度不高的问题。在数据量较少的数据集情况下,这类特征引入分类网络中使模型的分类准确率与最新的方法之一ARCNet-VGGNet16 以及GBNet 结果相当。在USGS 大幅遥感影像场景分类任务下,本文方法也取得较好的结果。
5 结语
本文提出了一种端到端的基于双向门控尺度特征融合的分类模型FAC-CNN,该网络在VGG-16 卷积神经网络的基础上,通过利用图像金字塔将输入图像变换为不同尺度的图像并输入分支网络中提取尺度特征,并利用主动旋转聚合得到的尺度特征馈入网络中。同时,得到的多尺度特征也将作为外观卷积特征的一部分作用在浅层外观卷积特征的提取过程中并利用双向门控来提升浅层外观卷积特征与高级语义特征的互补性,最终聚合这两类特征后利用softmax 分类器完成分类任务。在5 个公开数据集的实验结果表明,对多尺度特征的提取以及结合主动旋转聚合,可以较好地解决遥感影像数据集的图像在形状、纹理和颜色上存在较大差别,以及因拍摄高度和角度不同存在的尺度差异导致遥感场景分类精度不高的问题,使模型分类准确率得到进一步提高。
猜你喜欢
水土保持学报(2022年5期)2022-10-10
建材发展导向(2021年24期)2021-02-12
马克思主义哲学研究(2020年1期)2020-11-26
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
太空探索(2016年5期)2016-07-12
吉林农业(2016年4期)2016-05-14
时代英语·高三(2014年5期)2014-08-26
微型计算机(2009年4期)2009-12-23
雕塑(2000年2期)2000-06-22
